
Wprowadzenie do analizy plików dziennika SEO
Opublikowany: 2021-05-17Analiza logów to najdokładniejszy sposób analizy, w jaki sposób wyszukiwarki czytają nasze witryny. Na co dzień SEO, marketerzy cyfrowi i specjaliści od analityki internetowej korzystają z narzędzi, które pokazują diagramy dotyczące ruchu, zachowań użytkowników i konwersji. SEO zazwyczaj starają się zrozumieć, w jaki sposób Google indeksuje ich witrynę za pośrednictwem Google Search Console.
Więc… dlaczego SEO miałby analizować inne narzędzia, aby sprawdzić, czy wyszukiwarka poprawnie odczytuje witrynę? Ok, zacznijmy od podstaw.
Co to są pliki dziennika?
Plik dziennika to plik, w którym serwer WWW zapisuje wiersz dla każdego zasobu w witrynie, którego żądają boty lub użytkownicy. Każdy wiersz zawiera dane dotyczące żądania, które mogą obejmować:
IP rozmówcy, data, wymagany zasób (strona, .css, .js, …), klient użytkownika, czas odpowiedzi, …
Wiersz będzie wyglądał mniej więcej tak:
66.249.**.** - - [13/Apr/2021:00:07:31 +0200] "GET /***/x_*** HTTP/1.1" 200 40960 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "www.***.it" "-"
Możliwość indeksowania i aktualizacji
Każda strona ma trzy podstawowe statusy SEO:
- indeksowalny
- indeksowalny
- rangowalny
Z perspektywy analizy logów wiemy, że strona, aby została zaindeksowana, musi zostać odczytana przez bota. Podobnie treść już zindeksowana przez wyszukiwarkę musi zostać ponownie zindeksowana, aby mogła zostać zaktualizowana w indeksach wyszukiwarki.
Niestety w Google Search Console nie mamy tego poziomu szczegółowości: możemy sprawdzić, ile razy Googlebot odczytał stronę w witrynie w ciągu ostatnich trzech miesięcy i jak szybko odpowiadał serwer sieciowy.
Jak możemy sprawdzić, czy bot przeczytał stronę? Oczywiście za pomocą plików dziennika i analizatora plików dziennika.
Dlaczego SEO muszą analizować pliki dziennika?
Analiza pliku dziennika pozwala SEO (i administratorom systemu również) zrozumieć:
- Dokładnie to, co czyta bot
- Jak często bot to czyta
- Ile kosztują indeksowania pod względem czasu (ms)
Narzędzie do analizy dzienników umożliwia analizę dzienników poprzez grupowanie informacji według „ścieżki”, według typu pliku lub według czasu odpowiedzi. Świetne narzędzie do analizy logów pozwala nam również łączyć informacje uzyskane z plików logów z innymi źródłami danych, takimi jak Google Search Console (kliknięcia, wyświetlenia, średnie pozycje) czy Google Analytics.
Analizator logów Oncrawl
 Ucz się więcej
Ucz się więcejNa co zwracać uwagę w plikach dziennika?
Jedną z głównych ważnych informacji w plikach dziennika jest to, czego nie ma w plikach dziennika. Naprawdę nie żartuję. Pierwszym krokiem do zrozumienia, dlaczego strona nie jest indeksowana lub nie jest aktualizowana do najnowszej wersji, jest sprawdzenie, czy bot (na przykład Googlebot) ją przeczytał.
Następnie, jeśli strona jest często aktualizowana, ważne może być sprawdzenie, jak często bot czyta stronę lub sekcję witryny.
Następnym krokiem jest sprawdzenie, które strony są najczęściej czytane przez boty. Śledząc je, możesz sprawdzić, czy te strony:
- zasługują na tak częste czytanie
- lub są czytane tak często, ponieważ coś na stronie powoduje ciągłe, niekontrolowane zmiany
Na przykład kilka miesięcy temu witryna, nad którą pracowałem, miała bardzo wysoką częstotliwość odczytywania przez boty dziwnego adresu URL. Bot ujawnił, że ta strona pochodzi z adresu URL utworzonego przez skrypt JS, i że ta strona została opatrzona znacznikami wartości debugowania, które zmieniały się za każdym razem, gdy strona była ładowana… Po tym odkryciu dobry SEO z pewnością znajdzie odpowiednie rozwiązanie, aby to naprawić indeksować dziurę budżetową.
Budżet indeksowania
Budżet indeksowania? Co to jest? Każda strona ma swój metaforyczny budżet związany z wyszukiwarkami i ich botem. Tak: Google ustala rodzaj budżetu dla Twojej witryny. Nie jest to nigdzie rejestrowane, ale można to „policzyć” na dwa sposoby:
- sprawdzanie raportu statystyk indeksowania Google Search Console
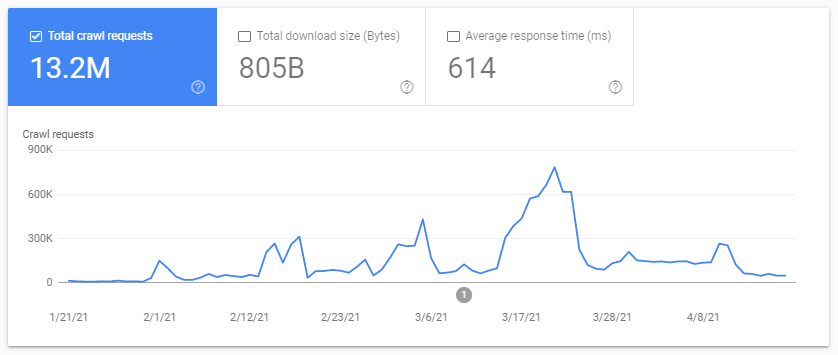
- sprawdzanie plików dziennika, grepowanie ( filtrowanie ) ich przez klienta użytkownika zawierającego „Googlebot” ( najlepsze wyniki uzyskasz, jeśli upewnisz się, że te klienty użytkownika pasują do poprawnych adresów IP Google… )
Budżet indeksowania zwiększa się, gdy witryna jest aktualizowana interesującą zawartością lub gdy regularnie aktualizuje zawartość lub gdy witryna otrzymuje dobre linki zwrotne.
W jaki sposób budżet indeksowania jest wykorzystywany w witrynie można zarządzać:
- linki wewnętrzne (follow / nofollow też!)
- noindex / kanoniczny
- robots.txt (ostrożnie: to „blokuje” klienta użytkownika)
Strony zombie
Dla mnie „strony zombie” to wszystkie strony, które od dłuższego czasu nie miały żadnego ruchu organicznego ani wizyt botów, ale mają wewnętrzne linki do nich.
Ten typ strony może zużywać zbyt duży budżet indeksowania i niepotrzebnie uzyskiwać pozycję strony z powodu wewnętrznych linków. Sytuację tę można rozwiązać:
- Jeśli te strony są przydatne dla użytkowników odwiedzających witrynę, możemy ustawić je na noindex, a wewnętrzne linki do nich jako nofollow ( lub użyć disallow robots.txt, ale bądź ostrożny… )
- Jeśli te strony nie są przydatne dla użytkowników odwiedzających witrynę, możemy je usunąć (i zwrócić kod stanu 410 lub 404) oraz usunąć wszystkie linki wewnętrzne.
Dzięki Oncrawl możemy stworzyć „raport zombie” na podstawie:
- Wyciski GSC
- Kliknięcia GSC
- Sesje GA
Możemy również użyć zdarzeń dziennika, aby odkryć strony zombie: możemy na przykład zdefiniować filtr 0 zdarzeń. Jednym z najłatwiejszych sposobów na to jest utworzenie segmentacji. W poniższym przykładzie filtruję wszystkie strony według następujących kryteriów: brak trafień Googlebota, ale z Inrank (oznacza to, że te strony mają wewnętrzne linki, które na nie prowadzą). 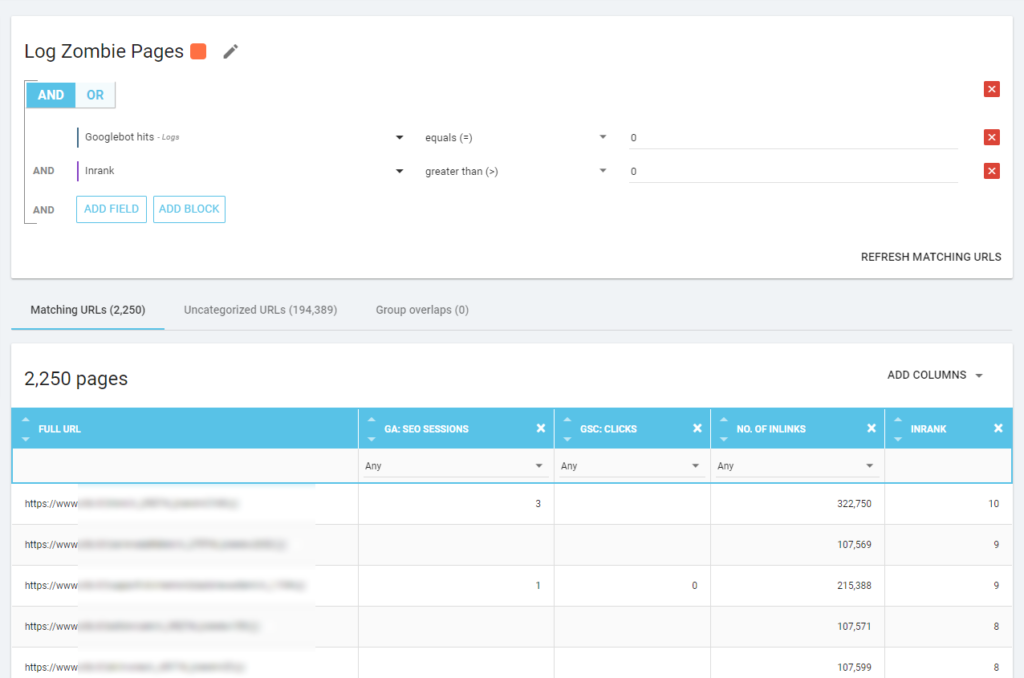
Teraz możemy używać tej segmentacji we wszystkich raportach Oncrawl. Pozwala nam to uzyskać wgląd w dowolną grafikę, na przykład: ile „stron dziennika zombie” zwraca kod statusu 200? 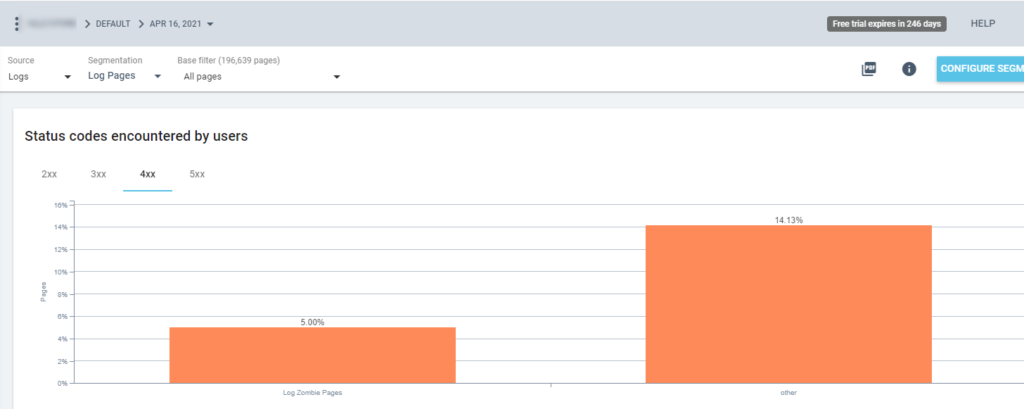
Strony osierocone
Dla mnie „strony osierocone”, na które warto uważnie się przyjrzeć, to wszystkie strony, które mają wysoką wartość pod względem ważnych wskaźników (sesja GA, wyświetlenie GSC, odwiedziny w logach,…), które nie mają żadnych wewnętrznych linków wskazujących na ich udział w rankingu strony i wskaż znaczenie strony.
Podobnie jak w przypadku „stron zombie”, aby utworzyć raport oparty na dzienniku, najlepszym sposobem jest utworzenie nowej segmentacji. 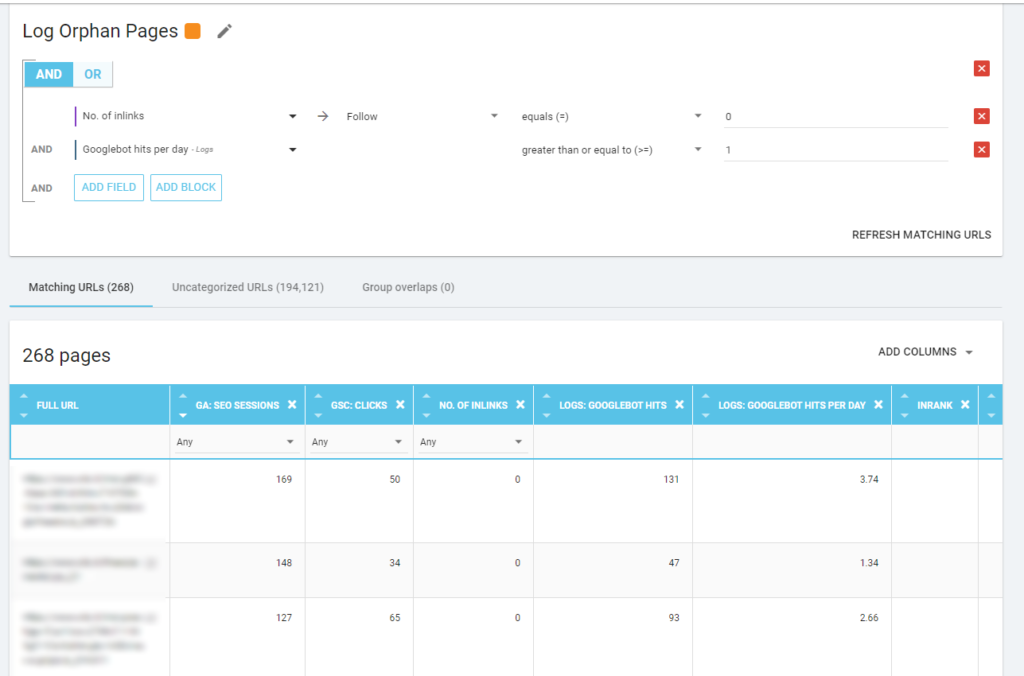
WOW, ile stron z sesjami i hitami i bez linków!
Sprawdzając raport oparty na „Zero Follow Inlinks”, zwróć uwagę na stan indeksowania: czy Oncrawl był w stanie zindeksować całą witrynę, czy tylko kilka stron? Możesz to zobaczyć na głównej stronie projektu: 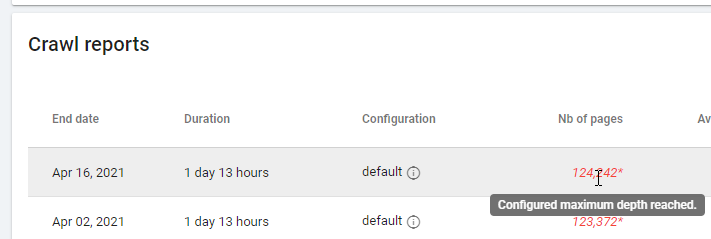
Jeśli maksymalna głębokość została osiągnięta:

- Sprawdź konfigurację indeksowania
- Sprawdź strukturę swojej witryny
Pliki dziennika i Oncrawl
Co Oncrawl oferuje w swoich domyślnych pulpitach nawigacyjnych?
Dziennik na żywo
Ten pulpit nawigacyjny jest przydatny do sprawdzania kluczowych informacji o tym, jak boty czytają Twoje witryny, gdy tylko boty odwiedzą witrynę i zanim informacje z plików dziennika zostaną całkowicie przetworzone. Aby uzyskać jak najwięcej z tego, zalecam częste przesyłanie plików dziennika: możesz to zrobić przez FTP, przez konektory, takie jak ten dla Amazon S3, lub możesz to zrobić ręcznie za pomocą interfejsu internetowego.
Pierwszy wykres pokazuje, jak często Twoja witryna jest czytana i przez którego bota. W poniższym przykładzie możemy porównać dostępy stacjonarne i mobilne. W tym przypadku wysłaliśmy do Oncrawl pliki dziennika przefiltrowane tylko pod kątem Googlebota: 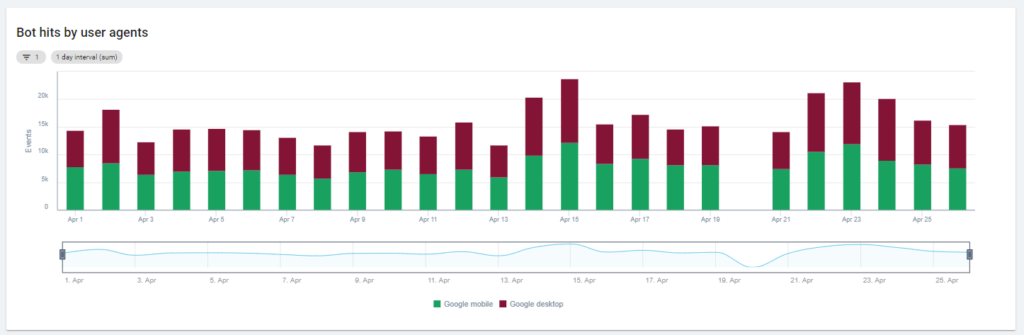
Ciekawe, że liczba odczytów z urządzeń mobilnych jest nadal bardzo wysoka: czy to normalne? To zależy… Witryna, którą analizujemy, nadal znajduje się w „indeksie mobile-first”, ale nie jest w pełni responsywną witryną: jest to dynamiczna witryna obsługująca (jak nazywa ją Google), a Google nadal sprawdza obie wersje!
Innym ciekawym diagramem jest „Trafienia botów według grup stron”. Domyślnie Oncrawl tworzy grupy na podstawie ścieżek URL. Możemy jednak ustawić grupy ręcznie, aby pogrupować adresy URL, których wspólna analiza jest najbardziej sensowna. 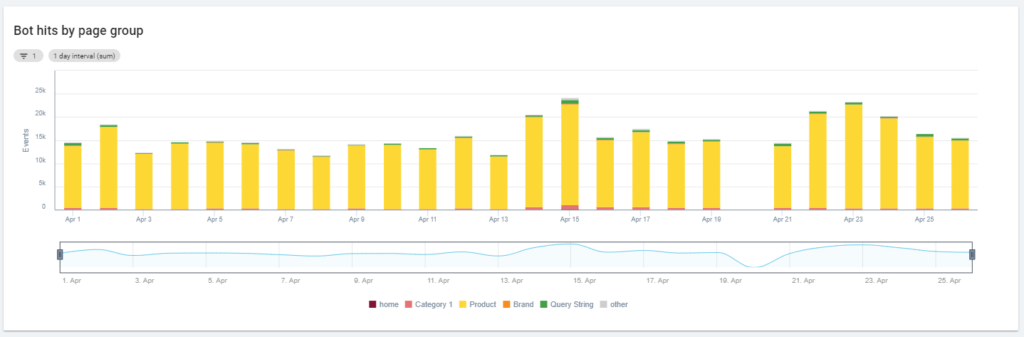
Jak widać, żółty wygrywa! Reprezentuje adresy URL ze ścieżką produktu, więc to normalne, że ma tak duży wpływ, zwłaszcza że mamy płatne kampanie produktowe Google.
I… tak, właśnie potwierdziliśmy, że Google używa standardowego Googlebota do sprawdzania stanu produktu związanego z plikiem danych sprzedawcy!
Zachowanie indeksowania
Ten pulpit nawigacyjny zawiera informacje podobne do „Dziennika na żywo”, ale informacje te zostały w pełni przetworzone i są agregowane według dnia, tygodnia lub miesiąca. Tutaj możesz ustawić okres dat (początek/koniec), który może cofnąć się w czasie tak daleko, jak tylko chcesz. Istnieją dwa nowe diagramy do dalszej analizy logów:
- Zachowanie indeksowania: aby sprawdzić stosunek między zindeksowanymi stronami a nowo zindeksowanymi stronami
- Częstotliwość indeksowania dziennie
Najlepszym sposobem odczytania tych diagramów jest połączenie wyników z działaniami w witrynie:
- Przeniosłeś strony?
- Czy zaktualizowałeś niektóre sekcje?
- Czy opublikowałeś nowe treści?
wpływ SEO
W przypadku SEO ważne jest, aby monitorować, czy zoptymalizowane strony są czytane przez boty, czy nie. Jak pisaliśmy o „stronach osieroconych”, ważne jest, aby upewnić się, że najważniejsze/zaktualizowane strony są czytane przez boty, tak aby najbardziej aktualne informacje były dostępne dla wyszukiwarek w celu uzyskania rankingu.
Oncrawl wykorzystuje koncepcję „Aktywnych stron”, aby wskazać strony, które otrzymują ruch organiczny z wyszukiwarek. Zaczynając od tej koncepcji, pokazuje kilka podstawowych liczb, takich jak:
- Wizyty SEO
- Aktywne strony SEO
- Wskaźnik aktywności SEO (odsetek aktywnych stron wśród wszystkich zindeksowanych stron)
- Fresh Rank (średni czas, jaki upływa od pierwszego przeczytania strony przez bota do pierwszej organicznej wizyty)
- Aktywne strony nie zostały zindeksowane
- Nowo aktywne strony
- Częstotliwość indeksowania aktywnych stron na dzień
Zgodnie z filozofią Oncrawl, jednym kliknięciem możemy wejść głęboko w jezioro informacji, przefiltrowane według danych, na które kliknęliśmy! Na przykład: które aktywne strony nie zostały zindeksowane? Jedno kliknięcie… 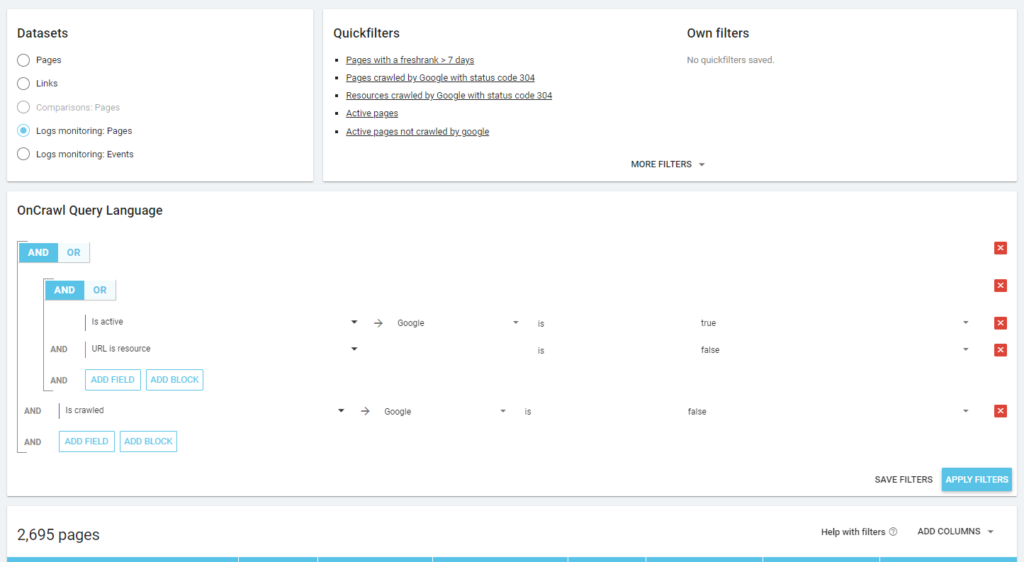
Poczytalność eksploracji
Ten ostatni pulpit nawigacyjny pozwala nam sprawdzić jakość indeksowania bo, a dokładniej, jak dobrze witryna prezentuje się w wyszukiwarkach:
- Analiza kodu statusu
- Analiza kodu statusu według dnia
- Analiza kodu statusu według grupy stron
- Analiza czasu odpowiedzi
Do dobrej pracy SEO konieczne jest:
- zmniejszyć liczbę 301 odpowiedzi z linków wewnętrznych
- usuń odpowiedzi 404/410 z linków wewnętrznych
- zoptymalizuj czas odpowiedzi, ponieważ jakość indeksowania przez Googlebota jest bezpośrednio powiązana z czasem odpowiedzi: spróbuj skrócić czas odpowiedzi w swojej witrynie o połowę, a zobaczysz (za kilka dni), że liczba zindeksowanych stron podwoi się.
Nauka o analizie logów i Eksploratorze danych Oncrawl
Do tej pory widzieliśmy standardowe raporty Oncrawl i jak z nich korzystać, aby uzyskać niestandardowe informacje za pomocą segmentacji i grup stron.
Ale sednem analizy logów jest zrozumienie, jak znaleźć coś złego. Zazwyczaj punktem wyjścia analizy jest sprawdzenie szczytów i porównanie ich z ruchem i celami:
- większość zindeksowanych stron
- najmniej zindeksowanych stron
- większość zindeksowanych zasobów (nie stron)
- częstotliwości indeksowania według typu pliku
- wpływ kodów statusu 3xx / 4xx
- wpływ kodów stanu 5xx
- wolniej indeksowane strony
- …
Chcesz zejść głębiej? Dobrze… musisz dodać dane. A Oncrawl oferuje naprawdę potężne narzędzie, takie jak Eksplorator danych.
Jak widać na poprzednim zrzucie ekranu (aktywne strony, które nie zostały zindeksowane), możesz tworzyć wszystkie raporty, które chcesz na podstawie swojej struktury analizy.
Na przykład:
- najgorsze strony z ruchem organicznym z dużą ilością indeksowania przez boty
- najlepsze strony ruchu organicznego ze zbyt dużym indeksowaniem przez boty
- wolniejsze strony z dużą ilością wyświetleń SERP
- …
Poniżej możesz zobaczyć, jak sprawdziłem, które strony są najczęściej indeksowane pod względem liczby sesji SEO: 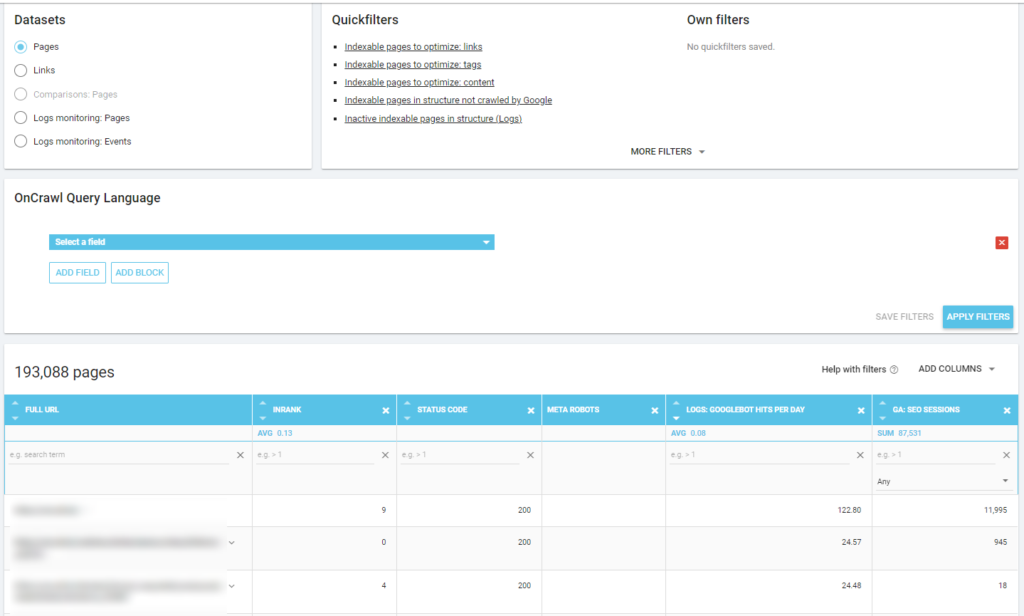
Na wynos
Analiza logów nie jest ściśle techniczna: aby zrobić to w najlepszy możliwy sposób, musimy połączyć umiejętności techniczne, umiejętności SEO i umiejętności marketingowe.
Zbyt często analiza jest wykluczana z „listy kontrolnej SEO”, ponieważ nasz klient nie ma dostępu do plików dziennika lub może być kosztowną analizą.
W rzeczywistości logi są jedynymi źródłami, z których można naprawdę sprawdzić, dokąd trafiają boty na naszych stronach, i dowiedzieć się, jak reagują na nie nasze serwery.
Narzędzie takie jak Oncrawl może znacznie zmniejszyć wymagania techniczne: po prostu prześlij pliki dziennika i zacznij je analizować!