
Jak odpowiadać na złożone pytania dotyczące danych za pomocą danych Oncrawl, poza Oncrawl
Opublikowany: 2022-01-04Jedną z zalet Oncrawl dla SEO dla przedsiębiorstw jest pełny dostęp do surowych danych. Niezależnie od tego, czy łączysz swoje dane SEO z BI lub przepływem pracy w nauce danych, przeprowadzasz własne analizy, czy pracujesz zgodnie z wytycznymi dotyczącymi bezpieczeństwa danych dla swojej organizacji, surowe dane SEO i audytu witryny mogą służyć wielu celom.
Dzisiaj przyjrzymy się, jak wykorzystać dane Oncrawl do odpowiedzi na złożone pytania dotyczące danych.
Co to jest złożone pytanie dotyczące danych?
Złożone pytania dotyczące danych to pytania, na które nie można odpowiedzieć za pomocą prostego wyszukiwania w bazie danych, ale wymagają one przetworzenia danych w celu uzyskania odpowiedzi.
Oto kilka typowych przykładów „złożonych” pytań dotyczących danych, które często zadają SEO:
- Tworzenie listy wszystkich linków kierujących do stron, które przekierowują do innych stron ze statusem 404
- Stworzenie listy wszystkich linków i ich tekstu kotwicy kierującego do stron w segmentacji opartej na metrykach innych niż URL
Jak odpowiadać na złożone pytania dotyczące danych w Oncrawl
Struktura danych Oncrawl jest zbudowana tak, aby umożliwić prawie wszystkim witrynom wyszukiwanie danych w czasie zbliżonym do rzeczywistego. Wiąże się to z przechowywaniem różnych typów danych w różnych zestawach danych w celu zapewnienia, że czasy wyszukiwania są ograniczone do minimum w interfejsie. Na przykład przechowujemy wszystkie dane związane z adresami URL w jednym zestawie danych: kod odpowiedzi, liczba linków wychodzących, rodzaj obecnych danych strukturalnych, liczba słów, liczba wizyt organicznych… A wszystkie dane związane z linkami przechowujemy w osobnym zestawie danych: cel linku, źródło linku, tekst kotwicy…
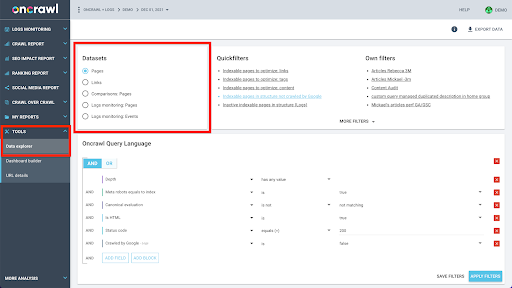
Łączenie tych zestawów danych jest skomplikowane obliczeniowo i nie zawsze jest obsługiwane w interfejsie aplikacji Oncrawl. Jeśli chcesz wyszukać coś, co wymaga przefiltrowania jednego zestawu danych w celu wyszukania czegoś w innym, zalecamy samodzielne manipulowanie nieprzetworzonymi danymi.
Ponieważ wszystkie dane Oncrawl są dostępne dla Ciebie, istnieje wiele sposobów łączenia zbiorów danych i wyrażania złożonych zapytań.
W tym artykule przyjrzymy się jednemu z nich, korzystającemu z Google Cloud i BigQuery, które jest odpowiednie w przypadku bardzo dużych zbiorów danych, z którymi spotyka się wielu naszych klientów podczas badania danych witryn z dużą liczbą stron.
Co będziesz potrzebował
Aby zastosować metodę, którą omówimy w tym artykule, potrzebujesz dostępu do następujących narzędzi:
- Oncrawl
- Oncrawl API z Big Data Export
- Przechowywanie w chmurze Google
- BigQuery
- Skrypt Pythona do przesyłania danych z Oncrawl do BigQuery (będziemy go tworzyć podczas tego artykułu).
Zanim zaczniesz, musisz mieć dostęp do pełnego raportu z indeksowania w Oncrawl.
Jak wykorzystać dane Oncrawl w Google BigQuery
Plan na dzisiejszy artykuł wygląda następująco:
- Najpierw upewnimy się, że Google Cloud Storage jest skonfigurowany do odbierania danych z Oncrawl.
- Następnie użyjemy skryptu Python do uruchomienia eksportu Big Data Oncrawl, aby wyeksportować dane z danego indeksowania do zasobnika Google Cloud Storage. Wyeksportujemy dwa zbiory danych: strony i linki.
- Gdy to zrobisz, utworzymy zbiór danych w Google BigQuery. Następnie utworzymy tabelę z każdego z dwóch eksportów w zbiorze danych BigQuery.
- Na koniec będziemy eksperymentować z zapytaniem o poszczególne zestawy danych, a następnie oba zestawy danych razem, aby znaleźć odpowiedź na złożone pytanie.
Konfiguracja w Google Cloud w celu odbierania danych Oncrawl
Aby uruchomić ten przewodnik w dedykowanym środowisku piaskownicy, zalecamy utworzenie nowego projektu Google Cloud, aby odizolować go od istniejących bieżących projektów.
Zacznijmy od domu Google Cloud.
Na swojej stronie głównej Google Cloud masz dostęp do wielu rzeczy oprócz Cloud Storage. Interesują nas zasobniki Cloud Storage, które są dostępne w warstwie przechowywania w chmurze Google Cloud Platform: 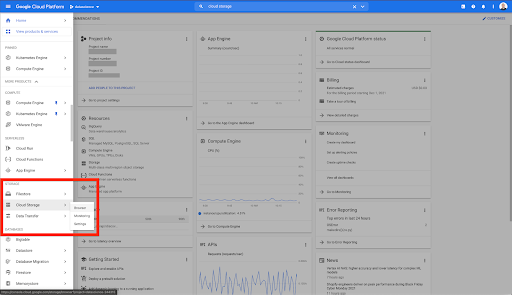
Możesz również uzyskać dostęp do przeglądarki Cloud Storage bezpośrednio pod adresem https://console.cloud.google.com/storage/browser.
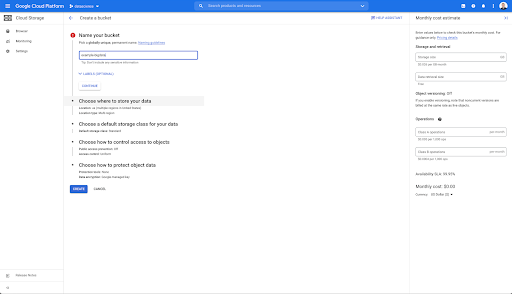
Następnie musisz utworzyć zasobnik Cloud Storage i przyznać odpowiednie uprawnienia, aby konto usługi Oncrawl mogło zapisywać w nim pod wybranym prefiksem.
Zasobnik Google Cloud Storage będzie służył jako tymczasowa pamięć do przechowywania wyeksportowanych Big Data z Oncrawl przed załadowaniem ich do Google BigQuery.
W tym zasobniku utworzyłem również dwa foldery: „linki” i „strony”: 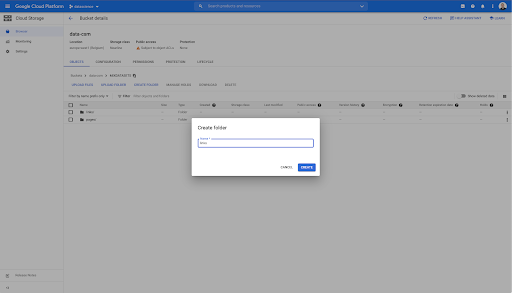
Eksportowanie zbiorów danych z Oncrawl
Teraz, gdy mamy skonfigurowaną przestrzeń, w której chcemy zapisać dane, musimy je wyeksportować z Oncrawl. Eksportowanie do zasobnika Google Cloud Storage za pomocą Oncrawl jest szczególnie łatwe, ponieważ możemy wyeksportować dane w odpowiednim formacie i zapisać je bezpośrednio w zasobniku. Eliminuje to wszelkie dodatkowe kroki.
Tworzenie klucza API
Eksportowanie danych z Oncrawl w formacie Parquet dla BigQuery będzie wymagało użycia klucza API, aby programowo działać na API w imieniu właściciela konta Oncrawl. Aplikacja Oncrawl umożliwia użytkownikom tworzenie nazwanych kluczy API, dzięki czemu Twoje konto jest zawsze dobrze zorganizowane i czyste. Klucze API są również powiązane z różnymi uprawnieniami (zakresami), dzięki czemu możesz zarządzać kluczami i ich przeznaczeniem.
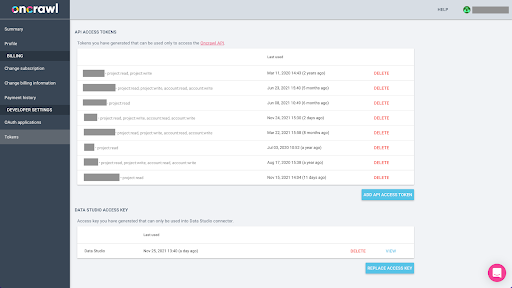
Nazwijmy nasz nowy klucz „Klucz sesji wiedzy”. Funkcja eksportu Big Data wymaga uprawnień do zapisu na koncie, ponieważ tworzymy eksporty danych. Aby to zrobić, musimy mieć dostęp do odczytu w projekcie oraz dostęp do odczytu i zapisu na koncie.
Teraz mamy nowy klucz API, który skopiuję do schowka.
Pamiętaj, że ze względów bezpieczeństwa możesz skopiować klucz tylko raz . Jeśli zapomnisz skopiować klucz, będziesz musiał usunąć klucz i utworzyć nowy.
Tworzenie skryptu Pythona
Zbudowałem w tym celu notatnik Google Colab, ale udostępnię poniższy kod, aby umożliwić Ci tworzenie własnych narzędzi lub własnego notatnika.
1. Przechowuj klucz API w zmiennej globalnej
Najpierw uruchamiamy środowisko i deklarujemy klucz API w zmiennej globalnej o nazwie „Oncrawl Token”. Następnie przygotowujemy się do dalszej części eksperymentu:
#@title Uzyskaj dostęp do Oncrawl API
#@markdown Podaj swój token API poniżej, aby umożliwić temu notatnikowi dostęp do Twoich danych Oncrawl:
# TWÓJ TOKEN DO ONCRAWL API
ONCRAWL_TOKEN = "" #@param {type:"string"}
!pip install więzienie
z IPython.display import clear_output
wyczyść_wyjście()
print('Wszystko wczytane.') 
2. Utwórz listę rozwijaną, aby wybrać projekt Oncrawl, z którym chcesz pracować
Następnie, używając tego klawisza, chcemy móc wybrać projekt, z którym chcemy się bawić, pobierając listę projektów i tworząc rozwijany widżet z tej listy. Uruchamiając drugi blok kodu, wykonaj następujące kroki:
- Wywołamy Oncrawl API, aby uzyskać listę projektów na koncie za pomocą klucza API, który właśnie został przesłany.
- Gdy już mamy listę projektów z odpowiedzi API, formatujemy ją jako listę, używając nazwy projektu oraz początkowego adresu URL projektu.
- Przechowujemy identyfikator projektu, który został podany w odpowiedzi.
- Budujemy rozwijane menu i pokazujemy je pod blokiem kodu.
#@title Wybierz witrynę do analizy, wybierając odpowiedni projekt Oncrawl
żądania importu
importuj więzienie
importuj ipywidgety jako widżety
importuj json
# Pobierz listę projektów
response = requests.get("https://app.oncrawl.com/api/v2/projects?limit={limit}&sort={sort}".format(
limit=1000,
sort='nazwa:asc'
),
headers={ 'Autoryzacja': 'Oficer '+ONCRAWL_TOKEN }
)
json_res = odpowiedź.json()
#przygotuj menu rozwijane, aby użytkownik mógł wybrać projekt
projekty = []
dla pozycji w json_res['projects']:
projekty.append(('{} - {}'.format(item['name'], item['start_url']), item['id']))
wyjście = widżety.Wyjście()
dropdown_purpose = widżety.Dropdown(opcje = projekty, description="Projekt: ")
def dropdown_project_eventhandler(zmiana):
output.clear_output()
z wyjściem:
wyświetlacz (projekty)
dropdown_purpose.observe(dropdown_project_eventhandler, names='wartość')
display(dropdown_purpose) Z rozwijanego menu, które to tworzy, możesz zobaczyć pełną listę projektów, do których klucz API ma dostęp. 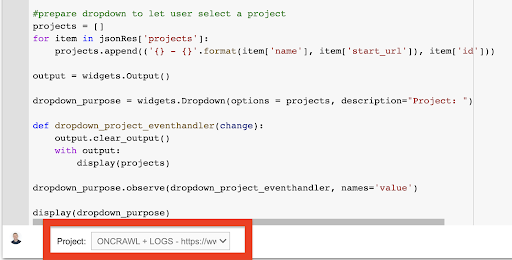
Na potrzeby dzisiejszej demonstracji używamy projektu demonstracyjnego opartego na witrynie Oncrawl.
3. Utwórz listę rozwijaną, aby wybrać profil indeksowania w projekcie, z którym chcesz pracować
Następnie zdecydujemy, którego profilu indeksowania użyć. Chcemy wybrać profil indeksowania w ramach tego projektu. Projekt demonstracyjny ma wiele różnych konfiguracji indeksowania: 
W tym przypadku przyjrzymy się projektowi, którego zespoły Oncrawl często używają do eksperymentów, więc wybiorę profil indeksowania używany przez zespół marketingowy do monitorowania wydajności witryny Oncrawl. Ponieważ ma to być najbardziej stabilny profil indeksowania, jest to dobry wybór w dzisiejszym eksperymencie.
Aby uzyskać profil indeksowania, użyjemy Oncrawl API, aby poprosić o ostatnie indeksowanie w każdym profilu indeksowania w projekcie:
- Przygotowujemy się do odpytywania Oncrawl API dla danego projektu.
- Poprosimy o wszystkie indeksowania zwrócone w kolejności malejącej zgodnie z datą ich „utworzenia w”.
żądania importu
importuj json
importuj ipywidgety jako widżety
id_projektu = dropdown_purpose.value
# Pobierz szczegóły projektów (w tym wszystkie indeksowania w projekcie)
projekt = requests.get("https://app.oncrawl.com/api/v2/projects/{}".format(project_id),
params=dict(include_nested_resources=True, sort="created_at:desc"),
headers={ 'Autoryzacja': 'Oficer '+ONCRAWL_TOKEN }).json()
# Grupa indeksuje według profilu indeksowania (nazwa indeksowania)
crawls_by_config = {}
próbować:
dla indeksowania w projekcie['crawls']:
if crawl['status'] in ["done"]:
jeśli crawl['crawl_config']['name'] nie znajduje się w crawls_by_config.keys():
crawls_by_config[crawl['crawl_config']['name']] = {'crawl_ids' : [], 'is_crawl_archived' : False}
if len(crawls_by_config[crawl['crawl_config']['name']]['crawl_ids']) == 0:
crawls_by_config[crawl['crawl_config']['name']]['crawl_ids'].append(crawl['id'])
if crawl['status'] == "zarchiwizowane":
crawls_by_config[crawl['crawl_config']['name']]['is_crawl_archived'] = Prawda
z wyjątkiem Wyjątku, jak e:
raise Exception("błąd {} , {}".format(e, projekt))
# Zbuduj listę dla rozwijanego wyboru
list = [("{} ({})".format(k, len(v['crawl_ids'])), k) for k, v in crawls_by_config.items()]
dropdown_crawl_configs = widżety.Dropdown(opcje = lista, opis="Konfiguracje indeksowania: ")
def dropdown_cc_eventhandler(zmiana):
output.clear_output()
z wyjściem:
display(crawls_by_config)
if len(crawls_by_config.values()) == 0:
print('Nie znaleziono indeksowania na żywo w tym projekcie')
dropdown_crawl_configs.observe(dropdown_cc_eventhandler, names='wartość')
display(dropdown_crawl_configs)Gdy ten kod zostanie uruchomiony, Oncrawl API odpowie nam listą indeksowań, malejąco według właściwości „created at”.
Następnie, ponieważ chcemy skupić się tylko na zakończonych indeksowaniach, przejdziemy przez listę indeksowań. Dla każdego indeksowania ze statusem „done” zapiszemy nazwę profilu indeksowania i będziemy przechowywać identyfikator indeksowania.
Będziemy przechowywać co najwyżej jedno indeksowanie według profilu indeksowania, aby nie ujawniać zbyt wielu indeksowań.
Rezultatem jest to nowe menu rozwijane utworzone z listy profili indeksowania w projekcie. Wybierzemy ten, który chcemy. To zajmie ostatnie indeksowanie przeprowadzone przez zespół marketingowy: 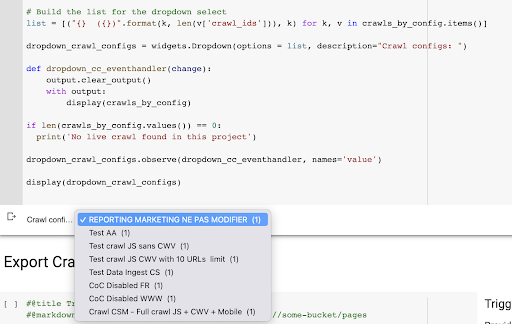
4. Zidentyfikuj ostatnie indeksowanie za pomocą profilu, którego chcemy użyć
Mamy już identyfikator indeksowania powiązany z ostatnim indeksowaniem w wybranym profilu. Jest ukryty w słowniku obiektów „crawl_by_config”. 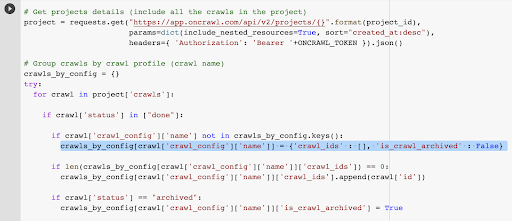
Możesz to łatwo sprawdzić w interfejsie: Znajdź ostatnie ukończone indeksowanie w tej analizie profilu. 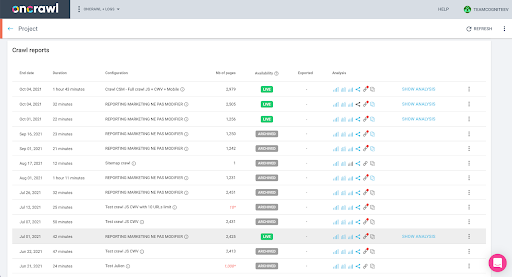
Jeśli klikniemy, aby wyświetlić analizę, zobaczymy, że identyfikator indeksowania kończy się na E617. 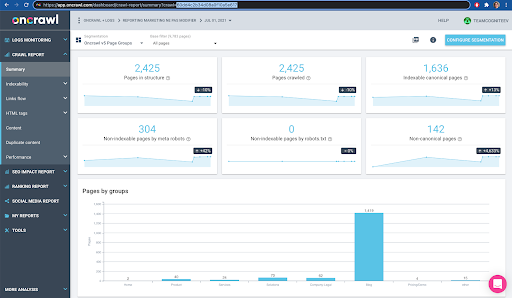
Zanotujmy tylko identyfikator indeksowania na potrzeby dzisiejszej demonstracji.
Oczywiście, jeśli już wiesz, co robisz, możesz pominąć kroki, które właśnie omówiliśmy, aby wywołać interfejs API Oncrawl w celu uzyskania listy projektów i listy indeksowań według profilu indeksowania: masz już identyfikator indeksowania z interfejs, a ten identyfikator to wszystko, czego potrzebujesz do uruchomienia eksportu.
Kroki, które przeszliśmy do tej pory, mają po prostu ułatwić proces uzyskiwania ostatniego indeksowania danego profilu indeksowania danego projektu, biorąc pod uwagę, do czego ma dostęp klucz API. Może to być przydatne, jeśli udostępniasz to rozwiązanie innym użytkownikom lub chcesz je zautomatyzować.
5. Eksportuj wyniki indeksowania
Teraz przyjrzymy się poleceniu eksportu:
#@title Uruchom eksport danych bigdata
#@markdown Podaj swój zasobnik GCS i prefiks gs://some-bucket/pages
# TWOJE WIADRO GCS
gcs_bucket = #@param {type:"string"}
gcs_prefix = #@param {type:"string"}
# Pobierz ostatni identyfikator indeksowania z danego projektu / profilu indeksowania
list_crawl_ids = crawls_by_config[dropdown_crawl_configs.value]['crawl_ids']
last_crawl_id = list_crawl_ids[0]
# Ładunek szablonu dla zapytania o eksport danych
ładowność = {
"data_export": {
"data_type": 'strona',
"resource_id": last_crawl_id,
"output_format": 'parkiet',
"cel": 'gcs',
"parametry_docelowe": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
# Uruchom eksport
export = requests.post("https://app.oncrawl.com/api/v2/account/data_exports", json=payload, headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json()
# Wyświetl odpowiedź API
wyświetlacz (eksport)
# Przechowuj identyfikator eksportu do wykorzystania w przyszłości
export_id = export['data_export']['id']Chcemy eksportować do zasobnika Cloud Storage, który skonfigurowaliśmy wcześniej.
W ramach tego wyeksportujemy strony dla ostatniego identyfikatora indeksowania:
- Ostatni identyfikator indeksowania uzyskuje się z listy identyfikatorów indeksowania, która jest przechowywana gdzieś w słowniku „crawls_by_config”, który został utworzony w kroku 3.
- Chcemy wybrać ten odpowiadający rozwijanemu menu w kroku 4, więc używamy atrybutu wartości z rozwijanego menu.
- Następnie wyodrębniamy atrybut crawl_ID. To jest lista. Na liście zachowamy 50 najlepszych pozycji. Musimy to zrobić, ponieważ w kroku 2, jak pamiętasz, podczas tworzenia słownika crawls_by_config przechowywaliśmy tylko jeden identyfikator indeksowania na nazwę konfiguracji.
Skonfigurowałem pola wejściowe, aby ułatwić podanie zasobnika i prefiksu lub folderu Google Cloud Storage, do którego chcemy wysłać eksport. 
Na potrzeby demonstracji dzisiaj będziemy pisać do folderu „mixed dataset”, w jednym z folderów, które już skonfigurowałem. Gdy ustawimy nasz zasobnik w Google Cloud Storage, przypomnisz sobie, że przygotowałem foldery do eksportu „linki” i do eksportu „stron”.
W przypadku pierwszego eksportu będziemy chcieli wyeksportować strony do folderu „pages” dla ostatniego identyfikatora indeksowania przy użyciu formatu pliku Parquet. 
W poniższych wynikach zobaczysz ładunek, który ma zostać wysłany do punktu końcowego eksportu danych, który jest punktem końcowym żądającym eksportu Big Data za pomocą klucza API:
# Ładunek szablonu dla zapytania o eksport danych
ładowność = {
"data_export": {
"data_type": 'strona',
"resource_id": last_crawl_id,
"output_format": 'parkiet',
"cel": 'gcs',
"parametry_docelowe": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
Zawiera kilka elementów, w tym typ zestawu danych, który chcesz wyeksportować. Możesz wyeksportować zbiór danych strony, zbiór danych linków, zbiór danych klastrów lub zbiór danych strukturalnych. Jeśli nie wiesz, co można zrobić, możesz wprowadzić tutaj błąd, a po wywołaniu interfejsu API otrzymasz komunikat z informacją, że wybór typu danych musi być stroną lub łączem, klastrem lub danymi strukturalnymi. Wiadomość wygląda tak:

{'fields': [{'message': 'Niepoprawny wybór. Musi być jedną z następujących: „strona”, „link”, „klaster”, „dane_strukturalne”.',
'nazwa': 'typ_danych',
'typ': 'invalid_choice'}],
„typ”: „invalid_request_parameters”}
Na potrzeby dzisiejszego eksperymentu wyeksportujemy zbiór danych strony i zbiór danych linków w oddzielnych eksportach.
Zacznijmy od zbioru danych strony. Kiedy uruchamiam ten blok kodu, wydrukowałem dane wyjściowe wywołania API, które wygląda tak:
{'data_export': {'data_type': 'strona',
„export_failure_reason”: Brak,
'id': 'XXXXXXXXXXXXXXX',
'output_format': 'parkiet',
'output_format_parameters': Brak,
„output_row_count”: Brak,
'rozmiar_wyjściowy_w_bajtach: 1634460016000,
'identyfikator_zasobu': '60dd4c2b34d08a0f10a5e617',
„status”: „WYMAGANY”,
„cel”: „gcs”,
'target_parameters': {'gcs_bucket': 'data-cms',
'gcs_prefix': 'MIXDATASET/strony/'}}}
To pozwala mi zobaczyć, że zażądano eksportu.
Jeśli chcemy sprawdzić status eksportu, jest to bardzo proste. Korzystając z identyfikatora eksportu, który zapisaliśmy na końcu tego bloku kodu, możemy w dowolnym momencie zażądać statusu eksportu za pomocą następującego wywołania API:
# STATUS EKSPORTU
export_status = requests.get("https://app.oncrawl.com/api/v2/account/data_exports/{}".format(export_id), headers={ 'Uprawnienie': 'Oficer '+ONCRAWL_TOKEN }).json ()
display(export_status)
Wskaże to status jako część zwróconego obiektu JSON:
{'data_export': {'data_type': 'strona',
„export_failure_reason”: Brak,
'id': 'XXXXXXXXXXXXXXX',
'output_format': 'parkiet',
'output_format_parameters': Brak,
„output_row_count”: Brak,
'output_size_in_bytes': Brak,
'requested_at': 1638350549000,
'identyfikator_zasobu': '60dd4c2b34d08a0f10a5e617',
„status”: „EKSPORT”,
„cel”: „gcs”,
'target_parameters': {'gcs_bucket': 'data-csm',
'gcs_prefix': 'MIXDATASET/strony/'}}} Po zakończeniu eksportu ( 'status': 'DONE' ) możemy wrócić do Google Cloud Storage.
Jeśli zajrzymy do naszego wiadra i przejdziemy do folderu „linki”, nie ma tu jeszcze niczego, ponieważ wyeksportowaliśmy strony. 
Gdy jednak zajrzymy do folderu „strony”, widzimy, że eksport się powiódł. Mamy plik Parkiet: 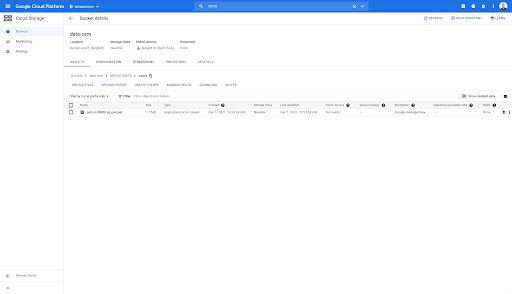
Na tym etapie zbiór danych stron jest gotowy do zaimportowania w BigQuery, ale najpierw powtórzymy powyższe kroki, aby uzyskać plik Parquet z linkami:
- Upewnij się, że ustawiłeś prefiks linków.
- Wybierz typ danych „link”.
- Uruchom ten blok kodu ponownie, aby zażądać drugiego eksportu.

Spowoduje to utworzenie pliku Parquet w folderze „linki”.
Tworzenie zbiorów danych BigQuery
Podczas trwania eksportu możemy przejść do przodu i zacząć tworzyć zbiory danych w BigQuery oraz importować pliki Parquet do osobnych tabel. Potem będziemy razem łączyć stoły.
Teraz chcemy pobawić się Google Big Query, które jest dostępne w ramach Google Cloud Platform. Możesz użyć paska wyszukiwania u góry ekranu lub przejść bezpośrednio do https://console.cloud.google.com/bigquery.
Tworzenie zbioru danych do Twojej pracy
Musimy utworzyć zbiór danych w Google BigQuery: 
Musisz podać nazwę zbiorowi danych i wybrać lokalizację, w której będą przechowywane dane. Jest to ważne, ponieważ warunkuje miejsce przetwarzania danych i nie można ich zmienić. Może to mieć wpływ, jeśli Twoje dane zawierają informacje objęte RODO lub innymi przepisami dotyczącymi prywatności. 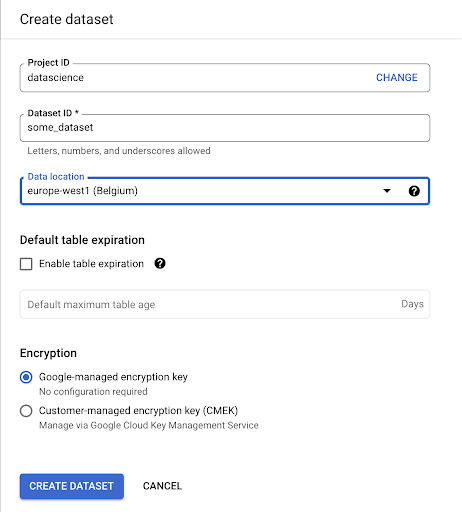
Ten zbiór danych jest początkowo pusty. Gdy go otworzysz, będziesz mógł utworzyć tabelę, udostępnić zestaw danych, skopiować, usunąć i tak dalej.
Tworzenie tabel dla swoich danych
W tym zbiorze danych utworzymy tabelę. 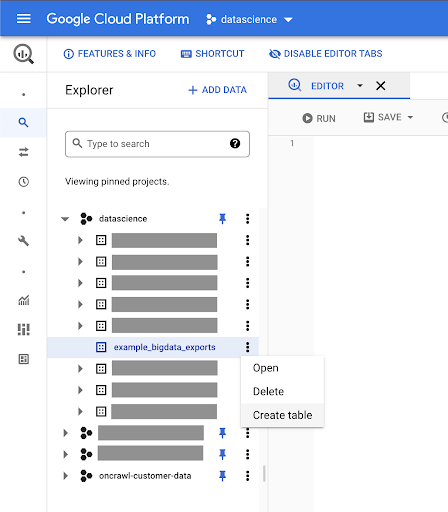
Możesz utworzyć pustą tabelę, a następnie podać schemat. Schemat to definicja kolumn w tabeli. Możesz zdefiniować własny lub przeglądać Google Cloud Storage, aby wybrać schemat z pliku.
Wykorzystamy tę ostatnią opcję. Przejdziemy do naszego zasobnika, a następnie do folderu „pages”. Wybierzmy plik stron. Jest tylko jeden plik, więc możemy wybrać tylko jeden, ale gdyby eksport wygenerował kilka plików, moglibyśmy wybrać je wszystkie. 
Kiedy wybieramy plik, automatycznie wykrywa, że jest on w formacie pliku Parquet. Chcemy stworzyć tabelę o nazwie „pages”, a schemat zostanie zdefiniowany przez plik źródłowy. 
Kiedy ładujemy plik Parquet, osadza on schemat. Innymi słowy, definicja kolumn tworzonej przez nas tabeli zostanie wywnioskowana ze schematu, który już istnieje w pliku Parquet. Tu właśnie dzieje się część magii.
Przejdźmy po prostu do przodu i po prostu utwórzmy tabelę z pliku Parquet. 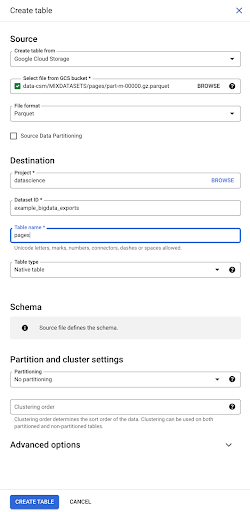
Na lewym pasku bocznym widzimy teraz, że w naszym zestawie danych pojawiła się tabela, która jest dokładnie tym, czego chcemy:
Tak więc mamy teraz schemat tabeli stron ze wszystkimi polami, które zostały automatycznie wywnioskowane z pliku Parquet. Mamy Inrank, głębokość strony, jeśli strona jest przekierowaniem i tak dalej i tak dalej: 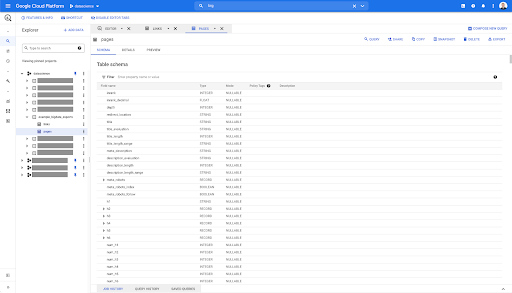
Większość z tych pól jest taka sama, jak pola udostępniane w Data Studio za pośrednictwem łącznika Oncrawl Data Studio i są takie same, jak te widoczne w Eksploratorze danych w interfejsie Oncrawl. 
Istnieją jednak pewne różnice. Kiedy bawimy się eksportem surowych dużych danych, masz wszystkie surowe dane.
- W Data Studio niektóre pola są zmieniane, niektóre są ukrywane, a niektóre są dodawane, na przykład stan.
- W Eksploratorze danych niektóre pola nazywamy „polami wirtualnymi”, co oznacza, że mogą być rodzajem skrótu do pola bazowego. Te pola wirtualne dostępne w Eksploratorze danych nie będą wyświetlane w schemacie, ale można je ponownie utworzyć na podstawie tego, co jest dostępne w pliku Parquet.
Zamknijmy teraz tę tabelę i zróbmy to ponownie dla linków.
W przypadku tabeli linków schemat jest nieco mniejszy. 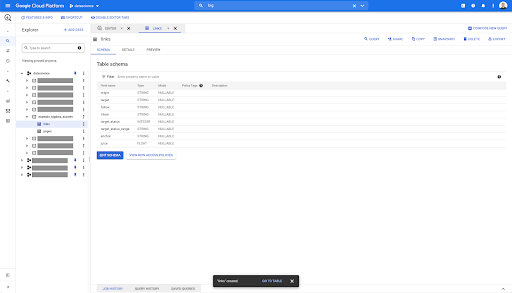
Zawiera tylko następujące pola:
- pochodzenie linku,
- cel linku,
- Następująca właściwość,
- Własność wewnętrzna,
- Status docelowy,
- Zakres statusu docelowego,
- Tekst zakotwiczenia i
- Sok lub kapitał kupiony przez link.
Kliknięcie karty podglądu w dowolnej tabeli w BigQuery powoduje wyświetlenie podglądu tabeli bez wysyłania zapytań do bazy danych: 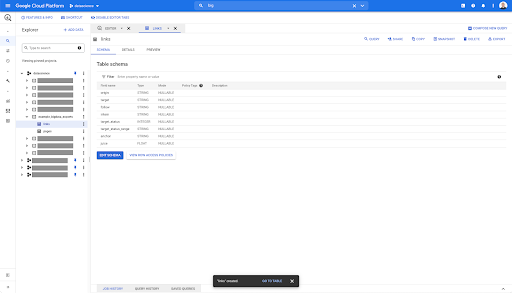
Daje to szybki podgląd tego, co jest w nim dostępne. W podglądzie tabeli linków powyżej masz podgląd każdego wiersza i wszystkich kolumn.
W niektórych zestawach danych Oncrawl możesz zobaczyć wiersze obejmujące kilka wierszy. Nie mam dla ciebie przykładu, ale jeśli tak jest, to dlatego, że niektóre pola zawierają listę wartości. Na przykład na liście nagłówków h2 na stronie jeden wiersz obejmuje kilka wierszy w Big Query. Przyjrzymy się temu później, jeśli zobaczymy przykład.
Tworzę zapytanie
Jeśli nigdy nie tworzyłeś zapytania w BigQuery, nadszedł czas, aby się nim pobawić i zapoznać się z jego działaniem. BigQuery używa SQL do wyszukiwania danych.
Jak działają zapytania
Jako przykład spójrzmy na wszystkie adresy URL i ich rangę…
WYBIERZ URL, ranking...
ze zbioru danych stron…
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` ...
gdzie kod stanu strony to 200…
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 ...
i zachowaj tylko pierwsze 10 wyników:
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 10
Po uruchomieniu tego zapytania otrzymamy pierwsze 10 wierszy listy stron, których kod stanu to 200.
Każda z tych właściwości może być modyfikowana. f Chcę 1000 wierszy zamiast 10, mogę ustawić 1000 wierszy:
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 1000
Jeśli chcę posortować, mogę to zrobić za pomocą „porządku według”: to da mi wszystkie wiersze uporządkowane według malejącej kolejności Inrank.
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.links` ORDER BY inrank DESC LIMIT 1000
To jest moje pierwsze zapytanie. Mogę to zapisać, jeśli chcę, co da mi możliwość ponownego wykorzystania tego zapytania później, jeśli zechcę: 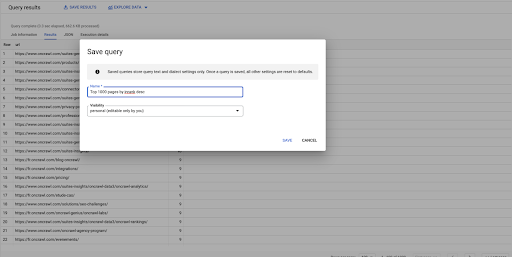
Używanie zapytań do odpowiedzi na proste pytania: Lista wszystkich wewnętrznych linków do stron o statusie 301
Teraz, gdy wiemy, jak skomponować zapytanie, wróćmy do naszego pierwotnego problemu.
Chcieliśmy odpowiedzieć na pytania dotyczące danych, proste lub złożone. Zacznijmy od prostego pytania, na przykład „jakie są wszystkie wewnętrzne linki, które prowadzą do stron o statusie 301 (przekierowane) i gdzie mogę je znaleźć?”
Tworzenie nowego zapytania
Zaczniemy od zbadania, jak to działa.
Poproszę kolumny dla następujących elementów z bazy „linki”:
- Początek
- Cel
- Kod stanu docelowego
SELECT źródło, cel, status_docelowy FROM `datascience-oncrawl.example_bigdata_exports.links`
Chcę ograniczyć je tylko do linków wewnętrznych, ale wyobraźmy sobie, że nie pamiętam nazwy kolumny ani wartości wskazującej, czy link jest wewnętrzny czy zewnętrzny. Mogę przejść do schematu, aby go sprawdzić, i użyć podglądu, aby wyświetlić wartość: 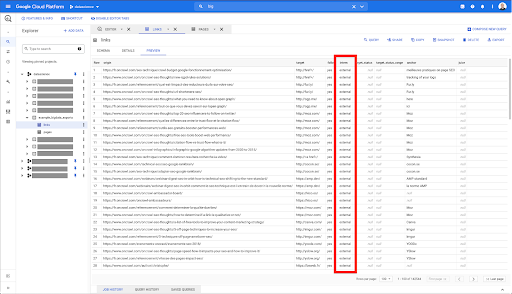
To mówi mi, że kolumna nosi nazwę „intern”, a możliwy zakres wartości to „external” lub „internal”.
W moim zapytaniu chcę określić „gdzie praktykant jest wewnętrzny” i na razie ograniczyć wyniki do pierwszych 100:
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE staż LIKE 'internal' LIMIT 100
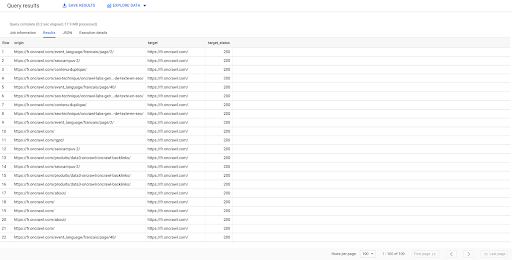
Powyższy wynik pokazuje listę linków wraz z ich statusem docelowym. Mamy tylko linki wewnętrzne, a mamy ich 100, zgodnie z zapytaniem.
Jeśli chcemy mieć tylko wewnętrzne linki prowadzące do przekierowanych stron, możemy powiedzieć „gdzie stażysta jak wewnętrzny i docelowy status wynosi 301”:
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE 'internal' AND target_status = 301
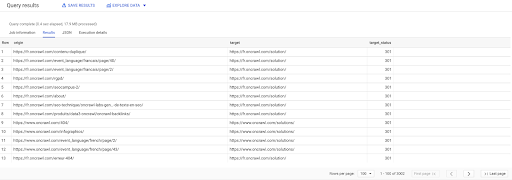
Jeśli nie wiemy, ile z nich istnieje, możemy uruchomić to nowe zapytanie i zobaczymy, że istnieją 3002 linki wewnętrzne o statusie docelowym 301.
Dołączanie do stolików: znajdowanie końcowych kodów statusu linków prowadzących do przekierowanych stron
W witrynie internetowej często znajdują się linki do stron, które są przekierowywane. Chcemy znać kod stanu strony, na którą są przekierowywani (lub końcowy docelowy adres URL).
W jednym zestawie danych masz informacje o linkach: stronę początkową, stronę docelową i jej kod stanu (np. 301), ale nie adres URL, na który wskazuje przekierowana strona. A w drugim masz informacje o przekierowaniach i ich ostatecznych celach, ale nie oryginalną stronę, na której znaleziono link do nich.
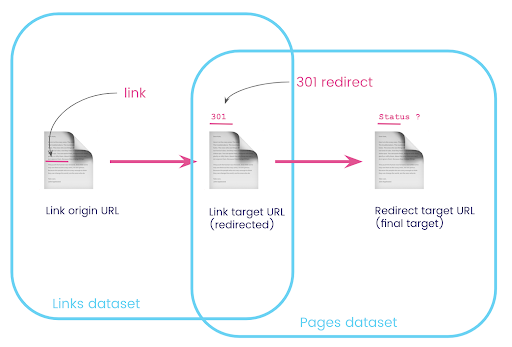
Rozbijmy to:
Po pierwsze, chcemy mieć linki do przekierowań. Zapiszmy to. Chcemy:
- Pochodzenie.
- Cel. Cel musi mieć kod stanu 301.
- Ostateczny cel przekierowania.
Innymi słowy, w zestawie danych linków chcemy:
- Pochodzenie linku
- Cel linku
W zbiorze danych stron chcemy:
- Wszystkie cele, które są przekierowywane
- Ostateczny cel przekierowania
To da nam zapytanie takie jak:
SELECT url, final_redirect_location, final_redirect_status FROM `datascience-oncrawl.example_bigdata_exports.pages` AS pages WHERE status_code = 301 OR status_code = 302
To powinno dać mi pierwszą część równania.
Teraz potrzebuję wszystkich linków prowadzących do strony, które są wynikiem właśnie utworzonego zapytania, używając aliasów dla moich zestawów danych i łącząc je w docelowym adresie URL łącza i adresie URL strony. Odpowiada to nakładającemu się obszarowi dwóch zestawów danych na diagramie na początku tej sekcji.
WYBIERZ linki.origin, strony.url, pages.final_redirect_location, pages.final_redirect_status Z `datascience-oncrawl.example_bigdata_exports.pages` Strony AS PRZYSTĄP `datascience-oncrawl.example_bigdata_exports.links` łącza AS NA links.target = pages.url GDZIE pages.status_code = 301 LUB pages.status_code = 302 ZAMÓW PRZEZ pochodzenie ASC
W wynikach zapytania mogę zmienić nazwy kolumn, aby były bardziej przejrzyste, ale już widzę, że mam link ze strony w pierwszej kolumnie, który prowadzi do strony w drugiej kolumnie, która z kolei jest przekierowywana do strona w trzeciej kolumnie. W czwartej kolumnie mam kod statusu ostatecznego celu: 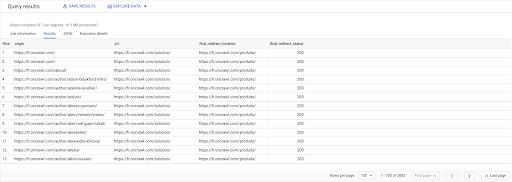
Teraz mogę powiedzieć, które linki prowadzą do przekierowanych stron, które nie prowadzą do 200 stron. Może są to na przykład 404, co daje mi listę priorytetowych linków do poprawienia.
Widzieliśmy wcześniej, jak zapisać zapytanie. Możemy również zapisać wyniki, do 16000 wierszy wyników: 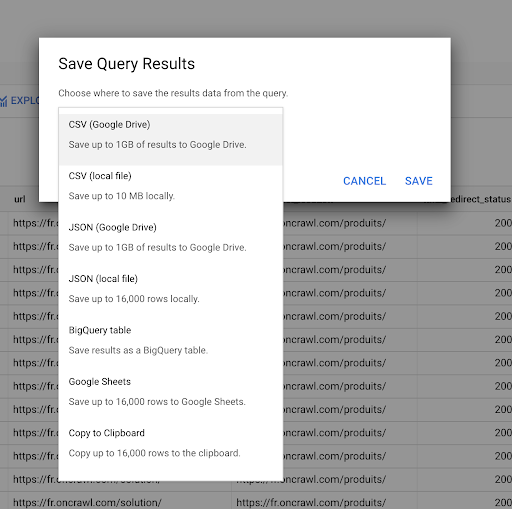
Wyniki te możemy następnie wykorzystać na wiele różnych sposobów. Oto kilka przykładów:
- Możemy zapisać to lokalnie jako plik CSV lub JSON.
- Możemy zapisać go jako arkusz kalkulacyjny Arkuszy Google i udostępnić go reszcie zespołu.
- Możemy go również wyeksportować bezpośrednio do Data Studio.
Dane jako przewaga strategiczna
Przy wszystkich tych możliwościach strategiczne wykorzystanie odpowiedzi na złożone pytania jest łatwe. Być może masz już doświadczenie w łączeniu wyników BigQuery z Data Studio lub innymi platformami wizualizacji danych albo masz już proces, który przekazuje informacje do zespołu inżynierów, a nawet do przepływu pracy analizy biznesowej lub analizy danych.
Jeśli kroki opisane w tym artykule zostały uwzględnione w ramach procesu, pamiętaj, że możesz je zautomatyzować w BigQuery: wszystkie czynności, które wykonaliśmy w tym artykule, są również dostępne za pośrednictwem interfejsu BigQuery API. Oznacza to, że mogą być uruchamiane programowo jako część skryptu lub niestandardowego narzędzia.
Niezależnie od dalszych kroków, pierwszym krokiem jest zawsze dostęp do surowych danych SEO i witryny. Wierzymy, że dostęp do danych jest jedną z najważniejszych części analizy technicznej: dzięki Oncrawl zawsze będziesz miał pełny dostęp do swoich surowych danych.
Dostęp do danych oznacza również, że możesz wyjść poza to, co jest możliwe w interfejsie Oncrawl i zbadać wszystkie relacje między Twoimi danymi, bez względu na to, jak złożone są zadawane pytania.