
Nauka o danych zorientowana na biznes
Opublikowany: 2018-12-13Mówią, że Data Scientist to najseksowniejsza praca XXI wieku (i wszyscy Data Scientists, których spotkałem na różnych konferencjach, wiedzą o tym). Ale kiedy mówią tylko o teoretycznej części uczenia maszynowego, czasami zastanawiam się, czy wiedzą, dlaczego ich praca jest gorąca. Powodem jest to, że Data Scientist wie, jak łączyć dane, umiejętności techniczne i wiedzę statystyczną, aby osiągnąć cele biznesowe. Aby dobrze wykonywać analizę danych, musisz najpierw pomyśleć o biznesie.
Znam przypadki, w których firmy dodawały narzędzia analityczne do śledzenia każdego dotyku użytkownika, nie zastanawiając się nad tym, co faktycznie chcą osiągnąć. Zgromadzili wiele danych, których nie rozumieli i nie mogli wykorzystać do rozwoju swojej działalności.
Nie popełniaj takich błędów! Pomyśl o swoich celach i specyfice branży na każdym etapie procesu Data Science. Im bardziej jesteś kreatywny, tym większa masz szansę na sukces. Aby to udowodnić, pokażę Wam kilka inspirujących przykładów Data Science w zastosowaniach gigantów…
Jak rozpocząć swoją przygodę z nauką o danych?
Słyszałeś, że wiele firm korzysta z ML, aby zwiększyć swoje dochody, ale nie masz pojęcia, jak zacząć? Aby nie skończyć z kosztowną infrastrukturą i nieprzydatnymi (w realizacji potrzeb biznesowych) danymi, warto zacząć od odpowiedzi na następujące pytania:
Jakie są cele biznesowe klienta? Jak możemy wykorzystać dane, aby je osiągnąć?
Następnie możesz zacząć planować, jakie dane można śledzić i wykorzystywać.
Zbieranie danych
Jakie dane powinniśmy zbierać? Odpowiedź na to pytanie może cię zaskoczyć. Według Todda Yellina (wiceprezesa ds. innowacji produktu w Netfliksie) istnieją dwa rodzaje danych, które można wykorzystać: jawne i niejawne [1]. W przypadku Netflixa jest to jednoznaczne, gdy użytkownik dosłownie ocenia film. Z drugiej strony domniemane są dane behawioralne – oparte na kliknięciach użytkowników i korzystaniu z aplikacji. Który rodzaj jest bardziej wartościowy?
Nie ma uniwersalnej odpowiedzi na to pytanie, ale w większości przypadków dane niejawne byłyby bardziej przydatne . A to dlatego, że… ludzie kłamią.
Rozważmy przykład człowieka, który twierdzi, że kocha filmy dokumentalne i ocenia je na 5/5. Ale, jak pokazują dane, ogląda ten gatunek raz w roku. Jednocześnie w każdy piątek wieczorem ogląda popularne seriale. A to dlatego, że jest zmęczony po pracy i chce po prostu odpocząć na kanapie. Jakie więc dane należy wykorzystać do przygotowania takiego systemu rekomendacji: ocena czy zachowanie użytkownika?
Aby odpowiedzieć na to pytanie, musimy pomyśleć o biznesowym celu jego rozwoju. Celem Netflix jest zachęcenie użytkownika do oglądania większej liczby filmów. Zaczęli od popularnego pięciogwiazdkowego systemu ocen. Kiedy zdali sobie sprawę, że bardziej prawdopodobne jest, że wspomniani użytkownicy zobaczą Friends zamiast filmu o II wojnie światowej, opracowali system rekomendacji oparty na zachowaniu użytkowników. Zrzucili również ocenę pięciu gwiazdek i zastąpili ją prostszym, binarnym systemem kciuk w górę i kciuk w dół.
Jak pokazuje ten przykład, zebrane dane powinny być wybierane z uwzględnieniem specyfiki branży i powinny zawierać wystarczającą ilość informacji, aby zrozumieć decyzje i potrzeby użytkowników. Ale tutaj napotykamy inny problem: dane behawioralne, teksty i inne nieustrukturyzowane dane są trudniejsze do analizy i wykorzystania w modelach uczenia maszynowego niż ustrukturyzowane. Teraz nadszedł czas, aby porozmawiać o inżynierii funkcji.
Inżynieria funkcji
Aby pokazać, jak ważna jest inżynieria funkcji w Data Science, chciałbym zacytować Andrew Ng – współzałożyciela Google Brain i założyciela deeplearning.ai:
Wymyślanie funkcji jest trudne, czasochłonne, wymaga wiedzy eksperckiej. Stosowane uczenie maszynowe to w zasadzie inżynieria funkcji. [2].
https://forum.stanford.edu/events/2011/2011slajdy/plenary/2011plenaryNg.pdf
Ciekawym przykładem celowego podejścia do przetwarzania danych jest Booking.com, gdzie użytkownicy mogą oceniać hotele od 0 do 10. Ale jeśli imprezowicz wysoko ocenia hotel, czy jest to dobry wybór dla rodzin z dziećmi? Niekoniecznie.

Na szczęście są też komentarze użytkowników, które zawierają więcej potrzebnych nam informacji. Booking.com wykorzystuje analizę sentymentu i modelowanie tematyczne, aby wydobyć mocne i słabe strony komentowanego hotelu oraz preferencje użytkowników dotyczące zakwaterowania.
Rozważmy ten przykład:
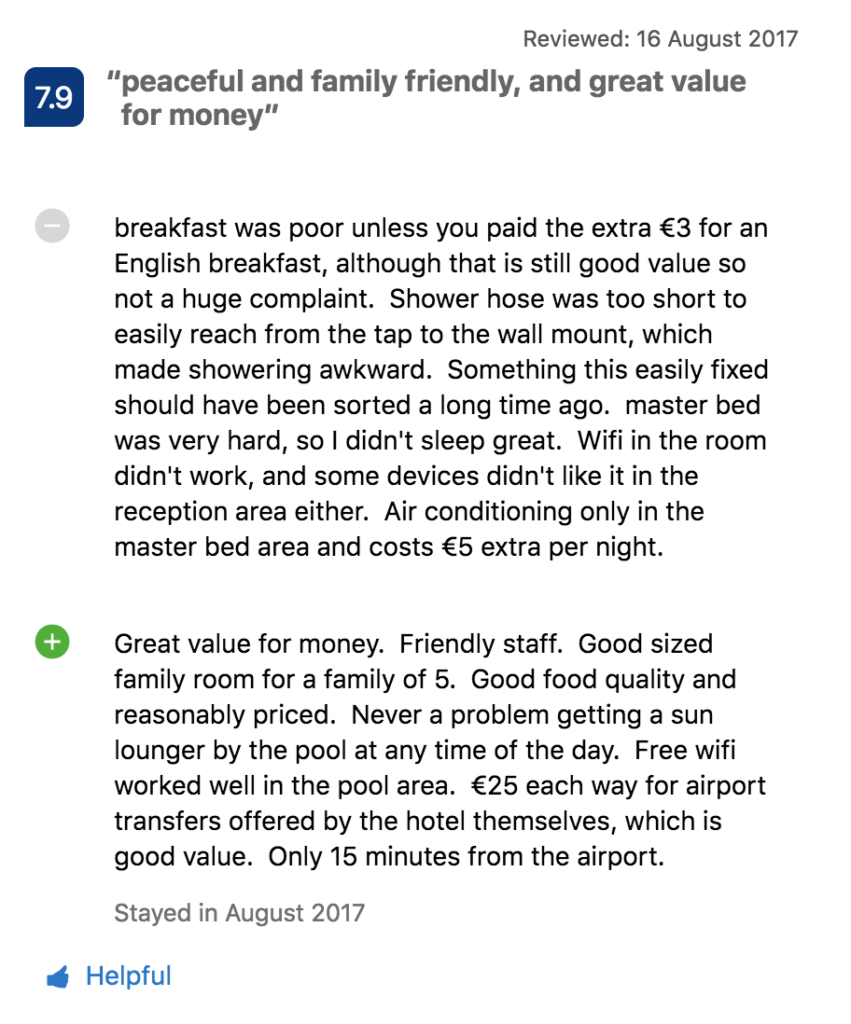
Temat Wyposażenie pokoju ma negatywny sentyment (użytkownik narzeka na prysznic, łóżko, wifi i klimatyzację). Jednocześnie ten użytkownik chwali wartość za cenę hotelu, personelu i jedzenia. System analizuje również to, co nie zostało wspomniane w komentarzu i dlatego prawdopodobnie nie jest ważne dla użytkownika – w naszym przykładzie może to być życie nocne.
Dzięki tym spostrzeżeniom platforma może zaoferować hotele bardziej odpowiednie dla użytkowników o podobnym profilu, w tym przypadku rodziny z dziećmi poszukującej miejsca na spędzenie wakacji w spokojnym hotelu za rozsądną cenę. Co więcej, Booking.com sortuje komentarze, aby u góry pokazać najciekawsze dla widza informacje.
Prowadzi to do sytuacji, w której wszyscy wygrywają: użytkownicy mogą szybciej i łatwiej znaleźć oferty dostosowane do ich konkretnych potrzeb, a platforma przynosi zysk, ponieważ są to te oferty, które użytkownicy chętniej kupują.

Ciekawi Cię analiza danych?
Ucz się więcejProdukt danych
Wdrożyłeś produkt danych z zadowalającymi wynikami? Nie czas na samozadowolenie. Jak pokazuje przykład Netflix [3] , ciągła praca nad ulepszaniem systemu może przynieść znaczne korzyści. Czy wystarczy odpowiednia rekomendacja filmowa? Co więcej moglibyśmy zrobić?
Jednym z nieszablonowych podejść Netflixa jest nie tylko polecanie filmów, ale także ilustrowanie ich obrazem, który byłby najbardziej atrakcyjny dla danego użytkownika. Powiedzmy, że polecają Ci Good Will Hunting . Jeśli w przeszłości oglądałeś wiele romcomów, możesz zobaczyć obraz całującej się pary, a jeśli jesteś fanem komedii, najprawdopodobniej obejrzysz zdjęcie popularnego amerykańskiego komika:

Dzięki takiemu podejściu użytkownik przewijający niezliczone opcje jest znacznie bardziej prawdopodobne, że zauważy film, który przyciągnie jego uwagę.
Ta i inne strategie rekomendacji przynoszą zdumiewające rezultaty – ponad 80% treści platformy opiera się na rekomendacjach algorytmicznych . Oznacza to, że użytkownikowi ciężko jest zabrakło rzeczy do obejrzenia. Kiedy jeden program się skończy, Netflix zaproponuje następny.
W ich biznesie daje to przewagę konkurencyjną, ponieważ użytkownicy znacznie rzadziej anulują swoje subskrypcje. To niezwykle udane zastosowanie Data Science zostało osiągnięte głównie dzięki dobremu zrozumieniu ich biznesu i użytkowników aplikacji.
Podsumowanie
Na jednej z tegorocznych konferencji Data Science prelegent zajmujący się prognozowaniem ryzyka kredytowego powiedział:
Kiedy ludzie pytają mnie, na czym właściwie polega moja praca, odpowiadam: wnoszę wartości biznesowe w oparciu o dane.
Dla mnie jest to jedna z najlepszych definicji Data Science. Nie powinna być zorientowana tylko na swoje teoretyczne podstawy, ale przede wszystkim na biznes. Jeśli chcesz stworzyć dobrą aplikację do uczenia maszynowego, musisz pomyśleć o tym, jak użytkownicy zachowują się w Twoim systemie i czego potrzebują. Mając to na uwadze, z powodzeniem osiągniesz swoje cele biznesowe.