
Zrozumienie raportu o zasięgu w Search Console
Opublikowany: 2019-08-15Wprowadzenie do raportu pokrycia i jak interpretować dane
Raport dotyczący zasięgu w Search Console zawiera informacje o tym, które strony w Twojej witrynie zostały zindeksowane, oraz zawiera listę adresów URL, które sprawiały problemy, gdy Googlebot próbował je przeszukać i zindeksować.
Strona główna raportu pokrycia pokazuje adresy URL w Twojej witrynie pogrupowane według stanu:
- Błąd: strona nie jest zindeksowana. Istnieje kilka powodów takiego stanu rzeczy, między innymi strony reagujące na 404, miękkie strony 404.
- Obowiązuje z ostrzeżeniami: strona jest zaindeksowana, ale występują problemy.
- Prawidłowy: strona jest zindeksowana.
- Wykluczono: strona nie jest indeksowana, Google przestrzega zasad w witrynie, takich jak tagi noindex w pliku robots.txt lub metatagi, tagi kanoniczne itp., które uniemożliwiają indeksowanie stron.
Ten raport o zasięgu zawiera o wiele więcej informacji niż stara konsola wyszukiwania Google. Google naprawdę poprawiło udostępniane dane, ale wciąż jest kilka rzeczy, które wymagają poprawy.
Jak widać poniżej, Google pokazuje wykres z liczbą adresów URL w każdej kategorii. Jeśli nastąpi nagły wzrost liczby błędów, możesz zobaczyć paski, a nawet skorelować je z wyświetleniami, aby określić, czy wzrost adresów URL z błędami lub ostrzeżeniami może obniżyć liczbę wyświetleń.

Po uruchomieniu witryny lub utworzeniu nowych sekcji chcesz widzieć rosnącą liczbę prawidłowych zindeksowanych stron. Zindeksowanie nowych stron przez Google zajmuje kilka dni, ale możesz użyć narzędzia do sprawdzania adresów URL, aby zażądać indeksacji i skrócić czas znajdowania nowej strony przez Google.

Jeśli jednak zauważysz malejącą liczbę prawidłowych adresów URL lub zauważysz nagłe wzrosty, ważne jest, aby zidentyfikować adresy URL w sekcji Błędy i naprawić problemy wymienione w raporcie. Google zapewnia dobre podsumowanie działań, które należy wykonać w przypadku wzrostu liczby błędów lub ostrzeżeń.
Google dostarcza informacji o błędach i liczbie adresów URL, w których występuje ten problem:

Pamiętaj, że Google Search Console nie pokazuje 100% dokładnych informacji. W rzeczywistości pojawiło się kilka raportów o błędach i anomaliach danych. Ponadto aktualizacja Google Search Console wymaga czasu, wiadomo, że dane są opóźnione od 16 do 20 dni. Ponadto raport czasami pokazuje więcej niż 1000 stron w kategoriach błędów lub ostrzeżeń, jak widać na powyższym obrazku, ale pozwala tylko zobaczyć i pobrać próbkę 1000 adresów URL do audytu i sprawdzenia.
Niemniej jednak jest to świetne narzędzie do wyszukiwania problemów z indeksacją w Twojej witrynie:
Gdy klikniesz określony błąd, zobaczysz stronę szczegółów zawierającą przykłady adresów URL:

Jak widać na powyższym obrazku, jest to strona szczegółów dla wszystkich adresów URL, które odpowiadają 404. Każdy raport ma link „Więcej informacji”, który prowadzi do strony dokumentacji Google zawierającej szczegółowe informacje na temat tego konkretnego błędu. Google udostępnia również wykres przedstawiający liczbę stron, których dotyczy problem, w czasie.
Możesz kliknąć każdy adres URL, aby sprawdzić adres URL, który jest podobny do starej funkcji „pobierz jako Googlebot” ze starej Google Search Console. Możesz także sprawdzić, czy strona jest blokowana przez plik robots.txt
Po naprawieniu adresów URL możesz poprosić Google o ich weryfikację, aby błąd zniknął z raportu. W pierwszej kolejności należy naprawiać problemy, które są w stanie walidacji „niepowodzenie” lub „nie rozpoczęto”.
Należy wspomnieć, że nie należy oczekiwać, że wszystkie adresy URL w Twojej witrynie zostaną zaindeksowane. Google twierdzi, że celem webmastera powinno być zindeksowanie wszystkich kanonicznych adresów URL. Zduplikowane lub alternatywne strony zostaną sklasyfikowane jako wykluczone, ponieważ mają podobną treść jak strona kanoniczna.
To normalne, że witryny zawierają kilka stron w wykluczonej kategorii. Większość witryn zawiera kilka stron bez metatagów indeksu lub blokowanych przez plik robots.txt. Gdy Google zidentyfikuje zduplikowaną lub alternatywną stronę, upewnij się, że te strony mają tag kanoniczny wskazujący poprawny adres URL i spróbuj znaleźć odpowiednik kanoniczny w prawidłowej kategorii.
Google umieścił filtr rozwijany w lewym górnym rogu raportu, dzięki czemu można filtrować raport pod kątem wszystkich znanych stron, wszystkich zgłoszonych stron lub adresów URL w określonej mapie witryny. Raport domyślny obejmuje wszystkie znane strony, w tym wszystkie adresy URL wykryte przez Google. Wszystkie przesłane strony zawierają wszystkie adresy URL zgłoszone za pośrednictwem mapy witryny. Jeśli przesłałeś kilka map witryn, możesz filtrować według adresów URL w każdej mapie witryny.
[Studium przypadku] Zwiększ budżet indeksowania na strategicznych stronach
 Przeczytaj studium przypadku
Przeczytaj studium przypadkuBłędy, ostrzeżenia, prawidłowe i wykluczone adresy URL
Błąd
- Błąd serwera (5xx): serwer zwrócił błąd 500, gdy Googlebot próbował zaindeksować stronę.
- Błąd przekierowania: podczas indeksowania adresu URL przez Googlebota wystąpił błąd przekierowania, ponieważ łańcuch był zbyt długi, wystąpiła pętla przekierowania, adres URL przekroczył maksymalną długość adresu URL lub w łańcuchu przekierowań był zły lub pusty adres URL.
- Przesłany adres URL zablokowany przez plik robots.txt: adresy URL z tej listy są blokowane przez plik robts.txt.
- Przesłany adres URL oznaczony „noindex”: adresy URL na tej liście mają tag meta robots „noindex” lub nagłówek http.
- Przesłany adres URL wydaje się być miękkim 404: miękki błąd 404 występuje, gdy strona, która nie istnieje (została usunięta lub przekierowana) wyświetla użytkownikowi komunikat „nie znaleziono strony”, ale nie zwraca kodu stanu HTTP 404. Miękkie błędy 404 zdarzają się również, gdy strony są przekierowywane na nieistotne strony, na przykład na stronę przekierowującą na stronę główną zamiast zwracania kodu stanu 404 lub przekierowywania do odpowiedniej strony.
- Przesłany adres URL zwraca nieautoryzowane żądanie (401): Strona przesłana do indeksowania zwraca nieautoryzowaną odpowiedź HTTP 401.
- Nie znaleziono przesłanego adresu URL (404): strona odpowiedziała błędem 404 Nie znaleziono, gdy Googlebot próbował ją zaindeksować.
- Przesłany adres URL ma problem z indeksowaniem: Googlebot napotkał błąd indeksowania podczas indeksowania tych stron, które nie należą do żadnej z pozostałych kategorii. Musisz sprawdzić każdy adres URL i określić, na czym mógł polegać problem.
Ostrzeżenie
- Zindeksowana, ale zablokowana przez plik robots.txt: strona została zaindeksowana, ponieważ Googlebot uzyskał do niej dostęp za pośrednictwem zewnętrznych linków prowadzących do strony, jednak strona jest zablokowana przez plik robots.txt. Google oznacza te adresy URL jako ostrzeżenia, ponieważ nie ma pewności, czy strona powinna być rzeczywiście zablokowana w wynikach wyszukiwania. Jeśli chcesz zablokować stronę, użyj metatagu „noindex” lub użyj nagłówka odpowiedzi HTTP noindex.
Jeśli Google jest poprawny, a adres URL został nieprawidłowo zablokowany, zaktualizuj plik robots.txt, aby umożliwić Google indeksowanie strony.
Ważny
- Przesłane i zindeksowane: adresy URL przesłane do Google za pośrednictwem sitemap.xml w celu zindeksowania i zostały zindeksowane.
- Zindeksowany, nie przesłany w mapie witryny: adres URL został wykryty przez Google i zindeksowany, ale nie został uwzględniony w mapie witryny. Zaleca się zaktualizowanie mapy witryny i uwzględnienie wszystkich stron, które Google ma przeszukiwać i indeksować.
Wyłączony
- Wykluczone przez tag „noindex”: gdy Google próbował zindeksować stronę, znalazł metatag robotów „noindex” lub nagłówek HTTP.
- Zablokowana przez narzędzie do usuwania stron: ktoś przesłał do Google prośbę o nieindeksowanie tej strony za pomocą żądania usunięcia adresu URL w Google Search Console. Jeśli chcesz, aby ta strona została zindeksowana, zaloguj się do Google Search Console i usuń ją z listy usuniętych stron.
- Zablokowany przez robots.txt: plik robots.txt zawiera wiersz, który wyklucza indeksowanie adresu URL. Możesz sprawdzić, która linia to robi, korzystając z testera pliku robots.txt.
- Zablokowane z powodu nieautoryzowanego żądania (401): Tak samo jak w kategorii Błąd, strony tutaj zwracane są z nagłówkiem HTTP 401.
- Anomalia indeksowania: jest to kategoria typu catch-all, adresy URL tutaj odpowiadają kodami odpowiedzi na poziomie 4xx lub 5xx; Te kody odpowiedzi uniemożliwiają indeksację strony.
- Zindeksowane – obecnie nieindeksowane: Google nie podaje powodu, dla którego adres URL nie został zindeksowany. Sugerują ponowne przesłanie adresu URL do indeksacji. Jednak ważne jest, aby sprawdzić, czy strona ma ubogą lub zduplikowaną treść, jest kanonizowana na inną stronę, ma dyrektywę noindex, wskaźniki pokazują złe wrażenia użytkownika, długi czas ładowania strony itp. Może być kilka powodów, dla których Google nie chce indeksować strony.
- Odnalezione – aktualnie nieindeksowane: Strona została znaleziona, ale Google nie uwzględnił jej w swoim indeksie. Możesz przesłać adres URL do indeksacji, aby przyspieszyć proces, jak wspomnieliśmy powyżej. Google twierdzi, że typowym powodem, dla którego tak się dzieje, jest przeciążenie witryny i zmiana harmonogramu indeksowania.
- Alternatywna strona z odpowiednim tagiem kanonicznym: Google nie zaindeksował tej strony, ponieważ zawiera ona tag kanoniczny wskazujący inny adres URL. Firma Google zastosowała się do reguły kanonicznej i poprawnie zindeksowała kanoniczny adres URL. Jeśli chciałeś, aby ta strona nie była indeksowana, nie ma tu nic do naprawienia.
- Duplikat bez kanonicznych wybranych przez użytkownika: Google znalazł duplikaty stron wymienionych w tej kategorii i żadna nie używa tagów kanonicznych. Google wybrał inną wersję jako tag kanoniczny. Musisz przejrzeć te strony i dodać tag kanoniczny wskazujący poprawny adres URL.
- Zduplikowane, Google wybrał inny kanoniczny niż użytkownik: adresy URL w tej kategorii zostały wykryte przez Google bez wyraźnego żądania indeksowania. Google znalazł je za pomocą zewnętrznych linków i ustalił, że istnieje inna strona, która czyni lepszą kanoniczną. Z tego powodu Google nie zaindeksował tych stron. Google zaleca oznaczenie tych adresów URL jako duplikatów adresu kanonicznego.
- Nie znaleziono (404): gdy Googlebot próbuje uzyskać dostęp do tych stron, odpowiada błędem 404. Google twierdzi, że te adresy URL nie zostały przesłane, te adresy URL zostały znalezione za pomocą zewnętrznych linków prowadzących do tych adresów URL. Dobrym pomysłem jest przekierowanie tych adresów URL na podobne strony, aby skorzystać z kapitału linków, a także upewnić się, że użytkownicy trafiają na odpowiednią stronę.
- Strona usunięta z powodu skargi prawnej: ktoś złożył skargę dotyczącą tych stron z powodu problemów prawnych, takich jak naruszenie praw autorskich. Tutaj możesz odwołać się od złożonej skargi prawnej.
- Strona z przekierowaniem: te adresy URL przekierowują, dlatego są wykluczone.
- Soft 404: Jak wyjaśniono powyżej, te adresy URL są wykluczone, ponieważ powinny odpowiadać 404. Sprawdź strony i upewnij się, że jeśli zawiera komunikat „nie znaleziono”, aby odpowiedziały nagłówkiem HTTP 404.
- Zduplikowany, przesłany adres URL, który nie został wybrany jako kanoniczny: podobnie jak „Google wybrał inny kanoniczny niż użytkownik”, jednak adresy URL w tej kategorii zostały przesłane przez Ciebie. Dobrym pomysłem jest sprawdzenie map witryn i upewnienie się, że nie zawierają zduplikowanych stron.
Jak wykorzystać dane i elementy działań do ulepszenia witryny?
Pracując w agencji, mam dostęp do wielu różnych stron i raportów z ich zasięgu. Poświęciłem czas na analizę błędów zgłaszanych przez Google w różnych kategoriach.
Pomocne było znalezienie problemów z kanonizacją i powielaniem treści, jednak czasami można napotkać rozbieżności, takie jak te zgłoszone przez @jroakes:

Wygląda na to, że Google Search Console > Inspekcja adresów URL > Test na żywo nieprawidłowo zgłasza wszystkie pliki JS i CSS jako dozwolone indeksowanie: Nie: zablokowane przez plik robots.txt. Przetestuj około 20 plików w 3 domenach. pic.twitter.com/fM3WAcvK8q
— JR%20Oakes ???? (@jroakes) Lipiec 16, 2019
AJ Koh napisał świetny artykuł wkrótce po udostępnieniu nowej konsoli Google Search Console, w którym wyjaśnia, że prawdziwą wartością danych jest ich wykorzystanie do namalowania obrazu stanu zdrowia dla każdego rodzaju treści w Twojej witrynie:
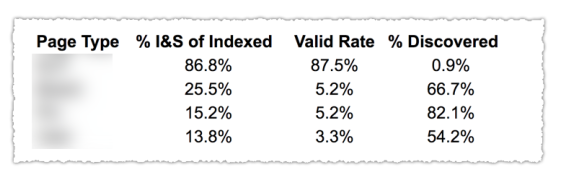
Jak widać na powyższym obrazku, adresy URL z różnych kategorii w raporcie pokrycia zostały sklasyfikowane według szablonu strony, takiego jak blog, strona usługi itp. Korzystanie z kilku map witryn dla różnych typów adresów URL może pomóc w tym zadaniu, ponieważ Google zezwala na możesz filtrować informacje o zasięgu według mapy witryny. Następnie dołączył trzy kolumny z następującymi informacjami: % zindeksowanych i przesłanych stron, Ważna stawka i % wykrytych.
Ta tabela naprawdę daje doskonały przegląd stanu Twojej witryny. Teraz, jeśli chcesz zagłębić się w różne sekcje, polecam przejrzenie raportów i dwukrotne sprawdzenie błędów przedstawianych przez Google.
Możesz pobrać wszystkie adresy URL prezentowane w różnych kategoriach i użyć OnCrawl, aby sprawdzić ich stan HTTP, znaczniki kanoniczne itp. oraz utworzyć arkusz kalkulacyjny, taki jak ten:
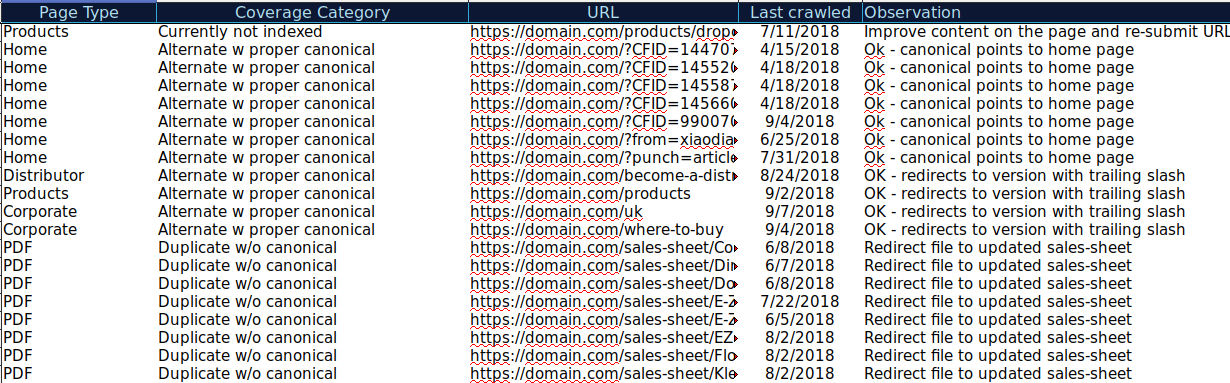
Takie uporządkowanie danych może pomóc w śledzeniu problemów, a także w dodawaniu działań do adresów URL, które należy poprawić lub naprawić. Możesz też odznaczyć adresy URL, które są poprawne i nie są wymagane żadne działania w przypadku tych adresów URL z parametrami z poprawnie zaimplementowaną kanoniczną implementacją tagu.
Rozpocznij bezpłatny 14-dniowy okres próbny
 Rozpocznij okres próbny
Rozpocznij okres próbnyMożesz nawet dodać więcej informacji do tego arkusza kalkulacyjnego z innych źródeł, takich jak ahrefs, Majestic i Google Analytics z integracją OnCrawl. Umożliwiłoby to wyodrębnienie danych linków, a także danych o ruchu i konwersji dla każdego adresu URL w Google Search Console. Wszystkie te dane mogą pomóc w podejmowaniu lepszych decyzji dotyczących tego, co zrobić dla każdej strony, na przykład jeśli masz listę stron z 404, możesz powiązać to z linkami zwrotnymi, aby określić, czy tracisz jakikolwiek udział linków z domen, do których prowadzą linki zepsute strony w Twojej witrynie. Możesz też sprawdzić zindeksowane strony i sprawdzić, jaki ruch organiczny uzyskują. Możesz zidentyfikować zindeksowane strony, które nie generują ruchu organicznego, i popracować nad ich optymalizacją (poprawą treści i użyteczności), aby zwiększyć ruch na tej stronie.
Dzięki tym dodatkowym danym możesz utworzyć tabelę podsumowania w innym arkuszu kalkulacyjnym. Możesz użyć formuły =LICZ.JEŻELI(zakres, kryteria), aby policzyć adresy URL w każdym typie strony (ta tabela może uzupełniać tabelę zasugerowaną powyżej przez AJ Kohn). Możesz również użyć innej formuły, aby dodać linki zwrotne, wizyty lub konwersje wyodrębnione dla każdego adresu URL i wyświetlić je w tabeli podsumowującej za pomocą następującej formuły =SUMA.JEŻELI (zakres, kryteria, [zakres_suma]). Otrzymasz coś takiego:
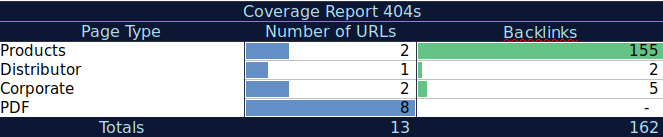
Bardzo lubię pracować z tabelami podsumowania, które dają mi podsumowanie danych i pomagają mi zidentyfikować sekcje, na których najpierw muszę się skupić.
Końcowe przemyślenia
O czym należy pamiętać podczas pracy nad rozwiązywaniem problemów i przeglądaniem danych w tym raporcie: Czy moja witryna jest zoptymalizowana pod kątem indeksowania? Czy liczba moich zindeksowanych i prawidłowych stron rośnie czy maleje? Strony z błędami rosną czy maleją? Czy pozwalam Google spędzać czas na adresach URL, które przyniosą większą wartość moim użytkownikom, czy też znajduje wiele bezwartościowych stron? Mając odpowiedzi na te pytania, możesz zacząć ulepszać swoją witrynę, tak aby Googlebot mógł wydawać budżet indeksowania na stronach, które mogą zapewnić użytkownikom wartość, a nie strony bezwartościowe. Możesz użyć pliku robots.txt, aby poprawić wydajność indeksowania, usunąć bezwartościowe adresy URL, jeśli to możliwe, lub użyć tagów kanonicznych lub noindex, aby zapobiec duplikowaniu treści.
Google stale dodaje funkcje i aktualizuje dokładność danych do różnych raportów w konsoli wyszukiwania Google, więc mamy nadzieję, że nadal będziemy widzieć więcej danych w każdej z kategorii w raporcie pokrycia, a także w innych raportach w Google Search Console.