
Znaczenie sieci semantycznej dla SEO: tworzenie semantycznych sieci partnerskich za pomocą szablonów zapytań i dokumentów – studium przypadku
Opublikowany: 2022-01-11Sieć semantyczna jest połączona z koncepcją bazy wiedzy, która może reprezentować informacje ze świata rzeczywistego dla rzeczy, które mają połączenia relacyjne. Baza wiedzy może zawierać tysiące typów relacji z miliardami jednostek i bilionami faktów. Sieć semantyczną można utworzyć z dowolnego rzeczywistego istnienia o wspólnych cechach, takich jak waga, rozmiar, rodzaj, zapach lub kolor. Relację między sieciami semantycznymi a siecią semantyczną tworzą semantyczne wyszukiwarki i optymalizacja.
Sieci semantyczne są używane w analizowaniu semantycznym, uściślaniu słów, tworzeniu WordNet, teorii grafów, przetwarzaniu języka naturalnego, rozumieniu i generowaniu. Perspektywa sieci semantycznej może być wykorzystana w ramach Semantic Search Engine Optimization poprzez zapewnienie semantycznej sieci treści.
W tym studium przypadku SEO zostaną wyjaśnione dwie różne strony internetowe z dwiema różnymi metodami z tą samą perspektywą w oparciu o szablony zapytania, dokumentu, intencji i stojące za nimi pary jednostka-atrybut.
Wykorzystując zrozumienie, w jaki sposób wyszukiwarki reprezentują wiedzę i jak poszerzają swoją reprezentację wiedzy, jestem w stanie wykorzystać to, aby uzyskać niesamowite wyniki w rankingu. Gdy zrozumiesz podstawowe pojęcia, wyjaśnię, w jaki sposób zastosowałem je na dwóch różnych stronach internetowych, a następnie opiszę szczegółowo zastosowane metody.
W jaki sposób sieci semantyczne mogą pomóc w rankingu Twojej witryny?
Poniżej znajdziesz ogólne wyniki surowe dla Projektu I.
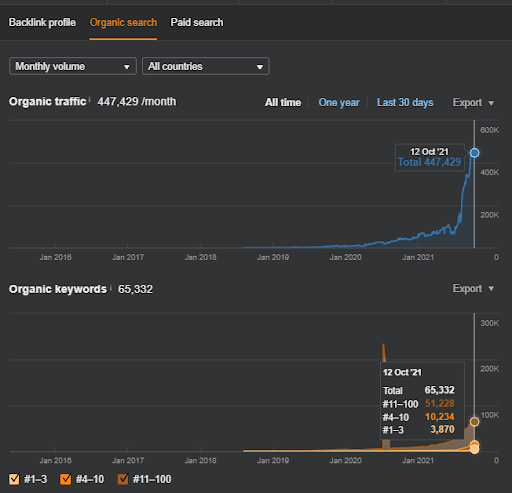
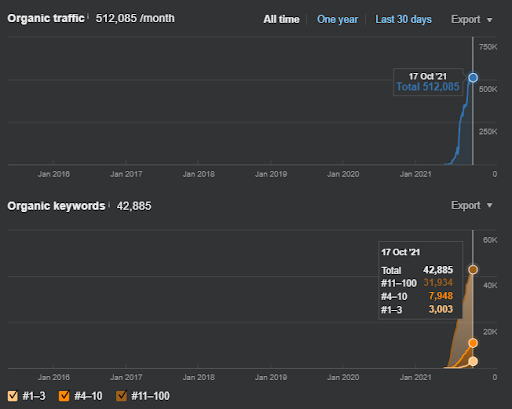
Wyniki projektu pierwszego, którym jest IstanbulBogaziciEnstitu.com. Aby udowodnić, że „Sieci semantyczne” mogą być używane do SEO z szablonami zapytań i dokumentów, zademonstruję dwie różne sieci informacyjne z Project One. Project One przyniesie znacznie lepsze wyniki w najbliższej przyszłości dzięki Semantic Content Network Two. Klient będzie odpowiedzialny za uruchomienie tej drugiej sieci, ale wyjaśnię też jej logikę.
17 dni później, oto postępy poczynione w Projekcie I: 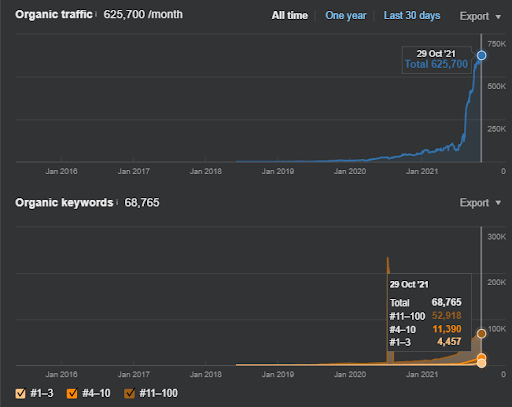
17 dni później proces zmiany rankingu Semantic Content Network jest bardziej przejrzysty.
Koncepcje semantycznej sieci partnerskiej pomagają nam zrozumieć wartość zapytań, intencji wyszukiwania, zachowań i szablonów dokumentów dla jednostek tego samego typu. W tym studium przypadku dotyczącym SEO skoncentrowanym na sieci semantycznej, poprzednie studium przypadku dotyczące autorytetu tematycznego i semantycznego SEO zostanie pogłębione poprzez dwie nowe witryny internetowe, które wykorzystują semantycznie tworzone sieci informacyjne wokół tych samych typów jednostek.
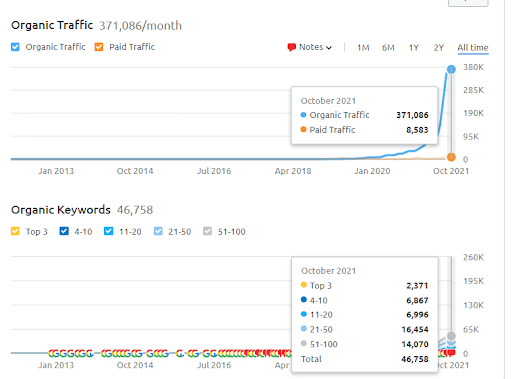
To jest grafika SEMRush pierwszego projektu. Muszę również wspomnieć, że ta strona straciła czerwcową aktualizację algorytmu Broad Core, gdyby nie straciła swojej „rankingu”, wyniki byłyby lepsze. W przypadku następnej aktualizacji Broad Core Algorithm, z lepszym autorytetem tematycznym, zasięgiem i danymi historycznymi, można łatwo odzyskać „ranking”.
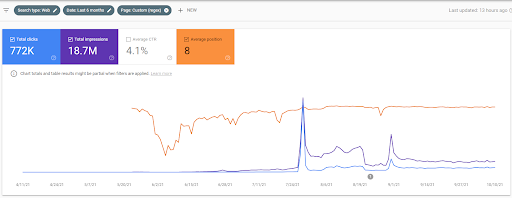
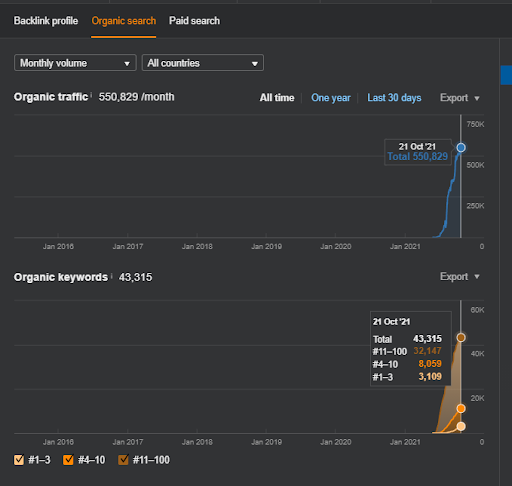
Nazwa Drugiego Projektu to Vizem.net. W przeciwieństwie do Project One widać, że Vizem.net ma wolniejszy, ale stały wzrost. Dzieje się tak dlatego, że używają semantycznych sieci partnerskich z nieco innych perspektyw. Poniżej możesz zobaczyć wyniki drugiego projektu Ahrefs.
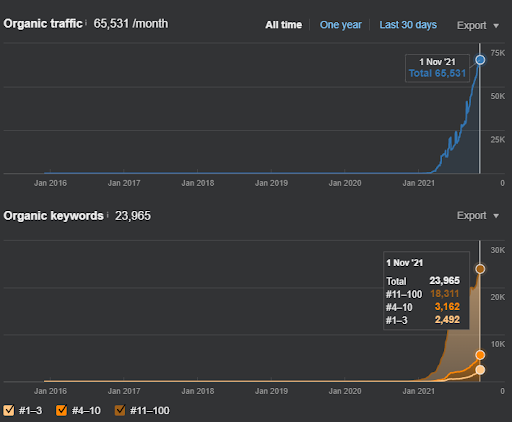
Wyniki Drugiego Projektu reprezentują „powolny proces zmiany rankingu” poprzez stopniową poprawę zasięgu tematycznego i autorytetu. Terminy „Ponowny ranking” i „Ranking początkowy” zostaną wyjaśnione po pojęciach związanych z semantycznymi sieciami treści. Jeśli zdajesz sobie sprawę z „stabilności” grafiki, to dlatego, że przestałem publikować nowe treści w źródle. I ma to wpływ na proces ponownego rankingu, jak widać na podstawie zliczeń 3 najczęstszych zliczeń zapytań. Relacje „Momentum” i „Reranking” można znaleźć po wyjaśnieniu podstawowych pojęć.
Poniżej znajdziesz wyniki SEMRush firmy Vizem.net.
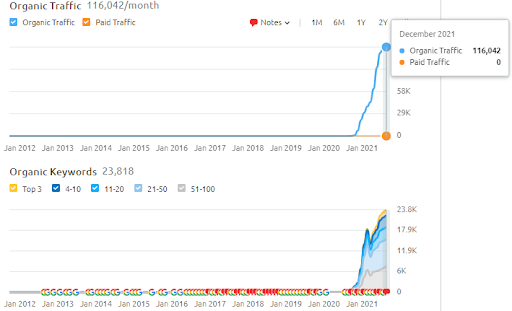
Rzeczywisty ruch na tej stronie jest 3 razy większy od liczby podanej w SEMRush. Możesz zrealizować tę samą „stabilność” i koncepcje „pędu” również na tych wykresach.
Pisząc studium przypadku Topical Authority SEO Case, podziękowałem Billowi Sławskiemu za poszerzenie mojej perspektywy. Powtarzam to również w przypadku Semantic Content Network SEO Case Study. Aby zrozumieć koncepcje „Ponownej rangi” i „Początkowej rangi”, należy przeczytać „W jaki sposób wyszukiwarki mogą zmienić pozycję wyników wyszukiwania”.
18 marca 2021 r. Oncrawl, RankSense i Holistic SEO & Digital opublikowały webinarium Python SEO and Data Science. Podczas webinaru zarejestrowano SERP w celu animowania różnic w wynikach. Widać, że wyszukiwarka zmienia rankingi niektórych źródeł z innymi z podobną częstotliwością.
Zanim przejdę dalej, wiem, że to długi artykuł. Ale tak naprawdę jest to krótkie wyjaśnienie bardzo złożonej metodologii SEO. Semantyczne sieci partnerskie wymagają zbytniego myślenia podczas ich projektowania oraz miesięcy edukacji dla klientów, autorów i przy wdrażaniu. Dlatego w tym artykule chcę skupić się na definicjach pojęć z najlepszymi możliwymi do wykonania krótkimi sugestiami i ważnymi patentami Google i innych wyszukiwarek, artykułami badawczymi wraz z ich własnymi koncepcjami. W wersji dłuższej (w zasadzie książka) skupiłem się na „rankingu początkowym” i „re-rankingu” semantycznych sieci treści.
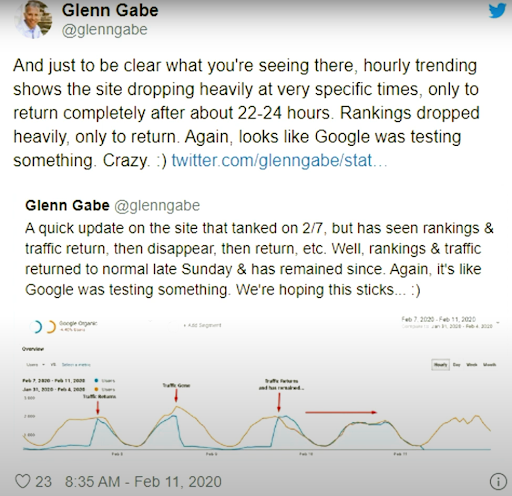
Od 11 lutego 2020 r. Glenn Gabe ma dobry przykład wizualnej metodologii ponownego rankingowania i testowania wyszukiwarek.
Jeśli chcesz dowiedzieć się więcej, przeczytaj „Znaczenie początkowego rankingu i ponownego rankingu dla SEO”.
Aby zagłębić się w rzeczywiste dane na potrzeby studium przypadku SEO, koncepcje zrozumienia semantycznej sieci treści powinny być przetwarzane z perspektywy rozumienia wyszukiwarek.
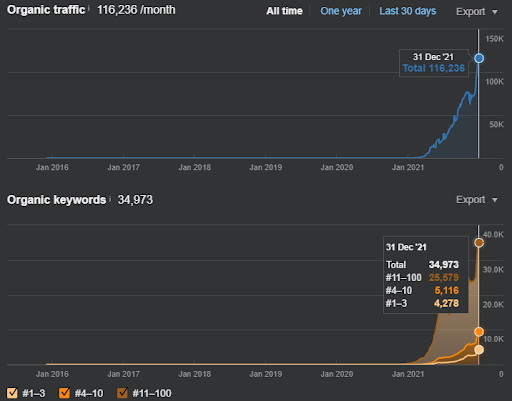
Jako przykład zmiany rankingu Vizem.net, zaktualizowaną sytuację można zobaczyć powyżej. W przyszłych sekcjach studium przypadku SEO będzie więcej wyjaśnień dotyczących algorytmów ponownego rankingu Google pod kątem SEO.
Co to jest sieć semantyczna?
Sieć semantyczna może być używana do łączenia i analizowania internetu rzeczy. Może to być korzystne dla rozpoznania potencjalnych nabywców na rynku technologii lub po prostu analizy słów kluczowych dla tworzenia sieci słów kluczowych i grupowania. Sieć semantyczna może służyć do wspomagania nawigacji i ujawniania struktury relacji lub relatywnego znaczenia rzeczy w stosunku do innej rzeczy. Sieć semantyczna składa się z następujących komponentów:
- Semantyka leksykalna: Zrozumienie, które słowo i pojęcie są powiązane z jakimi innymi, z jakimi różnicami.
- Komponent strukturalny: Zrozumienie, który węzeł jest połączony z którą krawędzią z jakimi informacjami.
- Składnik semantyczny: Definicja faktów.
- Część proceduralna: pomaga w tworzeniu dalszych połączeń między komponentami.
Ponieważ sieci semantyczne są wielozadaniowe, algorytmy NLP mogą być również wykorzystywane do bardzo różnych celów, takich jak pomoc w identyfikowaniu skomplikowanych problemów zdrowotnych. Ta sama struktura sieci semantycznej może być zaimplementowana w wielu innych obszarach, o ile te inne obszary pozostają między sobą w relacji semantycznej.
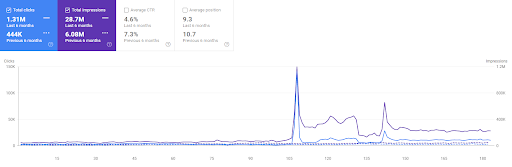
Porównanie pierwszego projektu z ostatnich 6 miesięcy.
Czym jest baza wiedzy?
Baza wiedzy to biblioteka informacji z klasyfikacją w formie do odczytu maszynowego. Baza wiedzy może służyć jako encyklopedia, którą można zawężać i pogłębiać na podstawie zapytania. Bazę wiedzy można utworzyć na podstawie propozycji, ekstrakcji faktów i ekstrakcji informacji. Relacja między siecią semantyczną a bazą wiedzy polega na tym, że wszystko, co znajduje się w sieci semantycznej, zostanie umieszczone w bazie wiedzy podczas wydobywania faktów.
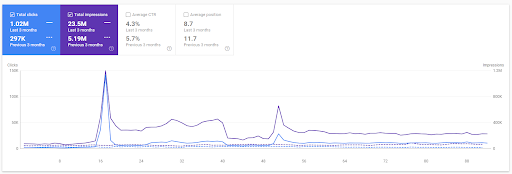
Porównanie Pierwszego Projektu z ostatnich 3 miesięcy
Co to jest semantyczna sieć partnerska?
Semantic Content Network reprezentuje sieć treści, która została przygotowana na podstawie komponentów sieci semantycznej i zrozumienia. Semantyczna sieć treści może zawierać wiele atrybutów jednostki lub jednostek z tej samej grupy w celu dostarczenia bardziej szczegółowej bazy wiedzy.
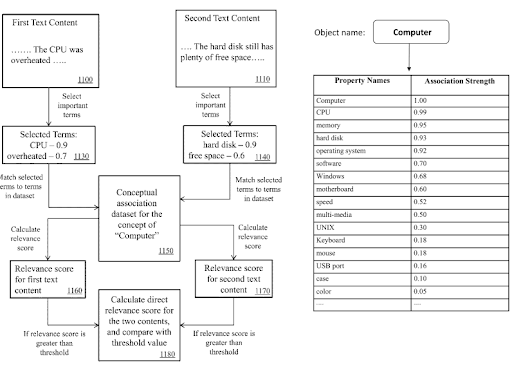
W ramach Semantic Content Network, Knowledge Domain Terms i Triples mogą być używane do sygnalizowania głównego celu dokumentu i ewentualnych elementów treści sąsiednich.
Wyszukiwarka może porównać własną bazę wiedzy z bazą wiedzy, którą można wygenerować z zawartości witryny. Jeśli strona internetowa ma wysoki poziom dokładności i kompleksowości dla różnych warstw kontekstowych, wyszukiwarka może ulepszyć własną bazę wiedzy z zawartości strony. Jeśli wyszukiwarka ulepsza i rozszerza swoją własną bazę wiedzy z innego źródła w otwartej sieci, jest to sygnał wysokiego poziomu zaufania opartego na wiedzy.
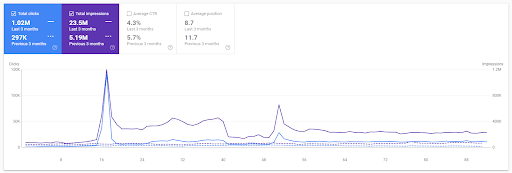
Porównanie rok do roku za ostatnie 3 miesiące na podstawie pierwszego projektu.
Co to jest zaufanie oparte na wiedzy?
Zaufanie oparte na wiedzy koncentruje się na otwartej sieci opartej na „dokładności informacji”, a nie „PageRank”. Jest to algorytm podobny do RankMerge. Zaufanie oparte na wiedzy obejmuje trojaczki, wyodrębnianie faktów, sprawdzanie dokładności i zrozumienie tekstu poprzez usunięcie niejednoznaczności tekstu. Zaufanie oparte na wiedzy można uzyskać, dostarczając semantyczne sieci treści, które mają silnie połączone komponenty w artykule, oparte na różnych, ale odpowiednich warstwach kontekstowych.
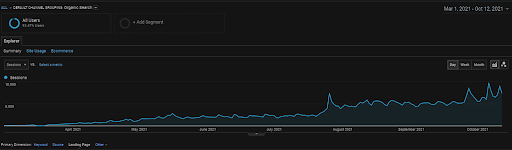
Sesja organiczna Vizem.net z GA za ostatnie 6 miesięcy.
Poniżej zobaczysz przykład prezentacji opartej na wiedzy Trust od Luna Dong. Pokazuje, jak wyszukiwarka może skupić się na „wewnętrznych czynnikach rankingowych” zamiast na egzogenicznych czynnikach rankingowych. Wyjaśnia, że wysoki PageRank nie może sam w sobie oznaczać wysokiej jakości i dokładności treści. Dlatego ważne jest posiadanie KBT (Knowledge-based Trust).
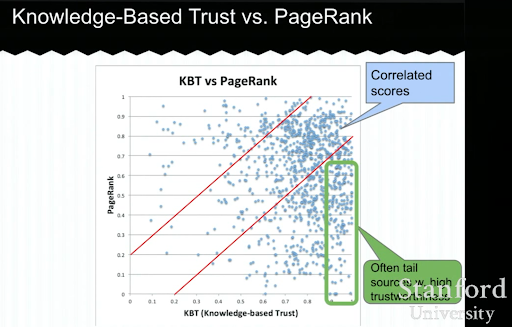
Ogromne podziękowania dla Arnouta Hellemansa, który podzielił się ze mną tym edukacyjnym wykładem podczas prywatnego czatu SEO. Jeśli chcesz dowiedzieć się więcej o zaufaniu opartym na wiedzy: Seminarium Stanford – Magazyn wiedzy i zaufanie oparte na wiedzy
Co to jest pokrycie kontekstowe?
Zasięg kontekstowy i zasięg tematyczny to nie to samo, co domena wiedzy i domena kontekstowa to nie to samo. Pokrycie kontekstowe reprezentuje kąty przetwarzania koncepcji. Pojęcie można przetwarzać na podstawie jego wspólnych punktów z innymi rzeczami. Na przykład, jeśli podmiot jest krajem, jego stanowisko w sprawie kryzysu środowiskowego może zostać przetworzone. Jeśli inne kraje są przetwarzane pod tym samym kątem, oznacza to, że obejmujemy domenę kontekstową.

Wyszukiwarka Google z biegiem czasu tworzy swoje prace badawcze i patenty. Prawy cytat z powyższej sekcji jest atrybutem „wektorów kontekstowych”, podczas gdy lewa sekcja jest atrybutem „taksonomii fraz”. Ciekawostką jest to, że nawet przykład jest taki sam, czyli „aparat cyfrowy”.
Pogłębione szczegóły i podczęści tych kombinacji reprezentują warstwy kontekstowe w obrębie domeny kontekstowej. Każda jednostka, niezależnie od tego, czy jest nazwana, czy nie, ma wiele domen kontekstowych. W ten sposób Google co roku wyodrębnia więcej domen kontekstowych, a użytkownicy wyszukują dłuższe zapytania. Po opracowaniu przetwarzania języka naturalnego i zrozumienia języka naturalnego zapytania i dokumenty rozszerzają się pod względem szczegółów i kontekstu.
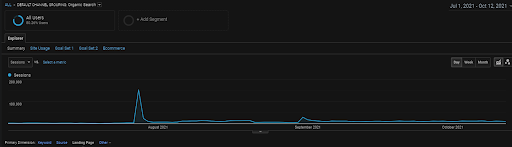
Grafika GA Organic Sessions z ostatnich 4 miesięcy projektu BogaziciEnstitu. Ze względu na „Etap pozyskiwania danych historycznych” projektu, zwiększone szczegóły nie są jasne, aby były postrzegane jako liniowe.
Zasięg kontekstowy można rozumieć przez „kwalifikatory kontekstu”. Kwalifikator kontekstu może być przymiotnikiem, przysłówkiem lub dowolnym innym przyimkiem, takim jak frazy zaczynające się od „for, in, at, while, while”. Poniższe pytania dotyczące encji nie są takie same pod względem domeny kontekstowej:
- Jakie są najbardziej przydatne owoce dla dzieci z bezsennością?
- Jakie są najbardziej przydatne owoce dla dzieci z lękiem?
Poniższe pytania dotyczące encji nie są takie same pod względem warstwy kontekstowej:
- Jakie są najbardziej przydatne owoce dla dzieci z ciężką bezsennością powyżej 6 roku życia?
- Jakie są najbardziej przydatne owoce dla dzieci poniżej 6 roku życia z niskim poziomem lęku?
Poniższe pytania dotyczące encji nie są takie same pod względem domen wiedzy:
- Jakie są najbardziej przydatne książki dla dzieci w wieku powyżej 6 lat z ciężką bezsennością?
- Jakie są najbardziej przydatne gry dla dzieci w wieku poniżej 6 lat z niskim poziomem lęku?
Ale wszystkie te pytania mogą dotyczyć tej samej sieci semantycznej, ponieważ wszystkie dotyczą tego samego „pojęcia” i „obszaru zainteresowań” z podobną aktywnością związaną z wyszukiwaniem i aktywnością w świecie rzeczywistym związaną z wyszukiwaniem.
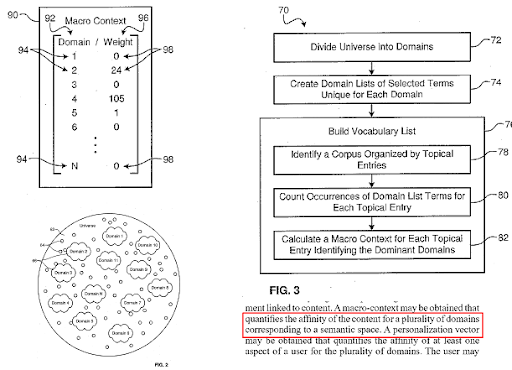
Wyszukiwarka dzieli sieć na różne domeny wiedzy i jednocześnie oblicza wyniki makro i mikrokontekstu dla źródła, strony internetowej i sekcji strony internetowej.
Wiem, że mam dla Ciebie wiele nowych koncepcji, a ponieważ jest to skrócona wersja tego artykułu, nie będę mógł tutaj o wszystkim mówić, ale w przyszłym kursie semantycznego SEO omówię takie rzeczy, jak różnica między „aktywnością związaną z wyszukiwaniem” a „aktywnością związaną z wyszukiwaniem w świecie rzeczywistym”.
Przejdźmy trochę do konkretów.
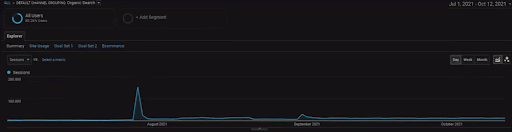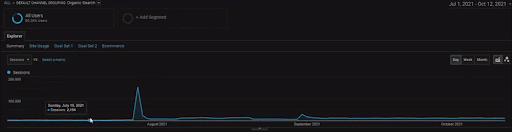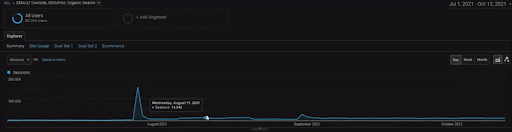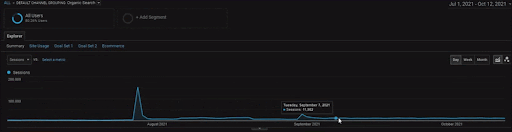
Aby pokazać szczegóły Projektu BogaziciEnstitu, możesz sprawdzić interaktywną wersję obrazu. Proces testowania i zmiany rankingu wyszukiwarek jest w tym projekcie bardziej przejrzysty po zdarzeniu źródła danych historycznych.
Jaki jest związek MuM z semantycznymi sieciami treści?
Wielozadaniowe uczenie się za pomocą zunifikowanego transformatora lub ujednoliconego modelu wielozadaniowego szkoli modele językowe w celu oceny danych wejściowych wizualnych, a także tekstu. Jest w stanie generować tekst wraz ze zrozumieniem. Dodatkowo MuM jest niezależny od języka, innymi słowy, semantyczne SEO zależy od umiejętności językowych, ale nie jest ograniczone do języka. Ponieważ podmioty nie mają języka, a znaczenie jest uniwersalne, MuM wykorzystuje informacje z wielu języków i wielu kontekstów w jednej bazie wiedzy.
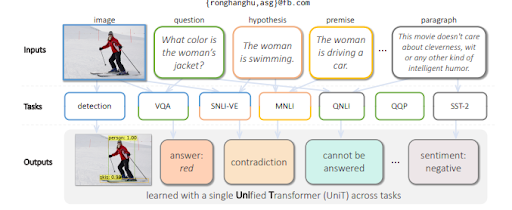
Aby odpowiedzieć na pytania z wizualizacji, MuM generuje pytania na podstawie wykrytych obiektów na obrazie. W niedalekiej przyszłości będzie można również generować pytania związane z audio i wideo.
MuM wykorzystuje różne domeny do wykrywania obiektów i rozumienia języka naturalnego dzięki strukturze kodera-dekodera transformatora. Każde wejście pochodzi z innego obszaru otwartej sieci, podczas gdy wszystkie są oceniane z jednego współdzielonego dekodera. Poniżej możesz zobaczyć kolejny przykład z artykułu badawczego.
Uwaga: MuM może być 1000 razy silniejszy niż BERT, ale BERT jest nadal używany w Text Encoder of MuM. Główną zaletą MuM jest to, że można go używać bezpośrednio do wizualizacji i dźwięku, dlatego można go nazwać modelem „wielozadaniowym”. Drugą zaletą jest to, że bezpośrednio usuwa wszystkie bariery językowe. Trzecią zaletą jest to, że jest w stanie połączyć wszystko z inną rzeczą bez potrzeby dodatkowych pośredników. Czwartą zaletą jest to, że MuM może również generować tekst, w przeciwieństwie do BERT.
Związek między MuM, Bazą Wiedzy, Sieciami Semantycznymi i Pokryciem Kontekstowym polega na tym, że wyszukiwarka jest w stanie znaleźć znacznie bardziej kontekstową domenę za pomocą kwalifikatorów kontekstowych i ich kombinacji z możliwymi domenami wiedzy. W ten sposób dobrze zorganizowana sieć treści semantycznych, która jest ukształtowana z odpowiednią mapą tematyczną i kontekstem źródłowym, może poprawić zaufanie do bazy wiedzy wraz z autorytetem tematycznym.
Jaki jest kontekst źródła?
Kontekst Źródła reprezentuje dwie rzeczy. Centralne wyszukiwanie internetowe źródła i centralne wyszukiwanie, które można wykonać za pomocą powiązanego wyszukiwania. W przypadku witryny e-commerce kontekstem źródłowym jest zakup określonego produktu lub określonego typu produktu. Jeśli jest to witryna turystyczna, kontekst źródła przenosi się gdzieś z innego miejsca w przypadku różnych rodzajów żywności, krajobrazów lub po prostu biznesu. Na podstawie kontekstu źródła należy dalej skonfigurować projekt semantycznej sieci partnerskiej i mapę tematyczną. Wymaga to wybrania sekcji środkowych na mapie tematycznej i sekcji dodatkowych na mapie tematycznej.
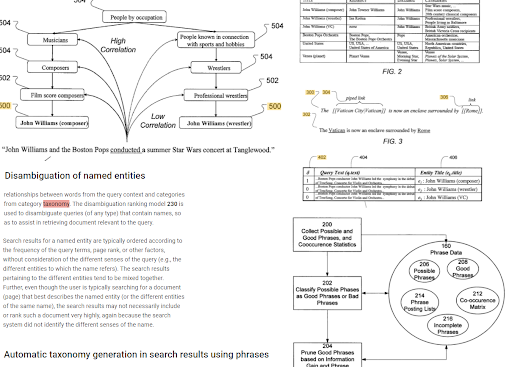
Indeksowanie oparte na frazach i zrozumienie wyszukiwania zorientowane na jednostki są ze sobą połączone w oparciu o semantykę. Powyżej „Ujednoznacznienie nazwanej jednostki” i „Automatyczne generowanie taksonomii w wynikach wyszukiwania za pomocą fraz” można zobaczyć razem w celu określenia „kontekstu”. Dobre frazy i unikalne, ale skorelowane informacje na temat pomogą w lepszym początkowym i ponownym rankingu.
Ponownie, niektóre z tych pojęć, „konfiguracja mapy tematycznej”, „semantyczny projekt sieci partnerskiej” nie zostały jeszcze zdefiniowane i nie jest to właściwe miejsce. Jednak powiązana aktywność wyszukiwania została wyjaśniona wraz z kanoniczną intencją wyszukiwania i reprezentatywnymi wyrażeniami dla tych kanonicznych intencji wyszukiwania.
Tło studium przypadku SEO skoncentrowanego na sieci semantycznej
W oparciu o powyższe koncepcje wykorzystałem sieci semantyczne do stworzenia studium przypadku SEO. Przyjrzymy się dwóm projektom stron internetowych, o których wspomniałem na początku tego artykułu, i zbadamy ich wyniki oraz sposób, w jaki zaimplementowałem sieci semantyczne do ich tworzenia.
Aby dać ci wyobrażenie o tym, jak potężne mogą być te sieci, poniżej przedstawiono wyniki związane z SEO dla studium przypadku SEO skoncentrowanego na sieci semantycznej.
- Zrozumienie sieci semantycznej jest koniecznością stworzenia odpowiedniej mapy tematycznej.
- W obu projektach SEO techniczne nie jest wykorzystywane w celu wyizolowania efektów SEO semantycznego.
- Optymalizacja szybkości strony nie jest używana z tego samego powodu.
- Projektowanie i optymalizacja WUX (Website User Experience) nie są używane.
- Linki zwrotne (odniesienia zewnętrzne i przepływ PageRank) nie są używane.
- Obie marki nie posiadają danych historycznych. Vizem.net jest zupełnie nowy, BogaziciEnstitusu ma starszą historię, ale była niższa niż rzeczywista firma.
- Nie używamy OnPage SEO ani innych branż SEO.
- Obie marki mają lepszy serwer niż w poprzednim przykładzie Topical Authority Case Study.
To studium przypadku SEO skoncentrowane na sieci semantycznej pomoże osobom, które chcą poprawić swoją perspektywę semantycznego SEO za pomocą dwóch różnych metodologii i koncepcji, które koncentrują się na dwóch różnych witrynach internetowych.
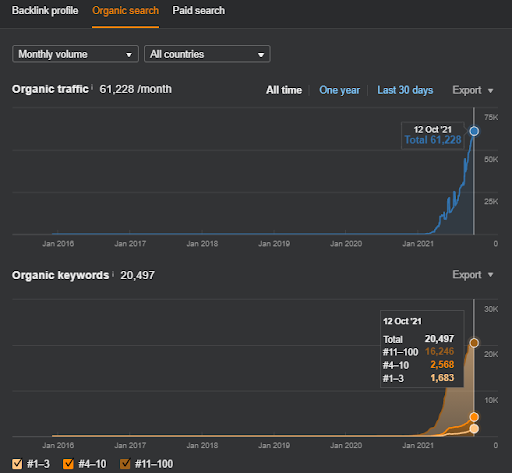
Projekt drugi: Vizem.net koncentruje się na procesie składania wniosków wizowych. Przed napisaniem, opublikowaniem, a nawet uruchomieniem tych projektów, wielokrotnie pokazywałem obie te strony innym moim klientom lub partnerom. A Vizem.net niedawno rozpoczął swoją podróż „Topical Authority”.
Pozycjonowanie w oparciu o studium przypadku Semantic Networks zostało napisane w dwóch różnych wersjach. Jeśli chcesz zapoznać się ze wszystkimi powiązanymi patentami, artykułami badawczymi i głęboko szczegółowymi badaniami, interpretacjami z punktu widzenia wyszukiwarek, jednocześnie lepiej rozumiejąc drzewa decyzyjne wyszukiwarek, możesz przeczytać Znaczenie wstępnego rankingu i ponownego rankingu SEO Artykuł studium przypadku dłuższy niż 30 000 słów. Jeśli nie masz wystarczającej wiedzy teoretycznej na temat SEO i tła historycznego, możesz kontynuować czytanie podsumowania.
Poniżej możesz zobaczyć grafikę Second Project (Vizem.net) z SEMRush.
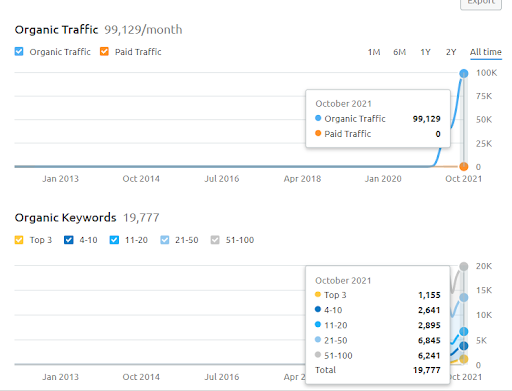
Grafika SEMRush drugiej strony internetowej. Vizem.net to całkowicie nowe źródło skierowane do branż o wysokim poziomie zakorzenionych konkurentów, takich jak „Aplikacja wizowa”. Szczególnie w związku z ostatnimi wydarzeniami w Turcji rośnie poziom konkurencji w branży. Dlatego przydatne jest korzystanie z perspektywy sieci semantycznej do tworzenia sieci partnerskiej.
Pierwszy projekt: Istanbul Bogazici Enstitusu: wzrost liczby kliknięć o 600% w ciągu 3 miesięcy — wykorzystanie danych historycznych i początkowego rankingu
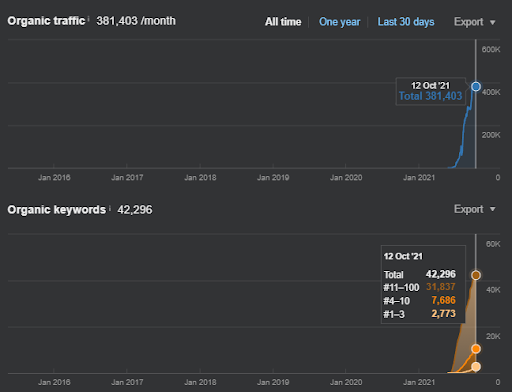
IstanbulBogazici Enstitusu to jedno z najtrudniejszych studiów przypadku SEO, jakie przeprowadziłem, nie z powodu wyszukiwarek, ale z powodu ludzi i moich problemów zdrowotnych. W ten sposób opuściłem projekt i nie opublikowałem trzeciej semantycznej sieci treści, która ma na celu uzupełnienie relacji semantycznych w oparciu o kontekst źródła. Nawet jeśli nie ma prawidłowo zaimplementowanych terminów z domeny wiedzy i fraz kontekstowych, jest skonfigurowany z wystarczającymi poziomami połączeń semantycznych i dokładności, aby umożliwić ogólną wydajność wyszukiwania organicznego wynoszącą ponad trzy miliony sesji miesięcznie, jeśli trzecia sieć partnerska jest publikowane w przyszłości, uwzględniając również rosnący efekt drugiej semantycznej sieci informacyjnej.
Poniżej zobaczysz zmieniającą się grafikę IstanbulBogazici Enstitusu na GSC w ciągu ostatnich 12 miesięcy. Projekt został prawidłowo uruchomiony w maju 2021 roku i zakończył się we wrześniu 2021 roku publikacją dwóch Semantic Content Networks.
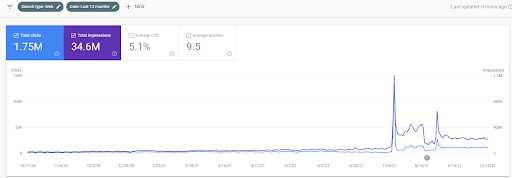
Poniżej możesz zobaczyć bardziej szczegółową wersję. Od 1400 kliknięć dziennie do 140000 kliknięć, a następnie regularne ponad 10 000 kliknięć dziennie można zobaczyć w wynikach bezpłatnych wyników wyszukiwania
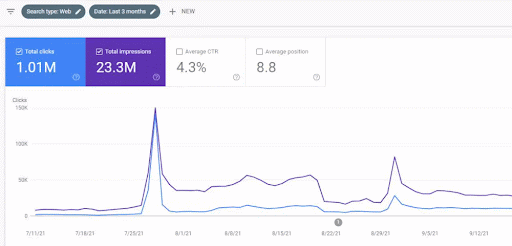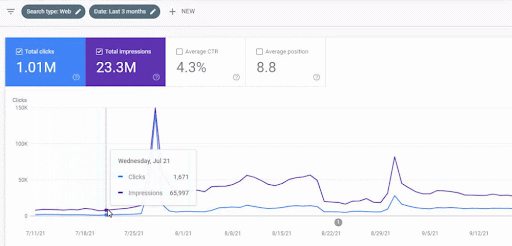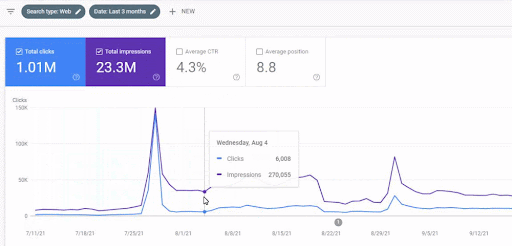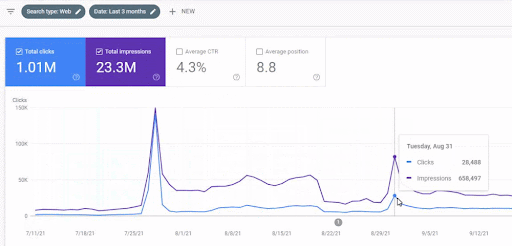
Wzrost ruchu w pierwszej sieci partnerskiej po uruchomieniu można zobaczyć poniżej.
Ten zrzut ekranu przedstawia 4. miesiąc pierwszej semantycznej sieci partnerskiej.
Jak widać z grafiki, cały ruch w witrynie został zdominowany i miał wpływ na First Semantic Content Network, który skupia się na „gałęziach edukacyjnych”. Drugą sieć partnerską, którą uruchomiłem za pomocą tej witryny, można zobaczyć poniżej w Google Search Console. Poniższy zrzut ekranu pochodzi z 16. dnia drugiej semantycznej sieci informacyjnej.
Wstępne rankingi i ponowne rankingi zostały użyte w artykule, ponieważ definiują fazy algorytmów rankingowania wraz z ich typami i celami przed testowaniem źródła oraz strony internetowej ze źródła w SERP dla ważniejszych zapytań, które mają popularność .
Na czym koncentruje się pierwsza sieć treści semantycznych pierwszego projektu?
„Semantic Content Network” wykorzystuje sieć semantyczną z bazy wiedzy w celu wyjaśnienia głównych, drugorzędnych i trzeciorzędnych relacji między elementami w bazie wiedzy. Dlatego stworzenie Semantic Content Network wymaga zaprojektowania kolejnej semantycznej sieci informacyjnej w oparciu o kontekst źródła, który jest główną funkcją witryny. W tym kontekście pierwsza semantyczna sieć treści skupiła się na „wydziałach uniwersyteckich, gałęziach edukacji i potrzebach edukacji uniwersyteckiej w ramach określonej organizacji i branży”.
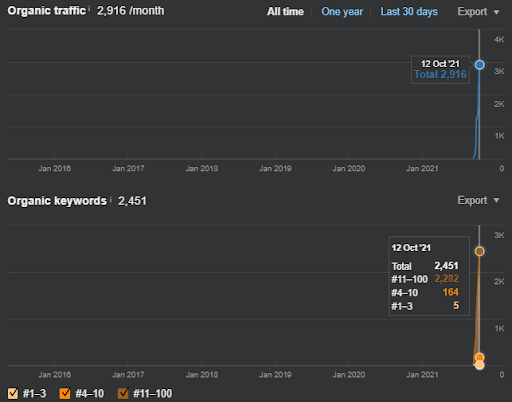
Poniżej znajdziesz grafikę Ahrefs First Semantic Content Network.
To jest pięć dni później od poprzedniego zrzutu ekranu.
„Root: istanbulbogazicienstitu.com/bolum”, po pierwszej fazie wstępnego rankingu proces zmiany rankingu jest bardziej wydajny i produktywny.
Możesz zobaczyć wersję późniejszą o cztery dni, jak poniżej, aby wspierać naturę „ponownego rankingu”.
Na czym koncentruje się druga sieć treści semantycznych pierwszego projektu?
Druga semantyczna sieć treści koncentruje się na zawodach, pracach, umiejętnościach i niezbędnej edukacji dla tych umiejętności lub rutyny. W oparciu o pierwszą semantyczną sieć partnerską obsługiwana jest druga semantyczna sieć partnerska. I zgodnie z „szablonami zapytań – szablonami intencji” tworzone są jeszcze dwie różne semantyczne sieci treści podrzędnych i umieszczane z „połączeniami relacyjnymi”, podczas gdy są one połączone z wyższymi podobnymi poziomami hierarchicznymi.
Wiem, że te sekcje są dla Ciebie skomplikowane, ponieważ nie widziałeś jeszcze definicji poniższych rzeczy.
- Semantyczna sieć partnerska
- Kontekst źródłowy
- Semantyczna sieć treści podrzędnych
- Baza wiedzy
- Połączenia relacyjne
- Ranking początkowy
- Zmiana rankingu
- Zasięg kontekstowy
- Ranking porównawczy
- Ekstrakcja faktów
Po wyjaśnieniu drugiej strony łatwiej będzie zrozumieć te pojęcia i zdania.
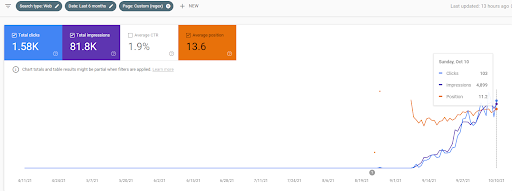
Vizem.net: Od 0 do ponad 9.000 kliknięć dziennie w ciągu 6 miesięcy – wykorzystany ranking porównawczy z pokryciem kontekstowym
Możesz zobaczyć wykres Vizem.net z ostatnich 12 miesięcy. W przypadku tego projektu, ze względu na Covid-19, doświadczyliśmy wielu problemów ekonomicznych, ponieważ inwestor pochodzi z branży gimnastycznej. Mogę więc powiedzieć, że problemy ekonomiczne spowolniły projekt i spowodowały pewne opóźnienia dla „procesów rerankingu”.
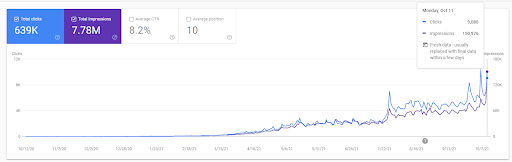
Aby zrozumieć początkowy ranking i nieco dalej zmienić ranking, możesz skorzystać z poniższego wykresu.
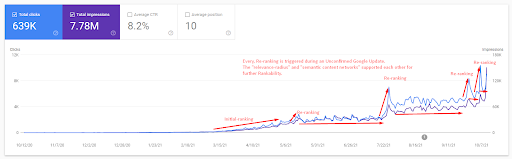
Niektóre definicje dotyczące początkowego rankingu i ponownego rankingu z powyższej grafiki można znaleźć poniżej.
- Wielkie skoki w rankingu miały miejsce podczas niepotwierdzonych aktualizacji Google. Niektóre testy dały kilka polecanych fragmentów, a ludzie również zadawali pytania.
- Niektóre testy Google usunęły zarobki FS i PAA.
- Za każdym razem przedział czasu między dwoma procesami zmiany rankingu był krótszy.
- Procesy zmiany rankingu za każdym razem poprawiały ranking źródła.
- Źródło zawsze poprawiało swój promień trafności, jednocześnie rozszerzając klastry zapytań.
Dla przypomnienia mogę zostawić zdanie poniżej.
Jeśli wyszukiwarka indeksuje twoją stronę internetową, nie oznacza to, że wyszukiwarka zrozumiała stronę internetową. Indeksowanie przebiega szybciej niż zrozumienie, a przez większość czasu wyszukiwarka „początkowo” umieszcza stronę internetową z podpowiedziami. Po zrozumieniu następuje „przeklasyfikowanie”. 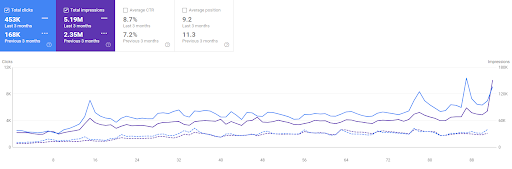
Porównanie Vizem.net z ostatnich 3 miesięcy
Jak wygląda sieć treści semantycznych Vizem.net?
Pamiętam, że dla wielu moich klientów, znajomych czy tajnych grup SEO, podczas spotkań demonstrowałem obie te strony, mówiąc „wybuchną”. A pisząc ten artykuł, powiem ci to:
Obejrzyj semantyczną sieć treści „istanbulbogazicienstitu.com/meslek”, ponieważ będzie eksplodować. Możesz też znaleźć film, który opublikowałem przed napisaniem tego artykułu, pokazując „Dane historyczne” z wydarzenia sezonowego i jego wpływ na procesy początkowe i ponowne rankingu. Możesz to zobaczyć poniżej.
Na tej podstawie sieć treści semantycznych Vizem.net nie jest podobna do IstanbulBogazici Enstitusu, dlatego nie zastosowałem „intensywnego poziomu wzrostu pokrycia tematycznego i danych historycznych”, musiałem stworzyć autorytet związany z pewnym typy jednostek, ich atrybuty i możliwe akcje za zapytaniami dla tych par jednostka-atrybut. Vizem.net to nie tylko „edukacyjne filie uniwersyteckie” czy „zawody i kursy online”. Ma „kraje do składania wniosków wizowych”. Dlatego stworzenie wystarczającego poziomu Topical Authority wymaga spójności w czasie z co najmniej 190 różnymi semantycznymi sieciami treści.
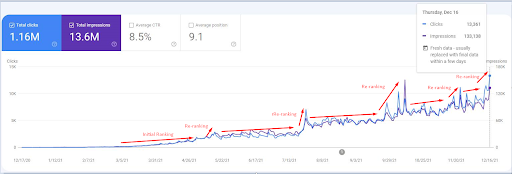
Zrzut ekranu z 18 grudnia 2021 r. Widać ciągłą zmianę rankingu oraz wzrost wyświetleń i kliknięć. To jest 4 tygodnie później od poprzedniego zrzutu ekranu.
Aby zobaczyć zdarzenia związane z ponownym rankingiem, możesz porównać nagą wersję grafiki wyników wyszukiwania organicznego, która pokazuje efekt semantycznego SEO. 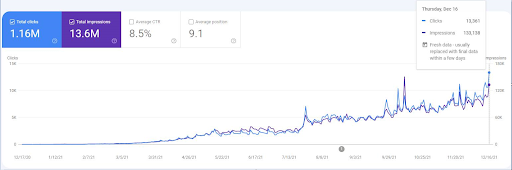
Te 190 różnych semantycznych sieci informacyjnych jest kształtowanych na podstawie samego „kraju”, a kraje są umieszczane na środku mapy tematycznej z każdą możliwą warstwą kontekstową, aby poprawić zasięg wyszukiwania.
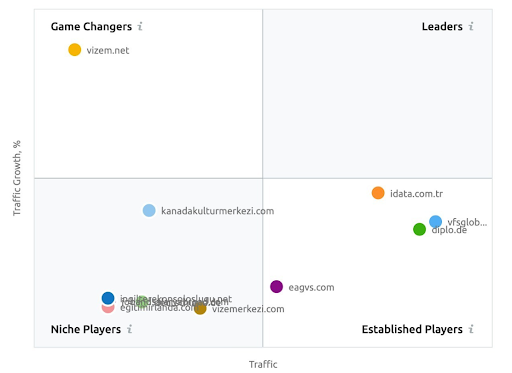
Zrzut ekranu z SEMRush pokazujący ich postrzeganie Vizem.net w przeciwieństwie do innych graczy z branży.
Opublikowałem też kolejny film, tylko dla Vizem.net. W tym filmie ostatnia sytuacja serwisu nie istnieje, dlatego uważam, że zapewnia również ładne porównanie między dniem dzisiejszym a tamtym.
Wreszcie, publikowanie nieistotnych rzeczy w nieistotnym artykule, segmencie witryny lub źródle może zmniejszyć ogólne znaczenie encji sieciowej w określonej dziedzinie wiedzy. Vizem.net pokaże swoją prawdziwą wartość, a Rankability w przyszłości będzie znacznie lepszy.
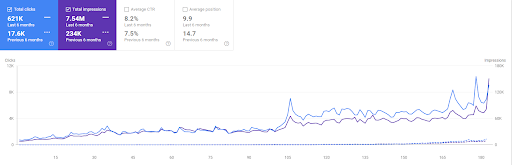
Porównanie ostatnich 6 miesięcy Vizem.net.
Zanim przejdę dalej, wiem, że to długi artykuł. Ale tak naprawdę jest to krótkie wyjaśnienie bardzo złożonej metodologii SEO. Semantyczne sieci partnerskie wymagają zbytniego myślenia podczas ich projektowania oraz miesięcy edukacji dla klientów, autorów i przy wdrażaniu. Dlatego w tym artykule chcę skupić się na definicjach pojęć z najlepszymi możliwymi do wykonania krótkimi sugestiami i ważnymi patentami Google i innych wyszukiwarek, artykułami badawczymi wraz z ich własnymi koncepcjami. W wersji dłuższej (w zasadzie książka) skupiłem się na „rankingu początkowym” i „re-rankingu” semantycznych sieci treści.
Jeśli chcesz dowiedzieć się więcej, przeczytaj „Znaczenie początkowego rankingu i ponownego rankingu dla SEO”.
Do tej pory przetworzyliśmy poniższe rzeczy.
- Sieć semantyczna
- Baza wiedzy
- Semantyczna sieć partnerska
- Zaufanie oparte na wiedzy
- Zasięg kontekstowy
- Domena kontekstowa i warstwy
- Związek MuM z semantycznymi sieciami treści
- Kontekst źródła
Te pojęcia mają na celu zrozumienie, jak działają semantyczne sieci partnerskie i jak można ich używać z mapą tematyczną. Kolejne sekcje będą dotyczyły tego, jak wyszukiwarka ocenia semantyczne sieci partnerskie na początku i później, Modyfikacja. W tym kontekście będą przetwarzane poniższe rzeczy.
- Ranking początkowy
- Zmiana rankingu
- Szablon zapytania
- Szablon dokumentu
- Szablon zamiaru wyszukiwania
- Co należy zrobić, aby wykorzystać semantyczne sieci partnerskie
Co to jest początkowy ranking SEO?
Jest to nowy termin i pojęcie dla SEO, ale stare dla wyszukiwarek. Długa wersja „Studium przypadku SEO skoncentrowanego na sieci semantycznej” koncentruje się na algorytmach rankingowych opartych na algorytmach zależnych od zapytania, dokumentu, źródła i wielu patentach. Predykcyjne wyszukiwanie informacji lub algorytmy predykcyjnego rankingu próbują obniżyć koszt obliczeń. I nawet jeśli indeksowanie odbywa się w ciągu jednego dnia, zrozumienie dokumentu może zająć miesiące, a nawet lata. Obliczenie początkowego rankingu jest zatem sposobem na poprawę jakości SERP przy jednoczesnym obniżeniu kosztów. Niektóre zadania związane z wyszukiwarką mają wyższy priorytet niż inne, jeśli chodzi o utrzymanie indeksu żywego, świeżego i wystarczająco wysokiej jakości.

Termin „początkowy ranking” pojawia się w dziesiątkach tysięcy różnych patentów Google i artykułów naukowych, ponieważ jest to klasyczna perspektywa wśród twórców wyszukiwarek. Tak więc powyżej można zobaczyć różne dokumenty patentowe z kontynuacją tych samych paragrafów oraz terminy z niewielkimi zmianami wokół początkowego rankingu.
Początkowy ranking reprezentuje rangę dokumentu w SERP natychmiast po zindeksowaniu. Początkowy ranking dokumentu reprezentuje ogólny autorytet i związek źródła z określonym tematem, szablonem zapytania i intencją wyszukiwania. Ta sama treść może być różnie oceniana pod względem początkowego rankingu między różnymi źródłami. Początkowy ranking jest ważny podczas korzystania z semantycznych sieci partnerskich, aby zobaczyć ogólną poprawę jakości i autorytetu źródła. Każdy nowy dokument zwiększa swój początkowy ranking, jednocześnie zmniejszając opóźnienie indeksowania, jeśli projekt semantycznej sieci informacyjnej ma prawidłową strukturę.
Wstępny ranking wspiera proces zmiany rankingu i jego efektywność dla źródła. A „Ranking źródła” powinien być przetwarzany za pomocą tych dwóch terminów, początkowego i ponownego rankingu.
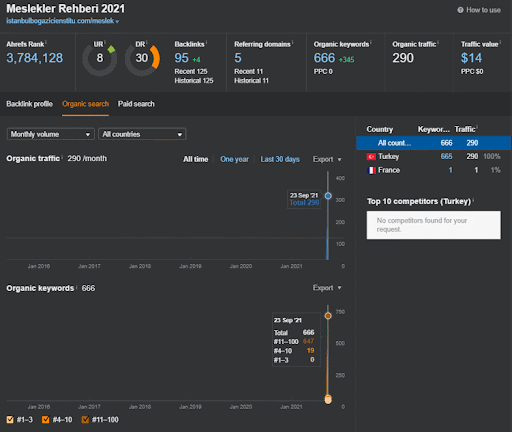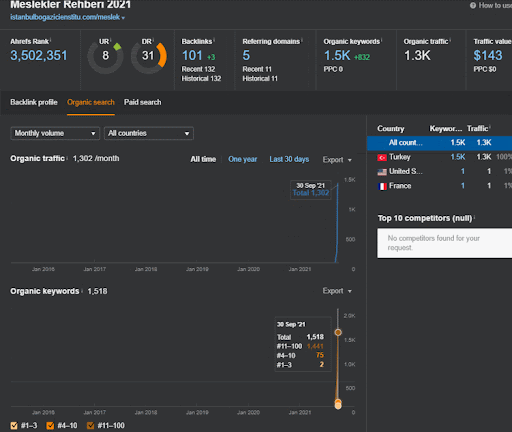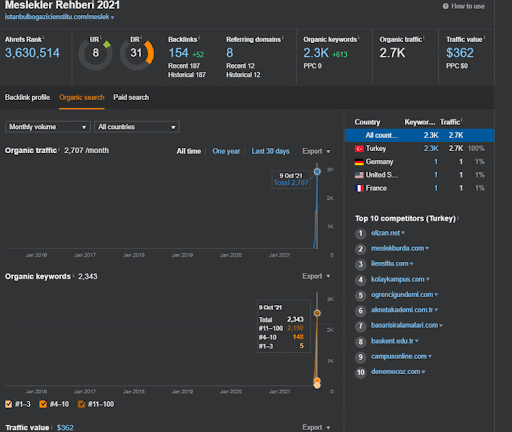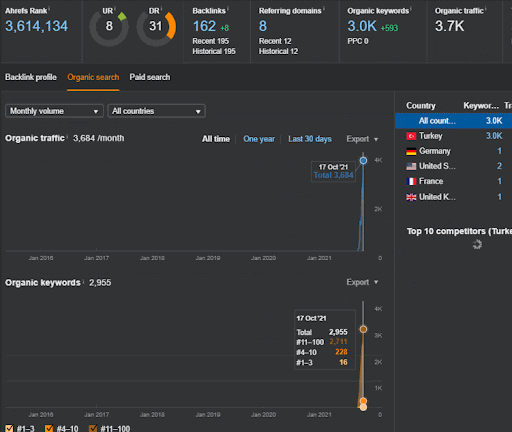
Możesz obejrzeć pierwsze 20 dni zmian wyników organicznych w drugiej sieci partnerskiej z Projektu I.
W tym kontekście, za każdym razem, gdy Vizem.net publikuje nowy dokument lub gdy IstanbulBogazici Enstitu publikuje nową semantyczną sieć treści, początkowy ranking jest lepszy niż wcześniej, a treść jest indeksowana szybciej.
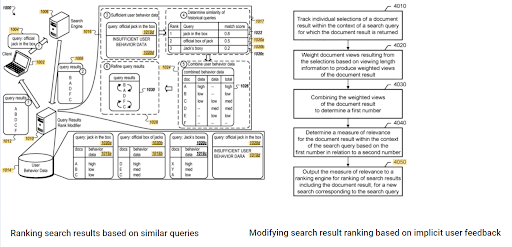
Między tymi dwoma komplementarnymi patentami Google widać znaczenie początkowego rankingu i danych historycznych. Jeden dotyczy początkowego i ponownego rankingu dokumentów na podstawie niejawnych informacji zwrotnych od użytkowników. The other one is for doing the same if enough level of user data doesn't exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine's point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document's ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the IstanbulBogazici Enstitu in terms of the initial and re-ranking. 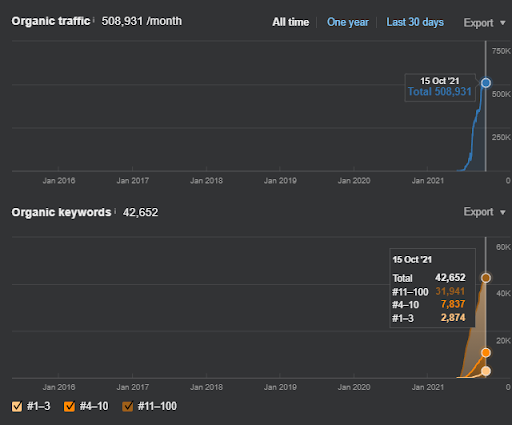
15 October 2021, performance of the first semantic content network of the IstanbulBogaziciEnstitusu which is the 124th day of the launch. 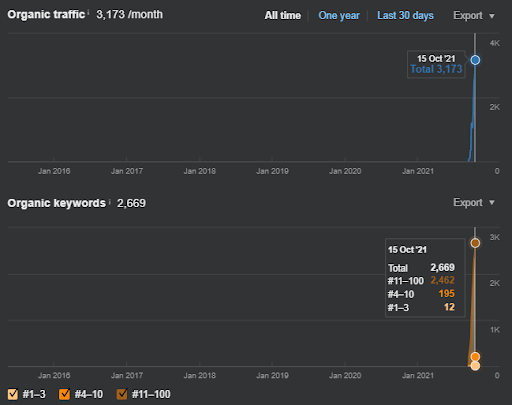
15 October 2021, performance of the Second Semantic Content Network of IstanbulBogazici Enstitu which is the 19th day of the launch. 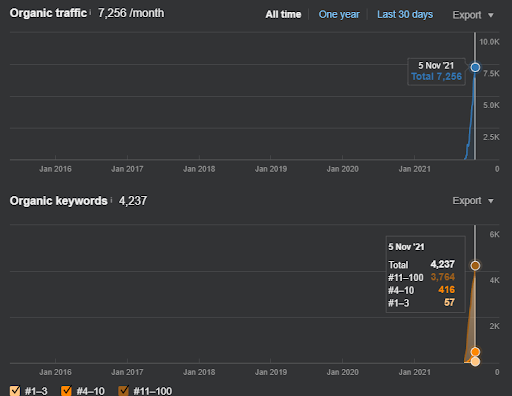
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”. 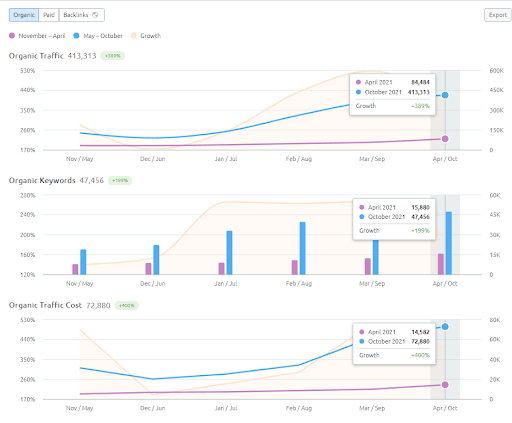
The 6 Months of Growth Comparison of the IstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source's context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction's validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.
In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months' for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.
Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.

The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
Dane dotyczące indeksowania³
 Ucz się więcej
Ucz się więcejWhat is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them. 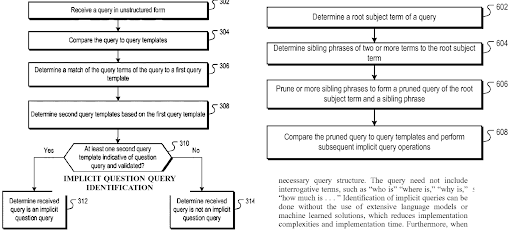
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.
In this context, a query template can be used for feeding the search engines' historical data for creating trust. Even if a search engine doesn't understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas. 
“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it. 
A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian , meaning that they are more influenced by the current page than their history of navigation. 
A section that explains how a search engine can use the document templates to see a user's interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”. 
A section from the “Are web users Markovian?” research paper.
Tak, oni są. Probabilistic Ranking oraz Degraded Relevance Ranking to główne kolumny semantycznej wyszukiwarki służącej do zrozumienia użytkowników i stworzenia możliwie najlepszej jakości SERP, przygotowanego na stany możliwości. 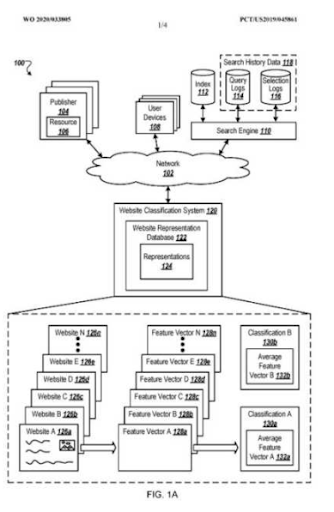
Wcześniej Bill Slawski napisał „Wektory Reprezentacji Witryny”, aby „projekt i wygląd strony internetowej” był argumentem za uczeniem się reprezentacji stron internetowych.
Co to jest szablon zamiaru wyszukiwania?
Szablon intencji wyszukiwania może być reprezentowany przez potrzebę kryjącą się za szablonem zapytania. Szablon dokumentu zapytania można połączyć na podstawie szablonu intencji. Posiadanie szablonu intencji wyszukiwania z możliwym „Zdegradowanym rankingiem trafności” i zrozumieniem „Rankingu probabilistycznego” pomoże w stworzeniu najlepszej możliwej aktywności wyszukiwania i zasięgu intencji wyszukiwania w prawidłowej kolejności. Podczas tworzenia semantycznej sieci treści najważniejszą rzeczą jest dostosowanie szablonu intencji dokumentu w oparciu o kontekst źródła w celu ukończenia sieci semantycznej opartej na domenie wiedzy poprzez poprawę zasięgu kontekstowego w celu poprawy zaufania opartego na wiedzy i autorytetu tematycznego . 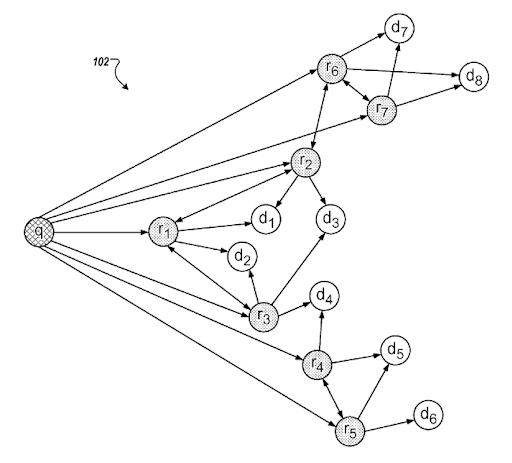
Sekcja z „Udoskonalenia zapytań na podstawie wnioskowanej intencji” Google. Działa poprzez klastry zapytań i szablony intencji z połączeniami semantycznymi. Możesz tego doświadczyć na różnych poziomach taksonomii fraz.
Zanim przejdziemy do konkretnych przykładów i sugestii, które pomogą Ci stworzyć lepszą semantyczną sieć treści, muszę Ci powiedzieć, że nawet prosta wersja tego studium przypadku SEO wymaga wysokiego poziomu zrozumienia wyszukiwarek i umiejętności komunikacyjnych. Dlatego chociaż czuję, że przekazuję informacje na wysokim poziomie, wiem, że kurs Semantic SEO, który stworzę, pokaże Ci więcej i lepszych konkretnych przykładów. 
Ten sam patent wyjaśnia właściwe powiązania między różnymi „ścieżkami zapytań” i „zmianami kontekstu”.
Co powinieneś wiedzieć o korzystaniu z semantycznych sieci partnerskich?
Aby utworzyć semantyczną sieć partnerską, czasami nawet prosty opis i projekt treści semantycznej może zająć godzinę, jeśli umieścisz wszystkie istotne szczegóły w oparciu o semantykę leksykalną lub typy relacji między jednostkami i frazami. Używając jednocześnie wielu punktów widzenia, takich jak indeksowanie oparte na frazach oraz wektory słów lub wektory kontekstowe, do obliczania kontekstowego znaczenia treści ogólnie dla domeny kontekstowej lub jej znaczenia na podstawie poszczególnych typów treści podrzędnych, wymaga wysokiego poziomu znajomości semantycznej wyszukiwarki.
Tak więc użycie metodologii generatywnej ułatwi wszystko dzięki pojęciom, które wyjaśniłem ci powyżej, ponieważ nawet jeśli przygotujesz każdą semantyczną część sieci treści doskonale, autorzy i autorzy nie będą w stanie jej napisać, ani menedżerowie treści nie będzie w stanie podążać za twoją wizją. W ten sposób może cię to zmęczyć na nic i sprawić, że opuścisz projekt, tak jak ja w przypadku niektórych z tych projektów SEO, po tym, jak udowodnię koncepcję w wystarczająco żywy i kontrolowany sposób.
Poniższe sugestie będą tylko prostymi, wykonywalnymi i krótkimi krokami, które ci pomogą.
1. Nie używaj stałych łączy paska bocznego z każdej sieci semantycznej sieci partnerskiej
Każdy link powinien mieć opis połączenia między dwoma dokumentami hipertekstowymi, jak każde słowo na stronie internetowej. Użycie semantycznego kodu HTML może pomóc w określeniu pozycji i funkcji dokumentu na stronie internetowej, jednocześnie pomagając wyszukiwarkom inaczej ważyć sekcje pod względem kontekstu.
W przykładzie Vizem.net nie użyłem tego samego projektu paska bocznego. Pasek boczny nie pokazywał najnowszych ani najbardziej krytycznych postów. Paski boczne pokazują tylko atrybuty jednostek centralnych i nie są one stałe, są dynamiczne. Innymi słowy, w oparciu o hierarchię w obrębie mapy tematycznej semantyczne sieci sieci partnerskiej zmieniają się, nawet jeśli znajdują się na pasku bocznym. 
Myślenie o modelach rozsądnego i ostrożnego surfera może pomóc SEO w stworzeniu lepszego dopasowania między różnymi dokumentami hipertekstowymi.
Dodatkowo link płynie pod względem widoczności, a popularność powinna podążać za kontekstem źródła z najlepszych możliwych połączeń. Poniżej możesz zobaczyć sekcje paska bocznego z dostosowanymi semantycznymi kodami HTML. 
Zgodnie z hierarchią artykułu, który jest aktywny w sesji użytkownika, zmienią się zakładki, kolejność zakładek, linki w zakładkach. Powyższy przykład pochodzi z poniższej hierarchii menu nawigacyjnego. ![]()
2. Wspieraj semantyczne sieci partnerskie za pomocą PageRank
Nawet jeśli zewnętrzny PageRank nie jest konieczny ze źródeł zewnętrznych, jeśli potrafisz z niego korzystać, zdasz sobie sprawę, że początkowy ranking i zmiana rankingu będą lepsze. W przypadku obu tych projektów nie korzystałem z nich, ale tym razem nie o to mi chodziło. W przypadku Vizem.net były problemy ekonomiczne, a ja nie chciałem wydawać budżetu na digital PR i popularyzację. Dla Istanbul BogaziciEnstitusu zaaranżowałem kilka „lokalnie powiązanych źródeł”, aby potwierdzić autentyczność źródła dla konkretnego tematu, ale znowu firma nie była w stanie tego wdrożyć z powodu problemów z budżetem i dyscypliną organizacyjną. 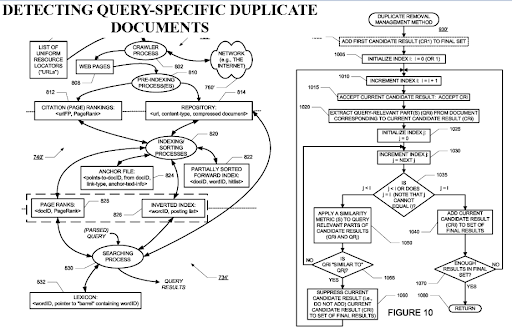
Wykrywanie zduplikowanych dokumentów specyficznych dla zapytania jest ważnym punktem widzenia wyszukiwarek, ponieważ PageRank może pomóc w filtrowaniu dokumentu jako wartościowego, nawet jeśli jest zduplikowany. Ponieważ wysoce zorganizowane semantyczne sieci z treścią mogą być do siebie podobne, przydatny jest przepływ PageRank i dane historyczne.
Jeśli chodzi o wybór zewnętrznego punktu przepływu PageRank dla tego typu semantycznych sieci z treścią, użyj źródeł z danymi historycznymi. W moim przypadku ułożyłem te punkty końcowe PageRank wcześniej, zanim uruchomiłem i opublikowałem pierwszą semantyczną sieć partnerską. W ten sposób mogłem uzyskać zewnętrzne referencje od bezpośrednich konkurentów, ale kiedy opublikowałem semantyczną sieć treści, konkurenci zrezygnowali z łączenia źródła, ponieważ widzieli masowy wzrost źródła jako konkurenta.
Ta sytuacja prowadzi nas do trzeciej sugestii. Gdybyśmy byli w stanie wykorzystać przepływ PageRank z zewnętrznych odnośników, proces zmiany rankingu byłby szybszy, a początkowy ranking byłby wyższy.
3. Używaj różnych tekstów zakotwiczeń ze stopki, nagłówka i treści głównej dla wyróżniających się części sieci treści semantycznej
Teksty zakotwiczeń lub „tekst linków” z punktu widzenia wyszukiwarki sygnalizują związek między dokumentem hipertekstowym a innym. Zgodnie z oryginalnym dokumentem PageRank, liczba linków jest proporcjonalna do przepływu PageRank. Ale później Google zmienił to, aby zapobiec „faszerowaniu linków” i ograniczyło linki, które faktycznie mogą przekazywać PageRank. Na tej podstawie opracowywane są modele TrustRank, Cautious Surfer, Hilltop Algorithm lub Reasonable Surfer Models. 
Są to dwa linki do dwóch różnych semantycznych sieci treści dla BogaziciEnstitusu, ale ponieważ nie wdrażałem technicznych SEO ani ulepszeń UX, możesz zdać sobie sprawę z „taniości” projektów przycisków.
Według Google ten sam link nie może przekazać PageRank po raz drugi do innej strony internetowej, podczas gdy PageRank zostanie przekazany tylko z pierwszego linku. I w oryginalnej formie algorytmu PageRank, dokument hipertekstowy może się łączyć, aby poprawić swój PageRank, lub przekierowania 301 mogą być użyte do pobrania PageRank dokumentu, do którego prowadzi łącze. Obie te sytuacje stworzyły stare techniki Black Hat, takie jak tymczasowe przekierowanie strony internetowej na inną tylko po to, aby odebrać jej PageRank. Było to z czasów, gdy SEO mogli zobaczyć PageRank strony internetowej z Google Search Console lub SERP. Później Google zaczęło osłabiać PageRank każdym przekierowaniem, podczas gdy Danny Sullivan wyjaśnił, że przekierowania 301 w pełni przejdą PageRank. Oprócz tych wszystkich zmian, ważne jest to, że nawet jeśli drugi link nie przekazuje PageRank, nadal przekazuje trafność tekstu linku. 
Wybitne sekcje sieci treści semantycznej zostały połączone ze strony głównej na podstawie „doprecyzowań środkowych zapytań”, które obejmują „czasowniki, predykaty” lub „działania osoby wyszukującej”.
W związku z tym widoczne semantyczne sekcje sieci treści semantycznej powinny być połączone z menu nagłówka i stopki z sekcjami o wyższej taksonomii, a teksty linków powinny się różnić od siebie. W tych przykładach użyłem linków nagłówka z widocznymi, ale krótkimi tekstami linków, podczas gdy przykłady w stopce były dłuższe. 
Sekcja „Indeksowanie tagów kotwicy w systemie robota indeksującego” podsumowuje znaczenie tekstu kotwicy i tekstu adnotacji w pozycjonowaniu strony internetowej w klastrach zapytań i klastrach stron internetowych.
Jeśli sekcja semantycznej sieci partnerskiej jest zbyt widoczna, aby prawidłowo przekazać ranking PageRank i indeksowania, połączyłem najważniejsze sekcje z odpowiednimi tekstami linków i akapitami wyjaśniającymi, które zawierają wyróżniające się atrybuty z różnymi odmianami odpowiednich N-gramów. 
Jest to drugi powiązany obszar ze strony głównej Vizem.net, znajduje się za akordeonem i skupia się na krajach w zapytaniach oraz łączy środkową sekcję semantycznej sieci treści.
Uwaga: Wokół tekstów zakotwiczeń zawsze zastosowano zaplanowany „tekst adnotacji”, aby poprawić precyzję celu linku.
4. Ogranicz ograniczenie liczby linków i dopasowywanie linków do komputerów stacjonarnych i mobilnych oraz głównej zawartości
Oba projekty są ograniczone do mniej niż 150 wewnętrznych linków na stronę internetową. Za pomocą semantycznego kodu HTML miejsca i funkcje linków są jasne dla robotów indeksujących. IstanbulBogazici Enstitusu zawierało ponad 450 linków na stronę internetową, a niektóre z nich były linkami własnymi (link z tej samej strony do tej samej strony). Najgorsze jest to, że połowa tych linków nie istniała w mobilnej wersji treści. 
URL Keep Score, Crawl Score i inne typy wyników mogą być używane do określania widoczności łącza w wewnętrznej mapie URL, a znaczniki identyfikujące dokument w różnych warstwach mogą być używane do sortowania indeksu na podstawie niezależnych od zapytania ocen trafności.
Ponieważ Google używa indeksowania tylko dla urządzeń mobilnych, jeśli treść nie istnieje w wersji mobilnej, zostanie zignorowana i nie będzie używana do oceny trafności i celów rankingowych. W ten sposób treści mobilne i stacjonarne zostały skonfigurowane tak, aby były ze sobą dopasowane. Nawet jeśli Google toleruje rozbieżności treści między wersją komputerową i mobilną, nadal utrudnia to zrozumienie i ranking strony internetowej dla wyszukiwarek. 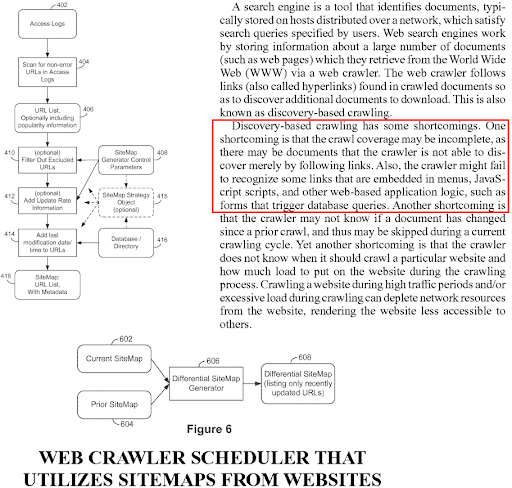
Wyszukiwarka może wygenerować mapę witryny dla witryny, a ta mapa witryny może zostać ponownie wygenerowana w pętli, jeśli linki i metadane adresu URL nie zostaną dopasowane między klientami użytkownika lub osiami czasu. Dlatego ważne jest, aby ścieżka indeksowania była krótka, kolejka indeksowania krótka i spójne linki wewnętrzne.
Wraz z linkami między różnymi stronami internetowymi, również linki do podsekcji stron internetowych są używane z „spisem treści” i „Fragmentami adresów URL”. Te fragmenty adresów URL celują w konkretną podsekcję strony internetowej, nadając jej odpowiednią nazwę, a konkretna sekcja została umieszczona w tagu sekcji z h2. Za pomocą fragmentów URL z „linkami nawigacyjnymi na stronie” łatwiej było dotrzeć użytkownika z SERP do określonej sekcji strony internetowej, a dolne sekcje treści zostały uwydatnione w celu zaspokojenia potrzeby stojącej za zapytanie.
5. Miej dyscyplinę na poziomie wojskowym dla swoich projektów SEO
To zupełnie inny temat i można napisać kolejny artykuł, aby określić, co oznacza dyscyplina na poziomie wojskowym lub dlaczego jest przydatna w projekcie SEO. Muszę jednak powiedzieć, że w ciągu ostatnich 2 miesięcy przeszkoliłem wielu dyrektorów generalnych i SEO z innych agencji wraz z ich zespołami, aby sprawdzić, czy mój projekt kursu będzie działał dobrze, czy nie.
Zawsze, gdy widzę sukces i wysoki poziom zaangażowania w sesje edukacyjne, które wykonuję, pojawia się silna wola i wytrwałość. Głównym problemem jest to, że semantyczne SEO jest znacznie trudniejsze niż inne branże SEO. Pozycjonowanie techniczne jest uniwersalne i ma nawet napisane poradniki na każdym kroku. OnPage SEO lub WUX i Layout Design można śledzić za pomocą pomiarów numerycznych. Jeśli chodzi o semantykę, jest to praktyka łączenia perspektywy maszyny działającej w oparciu o złożony system adaptacyjny z homo-sapiens, którzy nie rozumieją, jak działa maszyna.
To rozróżnienie wymaga betonowego podłoża, które należy położyć od pierwszego dnia projektu. Przez większość czasu korzystam z poniższych zasad.
- Projekty treści i semantyczna sieć treści nie muszą być logiczne dla autora lub pisarza.
- Zadaniem menedżera treści jest kontrola zgodności treści z projektem treści.
- Zadaniem autora jest pisanie treści wraz z powiązanymi informacjami, które zawierają wysoki poziom dokładności i szczegółowości.
- Linki, definicje, dowody, porównania, propozycje, odniesienia powinny być wykonane na konkretnych przykładach, a nie na puszystości.
- Każde niepotrzebne słowo jest rozmyciem kontekstu i pojęcia.
Kiedy czytasz, może wydawać się to łatwe do wdrożenia, ale nie jest to takie proste. W ten sposób mogę powiedzieć, że miałem nawet zwolnić kilku moich pracowników. Cieszę się, że nie, przynajmniej na razie. W normalnych warunkach będzie wiele pytań, które zostaną Ci zadane, jeśli właściciel pytania nie jest SEO lub właścicielem firmy, nie odpowiadaj. Oszczędzaj energię w pamięci danych wyszukiwarki, która będzie przechowywać Twoje pozytywne opinie, a nie zbędne i nieistotne opinie na temat rankingów.
6. Rozszerz źródło o trafność kontekstową
Ta sekcja dotyczy całkowicie zrozumienia potrzeby Google w zakresie tworzenia MuM. Podczas projektowania mapy tematycznej będzie ona zawierać wiele semantycznych sieci partnerskich, które zapewnią lepszą bazę wiedzy na poziomie witryny. Dlatego publikując te podsekcje, powinny mieć możliwość połączenia się z kontekstem źródła lub może to zmienić sposób, w jaki wyszukiwarka widzi źródło, a temat strony internetowej może przełączyć się na inną domenę wiedzy. Na przykład łączenie rzeczy wokół pojęć i obszarów zainteresowań z możliwymi działaniami wymaga zrozumienia skomplikowanych połączeń znaczeń ze sobą. Wyjaśnienie tych połączeń użytkownikowi, pisarzowi i jednocześnie maszynie to proces tworzenia Semantic Content Network. 
Aby to osiągnąć, każda nowa sekcja witryny powinna być połączona z centralną sekcją mapy tematycznej. Te kontekstowe mosty można zobaczyć na podstawie własnego projektu i objaśnień LaMDA firmy Google.
Spotykam się z wieloma pytaniami typu „czy powinienem pisać na inny temat”, „jeśli będę miał dwie różne nisze, czy to zaszkodzi?”. Jeśli połączysz wszystkie te podsekcje, segmenty witryn internetowych jako silnie powiązane ze sobą komponenty, te semantyczne sieci treści będą wspierać się nawzajem w celu uzyskania lepszych rankingów, zamiast dzielić tożsamość marki i autorytet tematyczny na dwa różne i nieistotne tematy.
7. Twórz rzeczywisty ruch i przeprowadzaj audyt za pomocą niestandardowej segmentacji Google Analytics
Rzeczywisty ruch jest połączony z RankMerge w taki sam sposób, w jaki Trust oparty na wiedzy jest połączony z PageRank. Niedługo myślę o napisaniu kolejnego artykułu zatytułowanego „When the PageRank Lies…”, aby wyjaśnić, dlaczego wyszukiwarka próbuje wpływać na PageRank sygnałami bocznymi. W rzeczywistości PageRank nie jest ostatecznym sygnałem, który pokazuje autorytet, wiedzę i wiarygodność źródła. Może być sygnałem do rankingu i czynnikiem, ale nie można mu ufać samemu. RankMerge to proces łączenia ruchu w witrynie i PageRank w taki sposób, aby witryna miała sens dla wyszukiwarki. Wysoki PageRank i niski ruch mogą sygnalizować „niepopularny ruch” lub „manipulację PageRank”.
W związku z tym, aby poprawić dane historyczne źródła, wykorzystałem sezonowe zdarzenia SEO i zwiększyłem liczbę zapytań „marka + termin ogólny”. Ruch bezpośredni i strony internetowe dodawane do zakładek zwiększają się o rzeczywisty i autentyczny ruch.
Tego typu dane pomagają wyszukiwarce zaufać jej w rankingu coraz wyżej w SERP.
Aby móc kontrolować rzeczywisty ruch pochodzący z semantycznej sieci partnerskiej, SEO może utworzyć niestandardowy segment z Google Analytics, aby zobaczyć, w jaki sposób pochodzą one z ruchu bezpośredniego. Można również tworzyć cele niestandardowe, takie jak tworzenie możliwej ścieżki wyszukiwania z pierwszej semantycznej sieci partnerskiej do drugiej sieci partnerskiej. Jest to dowód koncepcji, że sieć semantyczna jest zbudowana wokół zainteresowań, pojęć i możliwych działań związanych z wyszukiwaniem.
Poniżej znajdziesz tylko jeden przykład dla jednej ze stron internetowych, które są umieszczone w pierwszej Semantic Content Network, w celu zademonstrowania pozyskanego ruchu bezpośredniego za pośrednictwem ruchu organicznego. 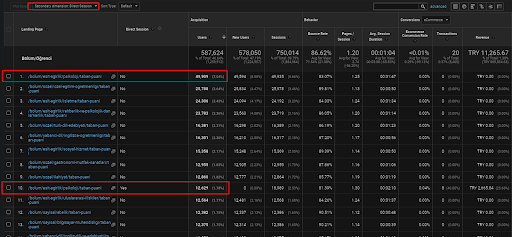
W ciągu ostatnich 3 miesięcy tylko jedna strona internetowa z pierwszej semantycznej sieci treści była używana przez 49 000 użytkowników organicznych. Ponadto 12.900 dodatkowych użytkowników przybyło jako ruch bezpośredni, który po raz pierwszy został pozyskany przez bezpłatne wyszukiwanie. Ponadto dane sesji/strony oraz średni czas trwania sesji są wyższe w przypadku tych segmentów użytkowników.
Jak wspomniano wcześniej, wyszukiwarka może grupować zapytania, dokumenty, intencje, koncepcje, zainteresowania, działania, ale także może grupować użytkowników. Jeśli grupa użytkowników pozostawi pozytywne opinie podczas tworzenia wartości marki, dodając te strony internetowe do zakładek, wpisując bezpośrednio pasek adresu i przeszukując ogólne terminy wraz z nazwą marki, pokazuje to, że źródło poprawia jej autorytet i wyszukiwarkę jest w stanie rozpoznać wszystko od SERP, Chrome i własnych adresów DNS. 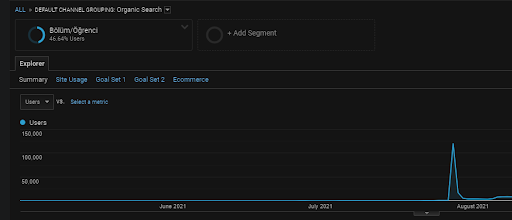
Powyżej widać segment użytkowników pierwszej sieci partnerskiej. Możesz utworzyć segment użytkowników dla każdej semantycznej sieci partnerskiej z niestandardowymi celami, a także możesz dodać segmenty podrzędnych użytkowników dla semantycznych podsieci z treścią.
8. Obsługuj semantyczne sieci treści za pomocą podsekcji opartych na działaniach związanych z wyszukiwaniem
Ta sekcja dotyczy również rozwiązywania atrybutów encji i analizy, która jest innym tematem. Mówiąc prościej, niektóre atrybuty tych jednostek oparte na domenach kontekstowych powinny być umieszczone w hierarchii niższej, a nie wyższej. W tym przypadku „Vizem.net” może dać lepszy przykład, podczas gdy dla Bogazici Enstitusu można to zademonstrować za pomocą „Wynagrodzeń z zawodów” i „Punktów egzaminacyjnych uniwersytetów”. Te dwa wyróżniające się atrybuty zostały umieszczone na podstawie szablonów zapytań i dokumentów w semantycznych sieciach treści podrzędnych. 
Identyfikacja jednostek semantycznych z zapytania wyszukiwania to kolejny patent Google, który dzieli frazy na różne kategorie semantyczne i agreguje trafność dokumentu na podstawie jego bliskości do wszystkich odmian zapytania.
W poprzednim SEO Case Study nie stosowałem tego typu struktury, stworzyłem ścieżkę indeksowania w oparciu o „chronologię” oraz linki wewnętrzne, które są ściśle ograniczone. W tych artykułach ilość linków wewnętrznych umieszczonych w głównej treści jest wyższa niż w poprzednim.
9. Używaj słów tematycznych w adresach URL
Jeśli Google napotka dwa różne adresy URL z tą samą treścią bez żadnego sygnału kanonizacji, wybiera krótki jako kanoniczny. Ponieważ krótkie adresy URL są łatwiejsze do przeanalizowania, rozwiązania i żądania. Kiedy masz biliony stron internetowych, które codziennie odświeżasz miliardy razy, nawet litery w adresach URL mogą pokazywać „bilans kosztów / jakości” witryny. Jak powiedziałem wcześniej, „koszt odzyskania” powinien być niższy niż „koszt nie odzyskania”. Jeśli chcesz być zrozumiany przez wyszukiwarkę, powinieneś umieścić „uporządkowane i uzupełniające sygnały kontekstowe” na każdym poziomie, w tym w adresach URL. 
Sekcja z rankingu „opartego na dowodach” poprzez agregację dowodów. Wyjaśnia, jak można dopasować odpowiedź do pytania.
W tym kontekście przez większość czasu używam pojedynczego słowa w adresie URL. Mogą one odzwierciedlać hierarchię i strukturę semantycznej sieci informacyjnej. Niektórzy nadal uważają, że „liczba warstw” w adresie URL wpływa na częstotliwość indeksowania, przed 2019 r. była to prawda. Ale dopóki treść ma sens i zadowala użytkowników z popularnego lub znanego tematu, taka sytuacja nie będzie miała na nią wpływu.
Aby to zademonstrować, możesz skorzystać z poniższego przykładu.
- Domena główna/semantyczna-zawartość-sieć-1/typ-1/sub-treść-sieć-część-dla-typu-1
- Domena główna/semantyczna-zawartość-sieć-2/typ-2/sub-treść-sieć-część-dla-typu-2
Te dwie semantyczne sieci informacyjne mogą łączyć się ze sobą z tej samej hierarchii, a także mogą łączyć się na podstawie trafności. Jest tu więcej rzeczy, o których możemy porozmawiać, takich jak „Zawartość grupowania jednostek – Treść typu centrum”, ale temat na inny dzień.
Uwaga: planowana trzecia sieć semantyczna może być również przetwarzana jako „Conceptual Grouper Content Network”. A jeśli zostanie opublikowany, z efektem Second Semantic Content Network, całkowity ruch organiczny może wynieść ponad 3 miliony sesji miesięcznie.
10. Zrozum różnicę między zagnieżdżaniem a łączeniem
Praktyczna różnica metodologiczna polega na łączeniu ze sobą podobnych rzeczy w oparciu o domenę kontekstową, podczas gdy zagnieżdżanie to grupowanie podobnych treści w tym samym celu. Takie grupowanie pomoże wyszukiwarce szybciej znajdować podobne treści, a tworzenie źródłowego wyniku jakości dla tych grup lub zagnieżdżone treści oparte na sieci semantycznej będzie łatwiejsze. 
Wyobraź sobie, że istnieją dwie różne ścieżki przeszukiwania, jak poniżej.
- Ścieżka indeksowania 1: Natrafia na adresy URL losowo, bez szablonu, podobieństwa i kontekstu.
- Ścieżka indeksowania 2: Natrafia na adresy URL, które mają sens nawet z samego adresu URL, z szablonem o wysokim poziomie podobieństwa i trafności w oparciu o kontekst.
Jeśli nawet ze ścieżki indeksowania treść ma sens, „początkowy ranking” i „ponowny ranking” będą lepsze dzięki „wyzwalaniu ponownego rankingu opartego na zrozumieniu zasięgu w wyszukiwarce”.
Uwaga: Właściwe używanie linków wewnętrznych z taksonomią fraz jest ważne dla zagnieżdżania i łączenia.
To prowadzi nas do dwóch ostatnich praktycznych metod dzielenia się pokrótce. I ta sekcja jest ponownie związana z wysokim poziomem dyscypliny i wystarczalności organizacyjnej. 
Patent Trystana Upstilla i Stevena D. Bakera za rozpoznawanie współwystępujących terminów na listach HTML. Ważnym elementem tego patentu jest to, że pokazuje wartość pojedynczej listy HTML w celu określenia listy terminów współwystępujących dla danego tematu lub części taksonomii fraz.
11. Zrozum, kiedy publikować semantyczną sieć treści z dostosowaną częstotliwością
Zostało to wyjaśnione wcześniej, ale w jednym z tych projektów SEO Case Study opublikowałem prawie 400 treści w ciągu jednego dnia. Jeśli chodzi o drugą, to zacząłem publikować nagle tylko 10-15 treści, potem stopniowo zwiększałem prędkość, aż zaczną się problemy ekonomiczne związane z Covidem.
Jeśli nowe źródło tworzy nową sieć semantyczną, opublikowanie jej pierwszego dnia może być nieco trudniejsze niż myślisz, sprawdzenie wszystkich linków wewnętrznych, gramatyki i informacji na stronie internetowej nie jest takie proste. Jeśli jednak cała treść pochodzi tylko z jednego tematu i szablonu zapytania, a źródło nie ma żadnej historii na ten temat, opublikowanie większej części semantycznej sieci informacyjnej ma takie zalety, jak szybsze indeksowanie, zrozumienie i zmiana rankingu.
W mojej sytuacji doszło też do wydarzenia historycznego z sezonowością. Tak więc moim celem było posiadanie wystarczającego poziomu średniej pozycji, aż będę mógł być testowany przez wyszukiwarkę pod kątem konkretnych podmiotów i działań wyszukiwania w stosunku do starszych źródeł. W związku z tym opublikowałem pierwszą semantyczną sieć partnerską z wysokim poziomem przygotowania przed 45 dniami od wydarzenia sezonowego.
Następnie możesz zobaczyć, jak wyszukiwarka wielokrotnie testowała źródło, jak poniżej. 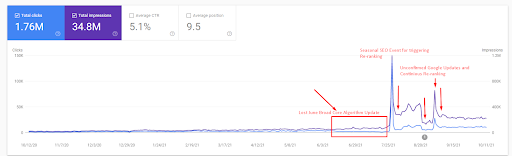
Bardziej szczegółowe wyjaśnienie znajduje się poniżej. 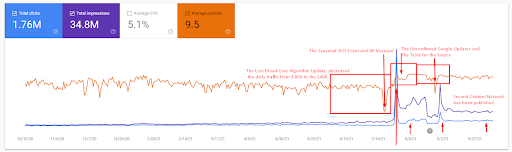
Krótkie sprawdzenie faktów można znaleźć poniżej, aby zapoznać się z powyższym wyjaśnieniem zrzutu ekranu.
- Aktualizacja Broad Core Algorithm zmniejszyła ruch w witrynie o ponad 200%.
- Serwis stracił również ponad 15 000 zapytań.
- Wpłynęło to na ogólną indeksację źródła dla nowej semantycznej sieci treści, ponieważ w szczegółowym artykule poświęconym SEO wyjaśniono lepiej.
- Dzięki sezonowemu wydarzeniu SEO zmiana rankingu nastąpiła wcześniej, a po sezonowym wydarzeniu SEO wyszukiwarka znormalizowała ranking źródła na podstawie rzeczywistego ruchu podczas niepotwierdzonych aktualizacji.
- Zapytania i rankingi uzyskane dzięki First Semantic Content Network i wydarzeniu sezonowemu zostały zabezpieczone i dodatkowo ulepszone.
- Pierwsza sieć Semantic Content Network wspierała również nową i drugą Semantic Content Network.
Utratę zapytań i średnią utratę rankingu można również zobaczyć w Ahrefs, jak poniżej. Możesz sprawdzić efekt aktualizacji algorytmu Google Broad Core Algorithm Update (GBCAU) z czerwca 2021 r. wraz z efektem niepotwierdzonej aktualizacji. 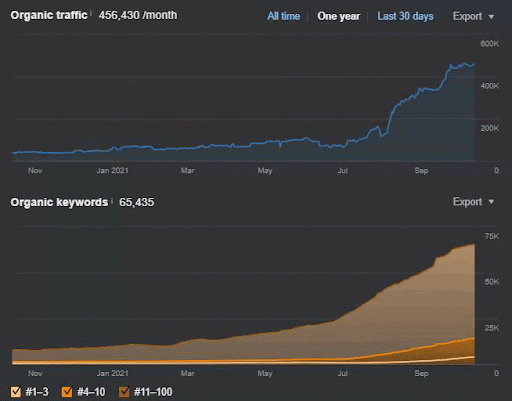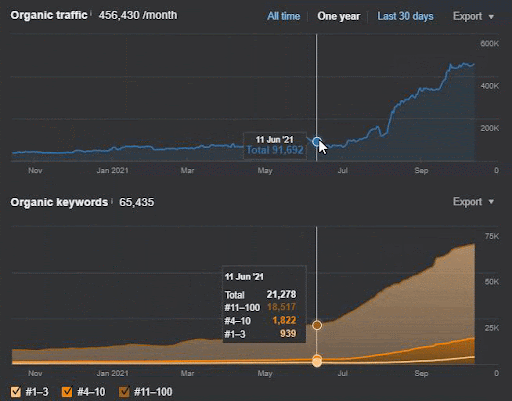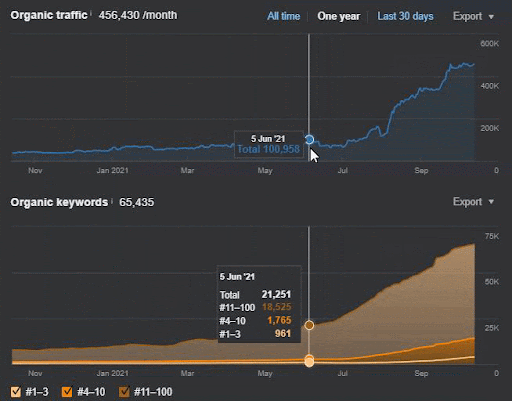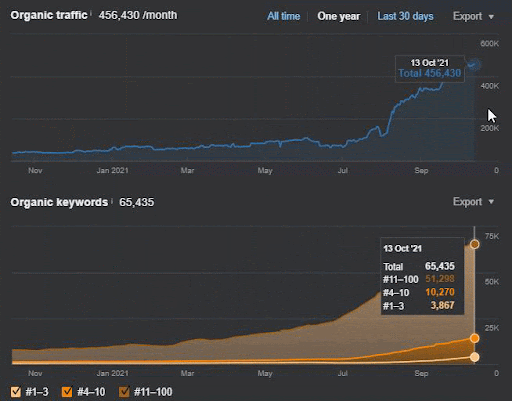
Dlatego korzystanie z semantycznej sieci partnerskiej z wieloma możliwymi strategiami jest koniecznością. Nawet jeśli GCBAU zostanie utracone, nadal, dzięki innym czynnikom związanym z wyszukiwarką, natura może pomóc SEO. Dlatego możesz sobie wyobrazić, dlaczego wyjaśnienie tych rzeczy autorowi lub klientowi jest trudniejsze niż techniczne SEO. Semantyczne SEO nie używa wartości liczbowych, wykorzystuje wiedzę teoretyczną pochodzącą ze zrozumienia wyszukiwarek za pośrednictwem patentów, prac badawczych, doświadczenia i historycznych ogłoszeń.
12. Użyj optymalizacji zdań na stronie, aby uzyskać lepszą strukturę faktów
Szczerze mówiąc, nawet dziesiąty wpis jest zupełnie nowym tematem i może wymagać tutaj nawet napisania 20 000 słów. Ale zacznę od prostego przykładu.
- X to Y.
- Y to X.
W przykładowych zdaniach powyżej możesz zrozumieć poniższe rzeczy.
- Powyższe zdania nie są duplikatami treści.
- Powyższe propozycje są duplikatami.
- Wyjaśnienia relacyjne między dwoma zdaniami są takie same.
- Etykiety ról semantycznych są w 100% różne.
- Dane wyjściowe rozpoznawania jednostek nazwanych są w 100% takie same.
Optymalizacja zdań na stronie jest powiązana z algorytmami generowania pytań i technologiami parowania pytań i odpowiedzi. Format pytania wymaga określonego typu zdania. A na niektóre rodzaje pytań należy odpowiadać za pomocą określonych rodzajów zdań. Optymalizacja struktury zdań będzie miała wpływ na format treści, NER i wyodrębnianie faktów. 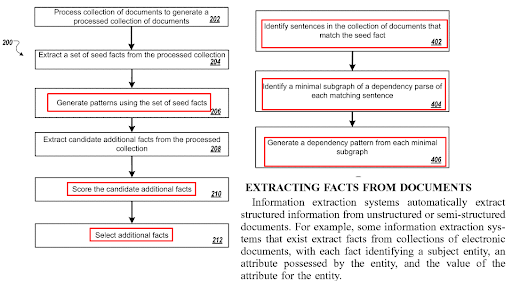
Trójki (jeden obiekt, dwa obiekty) można szybciej wyodrębnić i sprawdzić pod względem dokładności. Dwa podobne zdania nie oznaczają, że są zduplikowane, to znaczy, że są do siebie zbliżone pod względem budowy zdania. Dopóki propozycja jest inna, używanie podobnych zdań między podobnymi szablonami dokumentów dla różnych par zapytanie-intencja jest koniecznością przy tworzeniu semantycznej sieci informacyjnej. 
Jasne struktury zdań z odpowiednim wzorem są przydatne, aby fragmenty tekstu były bardziej dopasowane do siebie, jednocześnie pomagając wyszukiwarce w rozpoznawaniu nazwanych jednostek, tematów, atrybutów wraz z ich wartościami względem siebie.
Pomoże to również zobaczyć, którą sekcję artykułu można ulepszyć, oraz w Topical Nets, gdzie treść jest lepiej oceniana pod względem typów par słów, wektorów słów i intencji. Ponieważ, jeśli pewne typy struktur zdań dla niektórych typów pytań można zaobserwować na wielu stronach internetowych, pomoże to w zaawansowanych testach SEO A/B z nieskończoną ilością próbek danych i próbek testowych. Możesz utworzyć wiele projektów zdań na stronie, aby sprawdzić, jak wyszukiwarka wyodrębnia fakty w celu ich porównania. 
Jeśli chodzi o podawanie faktów, należy pamiętać o „Skarbcu Wiedzy” i Luna Dong.
13. Podawaj informacje ze świata rzeczywistego z precyzją i spójnością, a nie opiniami za pomocą Fluff
Precyzja oznacza tutaj możliwość porównania z wartościami liczbowymi lub konceptualnymi konkretnymi relacjami. Konsekwencja sprawia, że chronisz swoją postawę przed konkretną propozycją. Na przykład nie mów, że „X produkt jest najlepszy dla Y” dla każdej recenzji produktu związanej z Y. Nie podawaj sprzecznych propozycji w całej witrynie. A jeśli produkt jest najlepszy, jaki jest tego dowód? Materiał, rozmiar czy kolor i zapach? Puch w tekście oznacza, że używasz niepotrzebnych słów pomostowych lub nie mówisz rzeczy, których nie można udowodnić, lub które zaprzeczają prawdzie.
W kontekście tych nieokreślonych instrukcji, które są obsługiwane przez niektóre przykłady, możesz sprawdzić jeden z modeli językowych Google, którym jest KeALM.
Służy do generowania tekstu z bazy danych z modelami typu data-to-text i służy do sprawdzania poprawności treści. 
KELM jest przykładem Audytu Dokładności dla propozycji metodami text-to-data.
Jest to również trochę o definicji „Triplet” i „Otwarte wyodrębnianie informacji dla nieznanych jednostek”, ale jak wiecie, jest to krótka wersja i myślę, że powiedziałem wystarczająco dużo. Zasadniczo, gdy podajesz nieprawidłowe informacje w swojej witrynie, upewnij się, że Google jest w stanie je zrozumieć, aby zmniejszyć zaufanie oparte na wiedzy źródła. W tym przypadku możesz potrzebować również wiedzieć, że skoro jesteś w stanie rozszerzyć bazę wiedzy, wyszukiwarka może zmienić własną bazę wiedzy na podstawie twoich informacji, jeśli masz skorelowane źródło z PageRank i zaufanie do bazy wiedzy z dużą dokładnością i unikalnymi trojaczkami.
14. Zrozum semantyczne drzewo zależności dla encji
Semantic Dependency Tree oznacza, że atrybuty sygnalizujące relacje z innymi podmiotami mają między sobą hierarchiczną zależność. Drzewo zależności semantycznych można zaobserwować, sprawdzając wiele profili encji i kątów, na przykład kraj może być członkiem organizacji, a jako inna jednostka, ta organizacja może mieć inne atrybuty, które można przypisać powiązanym krajom z wywnioskowanymi relacjami.
Poniżej zobaczysz prosty przykład bezpośrednio z wyszukiwarki. 
REALM to metoda wykorzystująca drzewa zależności semantycznych do wyodrębniania informacji z niejednoznacznego tekstu.
W otwartej sieci wyodrębnianie otwartych informacji może rozpoznawać nowe nazwane jednostki i wyodrębniać te same jednostki jako współwystępujące z innymi jednostkami. Te współwystępowania i wzajemne atrybuty w artykule mogą przypisywać kontekst i typ relacji kandydującej między jednostkami. Na podstawie połączeń i typu jednostki można utworzyć semantyczne drzewo zależności. Ta sama logika występuje również w przypadku leksykalnej semantyki. Słowo „chłopiec” ma kilka możliwych znaczeń i kilka innych znaczeń. Takich jak chłopiec to mężczyzna i prawdopodobnie nastolatek, który nie jest żonaty. Może być również używany blisko ucznia. Z drugiej strony słowo „królowa” zawiera inne poboczne i dokładne znaczenia, takie jak „kobieta” i „bycie gubernatorem”. Zatem posiadanie czegoś do zarządzania jest naturalną hierarchią semantycznego drzewa zależności, która może sygnalizować niektóre typy szablonów zapytań, takie jak „Królowa…” lub „Dla Quen”. These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together. 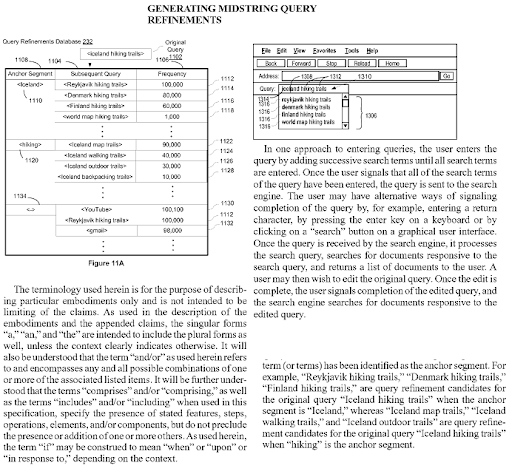
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network's connections to each other. Every midstring query refinement is a part of the topic's sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.