
Wyodrębnij dane z Google Search Console API do analizy danych w Pythonie
Opublikowany: 2022-03-01Google Search Console (GSC) jest zdecydowanie jednym z najbardziej przydatnych narzędzi dla specjalistów SEO, ponieważ pozwala uzyskać informacje o pokryciu indeksu, a zwłaszcza o zapytaniach, dla których aktualnie jesteś w rankingu. Wiedząc o tym, wiele osób analizuje dane GSC za pomocą arkuszy kalkulacyjnych i jest w porządku, o ile rozumiesz, że jest znacznie więcej miejsca na ulepszenia za pomocą narzędzi, takich jak języki programowania.
Niestety interfejs GSC jest dość ograniczony zarówno pod względem wyświetlanych wierszy (tylko 5000), jak i dostępnego okresu, tylko 16 miesięcy. Oczywiste jest, że może to poważnie ograniczyć możliwość uzyskiwania wglądu i nie jest odpowiednie dla większych witryn.
Python pozwala z łatwością uzyskiwać dane GSC i automatyzować bardziej złożone obliczenia, które wymagałyby znacznie więcej wysiłku w tradycyjnym oprogramowaniu do arkuszy kalkulacyjnych.
Jest to rozwiązanie jednego z największych problemów w Excelu, a mianowicie limitu wierszy i szybkości. W dzisiejszych czasach masz o wiele więcej alternatyw do analizy danych niż wcześniej i tu właśnie pojawia się Python.
Aby skorzystać z tego samouczka, nie potrzebujesz żadnej zaawansowanej wiedzy o kodowaniu, wystarczy zrozumieć kilka podstawowych pojęć i trochę praktyki z Google Colab.
Pierwsze kroki z interfejsem API Google Search Console
Zanim zaczniemy, ważne jest, aby skonfigurować interfejs Google Search Console API. Proces jest dość prosty, wystarczy konto Google. Kroki są następujące:
- Utwórz nowy projekt w Google Cloud Platform. Powinieneś mieć konto Google i jestem pewien, że je masz. Przejdź do konsoli, a na górze powinieneś znaleźć opcję tworzenia nowego projektu.
- Kliknij menu po lewej stronie i wybierz „API i usługi”, przejdziesz do kolejnego ekranu.
- Na pasku wyszukiwania u góry znajdź „Google Search Console API” i włącz go.
- Następnie przejdź do zakładki „Poświadczenia”, potrzebujesz jakiegoś uprawnienia do korzystania z interfejsu API.
- Skonfiguruj ekran „zgoda”, ponieważ jest to obowiązkowe. Nie ma znaczenia, do jakiego użytku zamierzamy wykorzystać, czy będzie to publiczne, czy nie.
- Możesz wybrać „Aplikację na komputer” jako typ aplikacji
- W tym samouczku użyjemy OAuth 2.0. Powinieneś pobrać plik json i gotowe.
W rzeczywistości jest to najtrudniejsza część dla większości ludzi, zwłaszcza tych, którzy nie są przyzwyczajeni do interfejsów Google API. Nie martw się, kolejne kroki będą znacznie prostsze i mniej problematyczne.
Pobieranie danych z Google Search Console API za pomocą Pythona
Zalecam korzystanie z notatnika, takiego jak Jupyter Notebook lub Google Colab. To drugie jest lepsze, ponieważ nie musisz się martwić o wymagania. Dlatego to, co zamierzam wyjaśnić, opiera się na Google Colab.
Zanim zaczniemy, zaktualizuj swój plik json do Google Colab za pomocą następującego kodu:
z plików importu google.colab files.upload()
Następnie zainstalujmy wszystkie biblioteki, których będziemy potrzebować do naszej analizy i zróbmy lepszą wizualizację tabeli za pomocą tego fragmentu kodu:
%%zdobyć #załaduj to, co jest potrzebne !pip zainstaluj git+https://github.com/joshcarty/google-searchconsole importuj pandy jako PD importuj numer jako np importuj matplotlib.pyplot jako plt z google.colab importuj tabelę_danych !Klon git https://github.com/jroakes/querycat.git !pip install -r querycat/requirements_colab.txt !pip zainstaluj umap-learn data_table.enable_dataframe_formatter() #dla lepszej wizualizacji tabeli
Na koniec możesz załadować bibliotekę searchconsole, która oferuje najłatwiejszy sposób na zrobienie tego bez polegania na długich funkcjach. Uruchom poniższy kod z argumentami, których używam i upewnij się, że client_config ma taką samą nazwę, jak przesłany plik json.
importuj konsolę wyszukiwania konto = searchconsole.authenticate(client_config='client_secret_.json',serialize='credentials.json', flow='console')
Zostaniesz przekierowany na stronę Google do autoryzacji aplikacji, wybierz swoje konto Google, a następnie skopiuj i wklej kod, który otrzymasz w pasku Google Colab.
Jeszcze nie skończyliśmy, musisz wybrać nieruchomość, dla której będziesz potrzebować danych. Możesz łatwo sprawdzić swoje właściwości za pośrednictwem account.webproperties, aby zobaczyć, co należy wybrać.
property_name = input('Wstaw nazwę swojej witryny zgodnie z GSC: ')
webproperty=account[str(property_name)]
Gdy skończysz, uruchomisz niestandardową funkcję, aby utworzyć obiekt zawierający nasze dane.
def extract_gsc_data(webproperty, start, stop, *args):
jeśli usługa internetowa nie jest Brak:
print(f'Wyodrębnianie danych dla {webproperty}')
gsc_data = webproperty.query.range(start, stop).dimension(*args).get()
zwróć dane_gsc
w przeciwnym razie:
print('Nie znaleziono usługi internetowej, wybierz właściwą')
powrót Brak
Ideą funkcji jest pobranie właściwości, którą zdefiniowałeś wcześniej i ram czasowych, w postaci dat rozpoczęcia i zakończenia, wraz z wymiarami.
Wybór możliwości wyboru wymiarów jest kluczowy dla specjalistów SEO, ponieważ pozwala zrozumieć, czy potrzebujesz określonego poziomu szczegółowości. Na przykład w niektórych przypadkach możesz nie być zainteresowany uzyskaniem wymiaru daty.
Proponuję zawsze wybierać zapytanie i stronę, ponieważ interfejs Google Search Console może je eksportować osobno i bardzo denerwujące jest ich łączenie za każdym razem. To kolejna zaleta interfejsu API Search Console.
W naszym przypadku możemy również bezpośrednio uzyskać wymiar daty, aby pokazać kilka ciekawych scenariuszy, w których trzeba wziąć pod uwagę czas.
ex = extract_gsc_data(usługa internetowa, '2021-09-01', '2021-12-31', 'zapytanie', 'strona', 'data')
Wybierz odpowiednie ramy czasowe, biorąc pod uwagę, że na większe nieruchomości będziesz musiał długo czekać. W tym przykładzie rozważam tylko 3 miesiące, które wystarczają średnio, aby uzyskać cenne informacje z większości zestawów danych.
Możesz wybrać nawet jeden tydzień, jeśli masz do czynienia z ogromną ilością danych, to na czym nam zależy to proces.
To, co ci tutaj pokażę, jest oparte albo na danych syntetycznych, albo na zmodyfikowanych danych rzeczywistych, aby nadawały się do przykładów. W rezultacie to, co tutaj widzisz, jest całkowicie realistyczne i może odzwierciedlać rzeczywiste scenariusze.
Czyszczenie danych
Dla tych, którzy nie wiedzą, nie możemy używać naszych danych w takim stanie, w jakim są, istnieją dodatkowe kroki, aby upewnić się, że działamy poprawnie. Przede wszystkim musimy skonwertować nasz obiekt do dataframe Pandas, struktury danych, którą musisz znać, ponieważ jest to podstawa analizy danych w Pythonie.
df = pd.DataFrame(dane=ex) df.głowa()
Metoda head może pokazać pierwsze 5 wierszy twojego zestawu danych, jest bardzo przydatna, aby rzucić okiem na to, jak wyglądają twoje dane. Możemy policzyć, ile mamy stron, korzystając z prostej funkcji.
Dobrym sposobem na usunięcie duplikatów jest przekształcenie obiektu w zestaw, ponieważ zestawy nie mogą zawierać zduplikowanych elementów.
Niektóre fragmenty kodu zostały zainspirowane notatnikiem Hamleta Batisty, a inny od Masakiego Okazawy.
Usuwanie haseł związanych z marką
Pierwszą rzeczą do zrobienia jest usunięcie markowych słów kluczowych, szukamy tych zapytań, które nie zawierają naszych markowych haseł. Jest to dość proste w przypadku funkcji niestandardowej i zwykle masz zestaw markowych terminów.
W celach demonstracyjnych nie musisz odfiltrowywać ich wszystkich, ale zrób to dla prawdziwych analiz. Jest to jeden z najważniejszych etapów czyszczenia danych w SEO, w przeciwnym razie ryzykujesz przedstawienie mylących wyników.
domain_name = str(input('Wstaw terminy związane z marką oddzielone przecinkiem: ')).replace(',', '|')
importuj ponownie
nazwa_domeny = re.sub(r"\s+", "", nazwa_domeny)
print('Usuń wszystkie spacje za pomocą RegEx:\n')
df['Marka/Niemarkowe'] = np.where(
df['query'].str.contains(nazwa_domeny), 'Marka', 'Bez marki'
)
Zamierzamy dodać nową kolumnę do naszego zbioru danych, aby rozpoznać różnicę między dwiema klasami. Możemy wizualizować za pomocą tabel lub wykresów słupkowych, ile stanowią one dla łącznej liczby zapytań.
Nie pokażę ci wykresu słupkowego, ponieważ jest bardzo prosty i myślę, że w tym przypadku lepszy jest stół.
brand_count_df = df['Markowe/Niemarkowe'].value_counts().rename_axis('cats').to_frame('counts')
brand_count_df['Procent'] = brand_count_df['liczba']/sum(brand_count_df['liczba'])
pd.options.display.float_format = '{:.2%}'.format
brand_count_df
Możesz szybko sprawdzić, jaki jest stosunek między słowami kluczowymi związanymi z marką a niemarkowymi, aby zorientować się, ile zamierzasz usunąć ze swojego zbioru danych. Nie ma tu idealnego stosunku, chociaż zdecydowanie chcesz mieć wyższy odsetek słów kluczowych niezwiązanych z marką.
Następnie możemy po prostu usunąć wszystkie wiersze oznaczone jako markowe i przejść do innych kroków.
#tylko wybieraj słowa kluczowe niezwiązane z marką df = df.loc[df['Markowe/niemarkowe'] == 'Bezmarkowe']
Uzupełnianie brakujących wartości i inne kroki
Jeśli Twój zbiór danych zawiera brakujące wartości (lub NA w żargonie), masz kilka opcji. Najczęstsze to usunięcie ich wszystkich lub wypełnienie ich wartością zastępczą, taką jak 0 lub średnią tej kolumny.
Nie ma prawidłowej odpowiedzi, a oba podejścia mają swoje wady i zalety, a także ryzyko. W przypadku danych Google Search Console najlepszą radą jest umieszczenie wartości zastępczej, takiej jak 0, aby nie docenić wpływu niektórych wskaźników.
df.fillna(0, miejsce = Prawda)
Zanim przejdziemy do faktycznej analizy danych, musimy dostosować nasze funkcje, a mianowicie kolumny naszego zbioru danych. Pozycja jest szczególnie interesująca, ponieważ chcemy ją wykorzystać w niektórych fajnych tabelach przestawnych.
Możemy zaokrąglić pozycję do liczby całkowitej, co służy naszemu celowi.
df['pozycja'] = df['pozycja'].round(0).astype('int64')
Należy wykonać wszystkie pozostałe kroki czyszczenia opisane powyżej, a następnie dostosować kolumnę daty.
Wydobywamy miesiące i lata za pomocą pand. Nie musisz być tak konkretny, jeśli pracujesz w krótszych ramach czasowych, jest to przykład, który uwzględnia pół roku.
#konwertuj datę do właściwego formatu df['data'] = pd.to_datetime(df['data']) #wyciąg miesięcy df['miesiąc'] = df['data'].dt.miesiąc #wyciąg lat df['rok'] = df['data'].dt.rok
[Ebook] SEO danych: kolejna wielka przygoda
 Przeczytaj ebook
Przeczytaj ebookAnaliza danych rozpoznawczych
Główną zaletą Pythona jest to, że możesz robić to samo, co w Excelu, ale z wieloma opcjami i łatwiej. Zacznijmy od czegoś, co każdy analityk zna naprawdę dobrze: tabel przestawnych.
Analiza średniego CTR na grupę pozycji
Analiza śr. CTR na grupę pozycji to jedno z najbardziej wnikliwych działań, ponieważ pozwala zrozumieć ogólną sytuację serwisu. Zastosuj oś, a następnie wykreślmy ją.
pd.options.display.float_format = '{:.2%}'.format
zapytanie_analiza = df.pivot_table(indeks=['pozycja'], values=['ctr'], aggfunc=['średnia'])
query_analysis.sort_values(by=['position'], ascending=True).head(10)
topór = query_analysis.head(10).plot(kind='bar')
ax.set_xlabel('Śr. pozycja')
ax.set_ylabel('CTR')
ax.set_title('CTR wg śr. pozycji')
siekiera.grid('w')
ax.get_legend().remove()
plt.xticks(obrót=0)
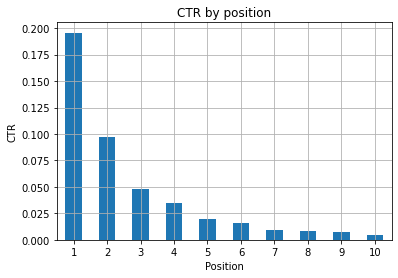
Rysunek 1: Przedstawienie CTR według pozycji w celu wykrycia anomalii.
Idealnym scenariuszem jest tutaj posiadanie lepszego CTR po lewej stronie wykresu, ponieważ zwykle pozycja 1 powinna mieć znacznie wyższy CTR. Bądź jednak ostrożny, możesz zobaczyć przypadki, w których pierwsze 3 miejsca mają niższy niż oczekiwany CTR i musisz to zbadać.
Proszę również wziąć pod uwagę skrajne przypadki, na przykład takie, w których pozycja 11 jest lepsza niż pierwsza. Jak wyjaśniono w dokumentacji Google dotyczącej Search Console, te dane nie są zgodne z kolejnością, o której myślisz na początku.
Ponadto dodaje, że jest to średnia, ponieważ pozycja linku zmienia się za każdym razem i nie można uzyskać 100% dokładności.
Czasami Twoje strony mają wysoką pozycję, ale nie są wystarczająco przekonujące, więc możesz spróbować poprawić tytuł. Ponieważ jest to ogólny przegląd, nie zobaczysz szczegółowych różnic, więc spodziewaj się szybkiego działania, jeśli problem występuje na dużą skalę.
Pamiętaj też, że grupa stron na niższych pozycjach ma wyższy średni CTR niż te na lepszych pozycjach.
Z tego powodu możesz chcieć rozszerzyć swoją analizę do pozycji 15 lub więcej, aby wykryć dziwne wzorce.
Liczba zapytań na pozycję i mierzenie działań SEO
Wzrost liczby zapytań, dla których zajmujesz pozycję w rankingu, jest zawsze dobrym sygnałem, ale niekoniecznie oznacza to lepsze rankingi w przyszłości. Licznik zapytań to proces liczenia liczby zapytań, dla których tworzysz ranking i jest to jedno z najważniejszych zadań, które możesz wykonać z danymi GSC.
Po raz kolejny bardzo pomocne są tabele przestawne, dzięki którym możemy wykreślić wyniki.
ranking_queries = df.pivot_table(indeks=['pozycja'], values=['zapytanie'], aggfunc=['liczba']) ranking_queries.sort_values(by=['pozycja']).head(10)
Jako specjalista SEO chcesz mieć większą liczbę zapytań po lewej stronie, na najwyższych pozycjach. Powód jest całkiem naturalny, wysokie pozycje uzyskują średnio lepszy CTR, co może przełożyć się na większą liczbę osób klikających na Twoją stronę.
topór = ranking_queries.head(10).plot(rodzaj='bar')
ax.set_ylabel('Liczba zapytań')
ax.set_xlabel('Pozycja')
ax.set_title('Rozkład rankingu')
siekiera.grid('w')
ax.get_legend().remove()
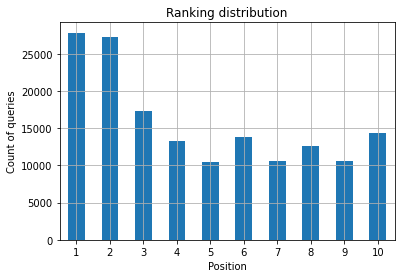
Rysunek 2: Ile mam zapytań według pozycji?
To, na czym ci zależy, to zwiększenie liczby zapytań na najwyższych pozycjach w miarę upływu czasu.
Zabawa z wymiarem daty
Zobaczmy, jak kliknięcia zmieniają się w rozważanym przedziale czasu, najpierw zmierzmy sumę kliknięć:
clicks_sum = df.groupby('data')['clicks'].sum()
Grupujemy dane według wymiaru daty i otrzymujemy sumę kliknięć dla każdego z nich, to rodzaj podsumowania.
Jesteśmy teraz gotowi do wykreślenia tego, co mamy, kod będzie dość długi tylko po to, aby poprawić wizualizację, nie bój się tego.

# Suma kliknięć w okresie
%config InlineBackend.figure_format = 'siatkówka'
z rysunku importu matplotlib.pyplot
figura(rozmiar=(8, 6), dpi=80)
topór = clicks_sum.plot(color='red')
siekiera.grid('w')
ax.set_ylabel('Suma kliknięć')
ax.set_xlabel('Miesiąc')
ax.set_title('Jak zmieniały się kliknięcia w ciągu miesiąca')
xlab = ax.xaxis.get_label()
ylab = ax.yaxis.get_label()
xlab.set_style('kursywa')
xlab.set_size(10)
ylab.set_style('kursywa')
ylab.set_size(10)
ttl = topór.tytuł
ttl.set_weight('pogrubienie')
ax.spines['right'].set_color((.8,.8,.8))
ax.spines['top'].set_color((.8,.8,.8))
ax.yaxis.set_label_coords (-.15, .50)
ax.fill_between(clicks_sum.index, clicks_sum.values, facecolor='yellow')
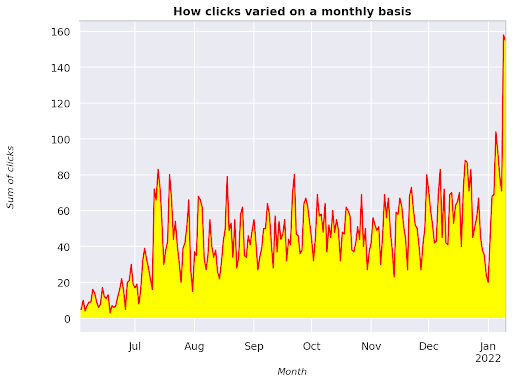
Rysunek 3: Wykres sumy kliknięć w odniesieniu do zmiennej miesiąca
To jest przykład od czerwca 2021 do połowy stycznia 2022. Wszystkie linie, które widzisz powyżej, mają za zadanie upiększyć tę wizualizację, możesz spróbować się z nią pobawić, aby zobaczyć, co się stanie.
Liczba zapytań na pozycję, miesięczny zrzut
Kolejną fajną wizualizacją, którą możemy narysować w Pythonie, jest mapa cieplna, która jest jeszcze bardziej wizualna niż prosty wykres słupkowy. Pokażę Ci, jak wyświetlać liczbę zapytań w czasie i według ich pozycji.
importuj seaborn jako sns sns.set_theme() df_new = df.loc[(df['pozycja'] <= 10) & (df['rok'] != 2022),:] # Załaduj przykładowy zestaw danych lotów i przekonwertuj na długą formę df_heat = df_new.pivot_table(indeks = "pozycja", kolumny = "miesiąc", wartości = "zapytanie", aggfunc='liczba') # Narysuj mapę termiczną z wartościami liczbowymi w każdej komórce f, ax = plt.subplots(figsize=(20, 12)) x_axis_labels = ["wrzesień", "październik", "listopad", "grudzień"] sns.heatmap(df_heat, annot=True, linewidths=.5, ax=ax, fmt='g', cmap = sns.cm.rocket_r, xticklabels=x_axis_labels) ax.set(xlabel = 'Miesiąc', ylabel='Pozycja', title = 'Jak liczba zapytań na pozycję zmienia się w czasie') #rotate Etykiety pozycji, aby były bardziej czytelne plt.yticks(obrót=0)
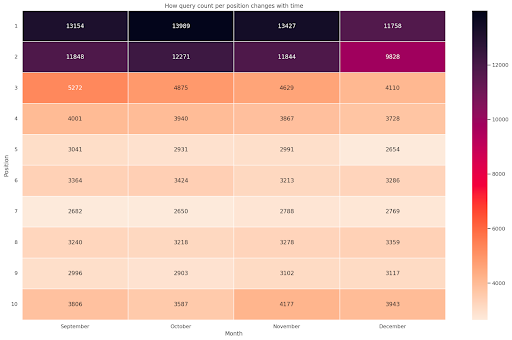
Rysunek 4: Mapa termiczna pokazująca postęp liczenia zapytań według pozycji i miesiąca.
To jedna z moich ulubionych map cieplnych, które mogą być dość skuteczne w wyświetlaniu tabel przestawnych, takich jak w tym przykładzie. Okres ten obejmuje ponad 4 miesiące, a jeśli przeczytasz go w poziomie, możesz zobaczyć, jak zmienia się liczba zapytań w miarę upływu czasu. Na pozycji 10 masz niewielki wzrost od września do grudnia, ale na pozycji 2 masz uderzający spadek, co pokazuje fioletowy kolor.
W poniższym scenariuszu większość zapytań znajduje się na najwyższych pozycjach, co może być uderzająco nietypowe. Jeśli tak się stanie, możesz chcieć wrócić i przeanalizować ramkę danych, szukając możliwych terminów markowych, jeśli takie istnieją.
Jak widać z kodu, tworzenie skomplikowanych wykresów nie jest takie trudne, o ile masz za sobą logikę.
Liczba zapytań powinna rosnąć z czasem, jeśli robisz „właściwe” rzeczy, a my możemy wykreślić różnicę w dwóch różnych ramach czasowych. W podanym przeze mnie przykładzie wyraźnie tak nie jest, zwłaszcza w przypadku najwyższych pozycji, gdzie powinieneś mieć wyższy CTR.
Przedstawiamy podstawowe koncepcje NLP
Przetwarzanie języka naturalnego (NLP) jest darem niebios dla SEO i nie musisz być ekspertem, aby zastosować podstawowe algorytmy. N-gramy to jeden z najpotężniejszych, ale najprostszych pomysłów, które pozwalają uzyskać wgląd w dane GSC.
N-gramy to ciągłe ciągi liter, sylab lub słów. Dla naszej analizy jednostką miary będą słowa. N-gram nazywamy bigramem, gdy sąsiednie elementy to dwa (para), a trygram to trzy, i tak dalej. Proponuję przetestować z różnymi kombinacjami i podnieść maksymalnie do 5 gramów.
W ten sposób jesteś w stanie dostrzec najczęstsze zdania na stronach konkurencji lub ocenić własne. Ponieważ Google może polegać na indeksowaniu opartym na frazach, lepiej jest optymalizować pod kątem zdań, a nie poszczególnych słów kluczowych, jak pokazują patenty Google dotyczące tego tematu.
Jak stwierdził na powyższej stronie sam Bill Slawski, wartość zrozumienia powiązanych terminów ma wielką wartość dla optymalizacji i dla użytkowników.
Biblioteka nltk jest bardzo znana z aplikacji NLP i daje nam możliwość usunięcia słów stop w danym języku, takim jak angielski. Pomyśl o nich jako o szumie, który chcesz usunąć, w rzeczywistości artykuły i bardzo częste słowa nie dodają żadnej wartości w zrozumieniu tekstu.
importuj nltk
nltk.download('stopwords')
z nltk.corpus import stopwords
stoplist = stopwords.words('angielski')
ze sklearn.feature_extraction.text import CountVectorizer
c_vec = CountVectorizer(stop_words=stoplist, ngram_range=(2,3))
# macierz ngramów
ngrams = c_vec.fit_transform(df['zapytanie'])
# zliczanie częstotliwości ngramów
count_values = ngrams.toarray().sum(oś=0)
# lista ngramów
słownictwo = c_vec.słownictwo_
df_ngram = pd.DataFrame(sorted([(liczba_wartości[i],k) dla k,i w vocab.items()], reverse=True)
).rename(kolumny={0: 'częstotliwość', 1:'bigram/trygram'})
df_ngram.head(20).style.background_gradient()
Bierzemy kolumnę zapytania i liczymy częstotliwość bi-gramów, aby utworzyć ramkę danych przechowującą bi-gramy i ich liczbę wystąpień.
Ten krok jest w rzeczywistości bardzo ważny, aby przeanalizować również witryny konkurencji. Możesz po prostu zeskrobać ich tekst i sprawdzić, jakie są najczęstsze n-gramy, dostrajając n za każdym razem, aby zobaczyć, czy zauważysz różne wzorce na stronach o wysokim rankingu.
Jeśli zastanowisz się nad tym przez chwilę, ma to o wiele więcej sensu, ponieważ pojedyncze słowo kluczowe nie mówi nic o kontekście.
Nisko wiszące owoce
Jedną z najpiękniejszych rzeczy do zrobienia jest sprawdzenie nisko wiszących owoców, tych stron, które można łatwo poprawić, aby jak najszybciej uzyskać dobre wyniki. Jest to kluczowe w pierwszych krokach każdego projektu SEO, aby przekonać interesariuszy. Dlatego jeśli istnieje możliwość wykorzystania takich stron, po prostu zrób to!
Nasze kryteria uznania strony za taką to kwantyle wyświetleń i CTR. Innymi słowy, filtrujemy wiersze, które znajdują się w 80% najwyższych wyświetleń, ale znajdują się w 20%, które uzyskują najniższy CTR. Te wiersze będą miały gorszy CTR niż 80% pozostałych.
top_impressions = df[df['impressions'] >= df['impressions'].quantile(0.8)]
(top_impressions[top_impressions['ctr'] <= top_impressions['ctr'].quantile(0.2)].sort_values('impressions', ascending = False))
Teraz masz listę ze wszystkimi możliwościami posortowanymi według Wyświetleń w kolejności malejącej.
Możesz pomyśleć o innych kryteriach, aby określić, co jest nisko wiszącym owocem, zgodnie z potrzebami Twojej witryny i jej rozmiarem.
W przypadku mniejszych witryn możesz rozważyć szukanie wyższych wartości procentowych, podczas gdy w dużych witrynach powinieneś już uzyskać dużo informacji z kryteriami, których używam.
[Ebook] Techniczne SEO dla myślicieli nietechnicznych
 Przeczytaj ebook
Przeczytaj ebookPrzedstawiamy querycat: klasyfikacja i asocjacje
Querycat to prosta, ale potężna biblioteka, która umożliwia eksplorację reguł asocjacji dla słów kluczowych grupujących i wiele więcej. Pokażę tylko skojarzenia, ponieważ są one bardziej wartościowe w tego typu analizach.
Możesz dowiedzieć się więcej o tej niesamowitej bibliotece, zaglądając do repozytorium querycat GitHub.
Krótkie wprowadzenie do nauki reguł asocjacyjnych
Nauka reguł asocjacyjnych to metoda znajdowania reguł, które definiują asocjacje i współwystępowania w zestawach elementów. Różni się to nieco od innej nienadzorowanej metody uczenia maszynowego, tzw. klastrowania.
Cel końcowy jest jednak taki sam, uzyskanie klastrów słów kluczowych, aby zrozumieć, jak nasza witryna radzi sobie w przypadku niektórych tematów.
Querycat daje Ci możliwość wyboru pomiędzy dwoma algorytmami: Apriori i FP-Growth. Zamierzamy wybrać to drugie, aby uzyskać lepsze wyniki, więc możesz zignorować to pierwsze.
FP-Growth to ulepszona wersja Apriori do wyszukiwania częstych wzorców w zestawach danych. Nauka reguł asocjacyjnych jest również bardzo przydatna w przypadku transakcji e-commerce, na przykład możesz być zainteresowany zrozumieniem, co ludzie kupują razem.
W tym przypadku skupiamy się wyłącznie na zapytaniach, ale inna aplikacja, o której wspomniałem, może być kolejnym przydatnym pomysłem na dane Google Analytics.
Wyjaśnienie tych algorytmów z perspektywy struktury danych jest dość trudne i moim zdaniem nie jest konieczne do zadań SEO. Wyjaśnię tylko kilka podstawowych pojęć, aby zrozumieć, co oznaczają parametry.
3 główne elementy 2 algorytmów to:
- Wsparcie — wyraża popularność przedmiotu lub zestawu przedmiotów. Mówiąc technicznie, jest to liczba transakcji, w których zapytanie X i zapytanie Y występują razem, podzielona przez całkowitą liczbę transakcji.
Co więcej, może służyć jako próg do usuwania rzadkich przedmiotów. Bardzo przydatne do zwiększania istotności statystycznej i wydajności. Ustalenie dobrego minimalnego wsparcia jest bardzo dobre. - Zaufanie – możesz o tym myśleć jako o prawdopodobieństwie współwystępowania warunków.
- Wzrost – Stosunek między wsparciem (termin 1 i termin 2) a wsparciem terminu 1. Możemy spojrzeć na jego wartość, aby uzyskać wgląd w relacje między terminami. Jeśli jest większy niż 1, warunki są skorelowane; jeśli mniej niż 1, terminy prawdopodobnie nie będą miały związku: jeśli wzrost wynosi dokładnie 1 (lub blisko), nie ma znaczącego związku.
Dalsze szczegóły znajdują się w tym artykule o querycat napisanym przez autora biblioteki.
Teraz jesteśmy gotowi do przejścia do części praktycznej.
importuj zapytaniecat
query_cat = querycat.Categorize(df, 'zapytanie', min_support=10, alg='fpwzrost')
dfgrouped = df.groupby('kategoria').agg(sumclicks = ('kliknięcia', 'sum')).sort_values('sumclicks', ascending=False)
#utwórz grupę, aby filtrować kategorie z mniej niż 15 kliknięciami (dowolna liczba)
filtergroup = dfgrouped[dfgrouped['sumclicks'] > 15]
grupa filtrów
#nałóż filtr
df = df.merge(grupa filtrów, on=['kategoria','kategoria'], how='wewnętrzna')
W tym procesie przefiltrowaliśmy rzadsze kategorie, w moim przypadku wybrałem 15 jako punkt odniesienia. To tylko dowolna liczba, nie ma za nią żadnego kryterium.
Sprawdźmy nasze kategorie za pomocą następującego fragmentu:
df['kategoria'].value_counts()
A co z 10 najczęściej klikanymi kategoriami? Sprawdźmy ile zapytań mamy dla każdego z nich.
df.groupby('kategoria').sum()['kliknięcia'].sort_values(rosnąco=fałsz).head(10)
Liczba do wyboru jest dowolna, pamiętaj, aby wybrać taką, która odfiltruje dobry procent grup. Jednym z potencjalnych pomysłów jest uzyskanie mediany wyświetleń i obniżenie najniższego 50%, pod warunkiem, że chcesz wykluczyć małe grupy.
Pobieranie klastrów i co zrobić z danymi wyjściowymi
Zalecam wyeksportowanie nowej ramki danych, aby uniknąć ponownego uruchamiania FP-Growth. Zrób to, aby zaoszczędzić przydatny czas.
Gdy tylko masz klastry, chcesz poznać kliknięcia i wyświetlenia dla każdego z nich, aby ocenić, które obszary wymagają największej poprawy.
grouped_df = df.groupby('kategoria')[['kliknięcia', 'wyświetlenia']].agg('suma')
Dzięki pewnym manipulacjom danymi jesteśmy w stanie poprawić nasze wyniki skojarzeń i uzyskać kliknięcia i wyświetlenia dla każdego klastra.
group_ex = df.groupby(['kategoria'])['zapytanie'].apply(' | '.join).reset_index()
#usuń zduplikowane zapytania, a następnie posortuj je alfabetycznie
group_ex['query'] = group_ex['query'].apply(lambda x: ' | '.join(sorted(list(set(x.split('|'))))))
df_final = group_ex.merge(grouped_df, on=['kategoria', 'kategoria'], how='inner')
df_final.head()
Masz teraz plik CSV ze wszystkimi grupami słów kluczowych wraz z kliknięciami i wyświetleniami.
#zapisz plik csv i pobierz go na swój komputer lokalny. Jeśli korzystasz z Safari, rozważ przejście na Chrome w celu pobrania tych plików, ponieważ może to nie działać.
df_final.to_csv('clusters_queries.csv')
files.download('clusters_queries.csv')
W rzeczywistości istnieją lepsze metody klastrowania, jest to tylko przykład tego, jak używać querycat do wykonywania wielu zadań do natychmiastowego użycia. Głównym celem tutaj jest uzyskanie jak największej ilości informacji, szczególnie w przypadku nowych witryn internetowych, na których nie masz tak dużej wiedzy.
Obecnie najlepsze podejścia obejmują semantykę, więc jeśli chcesz skupić się na grupowaniu, sugeruję, abyś rozważył naukę wykresów lub osadzania.
Są to jednak zaawansowane tematy, jeśli jesteś nowicjuszem i możesz po prostu wypróbować kilka gotowych aplikacji Streamlit dostępnych online.
Dane dotyczące indeksowania³
 Ucz się więcej
Ucz się więcejWniosek i co dalej
Python może zaoferować dużą pomoc w analizie Twojej witryny i może pomóc w połączeniu czyszczenia danych, wizualizacji i analizy w jednym miejscu. Pozyskiwanie danych z API GSC jest zdecydowanie potrzebne do bardziej zaawansowanych zadań i stanowi „delikatne” wprowadzenie do automatyzacji danych.
Chociaż w Pythonie możesz wykonać wiele bardziej zaawansowanych obliczeń, sugeruję, aby sprawdzić, co ma sens pod względem wartości SEO.
Na przykład liczba zapytań jako całość jest o wiele ważniejsza na dłuższą metę, ponieważ chcesz, aby Twoja witryna była uwzględniana w przypadku większej liczby zapytań.
Używanie notatników to duża pomoc w pakowaniu kodu z komentarzami i to jest główny powód, dla którego sugeruję przyzwyczajenie się do Google Colab.
To dopiero początek tego, co może zaoferować analiza danych, ponieważ najlepsze pomysły pochodzą z połączenia różnych zestawów danych.
Google Search Console jest samo w sobie potężnym narzędziem i jest całkowicie darmowe, a ilość praktycznych informacji, które możesz z niego uzyskać, w dobrych rękach jest prawie nieograniczona.