
Autentyczność, Dalle-2 i Midjourney oraz nasza fascynacja obrazami i sztuką generowanymi przez sztuczną inteligencję
Opublikowany: 2022-08-04Ten artykuł dotyczy technologii stojącej za platformami takimi jak Dalle-2 i Midjourney oraz dlaczego twórcy Open AI powinni potencjalnie płacić Ci pieniądze – a nie pobierać od Ciebie…
Coraz więcej osób w Internecie nazywa Dalle-2 i Open AI oszustwem. Powodem jest to, że Dalle-2 nagle staje się usługą monetyzowaną, w której musisz kupować kredyty, jeśli korzystasz z platformy poza limitem wersji beta.
DALLE 2 to tylko jedna z wielu nowych platform oferujących dostęp do treści generowanych przez sztuczną inteligencję i twierdzących, że możesz ich używać do celów komercyjnych. Inne platformy to Midjourney, Jasper Art, Nightcafe, Starry AI i Craiyon. W tym poście skupimy się na Dalle 2, ale są one prawie identyczne, jeśli chodzi o wyzwania prawne i problemy.
Oszustwo jest naszym zdaniem dość surowym stwierdzeniem, ale istnieje oczywisty problem z wykorzystaniem danych utworzonych przez inne osoby (zdjęcia, filmy, adnotacje, osoby na obrazach itp.), a następnie rozpoczęcie ich odsprzedaży tym samym osobom.
Wielu z nas może przeoczyć ten problem, ponieważ jesteśmy po prostu zafascynowani nową technologią. Coś, co jest całkowicie zrozumiałe.
Jednak pomimo tego, że DALL-E 2 na koniec dnia jest tylko zaawansowaną maszyną do rozpoznawania wzorów, jego wydajność nie jest neutralna, a wzory nie pochodzą ze świeżego powietrza.
Opierają się na tonach danych, w których należy zadać wiele pytań prawnych. Pytania, które są ważne dla Ciebie jako potencjalnego użytkownika generowanych obrazów.
 Obraz stworzony przez DALLE-2
Obraz stworzony przez DALLE-2
Modele AI nie mogą być porównywane z istotami ludzkimi
Powinieneś zacząć od przeczytania tego genialnego artykułu w Engadget, zanim zaczniesz rozważać użycie obrazów DALL-E 2 do celów komercyjnych.
W artykule Engadget zwracają uwagę na jeszcze jedną bardzo ważną rzecz. Mianowicie fakt, że DALL-E 2 i OpenAI NIE zrzekają się własnego prawa do komercjalizacji obrazów, które użytkownicy tworzą za pomocą DALL-E. Zasadniczo oznacza to, że możesz generować obrazy, które następnie będą sprzedawać komercyjnie innym.
To pokazuje, że intencje są zupełnie inne niż czasami stosowana analogia, gdzie promotorzy dalle-2 porównują to do studenta czytającego pracę uznanego autora. W tym przykładzie uczeń może nauczyć się stylów i wzorów autora, a później znaleźć je w innych kontekstach i wykorzystać je ponownie.
Nie chodzi jednak o to, by ludzki mózg wykorzystywał twórczą pamięć do tworzenia nowych twórczych dzieł. Chodzi o ponowne użycie maszyny do rozpoznawania wzorców, a w niektórych przypadkach odtwarzanie danych treningowych na obrazach, które są następnie wykorzystywane lub nawet sprzedawane komercyjnie. To po prostu dwa różne światy – zarówno w przenośni, jak i dosłownie.
 Prawdziwe zdjęcie z prawdziwego świata
Prawdziwe zdjęcie z prawdziwego świata
Obietnica autentyczności JumpStory
Ten artykuł jest przeznaczony dla osób, które chcą głębiej zrozumieć, jak działa ta nowa technologia generowania obrazów AI. Ale zanim zaczniemy, tylko kilka słów o tym, dlaczego JumpStory nie buduje obecnie podobnej maszyny.
Oczywiście wielokrotnie zadano nam to pytanie. Nie tylko biorąc pod uwagę, że już używamy sztucznej inteligencji w naszej firmie, a ponieważ mamy dostęp do milionów autentycznych obrazów.
Nie jest to jednak dla nas dyskusja technologiczna, ale etyczna. Dyskusja, która zaowocowała naszą obietnicą autentyczności.
Jesteśmy zasadniczo przeciwni przyszłości, w której obrazy generowane przez sztuczną inteligencję stają się normą, a nie wyjątkiem. Nazywaj nas staroświeckimi, ale wierzymy, że PRAWDZIWY świat jest piękny.
Jesteśmy dumni, że nasze zdjęcia i filmy przedstawiają prawdziwych ludzi w różnych kształtach i rozmiarach. Nie sprzeciwiamy się wykorzystywaniu sztucznej inteligencji, ale uważamy, że nie powinna być ona wykorzystywana do generowania fałszywych ludzi lub rzeczywistości.
Technologie takie jak media syntetyczne i DALL-E 2 mogą być fascynujące na pierwszy rzut oka, ale stanowią też realne ryzyko. Grozi im zatarcie granic między rzeczywistością a fałszem, co będzie fundamentalnym zagrożeniem dla zaufania między ludźmi.
Właśnie dlatego JumpStory nie wykorzystuje sztucznej inteligencji do generowania fałszywych obrazów, ale zamiast tego wykorzystuje sztuczną inteligencję do identyfikowania, które obrazy są oryginalne, autentyczne i – oczywiście – legalne w celach komercyjnych.

Są to obrazy, które można znaleźć podczas korzystania z naszej usługi, a nasze podejście nazwaliśmy „Autentyczna inteligencja”.
Zrozumienie, w jaki sposób generowane są obrazy AI
Na razie dość o JumpStory i kwestiach prawnych z DALL-E 2. Przyjrzyjmy się, jak obrazy AI są generowane na platformach takich jak DALLE-2, Imagen, Crayion (dawniej Dall-E Mini), Midjourney itp. … Używając DALLE-2 jako najbardziej przereklamowanego obecnie przykładu.
Na początek DALLE-2 może wykonywać różnego rodzaju zadania, ale w tym wpisie na blogu skupimy się na zadaniu generowania obrazu.
Działa to tak, że monit tekstowy jest wprowadzany do kodera tekstu. Ten koder jest wyszkolony do mapowania monitu na przestrzeń reprezentacji. Następnie tak zwany wcześniejszy model odwzorowuje zakodowany tekst na odpowiednie kodowanie obrazu, które przechwytuje informacje semantyczne monitu o kodowanie tekstu.
(Jeśli to już staje się trochę geekowe, bardzo przepraszam, ale będzie jeszcze gorzej )
Ostatnim krokiem kodera obrazu jest wygenerowanie obrazu, który wizualizuje informacje semantyczne otrzymane przez koder. To są podstawy maszyn takich jak Open AI.
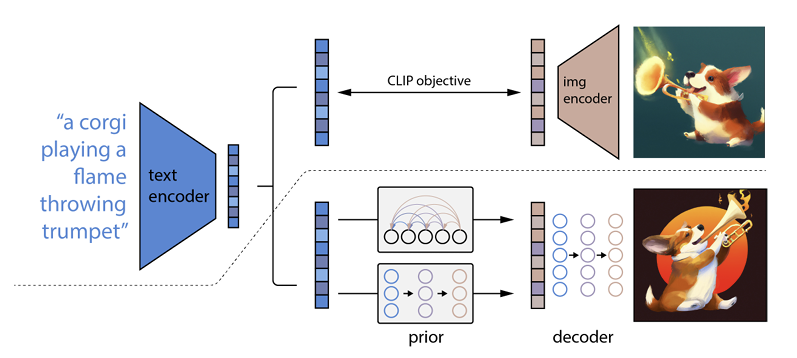
Związek między tekstem a obrazami
DALL-E 2 i podobne technologie są często określane jako generatory tekstu na obraz. Powodem jest ich zdolność do odbierania tekstu wejściowego i dostarczania obrazu.
Oto przykład: „Astronauta na koniu w stylu Andy'ego Warhola:

źródło: DALE-2
To, co się tutaj dzieje, opiera się na modelu Open AI o nazwie CLIP. CLIP to skrót od „Contrastive Language-Image Pre-training” i jest bardzo złożonym modelem wyszkolonym na milionach obrazów i podpisów.
CLIP jest szczególnie dobry w zrozumieniu, jak bardzo dany tekst odnosi się do konkretnego obrazu. Kluczem tutaj nie jest podpis, ale to, jak dany podpis jest powiązany z określonym obrazem.
Ten rodzaj technologii nazywa się „kontrastywną”, a CLIP jest w stanie nauczyć się semantyki z języka naturalnego. CLIP nauczył się tego poprzez proces, którego celem jest (teraz cytując dokumentację technologiczną): „jednocześnie maksymalizacja podobieństwa cosinusów między Npoprawnie zakodowanymi parami obraz/podpis i zminimalizowanie podobieństwa cosinusów między N 2 – N niepoprawnie zakodowanym obrazem /pary podpisów”.
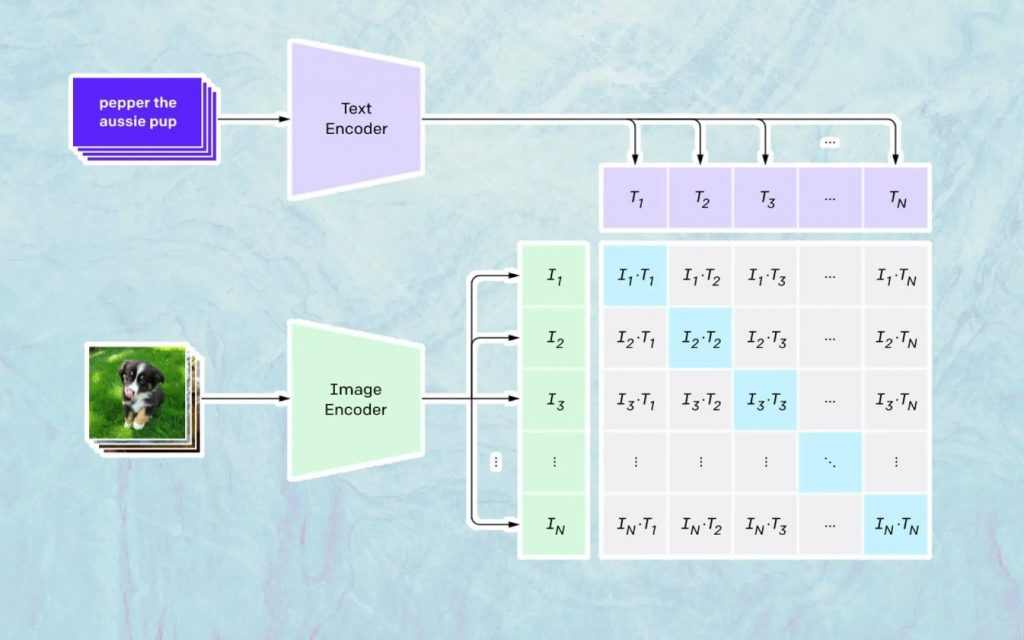
Generowanie obrazów
Jak opisano powyżej, model CLIP uczy się przestrzeni reprezentacji, w której może określić, w jaki sposób kodowania obrazów i tekstów są powiązane.
Kolejnym zadaniem jest wykorzystanie tej przestrzeni do generowania obrazów. W tym celu Open AI opracowała inny model o nazwie GLIDE, który jest w stanie wykorzystać dane wejściowe z CLIP i – wykorzystując model dyfuzyjny – wykonać generację obrazu.
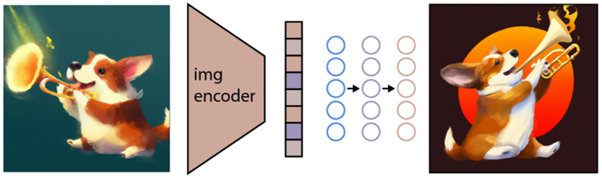
Aby krótko wyjaśnić, czym jest model dyfuzji, jest to w zasadzie model, który uczy się generować dane, odwracając stopniowy proces szumu. Przepraszamy, że teraz staje się to bardzo techniczne, więc przytoczę opis znajdujący się w dokumentacji Open AI:
„Proces szumu jest postrzegany jako sparametryzowany łańcuch Markowa, który stopniowo dodaje szum do obrazu, aby go uszkodzić, ostatecznie (asymptotycznie) w wyniku czystego szumu Gaussa. Model dyfuzji uczy się nawigować wstecz wzdłuż tego łańcucha, stopniowo usuwając szum w serii kroków czasowych, aby odwrócić ten proces”.

Jeśli chcesz jeszcze głębiej zagłębić się w tę technologię, zalecamy przeczytanie tego znakomitego artykułu autorstwa Ryana O'Connora.