
Zwiększanie bezpieczeństwa bankowości: uczenie maszynowe do wykrywania oszustw
Opublikowany: 2023-11-14Z każdą okazją pojawia się zagrożenie. Przejście w kierunku cyfryzacji w branży bankowej poprawiło jakość obsługi klientów i rozszerzyło bazę klientów o populacje, które wcześniej nie korzystały z usług bankowych. Wadą było to, że transakcje online i rozwiązania w zakresie płatności cyfrowych otworzyły nowe możliwości dla oszustów.
Wyniki badania KMPG dotyczącego oszustw wskazują, że częstotliwość i dotkliwość cyberataków wzrasta, powodując straty w wysokości miliardów dolarów.
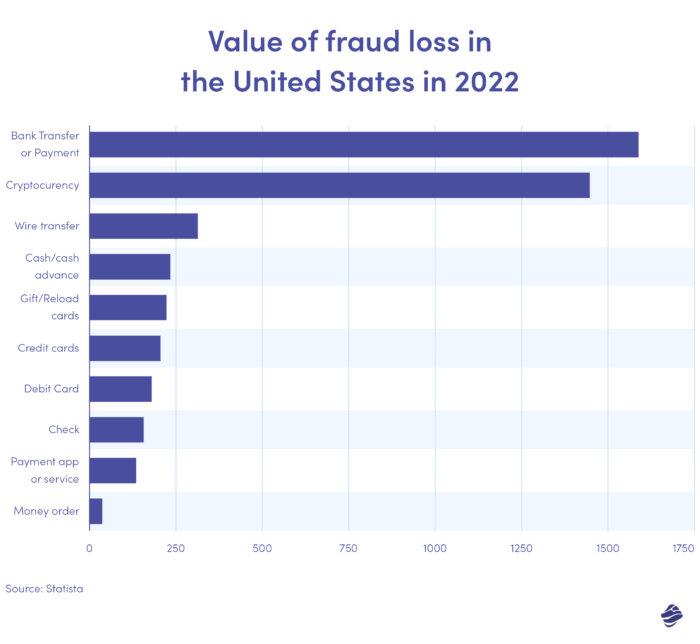
Powyższy wykres ilustruje wartość strat wynikających z oszustw według metody płatności w Stanach Zjednoczonych w 2022 r. Najwyższe były przelewy bankowe i płatności, ze stratą w wysokości 1,59 miliarda dolarów.
Straty te zmusiły instytucje bankowe do przyjęcia nowych rozwiązań w zakresie wykrywania, łagodzenia i zapobiegania oszustwom finansowym. Jedną z takich metod jest sztuczna inteligencja (AI), w szczególności uczenie maszynowe.
W tym artykule omówimy wszystko, co musisz wiedzieć o uczeniu maszynowym do wykrywania oszustw , w tym o korzyściach i rzeczywistych zastosowaniach.
Ewolucja wykrywania oszustw
Tradycyjne wykrywanie oszustw opiera się na podejściu opartym na regułach. Jak sama nazwa wskazuje, działa zgodnie z zestawem zasad lub warunków, które określają, czy transakcja jest autentyczna czy oszukańcza. Typowe warunki obejmują lokalizację (czy zakup znajduje się poza zwykłym obszarem użytkownika?) i częstotliwość (czy liczba i rodzaj zakupów są typowe dla użytkownika?).
Transakcja dochodzi do skutku tylko wtedy, gdy spełnia określone warunki. Na przykład klient z Ohio nagle został obciążony opłatą za zakup w punkcie sprzedaży w Nowej Zelandii. Lokalizacja jest poza numerem kierunkowym użytkownika, więc system oznacza transakcje jako fałszywe.
Tego typu system wykrywania oszustw ma kilka wad.
- Generuje dużą liczbę fałszywych alarmów. W tym miejscu blokujesz płatności od prawdziwych klientów.
- Jest nieelastyczny. Podejście oparte na regułach wykorzystuje stałe wyniki, co utrudnia dostosowanie się do trendów w bankowości cyfrowej. Aby wychwytywać nowe formy oszustw, należy zmienić zasady.
- To się nie skaluje. Wraz ze wzrostem ilości danych wzrasta również wysiłek, jaki należy podjąć, aby temu zapobiec. Wszelkie zmiany w systemie dokonywane są ręcznie, co czyni je kosztownymi i czasochłonnymi.
Wykrywanie oszustw w oparciu o reguły działa. Jednak jego wady sprawiają, że nie nadaje się do nowoczesnych środowisk cyfrowych. Nie rozpoznaje wzorców i polega na interwencji człowieka.
Co więcej, hakerzy nie przestrzegają harmonogramu pracy od 9 do 17 i mogą stosować wyrafinowane metody, takie jak fałszowanie lokalizacji i podszywanie się pod zachowanie klientów, aby oszukać systemy wykrywania oszustw. Dlatego potrzebny jest równie wysoko rozwinięty system, który działa 24 godziny na dobę, 7 dni w tygodniu.
Wejdź w uczenie maszynowe.
Uczenie maszynowe to sztuczna inteligencja (AI) , która wykorzystuje dane do uczenia algorytmów wykrywania oszustw w celu odkrywania wzorców i relacji danych, uzyskiwania wglądu i prognozowania.
Znasz już uczenie maszynowe, nawet jeśli o tym nie wiesz. Na przykład za każdym razem, gdy wchodzisz w interakcję z postem na Instagramie, przekazujesz algorytmowi informacje o rodzaju treści, które lubisz. Następnie przeszukuje aplikację w poszukiwaniu podobnych treści, które można dodać do kanału.
Jak uczenie maszynowe zmieni sposób wykrywania oszustw
Wykrywanie oszustw w bankowości za pomocą uczenia maszynowego już zmienia branżę, zapewniając szybszą, bardziej elastyczną i dokładniejszą identyfikację oszustw i reagowanie na nie.
System AI analizuje wzorce w danych klientów i automatycznie zmienia reguły w oparciu o historyczne i pojawiające się zagrożenia.
Pamiętasz tę opłatę POS w Nowej Zelandii, o której wspominaliśmy wcześniej? Wykrywanie oszustw za pomocą uczenia maszynowego uwzględnia, że za pomocą tej samej karty bankowej dokonano zakupu na lot do tej lokalizacji. Dlatego nowe obciążenie jest najprawdopodobniej uzasadnione.
Do uczenia algorytmów wykrywania oszustw wykorzystywane są dwa modele: nadzorowane uczenie maszynowe i uczenie maszynowe bez nadzoru.
Nadzorowane uczenie maszynowe
Model uczenia się nadzorowanego dostarcza algorytmom duże ilości danych oznaczonych jako oszustwa lub niebędące oszustwami. Algorytm bada te przykłady i uczy się, jakie wzorce i relacje odróżniają transakcje uzasadnione od fałszywych.
Ten model uczenia się jest czasochłonny, ponieważ wymaga ręcznego oznaczania danych. Co więcej, Twoje zbiory danych muszą być odpowiednio oznakowane i dobrze zorganizowane. Nieprawidłowo oznaczona transakcja będzie miała wpływ na dokładność algorytmu.
Dodatkowo uczy się wyłącznie na podstawie danych wejściowych zawartych w zestawie uczącym. Zatem transakcje realizowane za pośrednictwem nowo uruchomionych funkcji aplikacji bankowości mobilnej, które nie były częścią danych historycznych, nie zostaną oznaczone. Obecnie istnieje luka, którą oszuści mogą wykorzystać.
Uczenie maszynowe bez nadzoru
Model uczenia się bez nadzoru wykorzystuje minimalny wkład człowieka. Algorytm uczy się wzorców i zależności z dużych ilości nieoznaczonych danych, grupując zbiory danych na podstawie podobieństw i różnic.
Celem jest wykrycie nietypowej aktywności, która nie jest uwzględniona w zestawie danych szkoleniowych. Zatem uczenie się bez nadzoru wzmaga się tam, gdzie uczenie się pod nadzorem zanika i wykrywa nowe oszustwa.
Pamiętaj, że nie musisz wybierać pomiędzy modelem uczenia maszynowego nadzorowanego i nienadzorowanego. Można ich używać razem (model uczenia się częściowo nadzorowanego) lub niezależnie.
Korzyści z wykorzystania ML do wykrywania oszustw
Wspomnieliśmy o korzyściach płynących z wykrywania oszustw przy użyciu uczenia maszynowego w bankowości, ale omówmy je dalej.
- Prędkość
Obliczenia oparte na uczeniu maszynowym zachodzą szybko i pozwalają podejmować decyzje dotyczące oszustw w czasie rzeczywistym. Chociaż algorytmy oparte na regułach również podejmują decyzje w czasie rzeczywistym, w celu sygnalizowania oszustw polegają na pisemnych zasadach.
Co dzieje się w nowych scenariuszach bez z góry określonych reguł? Prowadzi to do wyników fałszywie dodatnich lub fałszywie ujemnych.
Uczenie maszynowe automatycznie wykrywa nowe wzorce, analizując regularne działania klientów i obliczając odpowiednie wyniki w ciągu milisekund.
- Dokładność
Systemy wykrywania oparte na regułach blokują prawdziwe transakcje lub dopuszczają oszukańcze, ponieważ nie wykrywają niuansów w zachowaniu klientów.
Systemy uczenia maszynowego uwzględniają zmienne wykraczające poza spisane zasady, na przykład znane oszukańcze zachowanie. Zmienne te pomagają kontekstualizować transakcję, zmniejszając odsetek fałszywych alarmów.
- Elastyczność
Uczenie maszynowe jest elastyczne i reaktywne. Zdolność samouczenia się umożliwia systemowi dostosowywanie się do nowych scenariuszy i wykrywanie nowych zagrożeń. Systemy oparte na regułach są sztywne i nie mają możliwości uczenia się. W związku z tym może reagować na oszukańcze działania wyłącznie zgodnie z wcześniej określonymi zasadami.
- Efektywność
Algorytmy uczenia maszynowego mogą analizować tysiące danych transakcyjnych na sekundę. Zamiast poświęcać koszty pracy i koszty ogólne na badanie przypadków niewielkich i umiarkowanych oszustw, uczenie maszynowe może przetwarzać powtarzające się lub wyraźne oszustwa. Pozwala specjalistom ds. oszustw skoncentrować się na złożonych wzorcach wymagających wglądu człowieka.
- Skalowalność
Zwiększona ilość danych wywiera presję na systemy oparte na regułach. Nowe zasady zwiększają złożoność systemu, utrudniając jego utrzymanie. Każdy błąd lub sprzeczność może sprawić, że cały model stanie się nieskuteczny.
Systemy uczenia maszynowego są odwrotnością. Nie tylko przyswajają duże ilości nowych danych, ale także je ulepszają.
Techniki uczenia maszynowego stosowane w wykrywaniu oszustw
Zanim przyjrzymy się różnym algorytmom używanym do wykrywania oszustw AI, przyjrzyjmy się, jak działa ten system.
Pierwszym krokiem jest wprowadzenie danych. Dokładność modelu zależy od ilości i jakości danych. Im więcej danych wysokiej jakości dodasz, tym dokładniejszy będzie model.
Następnie model analizuje dane i wyodrębnia kluczowe cechy opisujące normalne zachowania w porównaniu z zachowaniami oszukańczymi. Funkcje te obejmują tożsamość klienta (e-mail lub numer telefonu), lokalizację (adres IP lub adres wysyłki), metody płatności (imię i nazwisko posiadacza karty i kraj pochodzenia) i inne.
Trzecim krokiem jest przeszkolenie algorytmu (z większą ilością danych) w celu rozróżnienia transakcji prawdziwych od fałszywych. Model otrzymuje zbiór danych szkoleniowych i przewiduje prawdopodobieństwo oszustwa w różnych przypadkach. Gdy algorytm zostanie odpowiednio przeszkolony, możesz go uruchomić.
Przyjrzyjmy się teraz różnym algorytmom, których możesz użyć.
1. Regresja logistyczna
Regresja logistyczna jest algorytmem uczenia się nadzorowanego. Oblicza prawdopodobieństwo wystąpienia oszustwa w skali binarnej – oszustwa lub braku oszustwa – na podstawie parametrów modelu.
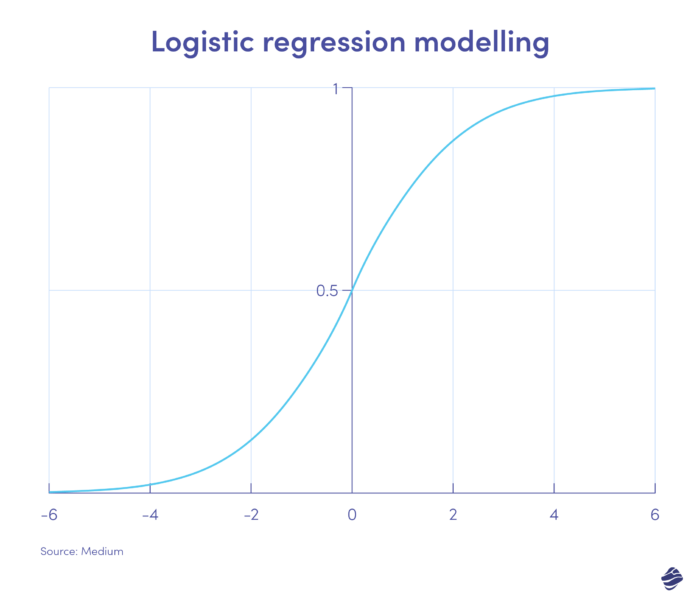
Transakcje, które znajdują się po dodatniej stronie wykresu, są najprawdopodobniej fałszywe, natomiast te po stronie ujemnej są najprawdopodobniej uzasadnione.
2. Drzewo decyzyjne
Drzewo decyzyjne jest algorytmem uczenia się nadzorowanego, ale wykracza poza algorytmy regresji logistycznej. Jest to hierarchiczna struktura decyzyjna, która analizuje dane na poziomach w celu ustalenia, czy transakcja jest prawdziwa, czy oszukańcza.
Poniżej znajduje się ilustracja drzewa decyzyjnego służącego do wykrywania oszustw związanych z kartami kredytowymi.
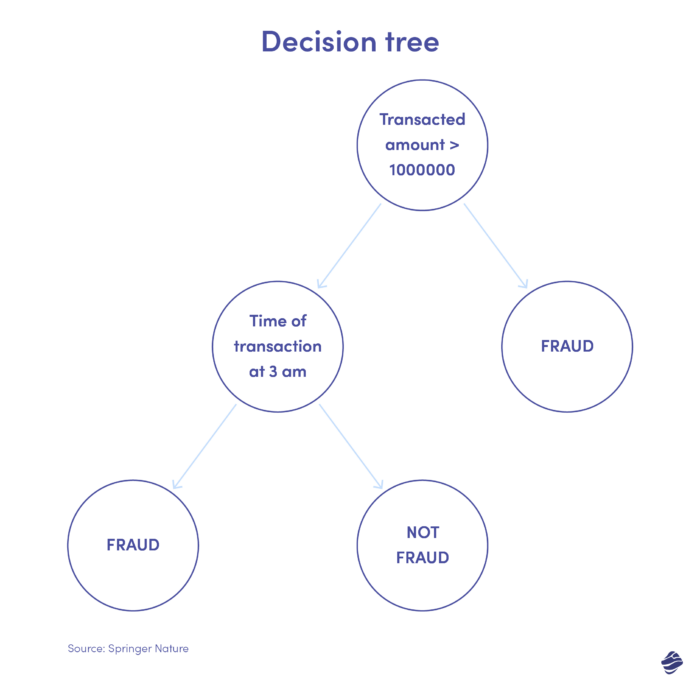
Warunkiem uznania transakcji za oszukańczą jest kwota transakcji. Jeśli wartość transakcji przekroczy ustalony próg, algorytm uzna ją za fałszywą. Jeśli nie, drzewo sprawdza inny warunek – czas transakcji. Jeśli moment jest nietypowy (tutaj jest godzina 3 w nocy), prawdopodobnie mamy do czynienia z oszustwem. Jeśli nie, sprawdza inny warunek. To idzie.
3. Losowy las
Losowy las to kombinacja wielu drzew decyzyjnych, przy czym każde drzewo decyzyjne sprawdza różne warunki – tożsamość, lokalizację itp.
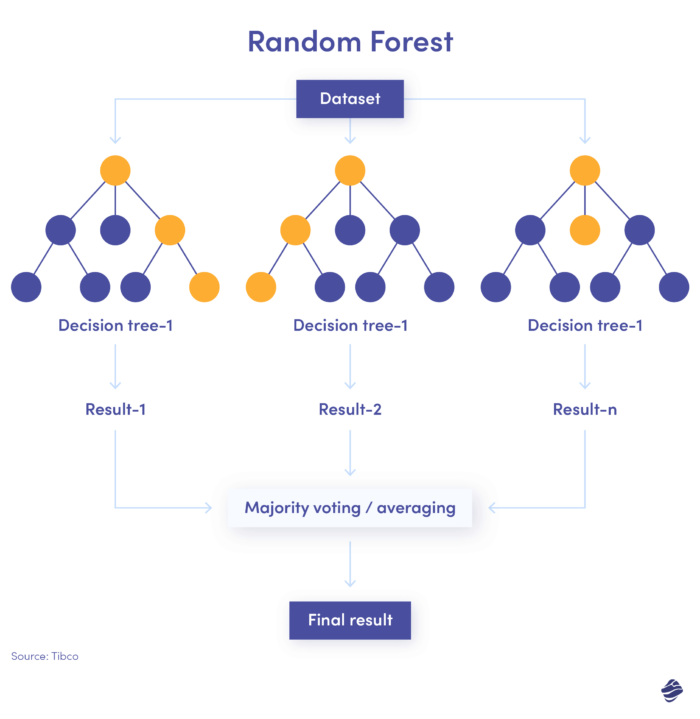
Po sprawdzeniu wszystkich parametrów każde poddrzewo oferuje decyzję. Łączna suma określa, czy transakcja jest prawdziwa, czy oszukańcza.
4. Sieci neuronowe
Sieci neuronowe to złożone algorytmy nienadzorowane. Zainspirowane ludzkim mózgiem sieci neuronowe przetwarzają dane w wielu warstwach, aby wyodrębnić funkcje wysokiego poziomu. Algorytm ten idzie w parze z głębokim uczeniem, które potrafi rozpoznawać wzorce w obrazach, tekście, dźwięku i innych danych.

Oto uproszczona wersja sieci neuronowej.
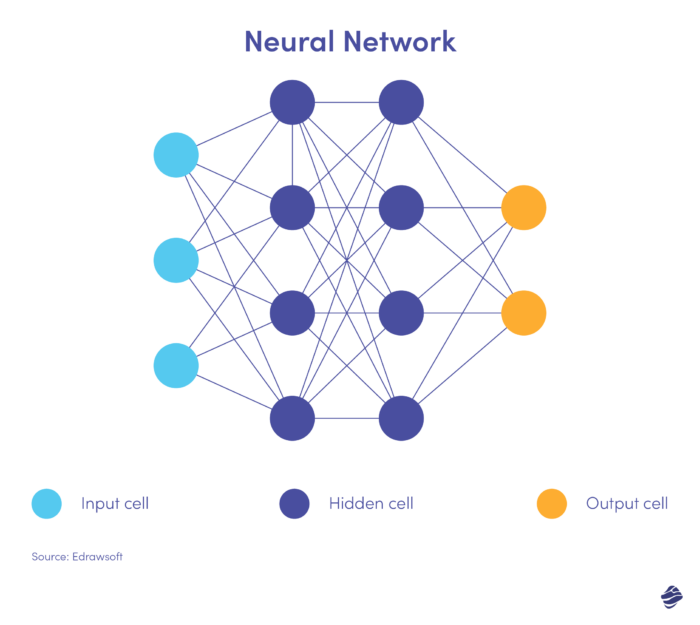
Sieć neuronowa składa się z trzech warstw: wejściowej, ukrytej i wyjściowej. Warstwa wejściowa przetwarza dane, warstwa ukryta analizuje dane z warstwy wejściowej w celu zidentyfikowania ukrytych wzorców, a warstwa wyjściowa klasyfikuje dane.
Głębokie sieci neuronowe mają kilka ukrytych warstw. Świetnie nadają się do identyfikowania zależności nieliniowych i wykrywania niespotykanych dotąd scenariuszy oszustw.
5. Maszyna wektorów nośnych
Maszyny wektorów nośnych (SVM) to nadzorowane algorytmy uczenia się, które przewidują, klasyfikują i wykrywają wartości odstające.
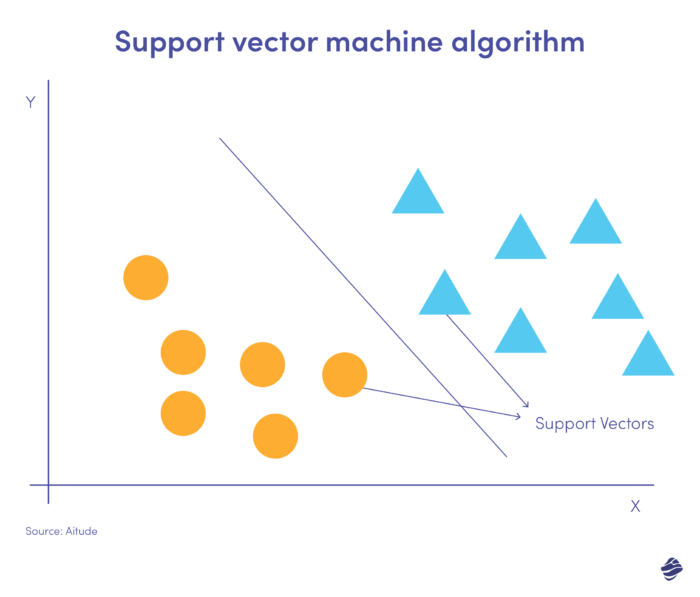
Ta liniowa ilustracja SVM przedstawia dwa zestawy danych oddzielone linią prostą zwaną hiperpłaszczyzną. To granica decyzyjna klasyfikuje dane jako stanowiące oszustwo lub niebędące oszustwem.
Punkty danych znajdujące się dalej od hiperpłaszczyzny można łatwo sklasyfikować. Wektory wsparcia (najbliżej hiperpłaszczyzny) są trudne do sklasyfikowania. Te wartości odstające mogą wpływać na położenie hiperpłaszczyzny, jeśli zostaną usunięte.
6. K-najbliższy sąsiad
K-najbliższy sąsiad (KNN) to algorytm uczenia się nadzorowanego. Opiera się na założeniu, że podobne elementy istnieją blisko siebie.
Poniżej prosta ilustracja.
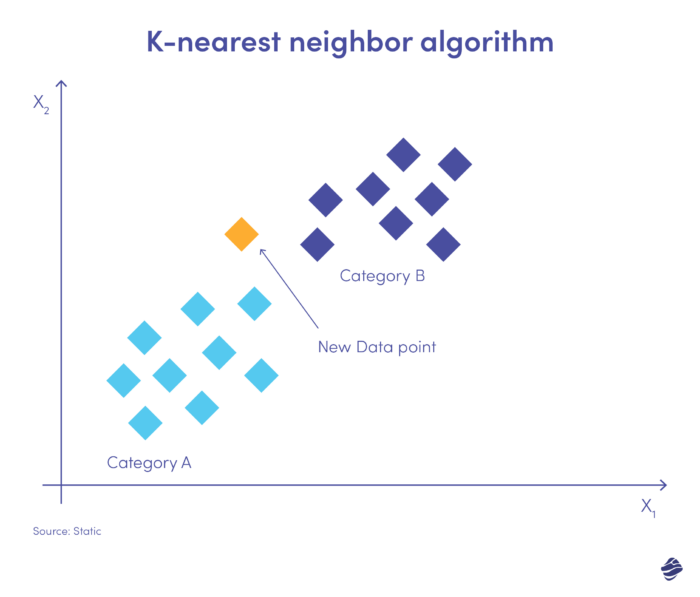
Nowy wpis danych należy umieścić w kategorii A lub B. Algorytm oblicza odległość między punktami danych za pomocą równania matematycznego zwanego odległością euklidesową. Nowy punkt danych należy do grupy z największą liczbą sąsiadów. Jeśli najbliższy zbiór danych jest oznaczony jako „oszustwo”, transakcja ta jest klasyfikowana jako oszukańcza.
Radzenie sobie z wyzwaniami i względami strategicznymi
Podobnie jak w przypadku wszystkich technologii, integracja uczenia maszynowego w celu wykrywania oszustw wiąże się z coraz większymi problemami. Oto kilka typowych wyzwań, przed którymi możesz stanąć.
Nieodpowiednia infrastruktura
Wiele systemów bankowych nie jest w stanie analizować dużych ilości złożonych danych. Co więcej, większość danych jest izolowana i przechowywana w oddzielnych magazynach.
Niestety, nie ma szybkiego rozwiązania tego problemu. Trzeba zainwestować w odpowiedni sprzęt i oprogramowanie.
Będziesz musiał nawiązać współpracę z doświadczoną agencją zajmującą się tworzeniem aplikacji Fintech i skonfigurować infrastrukturę, aby automatycznie wybierać odpowiednie algorytmy dla określonych zestawów danych, importować surowe dane i przygotowywać je do uczenia maszynowego, wizualizować dane, testować algorytm i nie tylko.
Jakość i bezpieczeństwo danych
Jakość danych jest istotną kwestią dla instytucji finansowych chcących wdrożyć uczenie maszynowe do wykrywania oszustw. Modele uczenia maszynowego nie rozróżniają dobrych i złych danych. Jeśli więc algorytm będzie zanieczyszczony nieistotnymi lub niekompletnymi danymi, dokładność modelu będzie niepoprawna.
Rozwiązania do pozyskiwania danych, takie jak Amazon Kinesis, gromadzą, oczyszczają i przekształcają surowe dane, dzięki czemu nadają się do modeli uczenia maszynowego. Po oczyszczeniu i uporządkowaniu danych należy oddzielić dane wrażliwe i niewrażliwe. Szyfruj poufne informacje i przechowuj je w zabezpieczonych obiektach. Należy także ograniczyć dostęp do tych danych.
Brak talentu
Pomimo tego, czego ludzie się boją, uczenie maszynowe nie kradnie miejsc pracy. Jest zupełnie odwrotnie. Nadal potrzebujemy analityków ds. oszustw do zarządzania złożonymi przypadkami, które wymagają ludzkiej wiedzy i doświadczenia. Ponadto uczenie maszynowe to nowa technologia i nie ma wystarczającej liczby ekspertów w tej dziedzinie.
To dobra wiadomość dla osób poszukujących pracy, ale nie dla instytucji, które nie potrafią w pełni wykorzystać potencjału uczenia maszynowego. Możesz pokonać tę przeszkodę, współpracując z firmami posiadającymi umiejętności umożliwiające wdrażanie uczenia maszynowego.
Studia przypadków wykrywania oszustw w bankowości z wykorzystaniem uczenia maszynowego
Przyjrzyjmy się teraz realnym przykładom wykrywania oszustw w bankowości za pomocą uczenia maszynowego.
Wykrywanie oszustw
Danske Bank to duńska międzynarodowa korporacja finansowa. Jest największym bankiem w Danii i wiodącym bankiem detalicznym w Europie Północnej. W ramach systemu wykrywania opartego na regułach bank miał trudności z ograniczeniem oszustw. Miał współczynnik wykrywania oszustw na poziomie 40% i współczynnik fałszywych alarmów na poziomie 99,5%.
Współpracując z Teradata, firmą zajmującą się oprogramowaniem do przetwarzania danych, Danske zintegrował oprogramowanie do głębokiego uczenia się, aby pomóc zidentyfikować potencjalne oszukańcze działania. W rezultacie uzyskano 60% zmniejszenie liczby wyników fałszywie dodatnich i wzrost liczby wyników fałszywie dodatnich o 50%.
Przeciwdziałanie praniu pieniędzy
OakNorth to komercyjny bank pożyczkowy w Wielkiej Brytanii, świadczący usługi finansowe dla przedsiębiorstw i osób fizycznych na rzecz przedsiębiorstw skalujących się. Bank miał niejednolity proces kontroli, obejmujący jednego dostawcę kontroli przeciwdziałających praniu pieniędzy, a drugiego obsługującego klientów. Co więcej, kontrole osób zajmujących eksponowane stanowiska polityczne (PEP) przyniosły wiele fałszywych wyników pozytywnych.
Współpracując z ComplyAdvantage, firmą zajmującą się wykrywaniem oszustw i przeciwdziałania praniu pieniędzy, bank zintegrował rozwiązanie do sprawdzania i ciągłego monitorowania, aby usprawnić przestrzeganie przepisów i skonsolidować dane. Umożliwiło to szybki transfer danych pomiędzy działalnością kredytową i oszczędnościową banku.
Ubezpieczenie kredytu
Hawaii USA Credit Union to największa kasa pożyczkowa na Hawajach i jedna z najlepszych kas pożyczkowych według magazynu Forbes. Chciała być konkurencyjna wobec firm Fintech i rozwijać swój portfel pożyczek osobistych bez zwiększania ryzyka.
Współpracując z Zest AI, kasa zautomatyzowała procesy decyzyjne, korzystając z modelu pożyczek osobistych opartego na sztucznej inteligencji. W modelu wykorzystano 278 zmiennych, aby zapewnić głębsze informacje niż system punktacji kredytowej VantageScore. Rezultatem był 21% wzrost wskaźnika zatwierdzeń i 0% wskaźnika oszustw związanych z niewykonaniem zobowiązania/wnioskami o pożyczkę.
Kluczowe kwestie do rozważenia podczas korzystania z ML do wykrywania oszustw
Chociaż wykrywanie oszustw w bankowości za pomocą uczenia maszynowego jest skuteczne, jest również zniechęcające. Systemy te wymagają dużej ilości dokładnych danych, w przeciwnym razie modele nie działają tak dobrze, jak powinny.
Oto kilka wskazówek, jak zoptymalizować proces uczenia maszynowego.
1. Ogranicz liczbę zmiennych wejściowych
W całym artykule mówiliśmy, że więcej znaczy więcej. To samo dotyczy ilości danych. Jednak mniej znaczy więcej w przypadku liczby zmiennych umożliwiających wykrywanie oszustw.
Typowe cechy, które należy wziąć pod uwagę podczas badania oszustw, obejmują:
- adres IP
- Adres e-mail
- Adres wysyłki
- Średnia wartość zamówienia/transakcji
Zaletą mniejszej liczby funkcji jest krótszy czas uczenia algorytmu. Unikasz także problemów związanych z nakładaniem się lub nieistotnymi zbiorami danych.
2. Zapewnij zgodność z przepisami
Zapobieganie oszustwom jest jednym z elementów bezpieczeństwa danych. Drugim jest prywatność danych. W wielu krajach obowiązują przepisy regulujące sposób, w jaki instytucje mogą gromadzić, wykorzystywać i przechowywać dane klientów. Istnieje między innymi chińska ustawa o ochronie danych osobowych (PIPL), kalifornijska ustawa o ochronie prywatności konsumentów (CCPA) i ogólne rozporządzenie Unii Europejskiej o ochronie danych (RODO).
Przepisy te mają wpływ na dane wykorzystywane w uczeniu maszynowym. Podstawową zasadą większości przepisów dotyczących ochrony danych osobowych jest powiadomienie/zgoda. Musisz powiadomić i uzyskać zgodę na wykorzystanie danych klienta do celów innych niż żądania użytkownika, w tym danych do szkolenia algorytmów uczenia maszynowego.
Najprostszym sposobem zapewnienia zgodności ze standardami prywatności jest skorzystanie z usług partnerów technicznych wyposażonych w funkcje zgodne z przepisami. Na przykład powinieneś nawiązać współpracę z firmą zajmującą się tworzeniem aplikacji bankowych, która rozumie, jak zachować prywatność i bezpieczeństwo danych.
3. Ustaw rozsądny próg
Reguły wartości transakcji mają minimalne wymagania, aby wywołać odpowiedź typu „akceptuj” lub „odrzuć”. Chcesz progu, który równoważy bezpieczeństwo i wygodę użytkownika. Jeśli próg jest zbyt rygorystyczny, ryzykujesz zablokowaniem legalnych transakcji. Jeśli próg jest zbyt luźny, zwiększysz wskaźnik udanych oszustw.
Oblicz swój apetyt na ryzyko, aby znaleźć właściwą równowagę. Poziomy ryzyka różnią się dla każdej instytucji finansowej lub produktu. Na przykład oferta banków udzielających mikrokredytów może ustalić wysoki próg dla kredytów o niskiej wartości. Bank komercyjny nie może być tak hojny w udzielaniu kredytów hipotecznych.
Przewidywanie przyszłości
Przyszłość jest teraz, ale tylko 17% organizacji wykorzystuje uczenie maszynowe w programach zwalczania nadużyć finansowych. Nie pozostawaj w tyle.
Oto kilka przełomowych rozwiązań, których możesz się spodziewać w zakresie bezpieczeństwa swojego banku dzięki uczeniu maszynowemu.
- Profilowanie urządzeń : identyfikacja różnych urządzeń łączących się z siecią bankową, analizowanie funkcji i zachowań każdego urządzenia.
- Zautomatyzowane wykrywanie i reagowanie na anomalie : identyfikuj oszukańcze zachowania znanych urządzeń i izoluj systemy, których to dotyczy.
- Wykrywanie dnia zerowego : identyfikacja nieznanych wcześniej luk w zabezpieczeniach i złośliwego oprogramowania w celu ochrony organizacji przed cyberatakami.
- Maskowanie danych : automatycznie wykrywa i anonimizuje poufne dane.
- Skalowane statystyki : identyfikacja trendów w oszustwach na wielu urządzeniach i w wielu lokalizacjach.
- Innowacyjna polityka : wykorzystaj wiedzę z zakresu uczenia maszynowego do opracowania odpowiednich polityk bezpieczeństwa.
Niezależnie od tego, czy reprezentujesz instytucję zarządzającą majątkiem, czy kasę kredytową, sztuczna inteligencja i uczenie maszynowe oferują ogromne możliwości wykrywania oszustw.
Należy jednak pamiętać, że hakerzy wykorzystują te technologie również do obchodzenia środków ochronnych. Zaktualizuj swoje modele uczenia maszynowego, aby wyprzedzić te ataki. Możesz także wzmocnić swoje bezpieczeństwo oparte na sztucznej inteligencji, korzystając ze starej, dobrej ludzkiej inteligencji.