
Ocena jakości prognoz dotyczących wpływu przyczynowego
Opublikowany: 2022-02-15CausalImpact to jeden z najpopularniejszych pakietów wykorzystywanych w eksperymentach SEO. Jego popularność jest zrozumiała.
Eksperymenty z SEO dostarczają ekscytujących spostrzeżeń i sposobów dla SEO na raportowanie wartości ich pracy.
Jednak dokładność dowolnego modelu uczenia maszynowego zależy od podanych informacji wejściowych.
Mówiąc najprościej, błędne dane wejściowe mogą zwrócić błędne oszacowanie.
W tym poście pokażemy, jak niezawodny (i niewiarygodny) może być CausalImpact. Dowiemy się również, jak nabrać pewności w wynikach eksperymentów.
Najpierw przedstawimy krótki przegląd działania CausalImpact. Następnie omówimy wiarygodność oszacowań CausalImpact. Na koniec poznamy metodologię, którą można wykorzystać do oszacowania własnych wyników eksperymentów SEO.
Co to jest wpływ przyczynowy i jak to działa?
CausalImpact to pakiet, który wykorzystuje statystyki Bayesa do oszacowania wpływu zdarzenia w przypadku braku eksperymentu. To oszacowanie nazywa się wnioskowaniem przyczynowym.
Wnioskowanie przyczynowe szacuje, czy zaobserwowana zmiana została spowodowana przez określone zdarzenie.
Jest często używany do oceny wydajności eksperymentów SEO.
Na przykład, po podaniu daty zdarzenia, CausalImpact (CI) użyje punktów danych przed interwencją do przewidzenia punktów danych po interwencji. Następnie porówna prognozę z zaobserwowanymi danymi i oszacuje różnicę z określonym progiem ufności.
Co więcej, grupy kontrolne mogą być wykorzystane do dokładniejszego przewidywania.
Różne parametry będą również miały wpływ na dokładność prognozy:
- Rozmiar danych testowych.
- Długość okresu przed eksperymentem.
- Wybór grupy kontrolnej do porównania.
- Hiperparametry sezonowości.
- Liczba iteracji.
Wszystkie te parametry pomagają nadać modelowi więcej kontekstu i zwiększyć jego niezawodność.
Oncrawl BI
 Odkryć
OdkryćDlaczego ocena dokładności eksperymentów SEO jest ważna?
W ostatnich latach przeanalizowałem wiele eksperymentów SEO i coś mnie uderzyło.
Wielokrotnie stosowanie różnych grup kontrolnych i ram czasowych na identycznych zestawach testowych i terminach interwencji dawało różne wyniki.
Dla ilustracji poniżej znajdują się dwa wyniki z tego samego zdarzenia.
Pierwsza zwróciła statystycznie istotny spadek. 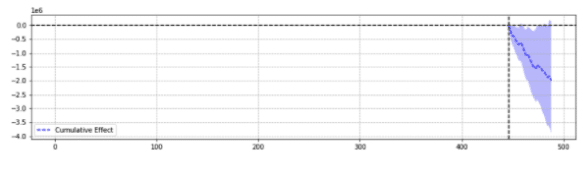
Druga nie była istotna statystycznie. 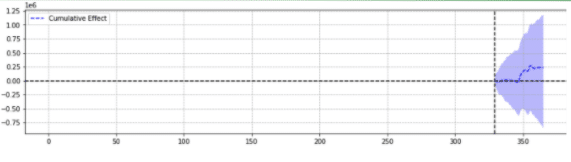
Mówiąc najprościej, dla tego samego zdarzenia zwracano różne wyniki na podstawie wybranych parametrów.
Trzeba się zastanowić, która prognoza jest trafna.
W końcu, czy „istotne statystycznie” nie ma zwiększać pewności naszych szacunków?
Definicje
Aby lepiej zrozumieć świat eksperymentów SEO, czytelnik powinien znać podstawowe pojęcia związane z eksperymentami SEO:
- Eksperyment : procedura podjęta w celu sprawdzenia hipotezy. W przypadku wnioskowania przyczynowego ma określoną datę rozpoczęcia.
- Grupa testowa : podzbiór danych, do którego stosuje się zmianę. Może to być cała witryna lub jej część.
- Grupa kontrolna : podzbiór danych, do którego nie zastosowano żadnych zmian. Możesz mieć jedną lub wiele grup kontrolnych. Może to być osobna witryna w tej samej branży lub inna część tej samej witryny.
Poniższy przykład pomoże zilustrować te pojęcia:
Modyfikacja tytułu (eksperyment) powinna zwiększyć organiczny CTR o 1% (hipoteza) stron produktów w pięciu miastach (grupa testowa). Szacunki zostaną poprawione przy niezmienionym tytule dla wszystkich pozostałych miast (grupa kontrolna).
Filary dokładnego przewidywania eksperymentów SEO
- Dla uproszczenia zestawiłem kilka interesujących spostrzeżeń dla specjalistów SEO, którzy uczą się, jak poprawić dokładność eksperymentów:
- Niektóre dane wejściowe w CausalImpact zwrócą błędne oszacowania, nawet jeśli są statystycznie istotne. To właśnie nazywamy „fałszywymi pozytywami” i „fałszywymi negatywami”.
- Nie ma ogólnej zasady regulującej, którą kontrolę należy zastosować w stosunku do zestawu testowego. Wymagany jest eksperyment, aby zdefiniować najlepsze dane kontrolne do wykorzystania dla określonego zestawu testowego.
- Korzystanie z CausalImpact z odpowiednią kontrolą i odpowiednią długością danych sprzed okresu może być bardzo precyzyjne, przy średnim błędzie wynoszącym zaledwie 0,1%.
- Alternatywnie, użycie CausalImpact z niewłaściwą kontrolą może prowadzić do wysokiego wskaźnika błędów. Eksperymenty osobiste wykazały statystycznie istotne różnice do 20%, podczas gdy w rzeczywistości nie było żadnej zmiany.
- Nie wszystko da się przetestować. Niektóre grupy testowe prawie nigdy nie zwracają dokładnych szacunków.
- Eksperymenty z grupami kontrolnymi lub bez nich wymagają różnych długości danych przed interwencją.
Nie wszystkie grupy testowe zwrócą dokładne oszacowania
Niektóre grupy testowe zawsze zwracają niedokładne prognozy. Nie powinny być używane do eksperymentów.
Grupy testowe z dużymi nietypowymi wahaniami ruchu często zwracają niewiarygodne wyniki.
Na przykład w tym samym roku witryna przeszła migrację witryny, została dotknięta pandemią COV, a część witryny została „nieindeksowana” przez 2 tygodnie z powodu błędu technicznego. Przeprowadzanie eksperymentów w tej witrynie zapewni niewiarygodne wyniki.
Powyższe wnioski zostały zebrane poprzez obszerną serię testów przeprowadzonych przy użyciu metodologii opisanej poniżej.
Kiedy nie używasz grup kontrolnych
- Użycie kontrolki zamiast prostego pre-post może zwiększyć nawet 18-krotnie precyzję oszacowania.
- Wykorzystanie danych sprzed 16 miesięcy było tak samo dokładne, jak wykorzystanie danych z 3 lat.
Podczas korzystania z grup kontrolnych
- Korzystanie z odpowiedniej kontroli jest często lepsze niż używanie wielu kontrolek. Jednak pojedyncza kontrola zwiększa ryzyko błędnego przewidywania w przypadkach, gdy ruch w ramach kontroli jest bardzo zróżnicowany.
- Wybór właściwej kontroli może zwiększyć precyzję 10-krotnie (np. jeden raportuje +3,1%, a drugi +4,1%, podczas gdy w rzeczywistości było to +3%).
- Większość skorelowanych wzorców ruchu między danymi testowymi a danymi kontrolnymi niekoniecznie oznacza lepsze oszacowania.
- Wykorzystanie danych sprzed 16 miesięcy NIE było tak dokładne, jak wykorzystanie danych z 3 lat.
Uważaj na długość danych przed eksperymentami
Co ciekawe, podczas eksperymentowania z grupami kontrolnymi, wykorzystanie danych sprzed 16 miesięcy może spowodować bardzo wysoki poziom błędów.
W rzeczywistości błędy mogą być tak duże, jak szacowanie trzykrotnego wzrostu ruchu, gdy nie było rzeczywistych zmian.
Jednak wykorzystanie danych z 3 lat pozwoliło usunąć ten wskaźnik błędu. Jest to sprzeczne z prostymi eksperymentami pre-post, w których wskaźnik błędu nie został zwiększony poprzez wydłużenie czasu trwania z 16 do 36 miesięcy.
To nie znaczy, że używanie kontroli jest złe. Wręcz przeciwnie.
Pokazuje po prostu, jak dodanie kontroli wpływa na prognozy.

Dzieje się tak w przypadku dużych różnic w grupie kontrolnej.
Ten wniosek jest szczególnie ważny w przypadku witryn, które miały nietypowe wahania ruchu w ciągu ostatniego roku (krytyczny błąd techniczny, pandemia COVID itp.).
Jak ocenić prognozę wpływu przyczynowego?
Obecnie w bibliotece CausalImpact nie ma wbudowanego wyniku dokładności. Tak więc należy wywnioskować inaczej.
Można przyjrzeć się, jak inne modele uczenia maszynowego szacują dokładność swoich prognoz i zdać sobie sprawę, że suma błędów kwadratów (SSE) jest bardzo powszechną miarą.
Suma kwadratów błędów lub resztowa suma kwadratów oblicza sumę wszystkich (n) różnic między oczekiwaniami (yi) a rzeczywistymi wynikami (f(xi)), do kwadratu. 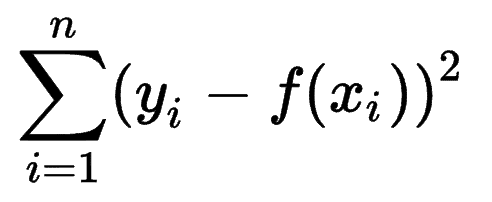
Im niższy SSE, tym lepszy wynik.
Wyzwanie polega na tym, że w przypadku eksperymentów pre-post dotyczących ruchu SEO nie ma rzeczywistych wyników.
Chociaż żadne zmiany nie zostały wprowadzone na miejscu, niektóre zmiany mogły nastąpić poza Twoją kontrolą (np. aktualizacja algorytmu Google, nowy konkurent itp.). Ruch SEO również nie różni się o stałą wartość, ale zmienia się stopniowo w górę iw dół.
Specjaliści SEO mogą się zastanawiać, jak sprostać temu wyzwaniu.
Przedstawiamy fałszywe odmiany
Aby mieć pewność co do wielkości zmienności spowodowanej zdarzeniem, eksperymentator może wprowadzić stałe wariacje w różnych momentach i sprawdzić, czy CausalImpact pomyślnie oszacował zmianę.
Co więcej, ekspert SEO może powtórzyć proces dla różnych grup testowych i kontrolnych.
Używając Pythona, wprowadzono stałe wariacje danych w różnych terminach interwencji w okresie po.
Następnie oszacowano sumę kwadratów błędów między zmiennością zgłoszoną przez CausalImpact a wprowadzoną zmiennością.
Pomysł wygląda tak:
- Wybierz dane testowe i kontrolne.
- Wprowadź fałszywe interwencje w rzeczywiste dane w różnych terminach (np. wzrost o 5%).
- Porównaj oszacowania CausalImpact z każdą z wprowadzonych odmian.
- Oblicz sumę kwadratów błędów (SSE).
- Powtórz krok 1 z wieloma kontrolkami.
- Wybierz kontrolę z najmniejszym SSE do eksperymentów w świecie rzeczywistym
Metodologia
Za pomocą poniższej metodologii stworzyłem tabelę, której mogłem użyć do zidentyfikowania, która kontrola miała najlepszy i najgorszy wskaźnik błędów w różnych momentach.
Najpierw wybierz dane testowe i kontrolne i wprowadź odchylenia od -50% do 50%.
Następnie uruchom CausalImpact (CI) i odejmij odmiany zgłoszone przez CI od faktycznie wprowadzonej odmiany.
Następnie oblicz kwadraty tych różnic i zsumuj wszystkie wartości.
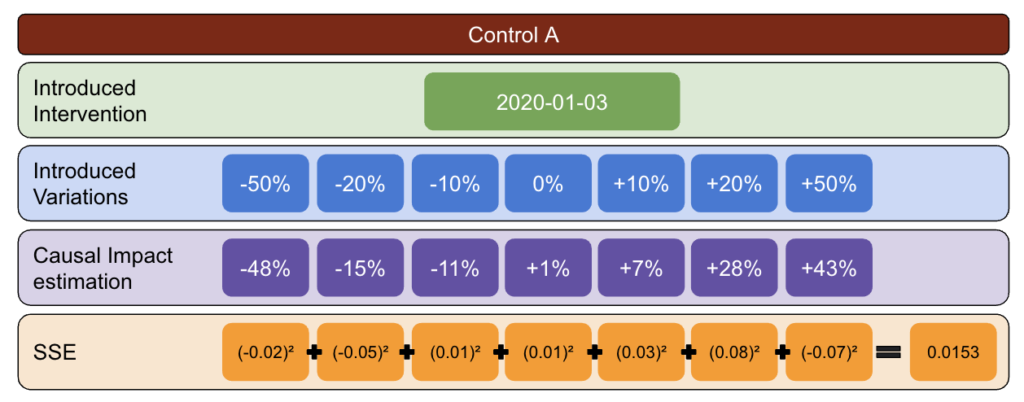
Następnie powtórz ten sam proces w różnych terminach, aby zmniejszyć ryzyko błędu spowodowanego rzeczywistą zmianą w określonym dniu.
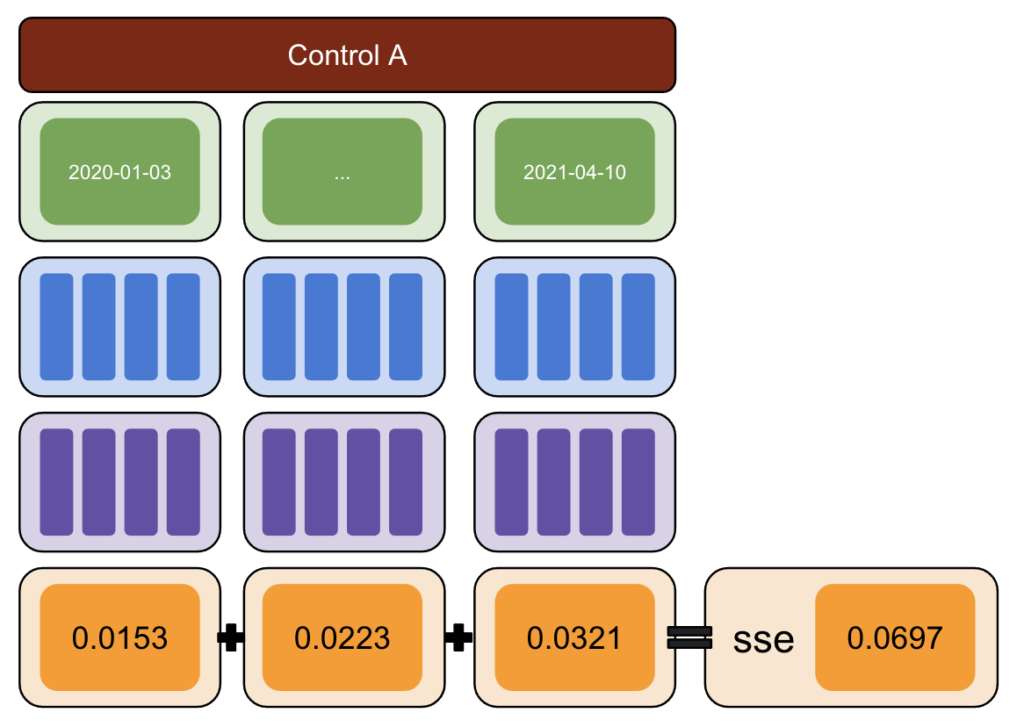
Ponownie powtórz z wieloma grupami kontrolnymi.
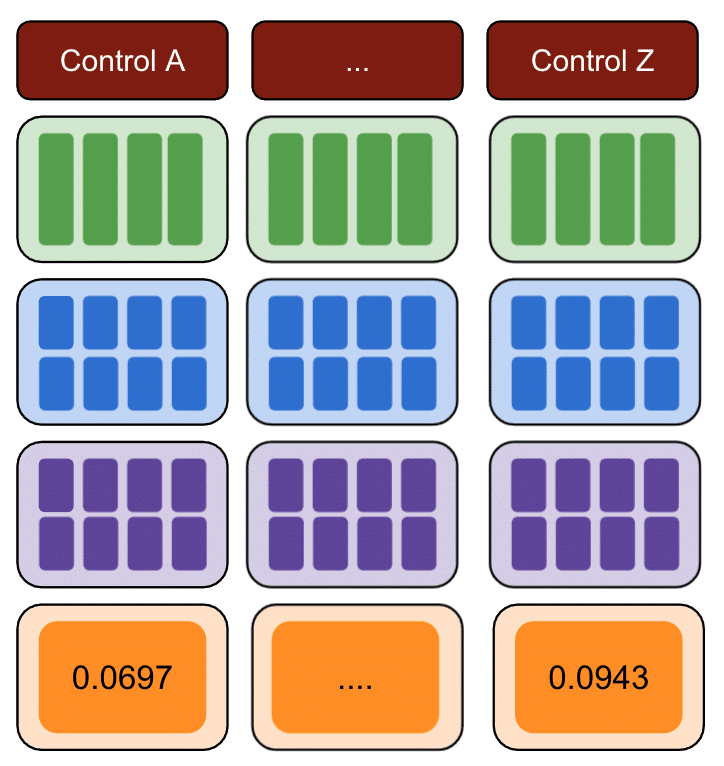
Wreszcie, grupa kontrolna z najmniejszą sumą błędów kwadratów jest najlepszą grupą kontrolną do wykorzystania w danych testowych.
Jeśli powtórzysz każdy z kroków dla każdego z danych testowych, wynik będzie się różnić.
W wynikowej tabeli każdy wiersz reprezentuje grupę kontrolną, każda kolumna reprezentuje grupę testową. Dane w środku to SSE.
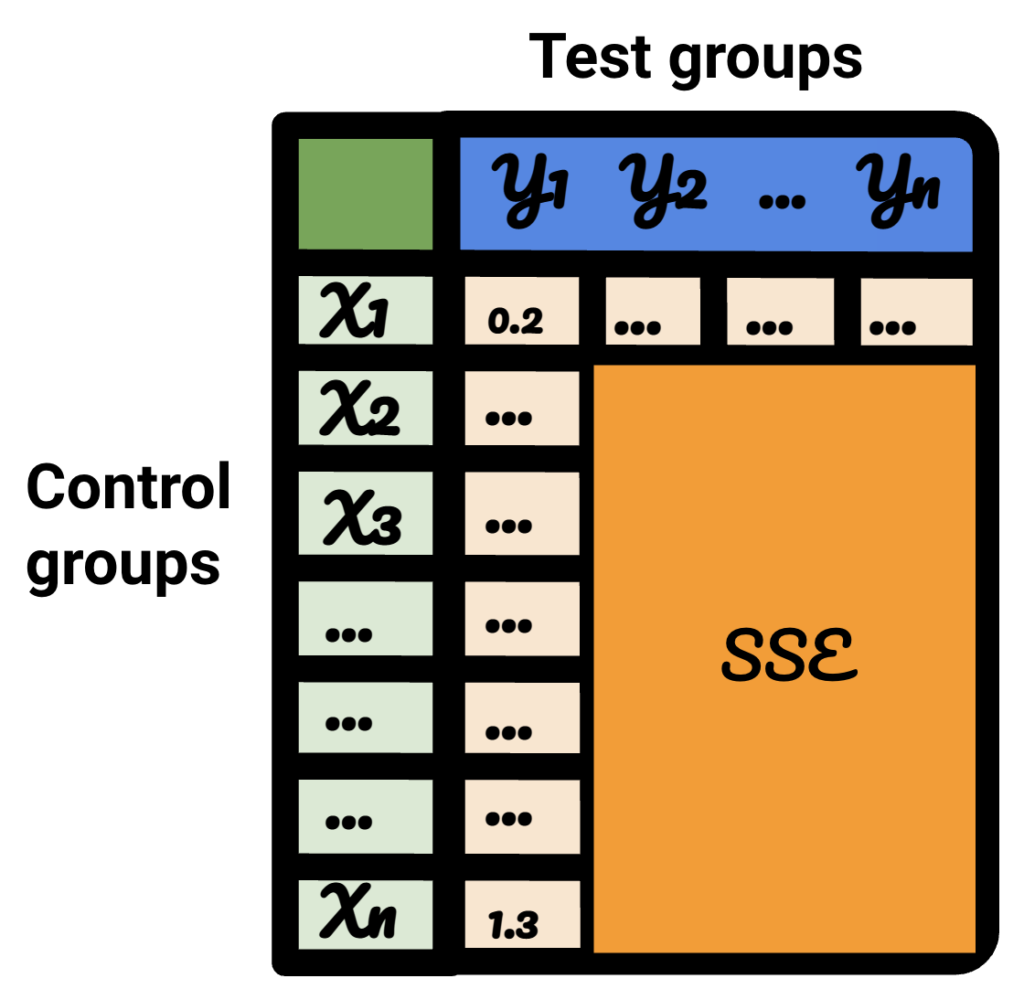
Sortując tę tabelę, jestem teraz pewien, że dla każdej z grup testowych mogę wybrać dla niej najlepszą grupę kontrolną.
Czy powinniśmy używać grup kontrolnych, czy nie?
Dowody pokazują, że użycie grup kontrolnych pomaga uzyskać lepsze szacunki niż proste pre-post.
Jednak dzieje się tak tylko wtedy, gdy wybierzemy odpowiednią grupę kontrolną.
Jak długi powinien być okres oszacowania?
Odpowiedź na to pytanie zależy od wybranych przez nas elementów sterujących.
Gdy nie używa się kontroli, wystarczy 16 miesięcy przed eksperymentem.
W przypadku korzystania z kontroli, używanie tylko 16 miesięcy może prowadzić do ogromnych wskaźników błędów. Korzystanie z 3 lat pomaga zmniejszyć ryzyko błędnej interpretacji.
Czy powinniśmy używać 1 kontroli czy wielu kontroli?
Odpowiedź na to pytanie zależy od danych testowych.
Bardzo stabilne dane testowe mogą działać dobrze w porównaniu z wieloma kontrolami. W tym przypadku jest to dobre, ponieważ użycie dużej ilości kontroli sprawia, że model jest mniej podatny na nieoczekiwane fluktuacje jednej z kontroli.
W innych zestawach danych użycie wielu elementów sterujących może sprawić, że model będzie 10-20 razy mniej precyzyjny niż użycie jednego.
Ciekawa praca w społeczności SEO
CausalImpact nie jest jedyną biblioteką, którą można wykorzystać do testowania SEO, ani powyższa metodologia nie jest jedynym rozwiązaniem pozwalającym sprawdzić jej dokładność.
Aby poznać alternatywne rozwiązania, przeczytaj kilka niesamowitych artykułów udostępnianych przez ludzi w społeczności SEO.
Najpierw Andrea Volpini napisała interesujący artykuł na temat mierzenia efektywności SEO za pomocą CausalImpact Analysis.
Następnie Daniel Heredia omówił pakiet Prophet Facebooka do prognozowania ruchu SEO za pomocą Prophet i Python.
Chociaż biblioteka Proroka jest bardziej odpowiednia do prognozowania niż do eksperymentów, warto poznać różne biblioteki, aby uzyskać mocne zrozumienie świata prognoz.
Na koniec bardzo ucieszyła mnie prezentacja Sandy'ego Lee w Brighton SEO, gdzie podzielił się spostrzeżeniami na temat Data Science do testowania SEO i podniósł niektóre pułapki związane z testowaniem SEO.
Rzeczy do rozważenia podczas przeprowadzania eksperymentów SEO
- Narzędzia do testowania podziału SEO innych firm są świetne, ale mogą też być niedokładne. Bądź dokładny przy wyborze rozwiązania.
- Chociaż pisałem o tym w przeszłości, nie można przeprowadzać eksperymentów SEO z podziałem testów za pomocą Menedżera tagów Google, chyba że po stronie serwera. Najlepszym sposobem jest wdrożenie za pośrednictwem sieci CDN.
- Bądź odważny podczas testowania. Niewielkie zmiany zwykle nie są wychwytywane przez CausalImpact.
- Testy SEO nie zawsze powinny być Twoim pierwszym wyborem.
- Istnieją alternatywy dla testowania mniejszych zmian, takich jak tagi tytułu. Testy A/B Google Ads lub testy A/B na platformie. Prawdziwe testy A/B są dokładniejsze niż testy podziału SEO i zwykle zapewniają więcej wglądu w jakość Twoich tytułów.
Powtarzalne wyniki
W tym samouczku chciałem skupić się na tym, jak można poprawić dokładność eksperymentów SEO bez konieczności znajomości kodu. Co więcej, źródło danych może się różnić, a każda witryna jest inna.
Dlatego kod Pythona, którego użyłem do stworzenia tej treści, nie był częścią zakresu tego artykułu.
Jednak dzięki logice możesz odtworzyć powyższe eksperymenty.
Wniosek
Gdybyś miał tylko jeden wniosek z tego artykułu, to analiza przyczynowego wpływu może być bardzo dokładna, ale zawsze może być daleka.
Dla SEO, którzy chcą korzystać z tego pakietu, bardzo ważne jest, aby zrozumieć, z czym mają do czynienia. Rezultatem mojej własnej podróży jest to, że nie zaufałbym CausalImpact bez uprzedniego przetestowania dokładności modelu na danych wejściowych.