
Co to jest krzywa CTR i jak ją obliczyć w Pythonie?
Opublikowany: 2022-03-22Krzywa CTR, lub innymi słowy organiczny współczynnik klikalności na podstawie pozycji, to dane, które pokazują, ile niebieskich linków na stronie wyników wyszukiwania (SERP) uzyskuje CTR na podstawie ich pozycji. Na przykład, przez większość czasu pierwszy niebieski link w SERP uzyskuje najwyższy CTR.
Na końcu tego samouczka będziesz mógł obliczyć krzywą CTR swojej witryny na podstawie jej katalogów lub obliczyć organiczny CTR na podstawie zapytań CTR. Wynikiem mojego kodu w Pythonie jest wnikliwy wykres pudełkowy i słupkowy, który opisuje krzywą CTR witryny.
Jeśli jesteś początkującym i nie znasz definicji CTR, wyjaśnię to dokładniej w następnej sekcji.
Co to jest organiczny CTR lub bezpłatny współczynnik klikalności?
CTR pochodzi z podziału kliknięć organicznych na wyświetlenia. Na przykład, jeśli 100 osób wyszukuje hasło „jabłko”, a 30 osób kliknie pierwszy wynik, CTR pierwszego wyniku wyniesie 30/100 * 100 = 30%.
Oznacza to, że na każde 100 wyszukiwań otrzymujesz 30% z nich. Należy pamiętać, że wyświetlenia w Google Search Console (GSC) nie są oparte na wyglądzie linku do Twojej witryny w widoku przeglądarki. Jeśli wynik pojawi się w wyszukiwarce SERP, otrzymasz jedno wyświetlenie na każde z wyszukiwań.
Jakie są zastosowania krzywej CTR?
Jednym z ważnych tematów w SEO są prognozy ruchu organicznego. Aby poprawić rankingi w niektórych zestawach słów kluczowych, musimy przeznaczyć tysiące dolarów, aby uzyskać więcej udziałów. Ale na poziomie marketingowym firmy często pojawia się pytanie: „Czy przydzielenie tego budżetu jest dla nas opłacalne?”.
Poza tematem alokacji budżetu na projekty SEO, musimy również oszacować wzrost lub spadek naszego ruchu organicznego w przyszłości. Na przykład, jeśli zobaczymy, że jeden z naszych konkurentów usilnie próbuje zastąpić nas w naszej pozycji w rankingu SERP, ile nas to będzie kosztować?
W tej sytuacji lub wielu innych scenariuszach potrzebujemy krzywej CTR naszej witryny.
Dlaczego nie korzystamy z badań krzywych CTR i nie korzystamy z naszych danych?
Po prostu odpowiedziałem, że nie ma żadnej innej strony internetowej, która ma cechy Twojej witryny w SERP.
Istnieje wiele badań dotyczących krzywych CTR w różnych branżach i różnych funkcjach SERP, ale kiedy masz swoje dane, dlaczego Twoje witryny nie obliczają CTR zamiast polegać na źródłach zewnętrznych?
Zacznijmy to robić.
Obliczanie krzywej CTR za pomocą Pythona: Pierwsze kroki
Zanim zagłębimy się w proces obliczania współczynnika klikalności Google na podstawie pozycji, musisz znać podstawową składnię Pythona i podstawową wiedzę na temat popularnych bibliotek Pythona, takich jak Pandas. Pomoże to lepiej zrozumieć kod i dostosować go na swój sposób.
Dodatkowo do tego procesu wolę używać notatnika Jupyter.
Aby obliczyć organiczny CTR na podstawie pozycji, musimy użyć tych bibliotek Pythona:
- Pandy
- Działka
- Kalejdo
Ponadto użyjemy tych standardowych bibliotek Pythona:
- os
- json
Jak powiedziałem, zbadamy dwa różne sposoby obliczania krzywej CTR. Niektóre kroki są takie same w obu metodach: importowanie pakietów Pythona, tworzenie folderu wyjściowego obrazów wykresu i ustawianie rozmiarów wydruku wyjściowego.
# Importowanie potrzebnych bibliotek do naszego procesu importuj system importuj json importuj pandy jako PD importuj plotly.express jako px importuj plotly.io jako pio importuj kalejd
Tutaj tworzymy folder wyjściowy do zapisywania naszych obrazów fabuły.
# Tworzenie folderu wyjściowego obrazów wykresu
jeśli nie os.path.exists('./output plot images'):
os.mkdir('./output wykresu obrazów')
Możesz zmienić wysokość i szerokość obrazów wykresu wyjściowego poniżej.
# Ustawianie szerokości i wysokości obrazów wyjściowych wykresu pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
Zacznijmy od pierwszej metody opartej o CTR zapytań.
Pierwsza metoda: Oblicz krzywą CTR dla całej witryny lub określonej bazy właściwości adresu URL na podstawie CTR zapytań
Przede wszystkim musimy uzyskać wszystkie nasze zapytania z ich CTR, średnią pozycją i wyświetleniem. Wolę używać jednego pełnego miesiąca danych z ostatniego miesiąca.
W tym celu otrzymuję dane zapytań ze źródła danych wyświetleń w witrynie GSC w Google Data Studio. Alternatywnie możesz pozyskać te dane w dowolny sposób, na przykład GSC API lub dodatek Google Sheets „Search Analytics for Sheets”. W ten sposób, jeśli Twój blog lub strony produktów mają dedykowaną właściwość adresu URL, możesz ich użyć jako źródła danych w GDS.
1. Pobieranie danych zapytań z Google Data Studio (GDS)
Aby to zrobić:
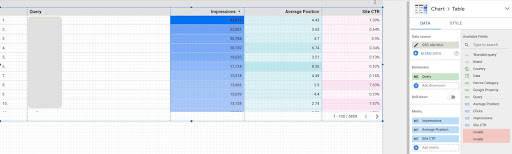
- Utwórz raport i dodaj do niego wykres tabeli
- Dodaj źródło danych „Wyświetlenie witryny” swojej witryny do raportu
- Wybierz „zapytanie” dla wymiaru oraz „ctr”, „średnia pozycja” i „”wyświetlenie” dla danych
- Odfiltruj zapytania zawierające nazwę marki, tworząc filtr (zapytania zawierające marki będą miały wyższy współczynnik klikalności, co zmniejszy dokładność naszych danych)
- Kliknij prawym przyciskiem myszy tabelę i kliknij Eksportuj
- Zapisz wynik jako CSV
2. Wczytywanie naszych danych i oznaczanie zapytań na podstawie ich pozycji
Do manipulowania pobranym plikiem CSV użyjemy Pand.
Najlepszą praktyką dla struktury folderów naszego projektu jest posiadanie folderu „data”, w którym zapisujemy wszystkie nasze dane.
Tutaj, ze względu na płynność samouczka, nie zrobiłem tego.
query_df = pd.read_csv('./downloaded_data.csv')
Następnie oznaczamy nasze zapytania na podstawie ich pozycji. Utworzyłem pętlę „for” do oznaczania pozycji od 1 do 10.
Na przykład, jeśli średnia pozycja zapytania wynosi 2,2 lub 2,9, zostanie ono oznaczone jako „2”. Manipulując średnim zakresem pozycji, możesz osiągnąć pożądaną dokładność.
dla i w zakresie (1, 11):
query_df.loc[(query_df['Średnia pozycja'] >= i) & (
query_df['Średnia pozycja'] < i + 1), 'etykieta pozycji'] = i
Teraz pogrupujemy zapytania na podstawie ich pozycji. Pomaga nam to lepiej manipulować każdą pozycją w zapytaniach o dane w kolejnych krokach.
query_grouped_df = query_df.groupby(['etykieta pozycji'])
3. Filtrowanie zapytań na podstawie ich danych w celu obliczenia krzywej CTR
Najłatwiejszym sposobem obliczenia krzywej CTR jest wykorzystanie wszystkich danych zapytań i wykonanie obliczeń. Jednakże; nie zapomnij pomyśleć o zapytaniach z jednym wyświetleniem na drugiej pozycji w Twoich danych.
Te zapytania, oparte na moim doświadczeniu, mają duży wpływ na ostateczny wynik. Ale najlepiej spróbować samemu. Na podstawie zbioru danych może się to zmienić.
Zanim zaczniemy ten krok, musimy stworzyć listę dla naszego wyjścia wykresu słupkowego i DataFrame do przechowywania naszych zmanipulowanych zapytań.
# Tworzenie DataFrame do przechowywania manipulowanych danych 'query_df' zmodyfikowany_df = pd.DataFrame() # Lista do zapisania każdej średniej pozycji dla naszego wykresu słupkowego średnia_lista_ctr = []
Następnie przełączamy się w pętli nad grupami query_grouped_df i dołączamy do ramki modified_df o największej liczbie 20% zapytań na podstawie wyświetleń.
Jeśli obliczanie CTR tylko na podstawie górnych 20% zapytań mających najwięcej wyświetleń nie jest dla Ciebie najlepsze, możesz to zmienić.
Aby to zrobić, możesz go zwiększyć lub zmniejszyć, manipulując .quantile(q=your_optimal_number, interpolation='lower')] , a your_optimal_number musi wynosić od 0 do 1.
Na przykład, jeśli chcesz uzyskać 30% najlepszych zapytań, your_optimal_num to różnica między 1 a 0,3 (0,7).
dla i w zakresie (1, 11):
# Try-oprócz obsługi sytuacji, w których katalog nie zawiera żadnych danych dla niektórych pozycji
próbować:
tmp_df = query_grouped_df.get_group(i)[query_grouped_df.get_group(i)['impressions'] >= query_grouped_df.get_group(i)['impressions']
.kwantyl(q=0,8, interpolacja='niższa')]
mean_ctr_list.append(tmp_df['ctr'].mean())
zmodyfikowany_df = zmodyfikowany_df.append(tmp_df, ignore_index=prawda)
z wyjątkiem KeyError:
mean_ctr_list.append(0)
# Usuwanie 'tmp_df' DataFrame w celu zmniejszenia zużycia pamięci
del [tmp_df]
4. Rysowanie wykresu pudełkowego
Ten krok jest tym, na co czekaliśmy. Aby narysować wykresy, możemy użyć Matplotlib, seaborn jako opakowania dla Matplotlib lub Plotly.
Osobiście uważam, że korzystanie z Plotly jest jednym z najlepszych rozwiązań dla marketerów, którzy uwielbiają eksplorować dane.
W porównaniu do Mathplotlib, Plotly jest tak łatwy w użyciu i za pomocą zaledwie kilku linijek kodu możesz narysować piękną fabułę.
# 1. Działka pudełkowa
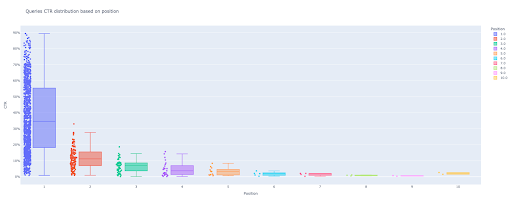
box_fig = px.box(modified_df, x='etykieta pozycji', y='CTR witryny', title='Rozkład CTR zapytań na podstawie pozycji',
points='wszystkie', color='etykieta pozycji', label={'etykieta pozycji': 'Pozycja', 'CTR witryny': 'CTR'})
# Pokazuje wszystkie dziesięć kleszczy osi X
box_fig.update_xaxes(tickvals=[i dla i w zakresie (1, 11)])
# Zmiana formatu znaczników osi Y na procenty
box_fig.update_yaxes(tickformat=".0%")
# Zapisywanie wykresu do katalogu 'output plot images'
box_fig.write_image('./output plot images/Kwerendy wykres pudełkowy CTR curve.png')
Za pomocą tylko tych czterech linii możesz uzyskać piękny wykres pudełkowy i rozpocząć eksplorację swoich danych.
Jeśli chcesz wchodzić w interakcję z tą kolumną, w nowym uruchomieniu komórki:
box_fig.show()
Teraz masz atrakcyjny wykres pudełkowy na wyjściu, który jest interaktywny.
Kiedy najedziesz kursorem na interaktywny wykres w komórce wyjściowej, ważną liczbą, którą jesteś zainteresowany, jest „człowiek” każdej pozycji.
Pokazuje średni CTR dla każdej pozycji. Ze względu na średnie znaczenie, jak pamiętasz, tworzymy listę, która zawiera średnią dla każdej pozycji. Następnie przejdziemy do następnego kroku, aby narysować wykres słupkowy na podstawie średniej każdej pozycji.
5. Rysowanie wykresu słupkowego
Podobnie jak wykres pudełkowy, rysowanie wykresu słupkowego jest tak łatwe. Możesz zmienić title wykresów, modyfikując argument title funkcji px.bar() .
# 2. Działka barowa
bar_fig = px.bar(x=[pos dla pozycji w zakresie (1, 11)], y=mean_ctr_list, title='Zapytania oznaczają rozkład CTR na podstawie pozycji',
label={'x': 'Pozycja', 'y': 'CTR'}, text_auto=True)
# Pokazuje wszystkie dziesięć kleszczy osi X
bar_fig.update_xaxes(tickvals=[i dla i w zakresie (1, 11)])
# Zmiana formatu znaczników osi Y na procenty
bar_fig.update_yaxes(tickformat='.0%')
# Zapisywanie wykresu do katalogu 'output plot images'
bar_fig.write_image('./output plot images/Queries bar plot CTR curve.png')
Na wyjściu otrzymujemy ten wykres:
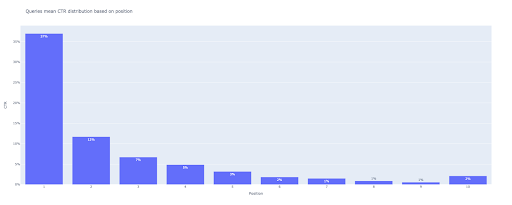
Podobnie jak w przypadku wykresu pudełkowego, możesz wchodzić w interakcje z tym wykresem, uruchamiając bar_fig.show() .
Otóż to! Za pomocą kilku linijek kodu uzyskujemy organiczny współczynnik klikalności na podstawie pozycji z danymi z naszych zapytań.
Jeśli masz właściwość adresu URL dla każdej z subdomen lub katalogów, możesz uzyskać te zapytania o właściwości adresu URL i obliczyć dla nich krzywą CTR.
[Studium przypadku] Poprawa rankingów, wizyt organicznych i sprzedaży dzięki analizie plików dziennika
 Przeczytaj studium przypadku
Przeczytaj studium przypadkuDruga metoda: obliczanie krzywej CTR na podstawie adresów URL stron docelowych dla każdego katalogu
W pierwszej metodzie obliczyliśmy nasz organiczny CTR na podstawie CTR zapytań, ale dzięki temu podejściu uzyskujemy wszystkie dane o naszych stronach docelowych, a następnie obliczamy krzywą CTR dla wybranych katalogów.

Kocham w ten sposób. Jak wiecie, CTR naszych stron produktów jest zupełnie inny niż naszych postów na blogu lub innych stron. Każdy katalog ma swój własny CTR na podstawie pozycji.
W bardziej zaawansowany sposób możesz skategoryzować każdą stronę katalogu i uzyskać organiczny współczynnik klikalności Google na podstawie pozycji dla zestawu stron.
1. Uzyskiwanie danych o stronach docelowych
Podobnie jak w przypadku pierwszej metody, istnieje kilka sposobów na uzyskanie danych z Google Search Console (GSC). W tej metodzie wolałem pobierać dane stron docelowych z eksploratora API GSC pod adresem: https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
Do tego, co jest potrzebne w tym podejściu, GDS nie zapewnia solidnych danych dotyczących strony docelowej. Możesz także użyć dodatku do Arkuszy Google „Analityka wyszukiwania w arkuszach”.
Pamiętaj, że Google API Explorer jest dobrym rozwiązaniem dla tych witryn, które zawierają mniej niż 25 tys. stron danych. W przypadku większych witryn możesz częściowo uzyskać dane stron docelowych i połączyć je ze sobą, napisać skrypt w języku Python z pętlą „for”, aby pobrać wszystkie dane z GSC, lub skorzystać z narzędzi innych firm.
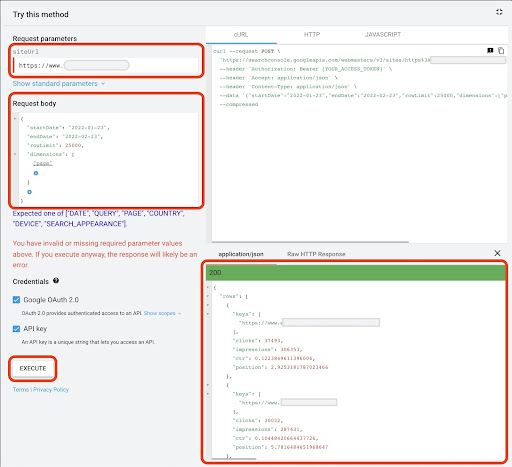
Aby pobrać dane z Google API Explorer:
- Przejdź do strony dokumentacji API GSC „Analiza wyszukiwania: zapytanie”: https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- Użyj Eksploratora API, który znajduje się po prawej stronie strony
- W polu „siteUrl” wpisz adres swojej usługi URL, np.
https://www.example.com. Możesz także wstawić właściwość domeny w następujący sposóbsc-domain:example.com - W polu „treść żądania” dodaj
startDateiendDate. Wolę otrzymywać dane z ostatniego miesiąca. Format tych wartości toYYYY-MM-DD - Dodaj
dimensioni ustaw jego wartości napage - Utwórz „dimensionFilterGroups” i odfiltruj zapytania z nazwami odmian marki (zastępując
brand_variation_namesTwojej marki RegExp) - Dodaj
rawLimiti ustaw go na 25000 - Na koniec naciśnij przycisk „WYKONAJ”
Możesz również skopiować i wkleić treść żądania poniżej:
{
"DataRozpoczęcia": "2022-01-01",
"endDate": "2022-02-01",
"wymiary": [
"strona"
],
"Grupy Filtrów Wymiarów": [
{
"filtry": [
{
"wymiar": "ZAPYTANIE",
"expression": "brand_variation_names",
"operator": "EXCLUDING_REGEX"
}
]
}
],
„Limit wiersza”: 25000
}
Po wykonaniu żądania musimy je zapisać. Ze względu na format odpowiedzi musimy utworzyć plik JSON, skopiować wszystkie odpowiedzi JSON i zapisać go z nazwą pliku downloaded_data.json .
Jeśli Twoja witryna jest mała, jak witryna firmy SASS, a dane dotyczące stron docelowych nie przekraczają 1000 stron, możesz łatwo ustawić datę w GSC i wyeksportować dane stron docelowych z zakładki „STRONY” jako plik CSV.
2. Ładowanie danych stron docelowych
Na potrzeby tego samouczka zakładam, że pobierasz dane z Google API Explorer i zapisujesz je w pliku JSON. Aby załadować te dane musimy uruchomić poniższy kod:
# Tworzenie DataFrame dla pobranych danych
z open('./downloaded_data.json') jako json_file:
landings_data = json.loads(json_file.read())['wiersze']
landings_df = pd.DataFrame(landings_data)
Dodatkowo musimy zmienić nazwę kolumny, aby nadała jej więcej znaczenia i zastosować funkcję, aby uzyskać adresy URL stron docelowych bezpośrednio w kolumnie „strona docelowa”.
# Zmiana nazwy kolumny „klucze” na kolumnę „strona docelowa” i konwersja listy „strona docelowa” na adres URL
landings_df.rename(columns={'keys': 'strona docelowa'}, inplace=True)
landings_df['strona docelowa'] = landings_df['strona docelowa'].apply(lambda x: x[0])
3. Pobieranie wszystkich katalogów głównych stron docelowych
Przede wszystkim musimy zdefiniować nazwę naszej strony.
# Definiowanie nazwy witryny między cudzysłowami. Na przykład „https://www.example.com/” lub „http://moja_domena.com/” nazwa_witryny = ''
Następnie uruchamiamy funkcję na adresach URL stron docelowych, aby pobrać ich katalogi główne i zobaczyć je w danych wyjściowych, aby je wybrać.
# Uzyskiwanie każdego katalogu stron docelowych (URL)
landings_df['katalog'] = landings_df['strona docelowa'].str.extract(pat=f'((?<={site_name})[^/]+)')
# Aby uzyskać wszystkie katalogi w danych wyjściowych, musimy manipulować opcjami Pandy
pd.set_option("display.max_rows", Brak)
# Katalogi stron internetowych
landings_df['katalog'].value_counts()
Następnie wybieramy, dla których katalogów potrzebujemy uzyskać ich krzywą CTR.
Wstaw katalogi do zmiennej important_directories .
Na przykład product,tag,product-category,mag . Oddziel wartości katalogu przecinkami.
ważne_katalogi = ''
ważne_katalogi = ważne_katalogi.split(',')
4. Etykietowanie i grupowanie stron docelowych
Podobnie jak zapytania, oznaczamy również strony docelowe na podstawie ich średniej pozycji.
# Etykietowanie pozycji stron docelowych
dla i w zakresie (1, 11):
landings_df.loc[(landings_df['pozycja'] >= i) & (
landings_df['pozycja'] < i + 1), 'etykieta pozycji'] = i
Następnie grupujemy strony docelowe na podstawie ich „katalogu”.
# Grupowanie stron docelowych na podstawie ich wartości „katalogu” landings_grouped_df = landings_df.groupby(['katalog'])
5. Generowanie wykresów pudełkowych i słupkowych dla naszych katalogów
W poprzedniej metodzie nie używaliśmy funkcji do generowania wykresów. Jednakże; aby automatycznie obliczyć krzywą CTR dla różnych stron docelowych, musimy zdefiniować funkcję.
# Funkcja tworzenia i zapisywania każdego wykresu katalogów
def each_dir_plot(dir_df, klucz):
# Grupowanie stron docelowych w katalogu na podstawie ich wartości „etykiety pozycji”
dir_grouped_df = dir_df.groupby(['etykieta pozycji'])
# Tworzenie DataFrame do przechowywania manipulowanych danych 'dir_grouped_df'
zmodyfikowany_df = pd.DataFrame()
# Lista do zapisania każdej średniej pozycji dla naszego wykresu słupkowego
średnia_lista_ctr = []
''''
Przewijanie grup „query_grouped_df” i dołączanie górnych 20% zapytań na podstawie wyświetleń do ramki DataFrame „modified_df”.
Jeśli obliczanie CTR tylko na podstawie górnych 20% zapytań mających najwięcej wyświetleń nie jest dla Ciebie najlepsze, możesz to zmienić.
Aby go zmienić, możesz go zwiększyć lub zmniejszyć, manipulując '.quantile(q=your_optimal_number, interpolation='lower')]'.
„you_optimal_number” musi zawierać się w przedziale od 0 do 1.
Na przykład, jeśli chcesz uzyskać 30% najlepszych zapytań, „your_optimal_num” to różnica między 1 a 0,3 (0,7).
''''
dla i w zakresie (1, 11):
# Try-oprócz obsługi sytuacji, w których katalog nie zawiera żadnych danych dla niektórych pozycji
próbować:
tmp_df = dir_grouped_df.get_group(i)[dir_grouped_df.get_group(i)['impressions'] >= dir_grouped_df.get_group(i)['impressions']
.kwantyl(q=0,8, interpolacja='niższa')]
mean_ctr_list.append(tmp_df['ctr'].mean())
zmodyfikowany_df = zmodyfikowany_df.append(tmp_df, ignore_index=prawda)
z wyjątkiem KeyError:
mean_ctr_list.append(0)
# 1. Działka pudełkowa
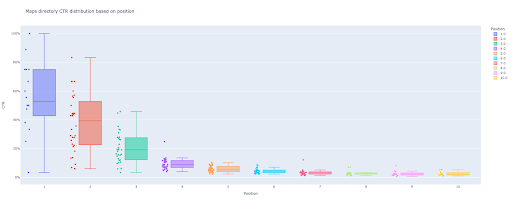
box_fig = px.box(modified_df, x='etykieta pozycji', y='ctr', title=f'{key} rozkład CTR katalogu na podstawie pozycji',
points='wszystkie', color='etykieta pozycji', label={'etykieta pozycji': 'Pozycja', 'ctr': 'CTR'})
# Pokazuje wszystkie dziesięć kleszczy osi X
box_fig.update_xaxes(tickvals=[i dla i w zakresie (1, 11)])
# Zmiana formatu znaczników osi Y na procenty
box_fig.update_yaxes(tickformat=".0%")
# Zapisywanie wykresu do katalogu 'output plot images'
box_fig.write_image(f'./output plot images/{key} directory-Box plot CTR curve.png')
# 2. Działka barowa
bar_fig = px.bar(x=[pos dla pozycji w zakresie(1, 11)], y=mean_ctr_list, title=f'{key} katalog oznacza rozkład CTR na podstawie pozycji',
label={'x': 'Pozycja', 'y': 'CTR'}, text_auto=True)
# Pokazuje wszystkie dziesięć kleszczy osi X
bar_fig.update_xaxes(tickvals=[i dla i w zakresie (1, 11)])
# Zmiana formatu znaczników osi Y na procenty
bar_fig.update_yaxes(tickformat='.0%')
# Zapisywanie wykresu do katalogu 'output plot images'
bar_fig.write_image(f'./output plot images/{key} directory-Bar wykres CTR curve.png')
Po zdefiniowaniu powyższej funkcji potrzebujemy pętli „for”, aby zapętlić dane katalogów, dla których chcemy uzyskać ich krzywą CTR.
# Zapętlenie katalogów i wykonanie funkcji 'each_dir_plot'
dla klucza, pozycja w landings_grouped_df:
jeśli klucz w ważnych_katalogach:
each_dir_plot(element, klucz)
W wyniku otrzymujemy nasze wykresy w folderze output plot images wykresów.
Zaawansowana wskazówka!
Możesz również obliczyć krzywe CTR różnych katalogów, korzystając ze strony docelowej zapytań. Dzięki kilku zmianom w funkcjach możesz grupować zapytania na podstawie ich katalogów stron docelowych.
Możesz użyć poniższej treści żądania, aby wykonać żądanie API w API Explorer (nie zapomnij o ograniczeniu 25000 wierszy):
{
"DataRozpoczęcia": "2022-01-01",
"endDate": "2022-02-01",
"wymiary": [
"zapytanie",
"strona"
],
"Grupy Filtrów Wymiarów": [
{
"filtry": [
{
"wymiar": "ZAPYTANIE",
"expression": "brand_variation_names",
"operator": "EXCLUDING_REGEX"
}
]
}
],
„Limit wiersza”: 25000
}
Wskazówki dotyczące dostosowywania obliczania krzywej CTR w Pythonie
Aby uzyskać dokładniejsze dane do obliczenia krzywej CTR, musimy skorzystać z narzędzi firm trzecich.
Na przykład, poza wiedzą, które zapytania mają polecany fragment, możesz poznać więcej funkcji SERP. Ponadto, jeśli korzystasz z narzędzi innych firm, możesz uzyskać parę zapytań z pozycją strony docelowej dla tego zapytania na podstawie funkcji SERP.
Następnie etykietowanie stron docelowych z ich katalogiem głównym (nadrzędnym), grupowanie zapytań na podstawie wartości katalogów, uwzględnianie funkcji SERP i wreszcie grupowanie zapytań na podstawie pozycji. W przypadku danych CTR możesz scalić wartości CTR z GSC z ich zapytaniami równorzędnymi.