
Jak zautomatyzować modelowanie marketing mix za pomocą arkusza kalkulacyjnego MMM data feed
Opublikowany: 2022-06-16Marketing mix modeling lub MMM przeżywa renesans, ponad 60 lat odkąd weszło do powszechnego użytku. W przeciwieństwie do większości metod atrybucji marketingowej, MMM nie wymaga danych na poziomie użytkownika, zamiast modelować, które kanały zasługują na udział w sprzedaży, poprzez statystyczne mapowanie skoków i spadków wydatków na działania i zdarzenia w Twoich kanałach marketingowych. Przechodząc od prostej regresji liniowej do technik takich jak regresja grzbietowa lub metody bayesowskie, modelowanie marketingowe zostało wynalezione na nowo dla współczesności.

Chcesz dowiedzieć się więcej o MMM?
Zapoznaj się z zaletami i wadami modelowania marketingu mix a modelowania atrybucji
Jednak istnieją poważne przeszkody do pokonania. Według firmy Meta/Facebook, która pracuje nad swoją biblioteką MMM o otwartym kodzie źródłowym od października 2021 r., budowanie modelu może zająć od 3 do 6 miesięcy. Szacuje się, że około 50% czasu spędza się na gromadzeniu i czyszczeniu danych przed rozpoczęciem modelowania . Jest to zgodne z moim doświadczeniem w Recast — a wcześniej Harrym — a także z wynikami badania CrowdFlower, które wykazało, że 60% czasu poświęconego na analizę danych spędza się na czyszczeniu i organizowaniu danych.
Przewiń do przodu >>
- Czyszczenie danych
- Budowanie modelu marketingu mix
- Zautomatyzowane modelowanie
Czyszczenie danych to 60% pracy, a jak to zrobić 0%
Aby zbudować dokładny model, potrzebujesz danych w określonym formacie. Przygotowanie danych jest czasochłonne, więc projekty MMM trwają dłużej niż to konieczne. To sprawia, że MMM jest specjalistyczną i kosztowną umiejętnością, więc większość firm może zbudować tylko jeden do dwóch modeli rocznie. Jeśli potrafisz zautomatyzować proces za pomocą narzędzia takiego jak Supermetrics do tworzenia pliku danych MMM, możesz regularnie aktualizować swój model, co pozwoli lepiej zoptymalizować budżet marketingowy.
Format danych tabelarycznych
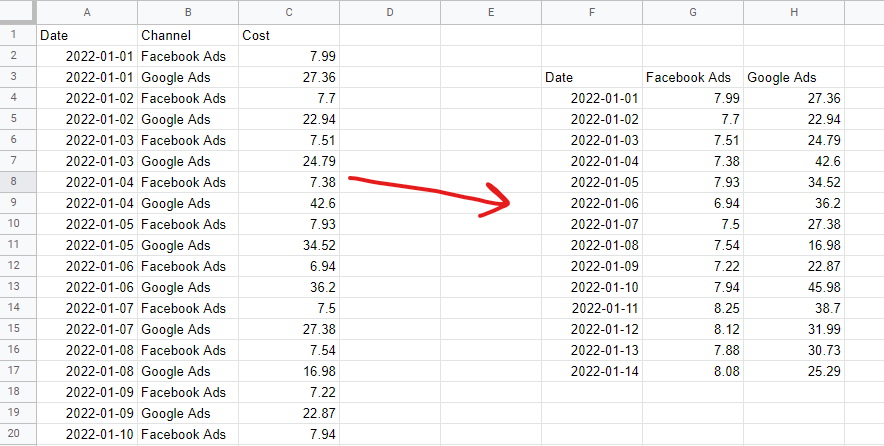
Aby zbudować model marketingu mix, musisz mieć dane ułożone w nieułożonym formacie tabelarycznym. Oznacza to jeden wiersz na obserwację — zwykle dni lub tygodnie — i jedną kolumnę na „cechę” modelu — zazwyczaj wydatki na media i zmienne organiczne lub zewnętrzne. Dane kategoryczne — na przykład lista świąt narodowych — muszą być zakodowane w zmiennych fikcyjnych — 1, gdy jest to święto, 0, gdy tak nie jest.
Połączone źródła danych
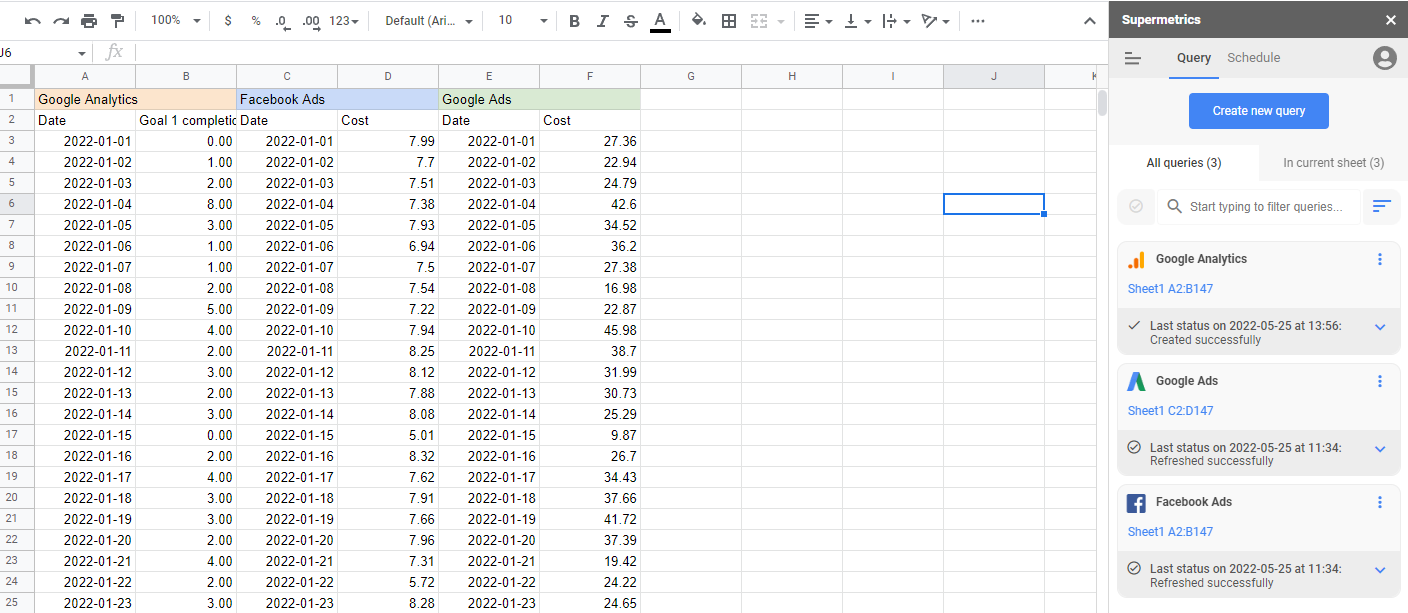
Aby zbudować model atrybucji marketingowej, musisz mieć wszystkie dane marketingowe w jednym miejscu. To jest to, co Supermetrics obsługuje automatycznie. Dzięki ponad 90 łącznikom wszystkie wydatki marketingowe, wydarzenia i działania można zebrać w jednym miejscu, manipulować w razie potrzeby, a następnie wyeksportować do wymaganego formatu i lokalizacji.
Eksportowanie do Arkuszy Google
Gdy już masz konto Supermetrics, wystarczy przejść do Rozszerzenia > Dodatki > Pobierz dodatki i zainstaluj je. Poprosi Cię o uwierzytelnienie za pomocą konta Google połączonego z kontem Supermetrics, a następnie w menu rozszerzeń pojawi się pasek boczny.
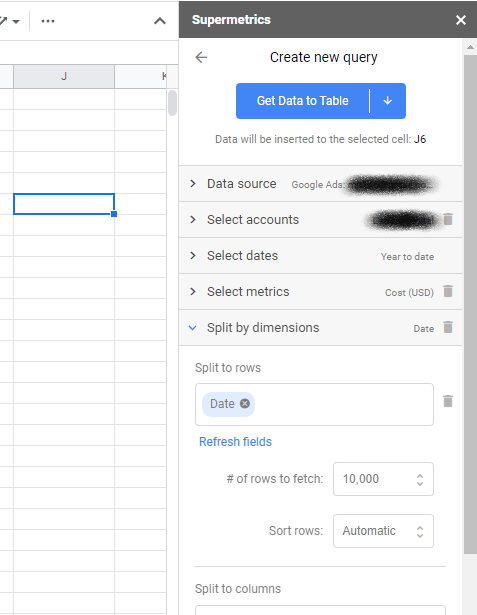
Po wykonaniu tej czynności możesz uruchomić pasek boczny — jeśli jeszcze nie został uruchomiony — i kliknąć, aby utworzyć nowe zapytanie. Zapytania pozwalają zdecydować, jakie dane pobrać i z jakich kont. Po wybraniu jednej z platform reklamowych, takich jak Facebook Ads i Google Ads, zostaniesz poproszony o uwierzytelnienie i przyznanie dostępu do Supermetrics.
Następnie wybierz konto, z którego chcesz pobierać dane, oraz zakres dat. Na koniec wybierz dane — zwykle koszt lub wyświetlenia w przypadku MMM — oraz wymiary — wybierz tylko datę, aby była zgodna z formatem tabelarycznym.
Opcjonalnie możesz dodać filtr, jeśli chcesz wybrać określony zestaw kampanii. Na przykład, jeśli masz „YT: ” w nazwie kampanii YouTube, możesz wybrać je jako osobne źródło, a następnie zduplikować zapytanie i filtr dla każdego z innych typów kampanii.
Po zakończeniu zapytania upewnij się, że wybrałeś komórkę, do której mają zostać pobrane dane, i kliknij przycisk „Pobierz dane do tabeli”. Jeśli się pomylisz, po prostu zduplikuj zapytanie i umieść je w odpowiednim miejscu, usuwając drugie.
Uważam, że pomocne jest umieszczenie nazwy każdego źródła w komórce nad tabelą, aby wiedzieć, skąd pobieram dane. Wynik powinien wyglądać tak:
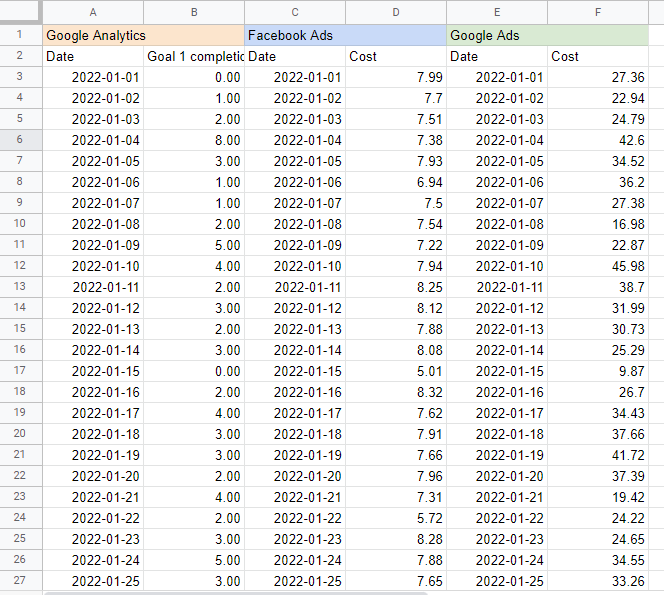
Budowanie modelu marketingu mix w Arkuszach Google
Modelowanie marketingu mix to potężne narzędzie do atrybucji, ale w rzeczywistości jest bardziej dostępne, niż mogłoby się wydawać. Większość praktyków korzysta z niestandardowego kodu i zaawansowanych statystyk, ale podstawy można wykonać w ciągu jednego popołudnia, korzystając jedynie z Excela lub Arkuszy Google.
Regresja liniowa z funkcją REGLINP
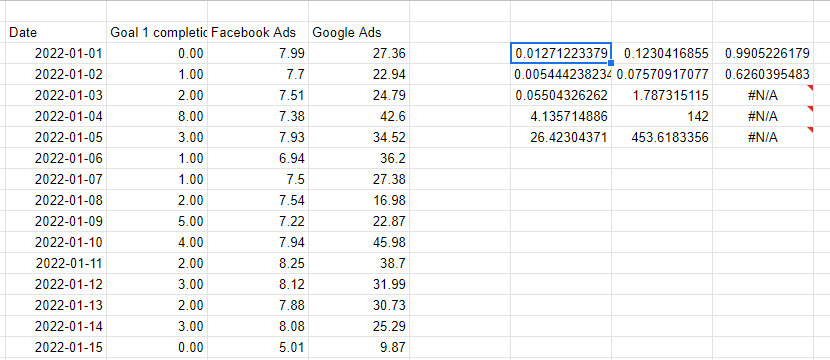
Zarówno Excel, jak i Arkusze Google zapewniają prostą metodę, funkcję REGLINP, do wykonywania regresji liniowej wielu zmiennych. Funkcja REGLINP działa poprzez przekazanie kolumny, którą próbujemy przewidzieć, a następnie wielu kolumn reprezentujących zmienne, których używamy do przewidywania. Ostatnie dwa parametry to to, czy chcemy linii przecięcia — zwykle 1 dla tak — i czy chcemy, aby dane wyjściowe były pełne — zawierające wszystkie statystyki dla modelu, a nie tylko współczynniki.
Zwróć uwagę, że zmienne X, których używamy do przewidywania, muszą być następujące po sobie, więc właśnie odwołałem się do kolumn po lewej stronie, aby powtórzyć wartości obok siebie.
Ponowne prognozowanie ze współczynnikami modelu
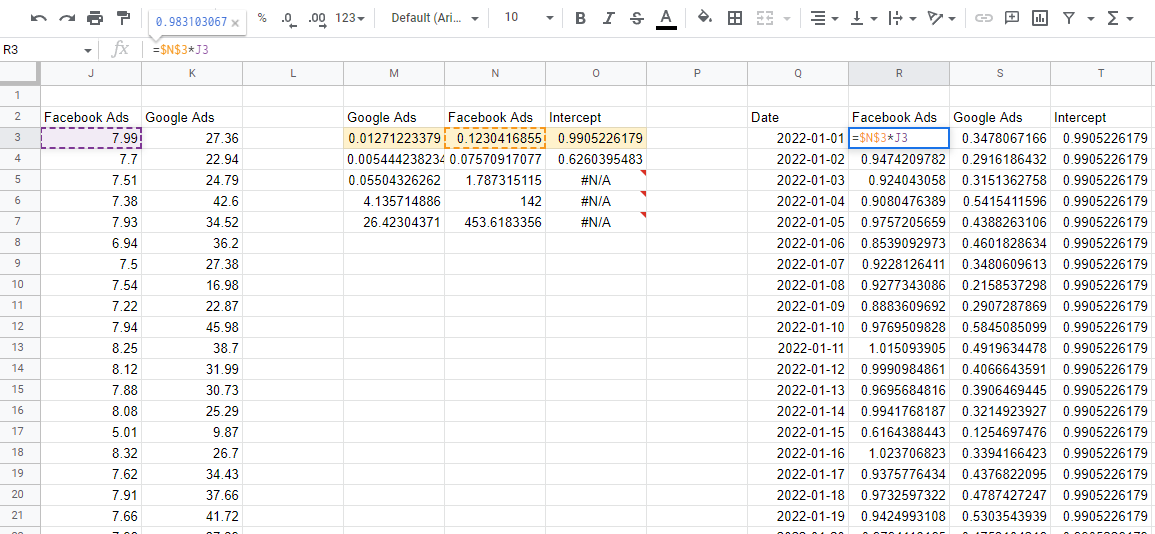
Teraz, gdy mamy już model, musimy użyć współczynników do oszacowania wpływu każdego kanału. Jeśli weźmiemy górny rząd liczb, to są współczynniki, i pomnożymy je przez odpowiednie wartości wejściowe z naszych danych — otrzymamy udział każdej zmiennej w całkowitej sprzedaży.

Jedną rzeczą, na którą należy zwrócić uwagę, jest to, że funkcja REGLINP wyprowadza współczynniki wstecz. Pierwsza wartość zaczynająca się od lewej jest zawsze ostatnią wprowadzoną zmienną, a następnie są one kontynuowane w odwrotnej kolejności, aż dojdziesz do ostatniej wartości, czyli przecięcia. Jeśli zsumujesz wszystkie te wartości wkładu, otrzymasz prognozy z modelu, które możesz porównać z rzeczywistymi, aby upewnić się, że model jest dokładny.
Sprawdzanie metryk dokładności modelu
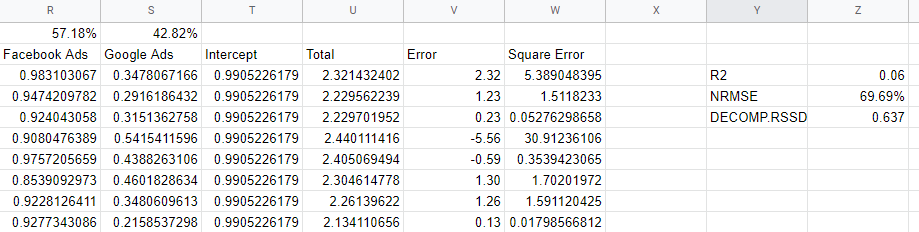
Skąd wiemy, czy nasz model jest niezawodny? Model powinien dobrze pasować do danych, powinien być w stanie przewidzieć nowe dane, których nie widział, i powinien mieć wiarygodne współczynniki. Kilka metryk walidacji uwzględnia te wymagania.
Sprawdź funkcje w szablonie, aby zobaczyć, jak obliczyć te metryki.
Aby użyć szablonu, przejdź do „Plik” > „Utwórz kopię” > „Uruchom Supermetrics” z listy dodatków > zduplikuj ten plik dla innego konta, a następnie przejdź do wyboru konta.
R2 lub R-kwadrat jest miarą tego, jaka część wariancji danych jest wyjaśniona przez model i wynosi od 0 do 1: dobry model byłby powyżej 0,7, ale wszystko, co zbliża się do 1, jest prawdopodobnie podejrzane. Blisko 0, podobnie jak w naszym modelu, to znak, że nie uwzględniamy w nim wystarczającej liczby zmiennych i musimy uwzględnić takie elementy, jak kanały organiczne, święta i czynniki makroekonomiczne.
„Znormalizowany pierwiastek błędu średniokwadratowego” to sposób, w jaki mierzymy dokładność i znajduje się on na podstawie różnicy między przewidywaniami modelu a wartościami rzeczywistymi, a następnie znalezieniu pierwiastka z kwadratów wartości jako procent wartości rzeczywistej. Najlepiej byłoby, gdyby odbywało się to na podstawie niewidocznych danych — grupy wstrzymanej — ale w naszym prostym modelu po prostu obliczyliśmy błąd w odniesieniu do danych w próbce.
Procedura pierwiastka i kwadratury obsługuje dla nas wartości ujemne i karze naprawdę duże błędy. Można to zinterpretować jako odsetek modelu wyłączony w danym dniu, więc jest to przydatna, intuicyjna miara.
Wiarygodność to duży temat i zwykle jest to coś, co do którego analityk powinien mieć ostatnie słowo. Jednak warto mieć metrykę, którą można obliczyć programowo, aby zrozumieć, jak bardzo model odbiega pod względem wyników od aktualnego zestawu kanałów.
Decomp RSSD to metryka wymyślona przez zespół Robyn na Facebooku, która mierzyła różnicę między Twoją obecną alokacją wydatków a kanałami, które przyniosły największe efekty, zgodnie z przewidywaniami modelu. Jeśli model powiedziałby, że Twój największy kanał w rzeczywistości nie generował tak dużej sprzedaży, miałbyś wysoki wskaźnik RSSD Decomp.
W naszym przypadku mamy wysoką wartość 0,6, ponieważ model daje zbyt duży kredyt Facebookowi, co oznacza niewielką kwotę wydatków.
Dostarczanie MMM automatycznie i na dużą skalę
Modelowanie Marketing Mix to jedna z tych czynności, które są nieskończenie skalowalne. Możesz uzyskać przyzwoite wyniki po południu z Excelem lub Google Sheets i Supermetrics, tak jak to zrobiliśmy tutaj, ale możesz także spędzić 3 miesiące z zespołem 6 analityków danych piszących niestandardowy kod za pomocą wyrafinowanych algorytmów, takich jak Bayesian MCMC, aby zbudować coś więcej solidny i dokładny.
Istnieje lista kontrolna funkcji związanych z budowaniem zaawansowanego modelu, z których niektóre wymagają zaawansowanej wiedzy statystycznej. Dodaj do tego kilku drogich inżynierów danych do budowania potoków danych, jeśli nie używasz Supermetrics do automatyzacji tej części.
Chcesz dowiedzieć się więcej o automatyzacji miksu modelowania?
Zapoznaj się z naszym artykułem o automatycznym modelowaniu marketingu mix
Uwaga: MMM jest trudne. Możesz wydać 500 USD, 5000 USD lub 50 000 USD na modelowanie i zobaczyć szalenie różne wyniki pod względem dokładności i niezawodności. To, co naprawdę ma znaczenie, to koszt alternatywny nieprawidłowej alokacji wydatków marketingowych.
Jeśli wydasz 10 tys. USD miesięcznie, model arkusza kalkulacyjnego raz na kwartał będzie w porządku. Jeśli jednak wydajesz ponad 100 000 USD miesięcznie, nawet 5% zniżki może kosztować dziesiątki tysięcy dolarów w ciągu roku.
Nie masz pewności, jakiego modelu dostępu do danych potrzebujesz dla swojego pliku danych MMM?
Sprawdź nasz artykuł, aby wybrać odpowiedni dla swojej firmy
Wtedy warto zainwestować w bardziej zaawansowane modelowanie. Przeprowadź analizę kompilacji i zakupu, aby zdecydować między niestandardowym rozwiązaniem zbudowanym na bibliotekach open source, takich jak Robyn Facebooka, a zaawansowanym oprogramowaniem do atrybucji, takim jak to, które zbudowaliśmy w Recast.
O autorze
Michael Kaminsky jest wykształconym ekonometrykiem z doświadczeniem w opiece zdrowotnej i ekonomii środowiska. Wcześniej zbudował zespół ds. marketingu w męskiej marce fryzjerskiej Harry's, zanim założył Recast.

Popraw wyniki swojej firmy
łącząc marketing i business intelligence w Twojej hurtowni danych