
Automatycznie wyodrębnij pojęcia i słowa kluczowe z tekstu (Część I: Metody tradycyjne)
Opublikowany: 2022-02-22W dziale badawczo-rozwojowym firmy Oncrawl coraz częściej staramy się ulepszać semantyczną zawartość Twoich stron internetowych. Korzystając z modeli uczenia maszynowego do przetwarzania języka naturalnego (NLP), możemy szczegółowo porównywać zawartość Twoich stron, tworzyć automatyczne podsumowania, uzupełniać lub poprawiać tagi Twoich artykułów, optymalizować zawartość zgodnie z danymi z Google Search Console itp.
W poprzednim artykule mówiliśmy o wyodrębnianiu treści tekstowej ze stron HTML. Tym razem chcielibyśmy porozmawiać o automatycznym wyodrębnianiu słów kluczowych z tekstu. Ten temat zostanie podzielony na dwa posty:
- pierwsza obejmie kontekst i tzw. „tradycyjne” metody z kilkoma konkretnymi przykładami
- drugi, który pojawi się wkrótce, będzie dotyczył bardziej semantycznych podejść opartych na transformatorach i metodach oceny w celu porównania tych różnych metod
Kontekst
Poza tytułem lub abstraktem, nie ma lepszego sposobu na zidentyfikowanie treści tekstu, artykułu naukowego lub strony internetowej niż za pomocą kilku słów kluczowych. Jest to prosty i bardzo skuteczny sposób na zidentyfikowanie tematu i pojęć znacznie dłuższego tekstu. Może to być również dobry sposób na kategoryzowanie serii tekstów: identyfikowanie ich i grupowanie według słów kluczowych. Witryny oferujące artykuły naukowe, takie jak PubMed lub arxiv.org, mogą oferować kategorie i rekomendacje oparte na tych słowach kluczowych.
Słowa kluczowe są również bardzo przydatne do indeksowania bardzo dużych dokumentów i wyszukiwania informacji, dziedziny wiedzy dobrze znanej przez wyszukiwarki
Brak słów kluczowych jest powracającym problemem w automatycznej kategoryzacji artykułów naukowych [1]: wiele artykułów nie ma przypisanych słów kluczowych. Dlatego należy znaleźć metody automatycznego wyodrębniania pojęć i słów kluczowych z tekstu. Aby ocenić trafność automatycznie wyodrębnionego zestawu słów kluczowych, zestawy danych często porównują słowa kluczowe wyodrębnione przez algorytm ze słowami kluczowymi wyodrębnionymi przez kilka osób.
Jak możesz sobie wyobrazić, jest to problem wspólny dla wyszukiwarek przy kategoryzowaniu stron internetowych. Lepsze zrozumienie zautomatyzowanych procesów wyodrębniania słów kluczowych pozwala lepiej zrozumieć, dlaczego strona internetowa jest pozycjonowana dla takiego lub takiego słowa kluczowego. Może również ujawnić luki semantyczne, które uniemożliwiają mu dobrą pozycję w rankingu słowa kluczowego, na które kierujesz.
Istnieje oczywiście kilka sposobów na wyodrębnienie słów kluczowych z tekstu lub akapitu. W tym pierwszym poście opiszemy tak zwane „klasyczne” podejścia.
[Ebook] SEO danych: kolejna wielka przygoda
 Przeczytaj ebook
Przeczytaj ebookOgraniczenia
Niemniej jednak mamy pewne ograniczenia i warunki wstępne przy wyborze algorytmu:
- Metoda musi być w stanie wyodrębnić słowa kluczowe z pojedynczego dokumentu. Niektóre metody wymagają pełnego korpusu, czyli kilkuset, a nawet tysięcy dokumentów. Chociaż metody te mogą być używane przez wyszukiwarki, nie będą one przydatne w przypadku pojedynczego dokumentu.
- Jesteśmy w przypadku nienadzorowanego uczenia maszynowego. Nie mamy pod ręką zbioru danych w języku francuskim, angielskim lub innych językach z adnotacjami. Innymi słowy, nie mamy już tysięcy dokumentów z wyodrębnionymi słowami kluczowymi.
- Metoda musi być niezależna od domeny/pola leksykalnego dokumentu. Chcemy mieć możliwość wyodrębniania słów kluczowych z dowolnego typu dokumentu: artykułów prasowych, stron internetowych itp. Należy zauważyć, że niektóre zbiory danych, które mają już wyodrębnione słowa kluczowe dla każdego dokumentu, często dotyczą medycyny określonej domeny, informatyki itp.
- Niektóre metody opierają się na modelach tagowania POS, tj. zdolności modelu NLP do identyfikowania słów w zdaniu według ich typu gramatycznego: czasownika, rzeczownika, określnika. Określenie ważności słowa kluczowego, które jest rzeczownikiem, a nie określnikiem, jest wyraźnie trafne. Jednak w zależności od języka modele tagowania POS są czasami bardzo nierównej jakości.
O tradycyjnych metodach
Rozróżniamy tak zwane „tradycyjne” metody i nowsze, które wykorzystują NLP – Natural Language Processing – techniki takie jak osadzanie słów i osadzanie kontekstowe. Ten temat zostanie omówiony w przyszłym poście. Ale najpierw wróćmy do klasycznych podejść, wyróżniamy dwa z nich:
- podejście statystyczne
- podejście grafowe
Podejście statystyczne będzie polegać głównie na częstotliwościach słów i ich współwystępowaniu. Zaczynamy od prostych hipotez, aby zbudować heurystykę i wyodrębnić ważne słowa: bardzo częste słowo, seria kolejnych słów, które pojawiają się kilka razy itp. Metody oparte na grafach zbudują graf, w którym każdy węzeł może odpowiadać słowu, grupie słowa lub zdanie. Wtedy każdy łuk może reprezentować prawdopodobieństwo (lub częstotliwość) obserwowania tych słów razem.
Oto kilka metod:
- Na podstawie statystyk
- TF-IDF
- GRABIE
- JAKE
- Oparte na wykresie
- TextRank
- Pozycja tematu
- Pojedyncza pozycja
Wszystkie podane przykłady wykorzystują tekst zaczerpnięty z tej strony internetowej: Jazz au Tresor : John Coltrane – Impressions Graz 1962.
Podejście statystyczne
Przedstawimy Ci dwie metody Rake i Yake. W kontekście SEO być może słyszałeś o metodzie TF-IDF. Ale ponieważ wymaga to zbioru dokumentów, nie będziemy się tym tutaj zajmować.
GRABIE
RAKE to skrót od Rapid Automatic Keyword Extraction. Istnieje kilka implementacji tej metody w Pythonie, w tym rake-nltk. Wynik każdego słowa kluczowego, który jest również nazywany keyphrase, ponieważ zawiera kilka słów, opiera się na dwóch elementach: częstotliwości słów i sumie ich współwystępowania. Struktura każdej frazy kluczowej jest bardzo prosta, składa się z:
- pociąć tekst na zdania
- pociąć każde zdanie na frazy kluczowe
W poniższym zdaniu weźmiemy wszystkie grupy słów oddzielone elementami interpunkcyjnymi lub stopwordami:
Tuż wcześniej Coltrane prowadził kwintet z Ericiem Dolphym u boku i Reggie Workmanem na kontrabasie.
Może to skutkować następującymi frazami:
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" .
Pamiętaj, że stopwords to seria bardzo częstych słów, takich jak „ the ”, „ in ”, „i” or „ it ”. Ponieważ metody klasyczne często opierają się na obliczeniu częstotliwości występowania słów, ważne jest, aby starannie dobierać przerywniki. W większości przypadków w naszych propozycjach fraz kluczowych nie chcemy umieszczać słów takich jak >"to" , "the" or „of”. Rzeczywiście, te stopwordy nie są związane z konkretną dziedziną leksykalną i dlatego są znacznie mniej istotne niż np. słowa „ jazz ” lub „ saxophone ”.

Po wyizolowaniu kilku kandydujących fraz kluczowych, nadajemy im ocenę zgodnie z częstotliwością słów i współwystępowania. Im wyższy wynik, tym bardziej trafne powinny być frazy kluczowe.
Spróbujmy szybko z tekstem z artykułu o Johnie Coltrane'u.
# fragment kodu Pythona dla rake z rake_nltk import rake # załóżmy, że masz już artykuł w zmiennej 'text' prowizja = prowizja (stopwords=FRENCH_STOPWORDS, max_length=4) rake.extract_keywords_from_text(text) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
Oto pierwsze 5 fraz:
„austriackie narodowe radio publiczne”, „liryczne szczyty bardziej niebiańskie”, „graz ma dwie osobliwości”, „saksofon tenorowy John Coltrane”, „tylko wersja nagrana”
Ta metoda ma kilka wad. Pierwszym z nich jest znaczenie wyboru stopwordów, ponieważ służą one do dzielenia zdania na kandydujące frazy kluczowe. Po drugie, gdy frazy kluczowe są zbyt długie, często mają wyższy wynik ze względu na współwystępowanie obecnych słów. Aby ograniczyć długość fraz kluczowych, ustawiliśmy metodę z max_length=4 .
JAKE
YAKE to skrót od Yet Another Keyword Extractor. Ta metoda jest oparta na następującym artykule YAKE! Ekstrakcja słów kluczowych z pojedynczych dokumentów przy użyciu wielu funkcji lokalnych, datowana na 2020 rok. Jest to nowsza metoda niż RAKE, której autorzy zaproponowali implementację Pythona dostępną na Github.
W przypadku RAKE będziemy opierać się na częstotliwości i współwystępowaniu słów. Autorzy dodadzą też kilka ciekawych heurystyk:
- rozróżnimy słowa pisane małymi i dużymi literami (albo pierwsza litera, albo całe słowo). Przyjmiemy tutaj, że słowa zaczynające się od dużej litery (poza początkiem zdania) mają większe znaczenie niż inne: nazwy osób, miasta, kraje, marki. To jest ta sama zasada dla wszystkich słów pisanych wielką literą.
- punktacja każdego kandydującego wyrażenia kluczowego będzie zależeć od jego pozycji w tekście. Jeśli kandydujące frazy kluczowe pojawiają się na początku tekstu, będą miały wyższy wynik niż gdyby pojawiły się na końcu. Na przykład artykuły z wiadomościami często wspominają o ważnych pojęciach na początku artykułu.
# fragment kodu Pythona dla yake z yake importuj KeywordExtractor jako Yake yake = Yake(lan = "fr", stopwords = FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords(tekst)
Podobnie jak RAKE, oto 5 najlepszych wyników:
„Treasure Jazz”, „John Coltrane”, „Impressions Graz”, „Graz”, „Coltrane”
Pomimo pewnych powtórzeń pewnych słów w niektórych frazach, metoda ta wydaje się dość interesująca.
Podejście grafowe
Tego typu podejście nie odbiega zbytnio od podejścia statystycznego w tym sensie, że będziemy również obliczać współwystępowanie słów. Sufiks rangi powiązany z niektórymi nazwami metod, takimi jak TextRank , opiera się na zasadzie algorytmu PageRank , który oblicza popularność każdej strony na podstawie jej linków przychodzących i wychodzących.
[Ebook] Automatyzacja SEO za pomocą Oncrawl
 Przeczytaj ebook
Przeczytaj ebookTextRank
Algorytm ten pochodzi z artykułu TextRank: Bringing Order into Texts z 2004 roku i opiera się na tych samych zasadach co algorytm PageRank . Jednak zamiast budować wykres ze stronami i linkami, zbudujemy wykres ze słowami. Każde słowo zostanie połączone z innymi słowami zgodnie z ich współwystępowaniem.
W Pythonie jest kilka implementacji. W tym artykule przedstawię pytextrank. Przełamujemy jedno z naszych ograniczeń dotyczących tagowania POS. Rzeczywiście, budując wykres, nie uwzględnimy wszystkich słów jako węzłów. Pod uwagę będą brane tylko czasowniki i rzeczowniki. Podobnie jak w poprzednich metodach, które używają odrzucanych słów do odfiltrowywania nieistotnych kandydatów, algo TextRank używa słów typu gramatycznego.
Oto przykład części wykresu, który zostanie zbudowany przez algo : 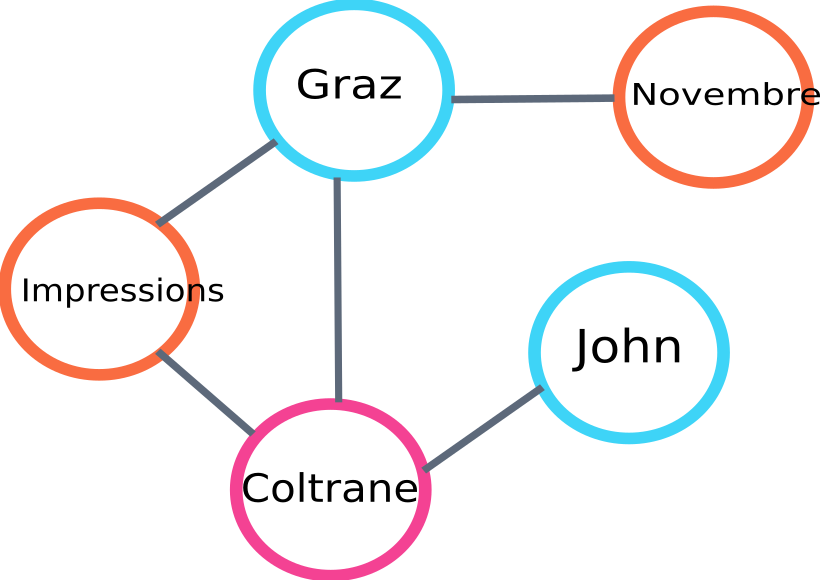
przykład wykresu rangi tekstu
Oto przykład użycia w Pythonie. Należy zauważyć, że ta implementacja wykorzystuje mechanizm potoku biblioteki spaCy. To właśnie ta biblioteka jest w stanie wykonać tagowanie POS.
# fragment kodu Pythona dla pytextrank
importuj przestrzeń
importuj pytextrank
# załaduj francuski model
nlp = spacy.load("fr_core_news_sm")
# dodaj pytextrank do potoku
nlp.add_pipe("textrank")
dokument = nlp(tekst)
textrank_keyphrases = doc._.frazy
Oto 5 najlepszych wyników:
„Kopenhaga”, „listopad”, „Impresje Graz”, „Graz”, „John Coltrane”
Oprócz wyodrębniania fraz kluczowych TextRank wyodrębnia również zdania. Może to być bardzo przydatne przy sporządzaniu tak zwanych „podsumowań ekstrakcyjnych” – ten aspekt nie zostanie omówiony w tym artykule.
Wnioski
Spośród trzech testowanych tutaj metod, dwie ostatnie wydają się nam dość istotne dla tematu tekstu. Aby lepiej porównać te podejścia, musielibyśmy oczywiście ocenić te różne modele na większej liczbie przykładów. Rzeczywiście istnieją metryki do pomiaru trafności tych modeli wyodrębniania słów kluczowych.
Listy słów kluczowych tworzone przez te tak zwane tradycyjne modele stanowią doskonałą podstawę do sprawdzenia, czy Twoje strony są dobrze kierowane. Ponadto dają pierwsze przybliżenie tego, jak wyszukiwarka może zrozumieć i sklasyfikować treść.
Z drugiej strony inne metody wykorzystujące wstępnie wytrenowane modele NLP, takie jak BERT, mogą być również używane do wyodrębniania koncepcji z dokumentu. W przeciwieństwie do tak zwanego podejścia klasycznego, metody te zwykle pozwalają na lepsze uchwycenie semantyki.
Różne metody oceny, osadzania kontekstowe i transformatory zostaną przedstawione w drugim artykule na ten temat!
Oto lista słów kluczowych wyodrębnionych z tego artykułu za pomocą jednej z trzech wymienionych metod:
„metody”, „słowa kluczowe”, „frazy kluczowe”, „tekst”, „wyodrębnione słowa kluczowe”, „przetwarzanie języka naturalnego”
Odniesienia bibliograficzne
- [1] Ulepszone automatyczne wyodrębnianie słów kluczowych przy większej wiedzy językowej, Anette Hulth, 2003
- [2] Automatyczne wyodrębnianie słów kluczowych z poszczególnych dokumentów, Stuart Rose i in. al, 2010
- [3] JARZ! Ekstrakcja słów kluczowych z pojedynczych dokumentów przy użyciu wielu funkcji lokalnych, Ricardo Campos i in. al, 2020
- [4] TextRank: Uporządkowanie tekstów, Rada Mihalcea i in. al, 2004
Rozpocznij bezpłatny 14-dniowy okres próbny
 Rozpocznij okres próbny
Rozpocznij okres próbny