
Prognozowanie ruchu SEO za pomocą Prophet i Pythona
Opublikowany: 2021-03-16Wyznaczanie celów i ocena osiągnięć w czasie jest bardzo interesującym ćwiczeniem, aby zrozumieć, co jesteśmy w stanie osiągnąć i czy stosowana przez nas strategia jest skuteczna, czy nie. Jednak zazwyczaj nie jest łatwo ustalić te cele, ponieważ najpierw musimy opracować prognozę.
Tworzenie prognozy nie jest rzeczą łatwą, ale dzięki pewnym dostępnym procedurom prognozowania, naszemu procesorowi i pewnym umiejętnościom programistycznym możemy znacznie zmniejszyć jej złożoność. W tym poście pokażę Ci, jak możemy dokonywać dokładnych prognoz i jak możesz zastosować to do SEO, używając Pythona i biblioteki Prophet, bez konieczności posiadania supermocy wróżbitów.
Jeśli nigdy nie słyszałeś o Proroku, możesz się zastanawiać, co to jest. Krótko mówiąc, Prophet to procedura prognozowania opublikowana przez zespół Core Data Science Facebooka, dostępna w językach Python i R, która bardzo dobrze radzi sobie z wartościami odstającymi i efektami sezonowymi.
dostarczaj dokładne i szybkie prognozy.
Kiedy mówimy o prognozowaniu, musimy wziąć pod uwagę dwie rzeczy:
- Im więcej mamy danych historycznych, tym dokładniejszy będzie nasz model, a tym samym nasze przewidywania.
- Model predykcyjny będzie ważny tylko wtedy, gdy czynniki wewnętrzne pozostaną takie same i nie będą miały na niego wpływu żadne czynniki zewnętrzne. Oznacza to, że jeśli na przykład publikujemy jeden post tygodniowo i zaczynamy publikować dwa posty tygodniowo, ten model może nie być odpowiedni do przewidywania wyniku tej zmiany strategii. Z drugiej strony, jeśli nastąpi aktualizacja algorytmu, model może również nie być prawidłowy. Pamiętaj, że model jest zbudowany na podstawie danych historycznych.
Aby zastosować to do SEO, zamierzamy przewidzieć sesje SEO na nadchodzący miesiąc, postępując zgodnie z następującymi krokami:
- Pobieranie danych z Google Analytics o sesjach organicznych za określony czas.
- Szkolenie naszego modelu.
- Prognozowanie ruchu SEO na najbliższy miesiąc.
- Ocena, jak dobry jest nasz model ze średnim błędem bezwzględnym.
Chcesz dowiedzieć się więcej o tym, jak działa ta procedura prognozowania? Zacznijmy więc!
Pobieranie danych z Google Analytics
Do ekstrakcji danych z Google Analytics możemy podejść na dwa sposoby: eksportując plik Excel z normalnego interfejsu lub używając API do pobrania tych danych.
Importowanie danych z pliku Excel
Najłatwiejszym sposobem uzyskania tych danych z Google Analytics jest przejście do sekcji Kanały na pasku bocznym, kliknięcie Organiczne i wyeksportowanie danych za pomocą przycisku znajdującego się u góry strony. Upewnij się, że w menu rozwijanym u góry wykresu wybrałeś zmienną, którą chcesz przeanalizować, w tym przypadku Sesje.
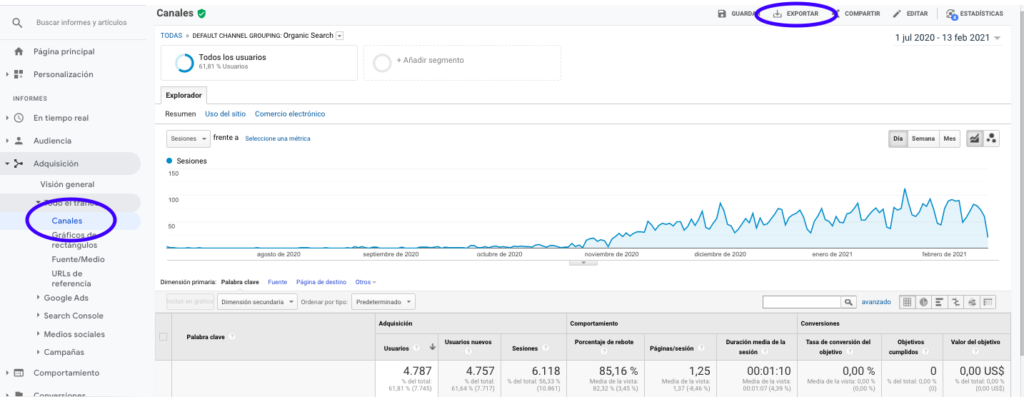
Po wyeksportowaniu danych do pliku Excel, możemy je zaimportować do naszego notatnika za pomocą Pand. Należy pamiętać, że plik Excel z takimi danymi będzie zawierał różne zakładki, dlatego zakładkę z miesięcznym ruchem należy podać jako argument w poniższym fragmencie kodu. Usuwamy również ostatni wiersz, ponieważ zawiera on całkowitą liczbę sesji, które zniekształciłyby nasz model.
importuj pandy jako PD
df = pd.read_excel ('.xlsx', nazwa_arkusza= "")
df = df.drop(len(df) - 1)
Za pomocą Matplotlib możemy narysować, jak wyglądają dane:
z matplotlib import pyplot
df["Sesje"].plot(title = "Sesje")
pyplot.show() 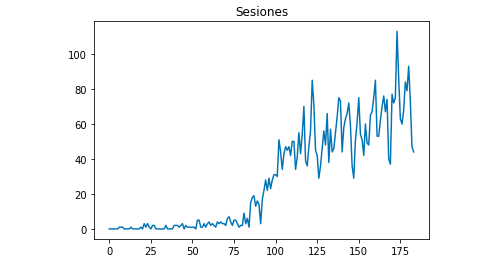
Korzystanie z interfejsu API Google Analytics
Przede wszystkim, aby skorzystać z Google Analytics API, musimy stworzyć projekt w konsoli programisty Google, włączyć usługę Google Analytics Reporting i uzyskać dane uwierzytelniające. Jean-Christophe Chouinard bardzo dobrze wyjaśnia w tym artykule, jak to skonfigurować.
Po uzyskaniu poświadczeń musimy dokonać uwierzytelnienia przed wysłaniem naszej prośby. Uwierzytelnianie należy przeprowadzić za pomocą pliku poświadczeń, który został pierwotnie pobrany z konsoli programisty Google. Będziemy również musieli zapisać w naszym kodzie identyfikator widoku GA z właściwości, której chcielibyśmy użyć.
z apiclient.discovery importuj kompilację
z oauth2client.service_account importuj poświadczenia konta usługi
ZAKRESY = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = ''
POGLĄD_
poświadczenia = ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE_LOCATION, SCOPES)
analytics = build('analyticsreporting', 'v4', poświadczenia=poświadczenia)Po uwierzytelnieniu wystarczy złożyć wniosek. Ten, którego musimy użyć, aby uzyskać dane o sesjach organicznych na każdy dzień, to:
odpowiedź = analytics.reports().batchGet(body={
'raportRequests': [{
'viewId': VIEW_ID,
'dateRanges': [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}],
'metryki': [
{"expression": "ga:sessions"}
], "wymiary": [
{"imię": "ga:data"}
],
"filtersExpression":"ga:channelGrouping=~Organic",
"includeEmptyRows": "prawda"
}]}).wykonać()Zauważ, że wybieramy zakres czasu w dataRanges. W moim przypadku zamierzam pobrać dane od 1 września do 31 stycznia: [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}]
Następnie wystarczy pobrać plik odpowiedzi, aby dołączyć do listy dni z ich sesjami organicznymi:
wartości_listy = [] dla x w odpowiedzi["raporty"][0]["dane"]["wiersze"]: list_values.append([x["wymiary"][0],x["metryki"][0]["wartości"][0]])
Jak widać, korzystanie z API Google Analytics jest dość proste i można je wykorzystać do wielu celów. W tym artykule wyjaśniłem, w jaki sposób można użyć interfejsu API Google Analytics do tworzenia alertów wykrywających strony o niskiej wydajności.

Dostosowywanie list do Dataframes
Aby skorzystać z Prophet, musimy wprowadzić Dataframe z dwiema kolumnami, które należy nazwać: „ds” i „y”. Jeśli zaimportowałeś dane z pliku Excel, mamy je już jako Dataframe, więc wystarczy nazwać kolumny „ds” i „y”:
df.kolumny = ['ds', 'y']
Jeśli skorzystałeś z API do pobrania danych, musimy przekształcić listę w ramkę danych i nazwać kolumny zgodnie z wymaganiami:
z pand importuj DataFrame df_sessions = DataFrame(list_values,columns=['ds','y'])
Trening modelki
Gdy już mamy Dataframe w wymaganym formacie, możemy bardzo łatwo określić i przeszkolić nasz model za pomocą:
importuj fbprophet z fbprophet import Prophet model = Prorok() model.fit(df_sessions)
Dokonywanie naszych prognoz
Wreszcie po wytrenowaniu naszego modelu możemy zacząć prognozować! Aby kontynuować przewidywanie, najpierw musimy stworzyć listę z zakresem czasu, który chcielibyśmy przewidzieć i dostosować format daty i godziny:
od importu pand do_datetime dni_prognozy = [] dla x w zakresie (1, 28): data = "2021-02-" + str(x) prognoza_dni.append([data]) prognoza_dni = DataFrame (prognoza_dni) prognoza_dni.kolumny = ['ds'] prognoza_dni['ds']= to_datetime(prognoza_dni['ds'])
W tym przykładzie używam pętli, która utworzy ramkę danych zawierającą wszystkie dni z lutego. A teraz to tylko kwestia wykorzystania wytrenowanego wcześniej modelu:
prognoza = model.predict(prognoza_dni)
Możemy narysować wykres z zaznaczeniem przewidywanego okresu:
z matplotlib import pyplot model.plot(prognoza) pyplot.show()
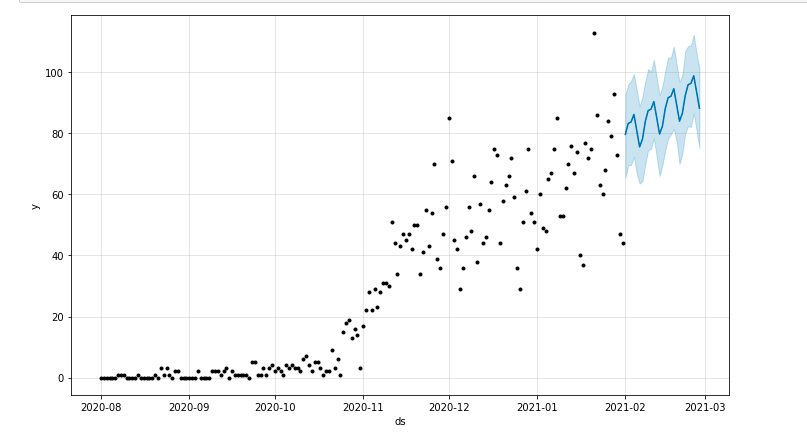
Ocena modelu
Na koniec możemy ocenić, jak dokładny jest nasz model, eliminując kilka dni z danych używanych do trenowania modelu, prognozując sesje dla tych dni i obliczając średni błąd bezwzględny.
Jako przykład zamierzam wyeliminować z oryginalnej ramki danych ostatnie 12 dni ze stycznia, prognozując sesje na każdy dzień i porównując rzeczywisty ruch z prognozowanym.
Najpierw eliminujemy z oryginalnej ramki danych 12 ostatnich dni z popem i tworzymy nową ramkę danych, która będzie zawierać tylko te 12 dni, które zostaną użyte do prognozy:
pociąg = df_sessions.drop(df_sessions.index[-12:]) future = df_sessions.loc[df_sessions["ds"]> train.iloc[len(train)-1]["ds"]]["ds"]
Teraz trenujemy model, wykonujemy prognozę i obliczamy średni błąd bezwzględny. Na koniec możemy narysować wykres, który pokaże różnicę między rzeczywistymi prognozowanymi wartościami a rzeczywistymi. To jest coś, czego nauczyłem się z tego artykułu napisanego przez Jasona Brownlee.
z importu sklearn.metrics mean_absolute_error
importuj numer jako np
z numpy importu tablicy
#Szkolemy modelkę
model = Prorok()
model.fit(pociąg)
#Dostosuj ramkę danych używaną dla dni prognozy do formatu wymaganego przez Proroka.
przyszłość = lista(przyszłość)
przyszłość = DataFrame (przyszłość)
future = future.rename(columns={0: 'ds'})
# Tworzymy prognozę
prognoza = model.predict(przyszłość)
# Obliczamy MAE między wartościami rzeczywistymi a przewidywanymi
y_true = df_sessions['y'][-12:].wartości
y_pred = prognoza['yhat'].wartości
mae = średnia_bezwzględna_błąd(y_prawda, y_pred)
# Wykreślamy ostateczny wynik w celu wizualnego zrozumienia
y_true = np. stos (y_true). astype (zmiennoprzecinkowa)
pyplot.plot(y_true, label='Rzeczywiste')
pyplot.plot(y_pred, label='Przewidywane')
pyplot.legend()
pyplot.show()
drukuj (mężczyzna) 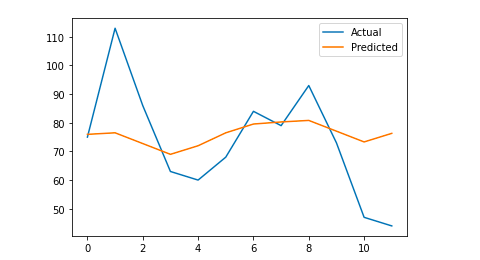
Mój średni błąd bezwzględny wynosi 13, co oznacza, że mój prognozowany model przypisuje do każdego dnia o 13 więcej sesji niż rzeczywiste, co wydaje się być akceptowalnym błędem.
To wszystko ludzie! Mam nadzieję, że ten artykuł był dla Ciebie interesujący i możesz zacząć tworzyć swoje prognozy SEO, aby wyznaczać cele.
Idąc dalej: OnCrawl Labs
Jeśli podobało Ci się prognozowanie ruchu za pomocą tej metody, zainteresuje Cię również OnCrawl Labs, laboratorium OnCrawl zajmujące się nauką o danych i uczeniem maszynowym, które oferuje wstępnie zakodowane projekty dla Twoich przepływów pracy SEO.
W prognozowaniu SEO OnCrawl Labs pomoże Ci udoskonalić prognozy SEO:
- Uzyskaj lepsze zrozumienie teorii i procesów stojących za algorytmem Facebook Prophet
- Przeanalizuj segment ruchu, np. ruch tylko ze słów kluczowych z długiego ogona lub tylko ze słów kluczowych związanych z marką…
- Postępuj krok po kroku, aby skonfigurować wydarzenia historyczne, dostosowując ich wpływ i prawdopodobieństwo ich powtórzenia.