
Jak prognozować przychody z ruchu organicznego niezwiązanego z marką na podstawie pozycji adresu URL za pomocą Pythona?
Opublikowany: 2022-05-24Co to jest prognozowanie SEO?
Prognozowanie SEO lub szacowanie ruchu organicznego to proces wykorzystujący dane z własnej witryny lub dane stron trzecich do oszacowania przyszłego ruchu organicznego w witrynie, przychodów z SEO i zwrotu z inwestycji w SEO. To oszacowanie można obliczyć przy użyciu wielu różnych metod na podstawie naszych danych.
W tym samouczku chcemy przewidzieć nasze przychody organiczne niemarkowe i ruch organiczny niemarkowy na podstawie pozycji naszych adresów URL i ich bieżących przychodów. Może to pomóc nam, jako SEO, uzyskać większe poparcie ze strony innych interesariuszy: od zwiększonego budżetu miesięcznego, kwartalnego lub rocznego po więcej roboczogodzin ze strony zespołu ds. produktu i programistów.
Pamiętaj, że ten samouczek dotyczy nie tylko ruchu organicznego niezwiązanego z marką; wprowadzając kilka zmian i znając Pythona, możesz go użyć do oszacowania ruchu na stronach docelowych.
W rezultacie możemy stworzyć Arkusz Google, taki jak na poniższym obrazku.
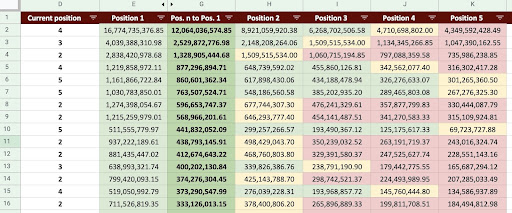
Obraz Arkuszy Google
Prognozowanie ruchu niemarkowego SEO
Pierwsze pytanie, które możesz zadać po przeczytaniu wstępu, brzmi: „Po co obliczać ruch organiczny niemarkowy?”.
Rozważmy firmę taką jak Amazon. Kiedy chcesz kupić książkę lub maskę, po prostu wpiszesz „kup maskę amazon”.
Marki są często na pierwszym miejscu, a kiedy chcesz coś kupić, wolisz kupować rzeczy, których potrzebujesz od tych firm. W każdej branży istnieją markowe firmy, które wpływają na zachowanie użytkowników w wyszukiwarkach Google.
Gdybyśmy mieli sprawdzić dane Google Search Console (GSC) firmy Amazon, prawdopodobnie odkrylibyśmy, że otrzymuje ona duży ruch z zapytań związanych z marką, a w większości przypadków pierwszym wynikiem zapytań związanych z marką jest witryna tej marki.
Jako SEO, tak jak ja, prawdopodobnie słyszałeś wiele razy, że „Tylko nasza marka pomaga naszemu SEO!” Jak możemy powiedzieć „Nie, tak nie jest” i pokazać ruch i przychody z zapytań niezwiązanych z marką?
Udowodnienie tego jest jeszcze bardziej skomplikowane, ponieważ wiemy, że algorytmy Google są tak złożone i trudno jest wyraźnie oddzielić wyszukiwania markowe od niemarkowych. Ale to właśnie sprawia, że to, co robimy jako SEO, jest jeszcze ważniejsze.
W tym samouczku pokażę Ci, jak odróżnić te dwie rzeczy – markowe i niemarkowe – i pokażę, jak potężne może być SEO.
Nawet jeśli Twoja firma nie jest markowa, nadal możesz wiele zyskać z tego artykułu: możesz dowiedzieć się, jak oszacować dane organiczne swojej witryny.
SEO ROI na podstawie szacowania ruchu
Bez względu na to, gdzie jesteś i co robisz, zasoby są ograniczone; czy to budżet, czy po prostu liczba godzin w dniu pracy. Wiedza o tym, jak najlepiej alokować swoje zasoby, odgrywa główną rolę w ogólnym zwrocie z inwestycji (ROI) i SEO.
Dyrektor ds. marketingu, wiceprezes ds. marketingu lub specjalista ds. marketingu wydajności mają różne KPI i wymagają różnych zasobów, aby osiągnąć swoje cele. Najlepszym sposobem, aby upewnić się, że otrzymasz to, czego potrzebujesz, jest udowodnienie jej konieczności poprzez wykazanie zwrotów, jakie przyniesie firmie. SEO ROI nie różni się. Kiedy nadejdzie pora alokacji budżetu w roku, a Twój zespół chce poprosić o większy budżet, oszacowanie ROI SEO może dać Ci przewagę w negocjacjach. Po obliczeniu oszacowania ruchu niezwiązanego z marką możesz lepiej ocenić budżet potrzebny do osiągnięcia pożądanych wyników.
Wpływ przewidywania SEO na strategię SEO
Jak wiemy, co 3 lub 6 miesięcy dokonujemy przeglądu naszej strategii SEO i dostosowujemy ją, aby uzyskać jak najlepsze wyniki. Ale co się dzieje, gdy nie wiesz, gdzie Twoja firma ma największy zysk? Możesz podejmować decyzje, ale nie będą one tak skuteczne, jak decyzje podejmowane, gdy masz pełniejszy obraz ruchu w witrynie.
Szacowanie przychodów z ruchu organicznego niezwiązanego z marką można połączyć z segmentacją stron docelowych i zapytań, aby zapewnić pełny obraz, który pomoże Ci opracować lepsze strategie jako menedżer SEO lub strateg SEO.
Różne sposoby prognozowania ruchu organicznego
W społeczności SEO istnieje wiele różnych metod i publicznych skryptów służących do przewidywania przyszłego ruchu organicznego.
Niektóre z tych metod obejmują:
- Prognozowanie ruchu organicznego w całej witrynie
- Prognozowanie ruchu organicznego na określonych stronach (blog, produkty, kategorie itp.) lub na pojedynczej stronie
- Prognozowanie ruchu organicznego dla konkretnych zapytań (zapytania zawierają „kup”, „jak to zrobić” itp.) lub zapytanie
- Prognozowanie ruchu organicznego w określonych okresach (szczególnie w przypadku wydarzeń sezonowych)
Moja metoda dotyczy określonych stron, a ramy czasowe to jeden miesiąc.
[Studium przypadku] Zwiększanie wzrostu na nowych rynkach dzięki SEO na stronie
 Przeczytaj studium przypadku
Przeczytaj studium przypadkuJak obliczyć przychody z ruchu organicznego
Dokładny sposób opiera się na danych Google Analytics (GA). Jeśli Twoja witryna jest zupełnie nowa, będziesz musiał użyć narzędzi innych firm. Wolę unikać korzystania z takich narzędzi, gdy masz własne dane.
Pamiętaj, że będziesz musiał przetestować dane stron trzecich, których używasz, z niektórymi prawdziwymi danymi strony, aby znaleźć ewentualne błędy w ich danych.
Jak obliczyć przychody z ruchu SEO niepowiązanego z marką za pomocą Pythona?
Do tej pory omówiliśmy wiele teoretycznych koncepcji, które powinniśmy znać, aby lepiej zrozumieć różne aspekty naszego ruchu organicznego i prognoz przychodów. Teraz zagłębimy się w praktyczną część tego artykułu.
Najpierw zaczniemy od obliczenia naszej krzywej CTR. W moim artykule dotyczącym krzywej CTR na Oncrawl wyjaśniam dwie różne metody, a także inne metody, z których możesz skorzystać, wprowadzając kilka zmian w moim kodzie. Polecam najpierw przeczytać artykuł o krzywej kliknięcia; daje wgląd w ten artykuł.
W tym artykule dostosowuję niektóre części mojego kodu, aby uzyskać konkretne wyniki, jakich oczekujemy w szacowaniu ruchu. Następnie pobierzemy nasze dane z GA i użyjemy wymiaru przychodów GA, aby oszacować nasze przychody.
Prognozowanie przychodów z ruchu organicznego niezwiązanego z marką za pomocą Pythona: Pierwsze kroki
Możesz uruchomić ten kod samodzielnie, bez znajomości Pythona. Wolę jednak, abyś wiedział trochę o składni Pythona i podstawową wiedzę na temat bibliotek Pythona, których użyję w tym kodzie prognozującym. Pomoże Ci to lepiej zrozumieć mój kod i dostosować go w sposób, który będzie dla Ciebie przydatny.
Aby uruchomić ten kod, użyję Visual Studio Code z rozszerzeniem Python firmy Microsoft, które zawiera rozszerzenie „Jupyter”. Ale możesz użyć samego notatnika Jupyter.
Do całego procesu musimy użyć tych bibliotek Pythona:
- Numpy
- Pandy
- Działka
Ponadto zaimportujemy kilka standardowych bibliotek Pythona:
- JSON
- drukuj
# Importowanie bibliotek potrzebnych do naszego procesu importuj json z pprint import pprint importuj numer jako np importuj pandy jako PD importuj plotly.express jako px
Krok 1: Obliczanie względnej krzywej CTR (Względna krzywa kliknięcia)
W pierwszym kroku chcemy obliczyć naszą względną krzywą CTR. Ale jaka jest względna krzywa CTR?
Jaka jest względna krzywa CTR?
Zacznijmy najpierw od „bezwzględnej krzywej CTR”. Kiedy obliczamy bezwzględną krzywą CTR, mówimy, że mediana CTR (lub średni CTR) pierwszej pozycji wynosi 36%, a drugiej pozycji 20% i tak dalej.
Na względnej krzywej CTR, moment procentowy, dzielimy medianę każdej pozycji przez CTR pierwszej pozycji. Na przykład względna krzywa CTR pierwszej pozycji będzie wynosić 0,36 / 0,36 = 1, druga będzie wynosić 0,20 / 0,36 = 0,55 i tak dalej.
Może zastanawiasz się, dlaczego warto to obliczyć? Pomyśl o stronie w rankingu na pierwszej pozycji, która ma 44% CTR. Jeśli ta strona przejdzie na drugą pozycję, krzywa CTR nie spadnie do 20%, bardziej prawdopodobne jest, że CTR spadnie do 44% * 0,55 = 24,2%.
1. Uzyskiwanie markowych i niemarkowych danych o ruchu organicznym z GSC
Do naszego procesu obliczeniowego musimy uzyskać nasze dane z GSC. Za pierwszym razem wszystkie dane będą oparte na zapytaniach związanych z marką, a następnym razem wszystkie dane będą oparte na zapytaniach niemarkowych.
Aby uzyskać te dane, możesz skorzystać z różnych metod: ze skryptów Pythona lub z dodatku Arkuszy Google „Search Analytics for Sheets”. Użyję eksploratora API GSC.
Wynikiem tych danych są dwa pliki JSON, które pokazują wydajność każdej strony. Jeden plik JSON, który pokazuje skuteczność stron docelowych na podstawie zapytań związanych z marką, a drugi pokazuje skuteczność stron docelowych na podstawie zapytań niezwiązanych z marką.
Aby uzyskać dane z eksploratora GSC API, wykonaj następujące kroki:
- Przejdź do https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
- Zmaksymalizuj eksplorator interfejsu API, który znajduje się w prawym górnym rogu strony.
- W polu „
siteUrl” wpisz nazwę swojej domeny. Na przykład „https://www.example.com” lub „http://your-domain.com”. - W treści żądania najpierw musimy zdefiniować parametry „
startDate” i „endDate”. Preferuję ostatnie 30 dni. - Następnie dodajemy „
dimensions” i wybieramy „page” dla tej listy. - Teraz dodajemy „
dimensionFilterGroups”, aby filtrować nasze zapytania. Jeden raz dla markowych i drugi dla zapytań niezwiązanych z marką. - Na koniec ustawiliśmy nasz „
rowLimit” na 25 000. Jeśli strony Twojej witryny, które każdego miesiąca generują ruch organiczny, przekraczają 25 tys., musisz zmodyfikować treść żądania. - Po złożeniu każdego żądania zapisz odpowiedź JSON. W przypadku wydajności markowej zapisz plik JSON jako „
branded_data.json”, a w przypadku wydajności niezwiązanej z marką zapisz plik JSON jako „non_branded_data.json”.
Po zrozumieniu parametrów w treści naszego żądania jedyne, co musisz zrobić, to skopiować i wkleić poniżej treści żądania. Rozważ zastąpienie nazw marek „ brand variation names ”.
Musisz oddzielić nazwy marek za pomocą potoku lub „ | ”. Na przykład „ amazon|amazon.com|amazn ”.
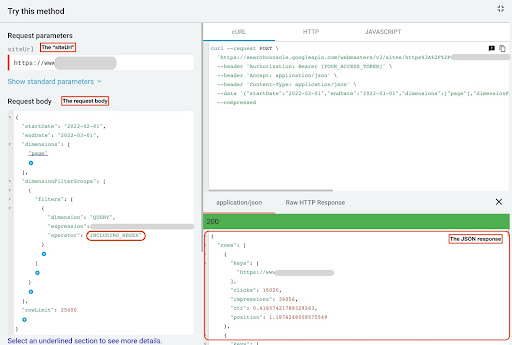
Eksplorator API GSC
Treść zapytania dotyczącego marki:
{
"DataRozpoczęcia": "2022-02-01",
"endDate": "2022-03-01",
"wymiary": [
"strona"
],
"Grupy Filtrów Wymiarów": [
{
"filtry": [
{
"wymiar": "ZAPYTANIE",
"expression": "nazwy odmian marki",
"operator": "INCLUDING_REGEX"
}
]
}
],
„Limit wiersza”: 25000
}
Treść żądania nieoznaczona marką:
{
"DataRozpoczęcia": "2022-02-01",
"endDate": "2022-03-01",
"wymiary": [
"strona"
],
"Grupy Filtrów Wymiarów": [
{
"filtry": [
{
"wymiar": "ZAPYTANIE",
"expression": "nazwy odmian marki",
"operator": "EXCLUDING_REGEX"
}
]
}
],
„Limit wiersza”: 25000
}
2. Importowanie danych do naszego notatnika Jupyter i wyodrębnianie katalogów witryn
Teraz musimy załadować nasze dane do naszego notatnika Jupyter, aby móc je modyfikować i wydobywać z nich to, czego chcemy. Zacznijmy od miejsca, w którym skończyliśmy powyżej.
Aby załadować markowe dane, musisz wykonać ten blok kodu:
# Tworzenie DataFrame dla wydajności adresów URL witryny w marce i markowych zapytaniach
z open(./branded_data.json") jako plik_json:
branded_data = json.loads(json_file.read())["wiersze"]
branded_df = pd.DataFrame(branded_data)
# Zmiana nazwy kolumny „klucze” na kolumnę „strona docelowa” i konwersja listy „strona docelowa” na adres URL
branded_df.rename(columns={"keys": "strona docelowa"}, inplace=True)
branded_df["strona docelowa"] = branded_df["strona docelowa"].apply(lambda x: x[0])
W przypadku stron docelowych nieoznaczonych marką musisz wykonać ten blok kodu:
# Tworzenie DataFrame dla wydajności adresów URL witryny w zapytaniach niemarkowych
z open("./non_branded_data.json") jako plik_json:
non_branded_data = json.loads(json_file.read())["wiersze"]
non_branded_df = pd.DataFrame(non_branded_data)
# Zmiana nazwy kolumny „klucze” na kolumnę „strona docelowa” i konwersja listy „strona docelowa” na adres URL
non_branded_df.rename(columns={"keys": "strona docelowa"}, inplace=True)
non_branded_df["strona docelowa"] = non_branded_df["strona docelowa"].apply(lambda x: x[0])
Ładujemy nasze dane, a następnie musimy zdefiniować nazwę naszej witryny, aby wyodrębnić jej katalogi.
# Definiowanie nazwy witryny między cudzysłowami. Na przykład „https://www.example.com/” lub „http://moja_domena.com/” SITE_NAME = "https://www.twoja_domena.com/"
Musimy tylko wyodrębnić katalogi z występu nieoznaczonego marką.
# Uzyskiwanie każdego katalogu stron docelowych (URL)
non_branded_df["katalog"] = non_branded_df["strona docelowa"].str.extract(
pat=f"((?<={SITE_NAME})[^/]+)"
)
Następnie drukujemy katalogi, aby wybrać, które z nich są ważne dla tego procesu. Możesz wybrać wszystkie katalogi, aby uzyskać lepszy wgląd w swoją witrynę.

# Aby uzyskać wszystkie katalogi w danych wyjściowych, musimy manipulować opcjami Pandy
pd.set_option("display.max_rows", Brak)
# Katalogi stron internetowych
non_branded_df["katalog"].value_counts()
Tutaj możesz wstawić dowolne katalogi, które są dla Ciebie ważne.
""" Wybierz, które katalogi są ważne dla uzyskania ich krzywej CTR.
Wstaw katalogi do zmiennej 'important_directories'.
Na przykład „produkt, tag, kategoria produktu, magazyn”. Oddziel wartości katalogu przecinkami.
"""
IMPORTANT_DIRECTORIES = "twoje_ważne_katalogi"
WAŻNE_KATALOGI = WAŻNE_KATALOGI.split(",")
3. Oznaczanie stron na podstawie ich pozycji i obliczanie względnej krzywej CTR
Teraz musimy oznaczyć nasze strony docelowe na podstawie ich pozycji. Robimy to, ponieważ musimy obliczyć względną krzywą CTR dla każdego katalogu na podstawie pozycji jego strony docelowej.
# Etykietowanie pozycji niemarkowych
dla i w zakresie (1, 11):
non_branded_df.loc[
(non_branded_df["pozycja"] >= i) & (non_branded_df["pozycja"] < i + 1),
"etykieta pozycji",
] = i
Następnie grupujemy strony docelowe na podstawie ich katalogu.
# Grupowanie stron docelowych na podstawie ich wartości „katalogu” non_brand_grouped_df = non_branded_df.groupby(["katalog"])
Zdefiniujmy funkcję do obliczania względnej krzywej CTR.
def each_dir_relative_ctr_curve(dir_df, klucz):
"""Funkcja oblicza każdą względem IMPORTANT_DIRECTORIES krzywą CTR.
"""
# Grupowanie „non_brand_grouped_df” na podstawie ich wartości „etykiety pozycji”
dir_grouped_df = dir_df.groupby(["etykieta pozycji"])
# Lista do zapisywania mediany CTR każdej pozycji
mediana_ctr_list = []
# Przechowywanie każdego katalogu jako klucza, a jego wartością jest "median_ctr_list"
directorys_median_ctr = {}
# Zapętlaj każdą grupę "dir_grouped_df"
dla i w zakresie (1, 11):
# Try-oprócz obsługi sytuacji, w których katalog na przykład nie zawiera żadnych danych dla pozycji 4
próbować:
tmp_df = dir_grouped_df.get_group(i)
median_ctr_list.append(np.median(tmp_df["ctr"]))
oprócz:
median_ctr_list.append(0)
# Obliczanie względnej krzywej CTR
katalogi_mediana_ctr[klucz] = np. tablica (mediana_lista_ctr) / np. tablica (
[median_ctr_list[0]] * 10
)
return directorys_median_ctr
Po zdefiniowaniu funkcji uruchamiamy ją.
# Zapętlenie katalogów i wykonanie funkcji 'each_dir_relative_ctr_curve'
directoryies_median_ctr_dict = dict()
dla klucza, pozycja w non_brand_grouped_df:
jeśli wpiszesz IMPORTANT_DIRECTORIES:
katalogi_median_ctr_dict.update(each_dir_relative_ctr_curve(element, klucz))
pprint(directories_median_ctr_dict)
Teraz załadujemy skuteczność naszych stron docelowych, markowych i niemarkowych, i obliczymy względną krzywą CTR dla naszych danych niezwiązanych z marką. Dlaczego robimy to tylko dla danych niezwiązanych z marką? Ponieważ chcemy przewidzieć ruch organiczny i przychody poza marką.
Krok 2: Przewidywanie przychodów z ruchu organicznego niezwiązanego z marką
W tym drugim kroku dowiemy się, jak pobrać nasze dane o przychodach i przewidzieć nasze przychody.
1. Scalanie markowych i niemarkowych danych organicznych
Teraz połączymy nasze markowe i niemarkowe dane. Pomoże nam to obliczyć odsetek ruchu organicznego niezwiązanego z marką na każdej stronie docelowej w porównaniu z całym ruchem.
# 'main_df' jest kombinacją 'całych danych witryny' i 'danych niezwiązanych z marką' DataFrames.
# Korzystając z tej ramki DataFrame, możesz dowiedzieć się, gdzie większość naszych kliknięć i wyświetleń
# pochodzą z zapytań, które nie są oznaczone marką.
main_df = non_branded_df.merge(
branded_df, on="strona docelowa", sufiksy=("_non_brand", "_branded")
)
Następnie modyfikujemy kolumny, aby usunąć niepotrzebne.
# Modyfikacja kolumn 'main_df' na te, których potrzebujemy
główny_df = główny_df[
[
"wstęp",
„clicks_non_brand”,
"ctr_non_brand",
"informator",
"etykieta pozycji",
"clicks_branded",
]
]
Teraz obliczmy odsetek kliknięć niezwiązanych z marką w stosunku do łącznej liczby kliknięć strony docelowej.
# Obliczanie odsetka kliknięć zapytań niemarkowych na podstawie stron docelowych do wszystkich kliknięć strony docelowej
main_df.loc[:, "clicks_non_brand_percentage"] = main_df.apply(
lambda x: x["clicks_non_brand"] / (x["clicks_non_brand"] + x["clicks_branded"]),
oś=1,
)
[Ebook] Automatyzacja SEO za pomocą Oncrawl
 Przeczytaj ebook
Przeczytaj ebook2. Ładowanie przychodów z ruchu organicznego
Podobnie jak w przypadku pobierania danych GSC, mamy wiele sposobów na uzyskanie danych GA: możemy użyć „dodatku Arkusze Google Analytics” lub interfejsu GA API. W tym samouczku wolę używać Google Data Studio (GDS) ze względu na jego prostotę.
Aby uzyskać dane GA z GDS, wykonaj następujące kroki:
- W GDS utwórz nowy raport lub eksplorator i tabelę.
- Do wymiaru dodaj „stronę docelową”, a do danych – „Przychody”.
- Następnie musisz utworzyć niestandardowy segment w GA na podstawie źródła i medium. Filtruj ruch „Google/organic”. Po utworzeniu segmentu dodaj go do sekcji segmentu w GDS.
- W ostatnim kroku wyeksportuj tabelę i zapisz ją jako „
landing_pages_revenue.csv”.
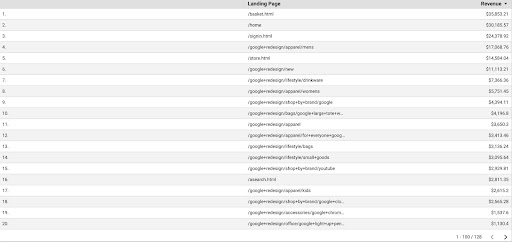
Przychody ze stron docelowych eksportu csv
Załadujmy nasze dane.
organic_revenue_df = pd.read_csv("./data/landing_pages_revenue.csv")
Teraz musimy dołączyć nazwę naszej witryny do adresów URL stron docelowych GA.
Kiedy eksportujemy nasze dane z GA, strony docelowe są w formie względnej, ale nasze dane GSC są w formie bezwzględnej.
Nie zapomnij sprawdzić danych stron docelowych GA. W zestawach danych, z którymi pracowałem, stwierdziłem, że dane GA wymagają za każdym razem trochę oczyszczenia.
# Łączenie adresów URL stron docelowych GA z SITE_NAME.
# Również zmiana nazw kolumn
organic_revenue_df.loc[:, "Strona docelowa"] = (
SITE_NAME[:-1] + organic_revenue_df[organic_revenue_df.columns[0]]
)
organic_revenue_df.rename(columns={"Strona docelowa": "strona docelowa", "Przychody": "przychody"}, inplace=True)
Teraz połączmy nasze dane GSC z danymi GA.
# W tym kroku łączę 'main_df' z 'dk_organic_revenue_df' DataFrame, która zawiera procent danych zapytań niezwiązanych z marką main_df = main_df.merge(organic_revenue_df, on="strona docelowa", how="lewo")
Na końcu tej sekcji robimy małe porządki w naszych kolumnach DataFrame.
# Trochę sprzątania DataFrame 'main_df'
główny_df = główny_df[
[
"wstęp",
„clicks_non_brand”,
"ctr_non_brand",
"informator",
"etykieta pozycji",
„clicks_non_brand_percentage”,
"przychód",
]
]
3. Obliczanie przychodów niemarkowych
W tej sekcji będziemy przetwarzać dane, aby wyodrębnić informacje, których szukamy.
Ale przede wszystkim przefiltrujmy nasze strony docelowe na podstawie „ IMPORTANT_DIRECTORIES ”:
# Usuwanie innych stron docelowych katalogów, nieuwzględnionych w „IMPORTANT_DIRECTORIES”
main_df = (
main_df[główny_df["katalog"].isin(WAŻNE_KATALOGI)]
.dropna(podzbiór=["przychody"])
.reset_index(drop=prawda)
)
Teraz obliczmy ruch przychodów organicznych nie związanych z marką.
Zdefiniowałem metrykę, której nie możemy łatwo obliczyć i jest bardziej intuicyjna niż cokolwiek innego, co prowadzi nas do przypisania jej liczby.
Wskaźnik „ brand_influence ” pokazuje siłę Twojej marki. Jeśli uważasz, że wyszukiwania niezwiązane z marką generują mniejszą sprzedaż w Twojej firmie, zmniejsz tę liczbę; na przykład coś takiego jak 0.8.
# Jeśli Twoja marka jest tak silna, że zapytania bez Twojej marki mogą sprzedać tyle samo, co zapytania z Twoją marką, to 1 jest dla Ciebie dobre.
# Pomyśl o szukaniu książki bez nazwy marki zawartej w zapytaniu. Czy kiedy widzisz Amazon, kupujesz na innych rynkach lub w sklepach?
wpływ_marki = 1
main_df.loc[:, "non_brand_revenue"] = main_df.apply(
lambda x: x["przychody"] * x["clicks_non_brand_percentage"] * brand_influence, oś=1
)
Narysujmy wykres kołowy, aby uzyskać wgląd w przychody niemarkowe na podstawie ważnych katalogów.
# W tej komórce chcę uzyskać wszystkie przychody ze stron docelowych niezwiązanych z marką na podstawie ich katalogu
non_branded_directory_dist_revenue_df = pd.tabela_przestawna (
main_df,
index="katalog",
wartości=["non_brand_revenue"],
aggfunc={"non_brand_revenue": "suma"},
)
pie_fig = px.pie(
non_branded_directory_dist_revenue_df,
wartości="non_brand_revenue",
name=non_branded_directory_dist_revenue_df.index,
title="Przychody niemarkowe na podstawie katalogów witryn",
)
pie_fig.update_traces(textposition="wewnątrz", textinfo="procent+etykieta")
pie_fig.pokaż()
Ten wykres przedstawia rozkład zapytań niezwiązanych z marką w Twoich IMPORTANT_DIRECTORIES .
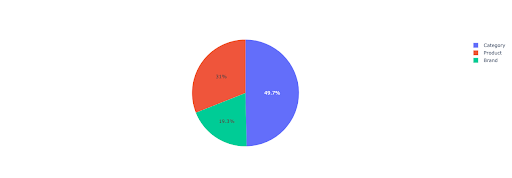
Dystrybucja zapytań niemarkowych
Na podstawie moich danych krzywej CTR widzę, że nie mogę polegać na CTR dla pozycji wyższych niż 5. Z tego powodu filtruję dane na podstawie pozycji.
Możesz zmodyfikować poniższy blok kodu na podstawie swoich danych.
# Ze względu na dokładność CTR w naszej krzywej CTR, myślę, że możemy pominąć lądowania z pozycją większą niż 5. Z tego powodu odfiltrowałem inne strony docelowe main_df = main_df[main_df["etykieta pozycji"] < 6].reset_index(drop=True)
4. Obliczanie „przychodu z kliknięcia” (RPC)
Tutaj stworzyłem niestandardową metrykę i nazwałem ją „Przychody z kliknięcia” lub RPC. Pokazuje nam to przychody wygenerowane przez każde kliknięcie niezwiązane z marką.
Możesz używać tej metryki na różne sposoby. Znalazłem stronę z wysokim RPC, ale niskimi kliknięciami. Kiedy sprawdziłem stronę, dowiedziałem się, że została zaindeksowana niecały tydzień temu i możemy użyć różnych metod optymalizacji strony.
# Obliczanie przychodów generowanych z każdego kliknięcia (RPC: Revenue Per Click)
main_df["rpc"] = main_df.apply(
lambda x: x["non_brand_revenue"] / x["clicks_non_brand"], oś=1
)
5. Przewidywanie przychodów!
Dochodzimy do końca, czekaliśmy do teraz z prognozą naszych przychodów organicznych niemarkowych.
Uruchommy ostatnie bloki kodu.
# Główna funkcja do obliczania przychodów na podstawie różnych pozycji
dla indeksu row_values w main_df.iterrows():
# Przełączanie między katalogami Lista CTR
ctr_curve = directorys_median_ctr_dict[row_values["katalog"]]
# Zapętlaj pozycje od 1 do 5 i obliczaj przychody na podstawie wzrostu lub spadku CTR
dla i w zakresie (1, 6):
if i == row_values["etykieta pozycji"]:
main_df.loc[indeks, i] = wartości_wierszów["przychody nie_markowe"]
w przeciwnym razie:
# main_df.loc[indeks, i + 1] ==
main_df.loc[indeks, i] = (
row_values["non_brand_revenue"]
* (krzywa_ctr[i - 1])
/ ctr_curve[int(row_values["etykieta pozycji"] - 1)]
)
# Obliczanie metryki „N do 1”. Pokazuje wzrost przychodów, gdy Twoja pozycja w rankingu zmieni się z „N” na „1”
main_df.loc[indeks, "N do 1"] = main_df.loc[indeks, 1] - main_df.loc[indeks, row_values["etykieta pozycji"]]
Patrząc na końcowy wynik, mamy nowe kolumny. Nazwy tych kolumn to „1”, „2”, „3”, „4”, „5”.
Co oznaczają te nazwy? Na przykład, mamy stronę na 3 pozycji i chcemy przewidzieć jej przychody, jeśli poprawi swoją pozycję, lub chcemy wiedzieć, ile stracimy, jeśli spadniemy w rankingu.
Kolumny „1” i „2” pokazują przychody strony, gdy średnia pozycja tej strony się poprawi, a kolumny „4” i „5” pokazują przychody tej strony, gdy spadniemy w rankingu.
Kolumna „3” w tym przykładzie pokazuje bieżące przychody ze strony.
Stworzyłem również metrykę o nazwie „N do 1”. Pokazuje, czy średnia pozycja tej strony zmieni się z „3” (lub N) na „1” i jak bardzo może to wpłynąć na przychody.
Zawijanie
Dużo omówiłem w tym artykule, a teraz twoja kolej, aby ubrudzić sobie ręce i przewidzieć przychody z ruchu organicznego niemarkowego.
To najprostszy sposób, w jaki możemy wykorzystać tę prognozę. Moglibyśmy uczynić ten algorytm bardziej złożonym i połączyć go z niektórymi modelami ML, ale to sprawiłoby, że artykuł byłby bardziej skomplikowany.
Wolę zapisać te dane w pliku CSV i przesłać je do Arkusza Google. Lub, jeśli planuję udostępnić go innym członkom mojego zespołu lub organizacji, otworzę go w programie Excel i sformatuję kolumny za pomocą kolorów, aby ułatwić czytanie.
Na podstawie tych danych możesz przewidzieć ROI z ruchu organicznego niezwiązanego z marką i wykorzystać go w procesie negocjacji.