
워드 벡터란 무엇이며 구조화된 마크업이 이를 어떻게 활용하는가
게시 됨: 2021-07-28단어 벡터를 어떻게 정의합니까? 이번 포스트에서는 단어 벡터의 개념을 소개하겠습니다. 다양한 유형의 단어 임베딩과 더 중요한 것은 단어 벡터의 기능에 대해 알아보겠습니다. 그런 다음 단어 벡터가 SEO에 미치는 영향을 확인할 수 있으며, 이를 통해 구조화된 데이터에 대한 Schema.org 마크업이 SEO에서 단어 벡터를 활용하는 데 어떻게 도움이 되는지 이해할 수 있습니다.
이 주제에 대해 더 자세히 알고 싶다면 이 게시물을 계속 읽으십시오.
바로 뛰어들자.
단어 벡터란 무엇입니까?
단어 벡터(단어 임베딩이라고도 함)는 의미가 유사한 단어가 동일한 표현을 갖도록 하는 단어 표현 유형입니다.
간단히 말해서 단어 벡터는 특정 단어의 벡터 표현입니다.
Wikipedia에 따르면:
텍스트 분석을 위한 단어를 표현하기 위해 자연어 처리(NLP)에서 사용되는 기술로, 일반적으로 벡터 공간에서 가까운 단어가 유사한 의미를 가질 수 있도록 단어의 의미를 인코딩하는 실수 값 벡터입니다.
다음 예는 이것을 더 잘 이해하는 데 도움이 될 것입니다.
다음과 같은 유사한 문장을 보십시오.
좋은 하루 되세요 . 좋은 하루 되세요.
그들은 거의 다른 의미를 가지고 있습니다. 완전한 어휘를 구성하면(V라고 합시다) 모든 단어를 결합하는 V = {Have, good, great, day}가 됩니다. 다음과 같이 단어를 인코딩할 수 있습니다.
단어의 벡터 표현은 1이 단어가 존재하는 위치를 나타내고 0이 나머지를 나타내는 원-핫 인코딩된 벡터일 수 있습니다.
가지고 = [1,0,0,0,0]
a=[0,1,0,0,0]
양호=[0,0,1,0,0]
훌륭함=[0,0,0,1,0]
일=[0,0,0,0,1]
우리의 어휘에 King, Queen, Man, Woman, Child의 다섯 단어만 있다고 가정합니다. 다음과 같이 단어를 인코딩할 수 있습니다.
왕 = [1,0,0,0,0]
여왕 = [0,1,0,0,0]
남자 = [0,0,1,00]
여자 = [0,0,0,1,0]
자식 = [0,0,0,0,1]
단어 임베딩의 유형(단어 벡터)
Word Embedding은 벡터가 텍스트를 나타내는 기술 중 하나입니다. 다음은 가장 인기 있는 단어 임베딩 유형입니다.
- 주파수 기반 임베딩
- 예측 기반 임베딩
여기서는 빈도 기반 임베딩 및 예측 기반 임베딩에 대해 자세히 설명하지 않겠지만 두 가지를 모두 이해하는 데 도움이 되는 다음 가이드를 찾을 수 있습니다.
단어 임베딩에 대한 직관적인 이해와 텍스트에서 기능을 생성하기 위한 BOW(Bag-of-Words) 및 TF-IDF에 대한 빠른 소개
WORD2Vec에 대한 간략한 소개
빈도 기반 임베딩이 인기를 얻었지만 여전히 단어의 맥락을 이해하는 데 공백이 있고 단어 표현에 제한이 있습니다.
예측 기반 임베딩(WORD2Vec)은 Google의 Tomas Mikolov가 이끄는 연구원 팀에 의해 2013년에 만들어지고 특허를 받았으며 NLP 커뮤니티에 도입되었습니다.
Wikipedia에 따르면 word2vec 알고리즘은 신경망 모델을 사용하여 방대한 텍스트 코퍼스(크고 구조화된 텍스트 세트)에서 단어 연관을 학습합니다.
일단 훈련되면 이러한 모델은 동의어를 감지하거나 부분 문장에 대한 추가 단어를 제안할 수 있습니다. 예를 들어, Word2Vec을 사용하면 King – 남자 + 여자 = Queen과 같은 결과를 쉽게 만들 수 있습니다. 이는 거의 마법 같은 결과로 간주되었습니다.
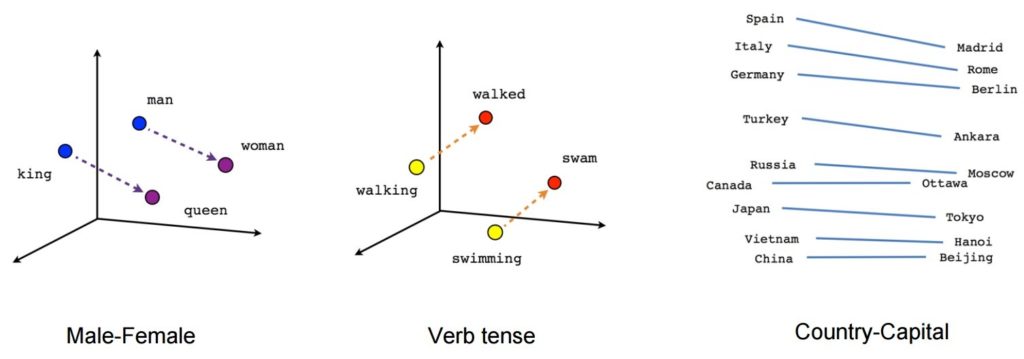 이미지 출처: 텐서플로
이미지 출처: 텐서플로
- [왕] – [남자] + [여자] ~= [여왕] (이에 대한 또 다른 생각은 [왕] – [여왕]이 [군주]의 성별 부분만 인코딩한다는 것입니다.
- [walking] – [swimming] + [swam] ~= [walked] (또는 [swam] – [swimming]은 동사의 "과거형"을 인코딩합니다)
- [마드리드] – [스페인] + [프랑스] ~= [파리] (또는 [마드리드] – [스페인] ~= [파리] – [프랑스] 대략 "수도")
출처: Brainslab 디지털
이것이 약간 기술적이라는 것을 알고 있지만 Stitch Fix는 의미론적 관계와 단어 벡터에 대한 환상적인 게시물을 작성했습니다.
Word2Vec 알고리즘은 단일 알고리즘이 아니라 몇 가지 AI 방법을 사용하여 인간의 이해와 기계의 이해를 연결하는 두 가지 기술의 조합입니다. 이 기술은 많은 NLP 문제를 해결하는 데 필수적입니다.
이 두 가지 기술은 다음과 같습니다.
- – CBOW(Continuous Bag of Words) 또는 CBOW 모델
- – 스킵 그램 모델.
둘 다는 단어에 대한 확률을 제공하는 얕은 신경망이며 단어 비교 및 단어 유추와 같은 작업에 도움이 되는 것으로 입증되었습니다.
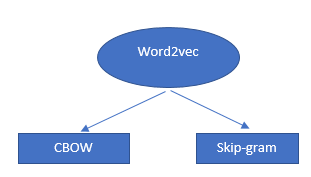
단어 벡터와 word2vecs의 작동 방식
Word Vector는 Google에서 개발한 AI 모델이며 매우 복잡한 NLP 작업을 해결하는 데 도움이 됩니다.
“Word Vector 모델에는 다음과 같은 한 가지 핵심 목표가 있습니다.
구글이 단어 간의 의미 관계를 감지하는 데 도움이 되는 알고리즘입니다.”
각 단어는 유사한 컨텍스트에 나타나는 단어의 벡터와 일치하도록 벡터(다차원으로 표현된 숫자로)로 인코딩됩니다. 따라서 텍스트에 대해 조밀한 벡터가 형성됩니다.
이러한 벡터 모델은 아이디어와 언어의 동등성, 유사성 또는 관련성을 기반으로 의미적으로 유사한 구문을 가까운 지점에 매핑합니다.
[사례 연구] 온페이지 SEO로 새로운 시장에서 성장 주도
 사례 연구 읽기
사례 연구 읽기Word2Vec- 어떻게 작동합니까?
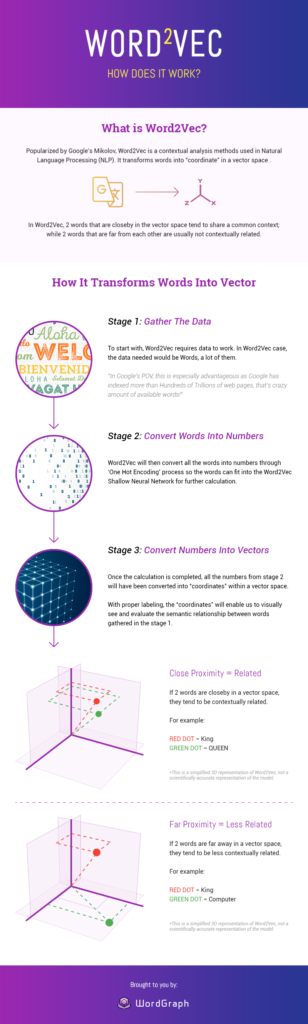
이미지 출처: 서프레서
Word2Vec의 장단점
우리는 Word2vec가 분포 유사성을 생성하는 매우 효과적인 기술임을 보았습니다. 여기에 다른 장점 중 일부를 나열했습니다.
- Word2vec 개념을 이해하는 데 어려움이 없습니다. Word2Vec은 뒤에서 무슨 일이 일어나는지 알 수 없을 정도로 복잡하지 않습니다.
- Word2Vec의 아키텍처는 매우 강력하고 사용하기 쉽습니다. 다른 기술에 비해 훈련 속도가 빠릅니다.
- 여기에서는 훈련이 거의 완전히 자동화되어 사람이 태그를 지정한 데이터가 더 이상 필요하지 않습니다.
- 이 기술은 소규모 데이터세트와 대규모 데이터세트 모두에서 작동합니다. 결과적으로 확장하기 쉬운 모델입니다.
- 개념을 알면 전체 개념과 알고리즘을 쉽게 복제할 수 있습니다.
- 의미론적 유사성을 매우 잘 포착합니다.
- 정확하고 효율적인 계산
- 이 접근 방식은 감독되지 않기 때문에 노력 면에서 시간이 매우 절약됩니다.
Word2Vec의 과제
Word2vec 개념은 매우 효율적이지만 몇 가지 점이 다소 어려울 수 있습니다. 다음은 가장 일반적인 몇 가지 문제입니다.
- 데이터 세트에 대한 word2vec 모델을 개발할 때 word2vec 모델은 개발하기 쉽지만 디버그하기 어렵기 때문에 디버깅이 주요 과제가 될 수 있습니다.
- 모호성을 다루지 않습니다. 따라서 여러 의미를 가진 단어의 경우 Embedding은 이러한 의미의 평균을 벡터 공간에 반영합니다.
- 알 수 없는 단어나 OOV 단어를 처리할 수 없음: word2vec의 가장 큰 문제는 알 수 없거나 어휘에 없는(OOV) 단어를 처리할 수 없다는 것입니다.
워드 벡터: 검색 엔진 최적화의 게임 체인저?
많은 SEO 전문가들은 Word Vector가 검색 엔진 결과에서 웹사이트의 순위에 영향을 미친다고 생각합니다.
지난 5년 동안 Google은 콘텐츠 품질과 언어 포괄성에 중점을 둔 두 가지 알고리즘 업데이트를 도입했습니다.
한 걸음 물러나서 업데이트에 대해 이야기해 보겠습니다.
벌새
2013년에 Hummingbird는 검색 엔진에 의미 분석 기능을 제공했습니다. 의미론을 알고리즘에 활용하고 통합함으로써 검색의 세계로 가는 새로운 길을 열었습니다.

Google Hummingbird는 2010년 Caffeine 이후 검색 엔진의 가장 큰 변화였습니다. 이름은 "정확하고 빠름"에서 따왔습니다.
Search Engine Land에 따르면 Hummingbird는 쿼리의 각 단어에 더 많은 주의를 기울이며 특정 단어가 아닌 전체 쿼리를 고려합니다.
Hummingbird의 주요 목표는 특정 키워드에 대한 결과를 반환하는 것보다 쿼리의 컨텍스트를 이해하여 더 나은 결과를 제공하는 것이었습니다.
"구글 벌새는 2013년 9월에 출시되었습니다."
랭크브레인
2015년 구글은 인공지능(AI)을 접목한 전략인 랭크브레인(RankBrain)을 발표했다.
RankBrain은 Google이 복잡한 검색 쿼리를 더 간단한 쿼리로 분해하는 데 도움이 되는 알고리즘입니다. RankBrain은 검색어를 "인간" 언어에서 Google이 쉽게 이해할 수 있는 언어로 변환합니다.
Google은 2015년 10월 26일 Bloomberg가 게시한 기사에서 RankBrain의 사용을 확인했습니다.
버트
2019년 10월 21일 BERT가 Google 검색 시스템에 출시되기 시작했습니다.
BERT는 Bidirectional Encoder Representations from Transformers의 약자로 Google에서 자연어 처리(NLP) 사전 교육에 사용하는 신경망 기반 기술입니다.
한마디로 BERT는 컴퓨터가 인간처럼 언어를 이해할 수 있도록 도와주는 것으로, 구글이 RankBrain을 도입한 이후 검색 분야에서 가장 큰 변화다.
이는 RankBrain을 대체하는 것이 아니라 콘텐츠 및 쿼리를 이해하기 위한 추가 방법입니다.
Google은 순위 시스템에서 BERT를 추가로 사용합니다. RankBrain 알고리즘은 일부 쿼리에 대해 여전히 존재하며 계속 존재할 것입니다. 그러나 Google은 BERT가 쿼리를 더 잘 이해할 수 있다고 생각하면 이를 사용합니다.
BERT에 대한 자세한 내용은 Barry Schwartz의 이 게시물과 Dawn Anderson의 심층 분석을 확인하세요.
Word Vector로 사이트 순위 지정
이미 고유한 콘텐츠를 만들어 게시했다고 가정하고 계속해서 다듬어도 순위나 트래픽이 향상되지 않습니다.
왜 이런 일이 당신에게 일어나고 있는지 궁금하십니까?
Word Vector: Google의 AI 모델을 포함하지 않았기 때문일 수 있습니다.
- 첫 번째 단계는 틈새 시장에 대한 상위 10개 SERP 순위의 단어 벡터를 식별하는 것입니다.
- 경쟁자가 사용하는 키워드와 내가 간과할 수 있는 키워드를 파악하십시오.
고급 자연어 처리 기술과 머신 러닝 프레임워크를 활용한 Word2Vec을 적용하면 모든 것을 자세히 볼 수 있습니다.
하지만 머신 러닝과 NLP 기술을 알고 있다면 가능하지만 다음 도구를 사용 하여 콘텐츠에 단어 벡터를 적용 할 수 있습니다.
WordGraph, 세계 최초의 워드 벡터 도구
이 인공 지능 도구는 자연어 처리를 위한 신경망으로 생성되고 기계 학습으로 훈련됩니다.
인공 지능을 기반으로 하는 WordGraph는 콘텐츠를 분석하고 상위 10개 순위 웹사이트와의 관련성을 높이는 데 도움을 줍니다.
귀하의 주요 키워드와 수학적으로 그리고 문맥적으로 관련이 있는 키워드를 제안합니다.
개인적으로 저는 WordGraph와 잘 작동하는 강력한 SEO 도구인 BIQ와 함께 사용합니다.
Biq에 내장된 콘텐츠 인텔리전스 도구에 콘텐츠를 추가하세요. 상위 순위에 오르고 싶다면 추가할 수 있는 페이지 SEO 팁 의 전체 목록을 보여줍니다.
이 예에서 콘텐츠 인텔리전스가 어떻게 작동하는지 확인할 수 있습니다. 목록은 실행 가능한 방법을 사용하여 페이지 SEO를 마스터하고 순위를 매기는 데 도움이 됩니다!
단어 벡터를 강화하는 방법: 구조화된 데이터 마크업 사용
스키마 마크업 또는 구조화된 데이터는 검색 엔진이 콘텐츠를 크롤링, 구성 및 표시하는 데 도움이 되는 schema.org 어휘를 사용하여 생성된 코드 유형(JSON, Java-Script Object Notation으로 작성)입니다.
구조화된 데이터를 추가하는 방법
HTML에 인라인 스크립트를 추가하여 구조화된 데이터를 웹사이트에 쉽게 추가할 수 있습니다.
아래 예는 조직의 구조화된 데이터를 가능한 가장 간단한 형식으로 정의하는 방법을 보여줍니다.
스키마 마크업을 생성하기 위해 이 스키마 마크업 생성기(JSON-LD)를 사용합니다.
다음은 https://www.telecloudvoip.com/에 대한 스키마 마크업의 라이브 예입니다. 소스 코드를 확인하고 JSON을 검색합니다.
스키마 마크업 코드가 생성된 후 Google의 리치 결과 테스트를 사용하여 페이지가 리치 결과를 지원하는지 확인하십시오.
Semrush 사이트 감사 도구를 사용하여 각 URL에 대한 구조화된 데이터 항목을 탐색하고 리치 결과에 포함될 수 있는 페이지를 식별할 수도 있습니다. 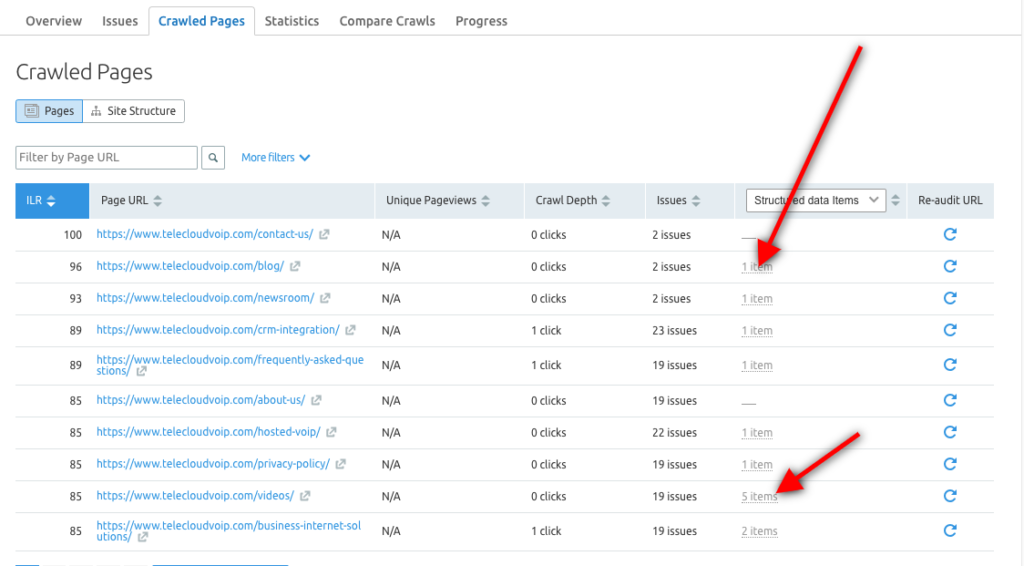
구조화된 데이터가 SEO에 중요한 이유는 무엇입니까?
구조화된 데이터는 Google이 웹사이트와 페이지의 내용을 이해하는 데 도움이 되므로 SEO에 중요합니다. 결과적으로 콘텐츠 순위가 더 정확해집니다.
구조화된 데이터는 더 많은 정보와 정확성으로 SERP(검색 엔진 결과 페이지)를 개선하여 검색 봇의 경험과 사용자 경험을 모두 개선합니다.
Google 검색에 미치는 영향을 확인하려면 Search Console로 이동하고 실적 > 검색 결과 > 검색 노출에서 '동영상' 및 'FAQ'와 같은 모든 리치 결과 유형의 분석을 보고 이러한 유형이 유도한 유기적 노출 및 클릭을 확인할 수 있습니다. 당신의 콘텐츠를 위해.
다음은 구조화된 데이터의 몇 가지 장점입니다.
- 구조화된 데이터는 의미 검색을 지원합니다.
- 또한 E‑AT(전문성, 권위 및 신뢰)를 지원합니다.
- 구조화된 데이터를 사용하면 더 많은 사람들이 귀하의 목록을 보게 되어 귀하로부터 구매할 가능성이 높아지므로 전환율을 높일 수도 있습니다.
- 구조화된 데이터를 사용하면 검색 엔진이 브랜드, 웹사이트 및 콘텐츠를 더 잘 이해할 수 있습니다.
- 검색 엔진은 연락처 페이지, 제품 설명, 레시피 페이지, 이벤트 페이지 및 고객 리뷰를 더 쉽게 구별할 수 있습니다.
- 구조화된 데이터의 도움으로 Google은 브랜드에 대한 더 정확하고 더 나은 지식 그래프와 지식 패널을 구축합니다.
- 이러한 개선으로 더 많은 유기적 노출과 유기적 클릭이 발생할 수 있습니다.
구조화된 데이터는 현재 Google에서 검색 결과를 개선하는 데 사용됩니다. 사람들이 키워드를 사용하여 웹페이지를 검색할 때 구조화된 데이터는 더 나은 결과를 얻는 데 도움이 될 수 있습니다. 스키마 마크업을 추가하면 검색 엔진이 귀하의 콘텐츠를 더 많이 인지하게 됩니다.
다양한 항목에 스키마 마크업을 구현할 수 있습니다. 다음은 스키마를 적용할 수 있는 몇 가지 영역입니다.
- 조항
- 블로그 게시물
- 뉴스 기사
- 이벤트
- 제품
- 비디오
- 서비스
- 리뷰
- 종합 평가
- 레스토랑
- 지역 기업
다음은 스키마로 마크업할 수 있는 항목의 전체 목록입니다.
엔터티 임베딩이 있는 구조화된 데이터
"개체"라는 용어는 모든 유형의 대상, 개념 또는 주제의 표현을 나타냅니다. 엔터티는 사람, 영화, 책, 아이디어, 장소, 회사 또는 이벤트가 될 수 있습니다.
기계는 실제로 단어를 이해할 수 없지만 엔티티 임베딩을 사용하면 왕 – 여왕 = 남편 – 아내의 관계를 쉽게 이해할 수 있습니다.
엔터티 임베딩은 원-핫 인코딩보다 더 나은 성능을 보입니다.
단어 벡터 알고리즘은 Google에서 단어 간의 의미적 관계를 발견하는 데 사용되며 구조화된 데이터와 결합되면 의미적으로 향상된 웹이 됩니다.
구조화된 데이터를 사용하면 보다 시맨틱한 웹에 기여하게 됩니다. 이것은 기계가 읽을 수 있는 형식으로 데이터를 설명하는 향상된 웹입니다.
웹사이트의 구조화된 의미 체계 데이터는 검색 엔진이 귀하의 콘텐츠를 적절한 대상과 일치시키는 데 도움이 됩니다. NLP, 머신 러닝 및 딥 러닝을 사용하면 사람들이 검색하는 것과 사용 가능한 타이틀 간의 격차를 줄이는 데 도움이 됩니다.
마지막 생각들
이제 단어 벡터의 개념과 그 중요성을 이해했으므로 단어 벡터, 엔티티 임베딩 및 구조화된 의미 데이터를 활용하여 유기적 검색 전략을 보다 효과적이고 효율적으로 만들 수 있습니다.
가장 높은 순위, 트래픽 및 전환을 달성하려면 단어 벡터, 엔티티 임베딩 및 구조화된 의미 데이터를 사용하여 웹페이지의 콘텐츠가 정확하고 정확하며 신뢰할 수 있음을 Google에 입증해야 합니다.