
Wzrost liczby wyszukiwań multimodalnych i wielojęzycznych
Opublikowany: 2022-01-06Rozszerzenie wyszukiwania poza zapytania tekstowe i usuwanie barier językowych to najnowsze trendy kształtujące przyszłość wyszukiwarek. Dzięki nowym funkcjom opartym na sztucznej inteligencji wyszukiwarki starają się promować lepsze doświadczenie wyszukiwania, a jednocześnie udostępniać nowe narzędzia, które pomogą użytkownikom uzyskać określone informacje. W tym artykule zajmiemy się rosnącym tematem multimodalnych i wielojęzycznych systemów wyszukiwania . Pokażemy również wyniki narzędzia wyszukiwania demo, które zbudowaliśmy w Wordlift.
Następna generacja wyszukiwarek
Dobre wrażenia użytkownika obejmują wiele aspektów interakcji między użytkownikami a wyszukiwarkami. Od projektu interfejsu użytkownika i jego użyteczności po zrozumienie intencji wyszukiwania i rozwiązywanie niejednoznacznych zapytań, duże wyszukiwarki przygotowują nową generację narzędzi wyszukiwania .
Wyszukiwanie multimodalne
Jednym ze sposobów opisania multimodalnej wyszukiwarki jest myślenie o systemie, który jest w stanie obsłużyć tekst i obrazy w jednym zapytaniu . Takie wyszukiwarki umożliwiłyby użytkownikom wyrażanie zapytań wejściowych za pomocą multimodalnego interfejsu wyszukiwania, a w rezultacie umożliwiłyby bardziej naturalne i intuicyjne wyszukiwanie.
W witrynie e-commerce multimodalna wyszukiwarka umożliwiłaby pobieranie odpowiednich dokumentów z indeksowanej bazy danych. Trafność ocenia się, mierząc podobieństwo dostępnych produktów do danego zapytania w więcej niż jednym formacie, takim jak tekst, obraz, dźwięk lub wideo. W rezultacie ta wyszukiwarka jest systemem multimodalnym, ponieważ mechanizmy leżące u jej podstaw są w stanie obsługiwać jednocześnie różne mody wejściowe, czyli formaty.
Na przykład zapytanie wyszukiwania może przybrać formę „sukienki w kwiaty”. W tym przypadku w sklepie internetowym dostępna jest duża liczba sukienek w kwiaty. Jednak wyszukiwarka zwraca sukienki, które nie są tak naprawdę satysfakcjonujące dla użytkownika, jak pokazano na poniższym rysunku.
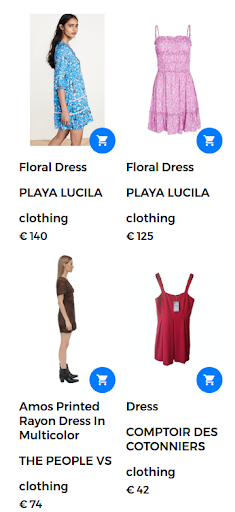
Zwrócono wyniki dla zapytania „sukienka w kwiaty”.
Aby zapewnić dobrą jakość wyszukiwania i zwracać bardzo trafne wyniki, multimodalna wyszukiwarka może połączyć tekst i obraz w jednym zapytaniu . W takim przypadku użytkownik dostarcza przykładowy obraz pożądanego produktu. Po uruchomieniu tego wyszukiwania jako wyszukiwania multimodalnego obrazem wejściowym jest sukienka w kwiaty, która jest pokazana na poniższym obrazie.

Obraz dostarczony przez użytkownika dla zapytania multimodalnego.
W tym scenariuszu pierwsza część zapytania pozostaje taka sama (suknia w kwiaty), a druga część dodaje aspekt wizualny do zapytania multimodalnego. Zwrócone wyniki dają sukienki, które są podobne do sukienki w kwiaty dostarczonej przez użytkownika. W tym przypadku dostępna jest dokładnie ta sama sukienka, a zatem jest pierwszym wynikiem zwracanym wraz z innymi podobnymi sukienkami.
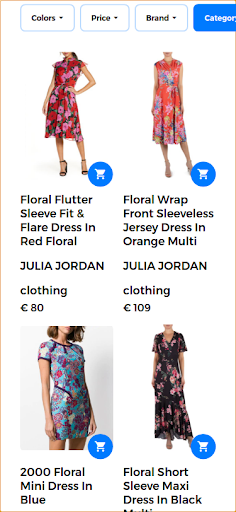
Odpowiednie wyniki wyszukiwania zwrócone w odpowiedzi na zapytanie multimodalne.
MILCZĄCY
Google wprowadził nową technologię, aby pomóc użytkownikom w złożonych zadaniach wyszukiwania. Ta nowa technologia, zwana MUM, oznacza zunifikowany model wielozadaniowy i jest w stanie przełamać bariery językowe i interpretować informacje w różnych formatach treści, takich jak strony internetowe i obrazy.
Google Lens to jeden z pierwszych produktów wykorzystujących zalety łączenia obrazów i tekstu w jedno zapytanie. W kontekście wyszukiwania MUM ułatwiłaby użytkownikom znajdowanie wzorów, takich jak określony wzór kwiatowy na obrazie dostarczonym przez użytkownika.
MUM to nowy kamień milowy AI w zrozumieniu informacji przedstawionych tutaj:
„Chociaż jesteśmy na początku odkrywania MUM, jest to ważny kamień milowy w kierunku przyszłości, w której Google będzie w stanie zrozumieć wszystkie różne sposoby, w jakie ludzie naturalnie komunikują się i interpretują informacje”.
Aby dowiedzieć się więcej o wyszukiwaniu multimodalnym Google MUM, zapoznaj się z tym artykułem internetowym: 
Rozszerzanie wyszukiwania w różnych językach
Chociaż obraz jest niezależny od języka, wyszukiwane hasła są specyficzne dla języka. Zadanie zaprojektowania systemu wielojęzycznego sprowadza się do budowania modeli językowych w szerokiej gamie języków.
Wyszukiwanie wielojęzyczne
Jednym z kluczowych ograniczeń obecnych systemów wyszukiwania jest to, że pobierają one dokumenty napisane lub opatrzone adnotacjami w języku, w którym użytkownik napisał zapytanie wyszukiwania. Ogólnie rzecz biorąc, te wyszukiwarki działają tylko w języku angielskim. Takie jednojęzyczne wyszukiwarki ograniczają użyteczność tych systemów w znajdowaniu przydatnych informacji napisanych w innym języku.
Z drugiej strony systemy wielojęzyczne akceptują zapytania w jednym języku i pobierają dokumenty, które są indeksowane w innych językach. W rzeczywistości system wyszukiwania jest wielojęzyczny, jeśli jest w stanie pobrać odpowiednie dokumenty z bazy danych, dopasowując treść dokumentu lub podpisy napisane w jednym języku z zapytaniem tekstowym w innym języku. Techniki dopasowywania obejmują zarówno mechanizmy syntaktyczne, jak i podejścia do wyszukiwania semantycznego.
Łączenie zdań w różnych językach z koncepcjami wizualnymi to pierwszy krok w promowaniu korzystania z wielojęzycznych modeli wizyjno-językowych . Dobrą wiadomością jest to, że koncepcje wizualne są interpretowane prawie w ten sam sposób przez wszystkich ludzi. Systemy te, zdolne do włączania informacji z więcej niż jednego źródła iw więcej niż jednym języku, nazywane są wielomodalnymi systemami wielojęzycznymi . Jednak parowanie obraz-tekst nie zawsze jest możliwe dla wszystkich języków na dużą skalę, jak omówiono w poniższej sekcji.
[Studium przypadku] Zwiększanie wzrostu na nowych rynkach dzięki SEO na stronie
 Przeczytaj studium przypadku
Przeczytaj studium przypadkuOd MAMA do MURAL
Wzrastają wysiłki na rzecz zastosowania zaawansowanych technik głębokiego uczenia i przetwarzania języka naturalnego w wyszukiwarkach. Google zaprezentowało nową pracę badawczą, która pozwala użytkownikom wyrażać słowa za pomocą obrazów. Na przykład słowo „valiha” odnosi się do instrumentu wykonanego z cytry rurowej, na którym grają Madagaskarowie. To słowo nie ma bezpośredniego tłumaczenia na większość języków, ale można je łatwo opisać za pomocą obrazów.
Nowy system, nazwany MURA, to skrót od Multimodal, Multi-task Retrieval Across Languages. Pozwala rozwiązać problem słów w jednym języku, które mogą nie mieć bezpośredniego tłumaczenia na język docelowy. W przypadku takich problemów wiele wstępnie wytrenowanych modeli wielojęzycznych nie znalazłoby semantycznie powiązanych słów ani nie przetłumaczyłoby słów na lub z języka o niewystarczających zasobach. W rzeczywistości MURAL może rozwiązać wiele rzeczywistych problemów:

- Słowa, które przekazują różne mentalne znaczenia w różnych językach: Jednym z przykładów jest słowo „ślub” w języku angielskim i hindi, które przekazuje różne mentalne obrazy, jak pokazano na poniższym obrazku z bloga Google.
- Niedobór danych dotyczących języków o niedostatecznych zasobach w sieci: 90% par tekst-obraz w sieci należy do dziesięciu najbogatszych w zasoby języków.

Obrazy pochodzą z wikipedii, przypisane do Psoni2402 (po lewej) i David McCandless (po prawej) z licencją CC BY-SA 4.0.
Zmniejszenie niejednoznaczności zapytań i zapewnienie rozwiązania problemu niedoboru par obraz-tekst w przypadku języków z niedostatecznymi zasobami to kolejne ulepszenie w kierunku następnej generacji wyszukiwarek opartych na sztucznej inteligencji.
Wyszukiwanie wielojęzyczne i multimodalne w akcji
W tej pracy wykorzystujemy istniejące narzędzia oraz dostępne modele językowe i wizyjne, aby zaprojektować multimodalny wielojęzyczny system, który wykracza poza jeden język i może obsługiwać więcej niż jedną modalność na raz .
Przede wszystkim, aby zaprojektować system wielojęzyczny, ważne jest semantyczne połączenie słów pochodzących z różnych języków. Po drugie, aby system był multimodalny, konieczne jest powiązanie reprezentacji języków z obrazami. W rezultacie jest to duży krok w kierunku długofalowego celu, jakim jest wielojęzyczne wyszukiwanie multimodalne.
Kontekst
Podstawowym przypadkiem użycia tego multimodalnego wielojęzycznego systemu jest zwrócenie odpowiednich obrazów ze zbioru danych po zapytaniu łączącym obraz i tekst w tym samym czasie. W tym duchu pokażemy kilka przykładów ilustrujących różne scenariusze multimodalne i wielojęzyczne.
Podstawą tej aplikacji demonstracyjnej jest Jina AI, ekosystem wyszukiwania neuronowego o otwartym kodzie źródłowym. Wyszukiwanie neuronowe, oparte na wyszukiwaniu informacji z głębokich sieci neuronowych (lub neuronowej IR), jest atrakcyjnym rozwiązaniem do budowy systemu multimodalnego. W tym demo używamy architektury MPNet Transformer z Hugging Face, wielojęzyczny-mpnet-base-v2, do przetwarzania opisów tekstowych i podpisów. Jeśli chodzi o część wizualną, korzystamy z MobileNetV2.
Poniżej przedstawiamy serię testów, aby pokazać moc wielojęzycznych i multimodalnych wyszukiwarek . Przed przedstawieniem wyników naszego narzędzia demonstracyjnego, oto lista kluczowych elementów opisujących te testy:
- Baza danych składa się z 1k obrazów przedstawiających ludzi grających muzykę. Te obrazy pochodzą z publicznego zbioru danych Flickr30K.
- Każdy obraz ma podpis napisany w języku angielskim.
Krok 1: Rozpoczęcie od zapytania tekstowego w języku angielskim
Najpierw zaczynamy od zapytania tekstowego, które odzwierciedla obecny sposób działania większości wyszukiwarek. Zapytanie brzmi „grupa muzyków”.
Zapytanie 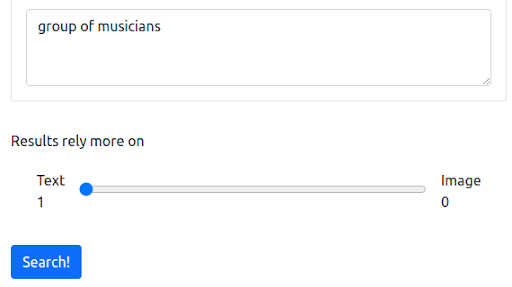
Wyniki 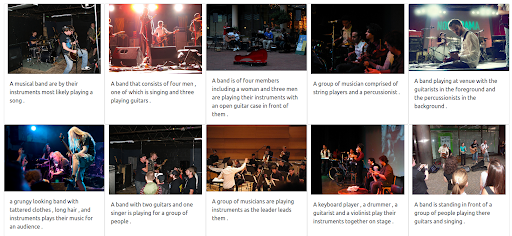
Nasza wyszukiwarka demonstracyjna oparta na Jinie zwraca obrazy muzyków, które są semantycznie powiązane z zapytaniem wejściowym. Jednak może to nie być typ muzyków, których chcemy.
Krok 2: Dodawanie multimodalności
Dodajmy teraz trochę multimodalności, wydając zapytanie, które łączy zarówno poprzednie zapytanie tekstowe, jak i obraz. Obraz przedstawia dokładniej muzyków, których szukamy.
Przede wszystkim interfejs użytkownika musi wspierać wydawanie tego typu zapytań. Następnie musimy przypisać wagę, aby zrównoważyć wagę każdej modalności podczas pobierania wyników. W takim przypadku zarówno tekst, jak i obraz mają równą wagę (0,5). Jak widać poniżej, nowe wyniki wyszukiwania zawierają wiele obrazów, które są wizualnie podobne do zapytania o obraz wejściowy.
Zapytanie 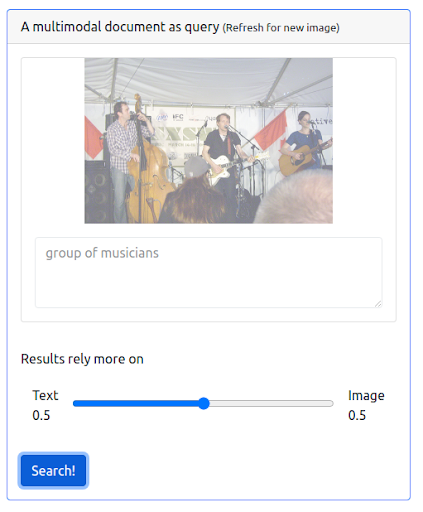
Wyniki 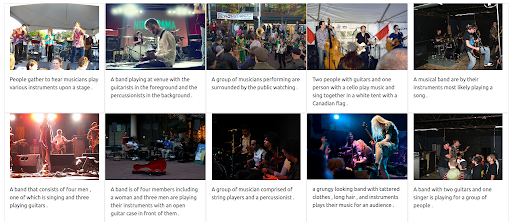
Krok 3: Przypisanie maksymalnej wagi do obrazu
Możliwe jest również nadanie obrazowi maksymalnej wagi. Spowoduje to wykluczenie tekstu wejściowego z zapytania. W takim przypadku więcej obrazów, które są wizualnie podobne do obrazu wejściowego, jest zwracanych i klasyfikowanych na pierwszych pozycjach. Należy pamiętać, że wyniki są ograniczone do obrazów dostępnych w zbiorze danych.
Zapytanie 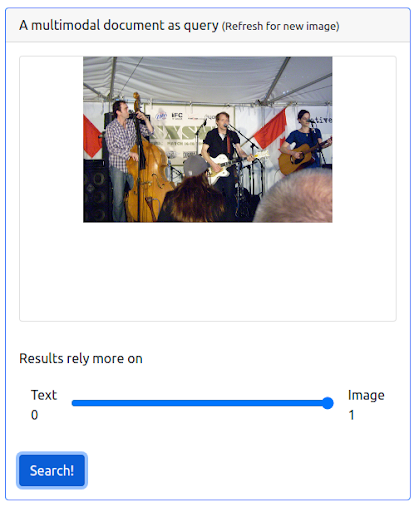
Wyniki 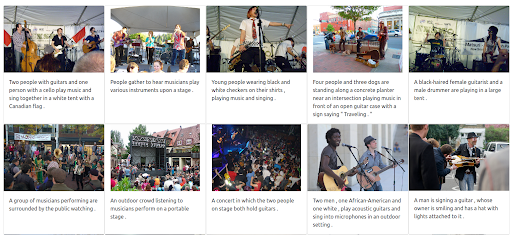
Krok 4: Testowanie wyszukiwania wielojęzycznego
Spróbujmy teraz zadać to samo zapytanie, ale używając różnych języków. Waga tekstu została zmaksymalizowana, aby zilustrować pełną moc tego wielojęzycznego systemu. Proszę pamiętać, że podpisy pod zdjęciami są tylko w języku angielskim. Wyszukiwanie jest powtarzane, aby objąć następujące języki:
- francuski: Groupe de musiciens
- włoski: Gruppo di musicisti
- niemiecki: Gruppe von Musikern
Niezależnie od języka zapytania wejściowego zwrócone wyniki są istotne i spójne we wszystkich trzech językach. Wyniki przedstawiono poniżej.
Wyniki zapytania w języku francuskim 
Wyniki zapytania w języku włoskim 
Wyniki zapytania w języku niemieckim 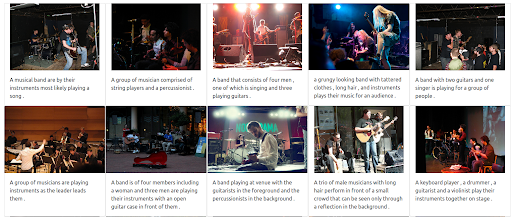
Multimodalna wielojęzyczna przyszłość wyszukiwania
W nadchodzących latach sztuczna inteligencja będzie coraz bardziej przekształcać wyszukiwanie i odblokowywać zupełnie nowe sposoby wyrażania zapytań i eksploracji informacji. Jak już ogłosił Google, zrozumienie informacji za pomocą MUM stanowi kamień milowy AI. Więcej systemów opartych na sztucznej inteligencji w przyszłości będzie zawierać funkcje i ulepszenia, od zapewniania lepszego doświadczenia wyszukiwania po odpowiadanie na wyrafinowane pytania i od przełamywania barier językowych po łączenie różnych trybów wyszukiwania w jednym zapytaniu.