
Crawl over Crawl jest już dostępny
Opublikowany: 2019-11-21Nasza funkcja Crawl over Crawl umożliwia porównanie dwóch różnych indeksowań i wyświetlenie ewolucji indeksowania .
W 2016 r. opierał się na naszym poprzednim wydaniu dotyczącym „Trendów”, które umożliwiało dostrzeżenie globalnych trendów między różnymi indeksowaniami. Teraz możesz uzyskać dostęp do pełnych widoków swoich ulepszeń SEO i wyróżnić różnice między indeksowaniem danego tematu . Aktualizacja Crawl over Crawl zawierała nowe typy wykresów do odczytywania danych.
W 2019 roku ulepszona została funkcja Crawl over Crawl. Możesz teraz zbadać:
- Dwie wersje witryny, które zawierają te same lub podobne strony, na przykład witryny produkcyjne i pomostowe lub wersje mobilne i komputerowe .
- Ta sama witryna w dwóch różnych momentach, na przykład przed i po zmianie w witrynie.
Porównanie dwóch wersji strony internetowej
Aby porównać dwie witryny, OnCrawl sprawdza podany przez Ciebie początkowy adres URL dla dwóch różnych indeksowań w celu określenia różnic w adresach internetowych różnych witryn. Zakłada, że te dwie wersje serwisu zawierają tę samą (lub prawie taką samą) treść. Oznacza to, że większość fragmentów adresów URL w dwóch porównywanych domenach, folderach lub subdomenach musi być taka sama .
Oto kilka przykładów witryn, które można porównać:
| Przypadek użycia | Indeksowanie 1 – URL początkowy | Indeksowanie 2 – URL początkowy |
|---|---|---|
| Witryny produkcyjne a miejsca inscenizacji | https://www.example.com | http://staging.example.com/site/ |
| Witryny na komputery a witryny mobilne | https://www.example.com | https://m.example.com |
| Wersje regionalne | https://www.example.com/en-us/ | https://www.example.com/pl-pl/ |
| Wersje regionalne | https://www.example.com | https://www.example.co.uk |
W przypadku złożonych różnic między początkowymi adresami URL automatyczne dopasowywanie może nie wystarczyć. W takim przypadku podczas konfigurowania indeksowania zobaczysz komunikat z prośbą o skontaktowanie się z OnCrawl za pośrednictwem czatu. Możemy pominąć automatyczne dopasowywanie, aby dostosować się do konkretnego przypadku.
Porównywanie jednej witryny w dwóch różnych punktach w czasie
Aby porównać jedną stronę w dwóch różnych momentach, na przykład przed i po ulepszeniu lub poważnej zmianie na stronie, musisz podać:
- Te same początkowe adresy URL
- Ta sama szerokość indeksowania (te same zasady eksploracji subdomeny)
Jak skonfigurować indeksowanie po indeksowaniu
Możesz uruchomić indeksowanie po indeksowaniu między dwoma istniejącymi indeksowaniami lub poprosić o porównanie z poprzednim indeksowaniem podczas tworzenia nowego. Więcej informacji na temat tworzenia indeksowania przez indeksowania można znaleźć w bazie wiedzy OnCrawl.
Jak czytać Crawl over Crawl sunburst
Czytasz sunburst jak tradycyjne ciasto. Te grafiki są bardzo przydatne do śledzenia ewolucji strony internetowej , indeksowania po indeksowaniu lub sprawdzania różnic między dwiema wersjami witryny (na przykład między wersją na żywo i podczas restrukturyzacji).
Ten wielopoziomowy wykres kołowy umożliwia porównanie dwóch indeksowań w zależności od danego motywu:
- Pierwszy poziom i wewnętrzny krąg : pokazuje strony należące do pierwszego indeksowania (starszego indeksowania).
- Drugi poziom i krąg zewnętrzny : pokazuje strony drugiego indeksowania (nowszego), które odpowiadają każdemu segmentowi wewnętrznego kręgu.
Dzięki temu możesz łatwo znaleźć na przykład strony do indeksowania w pierwszym indeksowaniu, których nie ma już w drugim i na odwrót.
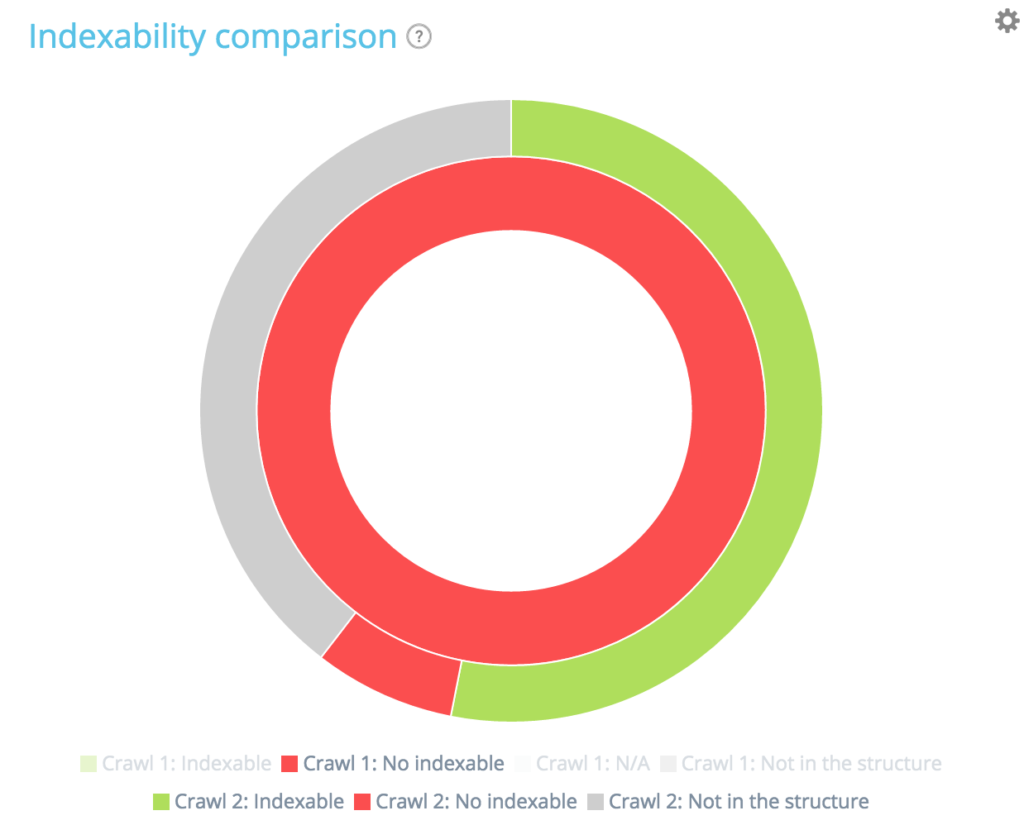
Na tym wykresie wewnętrzny okrąg pokazuje podział stron z pierwszego punktu widzenia indeksowania (starszego). Widać, że istnieją strony do indeksowania, nie ma stron do indeksowania i strony, które nie zostały przeszukane podczas pierwszego indeksowania, ale pojawiły się w drugim (sekcja szara).
Następnie dla każdej sekcji wewnętrznego kręgu możesz zobaczyć podział stron w danej sekcji podczas drugiego indeksowania. Wewnętrzna szara sekcja oznacza, że te strony nie istniały podczas pierwszego indeksowania, ale pojawiły się w drugim (zewnętrzna zielona i czerwona sekcja należąca do wewnętrznej szarej).

Szare sekcje oznaczają, że strony są nowe lub nieistniejące w strukturze, w zależności od tego, do którego cercle należą.
Klikając legendę, możesz zdecydować, które dane chcesz wyświetlić lub na których chcesz się skupić. Crawl 2 oferuje bardziej globalny widok.
Przyjrzyjmy się wewnętrznemu kręgowi.
Rozkład stron podczas pierwszego indeksowania zgodnie z ich indeksowalnością
 Pierwsze przeszukiwanie zawiera 10 854 stron do indeksowania i 177 stron nie do zindeksowania. 1 661 stron zostało znalezionych tylko podczas drugiego indeksowania.
Pierwsze przeszukiwanie zawiera 10 854 stron do indeksowania i 177 stron nie do zindeksowania. 1 661 stron zostało znalezionych tylko podczas drugiego indeksowania.
Teraz spójrz na zewnętrzny okrąg. Dla każdego segmentu pierwszego kręgu znajdujemy rozkład tych stron podczas drugiego indeksowania.
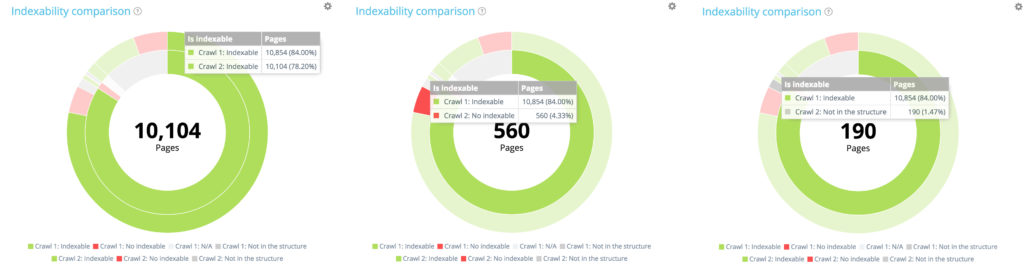
Spośród 10 854 indeksowanych stron w pierwszym przeszukiwaniu, tylko 10 104 nadal można zindeksować w drugim. 560 nie jest teraz indeksowanych, a 190 stron nie było już częścią witryny do indeksowania w momencie drugiego indeksowania.
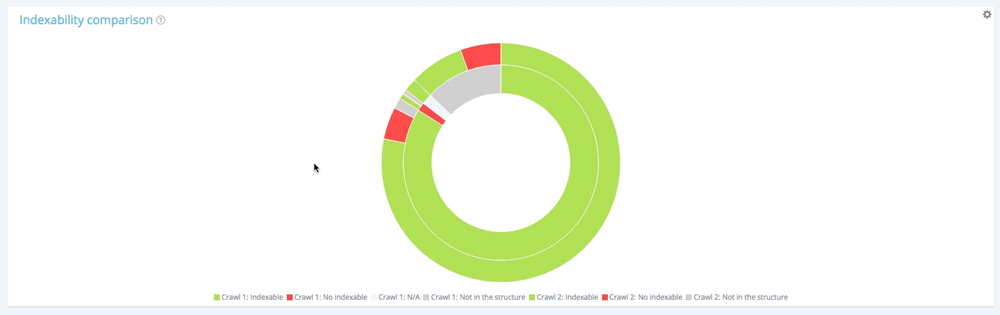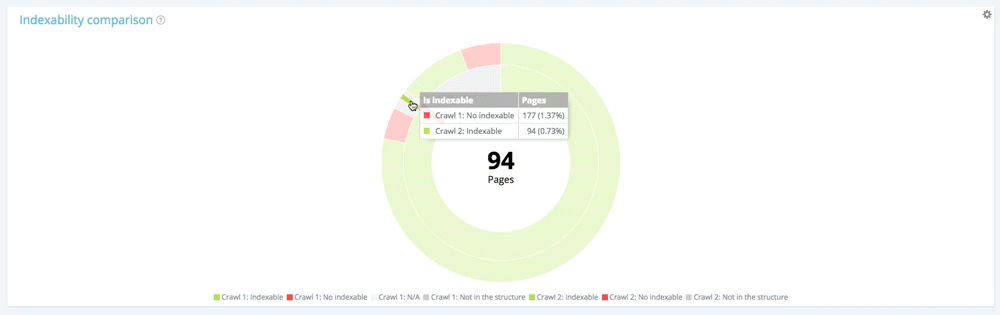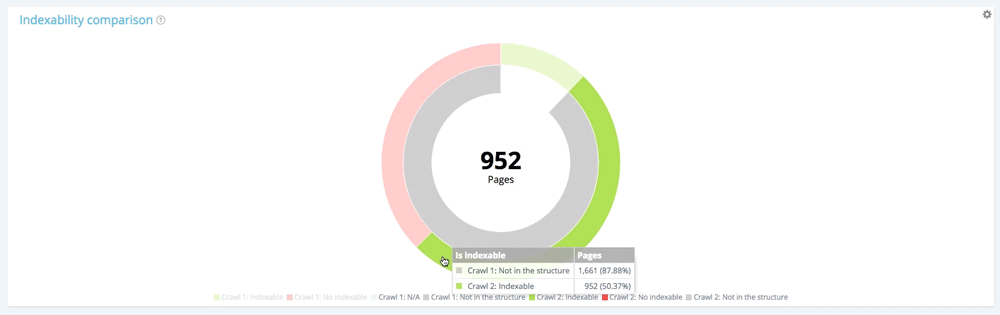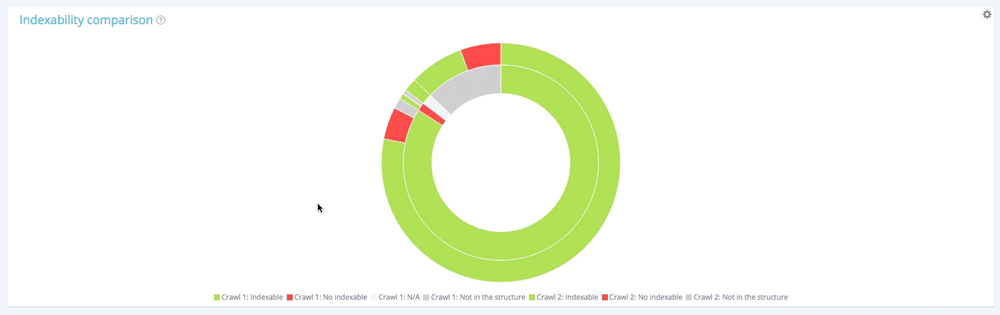
Skupmy się na małej sekcji: nieindeksowalne strony w pierwszym indeksowaniu
Używając legendy do ukrywania indeksowanych stron i stron, które nie znajdują się w strukturze witryny w momencie pierwszego indeksowania, możemy skoncentrować się tylko na nieindeksowanych stronach podczas pierwszego indeksowania.
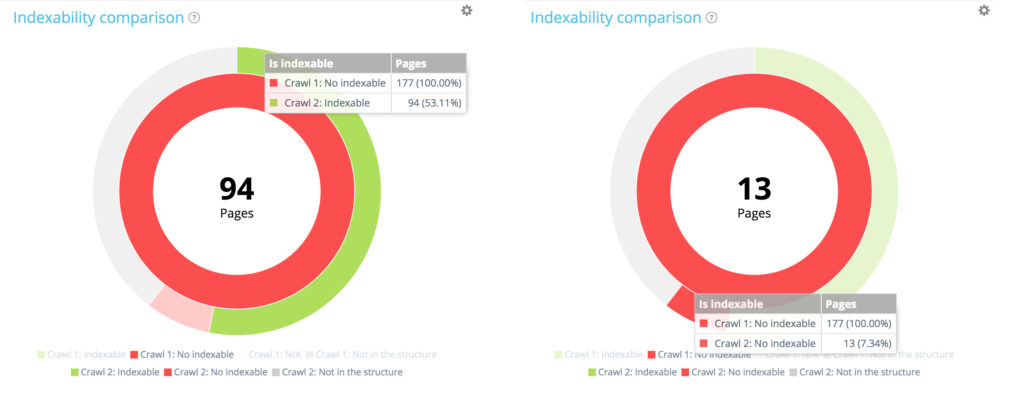 Spośród 177 nieindeksowanych stron z pierwszego indeksowania 94 są teraz indeksowane w drugim, a 13 pozostaje do zindeksowania.
Spośród 177 nieindeksowanych stron z pierwszego indeksowania 94 są teraz indeksowane w drugim, a 13 pozostaje do zindeksowania.
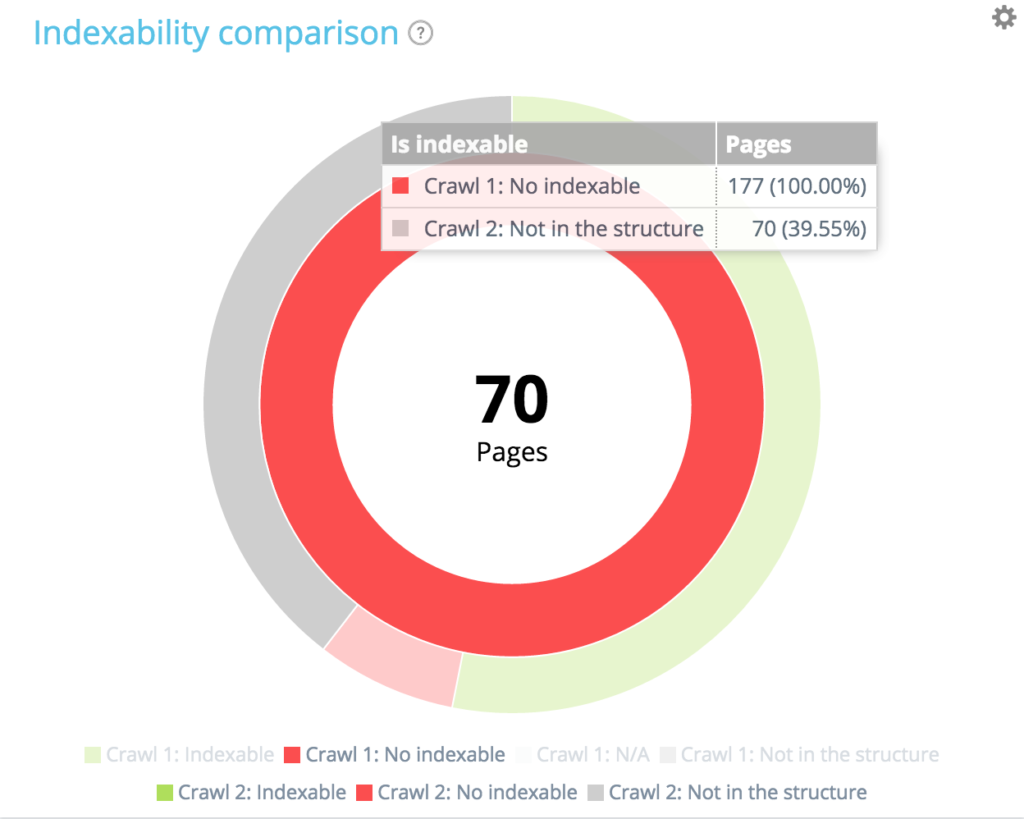
Spośród 177 stron, których nie można zindeksować podczas pierwszego przeszukiwania, 70 nie jest już obecnych podczas drugiego przeszukiwania. 94 + 13 + 70 = 177. Znajdujemy oczekiwany podział 177 stron niepodlegających indeksowaniu z pierwszego indeksowania.
Skoncentruj się na nowych stronach: strony znalezione tylko podczas drugiego indeksowania
Teraz użyjmy legendy, aby ukryć zarówno indeksowane, jak i nieindeksowalne strony z pierwszego indeksowania i pokażmy tylko strony, które nie były częścią struktury witryny podczas tego indeksowania. Pozwala to zobaczyć stan nowych stron pod względem indeksacji.
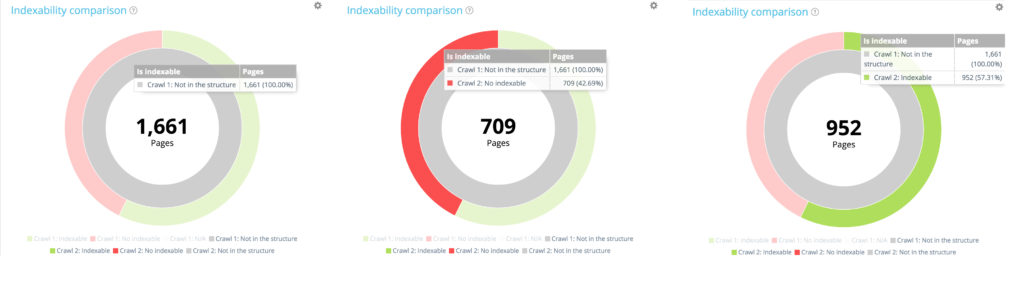
Wszystkie nowe strony: 1 661 stron.
Z 1661 nowo utworzonych stron 709 nie jest indeksowanych.
Z 1661 nowo utworzonych stron 952 można zindeksować.
Podsumowanie: wszystkie strony z drugiego indeksowania
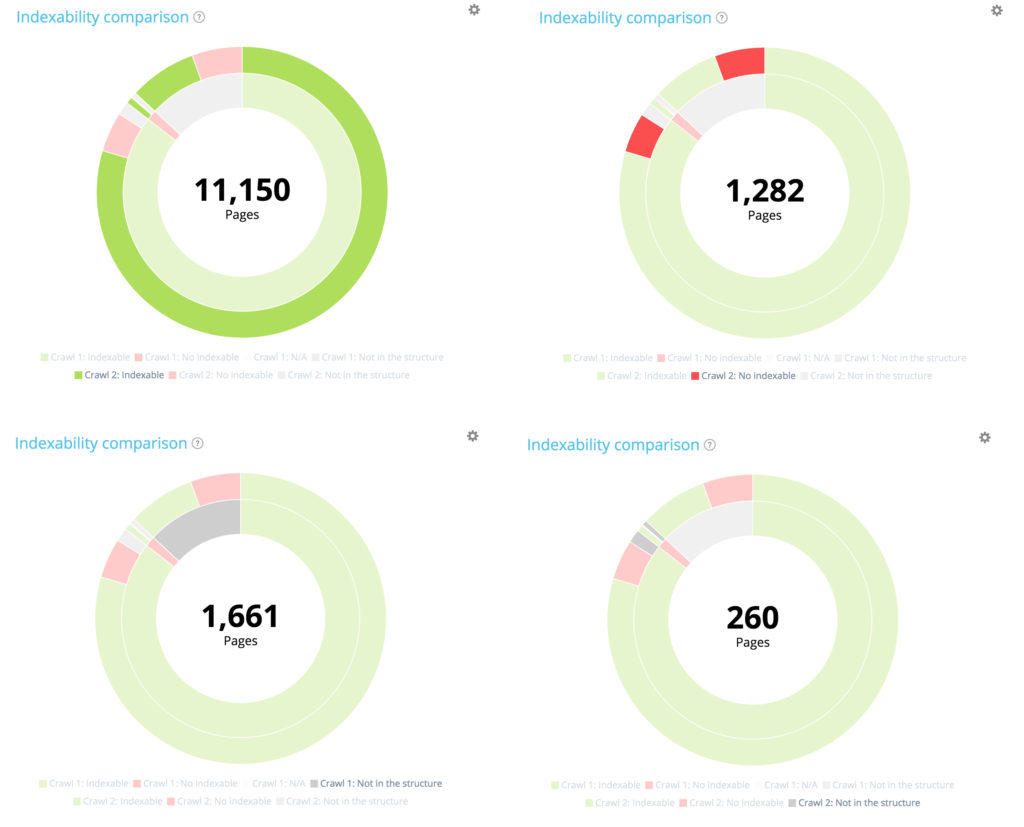 Podczas pierwszego indeksowania można było zindeksować 10 104 stron. 11 150 jest teraz indeksowanych w drugim. 177 stron nie było indeksowanych w pierwszym przeszukiwaniu, ale 1282 nie jest teraz indeksowanych w drugim.
Podczas pierwszego indeksowania można było zindeksować 10 104 stron. 11 150 jest teraz indeksowanych w drugim. 177 stron nie było indeksowanych w pierwszym przeszukiwaniu, ale 1282 nie jest teraz indeksowanych w drugim.
Utworzono 1661 stron, a 260 stron usunięto ze struktury.
Crawl over Crawl: dostępne dane
Ta nowa funkcja jest podzielona według ekspertyz biznesowych i między następującymi zakładkami:
- Struktura
- Łączenie wewnętrzne
- Zawartość
- Kody statusu
- Występ
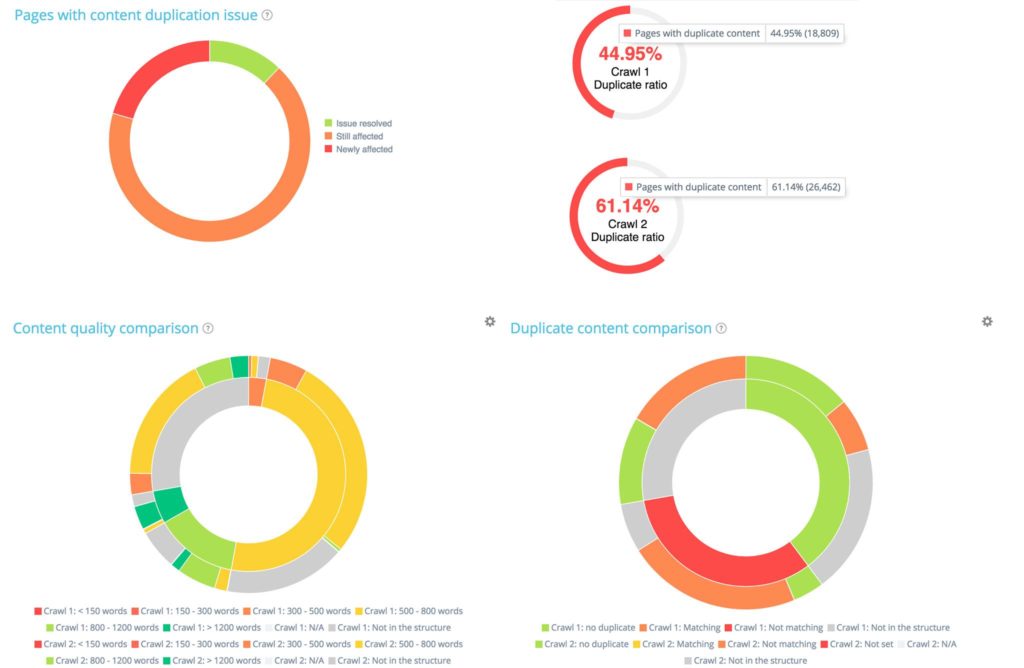
Na przykład w sekcji „Treść” skupisz się na różnicach w duplikacji między tymi dwoma indeksowaniami:
Możesz też przeanalizować, jak głębokość strony różni się w obu indeksach. Na poniższym wykresie widać różnice w głębokości:
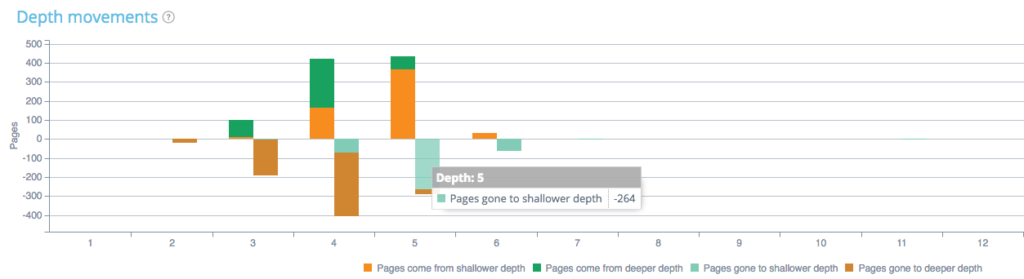
Na przykład, jeśli spojrzymy na głębokość 5, możemy zobaczyć strony, które przeszły na płytszą lub głębszą głębokość lub strony, które pochodzą z płytszej lub głębszej głębokości między indeksowaniem 1 a 2. Tutaj 264 strony, które były w indeksowaniu 1 i na głębokości 5 zszedł na płytszą głębokość (głębokość 4, 3 lub 2).
To tylko przegląd tego, co jest dostępne. Nasz Eksplorator danych pozwala również zagłębić się w ponad 700 metryk w celu porównań indeksowania.