
10 typowych technicznych problemów SEO – i jak je rozpoznać
Opublikowany: 2019-06-04Realizując usługi SEO w wielu branżach, czasami jesteś w stanie wychwycić typowe problemy, zwłaszcza podczas pracy na wspólnym CMS, takim jak WordPress, Shopify lub SquareSpace.
Tutaj przedstawiłem 10 dość typowych technicznych problemów SEO, na które możesz natknąć się podczas optymalizacji witryny.
Nie mówię, że te kwestie na pewno będą problematyczne dla Ciebie lub Twojego klienta – bardzo często kontekst jest nadal bardzo ważny. Nie zawsze istnieje rozwiązanie uniwersalne dla wszystkich, ale prawdopodobnie nadal dobrze jest uważać na scenariusze opisane poniżej.
1 – Plik Robots.txt blokujący dostęp do Googlebota
Nie jest to nic nowego dla większości technicznych SEO, ale nadal bardzo łatwo jest zaniedbywać sprawdzanie pliku robots – i to nie tylko w momencie przeprowadzania audytu technicznego, ale jako kontrola cykliczna.
Możesz użyć narzędzia takiego jak Search Console (stara wersja), aby sprawdzić, czy Google ma problemy z dostępem, lub możesz po prostu spróbować zaindeksować swoją witrynę jako Googlebot za pomocą narzędzia takiego jak OnCrawl (wystarczy wybrać jego klienta użytkownika). OnCrawl będzie przestrzegać pliku robots.txt, chyba że powiesz inaczej.
Wyeksportuj wyniki indeksowania i porównaj je ze znaną listą stron w Twojej witrynie i sprawdź, czy nie ma martwych punktów robota.
Aby pokazać, że nadal zdarza się to dość często i w przypadku niektórych dość dużych witryn, kilka tygodni temu zauważyłem, że narzędzie Pingdom's Speed Test zostało zablokowane w Google.
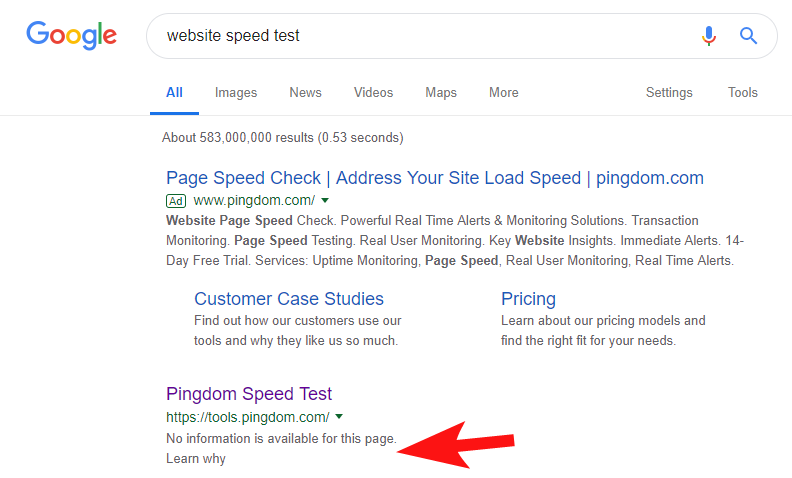
Przeglądanie ich pliku robotów (a następnie próbowanie indeksowania ich strony z OnCrawl jako Googlebot) potwierdziło moje podejrzenia, że blokują dostęp do swojej witryny.
Winny plik robots.txt jest pokazany poniżej:

Skontaktowałem się z nimi z „FYI”, ale nie otrzymałem odpowiedzi, ale kilka dni później zobaczyłem, że wszystko wróciło do normy. Uff – znów mogłem spokojnie spać!
W ich przypadku wydawało się, że za każdym razem, gdy skanujesz swoją witrynę w ramach audytu szybkości, tworzył adres URL zawierający zahaszowany znak wyróżniony w powyższym pliku robots.
Być może były one w jakiś sposób indeksowane, a nawet indeksowane, a oni chcieli to kontrolować (co byłoby bardzo zrozumiałe). W tym przypadku prawdopodobnie nie przetestowali w pełni potencjalnego wpływu – który ostatecznie był prawdopodobnie minimalny.
Oto ich obecne roboty dla wszystkich zainteresowanych.

Warto zauważyć, że w niektórych przypadkach dostęp do historycznych zmian w pliku robots.txt można uzyskać za pomocą Internet Wayback Machine. Z mojego doświadczenia wynika, że działa to najlepiej na większych witrynach, jak możesz sobie wyobrazić – są one znacznie częściej indeksowane przez archiwizator Wayback Machine.
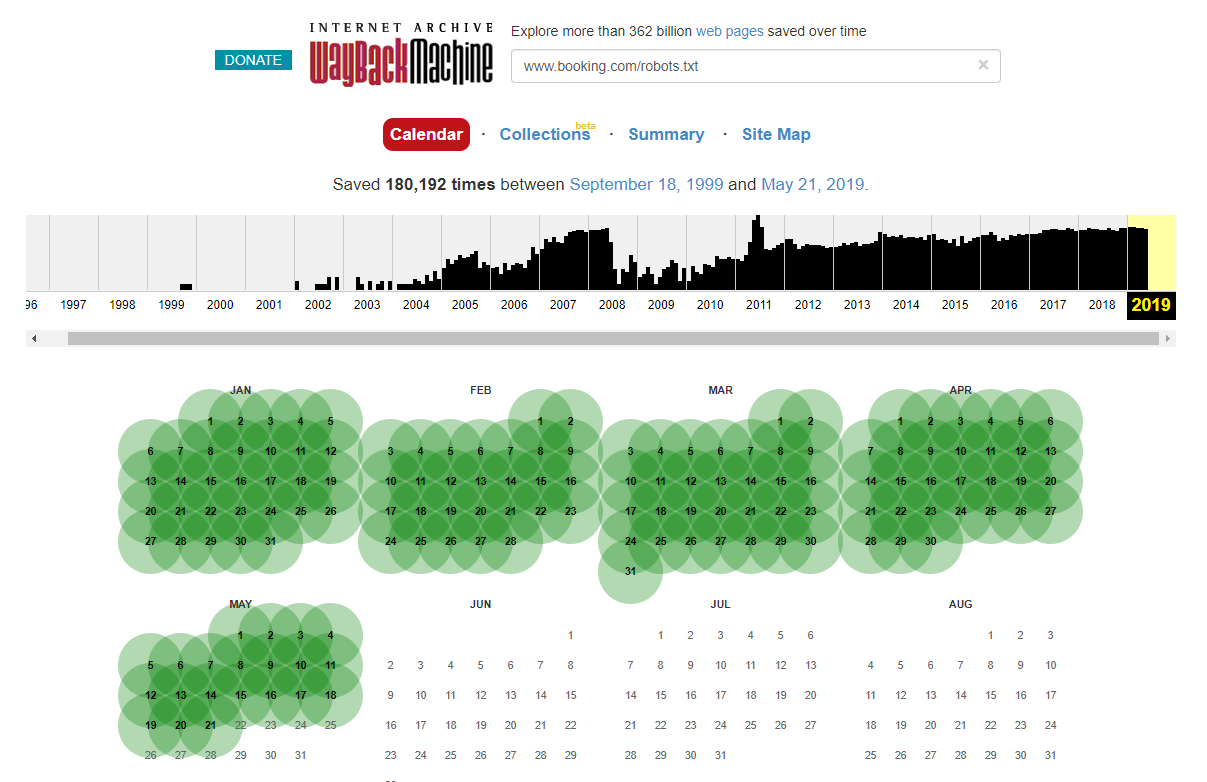
To nie pierwszy raz, kiedy widzę plik robots.txt na żywo na wolności, powodujący trochę spustoszenia w SERPS. I na pewno nie ostatni – to taka prosta rzecz do zaniedbania (w końcu to dosłownie jeden plik), ale sprawdzenie go powinno być częścią bieżącego harmonogramu pracy każdego SEO.
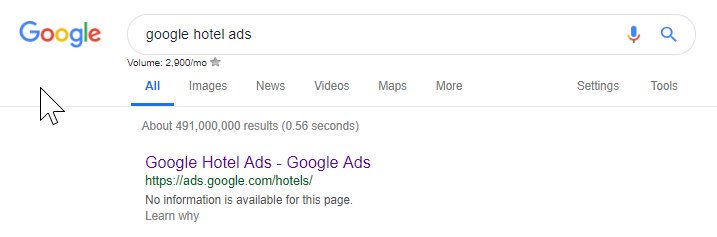
Z powyższego widać, że nawet Google czasami psuje plik robotów, blokując sobie dostęp do ich treści. Mogło to być celowe, ale patrząc na język ich pliku robotów poniżej, jakoś w to wątpię.
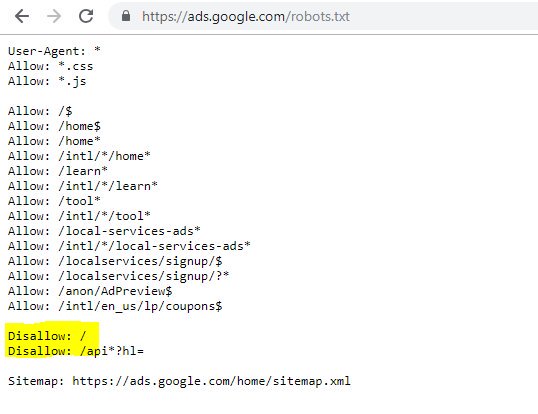
Podświetlony Disallow: / w tym przypadku uniemożliwiał dostęp do dowolnych ścieżek URL; bezpieczniej byłoby wymienić określone sekcje witryny, których nie należy indeksować.
2 – Problemy z konfiguracją domeny na poziomie DNS
Jest to zaskakująco powszechne, ale zwykle jest to szybkie rozwiązanie. Jest to jedna z tych tanich, *potencjalnie* znaczących zmian SEO, które uwielbiają techniczne SEO.
Często przy implementacjach SSL nie widzę poprawnie skonfigurowanej wersji domeny innej niż WWW, takiej jak przekierowanie 302 do następnego adresu URL i utworzenie łańcucha lub w najgorszym przypadku brak ładowania w ogóle.
Dobrym przykładem jest tutaj strona internetowa Hotel Football.
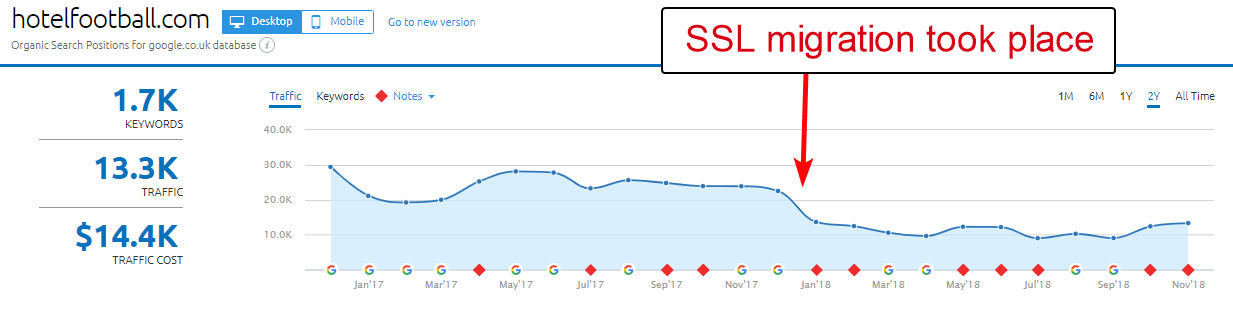
Przeszli migrację SSL na początku zeszłego roku, co nie okazało się dla nich tak dobre, sądząc z powyższego raportu przeglądu domen SEMRush.
Zauważyłem to jakiś czas temu, ponieważ dużo pracowałem w branży turystycznej i hotelarskiej – iz wielką miłością do piłki nożnej chciałem zobaczyć, jak wygląda ich strona internetowa (oraz jak radziła sobie naturalnie! ).
Właściwie było to bardzo łatwe do zdiagnozowania – strona miała mnóstwo bardzo dobrych linków zwrotnych, z których wszystkie wskazywały na nie-SSL, domenę WWW pod adresem http://www.hotelfootball.com/
Jeśli jednak spróbujesz uzyskać dostęp do powyższego adresu URL, nie zostanie on załadowany. Ups. I tak jest przynajmniej od około 18 miesięcy. Skontaktowałem się z agencją zarządzającą witryną za pośrednictwem Twittera, aby poinformować ich o tym, ale nie otrzymałem odpowiedzi.
W tym przypadku wszystko, co muszą zrobić, to upewnić się, że ustawienia strefy DNS są poprawne, z rekordem „A” dla wersji domeny „WWW”, który wskazuje na prawidłowy adres IP (działałoby również CNAME). Zapobiegnie to nierozpoznawaniu domeny.
Jedynym minusem lub powodem, dla którego rozwiązanie tego zajmuje tak dużo czasu, jest to, że uzyskanie dostępu do panelu zarządzania domeną witryny może być trudne, a nawet utrata haseł lub brak postrzegania tego jako wysokiego priorytetu.
Wysyłanie instrukcji naprawy osobie nie posiadającej klucza do nazwy domeny również nie zawsze jest dobrym pomysłem.
Bardzo chciałbym zobaczyć organiczny wpływ, jeśli/kiedy będą w stanie dokonać powyższej korekty – zwłaszcza biorąc pod uwagę wszystkie linki zwrotne, które zbudowała domena nie WWW od czasu uruchomienia hotelu przez byłych piłkarzy Manchesteru United, Gary'ego Neville'a, Ryana Giggsa i firmy.
Chociaż zajmują pierwsze miejsce w Google pod względem nazwy hotelu (jak można sobie wyobrazić), nie wydają się wcale mieć mocnych pozycji w żadnym z bardziej konkurencyjnych wyszukiwanych haseł niemarkowych (obecnie zajmują pozycję 10. w Google dla „hotelu w pobliżu Old Trafford”).
Z powyższym strzelili trochę samobójczego gola – ale naprawienie tego problemu może przynajmniej w jakiś sposób rozwiązać ten problem.
Robot SEO Oncrawl
 Ucz się więcej
Ucz się więcej3 – Nieuczciwe strony w mapie witryny XML
Znowu jest to dość podstawowe, ale jest dziwnie powszechne – po przejrzeniu mapy witryny XML witryny (która prawie zawsze znajduje się pod adresem domain.com/sitemap.xml lub domain.com/sitemap_index.xml, mogą pojawić się tutaj strony, które naprawdę nie wymagają indeksowania.
Typowymi winowajcami są ukryte strony z podziękowaniami (dzięki za przesłanie formularza kontaktowego), strony docelowe PPC, które mogą powodować zduplikowane problemy z treścią lub inne formy stron/postów/taksonomii, których nie zindeksowałeś już gdzie indziej.
Ponowne uwzględnienie ich w mapie witryny XML może wysyłać sprzeczne sygnały do wyszukiwarek – naprawdę powinieneś wymieniać tylko te strony, które chcesz znaleźć i zindeksować, co jest głównie punktem mapy witryny.
Możesz teraz skorzystać z przydatnego raportu w Search Console, aby sprawdzić, czy strony zostały uwzględnione w mapie witryny XML witryny za pomocą opcji Sprawdź adres URL.
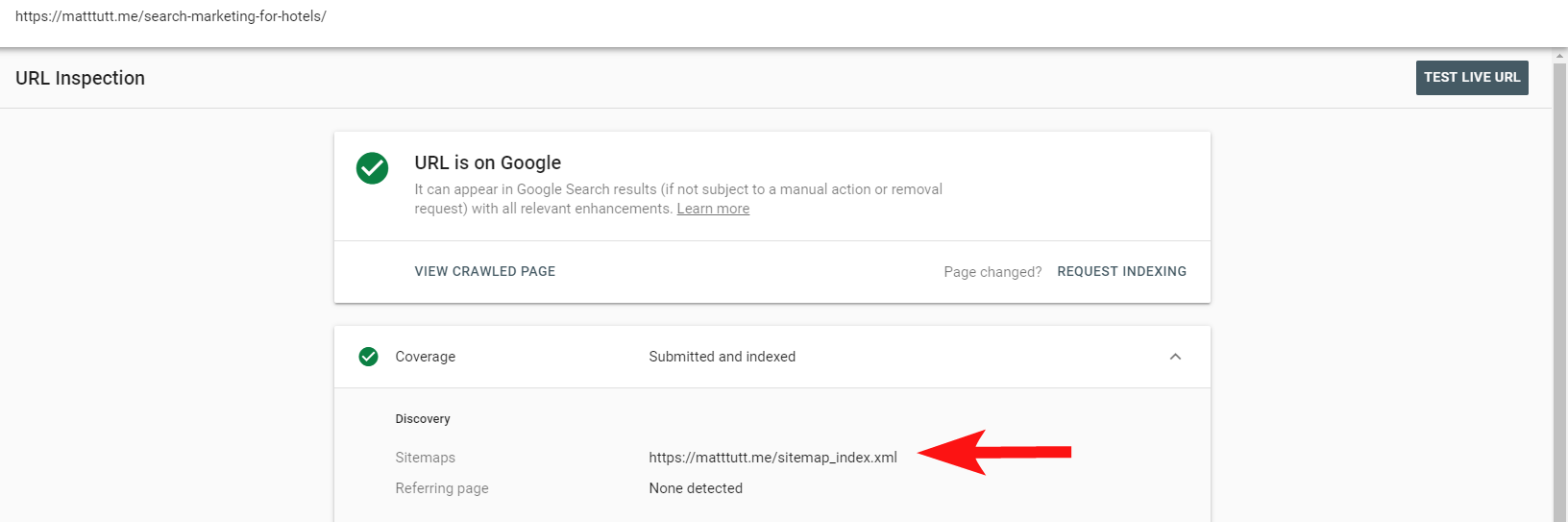
Jeśli masz dość małą witrynę, prawdopodobnie możesz po prostu ręcznie przejrzeć mapę witryny XML w przeglądarce – w przeciwnym razie pobierz ją i porównaj z pełnym indeksowaniem indeksowanych adresów URL.
Często można wyłapać tego rodzaju bezcenne treści niskiej jakości, przeprowadzając wyszukiwanie site:domena.com w Google, aby zwrócić wszystko, co zostało zaindeksowane.
Warto tutaj zauważyć, że może on zawierać stare treści i nie należy polegać na tym, że jest w 100% aktualny, ale jest to łatwy sposób na sprawdzenie, czy nie ma dużej ilości treści, które nadymają Twoje wysiłki SEO i pochłaniają budżety indeksowania.
4 – Problemy z renderowaniem treści przez Googlebota
Ten jest wart całego poświęconego mu artykułu i osobiście czuję, że spędziłem całe życie bawiąc się narzędziem Google do pobierania i renderowania.
Wiele już powiedziano na ten temat (i o JavaScript) przez bardzo zdolnych SEO, więc nie będę się w to zagłębiać, ale sprawdzenie, jak Googlebot renderuje Twoją witrynę, zawsze będzie warte twojego czasu.
Przeprowadzenie kilku kontroli za pomocą narzędzi online może pomóc w wykryciu martwych punktów Googlebota (obszarów w witrynie, do których nie mają one dostępu), problemów ze środowiskiem hostingu, problematycznego kodu JavaScript spalającego zasoby, a nawet problemów ze skalowaniem ekranu.
Zwykle te narzędzia innych firm są bardzo pomocne w diagnozowaniu problemu (Google mówi nawet, kiedy zasób jest zablokowany na przykład z powodu pliku robota), ale czasami możesz znaleźć się w kółko.
Aby pokazać na żywo przykład problematycznej witryny, strzelę sobie w stopę i odwołam się do mojej osobistej witryny – i szczególnie frustrującego motywu WordPress, którego używam.
Czasami podczas sprawdzania adresów URL w Search Console otrzymuję ostrzeżenie „Strona nie jest przyjazna dla urządzeń mobilnych” (patrz poniżej).
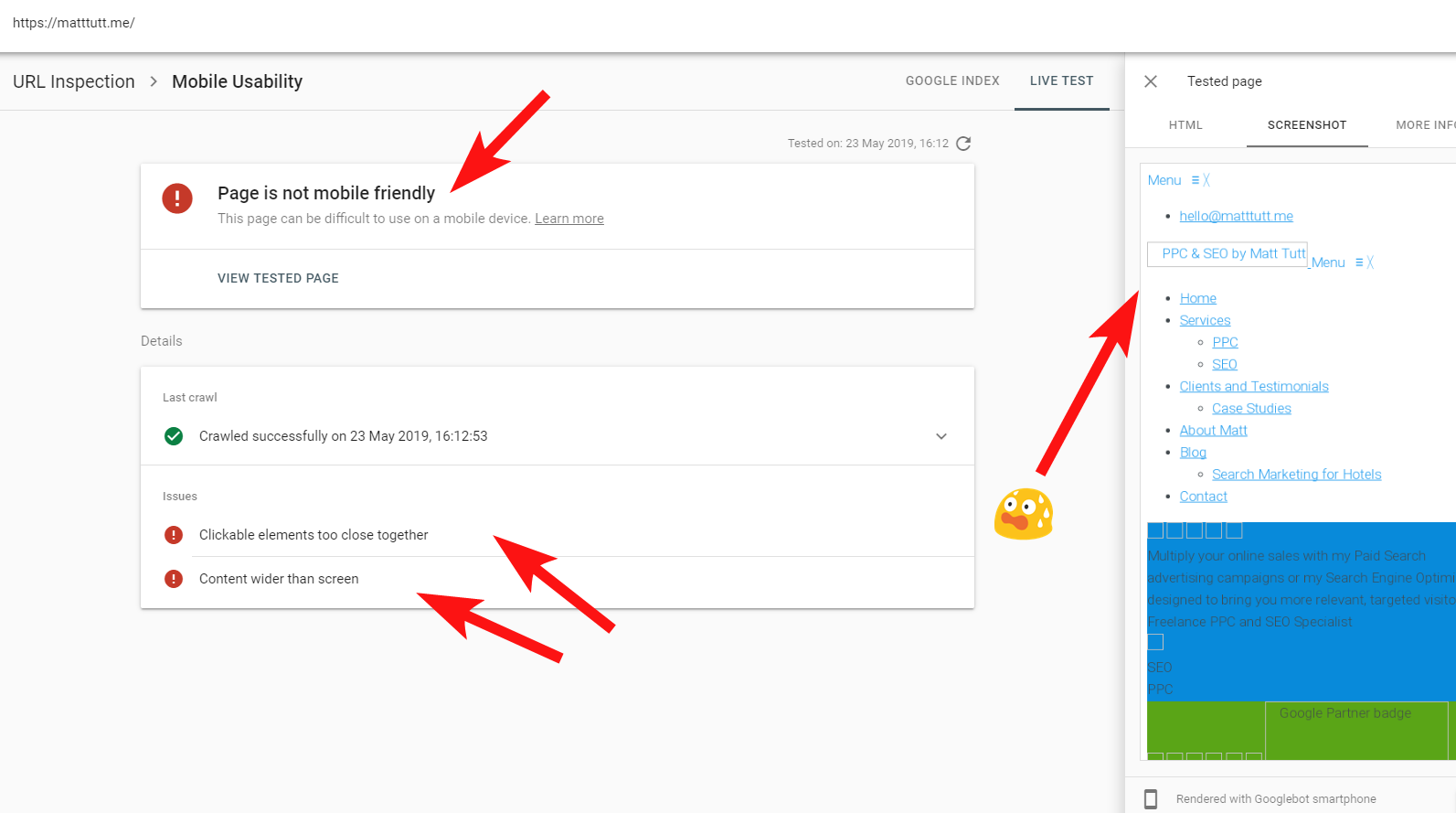
Po kliknięciu karty Więcej informacji (w prawym górnym rogu) wyświetla się lista zasobów, do których Googlebot nie mógł wtedy uzyskać dostępu, czyli głównie CSS i pliki graficzne.
Jest tak prawdopodobnie, ponieważ Googlebot nie zawsze jest w stanie zapewnić sobie pełną „energię” do renderowania strony – czasami dzieje się tak dlatego, że Google obawia się awarii mojej witryny (co jest rodzajem ich), a innym razem mogę mieć ograniczenia, ponieważ używali dużo zasobów do pobrania i renderowania mojej witryny.
Czasami w związku z powyższym warto przeprowadzić te testy kilka razy w rozłożonych odstępach czasu, aby uzyskać prawdziwszą historię. Zalecam również sprawdzenie dzienników serwera, jeśli możesz, aby sprawdzić, w jaki sposób Googlebot uzyskał (lub nie uzyskał) dostępu do zawartości Twojej witryny.
404 lub inne złe statusy dla tych zasobów byłyby wyraźnie złym znakiem, zwłaszcza jeśli są spójne.
W moim przypadku Google zwraca uwagę na to, że witryna nie jest przyjazna dla urządzeń mobilnych, co jest głównie wynikiem awarii niektórych plików stylu CSS podczas renderowania, co może słusznie wydawać dzwonki alarmowe.
Aby sprawy były jeszcze bardziej zagmatwane, podczas uruchamiania Testu optymalizacji mobilnej przez Google lub podczas korzystania z dowolnego narzędzia innej firmy nie są wykrywane żadne problemy: witryna jest przyjazna dla urządzeń mobilnych.
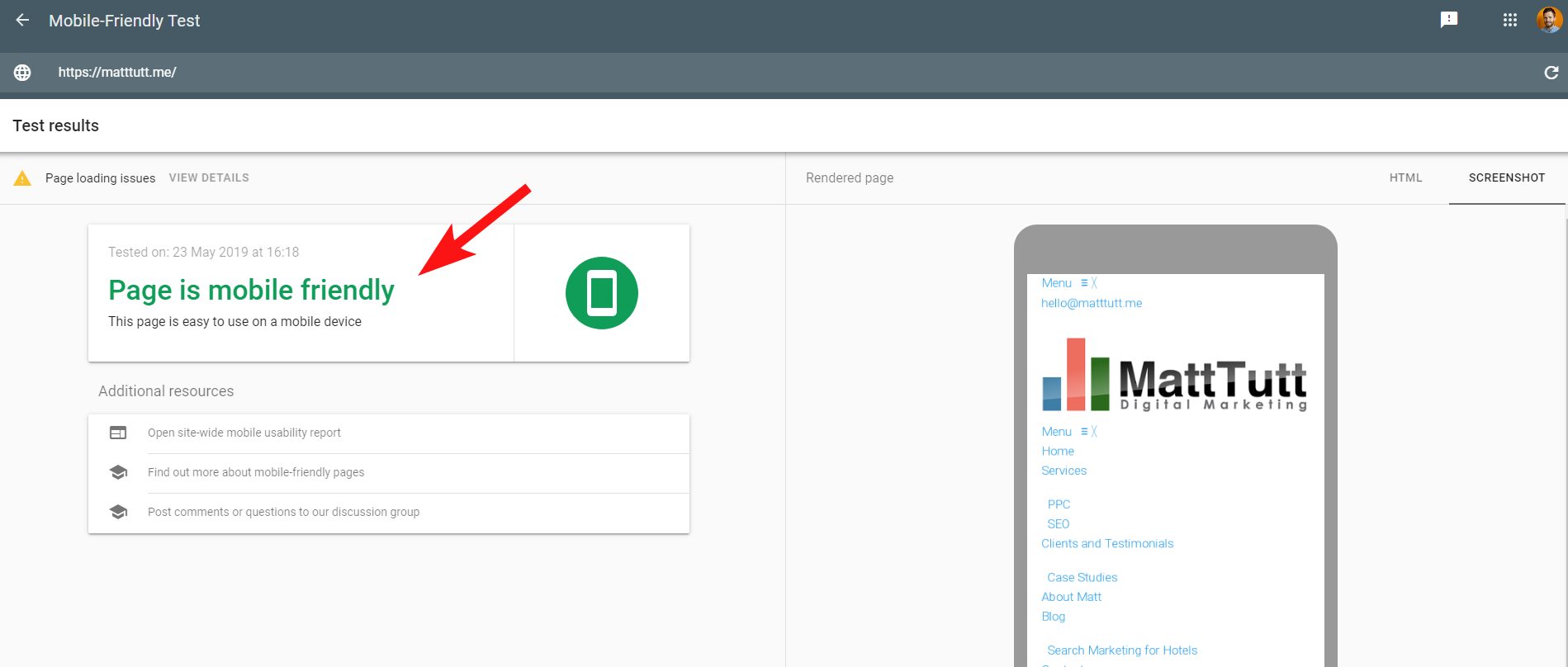
Te sprzeczne wiadomości od Google mogą być trudne do odszyfrowania dla SEO i twórców stron internetowych. Aby lepiej zrozumieć, skontaktowałem się z Johnem Muellerem, który zasugerował, abym sprawdził mojego hosta internetowego (bez problemów) i że plik CSS może być rzeczywiście buforowany przez Google.
Search Console używa starszej usługi renderowania stron internetowych (WRS) w porównaniu do narzędzia przyjaznego dla urządzeń mobilnych, więc obecnie przywiązuję większą wagę do tego drugiego.
Ponieważ Google ogłasza nowszego Googlebota z najnowszymi możliwościami renderowania, wszystko to może ulec zmianie, dlatego warto być na bieżąco z narzędziami, które najlepiej wykorzystać do renderowania kontroli.
Kolejna wskazówka – jeśli chcesz zobaczyć renderowaną stronę z możliwością przewijania, możesz przełączyć się na kartę HTML z narzędzia Google do testowania urządzeń mobilnych, nacisnąć CTRL+A, aby podświetlić cały wyrenderowany kod HTML, a następnie skopiować i wkleić do edytora tekstu i zapisz jako plik HTML.
Otwarcie tego w przeglądarce (ze skrzyżowanymi palcami, czasami zależy to od używanego CMS!) da Ci przewijalny render. Zaletą tego jest to, że możesz sprawdzić, jak renderuje się dowolna witryna – nie potrzebujesz dostępu do Search Console.
5 – Zhakowane strony i spamerskie linki zwrotne
Jest to całkiem zabawne i często można zakraść się na strony działające na starszych wersjach WordPressa lub innych platformach CMS, które wymagają regularnych aktualizacji zabezpieczeń.
W przypadku tego klienta (spa kosmetycznego) zauważyłem dziwne wyszukiwane hasła pojawiające się w Search Console.
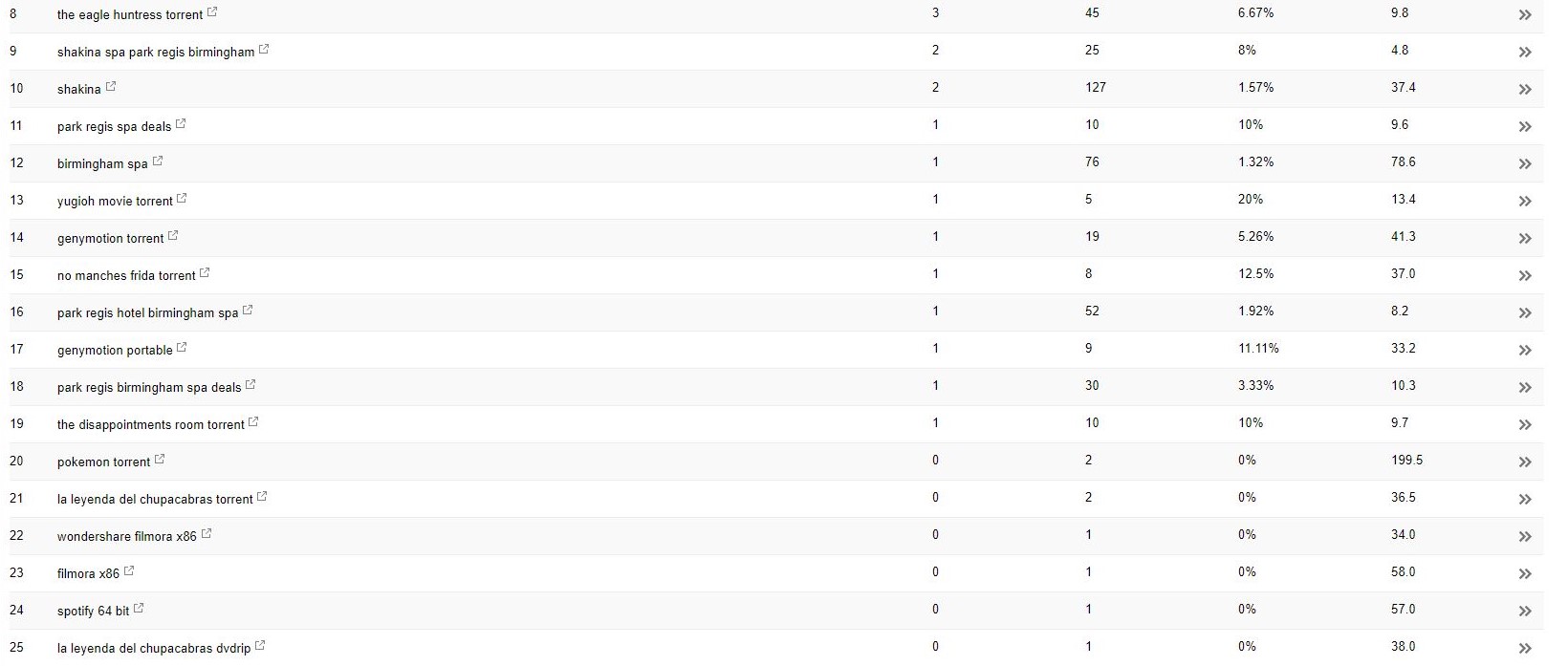
Co zaskakujące, nie tylko mieli wyświetlenia w Search Console, ale także kliknięcia – co oznacza, że coś musiało zostać zaindeksowane w domenie.
Sądząc po zapytaniach, było to wyraźnie spamerskie, a nie coś, z czym klient chciałby powiązać swoją działalność.
Przeprowadzenie prostego wyszukiwania „site:domena.com” w Google odkryło setki stron rzekomych torrentów, które klient rzekomo hostował na swojej stronie.
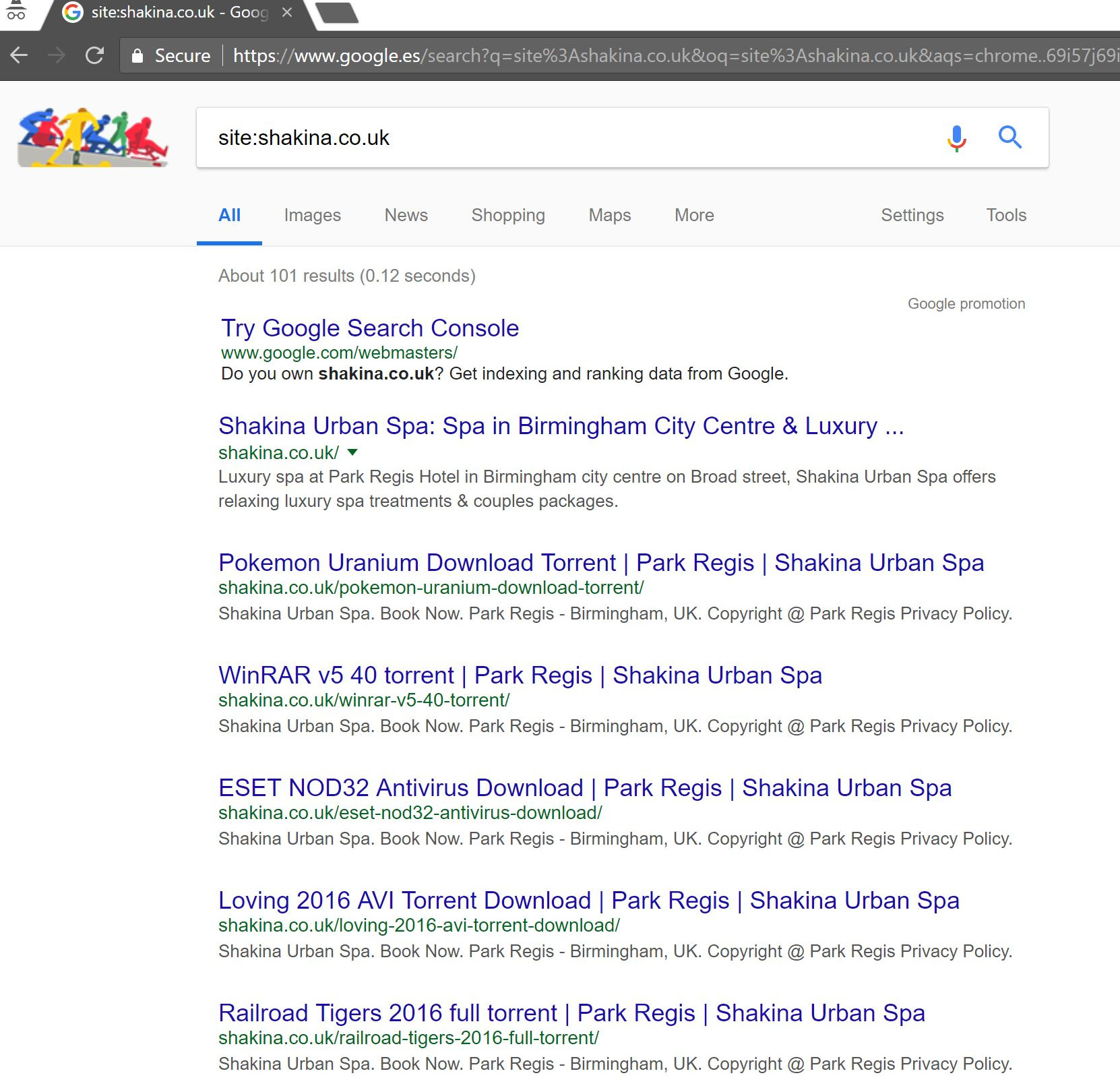
Odwiedzenie dowolnego z tych adresów URL faktycznie spowodowało błąd 404 – ale nadal były one indeksowane (sprawdzałem również różnych agentów użytkownika i wszyscy otrzymali ten sam błąd 404).
Następnie przepuściłem domenę przez narzędzie do sprawdzania linków zwrotnych Majestic i dało to długą listę bardzo niskiej jakości linków zwrotnych wskazujących na te strony w witrynach klientów – co prawdopodobnie pomogło w ich zindeksowaniu.
Spojrzenie na Anchor Cloud firmy Majestic z linkami zwrotnymi naprawdę pokazało zakres problemu.


Jedyną poprawką było zrzeczenie się wszystkich tych linków zwrotnych według domeny, a następnie przeprowadzenie czystego przeglądu instalacji WordPressa w nadziei na usunięcie wszelkich wstrzykniętych kodu lub zainstalowanie nowej kopii WordPressa.
Jeśli naprawdę martwisz się zindeksowaną treścią w przypadkach takich jak ten powyżej, możesz również podać kod stanu 410, aby naprawdę wyjaśnić sprawy robotom wyszukiwania.
Powyższe byłoby odpowiednie dla tych witryn, które otrzymały ostrzeżenia prawne z powodu roszczeń dotyczących praw autorskich ze strony producentów filmowych – co może czasami wystąpić w takich sytuacjach, jeśli problem nie zostanie szybko rozwiązany.
6 – Złe międzynarodowe ustawienia SEO
Ponieważ mieszkam w Hiszpanii, ale przeglądam Internet w moim ojczystym języku angielskim, często jestem automatycznie przekierowywany do hiszpańskiej wersji strony internetowej.
Chociaż rozumiem logikę (mieszkam w Hiszpanii, dlatego chcę przeglądać witrynę w języku hiszpańskim), jest to dość denerwujące z punktu widzenia użytkownika, a jeśli nie zostanie zrobione poprawnie, może również spowodować trochę spustoszenia w międzynarodowym SEO.
Witryny takie jak Google Ads przenoszą to na inny poziom – wykorzystując Angular JavaScript do dynamicznego generowania treści na podstawie mojej lokalizacji, nawet nie przechodząc przez żadne przekierowanie strony i ładując treść bezpośrednio w DOM.
Moją preferowaną metodą wyboru, gdy dostępnych jest wiele języków, jest przekierowanie użytkownika 302 do języka w oparciu o ustawienia przeglądarki internetowej.
Dlatego jeśli ktoś używa niemieckiego jako domyślnego języka w Google Chrome, prawdopodobnie bez problemu czyta witrynę po niemiecku, niezależnie od swojej fizycznej lokalizacji.
Pomaga to również w poruszaniu się po trudnościach, gdy ktoś mieszka w regionie, w którym mówi się różnymi językami, na przykład w Szwajcarii, gdzie używany jest francuski, włoski, niemiecki i retoromański.
Jest to również kluczowe ze względu na użyteczność, aby zapewnić opcję przełączania języków w zależności od preferencji — na wypadek, gdyby chcieli się przełączyć.
W jednym przypadku pracowałem z hotelem w Barcelonie, gdzie skrypt przekierowania języka JavaScript został dodany do witryny bez uwzględnienia wpływu SEO.
Ten skrypt przekierowywał użytkowników na podstawie ustawień języka przeglądarki (co samo w sobie nie jest takie złe) za pośrednictwem przekierowania JavaScript po stronie klienta.
Niestety w tym przypadku skrypt nie został poprawnie skonfigurowany ze względu na dziwną konfigurację permalinków witryn, a w połączeniu z brakiem tagu HTML lang na wszystkich stronach w witrynie, Googlebot trochę zwariował…
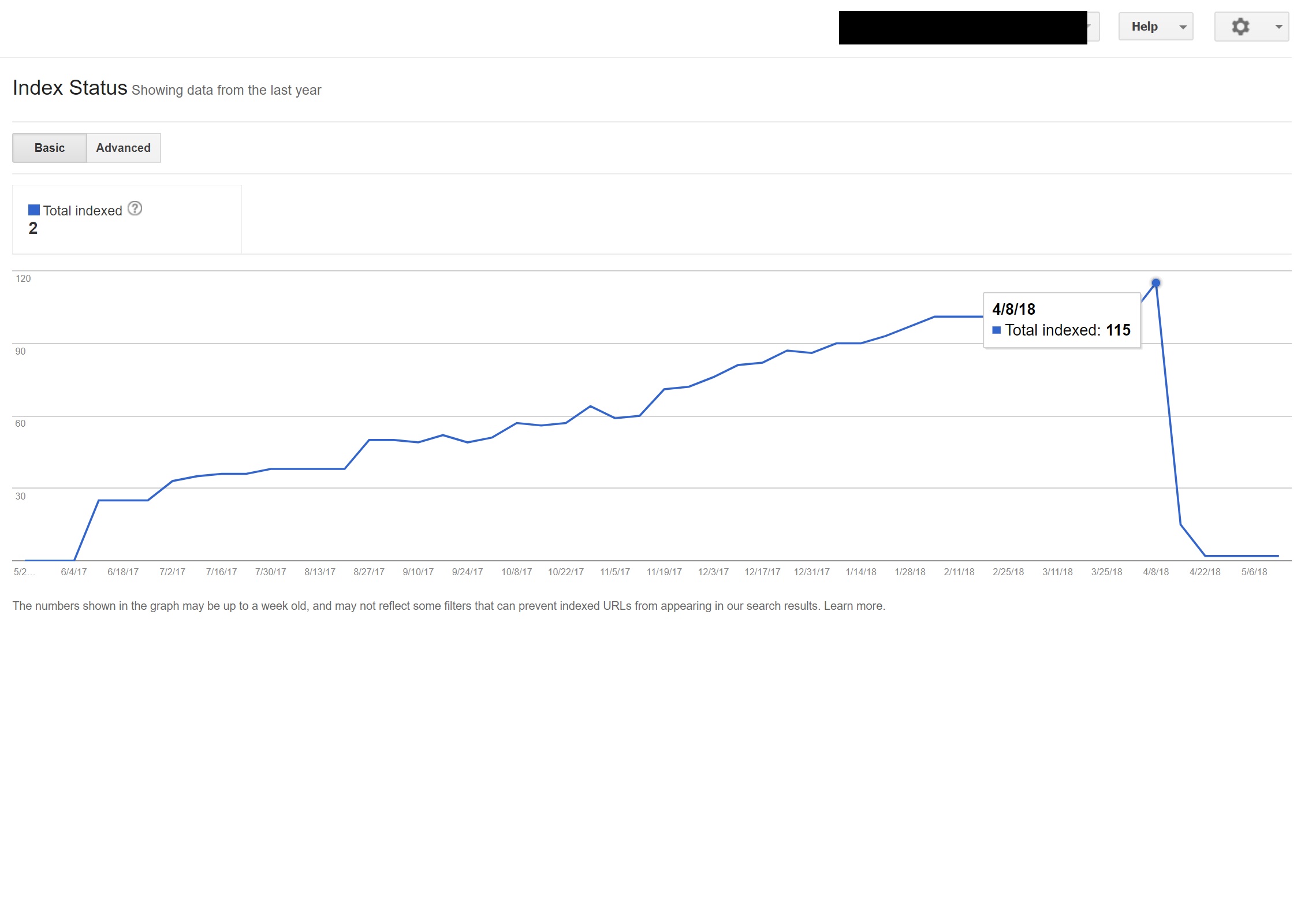
W tym przykładzie prawie cała zawartość witryny w języku innym niż angielski została zdeindeksowana przez Google, ponieważ była przekierowywana na strony, które nie istniały, co powodowało wyświetlanie wielu błędów 404.
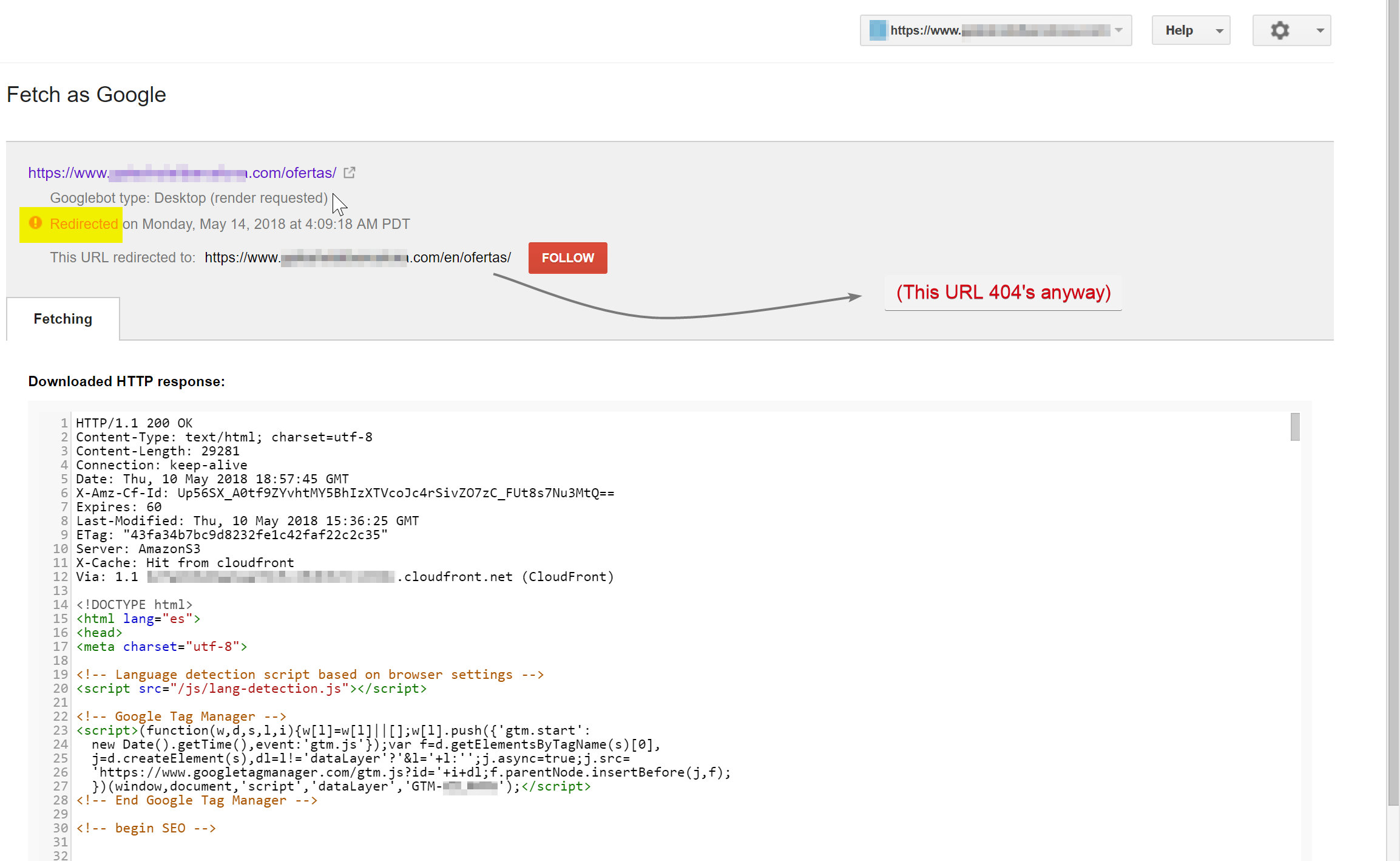
Googlebot próbował zindeksować hiszpańską treść (która istniała pod adresem nazwa_hotelu.com/ofertas) i został przekierowany do nazwa_hotelu.com/pl/ofertas – nieistniejący adres URL.
Co zaskakujące, w tym przypadku Googlebot śledził wszystkie te przekierowania JavaScript, a ponieważ nie mógł znaleźć tych adresów URL, był zmuszony usunąć je ze swojego indeksu.
W powyższym przypadku udało mi się to potwierdzić, uzyskując dostęp do dzienników serwera witryny, filtrując do Googlebota i sprawdzając, gdzie są obsługiwane kody 404.
Usunięcie wadliwego skryptu przekierowującego JavaScript rozwiązało problem i na szczęście przetłumaczone strony nie były długo deindeksowane.
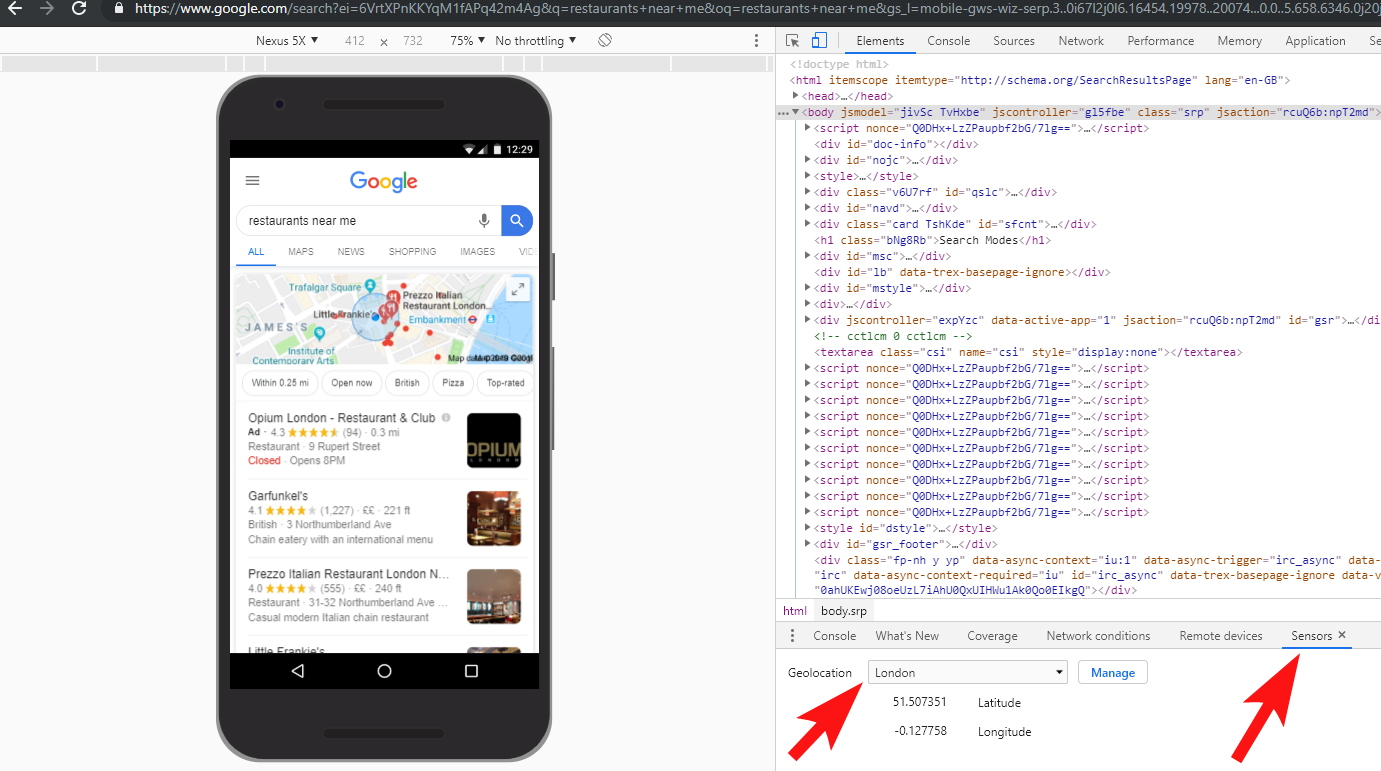
Zawsze dobrze jest w pełni przetestować różne rzeczy — inwestycja w VPN może pomóc zdiagnozować tego typu scenariusze, a nawet zmienić lokalizację i/lub język w przeglądarce Chrome.
[Studium przypadku] Obsługa wielu audytów witryn
 Przeczytaj studium przypadku
Przeczytaj studium przypadku7 – Zduplikowana treść
Zduplikowana treść to dość powszechny i dobrze omawiany problem, a istnieje wiele sposobów na sprawdzenie, czy w witrynie nie ma zduplikowanych treści – Richard Baxter napisał niedawno świetny artykuł na ten temat.
W moim przypadku sprawa jest prawdopodobnie trochę prostsza. Regularnie widuję witryny publikujące świetne treści, często w formie postów na blogu, a potem niemal natychmiast udostępniające te treści w witrynie innej firmy, takiej jak Medium.com.
Medium to świetna witryna do zmiany przeznaczenia istniejących treści w celu dotarcia do szerszej publiczności, ale należy zachować ostrożność przy podejściu do tego.
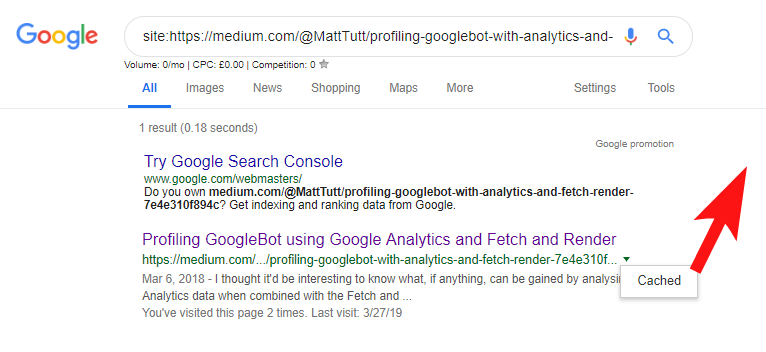
Podczas importowania treści z WordPressa na Medium, podczas tego procesu Medium użyje adresu URL Twojej witryny jako znacznika kanonicznego. Tak więc teoretycznie powinno pomóc w przyznaniu swojej witrynie zasługi za treść, jako oryginalne źródło.
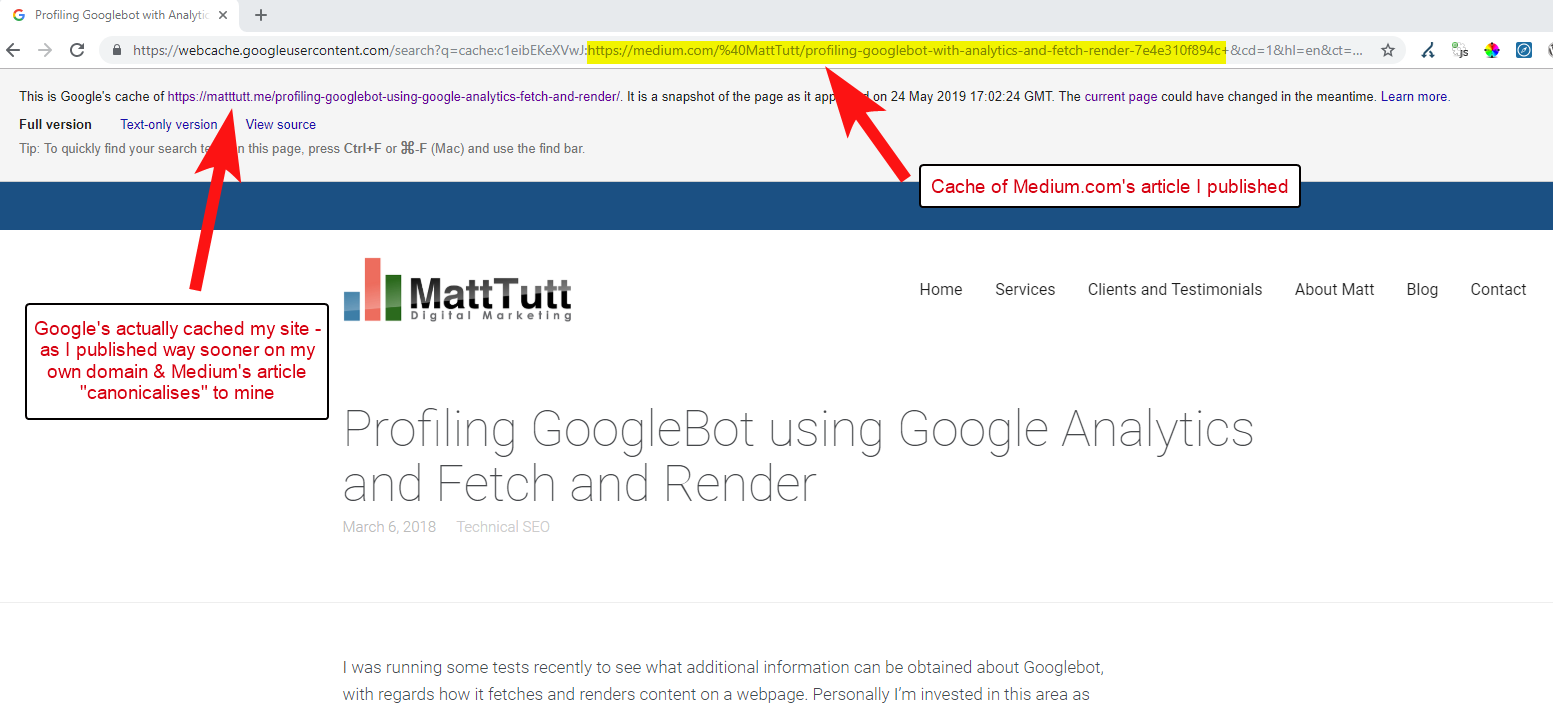
Z niektórych moich analiz wynika jednak, że nie zawsze tak działa.
Uważam, że tak jest, ponieważ gdy artykuł zostanie opublikowany na Medium bez uprzedniego umożliwienia Google przeszukania i zindeksowania artykułu w Twojej domenie, jeśli artykuł pójdzie dobrze na Medium (co jest trochę trafione lub chybione), Twoja treść zostanie zindeksowane i powiązane z witryną Medium pomimo ich kanonicznego wskazywania na Twoją.
Gdy treść zostanie dodana do Medium (a szczególnie, jeśli jest popularna), możesz prawie zagwarantować, że kawałek zostanie zeskrobany i ponownie opublikowany w Internecie w innym miejscu niemal natychmiast – więc znowu twoja treść jest duplikowana w innym miejscu.
Chociaż to wszystko się dzieje, istnieje duże prawdopodobieństwo, że jeśli Twoja domena jest dość mała pod względem uprawnień, Google może nawet nie mieć szansy na zindeksowanie i zindeksowanie opublikowanej przez Ciebie treści – i może się nawet zdarzyć, że element renderujący indeksowanie/indeksowanie nie zostało jeszcze ukończone lub występuje ciężki kod JavaScript powodujący duże opóźnienie między przeszukiwaniem, renderowaniem i indeksowaniem tej treści.
Widziałem sytuacje, w których duża firma publikuje świetny artykuł, ale następnego dnia publikuje go jako materiał myślowy na ogromnym blogu z wiadomościami branżowymi. Ponadto w ich witrynie wystąpił problem polegający na duplikowaniu (i indeksowaniu) treści pod adresem https://domain.com i https://www.domain.com.
Kilka dni po publikacji, szukając w Google dokładnej frazy artykułu w cudzysłowie, nigdzie nie było widać strony firmowej. Zamiast tego autorytatywny blog branżowy znalazł się na pierwszym miejscu, a kolejne pozycje zajmowali inni re-wydawcy.
W takim przypadku treść została powiązana z blogiem branżowym, więc wszelkie linki, które zyska artykuł, przyniosą korzyści tej witrynie, a nie oryginalnemu wydawcy.
Jeśli zamierzasz zmienić przeznaczenie treści w dowolnym miejscu w sieci, która prawdopodobnie zostanie zindeksowana, naprawdę powinieneś poczekać, aż będziesz całkowicie pewien, że została ona zindeksowana przez Google w Twojej własnej domenie.
Prawdopodobnie ciężko pracujesz, aby tworzyć i tworzyć swoje treści – nie wyrzucaj tego wszystkiego, ponieważ nie chcesz ponownie publikować w innym miejscu!
8 – Zła konfiguracja AMP (brak deklaracji adresu URL AMP)
Tylko garstka klientów, którym pomagałem, zdecydowała się wypróbować AMP, być może w oparciu o niektóre z wielu finansowanych przez Google studiów przypadków dotyczących jego wykorzystania.
Czasami nawet nie zdawałem sobie sprawy, że klient w ogóle ma wersję AMP swojej witryny – w raportach odesłań Analytics pojawił się jakiś dziwny ruch – gdzie wersja AMP witryny prowadziła z powrotem do wersji innej niż AMP.
W takim przypadku wersje stron AMP nie zostały poprawnie skonfigurowane, ponieważ nagłówki stron innych niż AMP nie zawierały odniesienia do adresu URL.

Bez informowania wyszukiwarek, że strona AMP istnieje pod określonym adresem URL, nie ma sensu w ogóle konfigurować AMP – chodzi o to, że jest ona indeksowana i zwracana w SERPS dla użytkowników mobilnych.
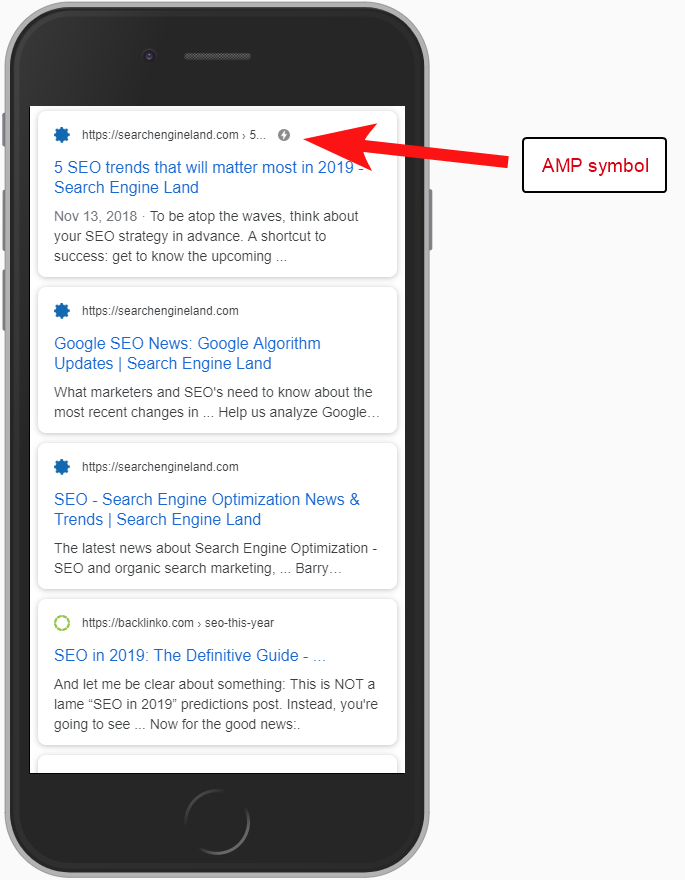
Dodanie odwołania do strony innej niż AMP jest ważnym sposobem poinformowania Google o stronie AMP i należy pamiętać, że tagi kanoniczne na stronach AMP nie powinny odwoływać się do siebie: prowadzą do strony innej niż AMP.
I chociaż nie jest to tak naprawdę kwestia techniczna dotycząca SEO, warto zauważyć, że nadal musisz dołączyć kod śledzenia na stronach AMP, jeśli chcesz mieć możliwość raportowania informacji o ruchu i zachowaniu użytkowników.
Zazwyczaj w ramach moich audytów SEO lubię przeprowadzać podstawowe kontrole implementacji analityki – w przeciwnym razie dane, które otrzymałeś, mogą w rzeczywistości nie być aż tak pomocne, zwłaszcza jeśli doszło do nieuzasadnionej konfiguracji analityki.
9 – Starsze domeny, które przekierowują 302 lub tworzą łańcuch przekierowań
Pracując z dużą niezależną marką hotelową w Stanach Zjednoczonych, która przeszła kilka rebrandingów w ciągu ostatnich kilku lat (dość powszechne w branży hotelarskiej), ważne jest, aby monitorować zachowanie poprzednich żądań nazw domen.
Łatwo o tym zapomnieć, ale może to być zwykła, półregularna kontrola polegająca na próbie zindeksowania starej witryny za pomocą narzędzia takiego jak OnCrawl, a nawet witryny innej firmy, która sprawdza kody stanu i przekierowania.
Częściej niż nie znajdziesz przekierowania domeny 302 do ostatecznego miejsca docelowego (301 jest zawsze najlepszym rozwiązaniem tutaj) lub 302 do wersji adresu URL niebędącej stroną WWW, zanim przejdziesz przez kilka kolejnych przekierowań przed trafieniem na końcowy adres URL.
John Mueller z Google stwierdził wcześniej, że śledzą tylko 5 przekierowań, zanim się poddają, podczas gdy wiadomo również, że po każdym przesłanym przekierowaniu część wartości linku jest tracona. Z tych powodów wolę trzymać się przekierowań 301, które są tak czyste, jak to tylko możliwe.
Redirect Path by Ayima to świetne rozszerzenie przeglądarki Chrome, które pokaże Ci stany przekierowań podczas przeglądania sieci.
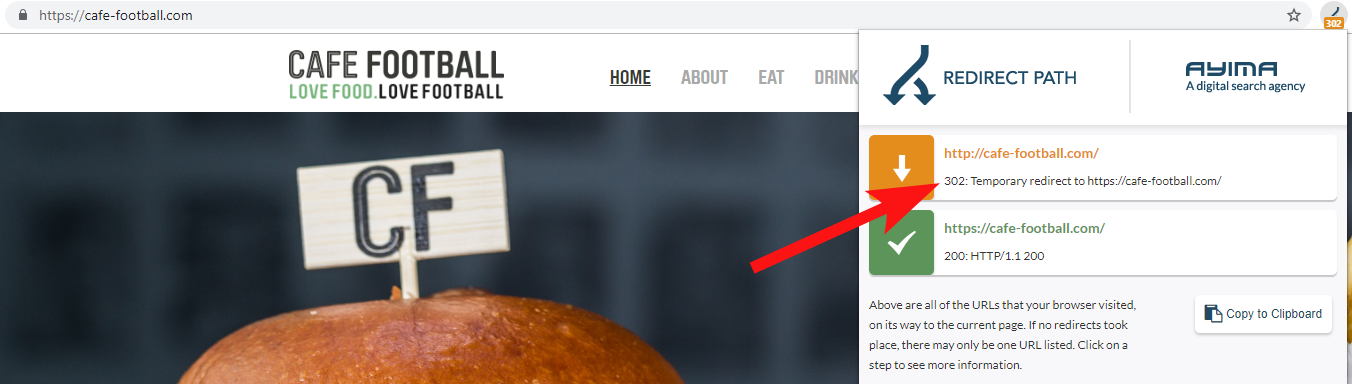
Innym sposobem, w jaki wykryłem stare nazwy domen należące do klienta, jest wyszukiwanie w Google jego numeru telefonu przy użyciu cudzysłowów dopasowania dokładnego lub części jego adresu.
Firma taka jak hotel rzadko zmienia adres (przynajmniej jego część) i możesz znaleźć stare katalogi/profile firm, które prowadzą do starej domeny.
Korzystanie z narzędzia do linków zwrotnych, takiego jak Majestic lub Ahrefs, może również pokazywać stare linki z poprzednich domen, więc jest to również dobry punkt wyjścia – zwłaszcza jeśli nie masz bezpośredniego kontaktu z klientem.
10 – Źle radzimy sobie z treścią wyszukiwania wewnętrznego
Właściwie jest to temat, o którym pisałem już wcześniej w OnCrawl – ale włączam go ponownie, ponieważ nadal widzę problematyczne treści wewnętrzne, które bardzo często pojawiają się „na wolności”.
Zacząłem ten artykuł, mówiąc o problemie dyrektywy robots.txt w Pingdom, który z zewnątrz wyglądał na poprawkę zapobiegającą przeszukiwaniu i indeksowaniu treści, które wysyłali.
Każda witryna, która wyświetla wewnętrzne wyniki wyszukiwania Google jako treść lub która wyświetla wiele treści generowanych przez użytkowników, musi być bardzo ostrożna w sposobie, w jaki to robi.
Jeśli witryna udostępnia wewnętrzne wyniki wyszukiwania Google w bardzo bezpośredni sposób, może to prowadzić do pewnego rodzaju ręcznej kary. Google prawdopodobnie uzna to za złe wrażenia użytkownika – wyszukują X, a następnie lądują na stronie, w której muszą ręcznie filtrować to, czego chcą.
W niektórych przypadkach uważam, że wyświetlanie treści wewnętrznych może być w porządku, zależy to tylko od kontekstu i okoliczności. Na przykład strona z ofertami pracy może chcieć udostępniać najnowsze wyniki pracy, które są aktualizowane prawie codziennie – więc prawie muszą sobie z tym poradzić.
Rzeczywiście jest znanym przykładem strony z ofertami pracy, która być może posuwa się za daleko, generując wszelkiego rodzaju treści na podstawie popularnych zapytań (po prostu zobacz poniżej, co może się stać, jeśli zastosujesz tę taktykę).
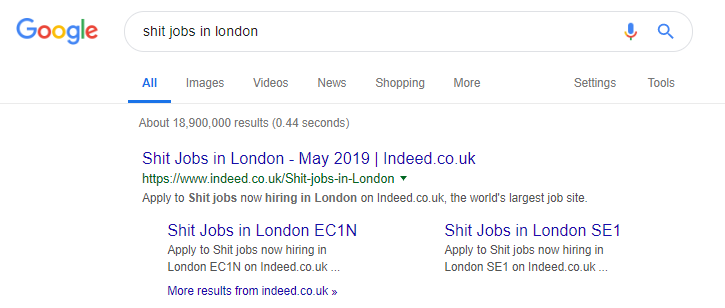
Mimo to jednak według danych SEMRush ich ruch organiczny ma się świetnie – ale są to cienkie linie, a zachowanie w ten sposób naraża Cię na wysokie ryzyko kary Google.
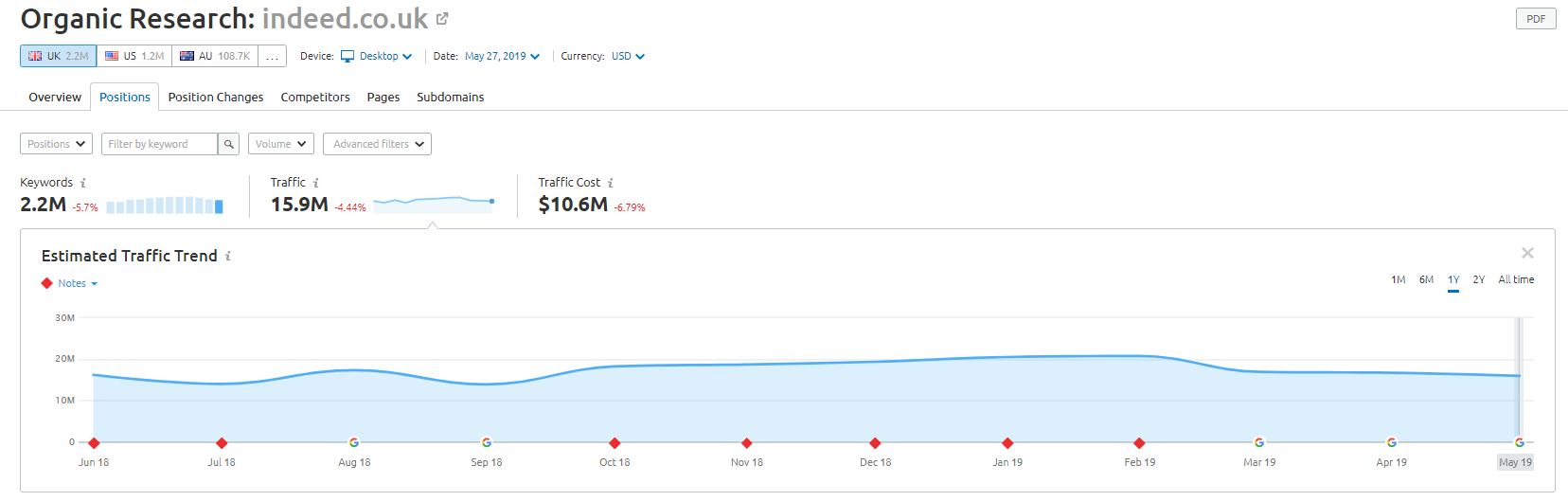
Sklep internetowy Wayfair.com to kolejna marka, która lubi żeglować pod wiatr. Z milionami zindeksowanych adresów URL (i wieloma automatycznie generowanymi adresami URL słów kluczowych) radzą sobie świetnie pod względem ruchu organicznego – ale istnieje wysokie ryzyko, że zostaną ukarane za udostępnianie treści w ten sposób wyszukiwarkom.
Wdrażając odpowiednią strukturę witryny, która obejmuje kategoryzowanie całej treści, budowanie różnych hierarchii nadrzędnych / podrzędnych, a nawet korzystanie z tagów lub innych niestandardowych taksonomii, możesz pomóc w nawigacji dla klientów i wyszukiwarek.
Używanie trików takich jak powyższe może wygrać w krótkim okresie, ale na dłuższą metę jest mało prawdopodobne. To sprawia, że kluczowe jest uzyskanie struktury witryny od samego początku lub przynajmniej odpowiednie zaplanowanie jej z wyprzedzeniem.
Zawijanie
10 błędów omówionych w tym artykule to jedne z najczęstszych problemów technicznych, jakie napotykam podczas audytów witryn.
Poprawienie tych błędów w witrynie to pierwszy krok do upewnienia się, że witryna jest technicznie sprawna. Po naprawieniu tych problemów audyty techniczne mogą koncentrować się na problemach specyficznych dla Twojej witryny.