
Indeksowanie, indeksowanie i Python: wszystko, co musisz wiedzieć
Opublikowany: 2021-05-31Chciałbym rozpocząć ten artykuł od bardzo prostego równania: jeśli Twoje strony nie są indeksowane, nigdy nie zostaną zindeksowane, a zatem zawsze ucierpi na tym Twoja wydajność SEO (i śmierdzi).
W związku z tym SEO muszą starać się znaleźć najlepszy sposób, aby ich witryny były indeksowane i udostępniać Google najważniejsze strony, aby je zaindeksować i zacząć pozyskiwać za ich pośrednictwem ruch.
Na szczęście mamy wiele zasobów, które mogą nam pomóc w ulepszaniu indeksowania naszej witryny, takich jak Screaming Frog, Oncrawl czy Python. Pokażę Ci, w jaki sposób Python może pomóc Ci w analizie i poprawie Twoich wskaźników przyjazności dla indeksowania i indeksowania. Przez większość czasu tego rodzaju ulepszenia prowadzą również do lepszych rankingów, większej widoczności w SERP i ostatecznie większej liczby użytkowników lądujących na Twojej stronie.
1. Żądanie indeksowania za pomocą Pythona
1.1. Dla Google
Żądanie indeksowania dla Google można wykonać na kilka sposobów, chociaż niestety żaden z nich nie przekonuje mnie. Przeprowadzę Cię przez trzy różne opcje z ich zaletami i wadami:
- Selenium i Google Search Console: z mojego punktu widzenia i po przetestowaniu go i pozostałych opcji jest to najskuteczniejsze rozwiązanie. Jednak po kilku próbach możliwe jest, że pojawi się wyskakujące okienko captcha, które je zepsuje.
- Pingowanie mapy witryny: zdecydowanie pomaga w indeksowaniu map witryn zgodnie z żądaniem, ale nie pod określonymi adresami URL, na przykład w przypadku dodania nowych stron do witryny.
- Google Indexing API: nie jest zbyt niezawodny, z wyjątkiem nadawców i witryn platform pracy. Pomaga zwiększyć szybkość indeksowania, ale nie indeksuje określonych adresów URL.
Po tym krótkim omówieniu każdej metody, przyjrzyjmy się im po kolei.
1.1.1. Selenium i Google Search Console
Zasadniczo to, co zrobimy w tym pierwszym rozwiązaniu, to dostęp do Google Search Console z przeglądarki z Selenium i powtórzenie tego samego procesu, który wykonalibyśmy ręcznie, aby przesłać wiele adresów URL do indeksowania w Google Search Console, ale w sposób zautomatyzowany.
Uwaga: nie nadużywaj tej metody i prześlij stronę do indeksowania tylko wtedy, gdy jej zawartość została zaktualizowana lub jeśli strona jest zupełnie nowa.
Sztuczka, aby móc zalogować się do Google Search Console za pomocą Selenium, polega na tym, aby najpierw uzyskać dostęp do OUATH Playground, jak wyjaśniłem w tym artykule o tym, jak zautomatyzować pobieranie raportów statystyk indeksowania GSC.
#Importujemy te moduły
czas importu
z selen importu webdriver
z webdriver_manager.chrome import ChromeDriverManager
z selen.webdriver.common.keys importuj klucze
#Instalujemy nasz sterownik Selenium
sterownik = webdriver.Chrome(ChromeDriverManager().install())
#Uzyskujemy dostęp do konta placu zabaw OUATH, aby zalogować się do usług Google
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192. .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow”)
#Przed wybraniem elementów za pomocą XPath i wprowadzeniem naszego adresu e-mail, czekamy trochę, aby upewnić się, że renderowanie zostało zakończone.
czas.sen(10)
form1=driver.find_element_by_xpath('//*[@]')
form1.send_keys("<Twój adres e-mail>")
form1.send_keys(Klucze.ENTER)
#To samo tutaj, trochę czekamy, a następnie wprowadzamy nasze hasło.
czas.sen(10)
form2=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
form2.send_keys("<twoje hasło>")
form2.send_keys(Klucze.ENTER)
Następnie możemy uzyskać dostęp do naszego adresu URL Google Search Console:
driver.get('https://search.google.com/search-console?resource_id=twoja_domena”')
czas.sen(5)
box=driver.find_element_by_xpath('/html/body/div[7]/div[2]/header/div[2]/div[2]/div[2]/form/div/div/div/div/div /div[1]/input[2]')
box.send_keys("Twój_URL")
box.send_keys(Klucze.ENTER)
czas.sen(5)
indeksacja = driver.find_element_by_xpath("/html/body/div[7]/c-wiz[2]/div/div[3]/span/div/div[2]/span/div[2]/div/div /div[1]/span/div[2]/div/c-wiz[2]/div[3]/span/div/span/span/div/span/span[1]")
indeksacja.klik()
czas.sen(120)
Niestety, jak wyjaśniono we wstępie, wydaje się, że po wielu żądaniach zaczyna wymagać puzzle captcha, aby kontynuować żądanie indeksowania. Ponieważ metoda automatyczna nie może rozwiązać captcha, jest to coś, co utrudnia to rozwiązanie.
1.1.2. Pingowanie mapy witryny
Adresy URL map witryn można przesyłać do Google za pomocą metody ping. Zasadniczo wystarczy wysłać żądanie do następującego punktu końcowego, wprowadzając adres URL mapy witryny jako parametr:
http://www.google.com/ping?sitemap=URL/of/file
Można to bardzo łatwo zautomatyzować za pomocą Pythona i żądań, jak wyjaśniłem w tym artykule.
importuj urllib.request url = "http://www.google.com/ping?sitemap=https://www.example.com/sitemap.xml" odpowiedź = urllib.request.urlopen(url)
1.1.3. Interfejs API indeksowania Google
Interfejs API indeksowania Google może być dobrym rozwiązaniem do poprawy szybkości indeksowania, ale zwykle nie jest to bardzo skuteczna metoda indeksowania treści, ponieważ powinna być używana tylko wtedy, gdy Twoja witryna zawiera JobPosting lub BroadcastEvent osadzone w VideoObject. Jeśli jednak chcesz to wypróbować i przetestować samodzielnie, możesz wykonać kolejne kroki.
Przede wszystkim, aby rozpocząć korzystanie z tego API, musisz przejść do Google Cloud Console, utworzyć projekt i poświadczenia konta usługi. Następnie musisz włączyć interfejs Indexing API z Biblioteki i dodać konto e-mail podane z danymi logowania konta usługi jako właściciel usługi w Google Search Console. Aby dodać ten adres e-mail jako właściciela usługi, może być konieczne użycie starej wersji Google Search Console.
Po wykonaniu poprzednich kroków będziesz mógł zacząć zlecać indeksowanie i deindeksowanie za pomocą tego interfejsu API, używając następnego fragmentu kodu:
z oauth2client.service_account importuj poświadczenia konta usługi
importuj httplib2
ZAKRESY = [ "https://www.googleapis.com/auth/indexing" ]
PUNKT KOŃCOWY = "https://indexing.googleapis.com/v3/urlNotifications:publikuj"
client_secrets = "ścieżka_do_twojej_poświadczeń.json"
poświadczenia = ServiceAccountCredentials.from_json_keyfile_name(client_secrets, scopes=SCOPES)
jeśli poświadczenia to Brak lub poświadczenia.invalid:
poświadczenia = tools.run_flow(przepływ, przechowywanie)
http = poświadczenia.authorize(httplib2.Http())
list_urls = ["https://www.example.com", "https://www.example.com/test2/"]
dla iteracji w zakresie (len(list_urls)):
zawartość = '''{
'url': "'''+str(list_urls[iteracja])+'''",
„typ”: „URL_UPDATED”
}'''
odpowiedź, treść = http.request(PUNKT KOŃCOWY, metoda="POST", body=treść)
drukuj(odpowiedź)
drukuj (treść)Jeśli chcesz poprosić o deindeksowanie, musisz zmienić typ żądania z „URL_UPDATED” na „URL_DELETED”. Poprzedni fragment kodu wydrukuje odpowiedzi z interfejsu API wraz z czasami powiadomień i ich statusami. Jeśli status wynosi 200, żądanie zostanie wykonane pomyślnie.
1.2. za Bing
Bardzo często, kiedy mówimy o SEO, myślimy tylko o Google, ale nie możemy zapominać, że na niektórych rynkach istnieją inne dominujące wyszukiwarki i/lub inne wyszukiwarki, które mają przyzwoity udział w rynku, jak Bing.
Od samego początku należy wspomnieć, że Bing ma już bardzo wygodną funkcję w Narzędziach Bing dla webmasterów, która w większości przypadków umożliwia zażądanie przesłania nawet 10 000 adresów URL dziennie. Czasami Twój dzienny limit może być niższy niż 10 000 adresów URL, ale możesz poprosić o zwiększenie limitu, jeśli uważasz, że potrzebujesz większego limitu, aby spełnić swoje potrzeby. Więcej na ten temat możesz przeczytać na tej stronie.
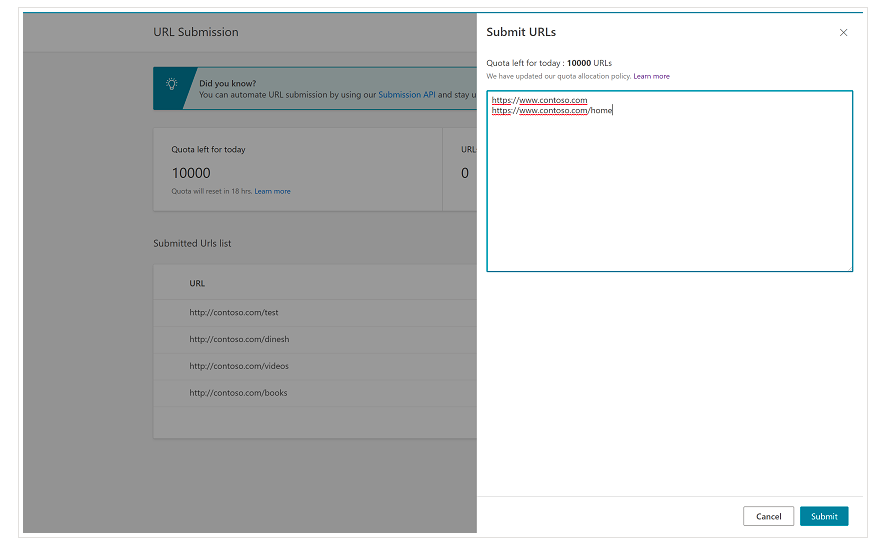
Ta funkcja jest rzeczywiście bardzo wygodna w przypadku zbiorczego przesyłania adresów URL, ponieważ wystarczy wprowadzić adresy URL w różnych wierszach w narzędziu do przesyłania adresów URL z normalnego interfejsu Bing Webmaster Tools.
1.2.1. Interfejs API indeksowania Bing
Interfejs API indeksowania Bing może być używany z kluczem interfejsu API, który należy wprowadzić jako parametr. Ten klucz API można uzyskać w Bing Webmaster Tools, przechodząc do sekcji Dostęp do interfejsu API, a następnie generując klucz API.
Gdy już otrzymamy klucz API, możemy poeksperymentować z API za pomocą następującego fragmentu kodu (wystarczy dodać klucz API i adres URL witryny):
żądania importu
list_urls = ["https://www.przyklad.com", "https://www.przyklad/test2/"]
dla y w list_urls:
url = 'https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=yourapikey'
myobj = '{"siteUrl":"https://www.example.com", "urlList":["'+ str(y) +'"]}'
headers = {'Typ treści': 'aplikacja/json; charset=utf-8'}
x = request.post(url, data=myobj, headers=headers)
print(str(y) + ": " + str(x))Spowoduje to wydrukowanie adresu URL i jego kodu odpowiedzi w każdej iteracji. W przeciwieństwie do Google Indexing API, ten interfejs API może być używany do dowolnego rodzaju witryny.
[Studium przypadku] Zwiększ widoczność, poprawiając indeksowanie witryny przez Googlebota
 Przeczytaj studium przypadku
Przeczytaj studium przypadku2. Analiza, tworzenie i przesyłanie map witryn
Jak wszyscy wiemy, mapy witryn są bardzo przydatnymi elementami, które zapewniają botom wyszukiwarek adresy URL, które mają indeksować. Aby boty wyszukiwarek wiedziały, gdzie znajdują się nasze mapy witryn, należy je przesłać do Google Search Console i Bing Webmaster Tools oraz umieścić w pliku robots.txt dla pozostałych botów.
Dzięki Pythonowi możemy pracować głównie nad trzema różnymi aspektami związanymi z mapami witryn: ich analizą, tworzeniem oraz przesyłaniem i usuwaniem z Google Search Console.
2.1. Importowanie i analiza map witryn za pomocą Pythona
Advertools to świetna biblioteka stworzona przez Eliasa Dabbasa, która może być używana do importowania map witryn, a także wielu innych zadań SEO. Będziesz mógł importować mapy witryn do Dataframes za pomocą:
sitemap_to_df('https://example.com/robots.txt', recursive=False)
Ta biblioteka obsługuje zwykłe mapy witryn XML, mapy witryn wiadomości i mapy witryn wideo.
Z drugiej strony, jeśli interesuje Cię tylko import adresów URL z mapy witryny, możesz również skorzystać z żądań biblioteki i BeautifulSoup.
żądania importu
z bs4 importuj BeautifulSoup
r = request.get("https://www.example.com/twoja_mapa_witryny.xml")
xml = r.tekst
zupa = PięknaZupa(xml)
adresy URL = zupa.find_all("loc")
adresy URL = [[x.text] dla x w adresach URL]
Po zaimportowaniu mapy witryny możesz bawić się wyodrębnionymi adresami URL i przeprowadzić analizę treści, jak wyjaśnił Koray Tugberk w tym artykule.
2.2. Tworzenie map witryn w Pythonie
Możesz także użyć Pythona do tworzenia sitemaps.xml z listy adresów URL, jak wyjaśnił JC Chouinard w tym artykule. Może to być szczególnie przydatne w przypadku bardzo dynamicznych witryn, których adresy URL szybko się zmieniają, a wraz z opisaną powyżej metodą ping może być doskonałym rozwiązaniem, aby zapewnić Google nowe adresy URL i szybko je przeszukiwać i indeksować.
Niedawno Greg Bernhardt stworzył również aplikację ze Streamlit i Python do generowania map witryn.
2.3. Przesyłanie i usuwanie map witryn z Google Search Console
Google Search Console ma interfejs API, którego można używać głównie na dwa różne sposoby: do wyodrębniania danych o wydajności sieci i obsługi map witryn. W tym poście skupimy się na opcji przesyłania i usuwania map witryn.
Po pierwsze, ważne jest, aby utworzyć lub użyć istniejącego projektu z Google Cloud Console, aby uzyskać poświadczenia OUATH i włączyć usługę Google Search Console. JC Chouinard bardzo dobrze wyjaśnia kroki, które należy wykonać, aby uzyskać dostęp do interfejsu API Google Search Console za pomocą Pythona i jak złożyć pierwsze żądanie w tym artykule. W zasadzie możemy w pełni wykorzystać jego kod, ale tylko wprowadzając zmianę, w zakresach dodamy „https://www.googleapis.com/auth/webmasters” zamiast „https://www.googleapis.com /auth/webmasters.readonly”, ponieważ użyjemy interfejsu API nie tylko do odczytu, ale także do przesyłania i usuwania map witryn.

Gdy połączymy się z API, możemy zacząć się z nim bawić i wyświetlić wszystkie mapy witryn z naszych właściwości Google Search Console z kolejnym fragmentem kodu:
dla site_url w Verify_sites_urls:
drukuj (site_url)
# Pobierz listę przesłanych map witryn
mapy witryn = webmasters_service.sitemaps().list(siteUrl=site_url).execute()
jeśli „mapa witryny” w mapach witryn:
sitemap_urls = [s['ścieżka'] dla sw mapach witryn['sitemap']]
drukuj (" " + "\n ".join(sitemap_urls))
Jeśli chodzi o konkretne mapy witryn, możemy wykonać trzy zadania, które omówimy w kolejnych sekcjach: przesyłanie, usuwanie i żądanie informacji.
2.3.1. Przesyłanie mapy witryny
Aby przesłać mapę witryny za pomocą Pythona, wystarczy określić adres URL witryny i ścieżkę mapy witryny oraz uruchomić ten fragment kodu:
STRONA INTERNETOWA = „Twoja własnośćGSC” SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().submit(siteUrl=WITRYNA INTERNETOWA, feedpath=SITEMAP_PATH).execute()
2.3.2. Usuwanie mapy witryny
Drugą stroną medalu jest usunięcie mapy witryny. Możemy również usuwać mapy witryn z Google Search Console za pomocą Pythona, używając metody „usuń” zamiast „prześlij”.
STRONA INTERNETOWA = „Twoja własnośćGSC” SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().delete(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.3. Żądanie informacji z map witryn
Na koniec możemy również zażądać informacji z mapy witryny za pomocą metody „get”.
STRONA INTERNETOWA = „Twoja własnośćGSC” SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().get(siteUrl=WITRYNA INTERNETOWA, feedpath=SITEMAP_PATH).execute()
To zwróci odpowiedź w formacie JSON, takim jak: 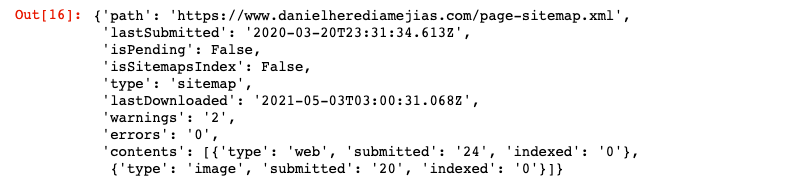
3. Analiza i możliwości powiązań wewnętrznych
Posiadanie odpowiedniej struktury linków wewnętrznych jest bardzo pomocne w ułatwieniu robotom wyszukiwarek indeksowania Twojej witryny. Niektóre z głównych problemów, na które natknąłem się podczas audytu wielu witryn internetowych o bardzo wyrafinowanych ustawieniach technicznych, to:
- Linki wprowadzone w zdarzeniach on-click: w skrócie, Googlebot nie klika przycisków, więc jeśli Twoje linki zostaną wstawione ze zdarzeniem on-click, Googlebot nie będzie mógł ich śledzić.
- Linki renderowane po stronie klienta: pomimo tego, że Googlebot i inne wyszukiwarki stają się coraz lepsze w wykonywaniu JavaScript, wciąż jest to dla nich wyzwaniem, więc znacznie lepiej jest renderować te linki po stronie serwera i wyświetlać je w surowym HTML, aby boty wyszukiwarek, niż oczekują od nich wykonywania skryptów JavaScript.
- Wyskakujące okienka logowania i/lub bramki wiekowej: wyskakujące okienka logowania i bramki wiekowe mogą uniemożliwić robotom wyszukiwarek indeksowanie treści kryjących się za tymi „przeszkodami”.
- Nadużywanie atrybutu nofollow: używanie wielu atrybutów nofollow wskazujących na wartościowe strony wewnętrzne uniemożliwi robotom wyszukiwarek ich indeksowanie.
- Noindex i follow: technicznie kombinacja dyrektyw noindex i follow powinna pozwolić botom wyszukiwarek indeksować linki znajdujące się na tej stronie. Wygląda jednak na to, że Googlebot po pewnym czasie przestaje indeksować strony z dyrektywami noindex.
Dzięki Pythonowi możemy analizować naszą wewnętrzną strukturę linkowania i znajdować nowe możliwości linkowania wewnętrznego w trybie zbiorczym.
3.1. Analiza linków wewnętrznych w Pythonie
Kilka miesięcy temu napisałem artykuł o tym, jak używać Pythona i biblioteki Networkx do tworzenia wykresów, aby wyświetlić wewnętrzną strukturę linków w bardzo wizualny sposób:
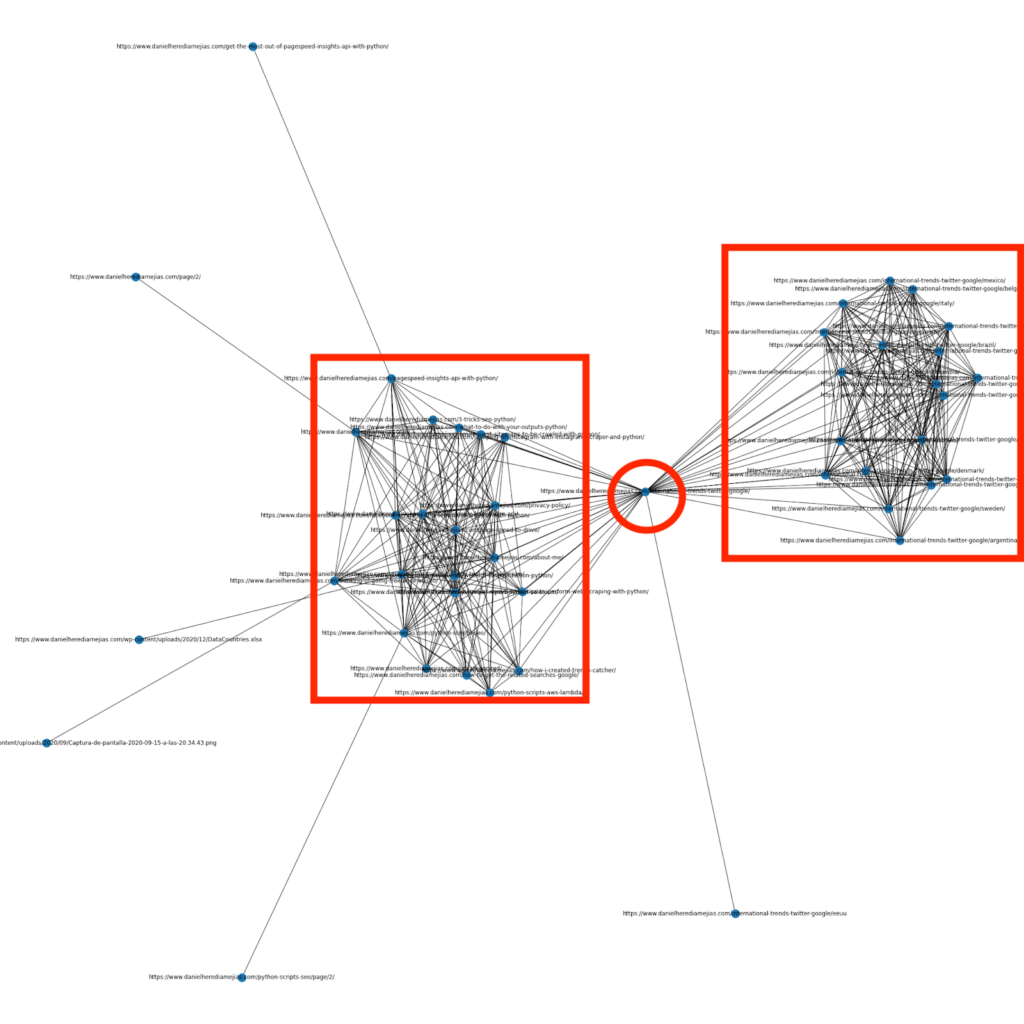
Jest to coś bardzo podobnego do tego, co można uzyskać z Screaming Frog, ale zaletą używania Pythona do tego rodzaju analiz jest to, że zasadniczo możesz wybrać dane, które chcesz uwzględnić w tych wykresach i kontrolować większość elementów wykresu, takich jak jako kolory, rozmiary węzłów, a nawet strony, które chcesz dodać.
3.2. Znajdowanie nowych możliwości wewnętrznych linków za pomocą Pythona
Oprócz analizowania struktur witryn, możesz również skorzystać z Pythona, aby znaleźć nowe możliwości wewnętrznych linków, dostarczając wiele słów kluczowych i adresów URL oraz iterując te adresy URL, wyszukując podane terminy w swoich fragmentach treści.
Jest to coś, co może bardzo dobrze współpracować z eksportami Semrush lub Ahrefs w celu znalezienia potężnych kontekstowych linków wewnętrznych z niektórych stron, które są już w rankingu pod kątem słów kluczowych, a zatem mają już pewien rodzaj autorytetu.
Możesz przeczytać więcej o tej metodzie tutaj.
4. Szybkość witryny, strony 5xx i miękkie strony błędów
Jak stwierdził Google na tej stronie, o tym, co oznacza budżet indeksowania dla Google, przyspieszenie witryny poprawia wrażenia użytkownika i zwiększa szybkość indeksowania. Z drugiej strony istnieją również inne czynniki, które mogą wpływać na budżet indeksowania, takie jak strony z błędami miękkimi, treści o niskiej jakości i duplikaty treści w witrynie.
4.1. Szybkość strony i Python
4.2.1 Analiza szybkości witryny za pomocą Pythona
Interfejs API Page Speed Insights jest bardzo przydatny do analizowania wydajności witryny pod względem szybkości strony i uzyskiwania wielu danych na temat wielu różnych wskaźników szybkości strony (prawie 50) oraz kluczowych wskaźników internetowych.
Praca z Page Speed Insights w Pythonie jest bardzo prosta, do korzystania z niego potrzebny jest tylko klucz API i żądania. Na przykład:
import urllib.request, json url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=your_URL&strategy=mobile&locale=en&key=yourAPIKey" #Pamiętaj, że możesz wstawić swój adres URL z adresem URL parametru, a także zmodyfikować parametr urządzenia, jeśli chcesz uzyskać dane dla komputerów stacjonarnych. odpowiedź = urllib.request.urlopen(url) data = json.loads(response.read())
Ponadto możesz również prognozować za pomocą Pythona i kalkulatora Lighthouse Scoring, jak bardzo ogólny wynik wydajności poprawi się w przypadku wprowadzenia żądanych zmian w celu zwiększenia szybkości strony, jak wyjaśniono w tym artykule.
4.2.2 Optymalizacja obrazu i zmiana rozmiaru za pomocą Pythona
W związku z szybkością strony internetowej, Python może być również używany do optymalizacji, kompresji i zmiany rozmiaru obrazów, jak wyjaśniono w tych artykułach napisanych przez Koraya Tugberka i Grega Bernhardta:
- Zautomatyzuj kompresję obrazu za pomocą Pythona przez FTP.
- Zmieniaj rozmiar obrazów za pomocą Pythona zbiorczo.
- Optymalizuj obrazy za pomocą Pythona pod kątem SEO i UX.
4.2. Wyodrębnianie 5xx i innych błędów kodu odpowiedzi za pomocą Pythona
Błędy kodu odpowiedzi 5xx mogą wskazywać, że Twój serwer nie jest wystarczająco szybki, aby obsłużyć wszystkie otrzymywane żądania. Może to mieć bardzo negatywny wpływ na szybkość indeksowania, a także może zaszkodzić użytkownikowi.
Aby upewnić się, że Twoja witryna działa zgodnie z oczekiwaniami, możesz zautomatyzować pobieranie raportu statystyk indeksowania za pomocą Pythona i Selenium, a także możesz uważnie obserwować swoje pliki dziennika.
4.3. Wyodrębnianie stron błędów miękkich za pomocą Pythona
Niedawno Jose Luis Hernando opublikował artykuł na cześć Hamleta Batisty o tym, jak zautomatyzować wyodrębnianie raportu pokrycia za pomocą Node.js. Może to być niesamowite rozwiązanie do wyodrębnienia stron z błędami miękkimi, a nawet błędów odpowiedzi 5xx, które mogą negatywnie wpłynąć na szybkość indeksowania.
Możemy również powtórzyć ten sam proces w Pythonie, aby skompilować tylko w jednej karcie Excela wszystkie adresy URL podane przez Google Search Console jako błędne, prawidłowe z ostrzeżeniami, prawidłowe i wykluczone.
Najpierw musimy zalogować się do Google Search Console, jak wyjaśniono wcześniej w tym artykule, za pomocą Pythona z Selenium. Następnie wybierzemy wszystkie pola statusu adresu URL, dodamy do 100 wierszy na stronę i zaczniemy iterować wszystkie typy adresów URL zgłaszanych przez GSC i pobierać każdy plik Excel.
czas importu
z selen importu webdriver
z webdriver_manager.chrome import ChromeDriverManager
z selen.webdriver.common.keys importuj klucze
sterownik = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192. .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow”)
czas.sen(5)
searchBox=driver.find_element_by_xpath('//*[@]')
searchBox.send_keys("<Twój adres e-mail>")
searchBox.send_keys(Keys.ENTER)
czas.sen(5)
searchBox=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
searchBox.send_keys("<twoje hasło>")
searchBox.send_keys(Keys.ENTER)
czas.sen(5)
twojadomena = str(input("Wstaw tutaj swoją właściwość http lub domenę. Jeśli jest to domena, dołącz: 'sc-domain':"))
driver.get('https://search.google.com/search-console/index?resource_https://search.google.com/search-console/index?resource_Tabla')
listvalues = [list_problems[x] for i in range(len(df1["URL"]))]
df1['Typ'] = listawartości
lista_wyników = df1.wartości.tolist()
w przeciwnym razie:
df2 = pd.read_excel(twojadomena.replace("sc-domain:","").replace("/","_").replace(":","_") + "-Pokrycie-Drilldown-" + dzisiaj + " (" + str(x) + ").xlsx", 'Tabla')
listvalues = [list_problems[x] for i in range(len(df2["URL"]))]
df2['Typ'] = listawartości
lista_wyników = lista_wyników + df2.wartości.tolist()
df = pd.DataFrame(list_results, columns= ["URL","TimeStamp", "Type"])
df.to_csv('<nazwa pliku>.csv', header=Prawda, indeks=Fałsz, kodowanie = "utf-8")
Ostateczny wynik wygląda następująco: 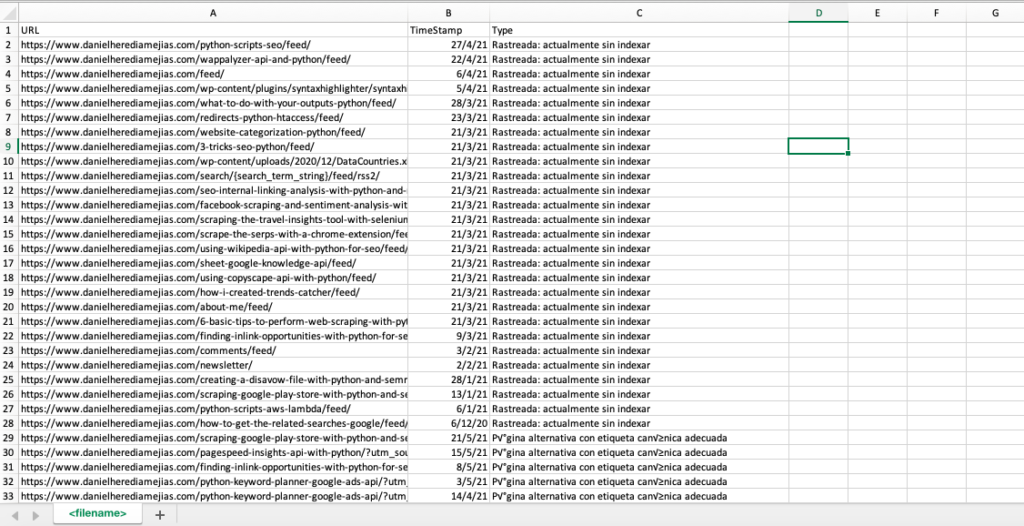
4.4. Analiza pliku dziennika za pomocą Pythona
Oprócz danych dostępnych w raporcie statystyk indeksowania z Google Search Console, możesz także analizować własne pliki za pomocą Pythona, aby uzyskać znacznie więcej informacji o tym, jak boty wyszukiwarek indeksują Twoją witrynę. Jeśli nie korzystasz jeszcze z analizatora logów do SEO, możesz przeczytać ten artykuł z SEO Garden, w którym wyjaśniono analizę logów za pomocą Pythona.
[Ebook] Cztery przypadki użycia do wykorzystania analizy dzienników SEO
Pobierz za darmo5. Wnioski końcowe
Widzieliśmy, że Python może być wspaniałym atutem do analizowania i ulepszania przeszukiwania i indeksowania naszych stron internetowych na wiele różnych sposobów. Zobaczyliśmy również, jak znacznie ułatwić życie, automatyzując większość żmudnych i ręcznych zadań, które wymagałyby tysięcy godzin twojego czasu.
Muszę powiedzieć, że niestety nie jestem w pełni przekonany do rozwiązań, które w tej chwili oferuje Google do żądania indeksowania dużej liczby adresów URL, chociaż do pewnego stopnia rozumiem jego obawy przed zaoferowaniem lepszego rozwiązania: wielu SEO może mieć tendencję nadużywać go.
W przeciwieństwie do tego istnieje Bing, który oferuje wyjątkowe i wygodne rozwiązania umożliwiające żądanie indeksowania adresów URL przez API, a nawet przez normalny interfejs w Narzędziach dla webmasterów Bing.
Ze względu na to, że interfejs API indeksowania Google ma miejsce na ulepszenia, inne elementy, takie jak dostępna i zaktualizowana mapa witryny, wewnętrzne linki, szybkość strony, strony z miękkimi błędami oraz duplikaty i treści o niskiej jakości stają się jeszcze ważniejsze, aby zapewnić że Twoja witryna jest prawidłowo zindeksowana, a najważniejsze strony są zaindeksowane.