
Jak wyodrębnić odpowiednią treść tekstową ze strony HTML?
Opublikowany: 2021-10-13Kontekst
W dziale badawczo-rozwojowym firmy Oncrawl coraz częściej staramy się dodawać wartość do semantycznej zawartości Twoich stron internetowych. Wykorzystując modele uczenia maszynowego do przetwarzania języka naturalnego (NLP), możliwe jest wykonywanie zadań z realną wartością dodaną dla SEO.
Zadania te obejmują czynności takie jak:
- Dostrajanie zawartości Twoich stron
- Dokonywanie automatycznych podsumowań
- Dodawanie nowych tagów do artykułów lub poprawianie istniejących
- Optymalizacja treści zgodnie z danymi z Google Search Console
- itp.
Pierwszym krokiem w tej przygodzie jest wyodrębnienie treści tekstowej ze stron internetowych, z których będą korzystać te modele uczenia maszynowego. Kiedy mówimy o stronach internetowych, obejmuje to HTML, JavaScript, menu, multimedia, nagłówek, stopkę, … Automatyczne i prawidłowe wyodrębnianie treści nie jest łatwe. W tym artykule proponuję zbadać problem i omówić niektóre narzędzia i zalecenia, które pomogą osiągnąć to zadanie.
Problem
Wyodrębnianie treści tekstowej ze strony internetowej może wydawać się proste. Z kilkoma linijkami Pythona, na przykład kilkoma wyrażeniami regularnymi (regexp), biblioteką analizującą, taką jak BeautifulSoup4, i gotowe.
Jeśli zignorujesz na kilka minut fakt, że coraz więcej witryn korzysta z silników renderujących JavaScript, takich jak Vue.js czy React, parsowanie HTML nie jest zbyt skomplikowane. Jeśli chcesz dokładniej rozwiązać ten problem, korzystając z naszego robota JS podczas indeksowania, proponuję przeczytać „Jak indeksować witrynę w JavaScript?”.
Chcemy jednak wyodrębnić tekst, który ma sens, czyli jak najbardziej informacyjny. Kiedy na przykład czytasz artykuł o ostatnim pośmiertnym albumie Johna Coltrane'a, ignorujesz menu, stopkę… i oczywiście nie przeglądasz całej zawartości HTML. Te elementy HTML, które pojawiają się na prawie wszystkich Twoich stronach, nazywają się boilerplate. Chcemy się go pozbyć i zachować tylko część: tekst niosący istotne informacje.
Dlatego właśnie ten tekst chcemy przekazać do przetwarzania modelom uczenia maszynowego. Dlatego tak ważne jest, aby ekstrakcja była jak najbardziej jakościowa.
Rozwiązania
Ogólnie rzecz biorąc, chcielibyśmy pozbyć się wszystkiego, co „wisi” wokół głównego tekstu: menu i innych paneli bocznych, elementów kontaktowych, linków w stopkach itp. Jest na to kilka sposobów. Najbardziej interesują nas projekty Open Source w Pythonie lub JavaScript.
tylkoTekst
jusText to proponowana implementacja w Pythonie z pracy doktorskiej: „Removing Boilerplate and Duplicate Content from Web Corpora”. Metoda umożliwia kategoryzację bloków tekstu z HTML jako „dobry”, „zły”, „zbyt krótki” według różnych heurystyk. Te heurystyki opierają się głównie na liczbie słów, stosunku tekstu do kodu, obecności lub braku linków itp. Więcej o algorytmie można przeczytać w dokumentacji.
trafilatura
trafilatura, również stworzona w Pythonie, oferuje heurystykę dotyczącą zarówno typu elementu HTML, jak i jego zawartości, np. długości tekstu, pozycji/głębokości elementu w HTML lub liczby słów. trafilatura używa również jusText do wykonania pewnych operacji przetwarzania.
czytelność
Czy zauważyłeś kiedyś przycisk na pasku adresu przeglądarki Firefox? To widok czytnika: pozwala usunąć szablon ze stron HTML, aby zachować tylko główną treść tekstową. Całkiem praktyczny w użyciu dla serwisów informacyjnych. Kod tej funkcji jest napisany w JavaScript i jest nazywany przez Mozillę czytelnością. Opiera się na pracach zainicjowanych przez laboratorium Arc90.
Oto przykład renderowania tej funkcji w artykule ze strony France Musique. 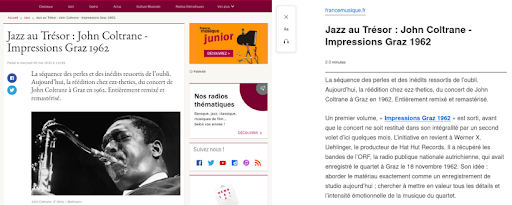
Po lewej fragment oryginalnego artykułu. Po prawej stronie jest to renderowanie funkcji Reader View w Firefoksie.
Inni
Nasze badania nad narzędziami do ekstrakcji treści HTML doprowadziły nas również do rozważenia innych narzędzi:
- gazeta: biblioteka do ekstrakcji treści, poświęcona raczej serwisom informacyjnym (Python). Ta biblioteka była używana do wyodrębniania treści z korpusu OpenWebText2.
- boilerpy3 to port Pythona biblioteki boilerpipe.
- Biblioteka dragnet Python również inspirowana boilerpipe.
Dane dotyczące indeksowania³
 Ucz się więcej
Ucz się więcejOcena i rekomendacje
Przed oceną i porównaniem różnych narzędzi chcieliśmy się dowiedzieć, czy społeczność NLP używa niektórych z tych narzędzi do przygotowania swojego korpusu (duży zestaw dokumentów). Na przykład zestaw danych o nazwie The Pile używany do trenowania GPT-Neo zawiera +800 GB tekstów w języku angielskim z Wikipedii, Openwebtext2, Github, CommonCrawl itp. Podobnie jak BERT, GPT-Neo to model języka, który wykorzystuje transformatory typów. Oferuje implementację open-source podobną do architektury GPT-3.

Artykuł „The Pile: An 800GB Dataset of Diverse Text for Language Modeling” wspomina o użyciu jusText dla dużej części ich korpusu z CommonCrawl. Ta grupa badaczy zaplanowała również wykonanie testu porównawczego różnych narzędzi do ekstrakcji. Niestety nie byli w stanie wykonać zaplanowanej pracy z powodu braku środków. W ich konkluzjach należy zauważyć, że:
- jusText czasami usuwał zbyt wiele treści, ale nadal zapewniał dobrą jakość. Biorąc pod uwagę ilość posiadanych danych, nie stanowiło to dla nich problemu.
- trafilatura była lepsza w zachowywaniu struktury strony HTML, ale zachowywała zbyt dużo schematu.
Do naszej metody oceny wzięliśmy około trzydziestu stron internetowych. Główną treść wyodrębniliśmy „ręcznie”. Następnie porównaliśmy wyodrębnianie tekstu z różnych narzędzi z tak zwaną treścią „referencyjną”. Jako metryki użyliśmy wyniku ROUGE, który jest używany głównie do oceny automatycznych podsumowań tekstowych.
Porównaliśmy również te narzędzia z „domowym” narzędziem opartym na regułach parsowania HTML. Okazuje się, że trafilatura, jusText i nasze domowe narzędzie radzą sobie lepiej niż większość innych narzędzi dla tego wskaźnika.
Oto tabela średnich i odchyleń standardowych wyniku ROUGE:
| Narzędzia | Oznaczać | Standardowy |
|---|---|---|
| trafilatura | 0,783 | 0,28 |
| Oncrawl | 0,779 | 0,28 |
| tylkoTekst | 0,735 | 0,33 |
| kocioł3 | 0,698 | 0,36 |
| czytelność | 0,681 | 0,34 |
| włóczek | 0,672 | 0,37 |
Biorąc pod uwagę wartości odchyleń standardowych, należy zauważyć, że jakość ekstrakcji może się znacznie różnić. Sposób implementacji HTML, spójność tagów i odpowiednie użycie języka może powodować wiele różnic w wynikach ekstrakcji.
Trzy narzędzia, które działają najlepiej, to trafilatura, nasze wewnętrzne narzędzie o nazwie „oncrawl” specjalnie na tę okazję i jusText. Ponieważ jusText jest używany przez trafilatura jako rozwiązanie awaryjne, zdecydowaliśmy się użyć trafilatura jako naszego pierwszego wyboru. Jednak gdy to drugie zawiedzie i nie wyodrębni zero słów, stosujemy własne zasady.
Zauważ, że kod trafilatura oferuje również benchmark na kilkuset stronach. Oblicza wyniki precyzji, wynik f1 i dokładność na podstawie obecności lub nieobecności pewnych elementów w wyodrębnionej treści. Wyróżniają się dwa narzędzia: trafilatura i gęś3. Możesz również przeczytać:
- Wybór odpowiedniego narzędzia do wyodrębniania treści z sieci (2020)
- repozytorium Github: benchmark ekstrakcji artykułów: biblioteki open-source i usługi komercyjne
Wnioski
Jakość kodu HTML i niejednorodność typu strony utrudnia wyodrębnienie wysokiej jakości treści. Jak odkryli badacze EleutherAI, którzy stoją za The Pile i GPT-Neo, nie ma doskonałych narzędzi. Istnieje kompromis między czasami obciętą treścią a szumem szczątkowym w tekście, gdy nie został usunięty cały szablon.
Zaletą tych narzędzi jest brak kontekstu. Oznacza to, że do wyodrębnienia treści nie potrzebują żadnych danych poza kodem HTML strony. Korzystając z wyników Oncrawl, moglibyśmy wyobrazić sobie hybrydową metodę wykorzystującą częstotliwości występowania określonych bloków HTML na wszystkich stronach serwisu do zaklasyfikowania ich jako boilerplate.
Jeśli chodzi o zbiory danych używane w testach porównawczych, na które natrafiliśmy w sieci, często są to strony tego samego typu: artykuły z wiadomościami lub wpisy na blogu. Niekoniecznie obejmują one witryny ubezpieczeniowe, biura podróży, e-commerce itp., w których wyodrębnienie treści tekstowej jest czasem bardziej skomplikowane.
W odniesieniu do naszego testu porównawczego oraz z powodu braku zasobów zdajemy sobie sprawę, że około trzydziestu stron to za mało, aby uzyskać bardziej szczegółowy obraz wyników. W idealnej sytuacji chcielibyśmy mieć większą liczbę różnych stron internetowych, aby doprecyzować nasze wartości porównawcze. Chcielibyśmy również dołączyć inne narzędzia, takie jak goose3, html_text czy inscriptis.