
Istotność statystyczna testów A/B: jak i kiedy zakończyć test
Opublikowany: 2020-05-22
W naszej ostatniej analizie 28 304 eksperymentów przeprowadzonych przez klientów Convert odkryliśmy, że tylko 20% eksperymentów osiąga poziom istotności statystycznej 95%. Econsultancy odkrył podobny trend w swoim raporcie optymalizacyjnym z 2018 roku. Dwie trzecie respondentów widzi „wyraźnego i statystycznie istotnego zwycięzcę” tylko w 30% lub mniej swoich eksperymentach.
Tak więc większość eksperymentów (70-80%) jest albo niejednoznaczna, albo wcześnie przerwana.
Spośród nich te zatrzymane wcześnie stanowią ciekawy przypadek, ponieważ optymalizatorzy wzywają do zakończenia eksperymentów, kiedy uznają to za stosowne. Robią to, gdy „widzą” wyraźnego zwycięzcę (lub przegranego) lub wyraźnie nieistotny test. Zwykle mają też jakieś dane, aby to uzasadnić.
Może to nie wydawać się tak zaskakujące, biorąc pod uwagę, że 50% optymalizatorów nie ma standardowego „punktu zatrzymania” dla swoich eksperymentów. Dla większości jest to konieczność, ze względu na presję konieczności utrzymywania określonej prędkości testowej (XXX testów/miesiąc) i wyścigu o dominację nad konkurencją.
Istnieje też możliwość negatywnego eksperymentu, który może negatywnie wpłynąć na przychody. Nasze własne badania wykazały, że nieudane eksperymenty mogą spowodować średnio 26% spadek współczynnika konwersji !
Podsumowując, wcześniejsze zakończenie eksperymentów nadal jest ryzykowne…
…ponieważ pozostawia prawdopodobieństwo, że eksperyment przebiegłby zgodnie z zamierzoną długością, zasilany odpowiednią wielkością próby, jego wynik mógłby być inny.
Skąd więc zespoły, które kończą eksperymenty wcześnie, wiedzą, kiedy nadszedł czas ich zakończenia? Dla większości odpowiedź leży w opracowaniu reguł zatrzymujących, które przyspieszają podejmowanie decyzji, bez uszczerbku dla ich jakości.
Odejście od tradycyjnych zasad zatrzymywania
W przypadku eksperymentów internetowych za standard służy wartość p 0,05. Ta 5-procentowa tolerancja błędu lub 95-procentowy poziom istotności statystycznej pomaga optymalizatorom zachować integralność ich testów. Mogą zapewnić, że wyniki są rzeczywistymi wynikami, a nie przypadkami.
W tradycyjnych modelach statystycznych do testowania o ustalonym horyzoncie — gdzie dane testowe są oceniane tylko raz w określonym czasie lub przy określonej liczbie zaangażowanych użytkowników — zaakceptujesz wynik jako istotny, jeśli masz wartość p mniejszą niż 0,05. W tym momencie możesz odrzucić hipotezę zerową, że twoja kontrola i leczenie są takie same, a obserwowane wyniki nie są przypadkowe.
W przeciwieństwie do modeli statystycznych, które umożliwiają ocenę danych podczas ich gromadzenia, takie modele testowe zabraniają przeglądania danych eksperymentu podczas jego trwania. Ta praktyka – znana również jako podglądanie – jest odradzana w takich modelach, ponieważ wartość p zmienia się niemal codziennie. Zobaczysz, że eksperyment będzie miał znaczenie jednego dnia, a następnego dnia jego wartość p wzrośnie do punktu, w którym nie będzie on już istotny.
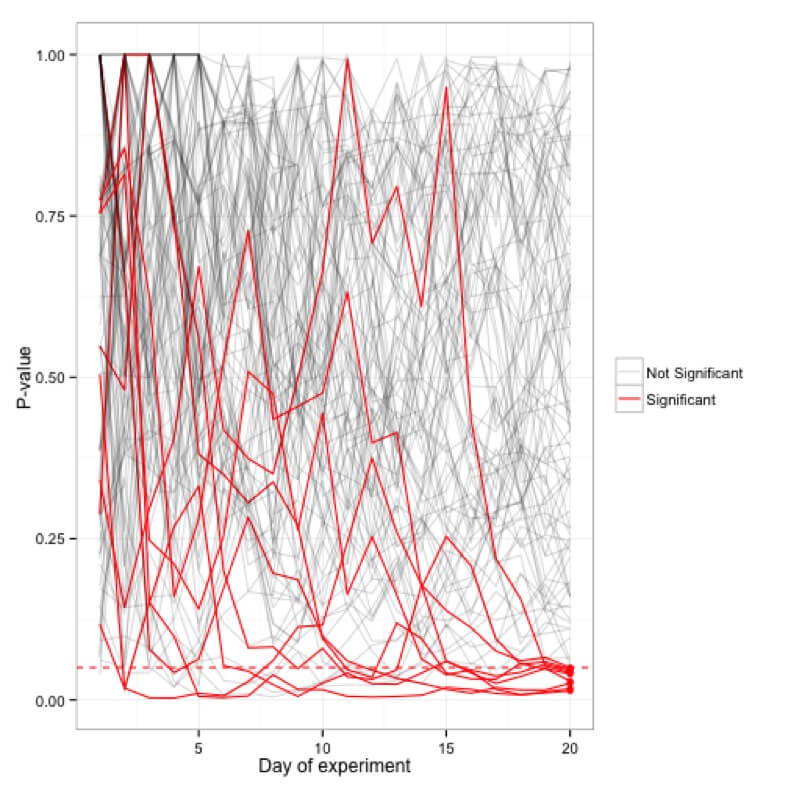
Symulacje wartości p wykreślone dla stu (20-dniowych) eksperymentów; tylko 5 eksperymentów faktycznie okazało się znaczących po 20 dniach, podczas gdy wiele z nich od czasu do czasu osiągało w międzyczasie granicę <0,05.
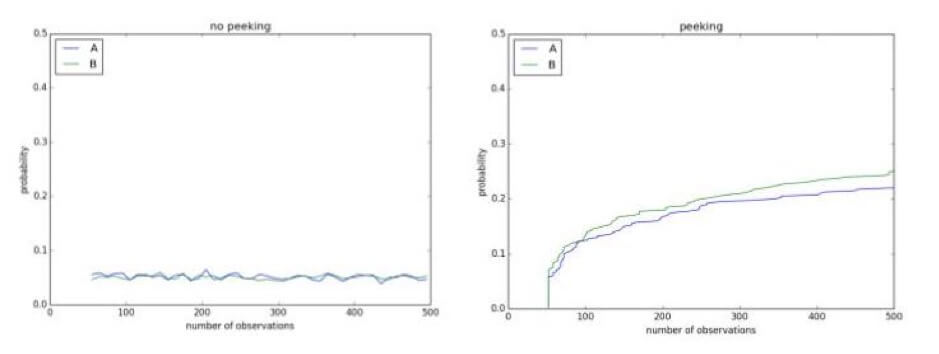
Spojrzenie na swoje eksperymenty w międzyczasie może pokazać wyniki, które nie istnieją. Na przykład poniżej masz test A/A z poziomem istotności 0,1. Ponieważ jest to test A/A, nie ma różnicy między kontrolą a leczeniem. Jednak po 500 obserwacjach podczas trwającego eksperymentu istnieje ponad 50% szans na stwierdzenie, że są różne i że hipotezę zerową można odrzucić:
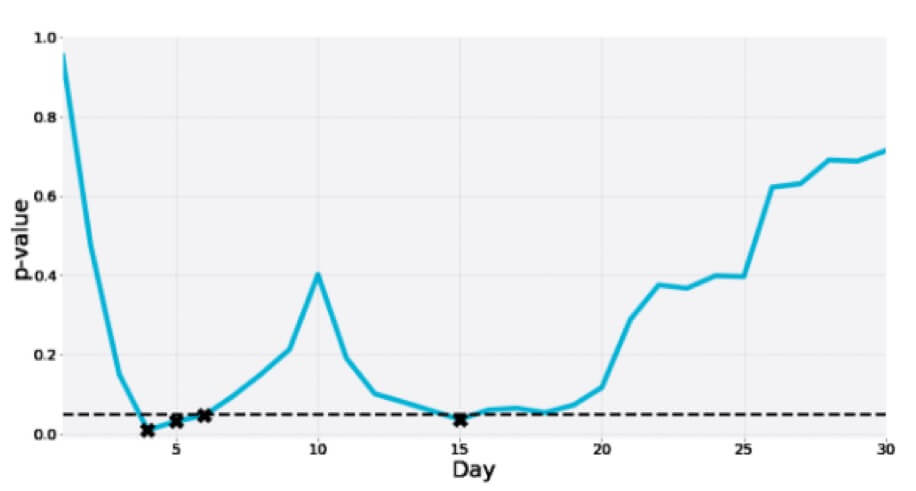
Oto kolejny z 30-dniowego testu A/A, w którym wartość p w międzyczasie wielokrotnie spada do strefy istotności tylko po to, by w końcu być znacznie większą niż wartość graniczna:
Prawidłowe zgłoszenie wartości p z eksperymentu o ustalonym horyzoncie oznacza, że musisz wcześniej zatwierdzić ustaloną wielkość próby lub czas trwania testu. Niektóre zespoły dodają również do tego eksperymentu określoną liczbę konwersji, kryteria zatrzymania i zamierzoną długość.
Problem polega jednak na tym, że uzyskanie wystarczającego ruchu testowego, aby zasilić każdy eksperyment w celu optymalnego zatrzymania przy użyciu tej standardowej praktyki, jest trudne dla większości witryn.
W tym miejscu pomaga użycie sekwencyjnych metod testowania, które obsługują opcjonalne reguły zatrzymywania.
Przejście w kierunku elastycznych reguł zatrzymywania, które umożliwiają szybsze podejmowanie decyzji
Sekwencyjne metody testowania pozwalają na wykorzystywanie danych eksperymentów w miarę ich pojawiania się i używanie własnych modeli istotności statystycznej, aby szybciej wykrywać zwycięzców dzięki elastycznym regułom zatrzymania.
Zespoły optymalizacyjne na najwyższych poziomach dojrzałości CRO często opracowują własne metodologie statystyczne wspierające takie testy. Niektóre narzędzia do testowania A/B również mają to wbudowane i mogą sugerować, czy wersja wydaje się wygrywać. Niektóre zapewniają pełną kontrolę nad sposobem obliczania istotności statystycznej, za pomocą wartości niestandardowych i nie tylko. Dzięki temu możesz podejrzeć i znaleźć zwycięzcę nawet w trwającym eksperymencie.

Statystyk, autor i instruktor popularnego kursu CXL na temat statystyk testów A/B, Georgi Georgiev jest zwolennikiem takich sekwencyjnych metod testowania, które pozwalają na elastyczność w liczbie i czasie analiz pośrednich:
„ Testowanie sekwencyjne pozwala zmaksymalizować zyski poprzez wczesne wdrożenie zwycięskiego wariantu, a także jak najwcześniej zatrzymać testy, w których prawdopodobieństwo uzyskania zwycięzcy jest niewielkie. Ta ostatnia minimalizuje straty spowodowane gorszymi wariantami i przyspiesza testowanie, gdy warianty po prostu nie przewyższają kontroli. We wszystkich przypadkach zachowany jest rygor statystyczny. ”
Georgiev pracował nawet nad kalkulatorem, który pomaga zespołom porzucić ustalone modele testów próbnych na rzecz takiego, który może wykryć zwycięzcę podczas trwania eksperymentu. Jego model uwzględnia wiele statystyk i pomaga przeprowadzać testy o około 20-80% szybciej niż standardowe obliczenia istotności statystycznej, bez poświęcania jakości.
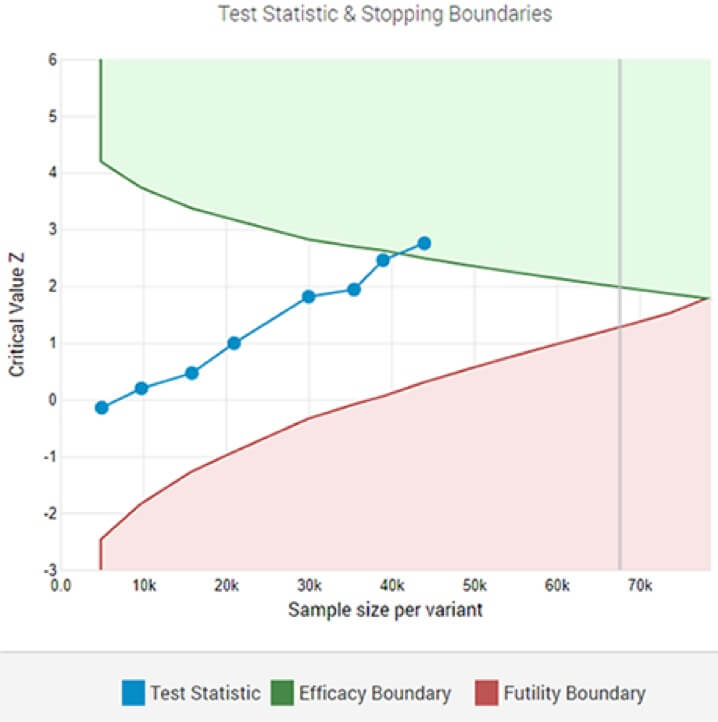
Adaptacyjny test A/B pokazujący statystycznie istotnego zwycięzcę przy wyznaczonym progu istotności po ósmej analizie pośredniej.
Chociaż takie testy mogą przyspieszyć proces podejmowania decyzji, jest jeden ważny aspekt, którym należy się zająć: rzeczywisty wpływ eksperymentu . Zakończenie eksperymentu w międzyczasie może prowadzić do jego przeszacowania.
Patrzenie na nieskorygowane szacunki wielkości efektu może być niebezpieczne, ostrzega Georgiev. Aby tego uniknąć, jego model wykorzystuje metody stosowania korekt, które uwzględniają obciążenie wynikające z monitorowania okresowego. Wyjaśnia, w jaki sposób ich zwinna analiza dostosowuje szacunki „w zależności od etapu zatrzymania i obserwowanej wartości statystyki (przekroczenie, jeśli występuje)”. Poniżej możesz zobaczyć analizę powyższego testu: (Zwróć uwagę, że szacowany wzrost jest niższy niż obserwowany, a przedział nie jest wokół niego wyśrodkowany).
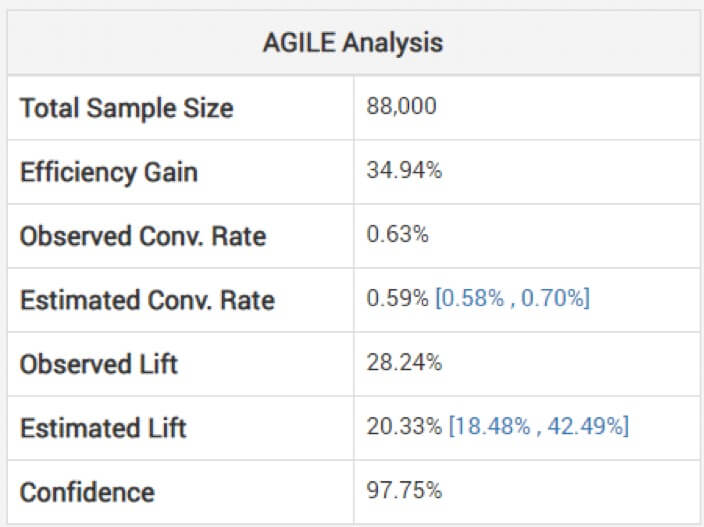
Tak więc wygrana może nie być tak duża, jak się wydaje na podstawie twojego eksperymentu krótszego niż zamierzone.
Strata również musi zostać uwzględniona, ponieważ nadal możesz błędnie zadzwonić do zwycięzcy zbyt wcześnie. Ale to ryzyko istnieje nawet w testach o ustalonym horyzoncie. Trafność zewnętrzna może być jednak większym problemem przy wczesnym wywoływaniu eksperymentów w porównaniu z testami o ustalonym horyzoncie czasowym. Ale jest to, jak wyjaśnia Georgiev, “ prosta konsekwencja mniejszej wielkości próby, a tym samym czasu trwania testu. “
W końcu… Tu nie chodzi o zwycięzców czy przegranych…
… ale o lepszych decyzjach biznesowych, jak mówi Chris Stucchio.
Lub, jak twierdzi Tom Redman (autor książki Data Driven: Profiting from Your Most Important Business Asset), w biznesie: „ często są ważniejsze kryteria niż istotność statystyczna. Ważnym pytaniem jest: „ Czy wynik utrzymuje się na rynku, choćby przez krótki okres czasu? „”
I najprawdopodobniej będzie, nie tylko przez krótki okres, zauważa Georgiev, „ jeśli jest statystycznie istotny, a kwestie dotyczące ważności zewnętrznej zostały uwzględnione w zadowalający sposób na etapie projektowania”.
Cała istota eksperymentowania polega na umożliwieniu zespołom podejmowania bardziej świadomych decyzji. Więc jeśli możesz przekazać wyniki — na które wskazują dane z twoich eksperymentów — wcześniej, to dlaczego nie?
Może to być mały eksperyment interfejsu użytkownika, do którego praktycznie nie można uzyskać „wystarczającej” wielkości próbki. Może to być również eksperyment, w którym Twój rywal miażdży oryginał, a Ty możesz po prostu wziąć ten zakład!
Jak pisze Jeff Bezos w liście do udziałowców Amazona, wielkie eksperymenty popłacają:
„ Biorąc pod uwagę dziesięć procent szans na 100-krotną wypłatę, powinieneś stawiać ten zakład za każdym razem. Ale nadal będziesz się mylił dziewięć razy na dziesięć. Wszyscy wiemy, że jeśli uderzysz w płoty, dużo uderzysz, ale także uderzysz w niektóre home runy. Różnica między baseballem a biznesem polega jednak na tym, że baseball ma skrócony rozkład wyników. Kiedy huśtasz się, bez względu na to, jak dobrze łączysz się z piłką, najwięcej przebiegów, jakie możesz uzyskać, to cztery. W biznesie, raz na jakiś czas, kiedy wejdziesz na szczyt, możesz zdobyć 1000 biegów. Ta długoterminowa dystrybucja zwrotów jest powodem, dla którego ważne jest, aby być odważnym. Wielcy zwycięzcy płacą za tak wiele eksperymentów. “
Wczesne wywoływanie eksperymentów jest w dużym stopniu jak podglądanie każdego dnia wyników i zatrzymanie się w punkcie, który gwarantuje dobry zakład.

