
Potok Business Intelligence oparty na usługach AWS – studium przypadku
Opublikowany: 2019-05-16W ostatnich latach obserwujemy wzrost zainteresowania analizą big data. Kadra kierownicza, menedżerowie i inni interesariusze biznesowi wykorzystują Business Intelligence (BI) do podejmowania świadomych decyzji. Pozwala im natychmiast analizować krytyczne informacje i podejmować decyzje oparte nie tylko na własnej intuicji, ale także na tym, czego mogą się nauczyć z rzeczywistego zachowania swoich klientów.
Decydując się na stworzenie efektywnego i informacyjnego rozwiązania BI, jednym z pierwszych kroków, jakie musi wykonać Twój zespół programistów, jest zaplanowanie architektury potoku danych. Istnieje kilka narzędzi opartych na chmurze, które można zastosować do zbudowania takiego potoku i nie ma jednego rozwiązania, które byłoby najlepsze dla wszystkich firm. Zanim zdecydujesz się na konkretną opcję, powinieneś wziąć pod uwagę swój obecny stos technologiczny, ceny narzędzi i zestaw umiejętności twoich programistów. W tym artykule pokażę architekturę zbudowaną przy użyciu narzędzi AWS , która została z powodzeniem wdrożona jako część aplikacji Timesheets.
Przegląd architektury
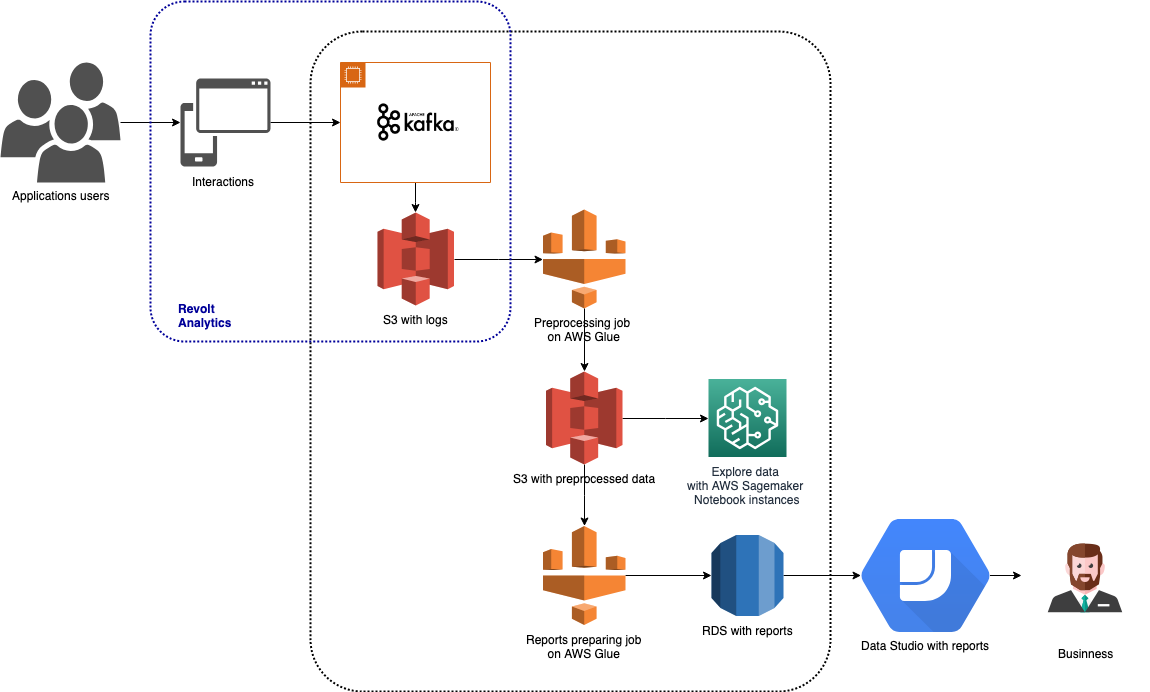
Ewidencja czasu pracy to narzędzie do śledzenia i raportowania czasu pracy pracownika. Można z niego korzystać za pośrednictwem aplikacji internetowych, iOS, Android i desktopowych, chatbota zintegrowanego z Hangouts i Slack oraz akcji w Asystencie Google. Ponieważ dostępnych jest wiele rodzajów aplikacji, istnieje również wiele różnorodnych danych do śledzenia. Dane są gromadzone za pośrednictwem Revolt Analytics, przechowywane w Amazon S3 i przetwarzane za pomocą AWS Glue i Amazon SageMaker. Wyniki analizy są przechowywane w Amazon RDS i służą do budowania wizualnych raportów w Google Data Studio. Architektura ta została przedstawiona na powyższym wykresie.
W kolejnych akapitach pokrótce opiszę każde z narzędzi Big Data wykorzystywanych w tej architekturze.
Analiza buntu
Revolt Analytics to narzędzie opracowane przez Miquido do śledzenia i analizy danych z aplikacji wszelkiego rodzaju. W celu uproszczenia implementacji Revolt w systemach klienckich zostały zbudowane zestawy SDK dla iOS, Android, JavaScript, Go, Python i Java. Jedną z kluczowych cech Revolt jest jego wydajność: wszystkie zdarzenia są kolejkowane, przechowywane i wysyłane w pakietach, co zapewnia, że są dostarczane zarówno szybko, jak i sprawnie. Revolt daje właścicielowi aplikacji możliwość identyfikacji użytkowników i śledzenia ich zachowania w aplikacji. Pozwala nam to budować przynoszące wartość modele uczenia maszynowego, takie jak w pełni spersonalizowane systemy rekomendacji i modele przewidywania rezygnacji, a także do profilowania klientów na podstawie zachowań użytkowników. Revolt zapewnia również funkcję sesji. Wiedza o ścieżkach i zachowaniach użytkowników w aplikacjach może pomóc Ci zrozumieć cele i potrzeby Twoich klientów.
Revolt można zainstalować na dowolnej wybranej przez Ciebie infrastrukturze. Takie podejście zapewnia całkowitą kontrolę nad kosztami i śledzonymi zdarzeniami. W przypadku Timesheets przedstawionym w tym artykule został on zbudowany na infrastrukturze AWS. Dzięki pełnemu dostępowi do magazynu danych właściciele produktów mogą łatwo uzyskać wgląd w ich aplikację i wykorzystać te dane w innych systemach.
Revolt SDK są dodawane do każdego elementu systemu Timesheets, który składa się z:
- Aplikacje na Androida i iOS (zbudowane z Flutter)
- Aplikacja komputerowa (zbudowana z Electrona)
- Aplikacja internetowa (napisana w React)
- Backend (napisany w Golangu)
- Hangouty i czaty online Slack
- Akcja w Asystencie Google
Revolt daje administratorom Timesheets wiedzę o urządzeniach (np. marka urządzenia, model) i systemach (np. wersja systemu operacyjnego, język, strefa czasowa) używanych przez klientów aplikacji. Ponadto wysyła różne niestandardowe zdarzenia związane z aktywnością użytkowników w aplikacjach. Dzięki temu administratorzy mogą analizować zachowania użytkowników, lepiej rozumieć ich cele i oczekiwania. Mogą również zweryfikować użyteczność wdrożonych funkcji i ocenić, czy te funkcje spełniają założenia Właściciela Produktu dotyczące sposobu ich wykorzystania.

Klej AWS
AWS Glue to usługa ETL (wyodrębnianie, przekształcanie i ładowanie), która pomaga przygotować dane do zadań analitycznych. Uruchamia zadania ETL w środowisku bezserwerowym Apache Spark. Zwykle składa się z trzech następujących elementów:
- Definicja przeszukiwacza — przeszukiwacz służy do skanowania danych we wszelkiego rodzaju repozytoriach i źródłach, klasyfikowania ich, wyodrębniania z nich informacji o schemacie i przechowywania metadanych na ich temat w Katalogu danych. Może na przykład skanować logi przechowywane w plikach JSON w Amazon S3 i przechowywać informacje o ich schemacie w Katalogu danych.
- Skrypt pracy – zadania AWS Glue przekształcają dane do pożądanego formatu. AWS Glue może automatycznie generować skrypt do ładowania, czyszczenia i przekształcania danych. Możesz również dostarczyć własny skrypt Apache Spark napisany w Pythonie lub Scali, który uruchomiłby żądane przekształcenia. Mogą obejmować zadania, takie jak obsługa wartości null, sesja, agregacje itp.
- Wyzwalacze — roboty indeksujące i zadania można uruchamiać na żądanie lub można je skonfigurować tak, aby uruchamiały się po wystąpieniu określonego wyzwalacza. Wyzwalaczem może być harmonogram oparty na czasie lub zdarzenie (np. pomyślne wykonanie określonego zadania). Ta opcja daje możliwość bezproblemowego zarządzania aktualnością danych w raportach.
W naszej architekturze Timesheets ta część potoku przedstawia się następująco:
- Wyzwalacz czasowy uruchamia zadanie przetwarzania wstępnego, które wykonuje czyszczenie danych, przypisuje dzienniki zdarzeń odpowiednie do sesji i oblicza początkowe agregacje. Dane wynikowe tego zadania są przechowywane w AWS S3.
- Drugi wyzwalacz jest skonfigurowany do uruchomienia po zakończeniu i pomyślnym wykonaniu zadania przetwarzania wstępnego. Ten wyzwalacz uruchamia zadanie, które przygotowuje dane, które są bezpośrednio wykorzystywane w raportach analizowanych przez Product Ownerów.
- Wyniki drugiej pracy są przechowywane w bazie danych AWS RDS. Dzięki temu są one łatwo dostępne i użyteczne w narzędziach Business Intelligence, takich jak Google Data Studio, PowerBI czy Tableau.
AWS SageMaker
Amazon SageMaker dostarcza moduły do budowania, trenowania i wdrażania modeli uczenia maszynowego.
Pozwala na trenowanie i dostrajanie modeli w dowolnej skali oraz umożliwia korzystanie z wysokowydajnych algorytmów dostarczanych przez AWS. Niemniej jednak możesz również użyć niestandardowych algorytmów po dostarczeniu odpowiedniego obrazu dockera. AWS SageMaker upraszcza również dostrajanie hiperparametrów dzięki konfigurowalnym zadaniom, które porównują metryki dla różnych zestawów parametrów modelu.
W grafiku wystąpienia SageMaker Notebook Instances pomagają nam eksplorować dane, testować skrypty ETL i przygotowywać prototypy wykresów wizualizacji do wykorzystania w narzędziu BI do tworzenia raportów. To rozwiązanie wspiera i usprawnia współpracę analityków danych, ponieważ zapewnia im pracę w tym samym środowisku programistycznym. Co więcej, pomaga to zapewnić, że żadne poufne dane (które mogą być częścią danych wyjściowych komórek notatników) nie będą przechowywane poza infrastrukturą AWS, ponieważ notatniki są przechowywane tylko w zasobnikach AWS S3, a do współdzielenia pracy między współpracownikami nie jest potrzebne żadne repozytorium git .
Zakończyć
Decyzja, których narzędzi Big Data i uczenia maszynowego użyć, ma kluczowe znaczenie przy projektowaniu architektury potoku dla rozwiązania Business Intelligence. Ten wybór może mieć istotny wpływ na możliwości systemu, koszty i łatwość dodawania nowych funkcji w przyszłości. Narzędzia AWS są z pewnością warte rozważenia, ale powinieneś wybrać technologię, która będzie odpowiadać Twojemu obecnemu stosowi technologicznemu i umiejętnościom Twojego zespołu programistów.
Skorzystaj z naszego doświadczenia w budowaniu przyszłościowych rozwiązań i skontaktuj się z nami!