
Szybki i brudny 11-etapowy audyt techniczny SEO dla ogólnej witryny Heath
Opublikowany: 2020-02-27Techniczne SEO ma znaczenie, ponieważ jest punktem wyjścia każdego projektu. Z punktu widzenia eksperta SEO, każda strona internetowa to nowy projekt. Strona internetowa powinna mieć solidne podstawy, aby osiągać dobre wyniki i osiągać najważniejsze KPI w SEO, takie jak rankingi.
Za każdym razem, gdy zaczynam nowy projekt, pierwszą rzeczą, którą robię, jest audyt techniczny SEO. W większości przypadków naprawa problemów technicznych może przynieść zdumiewające wyniki, gdy tylko witryna zostanie ponownie zindeksowana.
Zabawne jest dla mnie, gdy ludzie mówią o treści i większej ilości treści, ale nie mówią ani słowa o technicznym SEO. Jedno jest pewne, zdrowie witryny i techniczne SEO to dwie ważne rzeczy, które będą kluczowe w 2020 roku. Nie chcę przez to powiedzieć, że treść nie jest ważna. Tak jest, ale bez naprawienia problemów technicznych na stronie internetowej nie sądzę, aby treść mogła przynieść rezultaty.
Widziałem przypadki, w których ważne strony zostały zablokowane przez dyrektywy w pliku robots.txt lub najważniejsze strony kategorii lub usług są zepsute lub zablokowane przez metaroboty, takie jak noindex, nofollow. Jak można odnieść sukces bez ustalania priorytetów, naprawiając te problemy?
Zaskakująca może być liczba SEO, którzy nie wiedzą, jak zidentyfikować problemy techniczne, które należy zgłosić specjalistom ds. tworzenia stron internetowych w celu ich naprawienia. Przypomniało mi się kiedyś, że pracując w branży korporacyjnej, stworzyłem arkusz listy kontrolnej audytu Tech SEO do wykorzystania przez mój zespół. W tym czasie zdałem sobie sprawę, że posiadanie takiego arkusza szybkiej naprawy, jak ten, może ogromnie pomóc zespołowi i wygenerować szybki wzrost dla klienta. Dlatego uważam, że niezwykle ważne jest zainwestowanie w narzędzie/oprogramowanie, które może pomóc w technicznej diagnostyce SEO i zaleceniach.
Zacznijmy od praktycznego przeprowadzenia szybkiego audytu SEO, który zrobi dużą różnicę. Jest to szybkie ćwiczenie, które zajmie ci około godziny, nawet jeśli nie jesteś zawodowcem. Dla mnie używanie narzędzia Tech SEO, takiego jak OnCrawl, do szybkiego przewijania wszystkich rzeczy w ciągu pięciu minut bez konieczności wykonywania wszystkich prac ręcznych, ułatwia mi życie.
Omówię najważniejsze rzeczy do sprawdzenia podczas przeprowadzania Audytu Technicznego SEO. Jest więcej rzeczy, które możemy sprawdzić pod kątem problemów na stronie, ale chcę skupić się tylko na rzeczach, które spowodują problemy z indeksowaniem i przeszukiwaniem marnotrawstwa budżetu. Ustalenie priorytetów to sposób na upewnienie się, że najważniejsze strony będą indeksowane przez Googlebota.
- Indeksacja
- Plik robots.txt
- Znacznik meta robotów
- Błędy 4xx
- Mapy witryn
- HTTP/HTTPS (zabezpieczenie witryny, problemy z zawartością mieszaną i zduplikowaną zawartością)
- Paginacja
- Strona 404
- Głębokość i struktura witryny
- Długie łańcuchy przekierowań
- Implementacja tagu kanonicznego
1) Indeksowanie
To jest pierwsza rzecz do sprawdzenia. Wiele razy na indeksowanie może mieć wpływ konfiguracja wtyczki lub jakikolwiek drobny błąd, ale wpływ na wyszukiwalność może być ogromny, ponieważ obecnie zaindeksowanych jest ponad 6,16 miliardów stron internetowych. Musisz zrozumieć, że każda wyszukiwarka podejmuje wysiłek, a nawet Google musi nadać priorytet najbardziej odpowiedniej stronie pod kątem wygody użytkownika. Jeśli nie myślisz o ułatwieniu pracy Googlebotowi, Twoja konkurencja zrobi to i zyska znacznie większe zaufanie, które daje zdrowa witryna.
Gdy pojawią się problemy z indeksowaniem, problemy zdrowotne Twojej witryny przełożą się na utratę ruchu organicznego. Proces indeksowania oznacza, że wyszukiwarka przeszukuje stronę internetową i organizuje informacje, które później oferują ją w SERP. Wyniki zależą od trafności dla intencji użytkownika. Jeśli strona internetowa nie może lub ma problemy z indeksowaniem, będzie to faworyzować inne strony z tej samej niszy, aby mieć przewagę.
Używając operatorów wyszukiwania, na przykład:
Strona: www.abc.com
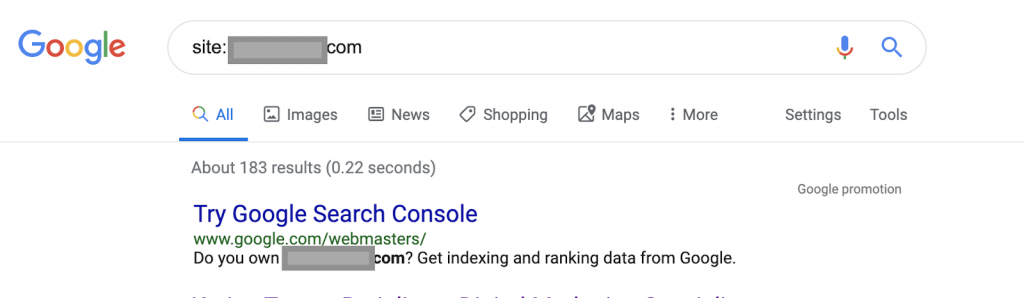
Zapytanie zwróci 183 strony zindeksowane przez Google. To jest przybliżone oszacowanie liczby stron zindeksowanych przez Google. Możesz sprawdzić w Google Search Console dokładny numer.
Powinieneś także użyć robota indeksującego, takiego jak OnCrawl, aby wyświetlić listę wszystkich stron, do których Google ma dostęp. Pokazuje inny numer, jak widać poniżej:
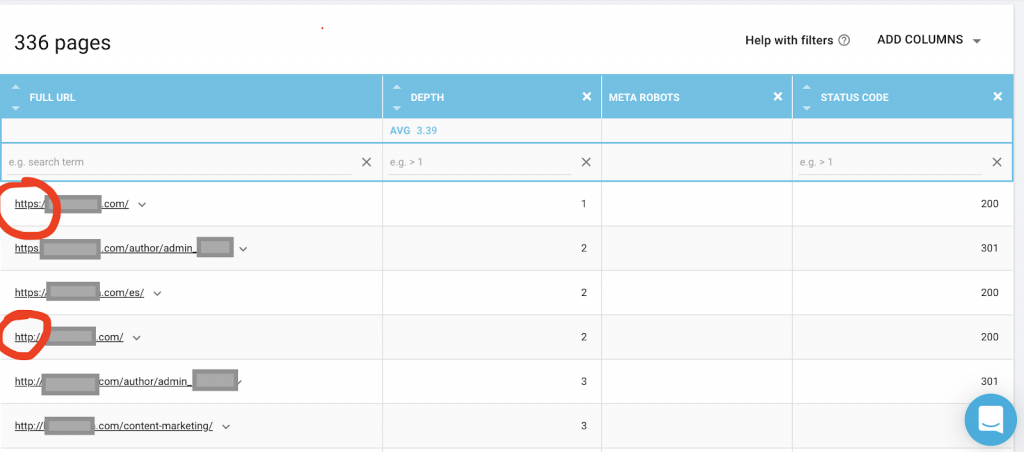
Ta witryna internetowa ma prawie dwa razy więcej stron, które można przeszukiwać, niż stron indeksowanych.
Może to ujawnić problem ze zduplikowaną zawartością lub nawet problem z wersją zabezpieczeń witryny między problemami HTTP i HTTPS. Porozmawiam o tym w dalszej części tego artykułu.
W tym przypadku strona została przeniesiona z HTTP na HTTPS. W OnCrawl widzimy, że strony HTTP zostały przekierowane. Zarówno wersje HTTP, jak i HTTPS są nadal dostępne dla Googlebota i może on indeksować wszystkie zduplikowane strony, zamiast nadawać priorytet najważniejszym stronom, które właściciel chce uszeregować, co powoduje marnowanie budżetu na indeksowanie.
Innym powszechnym problemem wśród zaniedbanych witryn lub dużych witryn, takich jak witryny e-commerce, są problemy z mieszaną zawartością. Krótko mówiąc, problemy pojawiają się, gdy zabezpieczona strona zawiera zasoby, takie jak pliki multimedialne (najczęściej: obrazy) załadowane z niezabezpieczonej wersji.
Jak to naprawić:
Możesz poprosić programistę internetowego, aby wymusił na wszystkich stronach HTTP wersję HTTPS i przekierował adresy HTTP do HTTPS, używając kodu stanu 301.
W przypadku problemów z mieszaną zawartością możesz ręcznie sprawdzić źródło strony i wyszukać zasoby załadowane jako „src=http://example.com/media/images”, co jest prawie szalone, zwłaszcza w przypadku dużych witryn. Dlatego musimy skorzystać z technicznego narzędzia SEO.
2) Plik Robots.txt:
Plik robots.txt informuje agentów indeksujących, których stron nie należy indeksować. Przewodnik po specyfikacjach robots.txt wskazuje, że format pliku musi być zwykłym tekstem o maksymalnym rozmiarze 500 KB.
Polecam dodać mapę witryny do pliku robots.txt. Nie wszyscy to robią, ale uważam, że to dobra praktyka. Plik robots.txt musi zostać umieszczony na serwerze hostowanym w public_html i umieszczony za domeną główną.
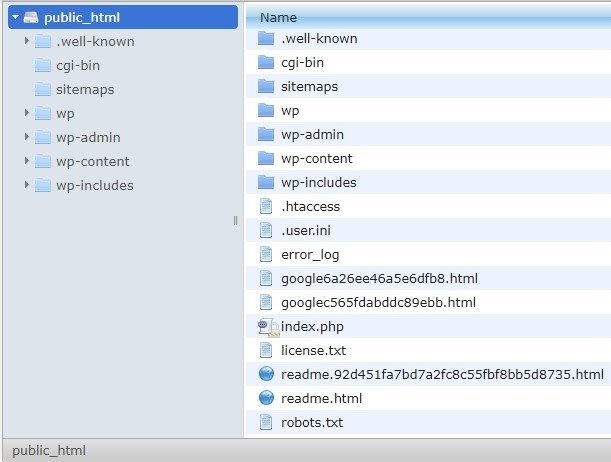
Możemy użyć dyrektyw w pliku robots.txt, aby uniemożliwić wyszukiwarkom indeksowanie niepotrzebnych stron lub stron zawierających poufne informacje, takie jak strona administracyjna, szablony lub koszyk (/cart, /checkout, /login, foldery takie jak /tag używane w blogach) , dodając te strony do pliku robots.txt.
Porada : Upewnij się, że nie zablokujesz folderu z plikami multimedialnymi, ponieważ spowoduje to wykluczenie z indeksowania obrazów, filmów lub innych nośników na własnym serwerze. Media mogą być bardzo ważne dla trafności strony, a także dla organicznego rankingu i ruchu dla obrazów lub filmów.
3) Znacznik Meta Robots
Jest to fragment kodu HTML, który instruuje wyszukiwarki, czy mają przeszukiwać i indeksować stronę ze wszystkimi linkami na tej stronie. Tag HTML trafia do nagłówka Twojej strony internetowej. Istnieją 4 popularne znaczniki HTML dla robotów:
- Nie obserwuj
- Podążać
- Indeks
- Brak indeksu
Gdy nie ma żadnych metatagów robotów, wyszukiwarki domyślnie będą śledzić i indeksować treść.
Możesz użyć dowolnej kombinacji, która najlepiej odpowiada Twoim potrzebom. Na przykład, korzystając z OnCrawl, odkryłem, że „strona autora” z tej witryny nie ma meta robotów. Oznacza to, że domyślnie kierunek to („follow, index”)
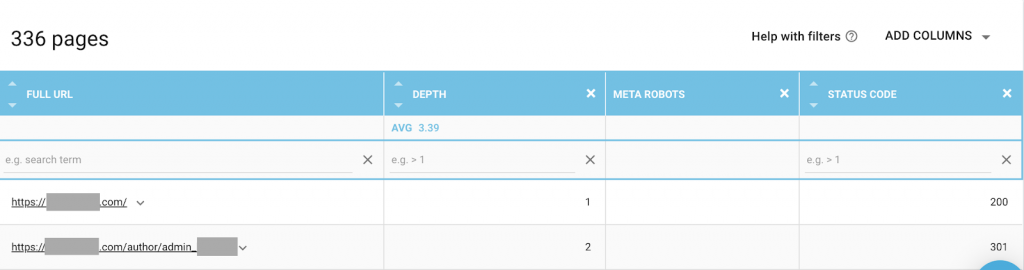
Powinno to być („noindex, nofollow”).
Czemu?
Każdy przypadek jest inny, ale ta strona jest małym osobistym blogiem. Na blogu publikuje tylko jeden autor, a domeną jest imię i nazwisko autora. W takim przypadku strona „autor” nie dostarcza żadnych dodatkowych informacji, mimo że jest generowana przez platformę blogową.
Innym scenariuszem może być strona internetowa, w której ważne są kategorie na blogu. Gdy właściciel chce uszeregować według kategorii na swoim blogu, metaroboty powinny być („obserwuj, indeksuj”) lub domyślnie na stronach kategorii.
W innym scenariuszu, w przypadku dużej i znanej witryny, w której najważniejsi eksperci SEO piszą artykuły śledzone przez społeczność, nazwisko autora w Google działa jako marka. W takim przypadku prawdopodobnie zechcesz zindeksować nazwiska niektórych autorów.
Jak widać, meta robotów można używać na wiele różnych sposobów.
Jak to naprawić:
Poproś programistę o zmianę metatagu robota zgodnie z potrzebami. W powyższym przypadku dla małej strony internetowej mogę to zrobić samodzielnie przechodząc do każdej strony i zmieniając ją ręcznie. Jeśli korzystasz z WordPressa, możesz to zmienić w ustawieniach RankMath lub Yoast.
4) Błędy 4xx:
Są to błędy po stronie klienta i mogą to być 401, 403 i 404.
- Nie znaleziono strony 404:
Ten błąd występuje, gdy strona nie jest dostępna pod zindeksowanym adresem URL. Mogło zostać przeniesione lub usunięte, a stary adres nie został poprawnie przekierowany za pomocą funkcji serwera WWW 301. Błędy 404 są złym doświadczeniem dla użytkowników i stanowią techniczny problem SEO, który należy rozwiązać. Dobrze jest często sprawdzać błędy 404 i je naprawiać, nie zostawiając ich na ciągłe sprawdzanie przez agentów indeksujących, którzy marnują swój budżet.
Jak to naprawić:
Musimy znaleźć adresy, które zwracają 404 i naprawić je za pomocą przekierowań 301, jeśli treść nadal istnieje. Lub, jeśli są to obrazy, można je zastąpić nowymi, zachowując tę samą nazwę pliku.
- 401 Nieautoryzowany
To jest kwestia uprawnień. Błąd 401 zwykle występuje, gdy wymagane jest uwierzytelnienie, takie jak nazwa użytkownika i hasło.
Jak to naprawić:
Oto dwie opcje: Pierwsza to zablokowanie strony przed wyszukiwarkami przy użyciu pliku robots.txt. Druga opcja to usunięcie wymogu uwierzytelniania.
- 403 Zabronione
Ten błąd jest podobny do błędu 401. Błąd 403 występuje, ponieważ strona zawiera linki, które nie są publicznie dostępne.

Jak to naprawić:
Zmień wymaganie na serwerze, aby zezwolić na dostęp do strony (tylko jeśli to pomyłka). Jeśli chcesz, aby ta strona była niedostępna, usuń wszystkie wewnętrzne i zewnętrzne linki ze strony.
- 400 złych żądań
Dzieje się tak, gdy przeglądarka nie może komunikować się z serwerem WWW. Ten błąd często występuje w przypadku nieprawidłowej składni adresu URL.
Jak to naprawić:
Znajdź łącza do tych adresów URL i popraw składnię. Jeśli nie da się tego naprawić, musisz skontaktować się z programistą internetowym, aby to naprawić.
Uwaga: 400 błędów możemy znaleźć w narzędziach lub w Konsoli Google

5) Mapy witryn
Mapa witryny to lista wszystkich adresów URL zawartych w witrynie. Mapy witryn poprawiają wyszukiwalność, ponieważ pomagają robotom indeksującym znaleźć i zrozumieć Twoje treści.
Mamy różne rodzaje map witryn i musimy upewnić się, że wszystkie są w dobrym stanie.
Mapy witryn, które powinniśmy mieć, to:
- Mapa witryny HTML: będzie ona znajdować się w Twojej witrynie i pomoże użytkownikom nawigować i znajdować strony w Twojej witrynie
- Mapa witryny XML: jest to plik, który pomoże wyszukiwarkom w indeksowaniu Twojej witryny (najlepiej należy go umieścić w pliku robots.txt).
- Mapa witryny XML wideo: taka sama jak powyżej.
- Grafika Mapa witryny XML: jest taka sama jak powyżej. Zaleca się tworzenie osobnych map witryn dla obrazów, filmów i treści.
W przypadku dużych witryn zaleca się posiadanie kilku map witryn w celu lepszego indeksowania, ponieważ mapy witryn nie powinny zawierać więcej niż 50 000 adresów URL.
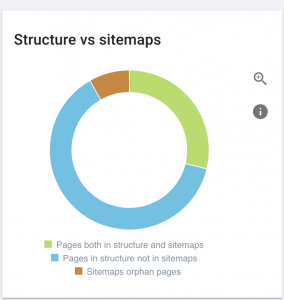
Ta witryna ma problemy z mapą witryny.
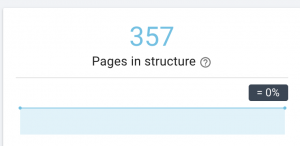
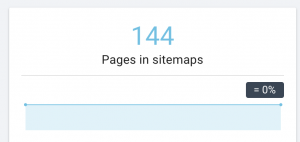
Jak to naprawiamy:
Rozwiązujemy ten problem, generując różne mapy witryn dla: treści, obrazów i filmów. Następnie przesyłamy je za pomocą Google Search Console, a także tworzymy mapę witryny HTML dla witryny. Nie potrzebujemy do tego programisty WWW. Do generowania map witryn możemy użyć dowolnego bezpłatnego narzędzia online.
6) HTTP/HTTPS (zduplikowana treść)
Wiele witryn ma te problemy w wyniku migracji z HTTP na HTTPS. W takim przypadku witryna będzie wyświetlać w wyszukiwarkach wersje HTTP i HTTPS. W konsekwencji tego powszechnego problemu technicznego, rankingi są rozmyte. Te problemy powodują również zduplikowane problemy z treścią.
![]()

Jak to naprawić:
Poproś programistę, aby naprawił ten problem, wymuszając cały HTTP na HTTPS.
Uwaga : nigdy nie przekierowuj całego HTTP do strony głównej HTTPS, ponieważ spowoduje to wygenerowanie miękkiego błędu 404. (Powinieneś powiedzieć to programistom internetowym; pamiętaj, że nie są to SEO).
7) Paginacja
Jest to użycie znacznika HTML („rel = prev” i „rel = next”), który ustala relacje między stronami i pokazuje wyszukiwarkom, że treść prezentowana na różnych stronach powinna być zidentyfikowana lub powiązana z jedną. Paginacja służy do ograniczania treści dla UX i wagi strony dla części technicznej, utrzymując je poniżej 3 MB. Do sprawdzenia paginacji możemy użyć darmowego narzędzia.
Paginacja powinna mieć własne odniesienia kanoniczne i wskazywać „rel = prev” i „rel = next”. Jedyną zduplikowaną informacją będzie tytuł meta i opis meta, ale programiści mogą to zmienić, tworząc mały algorytm, dzięki któremu każda strona będzie miała wygenerowany tytuł meta i opis meta.
Jak to naprawić:
Poproś programistę o zaimplementowanie tagów HTML z podziałem na strony z tagiem samokanonicznym.
Robot SEO Oncrawl
 Decouvri
Decouvri8) Niestandardowa strona 404 Nie znaleziono
Odpowiedź 404 jest, jak omówiliśmy wcześniej, błędem „ Nie znaleziono ”, który prowadzi użytkowników do uszkodzonego łącza lub nieistniejącej strony. To okazja do przekierowania użytkowników we właściwe miejsce. Istnieją świetne przykłady niestandardowych stron 404. To pozycja obowiązkowa.
Oto przykład świetnej niestandardowej strony 404:

Jak to naprawić:
Stwórz niestandardową stronę 404: wymyśl coś niesamowitego do dodania. Niech ten błąd stanie się szansą dla swojej firmy.
9) Głębokość/struktura strony
Głębokość strony to liczba kliknięć, dzięki którym Twoja strona znajduje się w domenie głównej. John Mueller z Google powiedział, że „strony bliżej strony głównej mają większą wagę”. Na przykład wyobraźmy sobie, że strona tutaj wymaga następującej nawigacji, aby się do niej dostać:

Strona „dywany” znajduje się 4 kliknięcia od strony głównej. Zaleca się, aby strony nie znajdowały się dalej niż 4 kliknięcia od domu, ponieważ wyszukiwarki mają trudności z indeksowaniem głębszych stron.
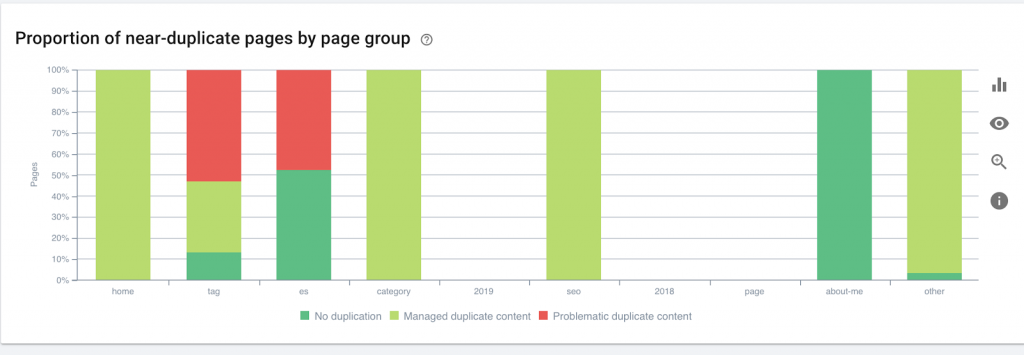
Ta grafika przedstawia grupę stron według głębokości. Pomaga nam zrozumieć, czy struktura witryny wymaga przeróbki.
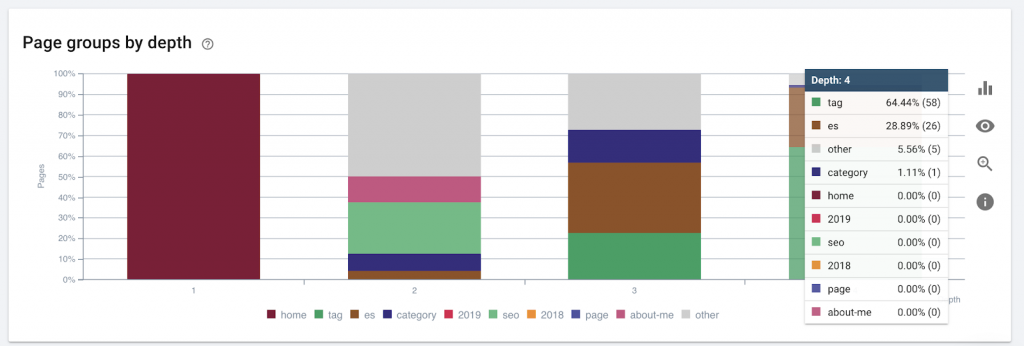
Jak to naprawić:
Najważniejsze strony powinny znajdować się najbliżej strony głównej dla UX, aby użytkownicy mieli łatwy dostęp i lepszą strukturę witryny. Bardzo ważne jest, aby wziąć to pod uwagę przy tworzeniu struktury serwisu lub przebudowie serwisu.
10. Łańcuchy przekierowań
Łańcuch przekierowań to seria przekierowań między adresami URL. Te łańcuchy przekierowań mogą również tworzyć pętle. Stwarza to również problemy dla Googlebota i marnuje budżet indeksowania.
Łańcuchy przekierowań możemy zidentyfikować za pomocą ścieżki przekierowania rozszerzenia Chrome lub w OnCrawl.
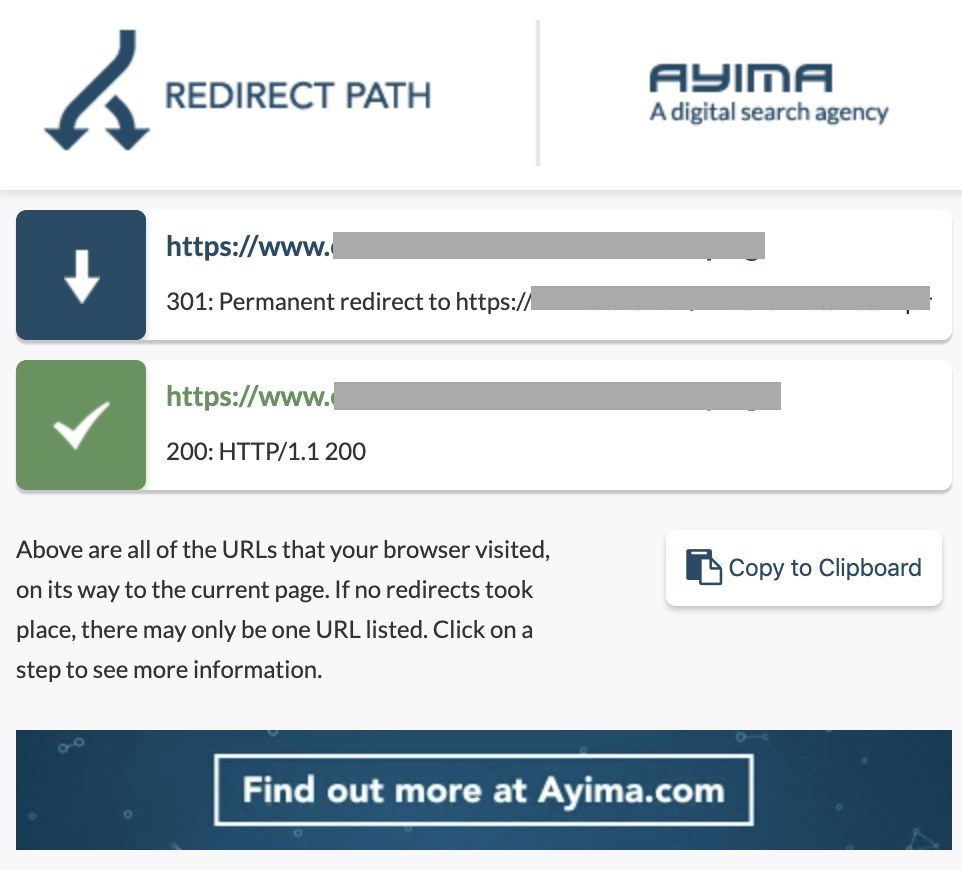
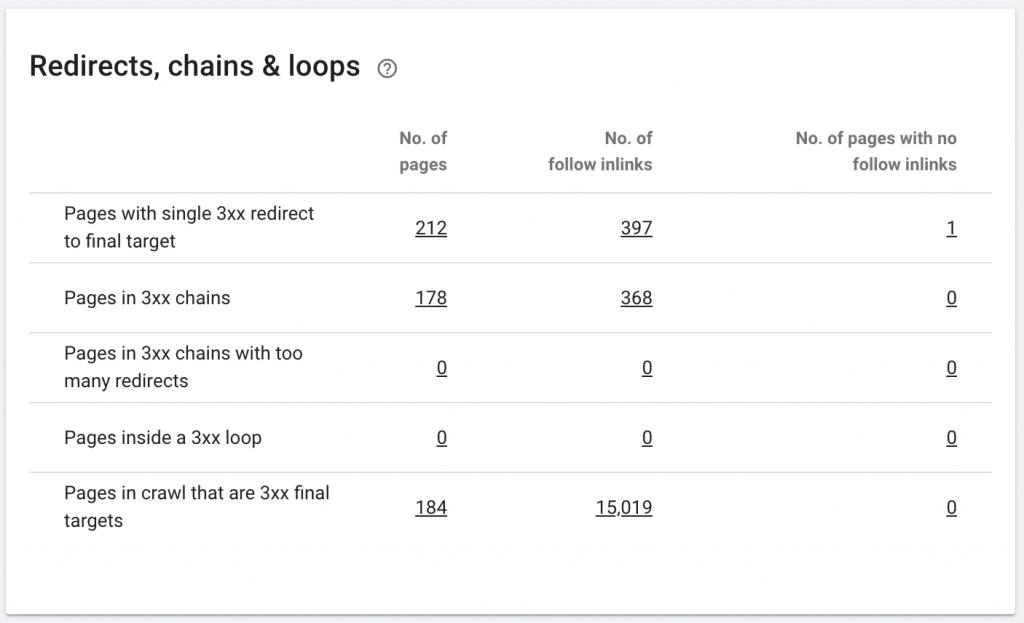
Jak to naprawić:
Naprawienie tego jest naprawdę łatwe, jeśli pracujesz z witryną WordPress. Po prostu przejdź do przekierowania i poszukaj łańcucha - usuń wszystkie linki biorące udział w łańcuchu, jeśli te zmiany nastąpiły ponad 2-3 miesiące temu, i po prostu pozostaw ostatnie przekierowanie pod bieżący adres URL. Programiści stron internetowych mogą również w tym pomóc, wprowadzając wszystkie wymagane zmiany w pliku .htacces, jeśli zajdzie taka potrzeba. Możesz sprawdzić i zmienić długie łańcuchy przekierowań w swoich wtyczkach SEO.
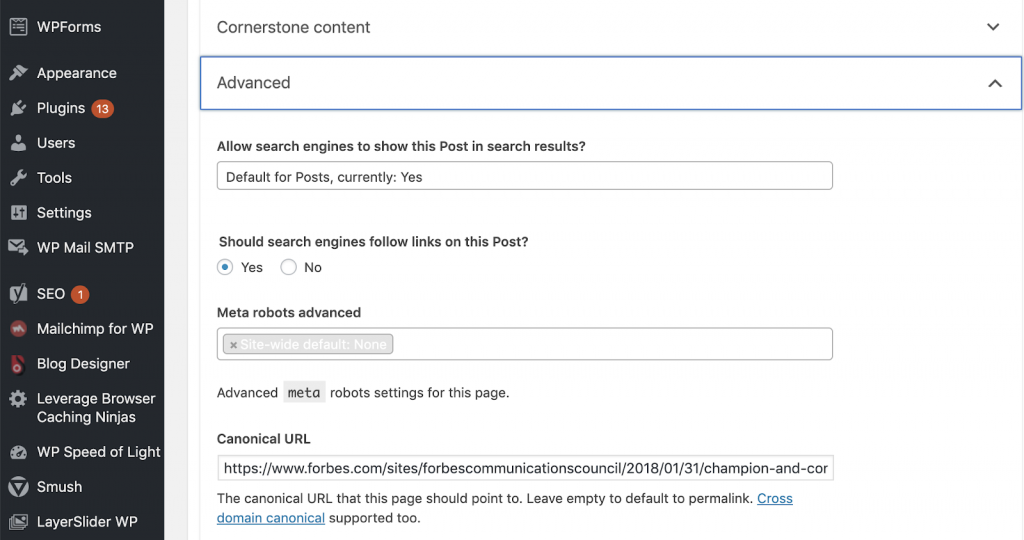
11) Kanoniści
Znacznik kanoniczny informuje wyszukiwarki, że adres URL jest kopią innej strony. To duży problem, który pojawia się na wielu stronach internetowych. Niewłaściwe zaimplementowanie kanonicznych lub ich wdrożenie w ogóle spowoduje zduplikowane problemy z treścią.
Kanoniczne są powszechnie używane w witrynach e-commerce, w których produkt można znaleźć wielokrotnie w różnych kategoriach, takich jak: rozmiar, kolor itp.

Możesz użyć OnCrawl, aby stwierdzić, czy Twoje strony mają tagi kanoniczne i czy są one poprawnie zaimplementowane. Następnie możesz zbadać i naprawić wszelkie problemy.
Jak to naprawiamy:
Jeśli pracujemy na WordPressie, możemy rozwiązać problemy kanoniczne za pomocą Yoast SEO. Przechodzimy do pulpitu WordPress, a następnie do Yoast -setting – advanced.
Przeprowadzenie własnego audytu
SEO, którzy chcą zacząć zajmować się technicznym SEO, potrzebują przewodnika z krótkimi krokami, które należy wykonać, aby poprawić kondycję SEO. Rozmowa o technicznym SEO z Johnem Shehatą, wiceprezesem ds. wzrostu widowni w Conde Nast i założycielem NewzDash podczas Global Marketing Day w Nowym Jorku w październiku 2019 r.
Oto, co mi powiedział:
„Wiele osób w branży SEO nie jest technicznych. Teraz nie każdy SEO rozumie, jak kodować i trudno jest poprosić ludzi, aby to zrobili. Niektóre firmy zatrudniają programistów i szkolą ich, aby zostali SEO, aby wypełnić lukę techniczną w SEO.”
Moim zdaniem SEO, który nie ma pełnej wiedzy o kodzie, nadal może świetnie sobie radzić w Tech SEO, wiedząc, jak przeprowadzić audyt, identyfikować kluczowe elementy, raportować, prosić programistów o wdrożenie i wreszcie testować zmiany.
Gotowy żeby zacząć? Pobierz listę kontrolną dotyczącą tych najważniejszych problemów.
