
Wprowadzenie do robota sieciowego
Opublikowany: 2016-03-08Kiedy rozmawiam z ludźmi o tym, co robię i czym jest SEO, zwykle rozumieją to dość szybko lub zachowują się tak, jak robią. Dobra struktura strony, dobra treść, dobre linki zwrotne. Ale czasami robi się trochę bardziej techniczny i kończy się na tym, że mówię o wyszukiwarkach indeksujących Twoją witrynę i zwykle je gubię…
Po co indeksować witrynę ?
Indeksowanie sieci zaczęło się od mapowania Internetu i sposobu, w jaki każda witryna była ze sobą połączona. Był również używany przez wyszukiwarki w celu odkrywania i indeksowania nowych stron internetowych. Roboty indeksujące były również wykorzystywane do testowania podatności witryny internetowej, testując witrynę i analizując, czy wykryto jakiś problem.
Teraz możesz znaleźć narzędzia, które indeksują Twoją witrynę, aby dostarczać Ci wglądu. Na przykład OnCrawl zapewnia dane dotyczące treści i SEO na stronie lub Majestic, które zapewniają wgląd w wszystkie linki prowadzące do strony.
Roboty indeksujące służą do zbierania informacji, które następnie mogą być wykorzystywane i przetwarzane w celu klasyfikowania dokumentów i zapewniania wglądu w gromadzone dane.
Budowanie robota jest dostępne dla każdego, kto zna trochę kodu. Stworzenie wydajnego robota jest jednak trudniejsze i wymaga czasu.
Jak to działa ?
Aby zaindeksować witrynę lub sieć, najpierw potrzebujesz punktu wejścia. Roboty muszą wiedzieć, że Twoja witryna istnieje, aby mogły przyjść i rzucić na nią okiem. W dawnych czasach przesyłałeś swoją witrynę do wyszukiwarek, aby poinformować ich, że Twoja witryna jest online. Teraz możesz łatwo zbudować kilka linków do swojej witryny i Voila jesteś w pętli!
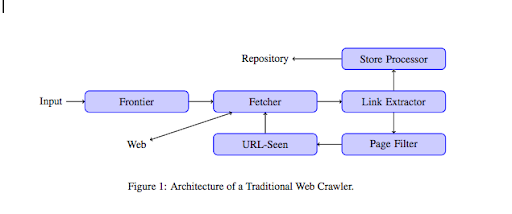
Gdy robot wyląduje na Twojej stronie, analizuje całą zawartość linijka po linijce i podąża za każdym z posiadanych linków, niezależnie od tego, czy są one wewnętrzne, czy zewnętrzne. I tak dalej, aż wyląduje na stronie, na której nie ma już linków lub jeśli napotka błędy, takie jak 404, 403, 500, 503.
Z bardziej technicznego punktu widzenia robot indeksujący działa z nasionami (lub listą) adresów URL. Jest to przekazywane do modułu pobierania, który pobierze zawartość strony. Ta zawartość jest następnie przenoszona do ekstraktora linków, który przeanalizuje kod HTML i wyodrębni wszystkie linki. Łącza te są wysyłane zarówno do procesora Sklepu, który, jak sama nazwa wskazuje, będzie je przechowywać. Te adresy URL przejdą również przez filtr strony, który wyśle wszystkie interesujące linki do modułu, który widzi URL. Ten moduł wykrywa, czy adres URL był już widziany, czy nie. Jeśli nie, zostanie wysłany do modułu pobierania, który pobierze zawartość strony i tak dalej.
Pamiętaj, że niektóre treści, takie jak Flash, są niemożliwe do przeszukania przez pająki. JavaScript jest teraz poprawnie indeksowany przez GoogleBota, ale od czasu do czasu nie indeksuje żadnego z nich. Obrazy nie są treścią, którą Google może technicznie zaindeksować, ale stało się na tyle sprytne, by zacząć je rozumieć !
Jeśli robotom nie powiedziano inaczej, będą czołgać się wszystko. Tutaj bardzo przydatny staje się plik robots.txt. Informuje roboty indeksujące (może to być określone dla każdego robota, np. GoogleBot lub MSN Bot – dowiedz się więcej o robotach tutaj), których stron nie mogą zaindeksować. Załóżmy na przykład, że masz nawigację za pomocą aspektów, możesz nie chcieć, aby roboty indeksowały je wszystkie, ponieważ mają one niewielką wartość dodaną i będą wykorzystywać budżet indeksowania. Użycie tej prostej linii pomoże Ci zapobiec indeksowaniu go przez robota
Agent użytkownika: *
Nie zezwalaj: /folder-a/
To mówi wszystkim robotom, aby nie indeksowały folderu A.
Klient użytkownika: GoogleBot
Disallow: /repertuar-b/
To z drugiej strony oznacza, że tylko Google Bot nie może indeksować folderu B.
Możesz również użyć oznaczenia w HTML, które mówi robotom, aby nie podążały za konkretnym linkiem za pomocą tagu rel=”nofollow”. Niektóre testy wykazały, że nawet użycie tagu rel="nofollow" na łączu nie zablokuje Googlebotowi obserwowania go. Jest to sprzeczne z jego przeznaczeniem, ale przyda się w innych przypadkach.
[Studium przypadku] Zwiększ widoczność, poprawiając indeksowanie witryny przez Googlebota
 Przeczytaj studium przypadku
Przeczytaj studium przypadku
Wspomniałeś o budżecie indeksowania, ale co to jest?
Załóżmy, że masz witrynę internetową wykrytą przez wyszukiwarki. Regularnie przychodzą, aby sprawdzić, czy dokonałeś jakichkolwiek aktualizacji w swojej witrynie i utworzyłeś nowe strony.
Każda witryna ma swój własny budżet indeksowania w zależności od kilku czynników, takich jak liczba stron w witrynie i jej rozsądek (jeśli na przykład zawiera dużo błędów). Możesz łatwo zorientować się w budżecie indeksowania, logując się do Search Console.
Budżet indeksowania ustala liczbę stron, które robot indeksuje w Twojej witrynie przy każdej wizycie. Jest proporcjonalnie powiązany z liczbą stron, które masz w witrynie i które zostały już zindeksowane. Niektóre strony są indeksowane częściej niż inne, zwłaszcza jeśli są regularnie aktualizowane lub jeśli są do nich linki z ważnych stron.
Na przykład twój dom jest twoim głównym punktem wejścia, który będzie bardzo często indeksowany. Jeśli masz bloga lub stronę kategorii, będą one często indeksowane, jeśli są połączone z główną nawigacją. Blog będzie również często indeksowany, ponieważ jest regularnie aktualizowany. Post na blogu może być często indeksowany po pierwszym opublikowaniu, ale po kilku miesiącach prawdopodobnie nie zostanie zaktualizowany.
Im częściej strona jest indeksowana, tym ważniejsze jest dla robota, że jest ważna w porównaniu z innymi. To wtedy musisz zacząć pracować nad optymalizacją budżetu indeksowania.
Optymalizacja budżetu indeksowania
Aby zoptymalizować budżet i upewnić się, że najważniejsze strony przyciągają uwagę, na jaką zasługują, możesz przeanalizować logi serwera i sprawdzić, jak Twoja witryna jest indeksowana:
- Jak często indeksowane są Twoje najpopularniejsze strony
- Czy widzisz, że mniej ważne strony są indeksowane bardziej niż inne, ważniejsze?
- Czy roboty często otrzymują błąd 4xx lub 5xx podczas indeksowania Twojej witryny?
- Czy roboty napotykają pułapki na pająki? (Matthew Henry napisał o nich świetny artykuł)
Analizując swoje dzienniki, zobaczysz, które strony, które uważasz za mniej ważne, są często indeksowane. Następnie musisz głębiej zagłębić się w swoją wewnętrzną strukturę linków. Jeśli jest indeksowany, musi mieć wiele linków do niego prowadzących.
Możesz także pracować nad naprawą wszystkich tych błędów (4xx i 5xx) za pomocą OnCrawl. Poprawi to indeksowanie, a także wrażenia użytkownika, jest to przypadek, w którym nie ma przegranych.
Indeksowanie VS Skrobanie?
Pełzanie i skrobanie to dwie różne rzeczy, które są używane do różnych celów. Indeksowanie witryny polega na wylądowaniu na stronie i podążaniu za linkami znalezionymi podczas skanowania treści. Robot przejdzie następnie na inną stronę i tak dalej.
Z drugiej strony Scraping to skanowanie strony i zbieranie ze strony określonych danych: tagu tytułu, metaopisu, tagu h1 lub konkretnego obszaru witryny, np. cennika. Skrobaki zwykle zachowują się jak „ludzie”, ignorują wszelkie reguły z pliku robots.txt, umieszczają w formularzach i używają klienta przeglądarki, aby nie zostać wykrytym.
Roboty wyszukiwarek zwykle działają jako scrapery, a także muszą zbierać dane w celu przetworzenia ich na potrzeby algorytmu rankingu. Nie szukają konkretnych danych w porównaniu do scrappera, po prostu wykorzystują wszystkie dostępne dane na stronie, a nawet więcej (czas ładowania to coś, czego nie można uzyskać ze strony). Roboty wyszukiwarek zawsze będą identyfikować się jako roboty, aby właściciel witryny mógł wiedzieć, kiedy ostatni raz odwiedził ich witrynę. Może to być bardzo pomocne podczas śledzenia rzeczywistej aktywności użytkowników.
Więc teraz wiesz trochę więcej o indeksowaniu, jak to działa i dlaczego jest to ważne, następnym krokiem jest rozpoczęcie analizy logów serwera. Zapewni to dogłębny wgląd w to, w jaki sposób roboty wchodzą w interakcję z Twoją witryną, które strony często odwiedzają i ile błędów napotykają podczas odwiedzania Twojej witryny.
Więcej technicznych i historycznych informacji na temat robota internetowego można znaleźć w „Krótkiej historii robotów indeksujących sieci”.