
잠재 시맨틱 인덱싱이란 무엇이며 어떻게 작동합니까?
게시 됨: 2020-04-02LSI(Latent Semantic Indexing)는 오랫동안 검색 마케터들 사이에서 논쟁의 원인이 되어 왔습니다. Google에서 '잠재적 의미 색인'이라는 용어를 검색하면 옹호자와 회의론자 모두를 동등하게 접하게 될 것입니다. 검색 엔진 마케팅의 맥락에서 LSI를 고려할 때의 이점에 대한 명확한 합의는 없습니다. 개념에 익숙하지 않은 경우 이 기사에서 LSI에 대한 토론을 요약하여 SEO 전략에 의미하는 바를 이해할 수 있기를 바랍니다.
잠재 시맨틱 인덱싱이란 무엇입니까?
LSI는 NLP(자연어 처리)에서 볼 수 있는 프로세스입니다. NLP는 기계가 인간의 언어를 해석하는 방법에 중점을 둔 언어학 및 정보 공학의 하위 집합입니다. 이 연구의 핵심 부분은 분포 의미론입니다. 이 모델은 대규모 데이터 세트 내에서 유사한 맥락적 의미를 가진 단어를 이해하고 분류하는 데 도움이 됩니다.
1980년대에 개발된 LSI는 정보 검색을 보다 정확하게 만드는 수학적 방법을 사용합니다. 이 방법은 단어 사이의 숨겨진 컨텍스트 관계를 식별하여 작동합니다. 다음과 같이 분해하는 데 도움이 될 수 있습니다.
- 잠복 → 숨겨진
- 의미론 → 단어 간의 관계
- 인덱싱 → 정보 검색
잠재 시맨틱 인덱싱은 어떻게 작동합니까?
LSI는 SVD(Singular Value Decomposition)의 부분 적용을 사용하여 작동합니다. SVD는 간단하고 효율적인 계산을 위해 행렬을 구성 요소로 줄이는 수학 연산입니다.
일련의 단어를 분석할 때 LSI는 접속사, 대명사 및 불용어라고도 하는 일반 동사를 제거합니다. 이것은 구의 주요 '내용'을 구성하는 단어를 분리합니다. 다음은 이것이 어떻게 보이는지에 대한 간단한 예입니다.
![]()
그런 다음 이러한 단어는 TDM( 용어 문서 매트릭스 )에 배치됩니다. TDM은 데이터 세트 내의 문서에서 각 특정 단어(또는 용어)가 나타나는 빈도를 나열하는 2D 그리드입니다.
그런 다음 칭량 기능이 TDM에 적용됩니다. 간단한 예는 값이 1인 단어가 포함된 모든 문서와 값이 0이 아닌 모든 문서를 분류하는 것입니다. 이러한 문서에서 단어가 일반적으로 동일한 빈도로 나타나는 경우 이를 동시 발생 이라고 합니다. 아래에서 TDM의 기본 예와 여러 구문에서 동시 발생을 평가하는 방법을 찾을 수 있습니다.
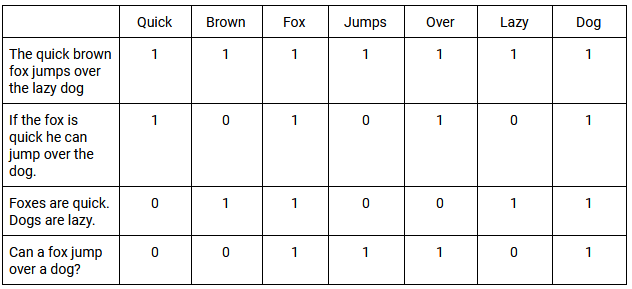
SVD를 사용하면 모든 문서에서 단어 사용 패턴을 대략적으로 파악할 수 있습니다. LSI에서 생성된 SVD 벡터는 개별 용어를 분석하는 것보다 의미를 더 정확하게 예측합니다. 궁극적으로 LSI는 단어 간의 관계를 사용하여 특정 상황에서 단어의 의미 또는 의미를 더 잘 이해할 수 있습니다.
[사례 연구] 온페이지 SEO로 새로운 시장에서 성장 주도
 사례 연구 읽기
사례 연구 읽기잠재 시맨틱 인덱싱은 어떻게 SEO와 관련이 되었습니까?
설립 초기에 Google은 검색 엔진이 특정 키워드의 빈도를 기반으로 웹사이트 순위를 매긴다는 사실을 발견했습니다. 그러나 이것이 가장 관련성이 높은 검색 결과를 보장하지는 않습니다. 대신 Google은 신뢰할 수 있는 정보 중재자로 간주되는 웹사이트의 순위를 매기기 시작했습니다.
시간이 지남에 따라 Google의 알고리즘은 품질이 낮고 관련 없는 웹사이트를 더 정확하게 필터링합니다. 따라서 마케터는 사용되는 정확한 단어에 의존하는 대신 검색 이면의 의미를 이해해야 합니다. 이것이 Roger Montti가 구식 SEO 신념에 대한 기사에서 LSI를 "검색 엔진을 위한 훈련 바퀴"라고 설명하고 LSI가 "오늘날 검색 엔진이 웹사이트 순위를 매기는 방식과 거의 관련이 없거나 0"이라고 덧붙인 이유입니다.
검색어의 의미는 검색어 뒤에 숨겨진 의도와 밀접하게 연결되어 있습니다. Google은 검색 품질 평가자 가이드라인이라는 문서를 유지 관리합니다. 이 가이드라인에서는 사용자 의도에 대한 네 가지 유용한 카테고리를 소개합니다.
- Know Query – 이것은 주제에 대한 정보를 찾는 것을 나타냅니다. 이에 대한 변형은 사용자가 특정 답변을 염두에 두고 검색하는 경우인 '간단한 지식' 쿼리입니다.
- 쿼리 수행 – 온라인 구매 또는 다운로드와 같은 특정 활동에 참여하려는 욕구를 반영합니다. 이러한 모든 쿼리는 '상호작용'이라는 의미로 정의할 수 있습니다.
- 웹사이트 쿼리 – 사용자가 특정 웹사이트나 페이지를 찾는 경우입니다. 이러한 검색은 특정 웹사이트 또는 브랜드에 대한 사전 인지도를 나타냅니다.
- 방문 쿼리 – 사용자가 오프라인 상점이나 레스토랑과 같은 물리적 위치를 검색하고 있습니다.
한 구절 내에서 단어의 문맥적 의미를 정의하는 LSI 이면의 이론은 Google에 경쟁 우위를 제공했습니다. 그러나 갑자기 'LSI 키워드'가 SEO 성공의 황금 티켓이라는 생각이 퍼지기 시작했습니다.

'LSI 키워드'가 실제로 존재합니까?
많은 저명한 출판물이 LSI 키워드의 확고한 지지자로 남아 있습니다. 그러나 Google의 웹마스터 트렌드 분석가인 John Mueller와 같은 여러 출처에서는 이것이 신화라고 말합니다. 이러한 출처는 다음 사항을 제기하기 시작했습니다.
- LSI는 World Wide Web 이전에 개발되었으며 이렇게 크고 동적인 데이터 세트에 적용할 의도가 없었습니다.
- 1989년 Bell Communications Research Inc.라는 조직에 부여된 Latent Semantic Indexing에 대한 미국 특허는 2008년에 만료되었을 것입니다. 따라서 Bill Slawski에 따르면 Google이 LSI를 사용하는 것은 '스마트 전신 장치를 사용하여 모바일 웹.'
- Google은 대량의 텍스트를 컴퓨터가 문자를 이해하는 데 도움이 되는 수학적 개체인 '벡터'로 변환하는 기계 학습 방법인 RankBrain을 사용합니다. RankBrain은 웹을 지속적으로 확장되는 데이터세트로 수용하므로 LSI와 달리 Google에서 사용할 수 있습니다.
궁극적으로 LSI는 마케터가 준수해야 할 진실을 드러냅니다. 단어의 고유한 컨텍스트를 탐색하면 콘텐츠에 채워진 키워드보다 사용자 의도를 더 잘 이해할 수 있습니다. 그러나 이것이 Google이 LSI를 기반으로 순위를 매기는 것을 반드시 확인하는 것은 아닙니다. 따라서 LSI가 SEO에서 정확한 과학이 아니라 철학으로 작동한다고 말할 수 있습니까?
LSI를 "검색 엔진을 위한 교육용 바퀴"라고 언급한 Roger Montti의 인용문으로 돌아가 보겠습니다. 자전거 타는 법을 배우면 훈련용 바퀴를 빼는 경향이 있습니다. 2020년에 Google이 더 이상 학습용 바퀴를 사용하지 않는다고 가정할 수 있습니까?
Google의 최근 알고리즘 업데이트를 고려할 수 있습니다. 2019년 10월 검색 담당 부사장인 Pandu Nayak은 Google이 BERT(Bidirectional Encoder Representations from Transformers)라는 AI 시스템을 사용하기 시작했다고 발표했습니다. 모든 검색어의 10% 이상에 영향을 미치는 이것은 최근 몇 년 동안 가장 큰 Google 업데이트 중 하나입니다.
검색 쿼리를 분석할 때 BERT는 특정 구문의 모든 단어와 관련하여 단일 단어를 고려합니다. 이 분석은 특정 단어 앞이나 뒤에 있는 모든 단어를 고려한다는 점에서 양방향입니다. 단일 단어를 제거하면 BERT가 구문의 고유한 컨텍스트를 이해하는 방식에 큰 영향을 미칠 수 있습니다.
이는 분석에서 불용어를 생략하는 LSI와 대조적입니다. 아래 예는 불용어를 제거하면 구문을 이해하는 방식이 어떻게 바뀔 수 있는지 보여줍니다.
![]()
중지 단어에도 불구하고 '찾기'는 검색의 핵심이며 '직접 방문' 쿼리로 정의합니다.
그렇다면 마케터는 어떻게 해야 할까요?
처음에 LSI는 Google이 콘텐츠를 관련 검색어와 일치시키는 데 도움이 될 수 있다고 생각했습니다. 그러나 LSI 사용을 둘러싼 마케팅 논쟁은 아직 하나의 결론에 도달하지 못한 것으로 보입니다. 그럼에도 불구하고 마케터는 자신의 작업이 전략적으로 적절하도록 유지하기 위해 여전히 많은 조치를 취할 수 있습니다.
첫째, 기사, 웹 카피 및 유료 캠페인은 동의어와 변형을 포함하도록 최적화되어야 합니다. 이것은 비슷한 의도를 가진 사람들이 언어를 다르게 사용하는 방식을 설명합니다.
마케터는 계속해서 권위 있고 명확하게 작성해야 합니다. 콘텐츠가 특정 문제를 해결하기를 원한다면 이것은 절대적으로 필요합니다. 이 문제는 정보가 부족하거나 특정 제품이나 서비스에 대한 필요성이 있을 수 있습니다. 마케터가 이렇게 하면 사용자 의도를 진정으로 이해하고 있음을 보여줍니다.
마지막으로 구조화된 데이터도 자주 사용해야 합니다. 웹사이트, 레시피 또는 FAQ에 관계없이 구조화된 데이터는 Google이 크롤링하는 내용을 이해할 수 있는 컨텍스트를 제공합니다.