
Aktualizacje Google Core: efekty, problemy i rozwiązania dla witryn YMYL
Opublikowany: 2019-12-04W tym studium przypadku przyjrzę się stronie Hangikredi.com, która jest jednym z największych finansowych i cyfrowych aktywów Turcji. Zobaczymy techniczne podtytuły SEO i trochę grafiki.
To studium przypadku zostało przedstawione w dwóch artykułach. Ten artykuł dotyczy aktualizacji Google Core z 12 marca, która miała silny negatywny wpływ na witrynę i tego, co zrobiliśmy, aby temu przeciwdziałać. Przyjrzymy się 13 problemom technicznym i rozwiązaniom, a także zagadnieniom holistycznym.
Przeczytaj drugą część, aby zobaczyć, jak zastosowałem naukę z tej aktualizacji, aby zostać zwycięzcą z każdej aktualizacji Google Core.
Problemy i rozwiązania: naprawianie skutków aktualizacji Google Core z 12 marca
Do 12 marca Aktualizacji Core Algorithm wszystko szło gładko w witrynie, w oparciu o dane analityczne. W ciągu jednego dnia, po opublikowaniu wiadomości o Aktualizacji Core Algorithm, nastąpił ogromny spadek rankingów i wielka frustracja w biurze. Osobiście nie widziałem tego dnia, ponieważ przybyłem dopiero, gdy zatrudnili mnie do rozpoczęcia nowego projektu i procesu SEO 14 dni później.
[Studium przypadku] Poprawa rankingów, wizyt organicznych i sprzedaży dzięki analizie plików dziennika
 Przeczytaj studium przypadku
Przeczytaj studium przypadkuRaport o uszkodzeniu witryny internetowej firmy po aktualizacji podstawowego algorytmu z 12 marca znajduje się poniżej:
- 36% strata sesji organicznych
- 65% Kliknij spadek
- 30% utrata CTR
- 33% organiczne straty użytkowników
- 100 000 utraconych wyświetleń dziennie.
- Utrata wyświetleń o 9,72%
- 8 000 utraconych słów kluczowych

Teraz, jak powiedzieliśmy na początku artykułu o studium przypadku, powinniśmy zadać jedno pytanie. Nie mogliśmy zapytać „Kiedy nastąpi kolejna aktualizacja Core Algorithm?” bo to już się stało. Pozostało tylko jedno pytanie.
„Jakie różne kryteria brało pod uwagę Google między mną a moim konkurentem?”
Jak widać na powyższym wykresie i w raporcie o szkodach, straciliśmy główny ruch i słowa kluczowe.
1. Problem: linkowanie wewnętrzne
Zauważyłem, że kiedy po raz pierwszy sprawdziłem liczbę linków wewnętrznych, tekst kotwicy i przepływ linków, mój konkurent wyprzedził mnie.
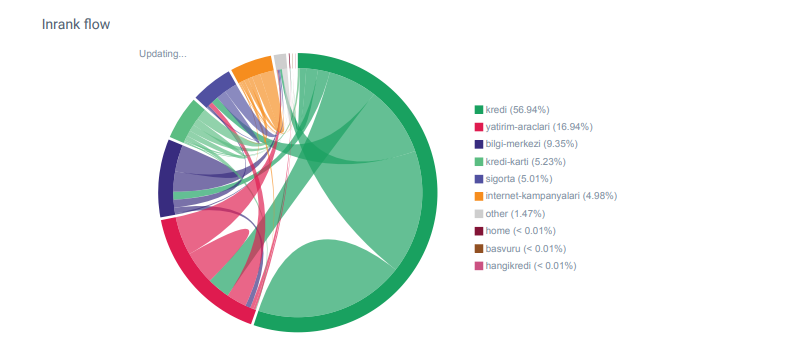
Raport Linkflow dla kategorii Hangikredi.com z OnCrawl
Mój główny konkurent ma ponad 340 000 linków wewnętrznych z tysiącami tekstów zakotwiczonych. W tamtych czasach nasza strona internetowa zawierała tylko 70 000 wewnętrznych linków bez wartościowych tekstów kotwic. Ponadto brak linków wewnętrznych wpłynął na budżet indeksowania i wydajność witryny internetowej. Mimo że 80% naszego ruchu pochodziło tylko z 20 stron produktów, 90% naszej witryny stanowiły strony przewodników z przydatnymi informacjami dla użytkowników. Większość naszych słów kluczowych i wyników trafności zapytań finansowych pochodzi z tych stron. Poza tym było zbyt wiele osieroconych stron.
Z powodu brakującej wewnętrznej struktury linków, kiedy wykonałem analizę logów w Kibanie, zauważyłem, że najczęściej indeksowane strony to te, które uzyskują najmniejszy ruch. Ponadto, kiedy sparowałem to z wewnętrzną siecią linków, odkryłem, że strony firmowe o najmniejszym ruchu (Prywatność, Pliki cookie, Bezpieczeństwo, Strony O nas) mają maksymalną liczbę linków wewnętrznych.
Jak omówię w następnej sekcji, spowodowało to, że Googlebot usunął czynnik linków wewnętrznych z Pagerank podczas indeksowania witryny, zdając sobie sprawę, że linki wewnętrzne nie zostały skonstruowane zgodnie z przeznaczeniem.
2. Problem: architektura witryny, wewnętrzny ranking stron, ruch i wydajność indeksowania
Zgodnie z oświadczeniem Google linki wewnętrzne i teksty zakotwiczeń pomagają Googlebotowi zrozumieć znaczenie i kontekst strony internetowej. Wewnętrzny PageRank lub Inrank jest obliczany na podstawie więcej niż jednego czynnika. Według Billa Sławskiego linki wewnętrzne i zewnętrzne nie są sobie równe. Wartość łącza dla przepływu Pagerank zmienia się w zależności od jego pozycji, rodzaju, stylu i grubości czcionki.

Jeśli Googlebot zrozumie, które strony są ważne dla Twojej witryny, będzie je częściej indeksować i indeksować szybciej. W tym przypadku ważnymi czynnikami są linki wewnętrzne i prawidłowy projekt drzewa witryny. Inni eksperci również komentowali tę korelację na przestrzeni lat:
„Większość linków zapewnia trochę dodatkowego kontekstu poprzez tekst kotwicy. Przynajmniej powinni, prawda?
–John Mueller, Google 2017„Jeśli masz strony, które uważasz za ważne w swojej witrynie , nie zakopuj ich 15 linków głęboko w witrynie i nie mówię o długości katalogu, mówię o rzeczywistej, musisz kliknąć 15 linków, aby znaleźć tę stronę jeśli istnieje strona, która jest ważna lub ma świetne marże zysku lub naprawdę konwersje, eskaluj, aby umieścić link do tej strony ze strony głównej , to jest to coś, co może mieć sens”.
–Matt Cutts, Google 2011„Jeśli jedna strona łączy się z inną ze słowem „kontakt” lub słowem „o”, a strona, do której prowadzi łącze, zawiera adres, ta lokalizacja adresu może zostać uznana za odpowiednią dla strony, na której znajduje się łącze”.
12 metod analizy linków Google, które mogły się zmienić – Bill Slawski
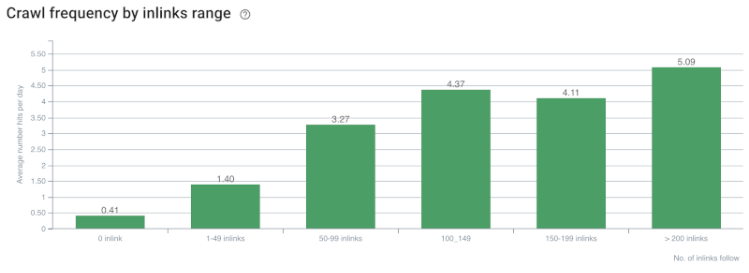
Korelacja szybkości indeksowania/popytu i liczby łączy wewnętrznych. Źródło: OnCrawl.
Jak dotąd możemy wyciągnąć następujące wnioski:
- Google dba o głębokość kliknięć. Jeśli strona internetowa jest bliżej strony głównej, powinno to być ważniejsze. Potwierdził to również John Mueller 1 lipca 2018 r. w angielskim Hangoucie Google dla webmasterów.
- Jeśli strona internetowa ma wiele wewnętrznych linków, które ją prowadzą, powinno to być ważne.
- Teksty zakotwiczeń mogą nadać stronie internetowej moc kontekstową.
- Link wewnętrzny może przekazywać różne wartości PageRank w zależności od jego pozycji, typu, grubości czcionki lub stylu.
- Przyjazne dla UX drzewo witryny, które daje jasne komunikaty o wewnętrznym autorytecie strony robotom wyszukiwarek, jest lepszym wyborem dla dystrybucji Inrank i wydajności indeksowania.
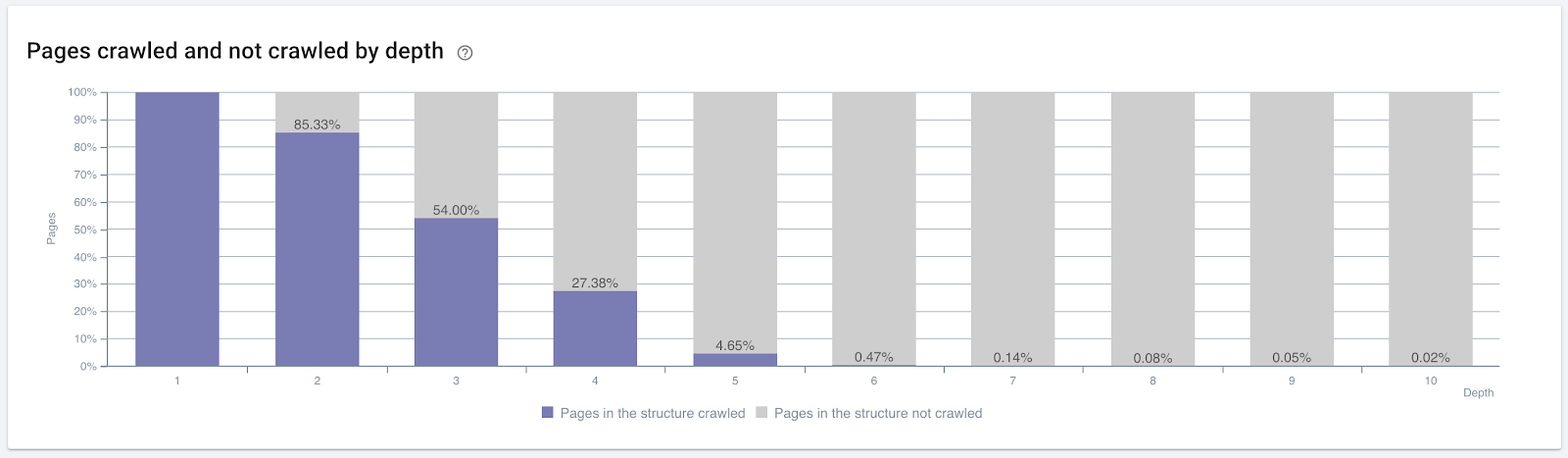
Procent zaindeksowanych stron według głębokości kliknięć. Źródło: OnCrawl.
Ale to nie wystarczy, aby zrozumieć naturę linków wewnętrznych i ich wpływ na wydajność indeksowania.
Robot SEO Oncrawl
 Ucz się więcej
Ucz się więcejJeśli strony, do których prowadzą najczęściej linki wewnętrzne, nie generują ruchu ani nie są klikane, daje to sygnały wskazujące, że drzewo witryny i struktura linków wewnętrznych nie są skonstruowane zgodnie z intencjami użytkownika. A Google zawsze stara się znaleźć najtrafniejsze strony, korzystając z intencji użytkownika lub jednostek wyszukiwania. Mamy kolejny cytat od Billa Sławskiego, który wyjaśnia ten temat:
„Jeśli zasób jest połączony z wieloma zasobami, które są nieproporcjonalne w stosunku do ruchu otrzymywanego za pomocą tych linków, zasób ten może zostać zdegradowany w procesie rankingu”.
Czy aktualizacja Świstaka właśnie miała miejsce w Google? — Bill Sławski„Wynik jakości selekcji może być wyższy dla selekcji, która skutkuje długim czasem przebywania (np. dłuższym niż próg czasu) niż wynik jakości selekcji dla selekcji, która skutkuje krótkim czasem przebywania”.
Czy aktualizacja Świstaka właśnie miała miejsce w Google? — Bill Sławski
Mamy więc jeszcze dwa czynniki:
- Czas przebywania na podlinkowanej stronie.
- Ruch użytkowników generowany przez łącze.
Liczba linków wewnętrznych i styl/pozycja nie są jedynymi czynnikami. Ważna jest również liczba użytkowników, którzy korzystają z tych linków oraz ich wskaźniki zachowania. Ponadto wiemy, że linki i strony, które są klikane/odwiedzane, są indeksowane przez Google znacznie częściej niż linki i strony, które nie są klikane ani odwiedzane.
„Coraz bardziej zbliżamy się do zrozumienia sekcji witryny, aby zrozumieć jakość tych sekcji”.
John Mueller, 2 maja 2017 r., angielski Hangout Google dla webmasterów.
Biorąc pod uwagę wszystkie te czynniki, podzielę się dwoma różnymi i różnymi wynikami Symulatora Pagerank:
Te obliczenia PageRank są wykonywane przy założeniu, że wszystkie strony są równe, w tym strona główna. Rzeczywista różnica jest określana przez hierarchię łączy.
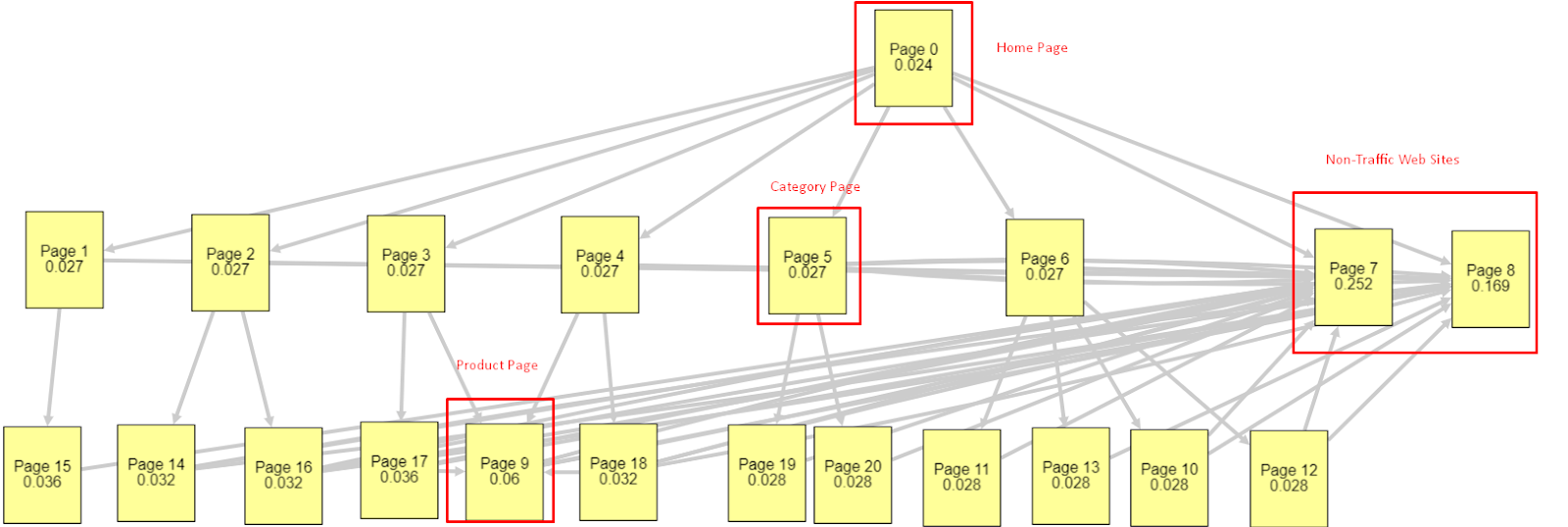
Pokazany tutaj przykład jest bliższy strukturze linków wewnętrznych sprzed 12 marca. PR strony głównej: 0,024, PR strony kategorii: 0,027, PR strony produktu: 0,06, PR strony niebędące ruchem w sieci: 0,252.
Jak możesz zauważyć, Googlebot nie może ufać tej wewnętrznej strukturze linków w obliczaniu wewnętrznego PageRank i ważności stron wewnętrznych. Strony niebędące ruchem i wolne od produktów mają 12 razy większy autorytet niż strona główna. Ma więcej niż strony produktowe.

Ten przykład jest bliższy naszej sytuacji przed aktualizacją podstawowego algorytmu z 5 czerwca. PR strony głównej: 0,033, strony kategorii: 0,037, strony produktu: 0,148 i PR stron bez ruchu: 0,037.
Jak możesz zauważyć, struktura linków wewnętrznych nadal nie jest właściwa, ale przynajmniej strony nietrafujące nie mają większego PR niż strony kategorii i strony produktów.
Jaki jest kolejny dowód na to, że Google usunęło wewnętrzny link i strukturę witryny z zakresu Pagerank zgodnie z przepływem użytkowników, żądaniami i intencjami? Oczywiście zachowanie Googlebota oraz Inlink Pagerank i korelacje rankingowe:
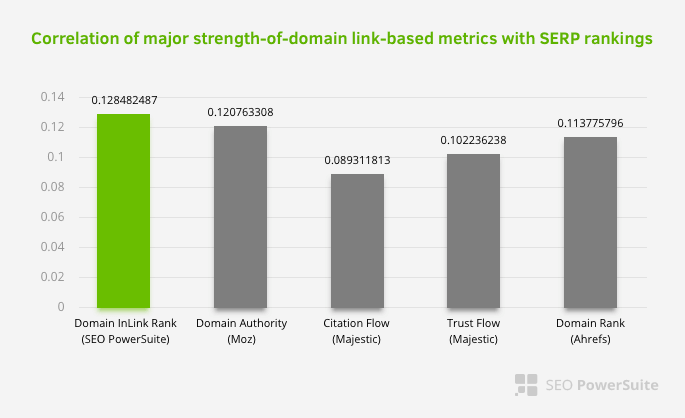
Nie oznacza to, że zwłaszcza sieć łączy wewnętrznych jest ważniejsza niż inne czynniki. Perspektywa SEO, która koncentruje się na jednym punkcie, nigdy nie może odnieść sukcesu. W porównaniu między narzędziami innych firm pokazuje, że wewnętrzna wartość Pagerank wzrasta w stosunku do innych kryteriów.
Według Inlink Rank i badania korelacji rang przeprowadzonego przez Aleha Barysevicha strony z największą liczbą linków wewnętrznych mają wyższe rankingi niż inne strony witryny. Według badania przeprowadzonego w dniach 4-6 marca 2019 r., 1 000 000 stron zostało przeanalizowanych według wewnętrznego wskaźnika Pagerank dla 33 500 słów kluczowych. Wyniki tych badań przeprowadzonych przez SEO PowerSuite zostały porównane z różnymi wskaźnikami Moz, Majestic i Ahrefs i dały dokładniejsze wyniki.
Oto niektóre z wewnętrznych numerów linków z naszej strony przed aktualizacją podstawowego algorytmu z 12 marca:
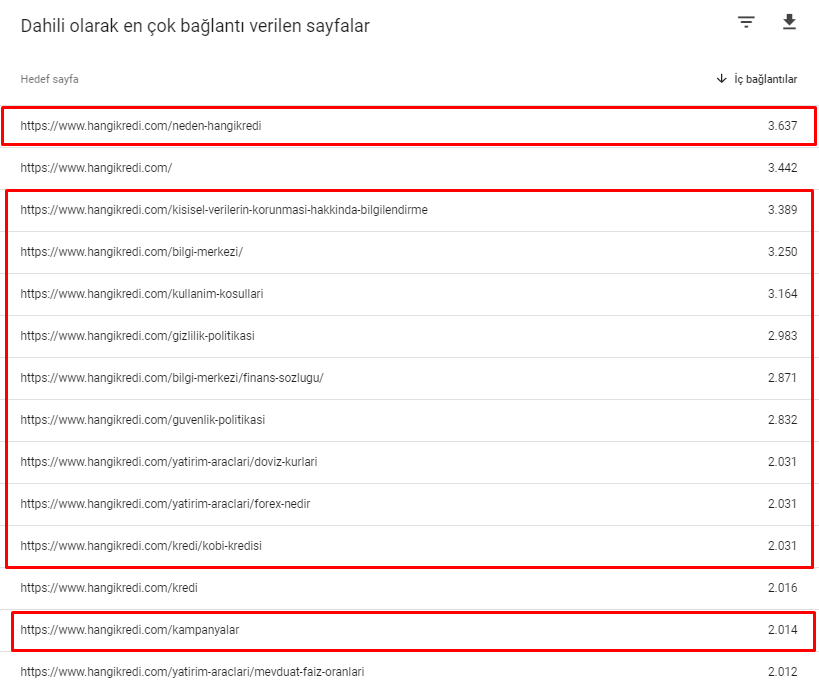
Jak widać, nasz schemat połączeń wewnętrznych nie odzwierciedla intencji i przepływu użytkownika. Strony, które otrzymują najmniejszy ruch (drobne strony produktów) lub które nigdy nie otrzymują ruchu (na czerwono), znajdowały się bezpośrednio na głębokości pierwszego kliknięcia i otrzymują PR ze strony głównej. A niektóre miały nawet więcej linków wewnętrznych niż strona główna.
W świetle tego wszystkiego możemy wskazać tylko dwa ostatnie punkty na ten temat.
- Szybkość indeksowania/zapotrzebowanie na najczęściej powiązane wewnętrznie strony
- Rzeźbienie linków i PageRank
Pomiędzy 1 lutego a 31 marca, oto strony najczęściej indeksowane przez Googlebota:
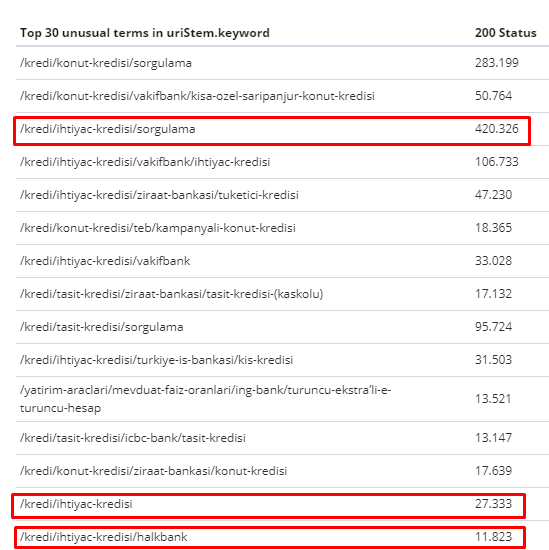
Jak możesz zauważyć, zindeksowane strony i strony, które mają najwięcej linków wewnętrznych, są całkowicie różne od siebie. Strony z największą liczbą linków wewnętrznych nie były wygodne dla użytkownika; nie mają organicznych słów kluczowych ani żadnej bezpośredniej wartości SEO. (
Adresy URL w czerwonych polach to najczęściej odwiedzane i najważniejsze kategorie stron produktów. Pozostałe strony na tej liście są drugą lub trzecią najczęściej odwiedzaną i ważną kategorią).
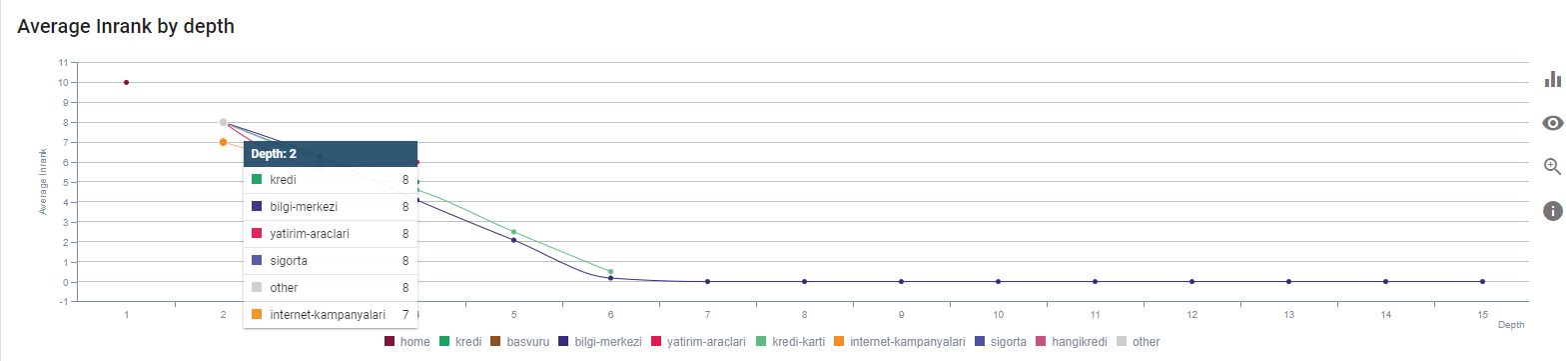
Nasz obecny Inrank według głębokości strony. Źródło: Oncrawl.
Co to jest rzeźbienie linków i co zrobić z linkami wewnętrznie nieobserwowanymi?
W przeciwieństwie do tego, w co wierzy większość SEO, linki oznaczone tagiem „nofollow” nadal przekazują wewnętrzną wartość PageRank. Dla mnie po tylu latach nikt nie opisał tego elementu SEO lepiej niż Matt Cutts w swoim artykule o rzeźbieniu w Pagerank z 15 czerwca 2009.
Przydatna część do rzeźbienia linków, która pokazuje prawdziwy cel rzeźbienia Pagerank.
„Polecam nie używać nofollow do pewnego rodzaju rzeźbienia PageRank w witrynie , ponieważ prawdopodobnie nie robi tego, co myślisz, że robi”.
–John Mueller, Google 2017
Jeśli masz bezwartościowe strony internetowe z punktu widzenia Google i użytkowników, nie powinieneś oznaczać ich tagiem „nofollow”. Nie zatrzyma przepływu PageRank. Powinieneś zabronić ich umieszczania w pliku robots.txt. W ten sposób Googlebot nie będzie ich indeksować, ale też nie przekaże im wewnętrznego PageRank. Ale powinieneś używać tego tylko do naprawdę bezwartościowych stron, jak powiedział Matt Cutts dziesięć lat temu. Strony, które dokonują automatycznych przekierowań dla marketingu afiliacyjnego lub strony w większości pozbawione treści, są tutaj wygodnymi przykładami.
Rozwiązanie: Lepsza i bardziej naturalna struktura wewnętrznych linków
Nasz konkurent miał wadę. Ich strona internetowa miała więcej anchor textów, więcej linków wewnętrznych, ale ich struktura nie była naturalna i użyteczna. Ten sam tekst zakotwiczenia został użyty z tym samym zdaniem na każdej stronie w ich witrynie. Paragraf wejściowy dla każdej strony został pokryty tą powtarzającą się treścią. Każdy użytkownik i wyszukiwarka może łatwo rozpoznać, że nie jest to naturalna struktura uwzględniająca korzyści użytkownika.
Zdecydowałem się więc na trzy rzeczy do zrobienia, aby naprawić wewnętrzną strukturę linków:
- Architektura informacji o witrynie lub drzewo witryny powinny podążać inną ścieżką niż łącza umieszczone w treści. Powinien ściślej podążać za umysłem użytkownika i siecią neuronową słów kluczowych.
- W każdym fragmencie treści słowa kluczowe poboczne powinny być używane wraz z głównymi słowami kluczowymi strony docelowej.
- Teksty kotwic powinny być naturalne, dostosowane do treści i powinny być użyte w innym miejscu na każdej stronie z uwzględnieniem percepcji użytkownika
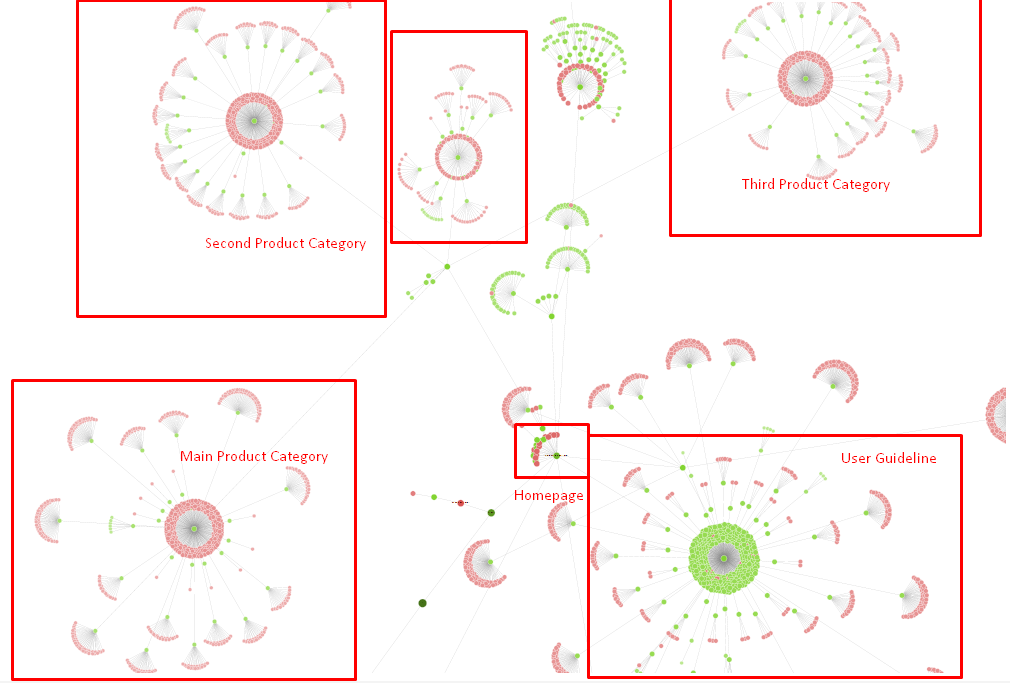
Na razie nasze drzewo witryny i część struktury linków.
Na powyższym diagramie możesz zobaczyć nasz aktualny link wewnętrzny i drzewo witryny.
Niektóre z rzeczy, które zrobiliśmy, aby rozwiązać ten problem, są poniżej:
- Stworzyliśmy 30 000 dodatkowych linków wewnętrznych z przydatnymi kotwicami.
- Wykorzystaliśmy naturalne spoty i słowa kluczowe dla użytkownika.
- Nie używaliśmy powtarzających się zdań i wzorców do linkowania wewnętrznego.
- Daliśmy właściwe sygnały Googlebotowi dotyczące Inrank strony internetowej.
- Zbadaliśmy wpływ prawidłowej struktury linków wewnętrznych na wydajność indeksowania za pomocą analizy logów i zauważyliśmy, że nasze główne strony produktów były indeksowane częściej w porównaniu z poprzednimi statystykami.
- Utworzono ponad 50 000 wewnętrznych linków do stron osieroconych.
- Wykorzystano linki wewnętrzne na stronie głównej do zasilania podstron i utworzono więcej wewnętrznych źródeł linków na stronie głównej.
- W celu ochrony Pagerank Power użyliśmy również tagu nofollow dla niektórych zbędnych linków zewnętrznych. (Nie chodziło o linki wewnętrzne, ale służy to temu samemu celowi.)
3. Problem: struktura treści
Google twierdzi, że w przypadku witryn YMYL wiarygodność i autorytet są o wiele ważniejsze niż w przypadku innych rodzajów witryn.

W dawnych czasach słowa kluczowe były tylko słowami kluczowymi. Ale teraz są to również byty , które są dobrze zdefiniowane, pojedyncze, znaczące i rozpoznawalne. W naszej treści pojawiły się cztery główne problemy:
- Nasza treść była krótka. (Zwykle długość treści nie jest ważna. Ale w tym przypadku nie zawierały one wystarczającej ilości informacji na temat tematów.)
- Imiona naszych pisarzy nie były pojedyncze, znaczące ani rozpoznawalne jako całość.
- Nasze treści nie były przyjazne dla oczu. Innymi słowy, nie była to zawartość „fast-foodowa”. Była zadowolona bez podtytułów.
- Użyliśmy języka marketingowego. W przestrzeni jednego akapitu mogliśmy zidentyfikować nazwę marki i jej reklamę dla użytkownika.
- Było wiele przycisków, które przekierowywały użytkowników na strony produktów ze stron informacyjnych.
- W treści naszych stron produktowych nie było wystarczającej ilości informacji ani wyczerpujących wskazówek.
- Projekt nie był przyjazny dla użytkownika. Używaliśmy w zasadzie tego samego koloru dla czcionki i tła. (W większości dzieje się tak z powodu problemów z infrastrukturą).
- Obrazy i filmy nie były postrzegane jako część treści.
- Zamiar użytkownika i zamiar wyszukiwania dla określonego słowa kluczowego nie były wcześniej postrzegane jako ważne.
- Było wiele zduplikowanych, niepotrzebnych i powtarzających się treści na ten sam temat.
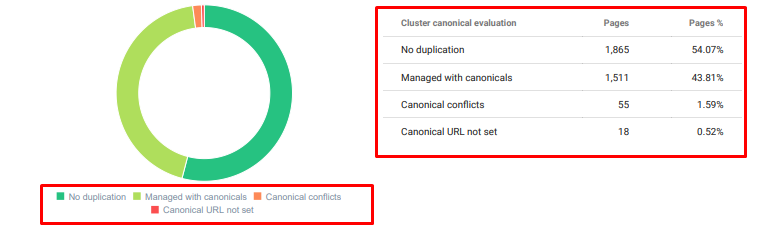
Audyt zduplikowanych treści Oncrawl od dzisiaj.
Rozwiązanie: Lepsza struktura treści dla zaufania użytkowników
Podczas sprawdzania problemu obejmującego całą witrynę, korzystanie z programu audytu obejmującego całą witrynę jako asystenta jest lepszym sposobem na zorganizowanie czasu spędzonego na projektach SEO. Podobnie jak w sekcji linków wewnętrznych, użyłem Oncrawl Site Audit wraz z innymi narzędziami i inspekcjami Xpath.
Po pierwsze, naprawienie każdego problemu w sekcji treści zajęłoby zbyt dużo czasu. W tych upadających, kryzysowych czasach czas był luksusem. Postanowiłem więc naprawić szybko wygrywające problemy, takie jak:
- Usuwanie zduplikowanych, niepotrzebnych i powtarzających się treści
- Ujednolicenie krótkich i cienkich treści, w których brakuje wyczerpujących informacji
- Ponowne publikowanie treści bez podtytułów i struktury umożliwiającej śledzenie wzroku
- Utrwalanie intensywnego tonu marketingowego w treści
- Usuwanie wielu przycisków wezwania do działania z treści
- Lepsza komunikacja wizualna z obrazami i filmami
- Zapewnienie zgodności treści i docelowych słów kluczowych z intencją użytkownika i intencją wyszukiwania
- Wykorzystywanie i pokazywanie podmiotów finansowych i edukacyjnych w treści dla zaufania
- Wykorzystanie społeczności społecznościowej do tworzenia społecznego dowodu aprobaty
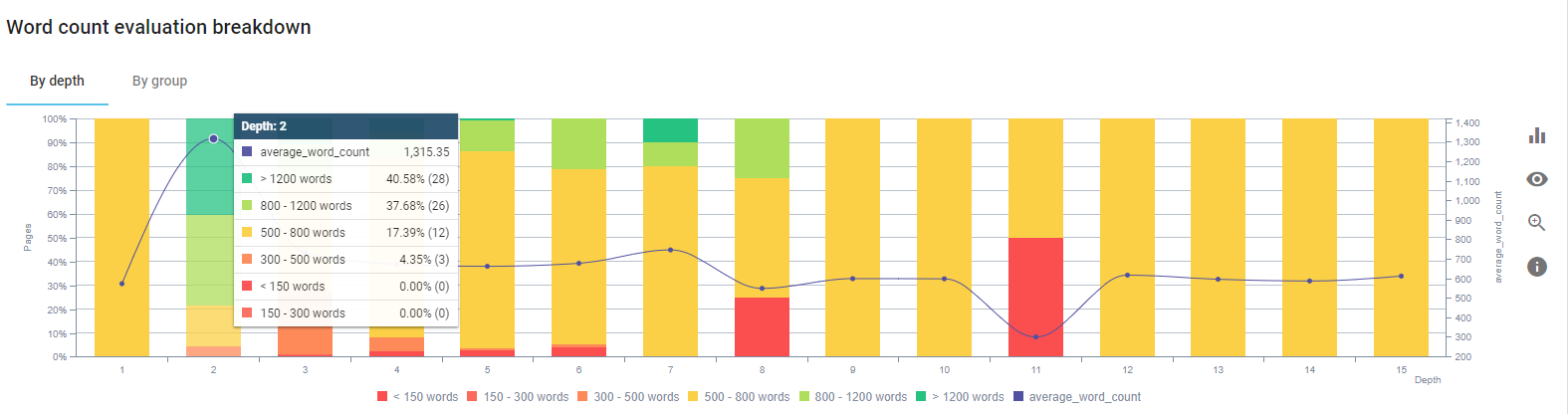

Skupiliśmy się na naprawieniu zawartości stron produktowych oraz najbliższych im stron poradnikowych.
Na początku tego procesu większość naszych produktów i transakcyjnych stron docelowych/wskazówek zawierała mniej niż 500 słów bez wyczerpujących informacji.
W ciągu 25 dni działania, które przeprowadziliśmy, są poniżej:
- Usunięto 228 stron z zduplikowaną, niepotrzebną i powtarzającą się treścią. (Profile linków zwrotnych Contents zostały sprawdzone przed procesem usunięcia. Aby poprawić komunikację z Googlebotem, użyliśmy kodów stanu 301 lub 410).
- Łącznie ponad 123 strony pozbawione wyczerpujących informacji.
- Użyte podtytuły zgodnie z ich znaczeniem i zapotrzebowaniem użytkowników w treści.
- Usunięto nazwę marki i przyciski CTA z językiem stylizowanym na marketing.
- Dołącz tekst do obrazów, aby wzmocnić główny temat.
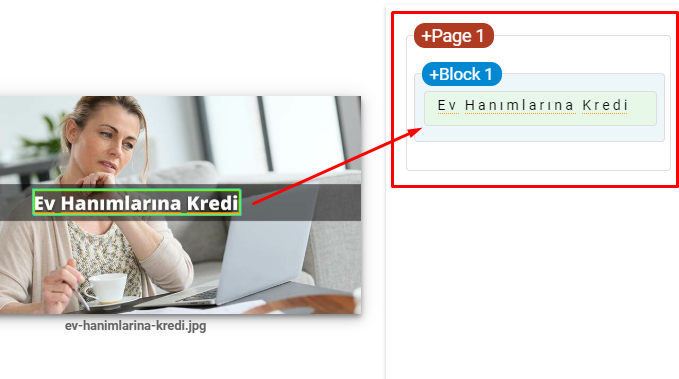
To jest zrzut ekranu z Google Vision AI. Google może odczytywać tekst na obrazach oraz wykrywać uczucia i tożsamości w podmiotach.
- Aktywowaliśmy naszą sieć społecznościową, aby przyciągnąć więcej użytkowników.
- Zbadaliśmy lukę w treści między konkurencją a nami i stworzyliśmy ponad 80 nowych treści.
- Wykorzystano Google Analytics, Search Console i Google Data Studio, aby określić strony o słabych wynikach o wysokim współczynniku odrzuceń i niskim ruchu.
- Poszukał polecanych fragmentów i ich słów kluczowych oraz struktury treści. Dodaliśmy te same nagłówki i strukturę treści do naszych powiązanych treści. Zwiększyło to liczbę polecanych fragmentów.
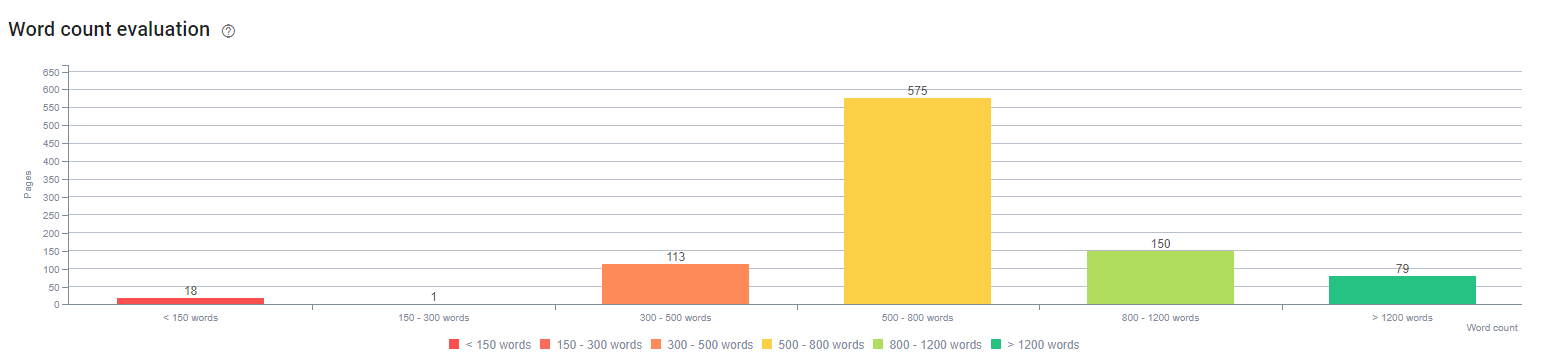
Na początku tego procesu nasze treści składały się głównie z 150-300 słów. Nasza średnia długość treści wzrosła o 350 słów dla całej witryny.
4. Problem: zanieczyszczenie indeksu, wzdęcia i znaczniki kanoniczne
Google nigdy nie wypowiedział się na temat Index Pollution i tak naprawdę nie jestem pewien, czy ktoś używał go wcześniej jako terminu SEO, czy nie. Wszystkie strony, które nie mają sensu dla Google w celu uzyskania bardziej efektywnego wyniku indeksowania, należy usunąć ze stron indeksu Google. Strony, które powodują zanieczyszczenie indeksu, to strony, które nie generują ruchu od miesięcy. Mają zerowy CTR i zero organicznych słów kluczowych. W przypadku, gdy mają kilka organicznych słów kluczowych, musieliby stać się konkurentem innych stron w Twojej witrynie dla tych samych słów kluczowych.
Przeprowadziliśmy również badania pod kątem rozdęcia indeksu i znaleźliśmy jeszcze więcej niepotrzebnych zindeksowanych stron. Te strony istniały z powodu błędnej struktury informacji o witrynie lub z powodu złej struktury adresu URL.
Innym powodem tego problemu były niepoprawnie używane znaczniki kanoniczne. Od ponad dwóch lat tagi kanoniczne traktowane są jedynie jako podpowiedzi dla Googlebota. Jeśli są używane nieprawidłowo, Googlebot nie obliczy ich ani nie zwróci na nie uwagi podczas wyceny witryny. A także, do tego obliczenia, prawdopodobnie nieefektywnie zużyjesz budżet indeksowania. Z powodu nieprawidłowego użycia tagów kanonicznych zindeksowaliśmy ponad 300 stron komentarzy ze zduplikowaną treścią.
Celem mojej teorii jest pokazywanie Google tylko wysokiej jakości i niezbędnych stron z potencjałem generowania kliknięć i tworzenia wartości dla użytkowników.
Rozwiązanie: naprawa zanieczyszczenia indeksu i wzdęcia
Najpierw skorzystałem z porady Johna Muellera z Google. Zapytałem go, czy użyłem tagu noindex dla tych stron, ale mimo to pozwoliłem Googlebotowi je śledzić, „czy stracę udział linków i wydajność indeksowania?”
Jak można się domyślić, początkowo powiedział tak, ale potem zasugerował, że użycie linków wewnętrznych może pokonać tę przeszkodę.
Zauważyłem również, że jednoczesne używanie tagów noindex i dofollow zmniejsza szybkość indeksowania tych stron przez Googlebota. Dzięki tym strategiom Googlebot mógł częściej indeksować moje produkty i ważne strony z wytycznymi. Zmodyfikowałem również swoją wewnętrzną strukturę linków, jak radził John Mueller.
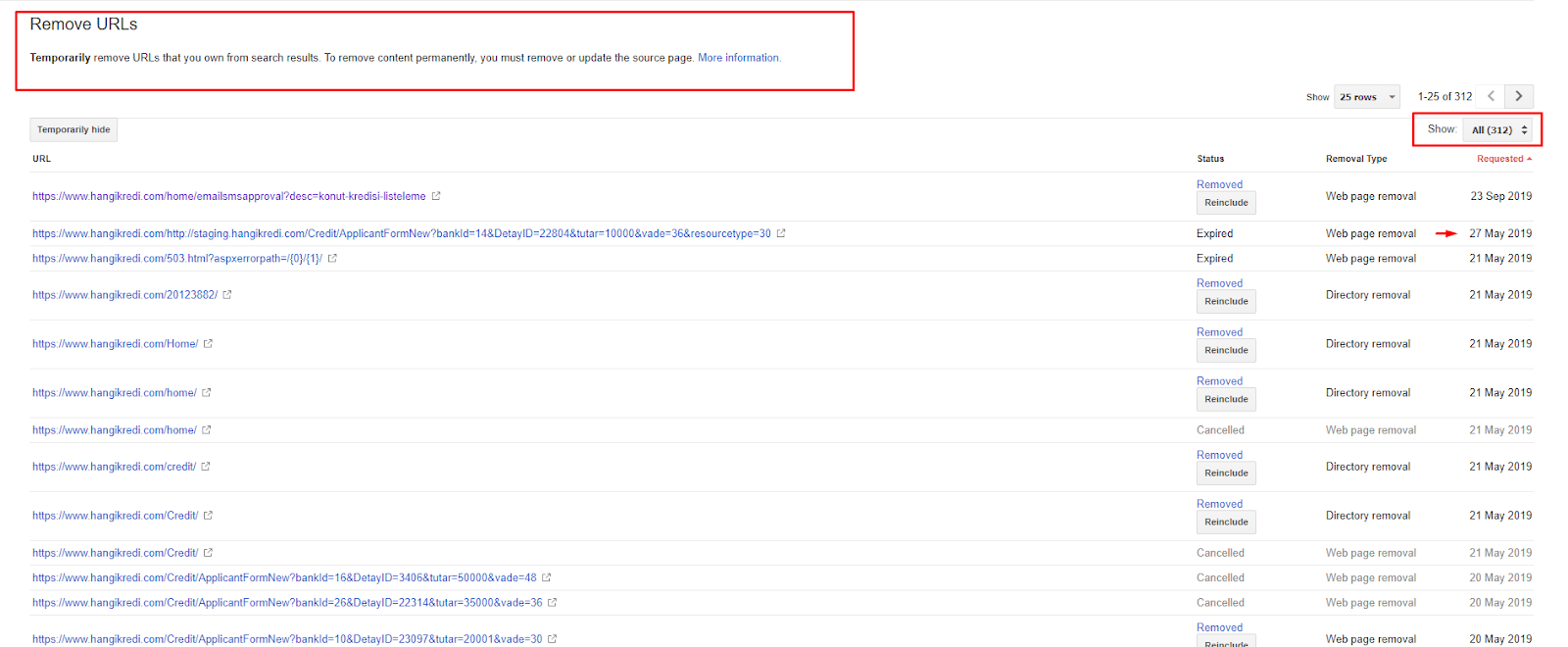
W krótkim czasie:
- Wykryto niepotrzebne zindeksowane strony.
- Z indeksu usunięto ponad 300 stron.
- Zaimplementowano tag Noindex.
- Struktura linków wewnętrznych została zmodyfikowana dla stron, które otrzymały linki ze stron usuniętych z indeksu.
- Z biegiem czasu badano wydajność i jakość indeksowania.
5. Problem: nieprawidłowe kody statusu
Na początku zauważyłem, że Googlebot odwiedza wiele usuniętych treści z przeszłości. Nawet strony sprzed ośmiu lat wciąż były indeksowane. Wynikało to z użycia nieprawidłowych kodów stanu, zwłaszcza w przypadku usuniętych treści.
Istnieje ogromna różnica między funkcjami 404 i 410. Jeden z nich dotyczy strony błędu, na której nie ma treści, a drugi dotyczy treści usuniętych. Ponadto prawidłowe strony odwoływały się również do wielu usuniętych adresów URL źródeł i treści. Niektóre usunięte obrazy i zasoby CSS lub JS zostały również wykorzystane na prawidłowych opublikowanych stronach jako zasoby. Wreszcie było wiele miękkich stron 404 i wiele łańcuchów przekierowań oraz 302-307 tymczasowych przekierowań dla stron przekierowywanych na stałe.
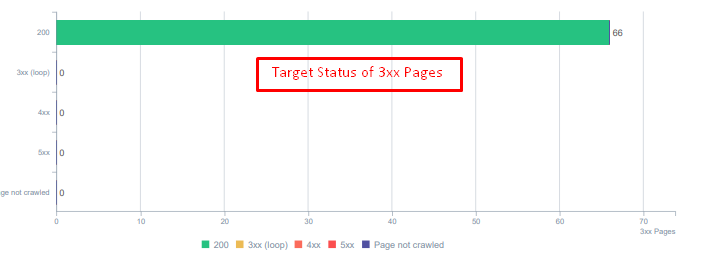
Kody stanu dla przekierowanych zasobów dzisiaj.
Rozwiązanie: naprawa błędnych kodów statusu
- Każdy kod statusu 404 został przekonwertowany na kod statusu 410. (Ponad 30000)
- Każdy zasób z kodem statusu 404 został zastąpiony nowym ważnym zasobem. (Ponad 500)
- Każde przekierowanie 302-307 było konwertowane na stałe przekierowanie 301. (Ponad 1500)
- Łańcuchy przekierowań zostały usunięte z używanych zasobów.
- Każdego miesiąca otrzymywaliśmy ponad 25 000 wejść na strony i zasoby z kodem stanu 404 w naszej Analizie logów. Teraz jest to mniej niż 50 dla 404 kodów stanu na miesiąc i zero trafień dla 410 kodów stanu…
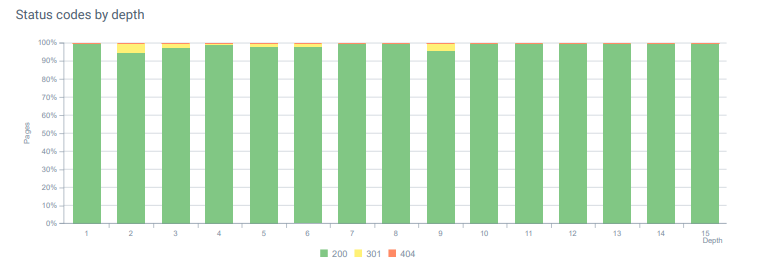
Kody statusu na całej głębokości strony dzisiaj.
6. Problem: semantyczny HTML
Semantyka odnosi się do tego, co coś znaczy. Semantyczny HTML zawiera znaczniki, które nadają znaczenie komponentowi strony w hierarchii. Dzięki tej hierarchicznej strukturze kodu możesz poinformować Google, jaki jest cel części treści. Ponadto w przypadku, gdy Googlebot nie może zaindeksować wszystkich zasobów wymaganych do pełnego wyrenderowania Twojej strony, możesz przynajmniej określić układ swojej strony internetowej i funkcje części treści Googlebotowi.
Na Hangikredi.com po 12 marca Google Core Algorithm Update wiedziałem, że nie ma wystarczającego budżetu na indeksowanie z powodu niezoptymalizowanej struktury strony. Aby więc ułatwić Googlebotowi zrozumienie celu, funkcji, zawartości i użyteczności strony internetowej, zdecydowałem się na użycie semantycznego HTML.
Rozwiązanie: semantyczne użycie HTML
Zgodnie z wytycznymi dotyczącymi oceny jakości Google, każda osoba wyszukująca ma zamiar, a każda strona internetowa ma funkcję zgodną z tą intencją. Aby udowodnić te funkcje Googlebotowi, wprowadziliśmy pewne ulepszenia w naszej strukturze HTML dla niektórych stron, które są rzadziej indeksowane przez Googlebota.
- Używany tag <main> do pokazywania głównej zawartości i funkcji strony.
- Używany <nav> dla części nawigacyjnej.
- Używane <footer> w stopce witryny.
- W artykule użyto <artykułu>.
- Użyto tagów <section> dla każdego tagu nagłówka.
- Użyto tagów <picture>, <table>, <citation> dla obrazów, tabel i cytatów w treści.
- Używany znacznik <aside> dla dodatkowej treści.
- Naprawiono problemy z hierarchią H1-H6 (pomimo najnowszego oświadczenia Google „używanie dwóch H1 nie stanowi problemu”, użycie odpowiedniej struktury pomaga Googlebotowi).
- Podobnie jak w sekcji Struktura treści, użyliśmy również semantycznego kodu HTML dla wyróżnionych fragmentów, użyliśmy tabel i list, aby uzyskać więcej wyników wyróżnionych fragmentów.

Dla nas nie był to realistycznie możliwy do wdrożenia rozwój dla całej witryny. Mimo to, z każdą aktualizacją projektu, wdrażamy semantyczne znaczniki HTML dla dodatkowych stron internetowych.
7. Problem: wykorzystanie danych strukturalnych
Podobnie jak użycie semantycznego kodu HTML, dane strukturalne mogą być używane do pokazywania Googlebotowi funkcji i definicji części stron internetowych. Ponadto dane strukturalne są obowiązkowe w przypadku wyników z elementami rozszerzonymi. Na naszej stronie internetowej do końca marca dane strukturalne nie były wykorzystywane lub, częściej, były wykorzystywane nieprawidłowo. W celu stworzenia lepszych relacji z podmiotami na naszej stronie internetowej i kontach off-page, rozpoczęliśmy wdrażanie danych strukturalnych.
Rozwiązanie: prawidłowe i przetestowane wykorzystanie danych strukturalnych
W przypadku instytucji finansowych i witryn YMYL dane strukturalne mogą rozwiązać wiele problemów. Na przykład mogą pokazać tożsamość marki, rodzaj treści i stworzyć lepszy widok fragmentu. W przypadku stron obejmujących całą witrynę i poszczególnych stron użyliśmy następujących typów danych strukturalnych:
- Często zadawane pytania Dane strukturalne dla głównych stron produktów
- Uporządkowane dane strony internetowej
- Dane strukturalne organizacji
- Uporządkowane dane z bułki tartej
8. Mapa witryny i optymalizacja pliku Robots.txt
W witrynie Hangikredi.com nie ma dynamicznej mapy witryny. Istniejąca wówczas mapa witryny nie zawierała wszystkich niezbędnych stron, a także zawierała usunięte treści. Ponadto w pliku Robots.txt nie zabroniono niektórych stron odsyłających podmiotów stowarzyszonych z tysiącami linków zewnętrznych. Dotyczyło to również niektórych plików JS innych firm, które nie są związane z treścią, oraz innych dodatkowych zasobów, które były niepotrzebne Googlebotowi.
Zastosowano następujące kroki:
- Utworzono sitemap_index.xml dla wielu map witryn, które są tworzone zgodnie z kategoriami witryn, aby uzyskać lepsze sygnały indeksowania i lepsze badanie zasięgu.
- Niektóre pliki JS innych firm i niektóre niepotrzebne pliki JS zostały niedozwolone w pliku robots.txt.
- Strony afiliacyjne z linkami zewnętrznymi i bez wartości strony docelowej były niedozwolone, jak wspomnieliśmy w sekcji PageRank lub Rzeźbienie linków wewnętrznych.
- Naprawiono ponad 500 problemów z zasięgiem. (Większość z nich to strony, które zostały zindeksowane, mimo że nie są dozwolone przez Robots.txt.)
Możesz zobaczyć naszą szybkość indeksowania, obciążenie i wzrost popytu na poniższym wykresie:
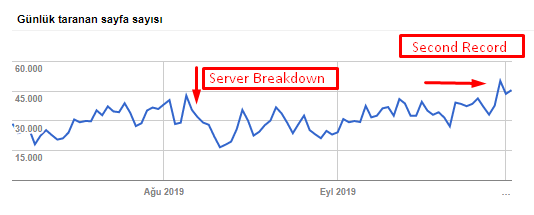
Liczba zindeksowanych stron dziennie przez Googlebota. Liczba stron indeksowanych dziennie do 1 sierpnia stale wzrastała. Po ataku, który spowodował awarię serwera na początku sierpnia, odzyskał on stabilność w nieco ponad miesiąc.

Dzienne obciążenie indeksowane przez Googlebota ewoluowało równolegle z liczbą stron indeksowanych w ciągu dnia.
9. Rozwiązywanie problemów z AMP
W witrynie internetowej firmy każda strona bloga ma wersję AMP. Z powodu nieprawidłowej implementacji kodu i brakujących kanonów AMP wszystkie strony AMP były wielokrotnie usuwane z indeksu. Spowodowało to niestabilny wynik indeksu i brak zaufania do witryny. Ponadto strony AMP zawierały domyślnie angielskie terminy i słowa w treściach tureckich.
- Naprawiono tagi kanoniczne na ponad 400 stronach AMP.
- Znaleziono i naprawiono nieprawidłowe implementacje kodu. (Głównie z powodu nieprawidłowej implementacji tagów AMP-Analytics i AMP-Canonical).
- Terminy angielskie zostały domyślnie przetłumaczone na język turecki.
- Stabilność indeksu i rankingu została stworzona dla strony blogowej serwisu firmy.
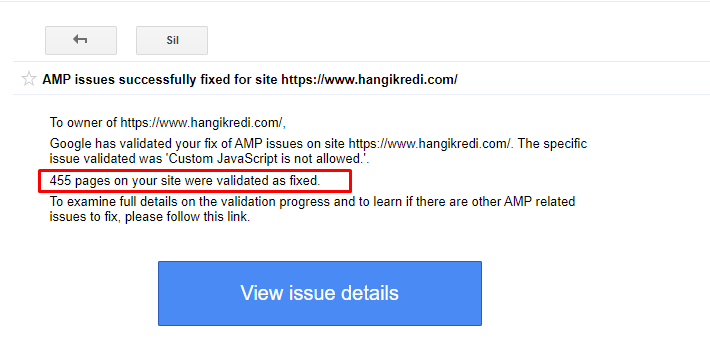
Przykładowy komunikat w GSC o ulepszeniach AMP
10. Problemy i rozwiązania metatagów
Z powodu problemów z budżetem indeksowania, czasami w krytycznych zapytaniach dotyczących ważnych głównych stron produktów, Google nie indeksował ani nie wyświetlał treści w metatagach. Zamiast metatytułu lista SERP zawierała tylko nazwę firmy zbudowaną z dwóch słów. Nie pokazano opisu fragmentu. To obniżało nasz CTR i szkodziło tożsamości marki. Rozwiązaliśmy ten problem, przenosząc metatagi na górę naszego kodu źródłowego, jak pokazano poniżej.
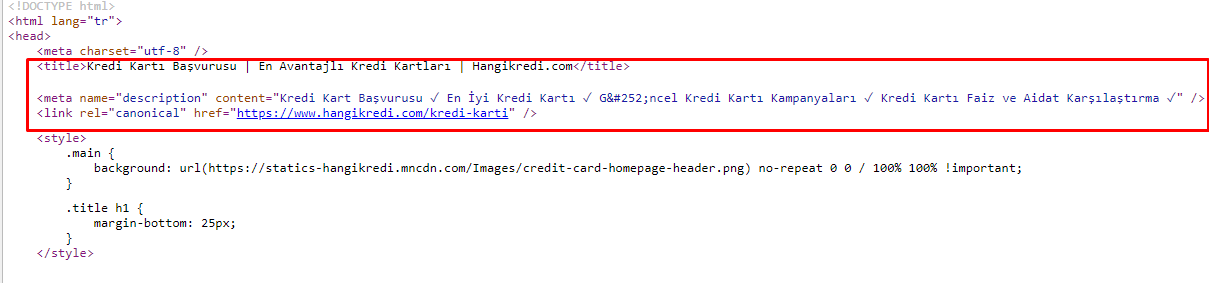
Oprócz budżetu indeksowania zoptymalizowaliśmy również ponad 600 metatagów dla stron transakcyjnych i informacyjnych:
- Zoptymalizowana długość znaków dla urządzeń mobilnych.
- Użyto więcej słów kluczowych w tytułach
- Wykorzystano inny styl metatagów i zbadano CTR, lukę w słowach kluczowych i zmiany w rankingu
- Dzięki tym procesom optymalizacji utworzono więcej stron z prawidłową strukturą drzewa witryn w celu lepszego kierowania na dodatkowe słowa kluczowe.
- Na naszej stronie nadal mamy różne meta tytuły, opisy i nagłówki do testowania algorytmu Google i CTR użytkowników wyszukiwania.
11. Problemy i rozwiązania dotyczące wydajności obrazu
Problemy z obrazem można podzielić na dwa typy. Dla wygody treści i szybkości strony. Dla obu, strona internetowa firmy ma wiele do zrobienia.
W marcu i kwietniu po negatywnej aktualizacji podstawowego algorytmu z 12 marca:
- Obrazy nie miały znaczników alt lub miały nieprawidłowe znaczniki alt.
- Nie mieli tytułów.
- Nie mieli prawidłowej struktury adresu URL.
- Nie mieli rozszerzeń nowej generacji.
- Nie zostały skompresowane.
- Nie mieli odpowiedniej rozdzielczości dla każdego rozmiaru ekranu urządzenia.
- Nie mieli podpisów.
Aby przygotować się do następnej aktualizacji algorytmu podstawowego Google:
- Obrazy zostały skompresowane.
- Ich rozszerzenia zostały częściowo zmienione.
- Dla większości z nich napisano tagi Alt.
- Tytuły i podpisy zostały naprawione dla użytkownika.
- Struktury adresów URL zostały częściowo naprawione dla użytkownika.
- Znaleźliśmy kilka nieużywanych obrazów, które wciąż są ładowane przez przeglądarkę, i usunęliśmy je z systemu.
Ze względu na infrastrukturę strony wprowadziliśmy częściowo korekty SEO wizerunku.
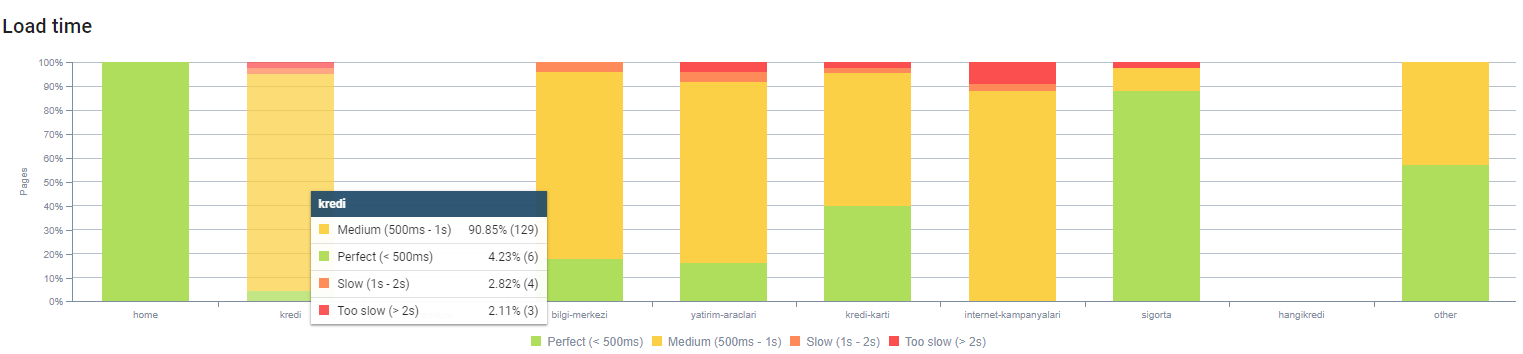
Możesz obserwować nasz czas ładowania strony według głębokości strony powyżej. Jak widać, większość stron produktowych jest nadal ciężka.
12. Problemy i rozwiązania dotyczące pamięci podręcznej, pobierania wstępnego i wstępnego ładowania
Przed 12 marca aktualizacją Core Algorithm na stronie internetowej firmy istniał luźny system pamięci podręcznej. Niektóre części zawartości były w pamięci podręcznej, ale niektóre nie. Był to szczególnie problem w przypadku stron produktów, ponieważ były one dwa razy wolniejsze niż strony produktów naszego konkurenta. Większość komponentów naszych stron internetowych jest w rzeczywistości źródłami statycznymi, ale nadal nie mają znaczników Etag do określania zakresu pamięci podręcznej.
Aby przygotować się do następnej aktualizacji algorytmu podstawowego Google:
- Zbuforowaliśmy niektóre komponenty dla każdej strony internetowej i uczyniliśmy je statycznymi.
- Te strony były ważnymi stronami produktów.
- Nadal nie używamy tagów elektronicznych ze względu na infrastrukturę witryny.
- Zwłaszcza obrazy, zasoby statyczne i niektóre ważne części treści są teraz w pełni buforowane w całej witrynie.
- Zaczęliśmy używać kodu dns-prefetch dla niektórych zapomnianych zasobów zewnętrznych.
- Nadal nie używamy kodu wstępnego ładowania, ale pracujemy nad podróżą użytkownika w witrynie w celu wdrożenia go w przyszłości.
13. Optymalizacja i minimalizacja HTML, CSS i JS
Ze względu na problemy z infrastrukturą witryny nie było tak wiele rzeczy do zrobienia dla szybkości witryny. Próbowałem wypełnić tę lukę każdą możliwą metodą, w tym usuwając niektóre elementy strony. W przypadku ważnych stron produktów wyczyściliśmy strukturę kodu HTML, skompresowaliśmy ją i skompresowaliśmy.
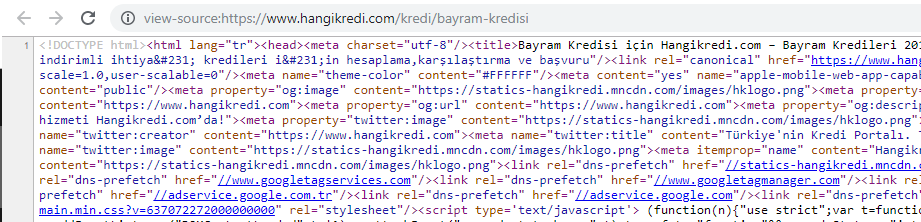
Zrzut ekranu z kodu źródłowego jednej z naszych sezonowych, ale ważnych stron produktów. Korzystanie z FAQ Structured Data, HTML Minifying, Image Optimization, Odświeżanie treści i Internal Linking dało nam pierwszą pozycję we właściwym czasie. (Słowo kluczowe to „Bayram Kredisi” w języku tureckim, co oznacza „Kredyt wakacyjny”)
Wdrożyliśmy również CSS Factoring, Refactoring i JS Compression częściowo małymi krokami. Kiedy rankingi spadły, zbadaliśmy różnicę w szybkości witryny między stronami naszego konkurenta a naszymi. Wybraliśmy kilka pilnych stron, które mogliśmy przyspieszyć. Na tych stronach częściowo oczyściliśmy i skompresowaliśmy krytyczne pliki CSS. Zainicjowaliśmy proces usuwania niektórych zewnętrznych plików JS używanych przez różne działy firmy, ale nie zostały one jeszcze usunięte. W przypadku niektórych stron produktów byliśmy również w stanie zmienić kolejność ładowania zasobów.
Badanie Zawodników
Oprócz każdego udoskonalenia technicznego SEO, inspekcja konkurencji była moim najlepszym przewodnikiem do zrozumienia natury i celów Aktualizacji Core Algorithm Update. Użyłem kilku przydatnych i pomocnych programów, aby śledzić zmiany wyglądu, treści, rangi i technologii mojego konkurenta.
- Do zmian w rankingu słów kluczowych użyłem Wincher, Semrush i Ahrefs.
- W przypadku wzmianek o marce korzystałem z Alertów Google, BuzzSumo, Talkwalkera.
- Do tworzenia raportów o nowych linkach i zyskach nowych słów kluczowych wykorzystałem Alert Ahrefs.
- Do zmian treści i projektu wykorzystałem Visualping.
- Do zmian technologicznych wykorzystałem SimilarTech.
- W przypadku Google Update News and Inspection używałem głównie Semrush Sensor, Algoroo i CognitiveSEO Signals.
- Do sprawdzenia historii adresów URL konkurentów użyłem Wayback Machine.
- Do szybkości serwerów konkurencji użyłem Chrome DevTools i ByteCheck.
- W przypadku kosztów indeksowania i renderowania użyłem „Co kosztuje moja witryna”. (Since last month, I have started using Onely's new JS Tools like WWJD or TL:DR..)

A screenshot from SimilarTech for my main competitor.
A screenshot from Visualping which shows the layout changes for my secondary competitor.
Testing the value of the changes
With all of these problems identified and solutions in place, I was ready to see whether the website would hold up to the next Google core algorithm updates.
In the next article, I'll look at the major core algorithm updates over the next several months, and how the site performed.