
Jak prognozować ruch w sieci wyszukiwania za pomocą Pythona i GA4
Opublikowany: 2021-04-26W każdej strategii ukierunkowanej na optymalizację pod kątem wyszukiwarek (SEO) niezbędna jest analiza danych. Coraz więcej specjalistów w tej dziedzinie decyduje się rozwijać swoją karierę w zakresie analizy ruchu organicznego w wyszukiwarkach, który sam w sobie ma zupełnie inne zachowanie i cechy charakterystyczne: wyszukiwanie płatne, e-mail, organiczne społecznościowe, bezpośrednie itp. to poczucie i dzięki szerokiej gamie dostępnych dziś narzędzi, tego rodzaju badania zdołały ewoluować w stopniu niewyobrażalnym w porównaniu do zaledwie kilku lat temu.
Ten duży krok naprzód wynika głównie z pojawienia się nowych metodologii i osiągnięć, które umożliwiły nam generowanie modeli analitycznych bez konieczności polegania na skomplikowanych operacjach matematycznych. Mamy szczęście, że mamy do dyspozycji sprawdzone już techniki i algorytmy, gotowe do rozpoczęcia z nimi pracy.
W poniższym artykule skupimy się na stworzeniu modelu predykcyjnego dla zbioru danych szeregu czasowego, w którym obliczony trend jest dostosowany do sezonowości i poprzedniej okresowości. Dokładniej, będziemy przewidywać ruch z bezpłatnych wyników wyszukiwania naszej usługi z Google Analytics 4 (zwany dalej GA4). Istnieje wiele opcji, aby to zrobić, jednak w tym konkretnym przypadku zdecydowałem się wykonać programowanie w całości w Pythonie.
Scenariusz, na którym opiera się ten artykuł, składa się z trzech wyraźnie zróżnicowanych części:
- Ekstrakcja danych . Jak krok po kroku korzystać z nowego API GA4 do zbierania organicznego ruchu z wyników wyszukiwania.
- Modelowanie danych . Korzystanie z Prophet, biblioteki open-source Facebooka do przewidywania szeregów czasowych.
- Wizualizacja danych . Pokaż zmiany trendów i prognozy modelowane.
Ekstrakcja danych GA4 za pomocą interfejsu API przy użyciu Pythona
Pierwszą rzeczą, którą musimy wiedzieć, kiedy mamy do czynienia z Google Analytics Data API (GA4), jest to, że GA4 to jego stan rozwoju. Jak wyszczególnia Google na swojej stronie, jest obecnie we wczesnej wersji. Konkretnie, na dzień napisania tego artykułu jest on nadal w fazie beta.
Należy zauważyć, że GA4 został opublikowany 14 października 2020 roku. Minęło zaledwie kilka miesięcy. W rzeczywistości ci, którzy mieli już usługę Universal Analytics i utworzą nową usługę GA4, będą mogli nadal korzystać z obu wersji obok siebie, bez żadnych ograniczeń. Nie wiadomo na pewno, kiedy usługi Universal Analytics przestaną działać. W każdym razie moim zaleceniem byłoby jak najszybsze utworzenie nowej właściwości typu GA4. W ten sposób będziesz mieć szerszą historię danych. Należy również wziąć pod uwagę, że każdy dzień, który mija GA4 integruje nowe funkcjonalności lub ulepsza już istniejące. W tej chwili jest w ciągłej ewolucji.
Z tego powodu oczywiście mogą wystąpić drobne zmiany w kodzie opisanym poniżej. Choć na pewno będą minimalne. Na przykład napotkałem już drobne drobiazgi, takie jak zmiana nazwy pola „entity” (faza alfa) na „właściwość” (faza beta) w ramach klasy RunReportRequest() .
Przede wszystkim, przed zbudowaniem żądania API, potrzebne jest zrozumienie, jakie elementy są dostępne. Zasadniczo chodzi o przestrzeganie poniższej struktury: 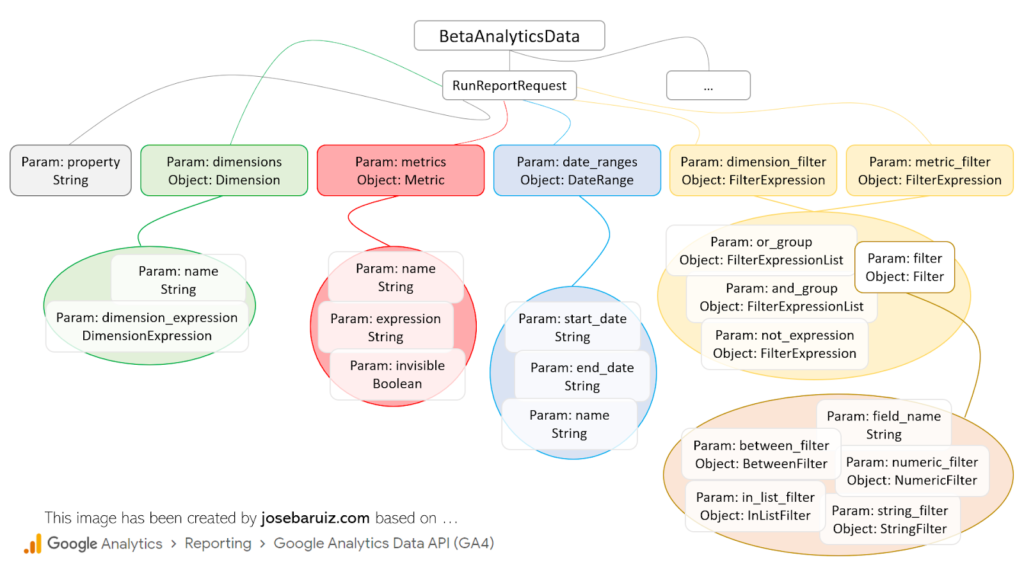
Typy RunReportRequest of GA4 Data v1 Beta API
Na pierwszy rzut oka jest to dość intuicyjne, choć rzeczywistość jest zupełnie inna. Aby złożyć wniosek, należy zawsze mieć pod ręką co najmniej następującą dokumentację:
- Programowanie Google APIS
- Raportowanie API danych Google Analytics (GA4).
Dzieje się tak po prostu dlatego, że nazwy pól różnią się nieco od oficjalnej dokumentacji, która reprezentuje pola w formacie JSON. Przykładem jest nazwa pola pola klasy Filter. W Pythonie powinniśmy to opisać jako nazwa_pola. Dobrą ogólną zasadą będzie zawsze przejście z pola typu wielbłąda (np. „fieldName”) do przypadku węża (np. „field_name”).
Zanim przejdziemy dalej, zatrzymajmy się na chwilę, aby zainicjować nasz projekt. Jak w zdecydowanej większości przypadków przy tworzeniu skryptów w Pythonie musimy poświęcić trochę czasu na zaimportowanie potrzebnych bibliotek i przygotowanie środowiska wykonawczego.
- Utwórz nowy projekt w Pythonie. W tym przypadku wykorzystano oprogramowanie PyCharm.
- Włącz Google Analytics Data API w Google Cloud Platform i pobierz utworzony plik konta usługi (typ JSON) i zapisz go w folderze, w którym powstał projekt Python. Po otwarciu tego pliku należy skopiować wartość pola client_email, która będzie wyglądać jak [email protected].
- Dodaj tę wartość client_email do właściwości GA4, z której zostaną wyodrębnione dane. Musisz to zrobić w sekcji zarządzania użytkownikami. Jako minimum konieczne będzie nadanie mu poziomu uprawnień „Odczyt i analiza”.
- Poprzez terminal klienta (PyCharm) zainstaluj bibliotekę danych Google Analytics w katalogu projektu, za pomocą którego będą realizowane żądania API:
pip install google-analytics-data
Od tego momentu wystarczy utworzyć żądanie, które, jak widać poniżej, składa się w zasadzie z trzech części (klient, żądanie i odpowiedź) i wyświetlić lub zapisać zebrane dane. 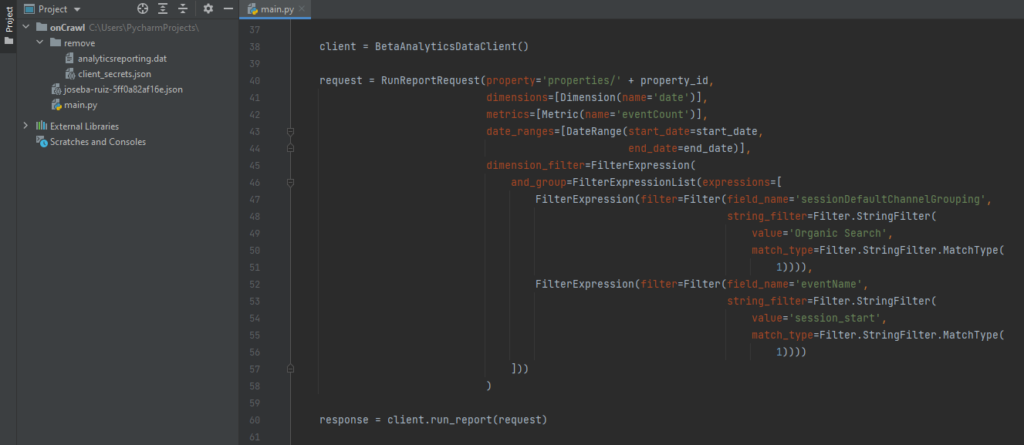
Kod do składania prostej prośby do GA4
Każdy wymiar, metryka, filtr, kolejność danych, zakres dat itp. dodane do zmiennej żądania należy dodać jako klasę (patrz poprzedni obraz „Typy dla RunReportRequest”) powiązana ze zmienną ( metryka = [Metric (..)] ). To znacznie ułatwia zrozumienie struktury gromadzonych danych. W tym sensie dla każdej klasy najwyższego poziomu należy przeprowadzić określony import. Oznacza to, że jeśli chcesz dodać wymiar i dane dla określonego zakresu czasu, wymagane będą co najmniej następujące obiekty…
z google.analytics.data_v1beta import BetaAnalyticsDataClient z google.analytics.data_v1beta.types importuj RunReportRequest z google.analytics.data_v1beta.types importuj DateRange z google.analytics.data_v1beta.types import Dimension z google.analytics.data_v1beta.types importuj dane
Oczywiście istnieje również możliwość dodania określonych wartości do określonych zmiennych ( name = 'eventCount' ). Z tego powodu konieczne jest wcześniejsze zrozumienie i zagłębienie się w opisywanej dokumentacji.
Oprócz tego należy zwrócić szczególną uwagę na zmienną os.environ [„GOOGLE_APPLICATION_CREDENTIALS”] , która będzie zawierać ścieżkę do pliku pobranego wcześniej w kroku 2. Ten wiersz kodu pozwoli uniknąć niektórych problemów podczas zarządzania uprawnieniami do Interfejs API Google.
Jeśli kod został wykonany poprawnie, zobaczysz wynik, który wygląda tak: {Data, Wydarzenia}, {20210418, 934}, {…}, ….
Dane dotyczące indeksowania³
 Ucz się więcej
Ucz się więcejPrzewidywanie danych przez Facebook Prophet
Obecnie istnieje wiele bezpłatnych i istniejących opcji przeprowadzania wszelkiego rodzaju prognoz na podstawie historii danych. W tym konkretnym przypadku wybrałem bibliotekę Proroka, ale co to tak naprawdę jest?
Jest to biblioteka typu open source (dostępna dla R i Python) stworzona przez zespół Data Science firmy Facebook w celu oszacowania zachowania zestawu danych szeregów czasowych w oparciu o model addytywny, w którym trendy nieliniowe są dostosowywane do sezonowości dziennej, tygodniowej i rocznej uwzględniać skutki dni urlopu.
Wracając do proponowanej implementacji (przewidywanie organicznego ruchu wyszukiwania), pierwszą rzeczą do zrobienia jest zainstalowanie następujących bibliotek:

- Pandy ( pip install pandy ). Zarządzaj i analizuj struktury danych.
- Plotly ( pip install plotly ). Tworzenie wszelkiego rodzaju grafik.
- Prorok ( conda install -c conda-forge fbprophet -y ).
Następnie, jak zawsze, musisz przeprowadzić importy związane z tymi bibliotekami. Następnie pozostaje Ci już tylko wykonać modelowanie prognozy i odpowiednią wizualizację. Aby to zrobić, w przypadku Proroka wystarczy postępować zgodnie z następującym procesem:
- Zainicjuj nowy obiekt Prophet z żądanymi atrybutami, aby wygenerować prognozę.
- Poproś o metodę dopasowania, przekazując jej dane wyodrębnione z GA4 jako ramkę danych. W niektórych przypadkach to żądanie może zająć kilka sekund. Ramka danych z zebranymi danymi może składać się tylko z dwóch kolumn, których nazwy są zawsze takie same: ds (pole typu daty) i y (dane do badania).
- Utwórz nową przyszłą ramkę danych określając liczbę okresów, do których prognoza powinna sięgać z wybranego zakresu dat oraz częstotliwość, z jaką dane będą agregowane (tygodniowe, miesięczne itp.)
- Poproś o metodę przewidywania, która przypisze każdemu wierszowi nowej przyszłej ramki danych przewidywaną wartość (yhat).
- Poproś o metodę wykresu, aby móc wyświetlić wygenerowane prognozy.
- Poproś o metodę plot_components, która pomaga wizualnie zrozumieć trend i sezonowość danych.
m = prorok () m.fit(df) future = m.make_future_dataframe(okresy=365) prognoza = m.predict(przyszłość) m.plot(prognoza) m.plot_components(prognoza) plt.pokaż()
Chociaż pożądana prognoza została wygenerowana w zaledwie sześciu krokach i wydaje się stosunkowo prosta, należy wziąć pod uwagę kilka elementów, które będą kluczowe do wygenerowania prognozy. Wszystkie one w taki czy inny sposób wpływają na trafność przepowiedni. W końcu chodzi o wygenerowanie prognozy zgodnej z logiką, w przypadku tego artykułu, naszego organicznego ruchu w wyszukiwarce. W tym celu konieczne jest zrozumienie niektórych bardziej zaawansowanych ustawień Proroka.
- Specjalne dni i wakacje. Istnieje możliwość dodania dni specjalnych.
- Odstające. Muszą zostać wyeliminowane, jeśli mają wpływ na oszacowanie.
- Punkty zmiany. Wykrywanie zmian trendów w analizowanym czasie.
- Diagnoza. Walidacja oparta na pomiarze błędu prognozy zgodnie z historycznym badaniem danych.
- Zwiększać. Wybór między liniowym a logistycznym.
- Sezonowość. Wybór między addytywnym a multiplikatywnym.
Wszystko to i wiele innych opcji jest szczegółowo opisanych w tej dokumentacji biblioteki Prophet.
Stworzenie kompletnego skryptu umożliwiającego wizualizację prognozy ruchu
Teraz pozostaje tylko połączyć wszystkie elementy układanki w jednym skrypcie. Typowym sposobem rozwiązania tego typu zagadek jest stworzenie funkcji dla każdego z wcześniej szczegółowych procesów, w taki sposób, aby można je było wykonać w uporządkowany i czysty sposób:
def ga4(identyfikator_właściwości, data_początkowa, data_końcowa): […] prognozowanie def(dim, met, per, freq): […] if __name__ == "__main__": wymiar, dane = ga4(PROPERTY_ID, START_DATE, END_DATE) prognozowanie (wymiar, metryka, OKRESY, CZĘSTOTLIWOŚĆ)
Przed wizualizacją końcowego wyniku prognozy warto przyjrzeć się przeanalizowanemu ruchowi organicznemu w wyszukiwarce.
Na pierwszy rzut oka widać, jak różne strategie i podjęte działania miały wpływ na czas. W przeciwieństwie do innych kanałów (na przykład kampanii w Płatnych wynikach wyszukiwania), ruch generowany z bezpłatnych wyników wyszukiwania zwykle ma niewiele znaczących oscylacji (doliny lub szczyty). Z biegiem czasu ma tendencję do stopniowego wzrostu lub spadku, a czasami jest pod wpływem wydarzeń sezonowych. Zwykle zauważalne wahania są związane z aktualizacjami algorytmu wyszukiwarki (Google, Bing itp.).
Wyniki działania skryptu można zobaczyć na poniższych obrazach, na których szczegółowo opisano ważne czynniki, takie jak trend, sezonowość, przewidywania lub częstotliwość danych.
Jeśli przeanalizujemy uzyskaną prognozę, można by w sposób ogólny stwierdzić, że „jeśli będziemy kontynuować tę samą strategię SEO wdrożoną do tej pory, ruch z wyszukiwarek będzie nadal stopniowo rósł”. Możemy zapewnić, że „nasze wysiłki na rzecz poprawy wydajności strony internetowej, generowania wysokiej jakości treści, dostarczania odpowiednich linków itp. były tego warte”. 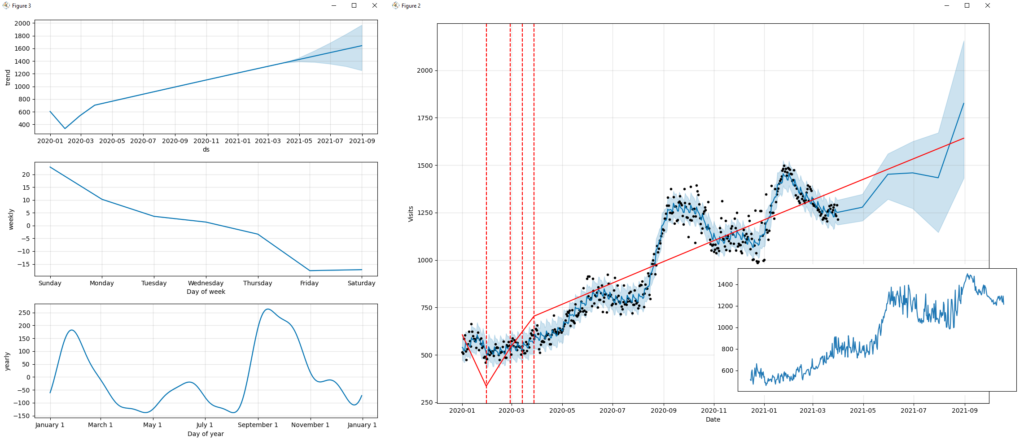
Wizualizacja trendu, sezonowości i prognozy, trendu organicznego ruchu wyszukiwania
Podsumowując, udostępnię kod w całości, więc wystarczy go skopiować i uruchomić w swoim IDE (zintegrowanym środowisku programistycznym) Pythona. Nie trzeba dodawać, że wszystkie wymienione powyżej biblioteki muszą zostać zainstalowane, aby działał poprawnie.
importuj pandy jako PD
importuj fbprophet
z fbprophet import Prophet
z fbprophet.plot importuj add_changepoints_to_plot
importuj matplotlib.pyplot jako plt
importuj system
z google.analytics.data_v1beta import BetaAnalyticsDataClient
z google.analytics.data_v1beta.types importuj DateRange
z google.analytics.data_v1beta.types import Dimension
z google.analytics.data_v1beta.types importuj dane
z google.analytics.data_v1beta.types importuj filtr
z google.analytics.data_v1beta.types importuj FilterExpression
z google.analytics.data_v1beta.types import FilterExpressionList
z google.analytics.data_v1beta.types importuj RunReportRequest
WŁASNOŚĆ_
START_DATE = '2020-01-01'
END_DATE = '2021-03-31'
OKRESY = 4
CZĘSTOT = 'M'
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "[Dodaj tutaj ścieżkę pliku json z poświadczeniami]"
def ga4(identyfikator_właściwości, data_początkowa, data_końcowa):
klient = BetaAnalyticsDataClient()
request = RunReportRequest(property='properties/' + property_id,
wymiary=[Wymiar(nazwa='data')],
metrics=[Metric(name='eventCount')],
zakresy_dat=[Zakres dat(data_początkowa=data_początkowa,
data_końcowa=data_końcowa)],
Dimension_filter=Wyrażenie filtra (
and_group=FilterExpressionList(expressions=[
FilterExpression(filter=Filter(field_name='sessionDefaultChannelGrouping',
string_filter=Filtr.StringFilter(
value='Bezpłatne wyszukiwanie',
match_type=Filtr.StringFilter.MatchType(
1)))),
FilterExpression(filter=Filter(field_name='nazwa zdarzenia',
string_filter=Filtr.StringFilter(
value='session_start',
match_type=Filtr.StringFilter.MatchType(
1))))
]))
)
odpowiedź = client.run_report(żądanie)
x, y = ([] dla i w zakresie(2))
dla wiersza w response.rows:
x.append(wiersz.wymiar_wartości[0].wartość)
y.append(wiersz.metric_values[0].value)
print(row.dimension_values[0].value, row.metric_values[0].value)
zwróć x, y
def prognozowanie (x, y, p, f):
print('Prorok %s' % fbprophet.__version__)
dane = {'ds': x, 'y': y}
df = pd.DataFrame(dane, kolumny=['ds', 'y'])
m = Prorok(wzrost='liniowy',
changepoint_prior_scale=0.5,
seasonity_mode='dodatek',
daily_seasonality=Fałsz,
week_seasonality=Prawda,
yearly_seasonality=Prawda,
święta=Brak,
)
m.fit(df)
future = m.make_future_dataframe(okresy=p, freq=f)
prognoza = m.predict(przyszłość)
print(prognoza[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].head())
fig = m.plot(prognoza, xlabel='Data', ylabel='Wizyty')
add_changepoints_to_plot(rys.gca(), m, prognoza)
m.plot_components(prognoza)
plt.pokaż()
if __name__ == "__main__":
grupa_kanałów, liczba_zdarzeń = ga4(PROPERTY_ID, START_DATE, END_DATE)
prognozowanie (grupa_kanałów, liczba_zdarzeń, OKRESY, CZĘSTOTLIWOŚĆ)
Mam nadzieję, że ten artykuł posłużył jako inspiracja i przyda się w kolejnych projektach. Jeśli chcesz kontynuować naukę o tego rodzaju implementacji lub dowiedzieć się więcej o bardziej technicznym marketingu cyfrowym, skontaktuj się ze mną. Więcej informacji znajdziesz w moim profilu autora poniżej.