
Nowa era UX: ewolucja podejścia do projektowania produktów AI
Opublikowany: 2024-01-18Zanim rok temu ChatGPT wkroczyło na scenę, sztuczna inteligencja (AI) i uczenie maszynowe (ML) były tajemniczymi narzędziami ekspertów i analityków danych – zespołów z dużym doświadczeniem niszowym i specjalistyczną wiedzą dziedzinową. Teraz jest inaczej.
Prawdopodobnie czytasz to, ponieważ Twoja firma zdecydowała się użyć GPT OpenAI lub innego LLM (model wielkojęzykowy) do wbudowania generatywnych funkcji AI w swój produkt. W takim przypadku możesz czuć się podekscytowany („Tak łatwo jest stworzyć nową, świetną funkcję!”) lub przytłoczony („Dlaczego za każdym razem otrzymuję inne wyniki i jak sprawić, by spełniało moje oczekiwania?”)Lub może czujesz jedno i drugie!
Praca ze sztuczną inteligencją może być nowym wyzwaniem, ale nie musi być onieśmielająca. W tym poście zebrano moje doświadczenia z lat spędzonych na projektowaniu pod kątem „tradycyjnego” podejścia do uczenia maszynowego w prostym zestawie pytań, które pomogą Ci pewniej ruszyć do przodu, gdy zaczniesz projektować pod kątem sztucznej inteligencji.
Inny rodzaj projektowania UX
Najpierw kilka informacji o tym, jak projektowanie AI UX różni się od tego, do czego jesteś przyzwyczajony. (Uwaga: w tym poście będę używał zamiennie AI i ML.) Być może znasz 5-warstwowy model projektowania UX Jessego Jamesa Garretta.
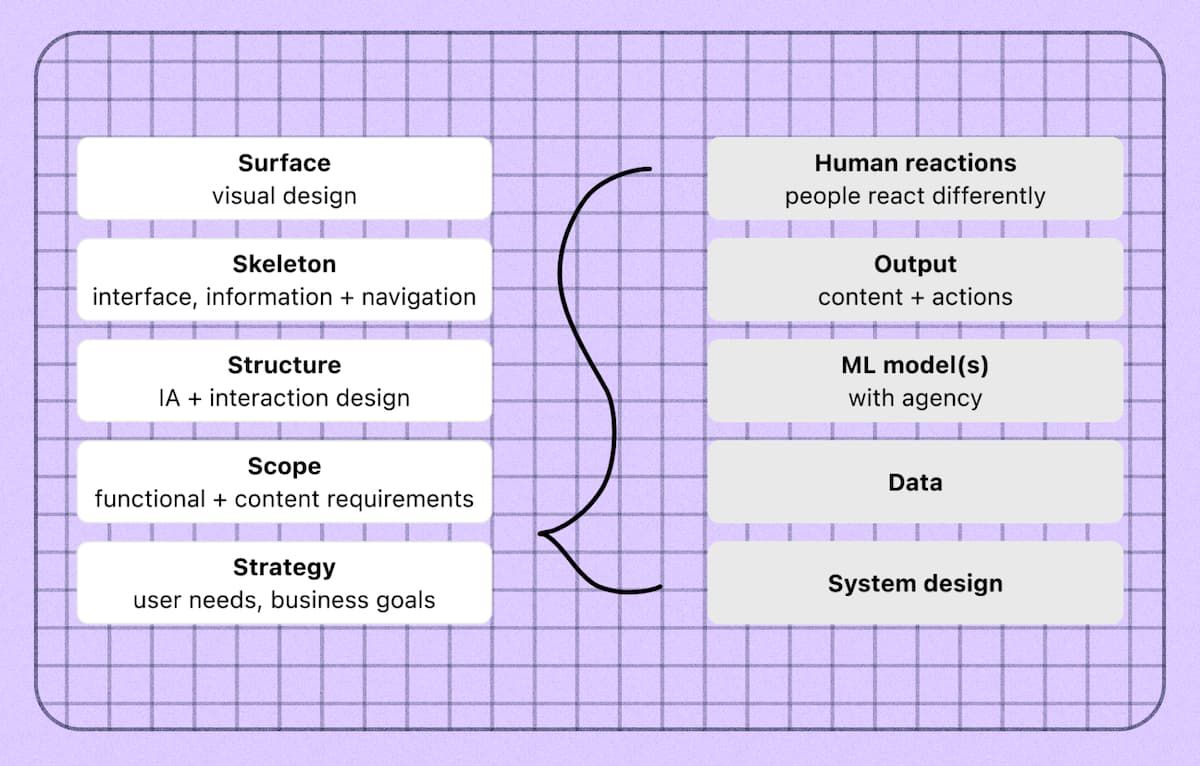
Diagram elementów doświadczenia użytkownika Jessego Jamesa Garretta
Model Garretta sprawdza się dobrze w przypadku systemów deterministycznych, ale nie wychwytuje dodatkowych elementów projektów uczenia maszynowego, które będą miały wpływ na późniejsze rozważania dotyczące UX. Praca z ML oznacza dodanie do modelu szeregu dodatkowych warstw, w warstwie strategii i wokół niej. Teraz oprócz tego, do czego przywykłeś projektować, potrzebujesz także głębszego zrozumienia:
- Jak zbudowany jest system.
- Jakie dane są dostępne dla Twojej funkcji, co zawiera, jak dobra i niezawodna jest.
- Modele ML, których będziesz używać, a także ich mocne i słabe strony.
- Dane wyjściowe, które wygeneruje Twoja funkcja, jak będą się różnić i kiedy zawiodą.
- Jak ludzie mogą reagować na tę funkcję inaczej, niż można by się spodziewać lub chcieć.
Zamiast zadawać sobie pytanie: „Jak możemy to zrobić?” w odpowiedzi na znany problem o szerokim zakresie możesz zadać sobie pytanie: „Czy możemy to zrobić?”
Zwłaszcza jeśli korzystasz z LLM, prawdopodobnie będziesz pracować wstecz od technologii, która odblokowuje zupełnie nowe możliwości i musisz określić, czy są one odpowiednie do rozwiązywania problemów, o których wiesz, lub nawet problemów, których nigdy nie uważałeś za możliwe do rozwiązania zanim. Być może będziesz musiał pomyśleć na wyższym poziomie niż zwykle – zamiast wyświetlać jednostki informacji, możesz zamiast tego zsyntetyzować duże ilości informacji i przedstawić trendy, wzorce i prognozy.
„Projektujesz system probabilistyczny, który jest dynamiczny i reaguje na dane wejściowe w czasie rzeczywistym”
Co najważniejsze, zamiast projektować system deterministyczny, który robi to, co mu każesz, projektujesz system probabilistyczny, który jest dynamiczny i reaguje na dane wejściowe w czasie rzeczywistym – z wynikami i zachowaniami, które będą czasami nieoczekiwane lub niewytłumaczalne, i gdzie wyważenie kompromisów może być niejasnym ćwiczeniem. W tym miejscu wchodzi w grę mój zestaw pięciu kluczowych pytań – nie po to, aby dostarczyć Ci odpowiedzi, ale aby pomóc Ci zrobić kolejny krok w obliczu niepewności. Zanurzmy się.
1. Jak zapewnisz dobre dane?
Analitycy danych uwielbiają mówić „śmieci na wejściu, śmieci na zewnątrz”. Jeśli zaczniesz od złych danych, zazwyczaj nie ma możliwości, abyś uzyskał dobrą funkcję sztucznej inteligencji.
Na przykład, jeśli budujesz chatbota, który generuje odpowiedzi na podstawie zbioru źródeł informacji, takich jak artykuły w centrum pomocy online, artykuły o niskiej jakości zapewnią chatbotowi niskiej jakości.
Kiedy zespół Intercom uruchomił Fin na początku 2023 r., zdaliśmy sobie sprawę, że wielu naszych klientów nie miało dokładnego wyczucia jakości treści pomocy, dopóki nie zaczęli korzystać z Fina i nie odkryli, jakie informacje są lub nie są obecne lub jasne w ich treść. Chęć posiadania przydatnej funkcji AI może być doskonałą funkcją zmuszającą zespoły do poprawy jakości swoich danych.
Czym zatem są dobre dane? Dobre dane to:
- Dokładne: dane prawidłowo odzwierciedlają rzeczywistość. Oznacza to, że jeśli mam 1,7 m wzrostu, to jest to zapisane w mojej karcie zdrowia. Nie jest napisane, że mam 1,9 m wzrostu.
- Kompletne: dane zawierają wymagane wartości. Jeśli do przewidywania potrzebny jest pomiar wzrostu, wartość ta jest obecna w dokumentacji zdrowotnej wszystkich pacjentów.
- Spójne: dane nie są sprzeczne z innymi danymi. Nie mamy dwóch pól na wysokość, jedno mówiące 1,7 m, a drugie 1,9 m.
- Świeże: dane są aktualne i aktualne. Twoja karta zdrowia nie powinna odzwierciedlać Twojego wzrostu w wieku 10 lat, jeśli jesteś teraz osobą dorosłą – jeśli się zmieniła, dokumentacja powinna się zmienić, aby to odzwierciedlić.
- Unikalne: dane nie są duplikowane. Mój lekarz nie powinien mieć dla mnie dwóch kart pacjentów, bo nie będzie wiedział, która jest ta właściwa.
Rzadko zdarza się mieć mnóstwo danych naprawdę wysokiej jakości, dlatego podczas opracowywania produktu AI konieczne może być dokonanie kompromisu w zakresie jakości/ilości. Być może uda Ci się ręcznie utworzyć mniejszą (ale miejmy nadzieję, że nadal reprezentatywną próbkę) danych lub odfiltrować stare, niedokładne dane w celu utworzenia wiarygodnego zestawu.
Spróbuj rozpocząć proces projektowania od dokładnego wyczucia jakości danych i planu ich ulepszenia, jeśli na początku nie będą doskonałe.
2. Jak dostosujesz swój proces projektowania?
Jak zwykle warto zacząć od eksploracji o niskiej wierności, aby określić idealne wrażenia użytkownika w przypadku problemu, który chcesz rozwiązać. Prawdopodobnie nigdy nie zobaczysz tego w produkcji, ale ta gwiazda północna może pomóc Tobie i Twojemu zespołowi, wzbudzić ich entuzjazm, a także zapewnić konkretny punkt wyjścia do sprawdzenia, czy jest to w rzeczywistości wykonalne.
„Poświęć trochę czasu na zrozumienie, jak działa system, w jaki sposób dane są gromadzone i wykorzystywane oraz czy Twój projekt uwzględnia rozbieżności, które możesz zobaczyć w wynikach modelu”
Kiedy już to zrobisz, czas zaprojektować system, dane i treści wyjściowe. Wróć do swojej gwiazdy północnej i zapytaj: „Czy to, co zaprojektowałem, jest w ogóle możliwe? Jakie są różnice w przypadku, gdy X lub Y nie działają dobrze?”
Poświęć trochę czasu na zrozumienie, jak działa system, w jaki sposób dane są gromadzone i wykorzystywane oraz czy Twój projekt uwzględnia wariancje, które możesz zobaczyć w wynikach modelu. W przypadku sztucznej inteligencji słaby wynik jest kiepskim doświadczeniem. W przykładzie chatbota może to wyglądać na odpowiedź, która nie podaje wystarczająco dużo szczegółów, odpowiada na pytanie poboczne lub nie wyjaśnia pytania, kiedy powinna.
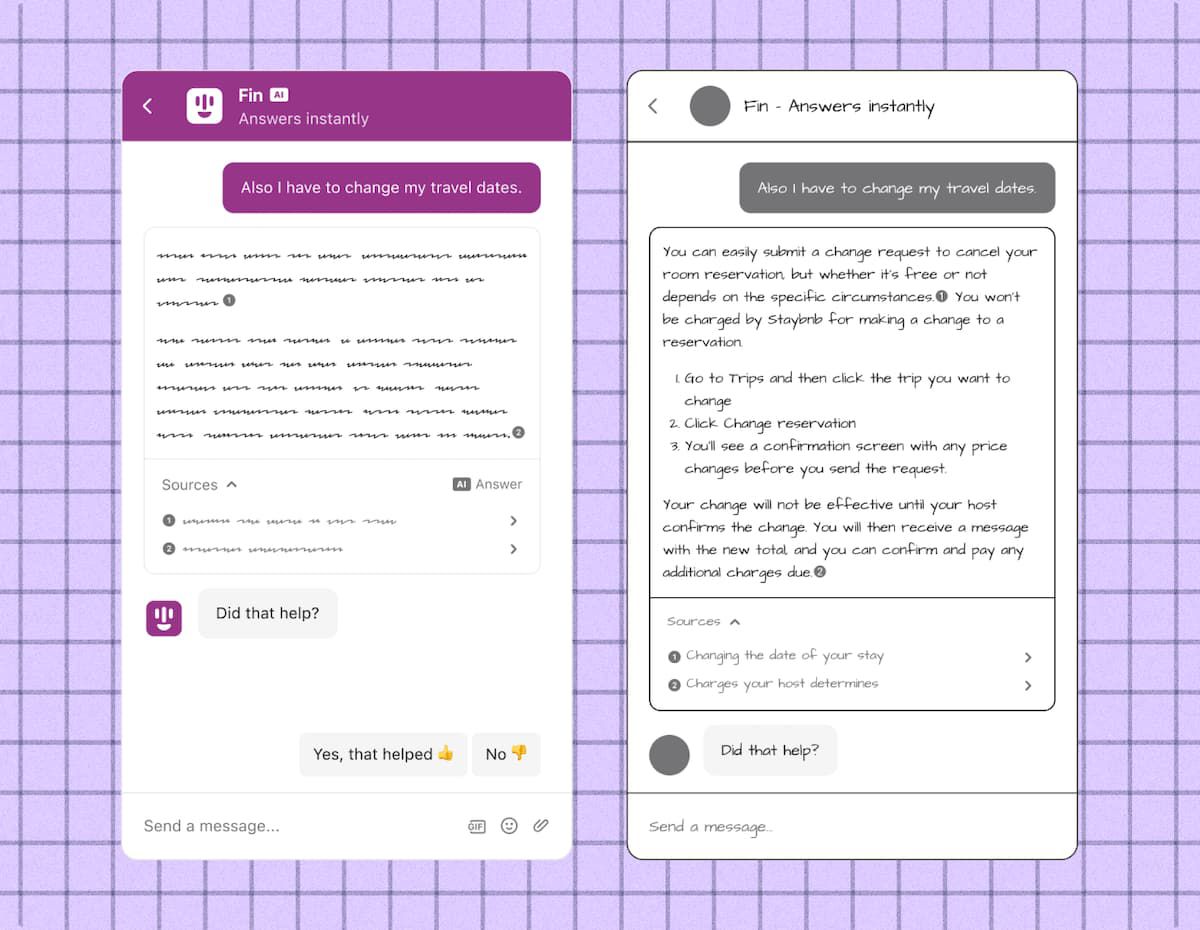
 Dwa przykłady sposobu wyświetlania wyników chatbota AI
Dwa przykłady sposobu wyświetlania wyników chatbota AI
Na powyższej ilustracji przykład po lewej stronie jest podobny do wielu wczesnych wyników, które widzieliśmy podczas opracowywania naszego chatbota Fin, które były dokładne, ale niezbyt pouczające i przydatne, ponieważ odsyłały do oryginalnego artykułu, zamiast podawać odpowiedź w tekście. Projekt pomaga uzyskać przykład po prawej stronie, który zawiera pełniejszą odpowiedź z jasnymi krokami i formatowaniem.
Nie zostawiaj zawartości wyników swoim inżynierom – należy zaprojektować doświadczenie z tym związane. Jeśli pracujesz nad produktem opartym na LLM, oznacza to, że powinieneś poeksperymentować z szybką inżynierią i wypracować własny punkt widzenia na temat tego, jaki powinien być kształt i zakres produktu wyjściowego.
Będziesz także musiał rozważyć, jak zaprojektować nowy zestaw potencjalnych stanów błędów, ryzyka i ograniczeń:
Stany błędów
- Problem z zimnym startem: przy pierwszym użyciu Twojej funkcji klienci mogą mieć niewiele danych lub nie mieć ich wcale. W jaki sposób uzyskają wartość od samego początku?
- Brak przewidywania: system nie ma odpowiedzi. Co się wtedy stanie?
- Zła prognoza: system dał słabą wydajność. Czy użytkownik będzie wiedział, że coś jest nie tak? Czy mogą to naprawić?
Ryzyko
- Fałszywe alarmy , na przykład gdy prognoza pogody przewiduje deszcz, ale nie pada. Czy wystąpią negatywne skutki, jeśli stanie się to z Twoim produktem?
- Fałszywe negatywy , na przykład gdy prognoza pogody nie przewiduje deszczu, ale jest ulewa. Jaki będzie wynik, jeśli stanie się to z Twoją funkcją?
- Ryzyka w świecie rzeczywistym , na przykład gdy wyniki ML bezpośrednio wpływają na życie ludzi, źródła utrzymania i możliwości. Czy mają one zastosowanie do Twojego produktu?
Nowe ograniczenia
- Ograniczenia użytkownika , takie jak nieprawidłowe modele myślowe dotyczące działania systemu, nierealistyczne oczekiwania lub obawy dotyczące produktu lub możliwość popadnięcia w samozadowolenie z biegiem czasu.
- Ograniczenia techniczne , takie jak koszt interfejsu API lub przechowywania i obliczeń, opóźnienia, czas pracy, dostępność danych, prywatność danych i bezpieczeństwo. Są to przede wszystkim kwestie dla inżynierów, ale mogą mieć również bezpośredni wpływ na wygodę użytkownika, dlatego należy rozumieć ograniczenia i możliwości.
3. Jak to będzie działać w przypadku niepowodzenia ML?
Kiedy, nieczy. Jeśli jesteś zaskoczony niepowodzeniami produkcyjnymi Twojego produktu AI, oznacza to, że nie przeprowadziłeś wcześniej wystarczającej liczby testów. Twój zespół powinien testować produkt i wyniki podczas całego procesu kompilacji, a nie czekać, aż udostępnisz tę funkcję klientom. Rygorystyczne testy dadzą Ci solidne pojęcie o tym, jak i kiedy Twój produkt może zawieść, dzięki czemu możesz zbudować doświadczenia użytkowników, aby złagodzić te awarie. Oto kilka sposobów, w jakie możesz skutecznie przetestować swój produkt.

Zacznij od prototypów projektów
Prototyp z jak największą ilością rzeczywistych danych. „Lorem ipsum” jest tutaj Twoim wrogiem – użyj prawdziwych przykładów, aby przetestować swój produkt. Na przykład podczas opracowywania naszego chatbota AI Fin ważne było przetestowanie jakości odpowiedzi udzielanych na prawdziwe pytania klientów, wykorzystując jako materiał źródłowy prawdziwe artykuły z Centrum pomocy.
Przykład podejścia dwóch projektantów do zaprojektowania chatbota dostarczającego odpowiedzi generowane przez sztuczną inteligencję
W tym porównaniu widzimy, że kolorowy przykład po lewej stronie jest bardziej atrakcyjny wizualnie, ale nie podaje żadnych szczegółów na temat jakości generowania odpowiedzi. Ma wysoką wierność wizualną, ale niską wierność treści. Przykład po prawej stronie jest bardziej pouczający i pozwala na testowanie i sprawdzanie, czy odpowiedzi sztucznej inteligencji są rzeczywiście dobrej jakości, ponieważ charakteryzują się wysoką wiernością treści.
Projektanci często lepiej znają się na pracy w całym zakresie wierności wizualnej. Jeśli projektujesz pod kątem uczenia maszynowego, powinieneś dążyć do pracy w całym spektrum wierności treści, dopóki w pełni nie sprawdzisz, czy wyniki są wystarczającej jakości dla Twoich użytkowników.
Kolorowy design Fina nie pomoże Ci ocenić, czy chatbot potrafi odpowiadać na pytania na tyle dobrze, że klienci za to zapłacą. Lepszą informację zwrotną uzyskasz, pokazując klientom prototyp, niezależnie od tego, jak prosty jest, który pokazuje im rzeczywiste wyniki na podstawie rzeczywistych danych.
Testuj na dużą skalę
Jeśli uważasz, że udało Ci się uzyskać niezmiennie dobrą jakość wyników,przeprowadź test historyczny , aby zweryfikować jakość wyników na większą skalę.Oznacza to, że inżynierowie powinni wrócić i uruchomić algorytm na podstawie bardziej historycznych danych, w przypadku których znasz lub możesz wiarygodnie ocenić jakość wyniku. Powinieneś przeglądać wyniki pod kątem jakości i spójności – i ujawniać wszelkie niespodzianki.
Potraktuj swój minimalnie opłacalny produkt (MVP) jako test
Twoja wersja MVP lub wersja beta powinna pomóc Ci rozwiązać wszelkie pozostałe pytania i znaleźć więcej potencjalnych niespodzianek. Pomyśl nieszablonowo o swoim MVP – możesz go zbudować w produkcie lub może to być po prostu arkusz kalkulacyjny.
„Spraw, aby wyniki zadziałały, a następnie zbuduj wokół nich otoczkę produktu”
Na przykład, jeśli tworzysz funkcję, która grupuje grupy artykułów w obszary tematyczne, a następnie definiuje tematy, warto upewnić się, że grupowanie zostało wykonane tuż przed zbudowaniem kompletnego interfejsu użytkownika. Jeśli Twoje klastry są złe, może być konieczne inne podejście do problemu lub umożliwienie różnych interakcji w celu dostosowania rozmiarów klastrów.
Możesz chcieć „zbudować” MVP, który będzie po prostu arkuszem kalkulacyjnym zawierającym wyniki i nazwane tematy i sprawdzić, czy Twoi klienci uznają sposób, w jaki to zrobiłeś, za wartość. Spraw, aby wyniki zadziałały, a następnie zbuduj wokół nich otoczkę produktu.
Przeprowadź test A/B po uruchomieniu swojego MVP
Będziesz chciał zmierzyć pozytywny lub negatywny wpływ swojej funkcji. Jako projektant prawdopodobnie nie będziesz odpowiedzialny za konfigurowanie tego, ale powinieneś starać się zrozumieć wyniki. Czy wskaźniki wskazują, że Twój produkt jest wartościowy? Czy są jakieś zakłócające czynniki w interfejsie użytkownika lub UX, które być może będziesz musiał zmienić w zależności od tego, co widzisz?
„Możesz wykorzystać dane telemetryczne dotyczące użytkowania produktu w połączeniu z jakościowymi opiniami użytkowników, aby lepiej zrozumieć, w jaki sposób użytkownicy wchodzą w interakcję z Twoją funkcją i jaką wartość z niej czerpią”
W zespole Intercom AI przeprowadzamy testy A/B za każdym razem, gdy wypuszczamy nową funkcję z wystarczająco dużą liczbą interakcji, aby określić istotność statystyczną w ciągu kilku tygodni. Jednak w przypadku niektórych funkcji po prostu nie będziesz mieć wystarczającej głośności – w takim przypadku możesz użyć danych telemetrycznych dotyczących użytkowania produktu w połączeniu z jakościowymi opiniami użytkowników, aby lepiej zrozumieć, w jaki sposób użytkownicy wchodzą w interakcję z Twoją funkcją i wartość, z której czerpią To.
4. Jak ludzie dopasują się do systemu?
Tworząc produkt AI, należy wziąć pod uwagę trzy główne etapy cyklu życia produktu:
- Konfigurowanie funkcji przed użyciem .Może to obejmować wybór poziomu autonomii, w ramach którego produkt będzie działał, selekcję i filtrowanie danych, które będą używane do prognoz oraz ustawianie kontroli dostępu. Przykładem tego są międzynarodowe ramy automatyzacji pojazdów autonomicznych SAE, które określają, co pojazd może zrobić samodzielnie oraz ile interwencji człowieka jest dozwolone lub wymagane.
- Monitorowanie funkcji podczas jej działania.Czy system potrzebuje człowieka, który będzie trzymał go w dobrej kondycji podczas działania? Czy potrzebujesz etapu zatwierdzania, aby zapewnić jakość? Może to oznaczać kontrole operacyjne, wskazówki człowieka lub zatwierdzenia na żywo przed wysłaniem wyników AI do użytkownika końcowego. Przykładem może być asystent pisania artykułów AI, który sugeruje zmiany w wersji roboczej artykułu pomocy, które autor musi zatwierdzić przed publikacją.
- Ocena funkcji po uruchomieniu.Zwykle oznacza to raportowanie, przekazywanie informacji zwrotnych lub podejmowanie działań oraz zarządzanie zmianami danych w czasie. Na tym etapie użytkownik spogląda wstecz na działanie zautomatyzowanego systemu, porównując go z danymi historycznymi lub przyglądając się jakości i decydując, jak ją ulepszyć (poprzez szkolenie modeli, aktualizację danych lub inne metody). Przykładem może być raport szczegółowo opisujący, jakie pytania użytkownicy końcowi zadali Twojemu chatbotowi AI, jakie były odpowiedzi i sugerowane zmiany, które możesz wprowadzić, aby poprawić odpowiedzi chatbota na przyszłe pytania.
Możesz wykorzystać te trzy fazy, aby pomóc w opracowaniu planu rozwoju produktu. Możesz mieć wiele produktów i wiele interfejsów użytkownika opartych na tej samej lub bardzo podobnej technologii ML zaplecza i po prostu zmieniać tam, gdzie zaangażowany jest człowiek. Zaangażowanie człowieka na różnych etapach cyklu życia może całkowicie zmienić propozycję produktu.
Do projektowania produktu AI można także podejść pod kątem czasu: zbuduj coś teraz, co w pewnym momencie może wymagać obecności człowieka, ale z planem ich usunięcia lub przeniesienia na inny etap, gdy użytkownicy końcowi przyzwyczają się do wyników i jakości funkcji AI.
5. Jak będziesz budować zaufanie użytkowników do systemu?
Wprowadzając sztuczną inteligencję do produktu, wprowadzasz model z podmiotowością do działania w systemie, podczas gdy wcześniej tę podmiotowość mieli tylko sami użytkownicy. Zwiększa to ryzyko i niepewność dla Twoich klientów. Poziom kontroli Twojego produktu w zrozumiały sposób wzrośnie, a Ty będziesz musiał zdobyć zaufanie użytkowników.
Możesz spróbować to zrobić na kilka sposobów:
- Zaoferuj „ciemną premierę” lub doświadczenie side-by-side, podczas którego klienci mogą porównać wyniki lub zobaczyć wyniki bez udostępniania ich użytkownikom końcowym. Pomyśl o tym jak o wersji testu historycznego skierowanej do użytkownika, którą przeprowadziłeś na wcześniejszym etapie procesu – chodzi o to, aby dać klientom pewność co do zakresu i jakości wyników, które zapewni Twoja funkcja lub produkt. Na przykład, kiedy uruchomiliśmy chatbota Fin AI firmy Intercom, zaoferowaliśmy stronę, na której klienci mogli przesyłać i testować bota na własnych danych.
- Najpierw uruchom funkcję pod nadzorem człowieka. Po pewnym czasie dobrej wydajności Twoi klienci prawdopodobnie zaufają mu, że działa bez nadzoru człowieka.
- Ułatw sobie wyłączenie tej funkcji, jeśli nie działa. Użytkownikom łatwiej jest zastosować funkcję sztucznej inteligencji w swoim przepływie pracy (zwłaszcza w biznesie), jeśli nie ma ryzyka, że coś zepsują i nie będą w stanie tego zatrzymać.
- Zbuduj mechanizm informacji zwrotnej , aby użytkownicy mogli zgłaszać słabe wyniki, a w idealnym przypadku system powinien reagować na te raporty w celu wprowadzenia ulepszeń w systemie. Pamiętaj jednak, aby ustalić realistyczne oczekiwania co do tego, kiedy i w jaki sposób zostaną podjęte działania w odpowiedzi na uwagi, aby klienci nie oczekiwali natychmiastowych ulepszeń.
- Zbuduj solidne mechanizmy raportowania , aby pomóc swoim klientom zrozumieć, jak działa sztuczna inteligencja i jaki zwrot z inwestycji dzięki niej uzyskują.
W zależności od produktu możesz wypróbować więcej niż jedną z nich, aby zachęcić użytkowników do zdobycia doświadczenia i poczucia komfortu z Twoim produktem.
Cierpliwość jest cnotą, jeśli chodzi o sztuczną inteligencję
Mam nadzieję, że te pięć pytań pomoże Ci w podróży do nowego, szybko zmieniającego się świata rozwoju produktów AI. Ostatnia rada: bądź cierpliwy podczas wypuszczania produktu na rynek. Uruchomienie i dostosowanie funkcji uczenia maszynowego do sposobu, w jaki firma lubi pracować, może wymagać znacznego wysiłku, dlatego krzywa wdrożenia może wyglądać inaczej, niż można by się spodziewać.
„Po zbudowaniu kilku funkcji sztucznej inteligencji zaczniesz lepiej rozumieć, jak Twoi klienci zareagują na nowe premiery”
Prawdopodobnie minie trochę czasu, zanim Twoi klienci zobaczą najwyższą wartość lub zanim będą mogli przekonać swoich interesariuszy, że sztuczna inteligencja jest warta swojej ceny i powinna zostać udostępniona szerzej użytkownikom.
Nawet klienci, którzy są naprawdę podekscytowani Twoją funkcją, mogą nadal potrzebować czasu na jej wdrożenie, albo dlatego, że muszą wykonać prace przygotowawcze, takie jak czyszczenie danych, albo dlatego, że pracują nad zdobyciem zaufania przed jej uruchomieniem. Może być trudno przewidzieć, jakiego wdrożenia się spodziewać, ale po zbudowaniu kilku funkcji sztucznej inteligencji zaczniesz lepiej rozumieć, jak poszczególni klienci zareagują na nowe premiery.
