
Kontrolowanie indeksowania i indeksowania: przewodnik SEO po pliku Robots.txt i tagach
Opublikowany: 2019-02-19Optymalizacja pod kątem budżetu indeksowania i blokowanie botów z indeksowania stron to pojęcia, które zna wielu SEO. Ale diabeł tkwi w szczegółach. Zwłaszcza, że najlepsze praktyki uległy znacznej zmianie w ostatnich latach.
Jedna niewielka zmiana w pliku robots.txt lub tagach robots może mieć ogromny wpływ na Twoją witrynę. Aby zapewnić zawsze pozytywny wpływ na Twoją witrynę, dzisiaj zajmiemy się:
Optymalizacja budżetu indeksowania
Co to jest plik Robots.txt
Czym są tagi Meta Robots
Czym są tagi X-Robots
Dyrektywy dotyczące robotów i SEO
Lista kontrolna najlepszych praktyk robotów
Optymalizacja budżetu indeksowania
Pająk wyszukiwarek ma „przydział” na liczbę stron, które może i chce zaindeksować w Twojej witrynie. Jest to znane jako „budżet indeksowania”.
Sprawdź budżet indeksowania swojej witryny w raporcie „Statystyki indeksowania” Google Search Console (GSC). Zauważ, że GSC to zbiór 12 botów, z których nie wszystkie są poświęcone SEO. Gromadzi również boty AdWords lub AdSense, które są botami SEA. W ten sposób narzędzie to daje wyobrażenie o globalnym budżecie indeksowania, ale nie jego dokładnym podziale.
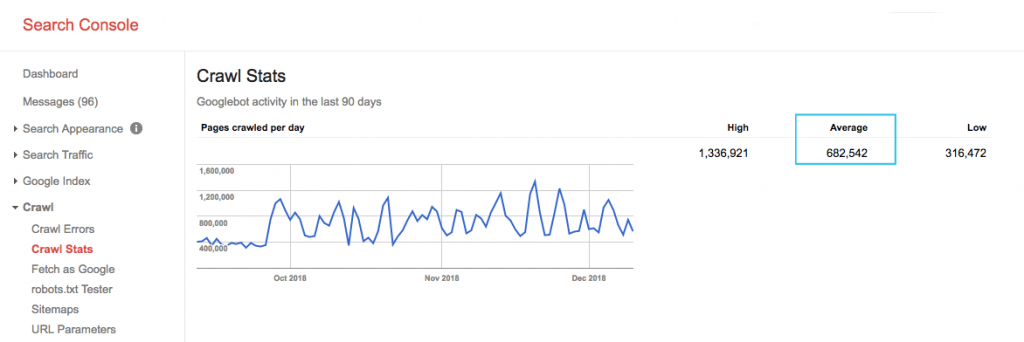
Aby liczba była bardziej użyteczna, podziel średnią liczbę stron indeksowanych dziennie przez całkowitą liczbę stron, które można zindeksować w Twojej witrynie – możesz poprosić programistę o liczbę lub uruchomić nieograniczony robot indeksujący witryny. Dzięki temu uzyskasz oczekiwany współczynnik indeksowania, na podstawie którego możesz rozpocząć optymalizację.
Chcesz wejść głębiej? Uzyskaj bardziej szczegółowy podział aktywności Googlebota, np. odwiedzane strony, a także statystyki innych robotów, analizując pliki dziennika serwera witryny.
Istnieje wiele sposobów na optymalizację budżetu indeksowania, ale warto zacząć od sprawdzenia w raporcie „Pokrycie” GSC, aby poznać aktualne zachowanie Google w zakresie przeszukiwania i indeksowania.
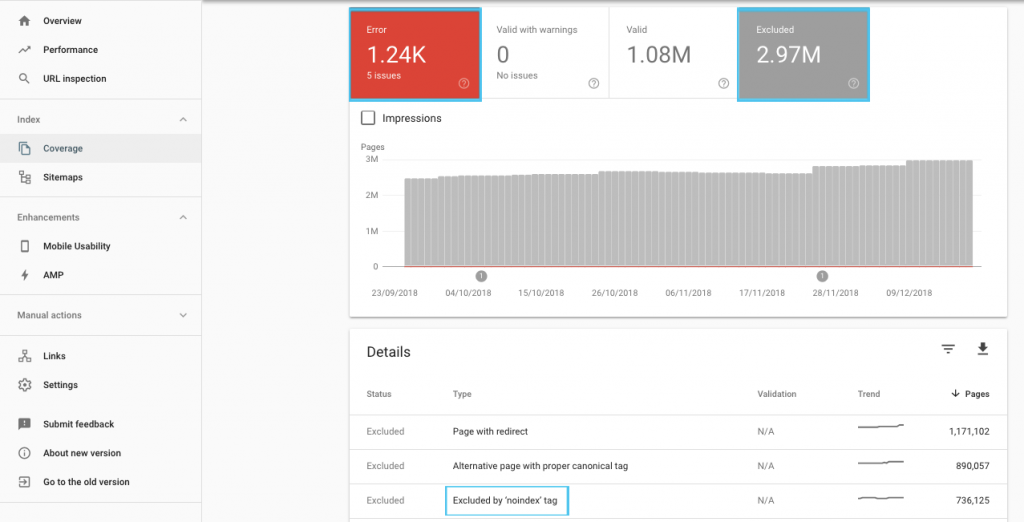
Jeśli zobaczysz błędy, takie jak „Przesłany adres URL oznaczony jako „noindex”” lub „Przesłany adres URL zablokowany przez plik robots.txt”, skontaktuj się z programistą, aby je naprawić. W przypadku wykluczeń robotów zbadaj je, aby zrozumieć, czy są one strategiczne z punktu widzenia SEO.
Ogólnie rzecz biorąc, SEO powinno dążyć do zminimalizowania ograniczeń indeksowania robotów. Najlepszą strategią jest ulepszanie architektury witryny, aby adresy URL były przydatne i dostępne dla wyszukiwarek.
Sami Google zauważają, że „solidna architektura informacji prawdopodobnie będzie znacznie bardziej produktywnym wykorzystaniem zasobów niż skupianie się na priorytetyzacji indeksowania”.
Biorąc to pod uwagę, warto wiedzieć, co można zrobić z plikami robots.txt i znacznikami robots, aby kierować indeksowaniem i przekazywaniem wartości linków. A co ważniejsze, kiedy i jak najlepiej wykorzystać to w nowoczesnym SEO.
[Studium przypadku] Zarządzanie indeksowaniem botów Google
 Przeczytaj studium przypadku
Przeczytaj studium przypadkuCo to jest plik Robots.txt
Zanim roboty-pająki wyszukiwarki przerobią jakąkolwiek stronę, sprawdzi plik robots.txt. Ten plik informuje boty, które ścieżki URL mają uprawnienia do odwiedzenia. Ale te wpisy to tylko dyrektywy, a nie nakazy.
Robots.txt nie może niezawodnie zapobiegać indeksowaniu , tak jak zapora lub ochrona hasłem. To cyfrowy odpowiednik napisu „proszę nie wchodzić” na otwartych drzwiach.
Uprzejme roboty indeksujące, takie jak główne wyszukiwarki, zazwyczaj będą przestrzegać instrukcji. Wrogie roboty indeksujące, takie jak skrobaki poczty e-mail, spamboty, złośliwe oprogramowanie i pająki, które skanują luki w witrynie, często nie zwracają uwagi.
Co więcej, jest to plik dostępny publicznie . Każdy może zobaczyć Twoje polecenia.
Nie używaj pliku robots.txt do:
- Aby ukryć poufne informacje. Używaj ochrony hasłem.
- Aby zablokować dostęp do twojej strony testowej i/lub deweloperskiej. Użyj uwierzytelniania po stronie serwera.
- Aby wyraźnie zablokować wrogie roboty. Użyj blokowania adresów IP lub blokowania klienta użytkownika (czyli wykluczaj dostęp do określonego robota za pomocą reguły w pliku .htaccess lub narzędzia takiego jak CloudFlare).
Każda witryna powinna mieć prawidłowy plik robots.txt z co najmniej jedną grupą dyrektyw. Bez niego wszystkie boty mają domyślnie pełny dostęp – więc każda strona jest traktowana jako możliwa do zindeksowania. Nawet jeśli to jest to, co zamierzasz, lepiej wyjaśnić to wszystkim interesariuszom za pomocą pliku robots.txt. Dodatkowo, bez tego, logi serwera będą pełne nieudanych żądań dotyczących pliku robots.txt.
Struktura pliku robots.txt
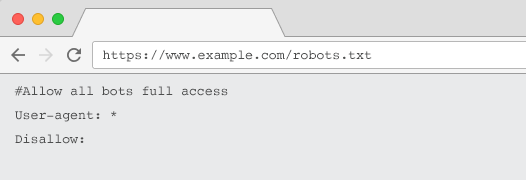
Aby roboty indeksujące mogły zostać rozpoznane, plik robots.txt musi:
- Być plikiem tekstowym o nazwie „robots.txt”. W nazwie pliku rozróżniana jest wielkość liter. „Robots.TXT” lub inne odmiany nie będą działać.
- Znajduj się w katalogu najwyższego poziomu swojej domeny kanonicznej i, jeśli to konieczne, w subdomenach. Na przykład, aby kontrolować indeksowanie wszystkich adresów URL znajdujących się poniżej https://www.example.com, plik robots.txt musi znajdować się pod adresem https://www.example.com/robots.txt, a dla subdomeny.example.com pod adresem subdomena.example.com/robots.txt.
- Zwróć status HTTP 200 OK.
- Użyj prawidłowej składni pliku robots.txt — sprawdź za pomocą narzędzia do testowania robots.txt w Google Search Console.
Plik robots.txt składa się z grup dyrektyw. Wpisy składają się głównie z:
- 1. User-agent: adresuje różne roboty. Możesz mieć jedną grupę dla wszystkich robotów lub użyć grup do nazwania określonych wyszukiwarek.
- 2. Disallow: Określa pliki lub katalogi, które mają być wykluczone z przeszukiwania przez powyższy agent użytkownika. Możesz mieć jedną lub więcej z tych linii w bloku.
Pełną listę nazw agentów użytkownika i więcej przykładów dyrektyw znajdziesz w przewodniku po pliku robots.txt na Yoast.
Oprócz dyrektyw „User-agent” i „Disallow” istnieje kilka niestandardowych dyrektyw:
- Zezwól: Określ wyjątki od dyrektywy zakazu dla katalogu nadrzędnego.
- Opóźnienie indeksowania: Ogranicz duże roboty, informując boty, ile sekund mają czekać przed odwiedzeniem strony. Jeśli masz niewiele sesji organicznych, opóźnienie indeksowania może zaoszczędzić przepustowość serwera. Ale zainwestowałbym ten wysiłek tylko wtedy, gdy roboty indeksujące aktywnie powodują problemy z obciążeniem serwera. Google nie akceptuje tego polecenia, oferuje opcję ograniczenia szybkości indeksowania w Google Search Console.
- Clean-param: unikaj ponownego indeksowania zduplikowanych treści generowanych przez parametry dynamiczne.
- Brak indeksu: zaprojektowany do kontrolowania indeksowania bez korzystania z budżetu indeksowania. Nie jest już oficjalnie obsługiwany przez Google. Chociaż istnieją dowody na to, że nadal może mieć wpływ, nie można na nim polegać i nie jest zalecany przez ekspertów, takich jak John Mueller.
@maxxeight @google @DeepCrawl Naprawdę unikałbym używania tam noindex.
— ???? Jan ???? (@JohnMu) 1 września 2015 r.
- Mapa witryny: optymalnym sposobem przesłania mapy witryny XML jest skorzystanie z Google Search Console i Narzędzi dla webmasterów innych wyszukiwarek. Jednak dodanie dyrektywy mapy witryny do podstawy pliku robots.txt pomaga innym robotom, które mogą nie oferować opcji przesyłania.
Ograniczenia pliku robots.txt dla SEO
Wiemy już, że plik robots.txt nie może uniemożliwić indeksowania wszystkim botom. Podobnie, zabronienie robotom indeksującym ze strony nie zapobiega uwzględnianiu jej na stronach wyników wyszukiwania (SERP).
Jeśli zablokowana strona ma inne silne sygnały w rankingu, Google może uznać ją za odpowiednią do wyświetlania w wynikach wyszukiwania. Pomimo braku indeksowania strony.
Ponieważ zawartość tego adresu URL jest nieznana Google, wynik wyszukiwania wygląda tak:

Aby ostatecznie zablokować wyświetlanie strony w SERP, musisz użyć metatagu robots „noindex” lub nagłówka HTTP X-Robots-Tag.
W takim przypadku nie zablokuj strony w pliku robots.txt , ponieważ strona musi zostać zindeksowana, aby tag „noindex” był widoczny i przestrzegany. Jeśli adres URL jest zablokowany, wszystkie tagi robots są nieskuteczne.
Co więcej, jeśli strona zgromadziła dużo linków przychodzących, ale Google nie może indeksować tych stron przez plik robots.txt, a linki są znane Google, wartość linków jest tracona.
Czym są tagi Meta Robots
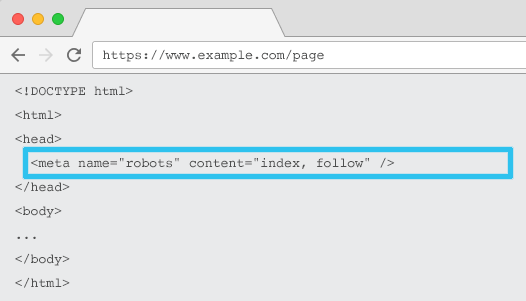
Umieszczona w kodzie HTML każdego adresu URL, meta name=”robots” mówi robotom indeksującym, czy i jak „indeksować” treść i czy „śledzić” (tj. indeksować) wszystkie linki na stronie, przekazując ich wartość.
Używając ogólnej meta name = „robots”, dyrektywa dotyczy wszystkich robotów indeksujących. Możesz także określić konkretnego agenta użytkownika. Na przykład meta nazwa = „googlebot”. Ale rzadko trzeba używać wielu metatagów robotów, aby ustawić instrukcje dla określonych pająków.
Podczas korzystania z metatagów robots należy wziąć pod uwagę dwie ważne kwestie:
- Podobnie jak w przypadku pliku robots.txt, metatagi są dyrektywami, a nie nakazami, więc niektóre boty mogą je ignorować.
- Dyrektywa robots nofollow dotyczy tylko linków na tej stronie. Możliwe, że robot indeksujący może kliknąć link z innej strony lub witryny bez nofollow. Więc bot może nadal dotrzeć i zaindeksować niechcianą stronę.
Oto lista wszystkich dyrektyw meta robots tag:
- indeks: nakazuje wyszukiwarkom wyświetlanie tej strony w wynikach wyszukiwania. Jest to stan domyślny, jeśli nie określono żadnej dyrektywy.
- noindex: informuje wyszukiwarki, aby nie pokazywały tej strony w wynikach wyszukiwania.
- obserwuj: nakazuje wyszukiwarkom podążanie za wszystkimi linkami na tej stronie i przekazywanie wartości, nawet jeśli strona nie jest zaindeksowana. Jest to stan domyślny, jeśli nie określono żadnej dyrektywy.
- nofollow: informuje wyszukiwarki, aby nie klikały żadnego linku na tej stronie ani nie przekazywały wartości.
- all: Odpowiednik „indeksuj, obserwuj”.
- none: odpowiednik „noindex, nofollow”.
- noimageindex: informuje wyszukiwarki, aby nie indeksowały żadnych obrazów na tej stronie.
- noarchive: informuje wyszukiwarki, aby nie pokazywały w wynikach wyszukiwania linku do tej strony w pamięci podręcznej.
- nocache: To samo co noarchive, ale używane tylko przez Internet Explorer i Firefox.
- nosnippet: informuje wyszukiwarki, aby nie pokazywały metaopisu ani podglądu wideo dla tej strony w wynikach wyszukiwania.
- notranslate: informuje wyszukiwarkę, aby nie oferowała tłumaczenia tej strony w wynikach wyszukiwania.
- niedostępny_po: Poinformuj wyszukiwarki, aby przestały indeksować tę stronę po określonej dacie.
- noodp: obecnie przestarzałe, kiedyś uniemożliwiało wyszukiwarkom używanie opisu strony z DMOZ w wynikach wyszukiwania.
- noydir: Teraz przestarzałe, kiedyś uniemożliwiało Yahoo używanie opisu strony z katalogu Yahoo w wynikach wyszukiwania.
- noyaca: Uniemożliwia Yandexowi używanie opisu strony z katalogu Yandex w wynikach wyszukiwania.
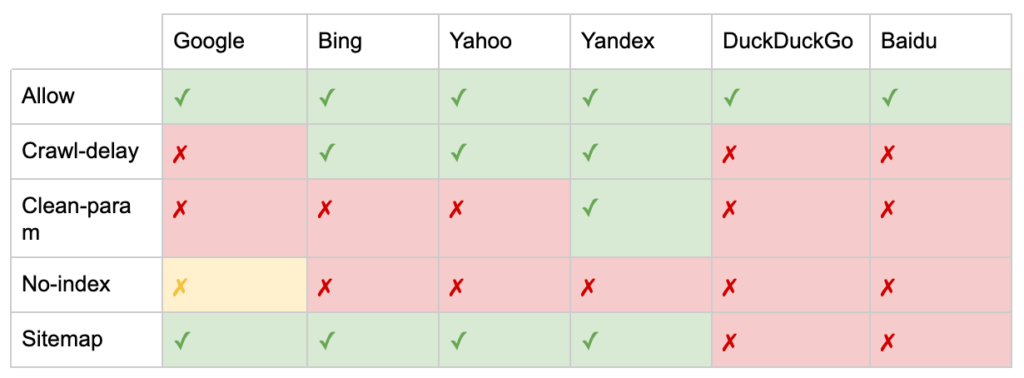
Jak udokumentował Yoast, nie wszystkie wyszukiwarki obsługują wszystkie metatagi robotów, a nawet są jasne, co robią, a czego nie obsługują.
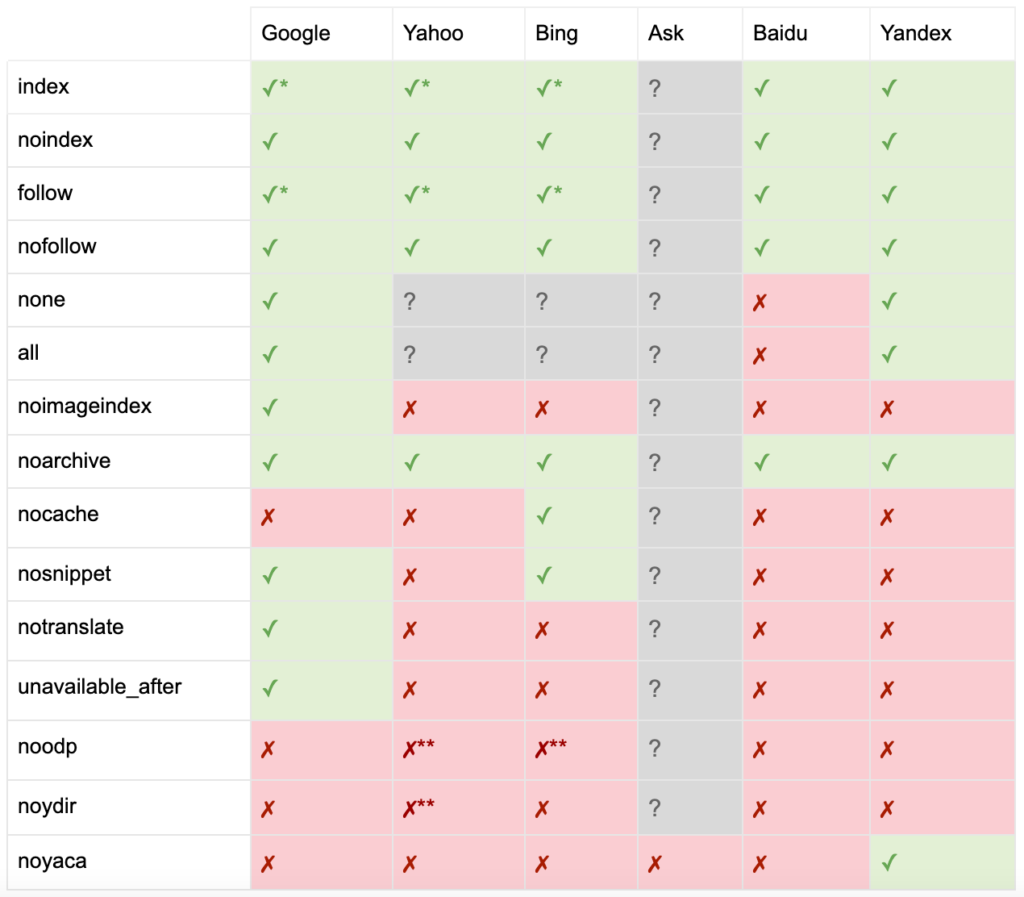
* Większość wyszukiwarek nie ma konkretnej dokumentacji na ten temat, ale zakłada, że obsługa wykluczania parametrów (np. nofollow) oznacza obsługę pozytywnego odpowiednika (np. follow).
** Chociaż atrybuty noodp i noydir mogą być nadal „obsługiwane”, katalogi już nie istnieją i prawdopodobnie te wartości nic nie robią.
Zwykle tagi robotów są ustawione na „indeksuj, obserwuj”. Niektórzy SEO uważają, że dodanie tego tagu w kodzie HTML jest tak samo zbędne, jak jest to ustawienie domyślne. Kontrargumentem jest to, że jasne określenie dyrektyw może pomóc uniknąć ludzkiego zamieszania.

Uwaga: adresy URL z tagiem „noindex” będą indeksowane rzadziej, a jeśli będą obecne przez dłuższy czas, w końcu doprowadzą Google do nofollow linków do strony.
Rzadko zdarza się znaleźć przypadek użycia, aby „nie śledzić” wszystkich linków na stronie z metatagiem robots. Częściej zdarza się, że „nofollow” dodaje się do poszczególnych linków za pomocą atrybutu linku rel=”nofollow”. Na przykład możesz rozważyć dodanie atrybutu rel="nofollow" do komentarzy generowanych przez użytkowników lub płatnych linków.
Jeszcze rzadziej zdarzają się przypadki użycia SEO dla dyrektyw tagów robotów, które nie dotyczą podstawowego indeksowania i śledzenia zachowań, takich jak buforowanie, indeksowanie obrazów i obsługa fragmentów itp.
Wyzwaniem związanym z metatagami robots jest to, że nie można ich używać do plików innych niż HTML, takich jak obrazy, wideo lub dokumenty PDF. Tutaj możesz zwrócić się do X-Robots-Tags.
Czym są tagi X-Robots
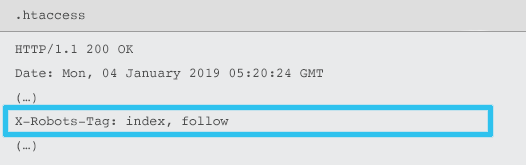
X-Robots-Tag są wysyłane przez serwer jako element nagłówka odpowiedzi HTTP dla danego adresu URL za pomocą plików .htaccess i httpd.conf.
Każda dyrektywa metatagu robots może być również określona jako X-Robots-Tag. Jednak X-Robots-Tag oferuje dodatkową elastyczność i funkcjonalność.
Możesz użyć X-Robots-Tag zamiast metatagów robotów, jeśli chcesz:
- Kontroluj zachowanie robotów dla plików innych niż HTML, a nie samych plików HTML.
- Kontroluj indeksowanie określonego elementu strony, a nie całej strony.
- Dodaj reguły określające, czy strona powinna być indeksowana. Na przykład, jeśli autor opublikował więcej niż 5 artykułów, zaindeksuj jego stronę profilową.
- Zastosuj dyrektywy indeksu i wykonaj na poziomie całej witryny, a nie tylko na stronie.
- Użyj wyrażeń regularnych.
Unikaj używania meta robotów i tagu x-robots na tej samej stronie — byłoby to zbędne.
Aby wyświetlić X-Robots-Tags, możesz użyć funkcji „Pobierz jako Google” w Google Search Console.
Dyrektywy dotyczące robotów i SEO
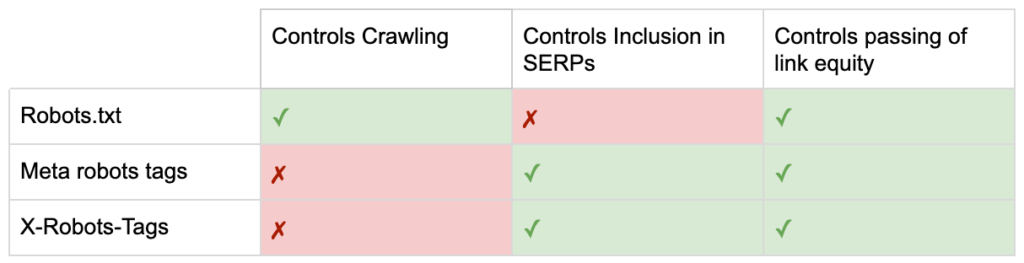
Więc teraz znasz różnice między trzema dyrektywami dotyczącymi robotów.
Plik robots.txt koncentruje się na oszczędzaniu budżetu indeksowania, ale nie zapobiega wyświetlaniu strony w wynikach wyszukiwania. Działa jako pierwszy strażnik Twojej witryny, nakazując botom, aby nie uzyskiwały dostępu przed żądaniem strony.
Oba typy znaczników robotów skupiają się na kontrolowaniu indeksowania i przekazywaniu kapitału linków. Metatagi robots działają dopiero po załadowaniu strony . Podczas gdy nagłówki X-Robots-Tag zapewniają bardziej szczegółową kontrolę i działają po odpowiedzi serwera na żądanie strony.
Dzięki temu zrozumieniu SEO może ewoluować sposób, w jaki używamy dyrektyw robotów do rozwiązywania problemów związanych z indeksowaniem i indeksacją.
Blokowanie botów w celu zaoszczędzenia przepustowości serwera
Problem: Analizując pliki dziennika, zauważysz, że wielu klientów użytkownika odbiera przepustowość, ale zwraca niewielką wartość.
- Roboty SEO, takie jak MJ12bot (od Majestic) lub Ahrefsbot (od Ahrefs).
- Narzędzia do zapisywania treści cyfrowych w trybie offline, takie jak Webcopier lub Teleport.
- Wyszukiwarki, które nie są odpowiednie na Twoim rynku, takie jak Baiduspider lub Yandex.
Nieoptymalne rozwiązanie: blokowanie tych pająków za pomocą pliku robots.txt, ponieważ nie ma gwarancji, że zostanie on honorowany i jest raczej publiczną deklaracją, która może dać zainteresowanym stronom konkurencyjny wgląd.
Podejście oparte na najlepszych praktykach: bardziej subtelna dyrektywa blokowania klienta użytkownika. Można to osiągnąć na różne sposoby, ale zwykle odbywa się to poprzez edycję pliku .htaccess w celu przekierowania wszelkich niechcianych żądań pająka na stronę 403 – Zabroniona.
Wewnętrzne strony wyszukiwania w witrynie korzystające z budżetu indeksowania
Problem: w wielu witrynach wewnętrzne strony wyników wyszukiwania w witrynie są generowane dynamicznie pod statycznymi adresami URL, które następnie pochłaniają budżet indeksowania i mogą powodować problemy z niedoborem treści lub powielaniem treści, jeśli zostaną zindeksowane.
Rozwiązanie nieoptymalne: nie zezwalaj na katalog z plikiem robots.txt. Chociaż może to zapobiegać pułapkom robotów indeksujących, ogranicza twoją pozycję w rankingu pod kątem wyszukiwań kluczowych klientów i przekazywanie takich stron link equity.
Podejście oparte na najlepszych praktykach: mapowanie trafnych, dużej liczby zapytań na istniejące przyjazne dla wyszukiwarek adresy URL. Na przykład, jeśli wyszukuję „samsung phone”, zamiast tworzyć nową stronę dla /search/samsung-phone, przekierowuję do /phones/samsung.
Jeśli nie jest to możliwe, utwórz adres URL oparty na parametrach. Następnie możesz łatwo określić, czy parametr ma być indeksowany w Google Search Console.
Jeśli zezwalasz na indeksowanie, przeanalizuj, czy takie strony są wystarczająco wysokiej jakości, aby pozycjonować. Jeśli nie, dodaj dyrektywę „noindex, follow” jako rozwiązanie krótkoterminowe, jednocześnie określając strategię poprawy jakości wyników, aby pomóc zarówno SEO, jak i użytkownikom.
Parametry blokowania za pomocą robotów
Problem: parametry ciągu zapytania, takie jak te generowane przez nawigację aspektową lub śledzenie, są znane z tego, że pochłaniają budżet indeksowania, tworzą zduplikowane adresy URL treści i dzielą sygnały rankingowe.
Nieoptymalne rozwiązanie: Nie zezwalaj na indeksowanie parametrów za pomocą pliku robots.txt lub metatagu robots „noindex”, ponieważ oba (pierwsze natychmiast, później przez dłuższy czas) uniemożliwią przepływ kapitału linków.
Podejście oparte na najlepszych praktykach: upewnij się, że każdy parametr ma jasny powód do istnienia i zaimplementuj reguły porządkowania, które używają kluczy tylko raz i zapobiegają pustym wartościom. Dodaj atrybut linku rel=canonical do odpowiednich stron z parametrami, aby połączyć zdolność rankingową. Następnie skonfiguruj wszystkie parametry w Google Search Console, gdzie dostępna jest bardziej szczegółowa opcja przekazywania preferencji indeksowania. Aby uzyskać więcej informacji, zapoznaj się z przewodnikiem obsługi parametrów Search Engine Journal.
Blokowanie obszarów administratora lub konta
Problem: uniemożliwia wyszukiwarce przeszukiwanie i indeksowanie jakichkolwiek prywatnych treści.
Nieoptymalne rozwiązanie: użycie pliku robots.txt do zablokowania katalogu, ponieważ nie gwarantuje to, że prywatne strony nie będą znajdować się w SERPach.
Podejście oparte na najlepszych praktykach: użyj ochrony hasłem, aby uniemożliwić robotom indeksującym dostęp do stron i wycofać dyrektywę „noindex” w nagłówku HTTP.
Blokowanie marketingowych stron docelowych i stron z podziękowaniami
Problem: często trzeba wykluczyć adresy URL, które nie są przeznaczone do bezpłatnych wyników wyszukiwania, takie jak dedykowane adresy e-mail lub strony docelowe kampanii CPC. Podobnie nie chcesz, aby osoby, które nie dokonały konwersji, odwiedzały Twoje strony z podziękowaniami za pośrednictwem SERP.
Nieoptymalne rozwiązanie: nie zezwalaj na pliki z plikiem robots.txt, ponieważ nie zapobiegnie to uwzględnianiu linku w wynikach wyszukiwania.
Najlepsze rozwiązanie: użyj metatagu „noindex”.
Zarządzaj duplikatami treści na stronie
Problem: niektóre witryny wymagają kopii określonej zawartości ze względu na wygodę użytkownika, na przykład wersji strony do druku, ale chcą mieć pewność, że wyszukiwarka będzie rozpoznawać stronę kanoniczną, a nie zduplikowaną. W innych witrynach zduplikowana treść jest spowodowana złymi praktykami programistycznymi, takimi jak wystawianie tego samego produktu na sprzedaż pod adresami URL wielu kategorii.
Nieoptymalne rozwiązanie: zablokowanie adresów URL z plikiem robots.txt uniemożliwi przesyłanie zduplikowanej strony jakichkolwiek sygnałów rankingowych. Brak indeksowania dla robotów w końcu doprowadzi do traktowania przez Google linków jako „nofollow”, co zapobiegnie przekazywaniu zduplikowanej strony jakiegokolwiek kapitału linków.
Podejście oparte na najlepszych praktykach: jeśli zduplikowana treść nie ma powodu, aby istnieć, usuń źródło i przekierowanie 301 do przyjaznego adresu URL dla wyszukiwarek. Jeśli istnieje powód, aby istnieć, dodaj atrybut rel=canonical link, aby konsolidować sygnały rankingowe.
Cienka zawartość stron związanych z dostępnymi kontami
Problem: strony związane z kontem, takie jak logowanie, rejestracja, koszyk, kasa lub formularze kontaktowe, często mają niewielką treść i oferują niewielką wartość dla wyszukiwarek, ale są niezbędne dla użytkowników.
Nieoptymalne rozwiązanie: nie zezwalaj na pliki z plikiem robots.txt, ponieważ nie zapobiegnie to uwzględnianiu linku w wynikach wyszukiwania.
Podejście oparte na najlepszych praktykach: w przypadku większości witryn liczba tych stron powinna być bardzo niewielka i możesz nie zauważyć wpływu na KPI wdrażania obsługi robotów. Jeśli czujesz taką potrzebę, najlepiej użyj dyrektywy „noindex”, chyba że istnieją zapytania wyszukiwania dla takich stron.
Oznaczanie stron przy użyciu budżetu indeksowania
Problem: Niekontrolowane tagowanie pochłania budżet indeksowania i często prowadzi do problemów z ubogą zawartością.
Nieoptymalne rozwiązania: Nie zezwalaj na plik robots.txt lub dodaj tag „noindex”, ponieważ oba te elementy utrudnią ranking odpowiednich tagów SEO i (natychmiast lub ostatecznie) zapobiegną przepuszczaniu kapitału linków.
Podejście oparte na najlepszych praktykach: oceń wartość każdego z Twoich obecnych tagów. Jeśli dane pokazują, że strona wnosi niewielką wartość do wyszukiwarek lub użytkowników, przekieruj ich 301. W przypadku stron, które przetrwają usunięcie, pracuj nad ulepszeniem elementów na stronie, aby stały się wartościowe zarówno dla użytkowników, jak i botów.
Indeksowanie JavaScript i CSS
Problem: wcześniej boty nie mogły indeksować kodu JavaScript i innych treści multimedialnych. To się zmieniło i teraz zdecydowanie zaleca się, aby umożliwić wyszukiwarkom dostęp do plików JS i CSS w celu opcjonalnego renderowania stron.
Nieoptymalne rozwiązanie: zablokowanie plików JavaScript i CSS w pliku robots.txt w celu zaoszczędzenia budżetu indeksowania może spowodować słabe indeksowanie i negatywnie wpłynąć na rankingi. Na przykład blokowanie dostępu wyszukiwarki do kodu JavaScript, który wyświetla reklamy pełnoekranowe lub przekierowuje użytkowników, może być postrzegane jako maskowanie.
Podejście oparte na sprawdzonych metodach: sprawdź, czy nie występują problemy z renderowaniem za pomocą narzędzia „Pobierz jako Google” lub uzyskaj szybki przegląd zasobów zablokowanych za pomocą raportu „Zablokowane zasoby”, które są dostępne w Google Search Console. Jeśli jakiekolwiek zasoby są zablokowane, co może uniemożliwić wyszukiwarkom prawidłowe renderowanie strony, usuń blokadę pliku robots.txt.
Robot SEO Oncrawl
 Ucz się więcej
Ucz się więcejLista kontrolna najlepszych praktyk robotów
Przerażająco często zdarza się, że witryna została przypadkowo usunięta z Google przez błąd kontrolujący robota.
Niemniej jednak obsługa robotów może być potężnym dodatkiem do Twojego arsenału SEO, jeśli wiesz, jak z niego korzystać. Tylko pamiętaj, aby postępować mądrze i ostrożnie.
Aby pomóc, oto krótka lista kontrolna:
- Zabezpiecz prywatne informacje, korzystając z ochrony hasłem
- Blokuj dostęp do witryn deweloperskich za pomocą uwierzytelniania po stronie serwera
- Ogranicz roboty indeksujące, które pobierają przepustowość, ale oferują niewielką wartość z powrotem dzięki blokowaniu klienta użytkownika
- Upewnij się, że domena podstawowa i wszelkie subdomeny mają plik tekstowy o nazwie „robots.txt” w katalogu najwyższego poziomu, który zwraca kod 200
- Upewnij się, że plik robots.txt zawiera co najmniej jeden blok z wierszem klienta użytkownika i wierszem zakazu
- Upewnij się, że plik robots.txt zawiera co najmniej jeden wiersz mapy witryny, wprowadzony jako ostatni wiersz
- Sprawdź poprawność pliku robots.txt w testerze GSC robots.txt
- Upewnij się, że każda indeksowana strona określa swoje dyrektywy dotyczące tagów robotów
- Upewnij się, że nie ma sprzecznych lub zbędnych dyrektyw między plikiem robots.txt, metatagami robots, X-Robots-Tags, plikiem .htaccess i obsługą parametrów GSC
- Napraw wszelkie błędy „Przesłany adres URL oznaczony jako „noindex” lub „Przesłany adres URL zablokowany przez plik robots.txt” w raporcie pokrycia GSC
- Zrozum przyczynę wszelkich wykluczeń związanych z robotami w raporcie pokrycia GSC
- Upewnij się, że w raporcie GSC „Zablokowane zasoby” są wyświetlane tylko odpowiednie strony
Idź sprawdzić obsługę robotów i upewnij się, że robisz to dobrze.