
Python 및 Sitemap을 사용하여 콘텐츠 전략 감사
게시 됨: 2020-10-08Python 라이브러리를 사용하여 SEO를 대신하여 수행할 수 있는 작업에 대한 관심은 더 이상 비밀이 아닙니다. 그러나 프로그래밍 경험이 거의 없는 대부분의 사람들은 많은 수의 라이브러리를 가져오고 사용하거나 푸시하는 데 어려움을 겪습니다. 결과는 일반 크롤러나 SEO 도구가 할 수 있는 것 이상입니다.
이것이 SEO, SEM, SMO, SERP 검사 및 콘텐츠 분석을 위해 특별히 제작된 Python 라이브러리가 모든 사람에게 유용한 이유입니다.
이 기사에서는 Elias Dabbas가 만들고 개발한 SEO용 Advertools Python 라이브러리로 수행할 수 있는 몇 가지 작업을 살펴보고 SEO, PPC 및 코딩 기능에서 큰 잠재력을 볼 수 있습니다. 아주 짧은 시간에. 또한 교육적이고 적응적인 방식으로 다른 Python 라이브러리와 함께 사용자 정의 Python 스크립트를 사용할 것입니다.
XML 사이트맵을 다운로드하고 분석하는 데 도움이 되는 Elias Dabbas의 sitemap_to_df 기능 덕분에 사이트맵에서 SEO를 위해 무엇을 배울 수 있는지 조사할 것입니다(사이트맵은 검색 엔진에 크롤링 및 인덱싱 가능한 URL을 보고하는 데 사용되는 XML 형식의 문서입니다).
이 기사에서는 다양한 구조에 따라 다른 웹사이트를 분석하기 위한 사용자 정의 Python 코드를 작성하는 방법, SEO 측면에서 데이터를 해석하는 방법, 콘텐츠 프로필, URL 및 사이트 구조와 관련하여 검색 엔진처럼 생각하는 방법을 보여줍니다. .
사이트맵을 기반으로 웹사이트의 콘텐츠 규모 및 전략 분석
사이트맵은 웹사이트가 콘텐츠를 게시하는 빈도, 콘텐츠 범주, 게시 날짜, 작성자 정보, 콘텐츠 주제 등 다양한 유형의 데이터를 캡처할 수 있는 웹사이트의 구성 요소입니다.
정상적인 조건에서는 scrapy로 사이트맵을 스크랩하고 Pandas를 사용하여 DataFrame으로 변환하고 원하는 경우 다양한 보조 라이브러리로 해석할 수 있습니다.
그러나 이 기사에서는 Advertools와 일부 Pandas 라이브러리 메서드 및 속성만 사용합니다. 수집한 데이터를 시각화하기 위해 일부 라이브러리가 활성화됩니다.
바로 들어가서 사이트맵을 사용하여 몇 가지 중요한 SEO 통찰력을 결론지을 웹사이트를 선택하겠습니다.
Advertools를 사용하여 사이트맵에서 데이터 프레임 추출 및 생성
Advertools에서는 단 한 줄의 코드로 웹사이트의 모든 사이트맵을 검색, 탐색 및 결합할 수 있습니다.
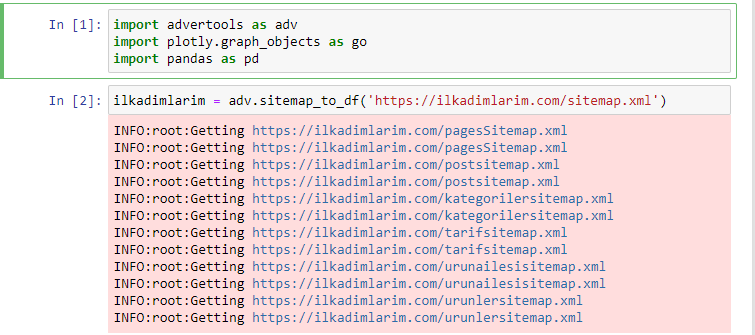
저는 일반 코드 편집기나 IDE 대신 Jupyter Notebook을 사용하는 것을 좋아합니다.
첫 번째 셀에서는 데이터 수집 및 구성을 위한 Pandas 및 Advertools와 데이터 시각화를 위한 Plotly.graph_objects를 가져왔습니다.
adv.sitemap_to_df('sitemap address') 명령은 단순히 모든 사이트맵을 수집하고 DataFrame으로 통합합니다.
Pandas 및 Advertools를 사용하여 동일한 작업을 수행하면 어떤 URL이 어떤 사이트맵에서 사용 가능한지 알 수 있습니다.
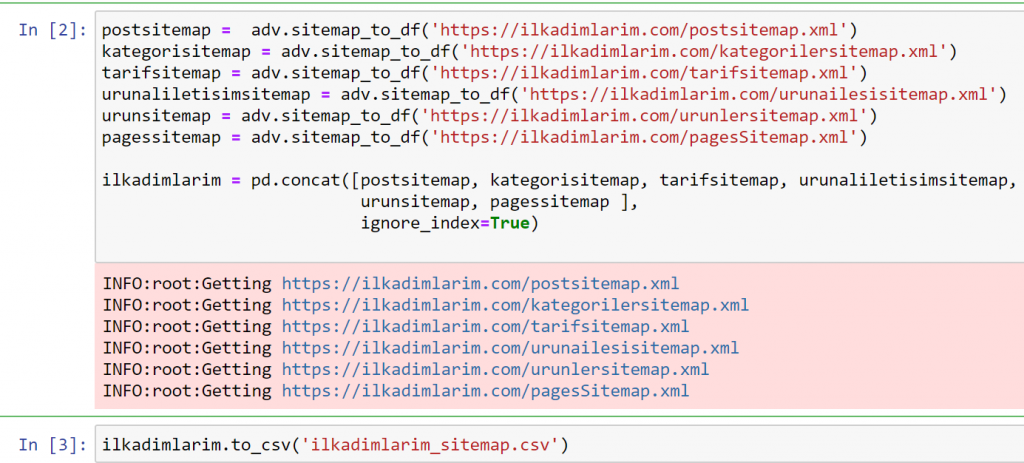
위의 예에서는 동일한 사이트맵을 별도로 가져온 다음 pd.concat 명령으로 결합하고 결과를 CSV로 전송했습니다. 이전 예제에서는 사이트맵 색인 파일을 사용했으며 이 경우 함수는 다른 모든 사이트맵을 검색합니다. 따라서 웹사이트의 특정 섹션에 관심이 있는 경우 여기에서 했던 것처럼 특정 사이트맵을 선택할 수 있는 옵션이 있습니다.
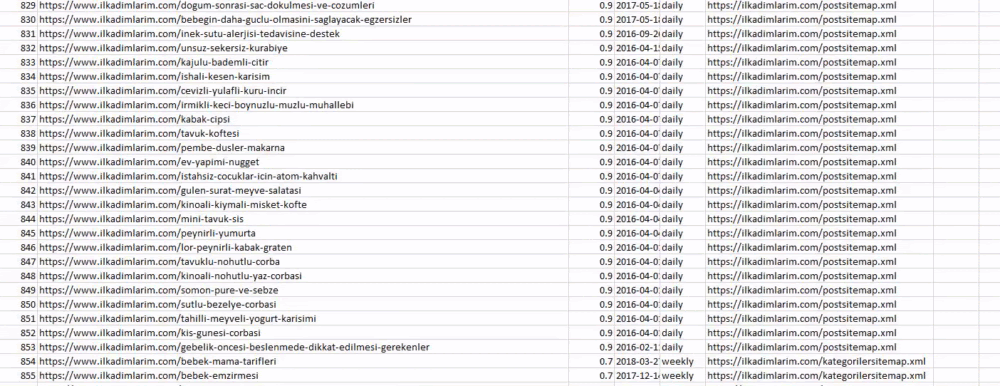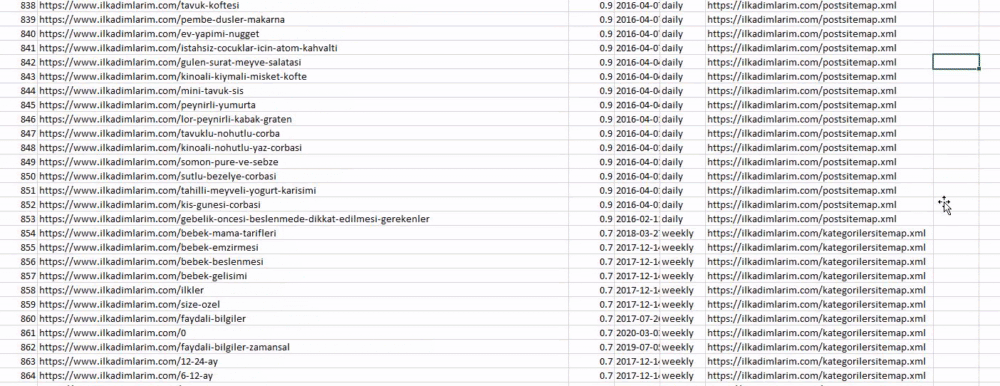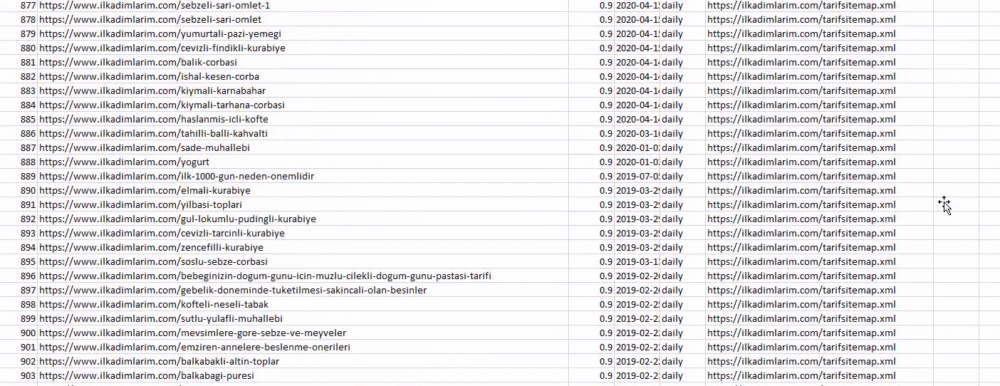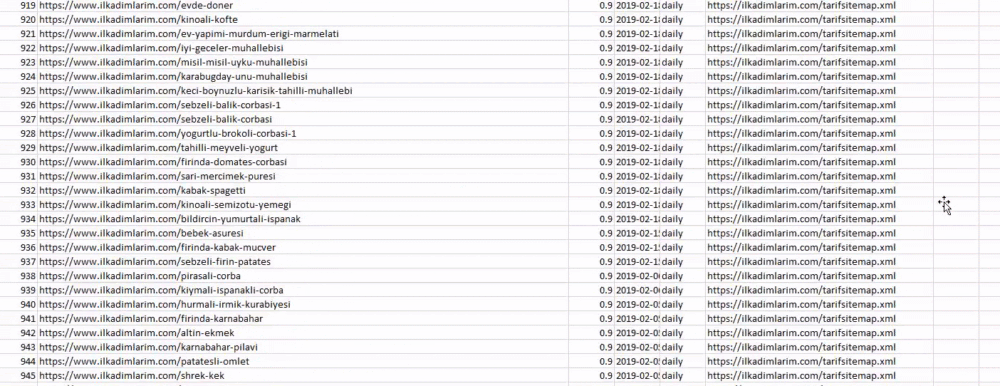
위에서 사이트맵 이름이 다른 열을 볼 수 있습니다. ignore_index=True 섹션은 여러 데이터 프레임을 병합한 경우 서로 다른 DataFrame의 인덱스 번호를 깔끔하게 정렬하기 위한 것입니다.
온크롤 데이터³
 더 알아보기
더 알아보기Python으로 콘텐츠 분석을 위한 Sitemap 데이터 프레임 정리 및 준비
사이트맵을 통해 웹사이트의 콘텐츠 프로필을 이해하려면 Advertools로 얻은 DataFrame을 검토할 수 있도록 준비해야 합니다.
Pandas 라이브러리의 몇 가지 기본 명령을 사용하여 데이터를 형성합니다.
Ilkadimlarim = pd.read_csv('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop(columns = '무명: 0')
ilkadimlarim['lastmod'] = pd.to_datetime(ilkadimlarim['lastmod'])
ilkadimlarim = ilkadimlarim.set_index('lastmod')
"Ilkadimlarim"은 터키어로 "나의 첫걸음"을 의미하며 상상할 수 있듯이 아기, 임신, 모성을 위한 사이트입니다.
우리는 이 라인으로 세 가지 작업을 수행했습니다.
- 이름: DataFrame에서 0이라는 빈 열을 제거했습니다. 또한 pd.to_csv() 함수와 함께 'index = False' 를 사용하면 처음에 이 'Unnamed 0' 열이 표시되지 않습니다.
- 마지막 수정 열의 데이터를 날짜 시간으로 변환했습니다.
- "lastmod" 열을 인덱스 위치로 가져왔습니다.
아래에서 DataFrame의 최종 버전을 볼 수 있습니다.
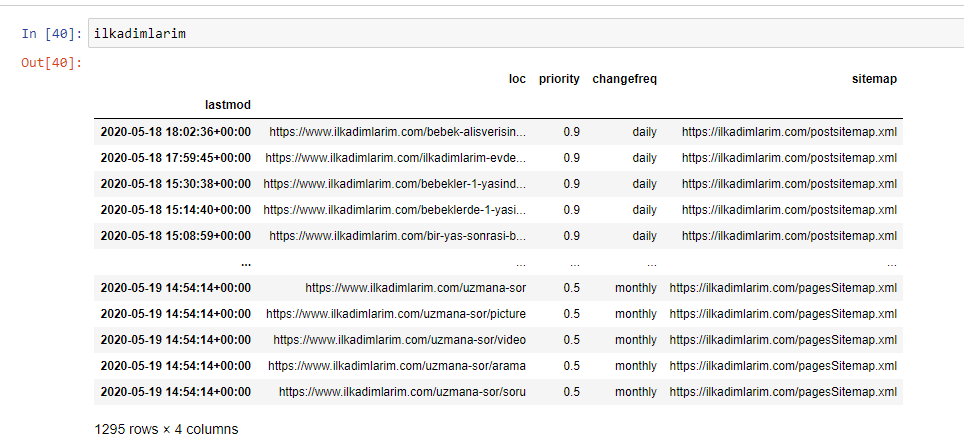
Google은 사이트맵의 우선순위 및 변경 빈도 정보를 사용하지 않는다는 것을 알고 있습니다. 그들은 그것을 "소음 주머니"라고 부릅니다. 그러나 다른 검색 엔진에 대한 웹사이트의 성능을 중요하게 생각한다면 해당 엔진도 검토하는 것이 유용할 수 있습니다. 개인적으로 나는 이 데이터에 대해 별로 신경 쓰지 않지만 여전히 DataFrame에서 데이터를 제거할 필요는 없습니다.
다른 열에서 사이트맵을 분류하려면 코드 줄이 하나 더 필요합니다.
ilkadimlarim['sitemap_cat'] = ilkadimlarim['sitemap'].str.split('/').str[3]
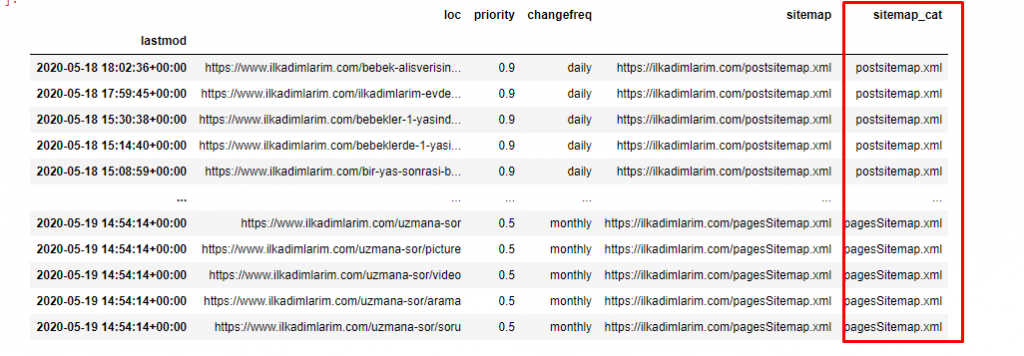
Pandas에서는 DataFrame에 새 열이나 행을 추가하거나 쉽게 업데이트할 수 있습니다. DataFrame['new_columns'] 코드 조각으로 새 열을 만들었습니다. DataFrame['column_name'].str 을 사용하면 열의 데이터 유형을 변경하여 다른 작업을 수행할 수 있습니다. .split('/') 관련 컬럼의 스트링 데이터를 / 문자로 나누어 리스트에 담는다. .str [숫자] 를 사용하여 해당 목록에서 특정 요소를 선택하여 새 열의 내용을 만듭니다.
Sitemap 개수 및 종류에 따른 Content Profile 분석
사이트맵을 유형에 따라 다른 열에 넣은 후 각 사이트맵에 콘텐츠의 비율이 몇 %인지 확인할 수 있습니다. 따라서 웹사이트의 어느 부분이 더 중요한지 추론할 수도 있습니다.
ilkadimlarim['sitemap_cat'].value_counts(정규화 = True) * 100
- DataFrame['column_name'] 은 프로세스를 만들고자 하는 열을 선택하고 있습니다.
- value_counts() 는 열에 있는 값의 빈도를 계산합니다.
- normalize=True 는 십진수 값의 비율을 사용합니다.
- *100으로 소수를 크게 하여 읽기 쉽게 했습니다.
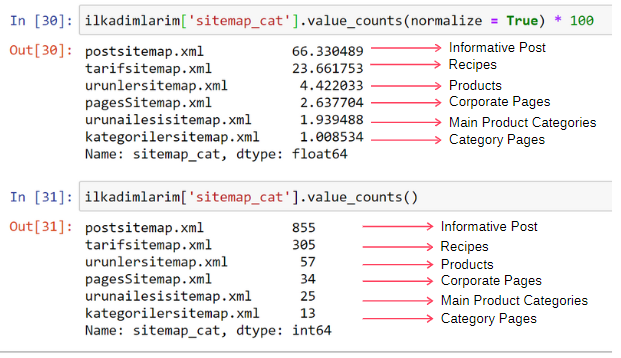
콘텐츠의 65%는 Post Sitemap에 있고 23%는 Recipe Sitemap에 있습니다. 제품 사이트맵에는 콘텐츠의 2%만 있습니다.
이는 광범위한 청중이 자체 제품을 마케팅할 수 있도록 유익한 콘텐츠를 만들어야 하는 웹사이트가 있음을 보여줍니다. 우리의 논문이 맞는지 확인해 봅시다.
계속하기 전에 아래 코드를 사용하여 ilkadimlarim['sitemap_cat'] 열 이름을 'URL_Count'로 변경해야 합니다.
ilkadimlarim.rename(columns={'sitemap_cat' : 'URL_Count'}, inplace=True)
- rename() 함수는 더 깊은 수준에서 데이터와 그 의미를 연결하기 위해 열 또는 인덱스의 이름을 수정하는 데 유용합니다.
- 'inplace=True' 속성 덕분에 열 이름을 영구적으로 변경했습니다.
- ilkadimlarim.rename(str.capitalize, axis='columns', inplace=True) 를 사용하여 열 및 색인의 문자 스타일을 변경할 수도 있습니다. 이것은 Ilkadimlarim의 모든 열의 첫 글자만 대문자로 씁니다.

이제 진행할 수 있습니다.
단일 프레임에서 이 정보를 보려면 아래 코드를 사용할 수 있습니다.
(일카딤라림['sitemap_cat']
.value_counts()
.to_frame()
.assign(백분율=람다 df: df['sitemap_cat'].div(df['sitemap_cat'].sum()))
.style.format(dict(sitemap_cat='{:,}', 백분율='{:.1%}')))
- to_frame() 은 선택한 열에서 value_counts()로 측정된 값을 프레임화하는 데 사용됩니다.
- assign() 은 프레임에 특정 값을 추가하는 데 사용됩니다.
- 람다 는 파이썬에서 익명 함수를 나타냅니다.
- 여기서 Lambda 함수와 사이트맵 유형은 Pandas div() 메서드를 통해 전체 사이트맵 수로 나눕니다.
- style() 은 지정된 최종 값이 작성되는 방법을 결정합니다.
- 여기서 format() 메서드를 사용하여 마침표 뒤에 쓸 자릿수를 설정합니다.
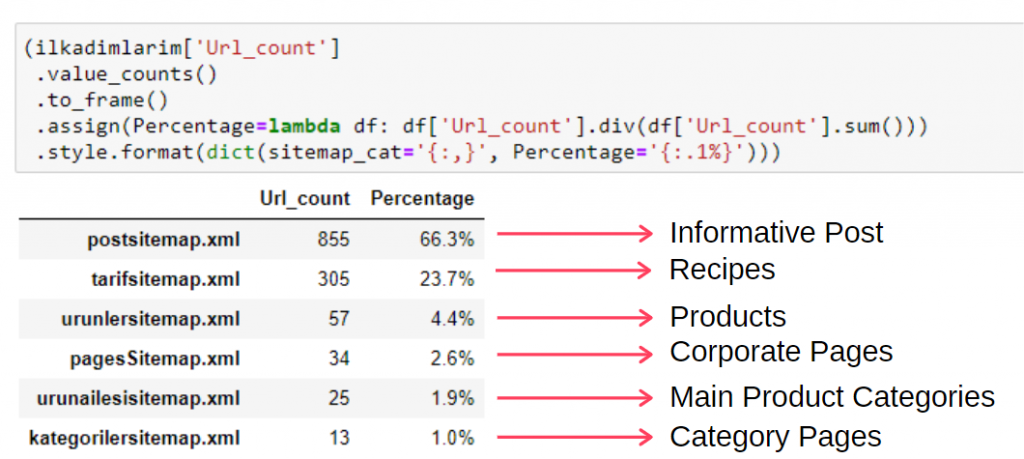
따라서 우리는 이 웹사이트에 대한 콘텐츠 마케팅의 중요성을 봅니다. 또한 두 줄의 코드로 연도별 기사 게시 동향을 확인하여 상황을 더 자세히 조사할 수도 있습니다.
Sitemap과 Python을 통한 연도별 콘텐츠 퍼블리싱 동향 조사 및 시각화
사이트맵 카테고리에 따라 조사한 웹사이트의 콘텐츠와 인텐트 매칭을 하였지만 아직 시간 기반 분류는 하지 않았습니다. 이를 수행하기 위해 resample() 메서드를 사용할 것입니다.
post_per_month = ilkadimlarim.resample('A')['loc'].count()
post_per_month.to_frame()
Resample은 Pandas 라이브러리의 메서드입니다. resample('A')는 연간 DataFrame에 대한 데이터 시리즈를 확인합니다. 몇 주 동안에는 'W'를, 몇 달 동안에는 'M'을 사용할 수 있습니다.
여기서 Loc은 인덱스를 상징합니다. count는 데이터 예제의 합계를 계산하려는 것을 의미합니다.
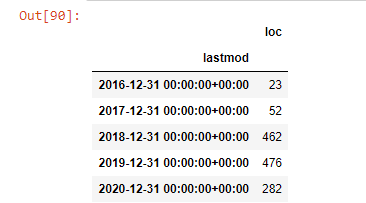
우리는 그들이 2016년에 기사를 출판하기 시작했지만 2017년 이후 주요 출판 경향이 증가했음을 알 수 있습니다. Plotly Graph Objects의 도움으로 이것을 그래픽에 넣을 수도 있습니다.
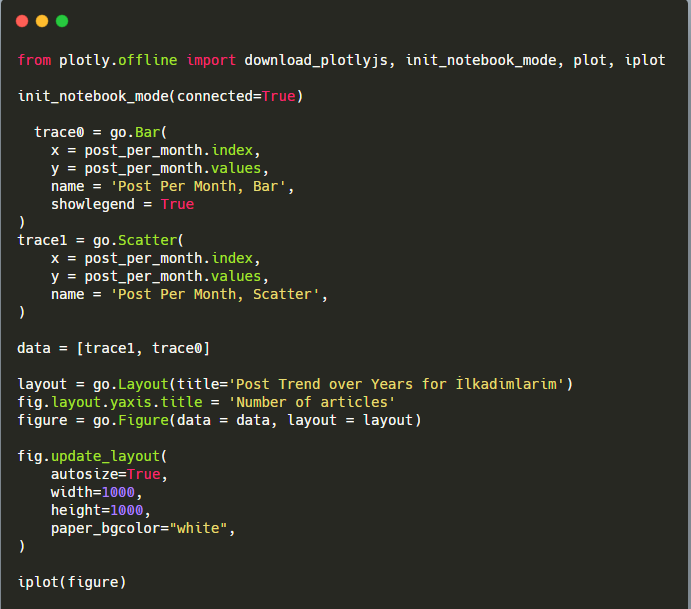
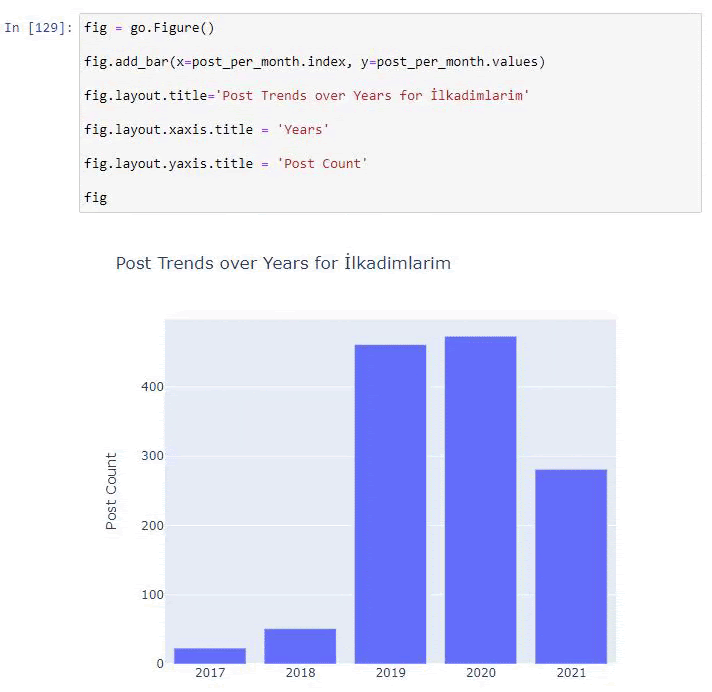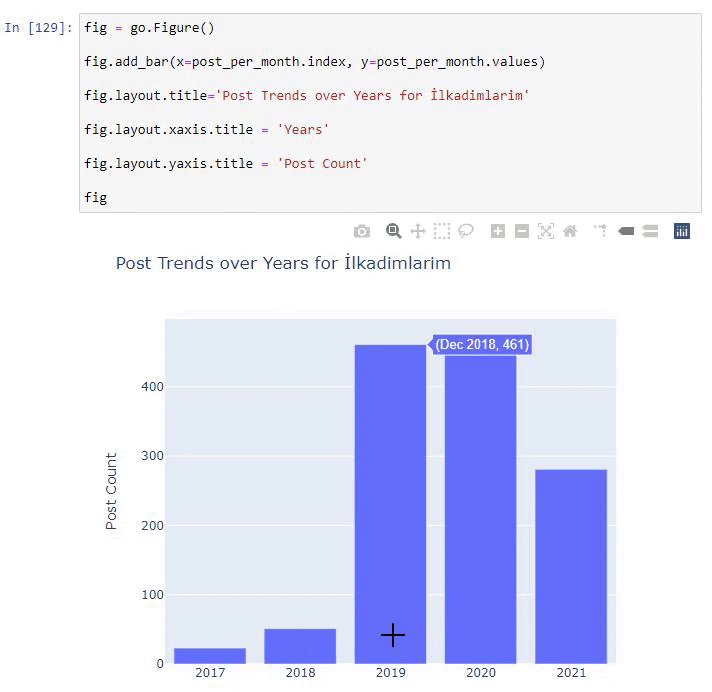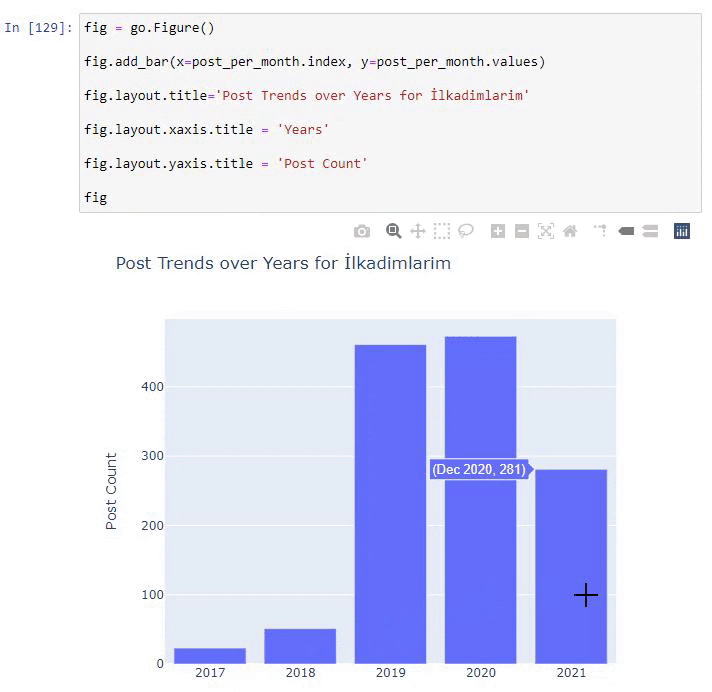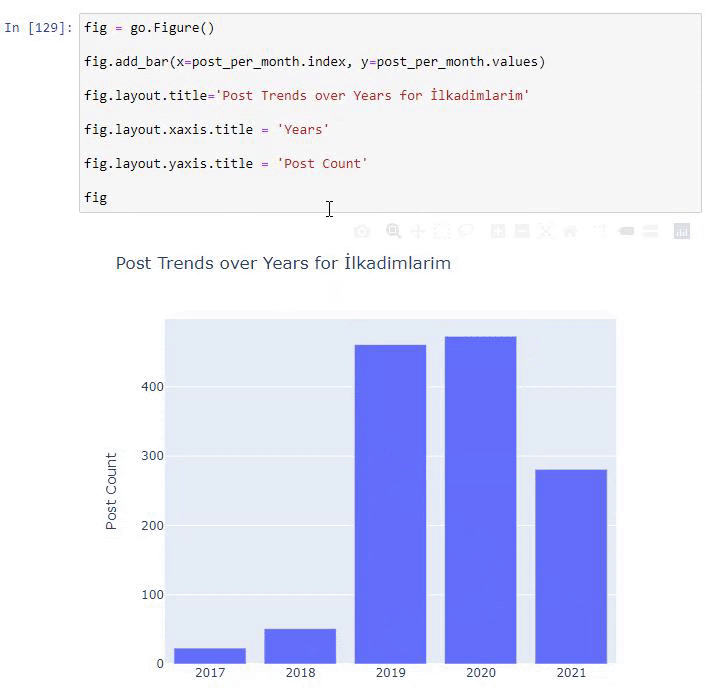
이 Plotly Bar Plot 코드 조각에 대한 설명:
- fig = go.Figure() 는 Figure를 생성하기 위한 것입니다.
- fig.add_bar() 는 그림에 막대그래프를 추가하기 위한 것입니다. 또한 괄호 안에 들어갈 X축과 Y축을 결정합니다.
- Fig.layout 은 도형과 축에 대한 일반 제목을 생성하기 위한 것입니다.
- 마지막 줄에서 우리는 go.Figure() 와 같은 fig 명령으로 생성한 플롯을 호출합니다.
아래에서 산점도 및 막대 그래프를 사용하여 월별로 동일한 데이터를 찾을 수 있습니다.
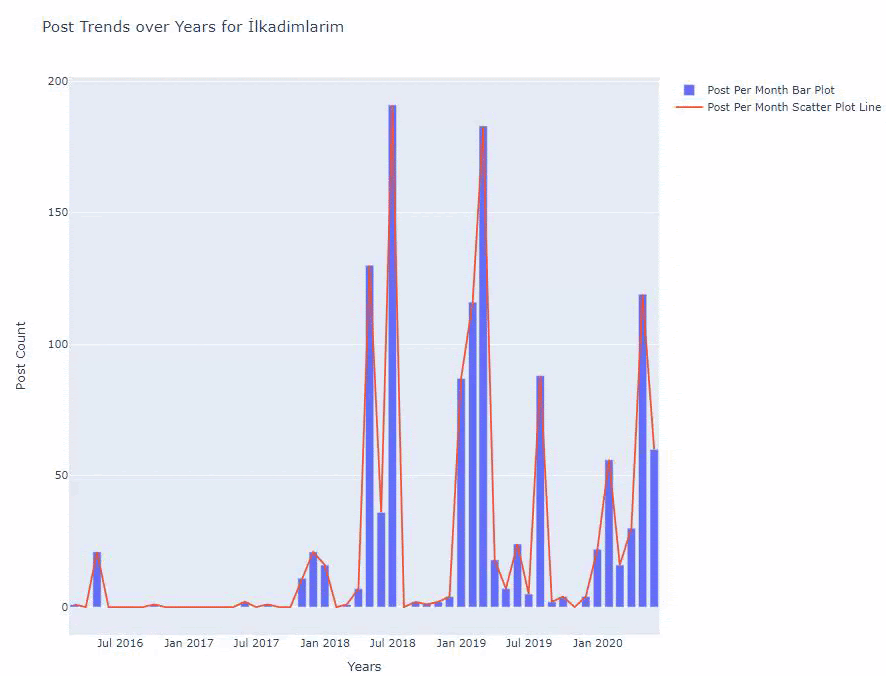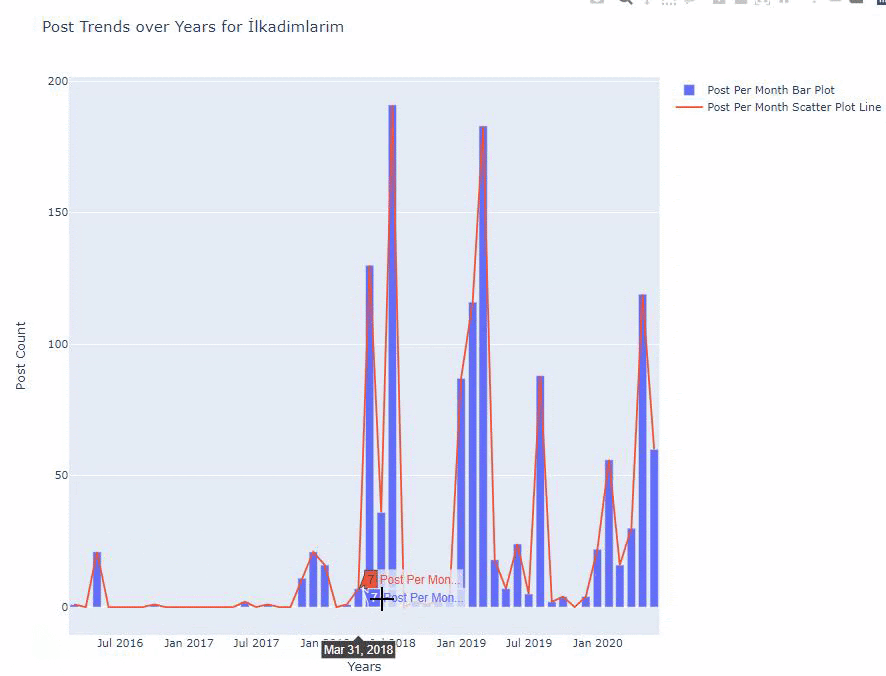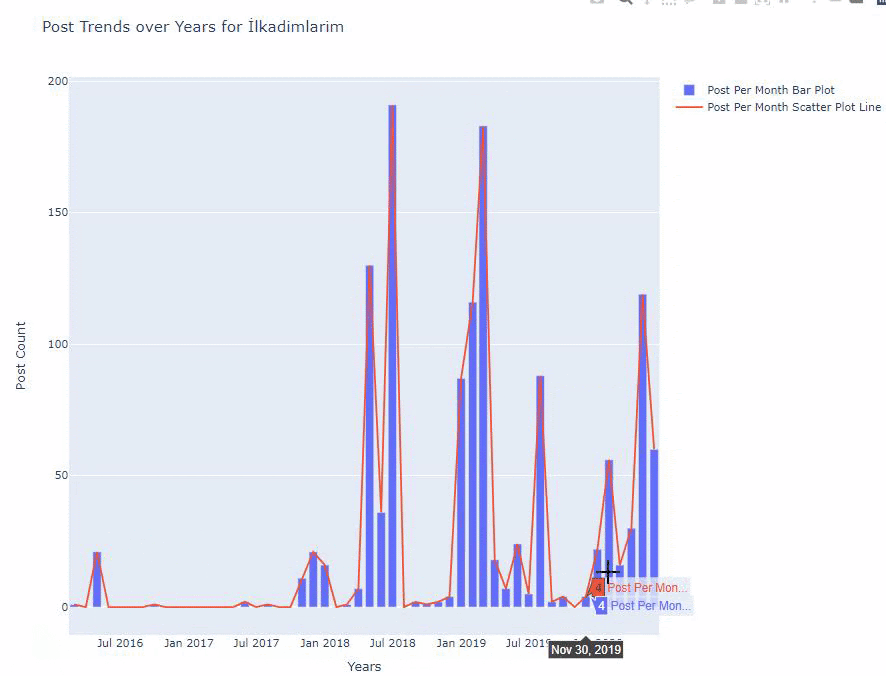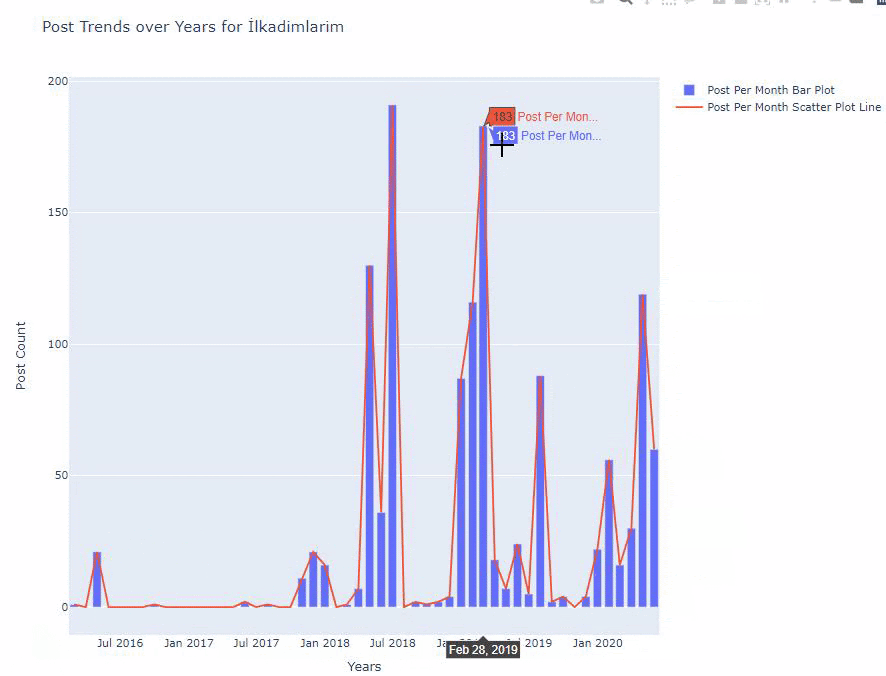
이 그림을 만드는 코드는 다음과 같습니다.
fig.add_scatter() 를 사용하여 두 번째 플롯을 추가했으며 name 속성을 사용하여 이름도 변경했습니다. fig.update_layout() 은 플롯의 크기와 배경색을 변경하기 위한 것입니다.
또한 호버 모드, 막대 사이의 거리 등을 변경할 수 있습니다. 여기에서 각 코드를 별도로 설명하면 주요 주제에서 벗어날 수 있으므로 코드만 공유하는 것으로 충분하다고 생각합니다.
우리는 또한 아래와 같은 카테고리에 따라 경쟁사의 콘텐츠 퍼블리싱 트렌드를 비교할 수 있습니다.
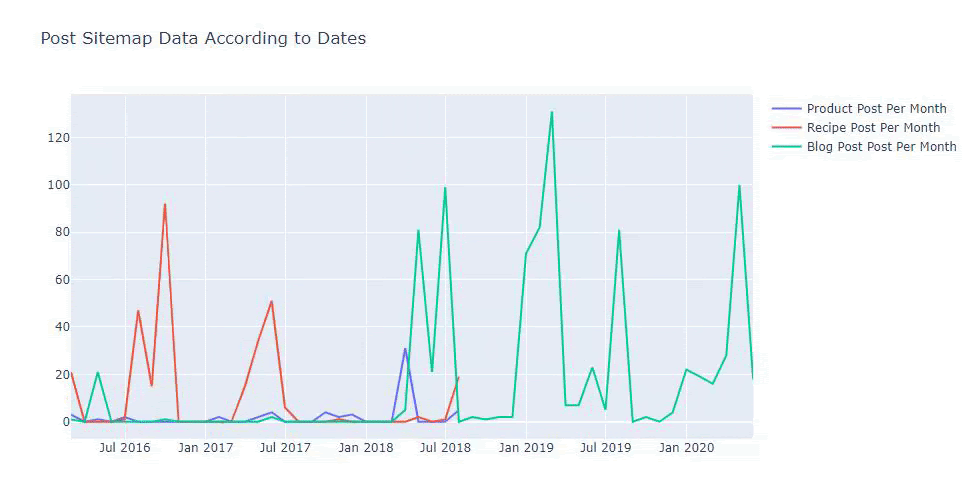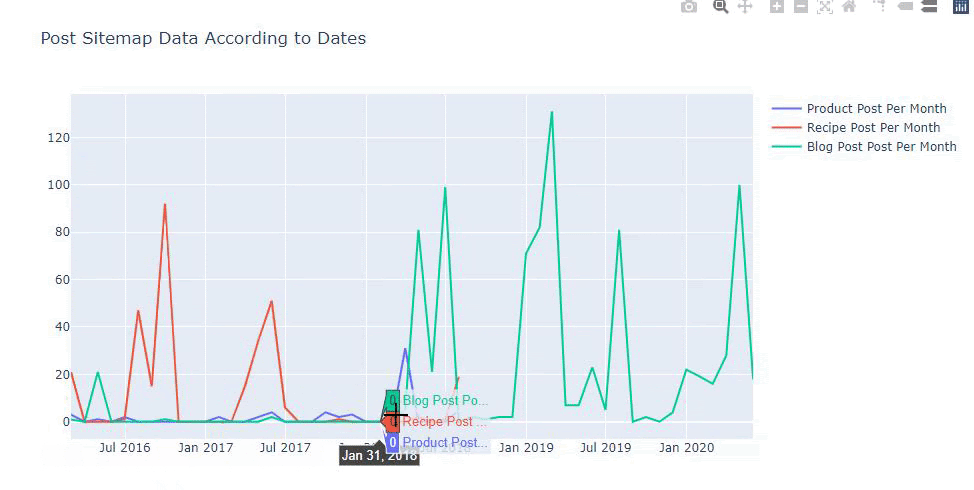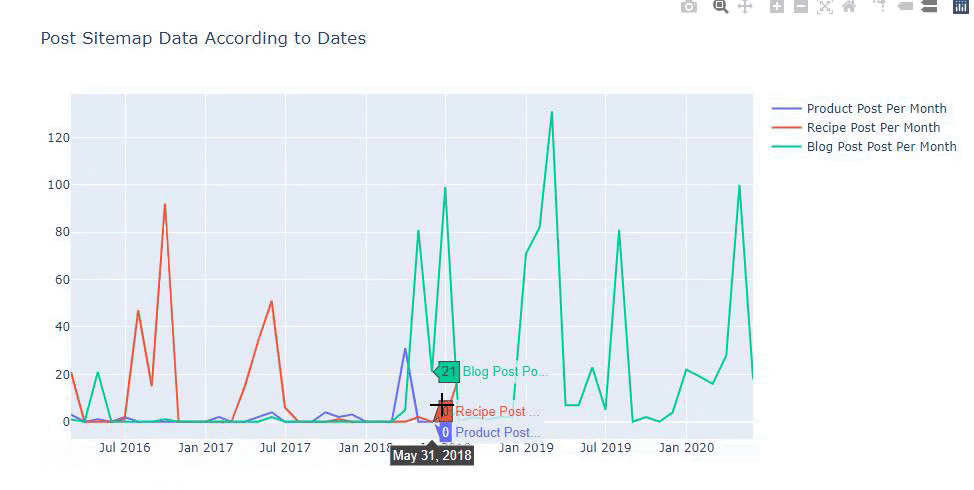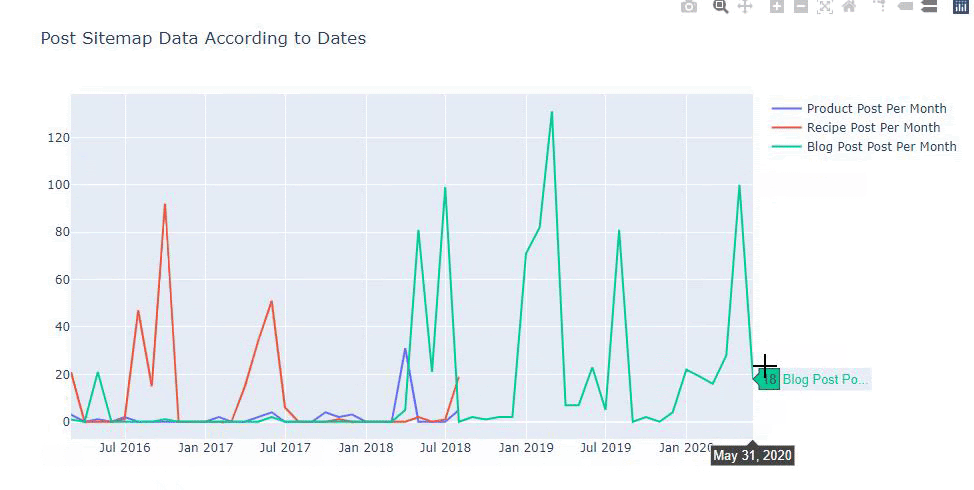
이 차트는 차이가 없음을 알 수 있듯이 두 번째 방법으로 생성되었지만 그 중 하나는 매우 간단합니다.
3개의 개별 사이트맵에서 콘텐츠를 게시하는 빈도와 추세를 차트로 나타내려면 간격이 가장 긴 사이트맵을 X축에 배치해야 합니다. 따라서 우리는 조사 중인 웹사이트가 검색 의도에 따라 각기 다른 유형의 콘텐츠를 게시하는 빈도를 비교할 수 있습니다.
아래 관련 코드를 살펴보면 위와 크게 다르지 않음을 알 수 있습니다.
여러 Y 축이 있는 산점도를 생성하려면 아래 코드를 사용할 수 있습니다.
다른 사이트맵을 통합하고 열이 산점도에서 여러 Y 축을 사용하도록 for 루프를 사용하는 것과 같은 다른 방법이 있지만 그러한 작은 사이트에서는 필요하지 않습니다. 대부분의 경우 수백 개의 사이트맵이 있는 웹사이트에서 이 방법을 사용하는 것이 더 논리적입니다.
또한 웹 사이트가 작기 때문에 그래픽이 얕아 보일 수 있지만 수백만 개의 URL이 있는 웹 사이트의 기사 뒷부분에서 볼 수 있듯이 이러한 그래픽은 다른 사이트를 비교하고 다른 범주를 비교할 수 있는 좋은 방법입니다. 같은 웹사이트.
Sitemap 및 Python을 사용하여 콘텐츠 범주, 의도 및 게시 추세 조사 및 시각화
이 섹션에서는 기사의 시작 부분에서 말한 소수의 제품을 마케팅하기 위해 특정 지식 영역에서 많은 콘텐츠를 작성했는지 확인합니다. 덕분에 다른 브랜드와 콘텐츠 제휴 여부를 알 수 있다.
사이트맵에서 찾을 수 있는 다른 것을 보여주기 위해 계속해서 조금 더 파고들 것입니다. 우리는 또한 다른 것들과 같은 사이트맵의 'loc' 부분에서 일부 정보를 얻을 수 있습니다.
Ilkadimlarim의 URL에는 카테고리 분류가 없습니다. 웹사이트의 URL에 카테고리 분류가 있는 경우 콘텐츠 배포에 대해 더 많이 알 수 있습니다. 그렇지 않은 경우 추가 코드를 작성하여 동일한 데이터에 액세스할 수 있지만 확실성은 떨어집니다.
이 시점에서 URL 분석이 수십억 개의 사이트를 크롤링하는 검색 엔진이 귀하의 웹사이트를 이해하는 데 드는 비용이 얼마나 절감되는지 상상할 수 있습니다.
a = ilkadimlarim['loc'].str.contains("bebek|hamile|haftalik")
베벡: 베이비
하밀레: 임신
Haftalik: 매주 또는 "임신한 주"
baby_post_count = ilkadimlarim[a].resample('M')['loc'].count()
baby_post_count.to_frame()
여기서 str() 메서드를 사용하면 특정 작업을 선택하는 열을 설정할 수 있습니다.
contains() 메서드를 사용하여 문자열로 변환된 데이터에 포함되어 있는지 확인하기 위해 데이터를 판별합니다.
여기서 "|" 용어 사이는 "또는" 을 의미합니다.
그런 다음 필터링한 데이터를 변수에 할당하고 이전에 사용한 resample() 메서드를 사용합니다.
반면에 count 방식은 어떤 데이터가 얼마나 많이 사용되었는지를 측정합니다.
count() 로 얻은 결과는 다시 to_frame() 으로 묶입니다.
또한 str.contains() 는 기본적으로 Regex 값을 사용하므로 더 적은 코드로 더 복잡한 필터링 조건을 만들 수 있습니다.
즉, 이 시점에서 "baby", "weekly", "pregnant"라는 단어가 포함된 URL을 ilkadimlarim 의 변수에 할당한 다음 URL의 게시 날짜를 이 필터에 대한 적절한 조건에 넣습니다. 프레임으로 생성됩니다.
그런 다음 'aptamil'이라는 단어가 포함된 URL에 대해서도 동일한 작업을 수행합니다. 압타밀은 일카딤라림이 선보인 유아영양제품의 이름이다. 따라서 정보 및 상업 콘텐츠의 방송 밀도에도 주의를 기울일 수 있습니다.
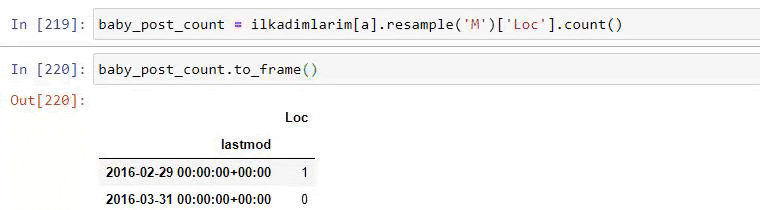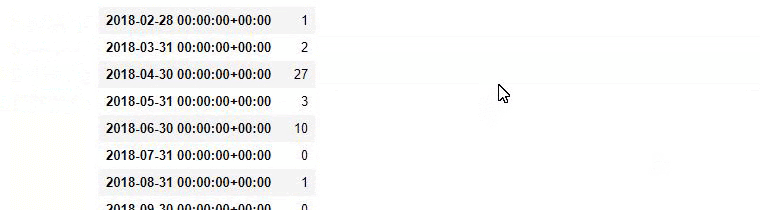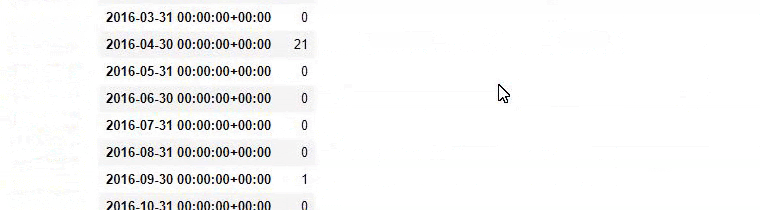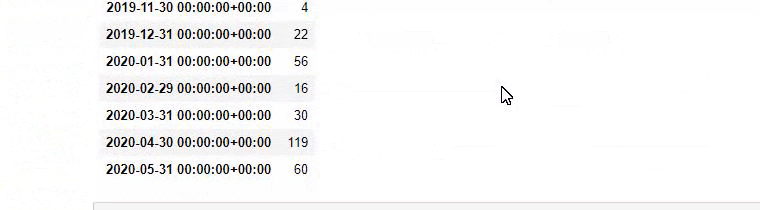
그리고 URL에서 더 확실하고 정확한 정보를 사용하여 서로 다른 검색 의도에 대해 수년에 걸쳐 일정을 게시하는 두 개의 서로 다른 콘텐츠 그룹을 볼 수 있습니다.
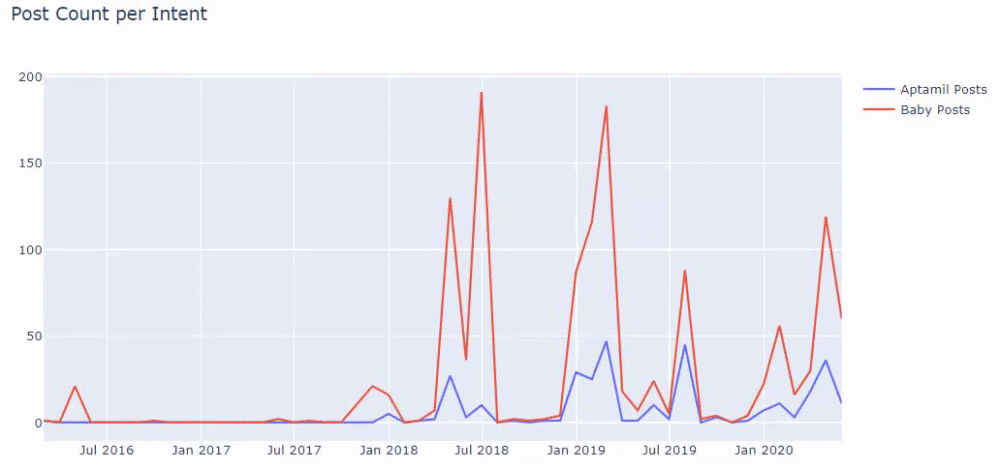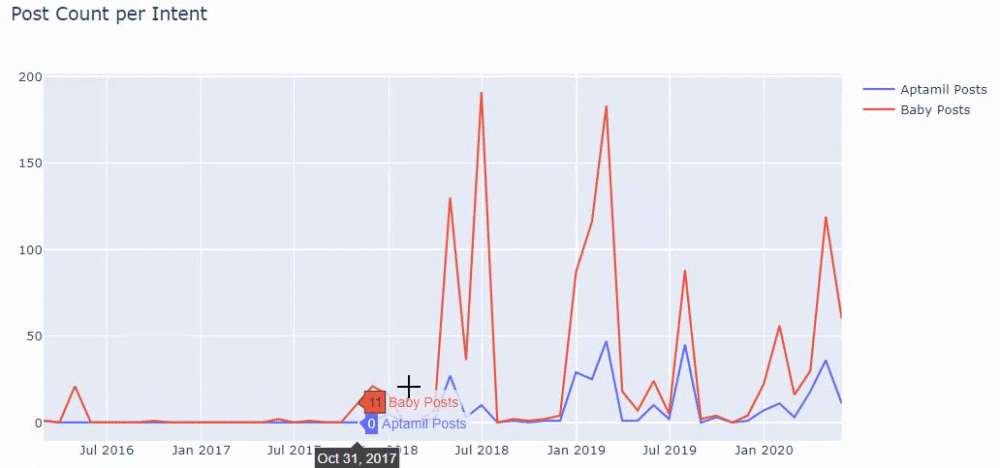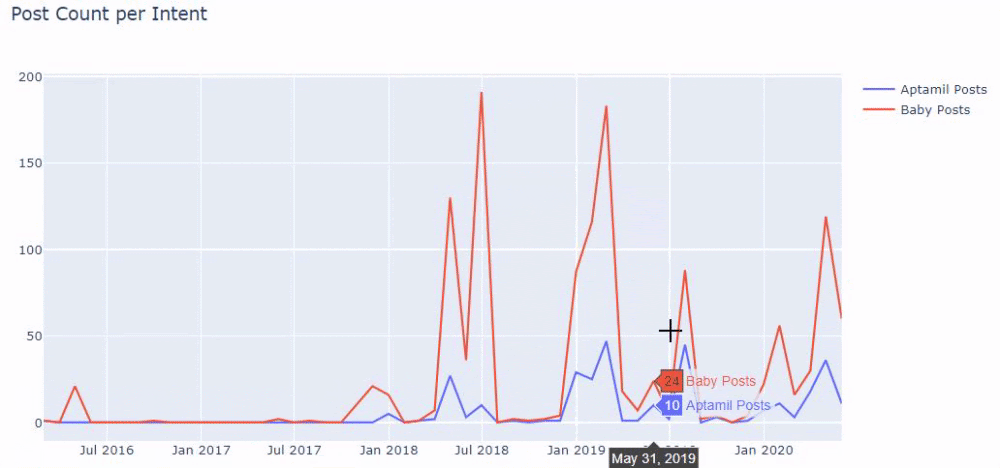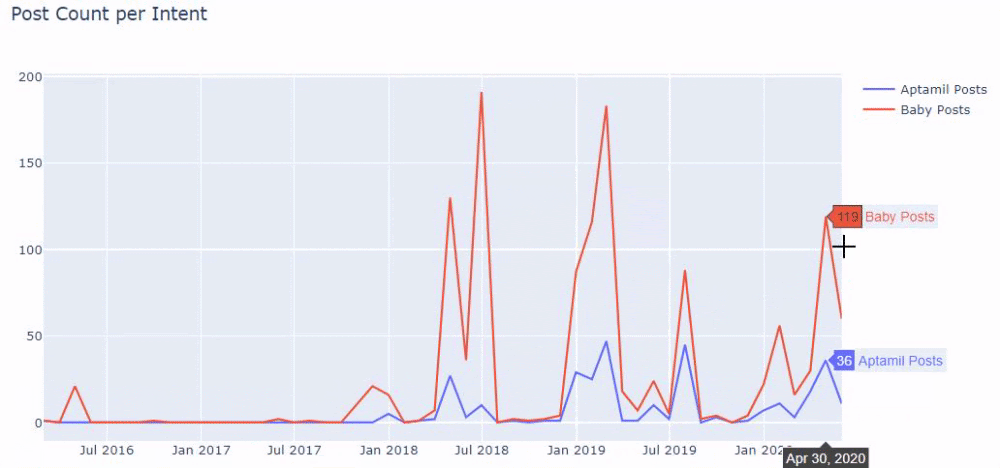
이 차트를 생성하는 코드는 이전 차트에 사용된 것과 동일하므로 공유되지 않았습니다.
Google의 검색 연산자 덕분에 Ilkadimlarim.com의 앵커 텍스트에 Aptamil이라는 단어가 사용된 페이지를 원할 때 38개의 결과를 얻었습니다. 이 페이지의 중요한 숫자는 정보를 제공하며 상업적 콘텐츠를 연결합니다.
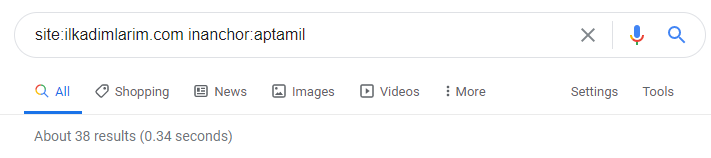

우리의 논문이 입증되었습니다.
"My First Steps"는 모성, 아기 돌보기 및 임신에 관한 수백 가지의 유익한 콘텐츠를 사용하여 대상 고객에게 다가갑니다. "일카딤라림"은 이 콘텐츠에서 앱타밀 제품이 포함된 페이지를 링크하고 사용자를 그곳으로 안내합니다.
Python을 사용한 Sitemap을 통한 비교 콘텐츠 프로파일링 및 콘텐츠 전략 분석
이제 원하신다면 동종 업계의 회사에 대해 동일한 작업을 수행하고 이 업계의 일반적인 측면과 두 브랜드 간의 전략 차이점을 이해하기 위해 비교를 해 보겠습니다.
두 번째 예로 Pampers라는 Prima.com.tr을 선택했지만 터키에서는 Prima라는 브랜드 이름을 사용합니다. Prima에는 단일 사이트맵이 있기 때문에 사이트맵으로 분류할 수는 없지만 적어도 URL에는 서로 다른 구분선이 있습니다. 따라서 우리는 매우 운이 좋습니다. 더 적은 코드를 작성해야 할 것입니다.
이해하기 어려운 사이트를 만들 때 Google에서 실행해야 하는 알고리즘이 얼마나 더 비용이 많이 드는지 상상해 보십시오! 이렇게 하면 URL 구조와 관련하여도 크롤링 비용 계산을 더 명확하게 이해할 수 있습니다.
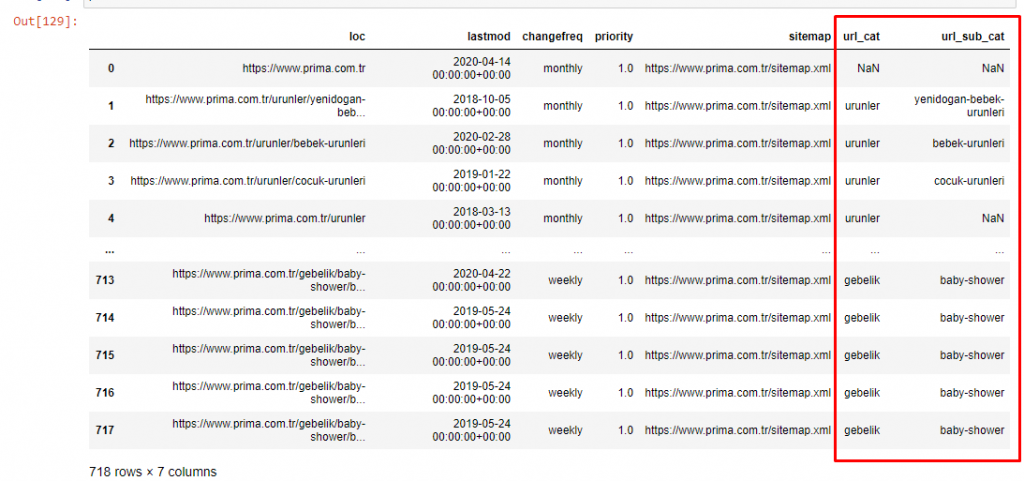
기사의 양을 더 늘리지 않기 위해 우리는 이미 수행한 것과 유사한 프로세스의 코드를 배치하지 않습니다.
이제 URL 범주 및 URL 하위 범주별로 콘텐츠 범주 분포를 조사할 수 있습니다. 우리는 그들이 회사 웹 페이지의 과도한 양을 가지고 있음을 알 수 있습니다. 이러한 기업 웹 페이지는 "prima-hakkinda"("Prima 정보") 섹션에 있습니다. 하지만 파이썬으로 확인해 보니 제품과 기업 웹페이지를 하나의 카테고리로 통합한 것을 볼 수 있습니다. 아래에서 콘텐츠 배포를 볼 수 있습니다.

다음 하위 범주에 대해서도 동일한 작업을 수행할 수 있습니다.
Prima가 "hamilek"(아랍어로 임신)의 변형인 "gebelik"(터키어로 임신)을 사용하고 둘 다 임신 기간을 의미한다는 점에 주목하는 것이 흥미로웠습니다.

이제 우리는 콘텐츠에 대한 더 깊은 분류를 봅니다. 내용의 9.2%는 건강한 임신, 7.3%는 아기의 성장 과정, 8.3%는 아기와 함께 할 수 있는 활동, 0.7%는 아기의 수면 순서에 관한 내용입니다. 이가 3.9%, 아기 안전이 1.9%, 가족에게 임신 사실을 알린다는 1.4%와 같은 주제도 있습니다. 보시는 바와 같이 URL과 그 분포율만으로도 업종을 알 수 있습니다.
이것은 완벽한 분류는 아니지만 적어도 우리는 경쟁자들의 마인드와 콘텐츠 마케팅 트렌드, 그리고 카테고리에 따른 그들의 웹사이트 콘텐츠를 볼 수 있습니다. 이제 월별 콘텐츠 퍼블리싱 빈도를 확인해보자.
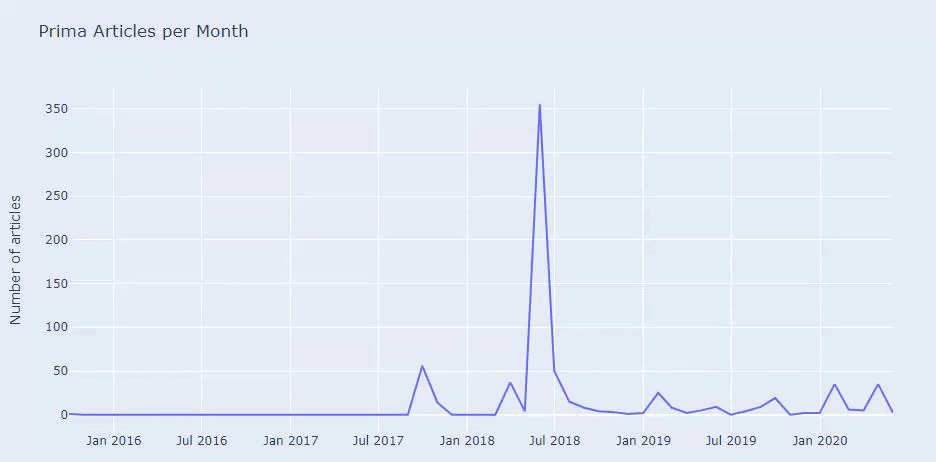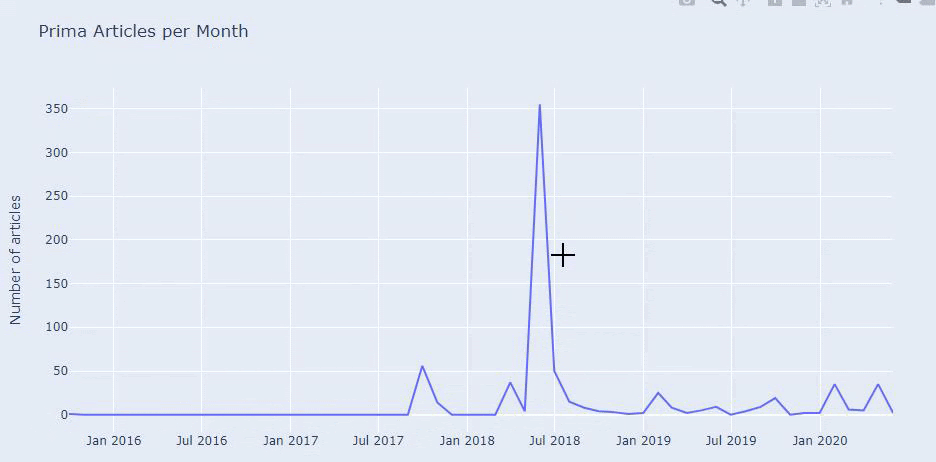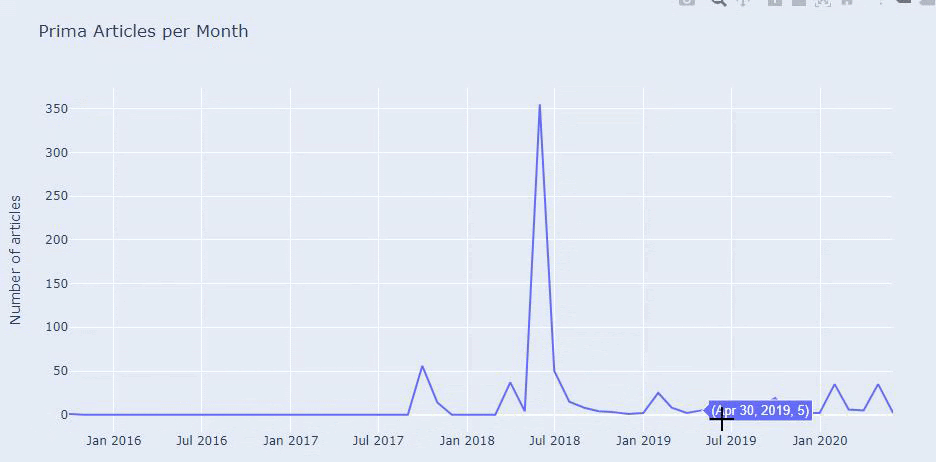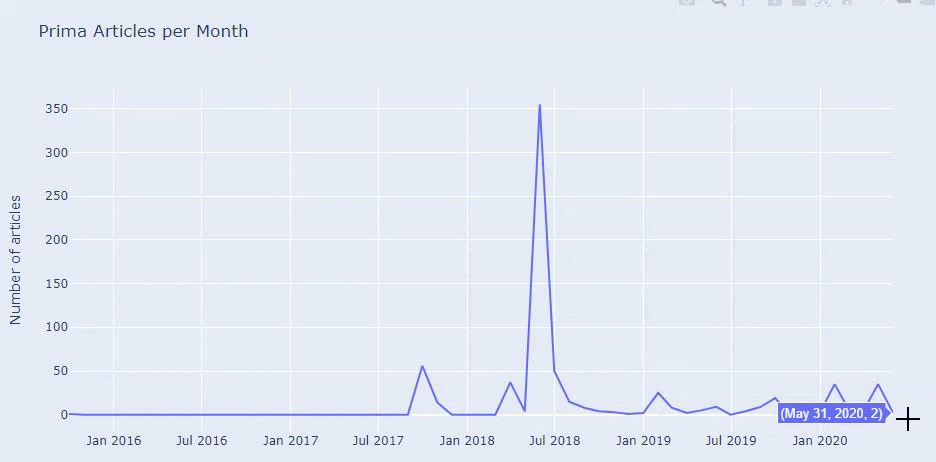
2018년 7월에 355개의 기사를 게시했으며 Sitemap에 따르면 그 이후로 내용이 새로 고쳐지지 않습니다. 또한 지난 몇 년 동안 카테고리별로 콘텐츠 퍼블리싱 트렌드를 비교할 수 있습니다. 보시다시피, 그들의 콘텐츠는 주로 4개의 다른 범주에 있으며 대부분은 같은 달에 게시됩니다.
계속하기 전에 사이트맵 데이터가 항상 정확하지 않을 수 있음을 말씀드리고 싶습니다. 예를 들어 이 날짜에 모든 사이트맵을 갱신했기 때문에 모든 URL에 대해 Lastmod 데이터가 업데이트되었을 수 있습니다. 이 문제를 해결하기 위해 Wayback Machine을 사용하여 그 이후로 콘텐츠를 변경하지 않았는지 확인할 수도 있습니다.
의심스러워 보여도 이 데이터는 진짜일 수 있습니다. 터키의 많은 기업들은 주문을 많이 하고 잠시 전에 콘텐츠를 공개하는 경향이 있습니다. 키워드 수를 확인하면 이 기간이 급증하는 것을 볼 수 있습니다. 따라서 비교 콘텐츠 프로필 및 전략 분석을 수행하는 경우 이러한 문제도 고려해야 합니다.
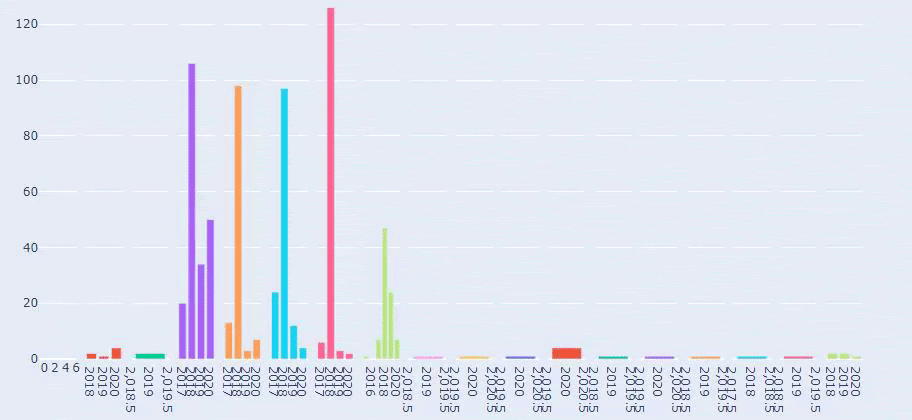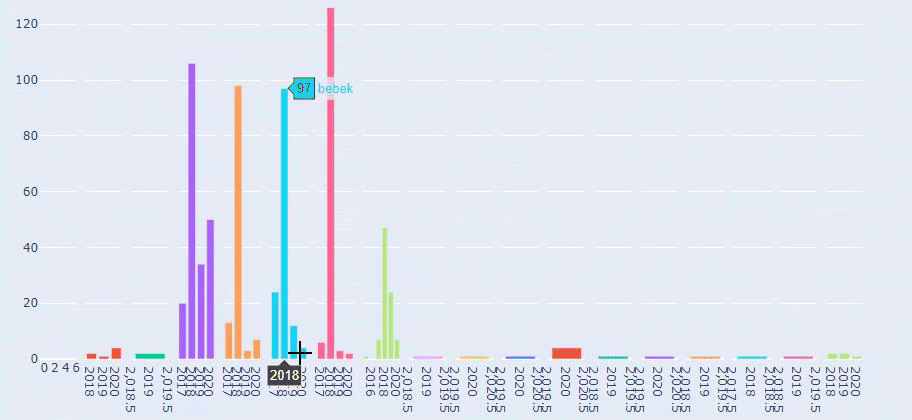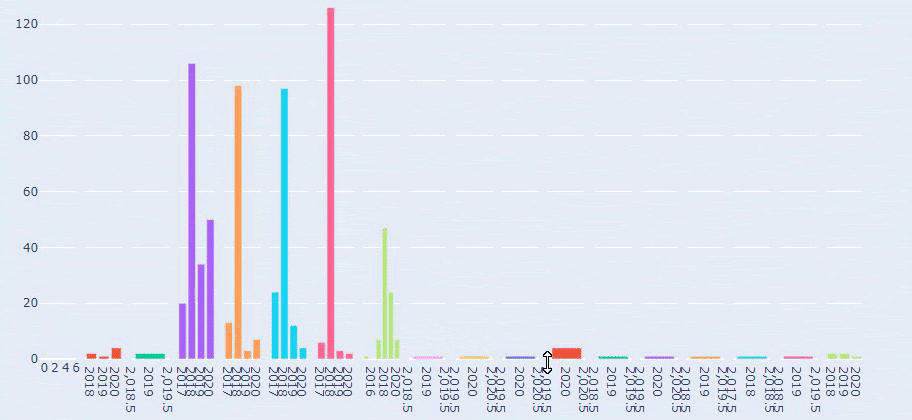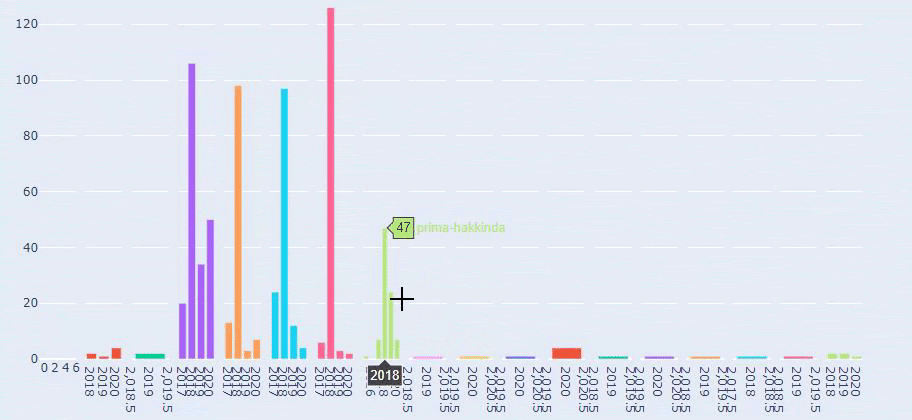
이것은 Prima.com.tr에 대한 모든 카테고리의 수년 간 콘텐츠 게시 동향을 비교한 것입니다.
이제 서로 다른 두 웹사이트의 콘텐츠 카테고리와 게시 동향을 비교할 수 있습니다.
Prima가 아기 성장, 임신 및 모성에 관한 기사를 게시하는 빈도를 살펴보면 Ilkadimlarim과 유사한 점을 알 수 있습니다.
- 대부분의 기사는 특정 시간에 게시되었습니다.
- 그들은 오랫동안 업데이트되지 않았습니다.
- 정보 콘텐츠 페이지 수에 비해 상품과 페이지 수가 매우 적었다.
- 최근에 그들은 사이트에 새로운 제품을 추가했습니다.
우리는 이 네 가지 기능을 업계의 기본 사고 방식으로 간주할 수 있으며 이러한 약점을 캠페인에 유리하게 사용할 수 있습니다. 결국 품질은 신선함을 요구합니다(Google 펠로우 Amit Singhal이 말한 대로).
이 시점에서 업계가 Googlebot의 행동에 익숙하지 않다는 것도 알 수 있습니다. 하루에 250개의 콘텐츠를 업로드하고 1년 동안 변경하지 않는 것보다 주기적으로 새로운 콘텐츠를 추가하고 오래된 콘텐츠를 정기적으로 업데이트하는 것이 좋습니다. 따라서 콘텐츠의 품질을 유지할 수 있고 Googlebot이 사이트를 더 쉽게 이해할 수 있으며 크롤링 요구 빈도 값이 경쟁업체보다 높습니다.
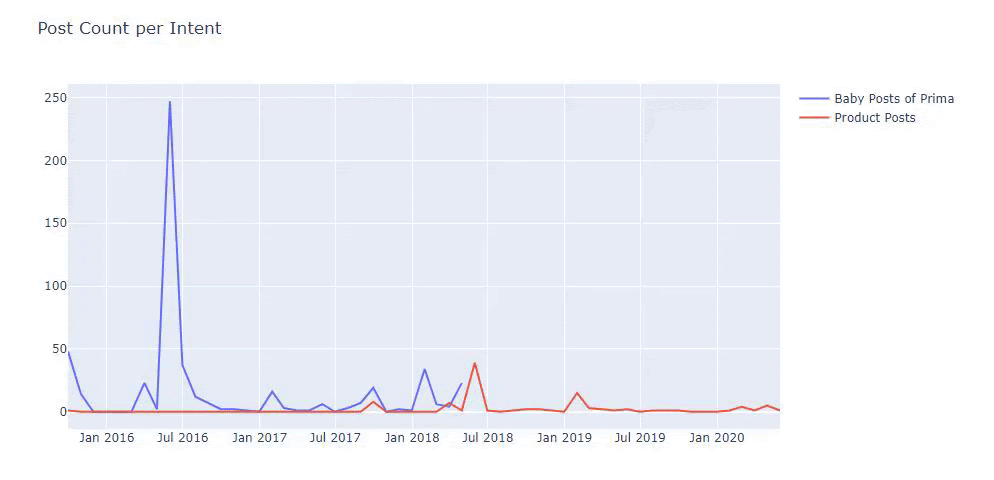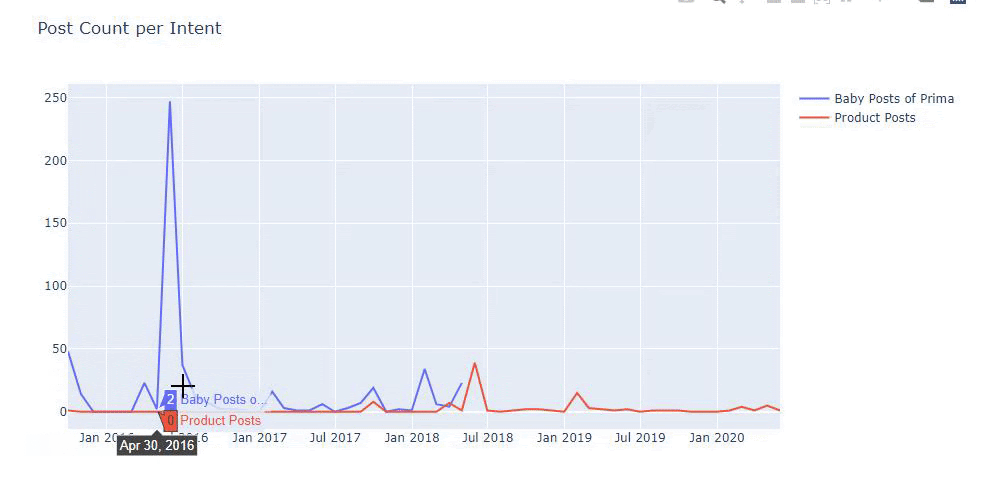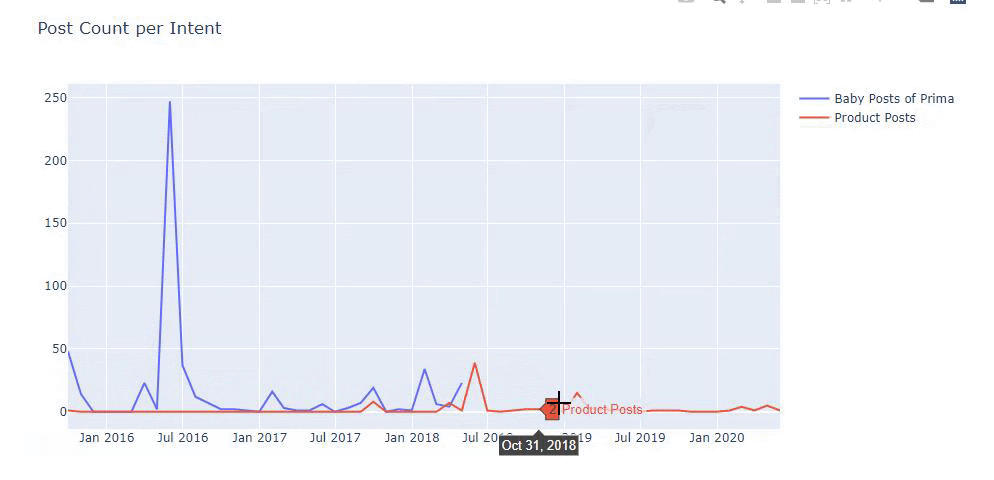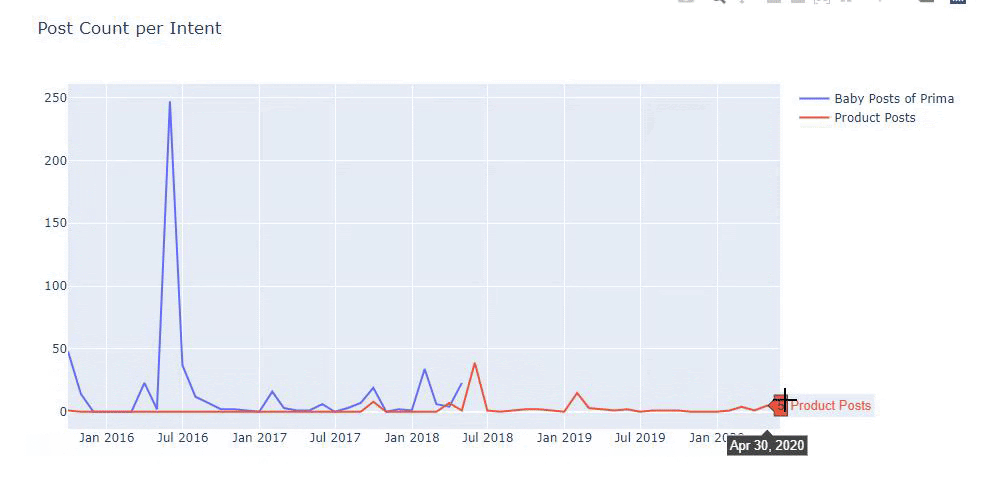
이전 방법을 사용하여 제품과 정보 콘텐츠 페이지를 구분하고 URL에서 가장 많이 사용되는 단어를 프로파일링했습니다. 여기에서 베이비 포스트는 유익한 콘텐츠임을 의미합니다.
보시다시피 하루에 247개의 콘텐츠를 추가했습니다. 또한 1년이 넘는 기간 동안 유익한 콘텐츠를 게시하거나 새로 고치지 않았으며 가끔 새로운 제품 페이지를 추가했습니다.
이제 하나의 그림에서 두 개의 다른 플롯으로 출판 경향을 비교해 보겠습니다. 이 그림을 만들기 위해 아래 코드를 사용했습니다.
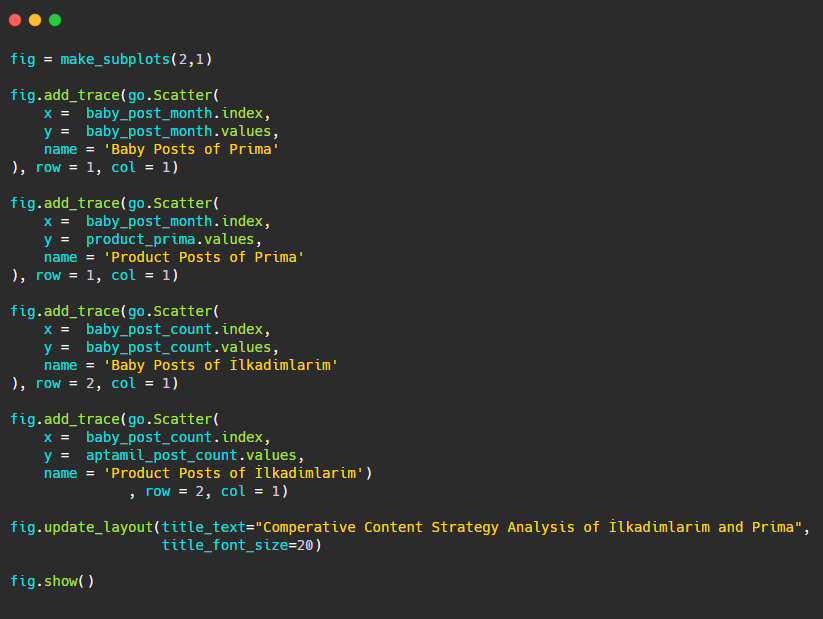
이 그래픽은 이전 그래픽과 다르기 때문에 코드를 보여드리고 싶었습니다. 여기에서 두 개의 개별 플롯이 동일한 그림에 배치됩니다. 이를 위해 make_subplots 메서드는 plotly.subplots import make_subplots의 명령으로 호출되었습니다.
make_subplots (2,1) 을 사용하여 2행 1열 그림으로 생성되었습니다.
따라서 col 및 row는 트레이스의 끝에 기록되고 위치가 지정됩니다. CSS의 그리드 시스템에 익숙한 사람이라면 누구나 쉽게 알아볼 수 있는 시스템입니다.
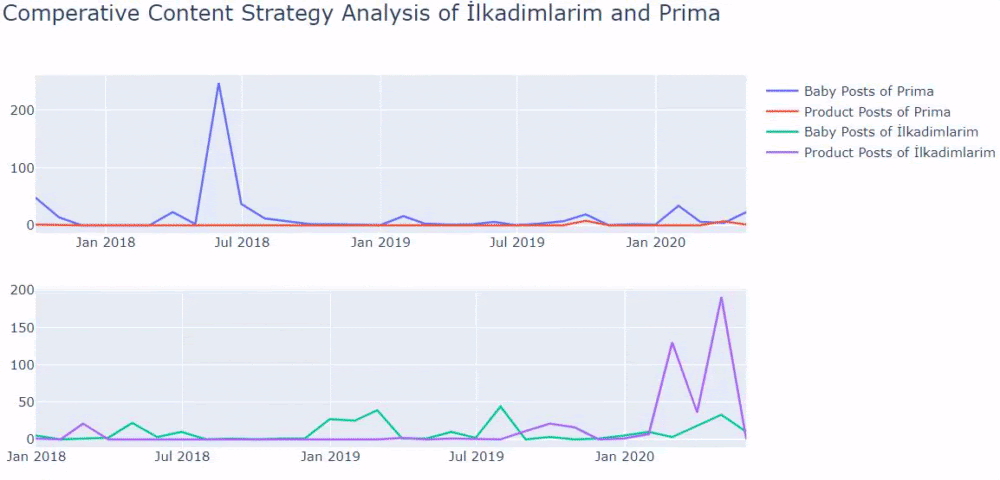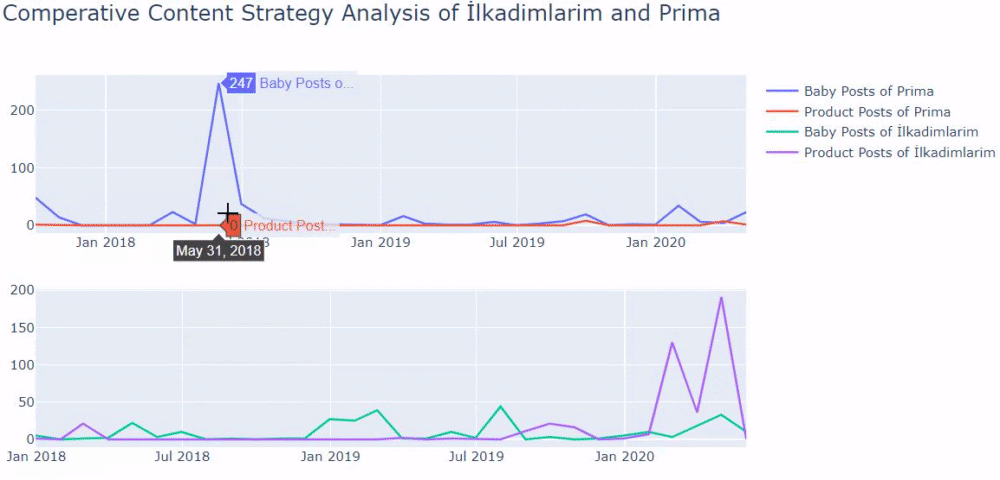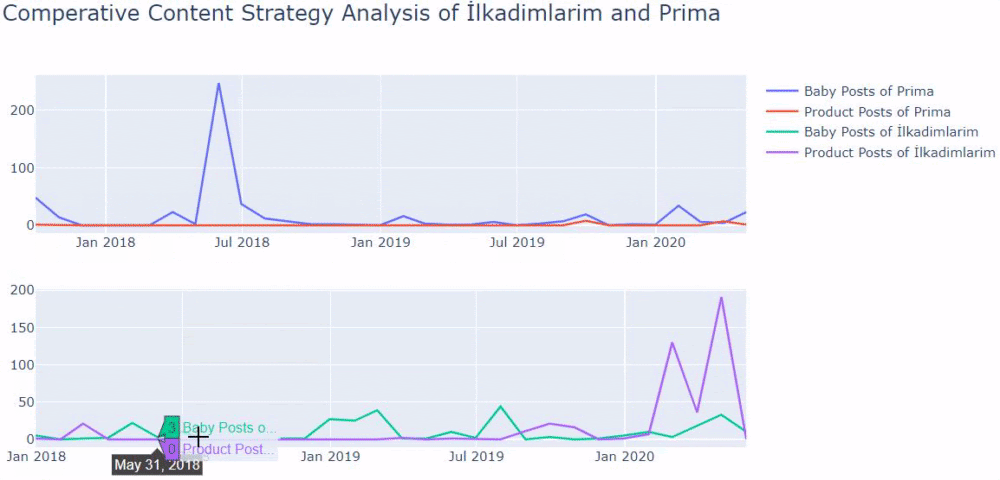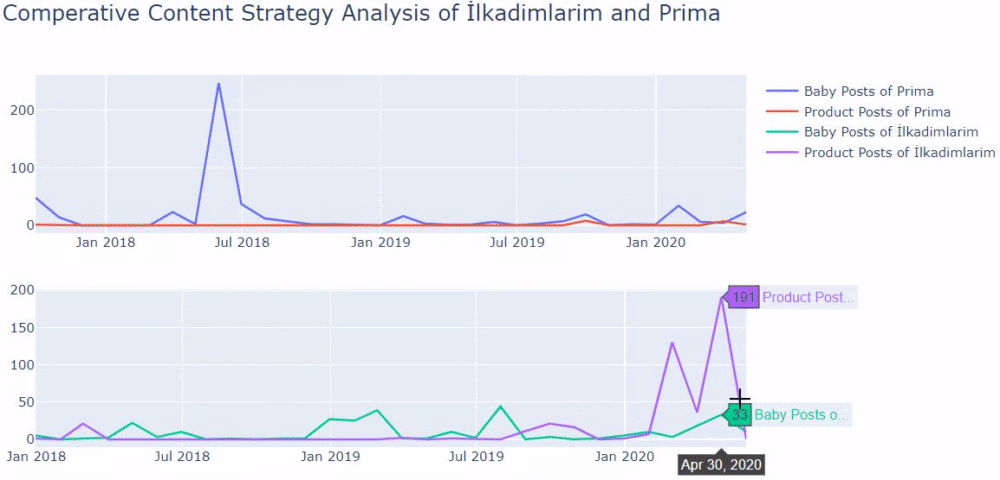
동일한 부문에 고객이 있는 경우 이 데이터를 사용하여 콘텐츠 전략을 만들고 경쟁사의 약점과 SERP를 통한 쿼리/랜딩 페이지 네트워크를 볼 수 있습니다. 또한 동일한 지식 영역 또는 동일한 사용자 의도에 대해 게시해야 하는 콘텐츠의 양을 이해할 수 있습니다.
콘텐츠 전략 분석의 일환으로 사이트맵에서 배울 수 있는 내용을 마무리하기 전에 다른 업계의 URL 수가 훨씬 더 많은 마지막 웹사이트를 살펴보겠습니다.
Python 및 Sitemap을 사용한 통화에 대한 뉴스 웹 엔터티의 콘텐츠 전략 분석
이 섹션에서는 Seaborn의 히트맵 플롯과 좀 더 멋진 프레이밍 및 데이터 추출 방법을 사용할 것입니다.

Elias Dabbas는 데이터 과학 및 SEO 측면에서 흥미롭고 정말 유용한 Kaggle Archive를 보유하고 있습니다. 이번 달에 그는 내가 필요한 코드를 작성하고 사이트맵을 통해 Advertools로 콘텐츠 전략 분석을 수행할 수 있도록 터키 뉴스 사이트용 Kaggle Dataset 섹션을 새로 열었습니다.
Kaggle에서 이러한 기술을 사용하기 시작하기 전에 이 기사에서 더 큰 웹 엔터티에서 동일한 기술을 사용할 경우 어떤 일이 발생하는지에 대한 몇 가지 예를 보여주고 싶습니다.
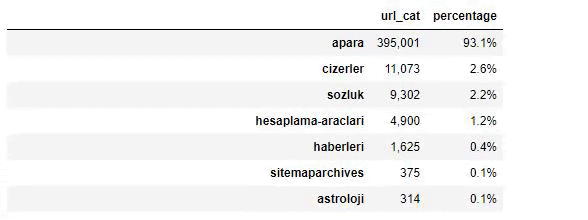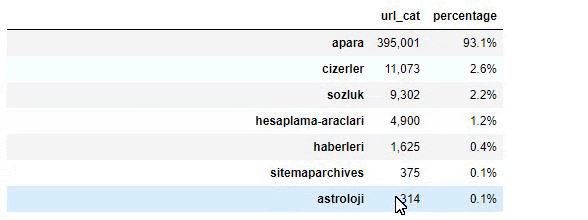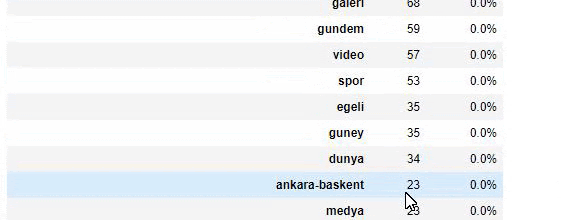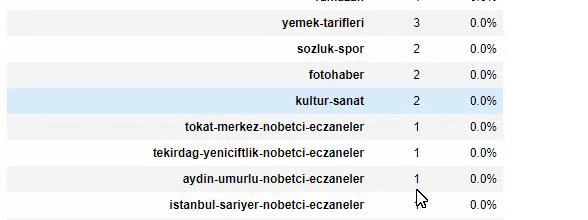
Sabah Newspaper의 내용을 분석할 때 내용의 상당 부분(81%)이 "apara"라는 범주에 있음을 알 수 있습니다. 또한 점성술, 계산, 사전, 날씨 및 세계 뉴스에 대한 몇 가지 큰 범주가 있습니다. (파라는 터키어로 돈을 의미)
Sabah Newspaper의 경우 Advertools로만 수집한 사이트맵으로 콘텐츠를 분석할 수도 있지만 해당 신문의 규모가 워낙 커서 사이트맵 수가 많고 동일한 URL을 포함하는 여러 사이트맵의 콘텐츠 때문에 선호하지 않았습니다. 범주.
아래에서 Advertools를 사용하여 초과된 사이트맵도 볼 수 있습니다.
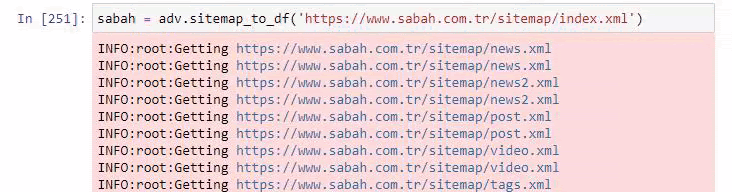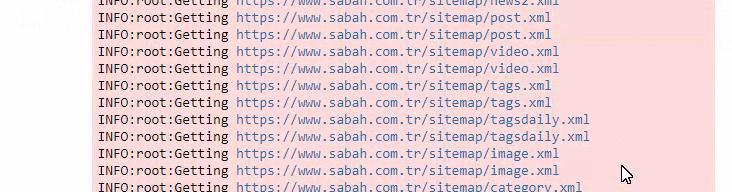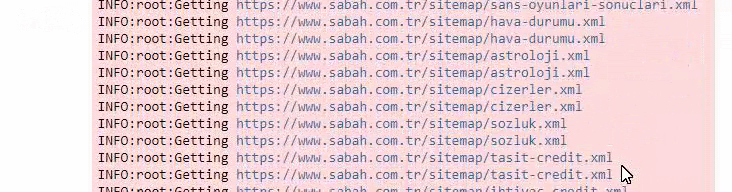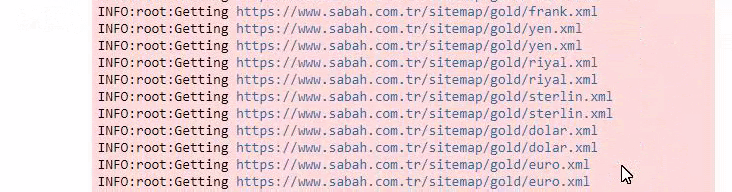
금, 신용, 통화, 태그, 기도 시간 및 약국 근무 시간 등과 같은 동일한 URL 범주에 대해 서로 다른 사이트맵이 있음을 알 수 있습니다.
요컨대, 우리는 URL의 하위 범주에 집중함으로써 이러한 세부 사항을 달성할 수 있습니다. 변수를 통해 다른 사이트맵을 통합하는 대신. 그래서 기사 초반과 같이 Advertools의 sitemap_to_df() 메소드로 모든 사이트맵을 통합했습니다.
또한 Elias Dabbas가 만든 다른 함수 집합을 사용하여 더 나은 데이터 프레임을 만들 수도 있습니다. dataset_utitilites 함수를 확인하면 몇 가지 예를 볼 수 있습니다. 아래 코드는 스타일 지정에 의한 누적 합계와 함께 지정된 URL 정규식의 전체 및 백분율을 제공합니다.
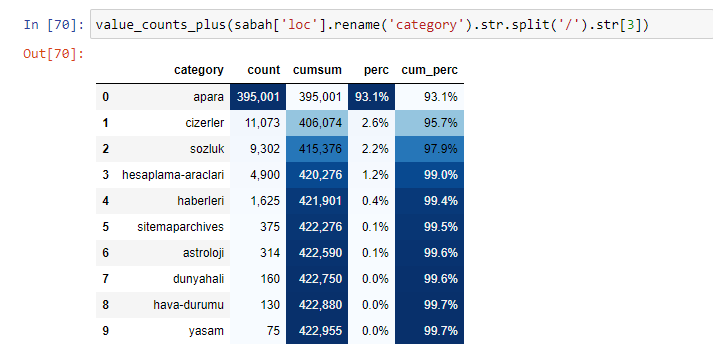
Sabah Newspaper의 하위 URL 분석에 대해서도 동일한 작업을 수행하면 다음과 같은 결과를 얻을 수 있습니다.
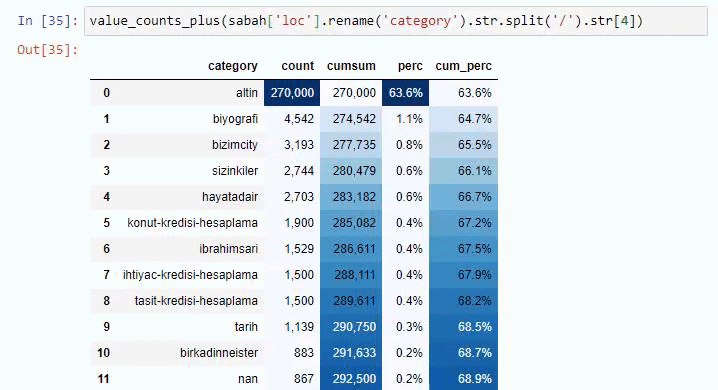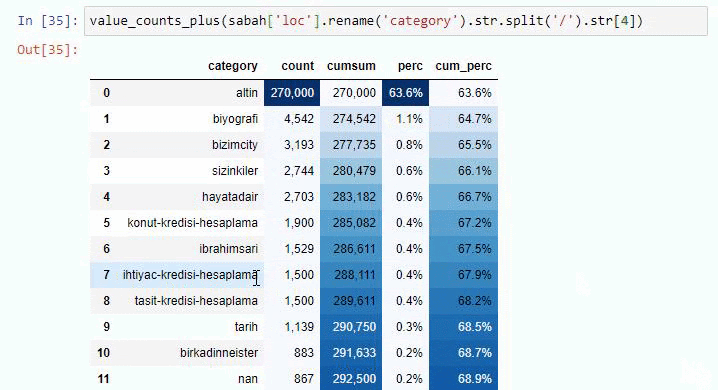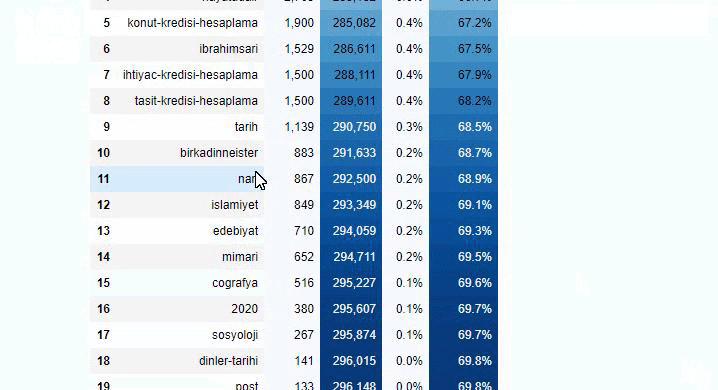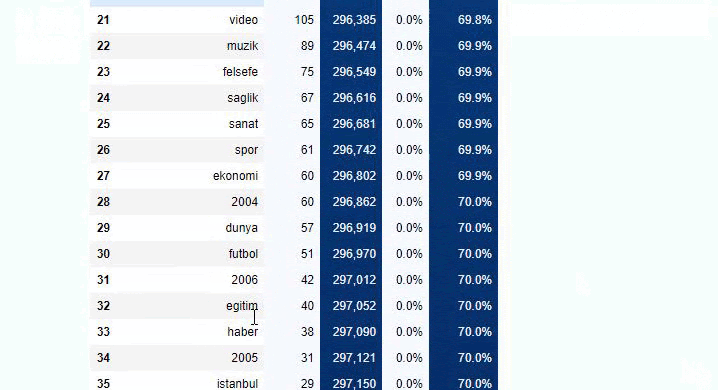
아래 줄을 변경하여 해당 함수가 출력할 줄 수를 늘릴 수 있습니다. 또한 함수의 내용을 살펴보면 이전에 사용한 것과 유사함을 알 수 있습니다.
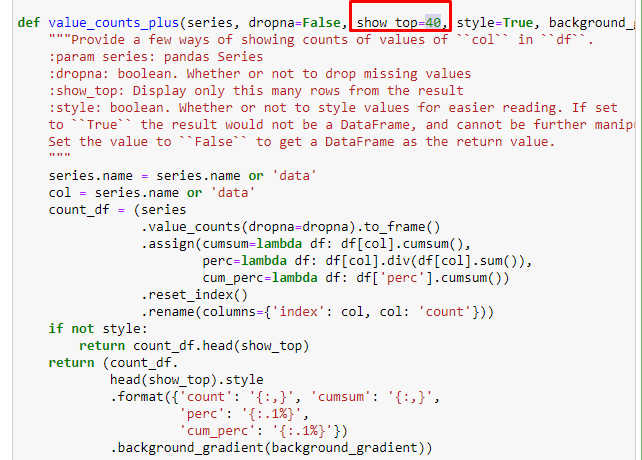
하위 분류에서 "종교 역사", "전기", "도시 이름", "축구", "Bizimcity(만화)", "모기지 신용"과 같은 다양한 분류를 볼 수 있습니다. 가장 큰 분류는 "골드" 카테고리입니다.
그렇다면 어떻게 신문에 금 가격에 대한 295,000개의 URL이 있을 수 있습니까?
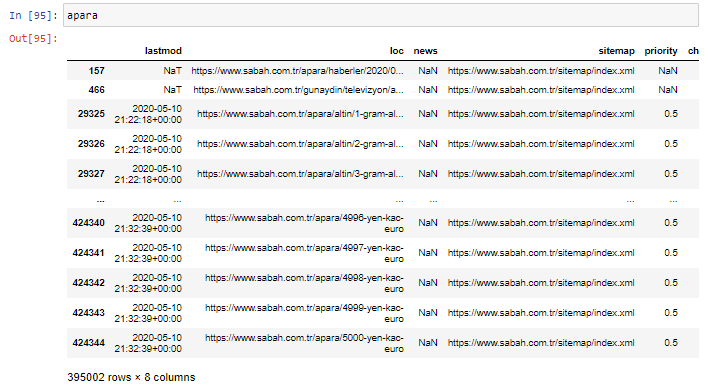
먼저 Sabah Newspaper의 첫 번째 URL 분석에서 "apara"가 포함된 모든 URL을 변수에 던집니다.
apara = 사바[sabah['loc'].str.contains('apara')]
결과는 다음과 같습니다.
.filter() 메서드를 사용하여 열을 필터링할 수도 있습니다.
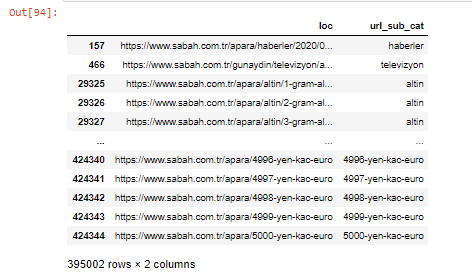
이제 DataFrame 하단에서 Sabah Newspaper가 5000유로, 4999유로, 4998유로 등과 같은 모든 통화 계산 금액에 대해 서로 다른 웹 페이지를 열었기 때문에 Apara URL이 과도하게 많은 이유를 알 수 있습니다.
그러나 이러한 URL 중 250,000개 이상이 'altin(gold)' 범주에 속하기 때문에 결론을 내리기 전에 확인해야 합니다.
apara.filter(['loc', 'url_sub_cat' ]).tail(60)은 이 데이터 프레임의 마지막 60줄을 보여줍니다.

Apara 그룹 내 골드 URL 분석에 대해서도 동일한 작업을 수행할 수 있습니다.
금 = apara[apara['loc'].str.contains('altin')]
gold.filter(['loc','url_sub_cat']).tail(85)
gold.filter(['loc','url_sub_cat']).head(85)
이 시점에서 Sabah Newspaper는 각 통화를 달러, 유로, 금 및 TL(터키 리라)로 변환하기 위해 5000개의 다른 페이지를 열었습니다. 1~5000 사이의 각 화폐 단위에 대한 별도의 계산 페이지가 있습니다. 아래에서 골드 그룹의 처음 85개 행과 마지막 85개 행의 예를 볼 수 있습니다. 금 가격 1g당 별도의 페이지가 열렸습니다.


우리는 이러한 페이지가 불필요하고 중복된 콘텐츠가 많고 지나치게 크다는 점에 의심의 여지가 없지만 Sabah Newspaper는 Google이 거의 모든 검색어, 최상위 순위에 계속 표시할 정도로 브랜드가 강력한 웹사이트입니다.
이 시점에서 우리는 또한 권위가 높은 오래된 뉴스 사이트에 대해 크롤링 비용 허용 범위가 높다는 것을 알 수 있습니다.
그러나 이것이 골드 카테고리에 다른 카테고리보다 더 많은 URL이 있는 이유는 설명하지 않습니다.
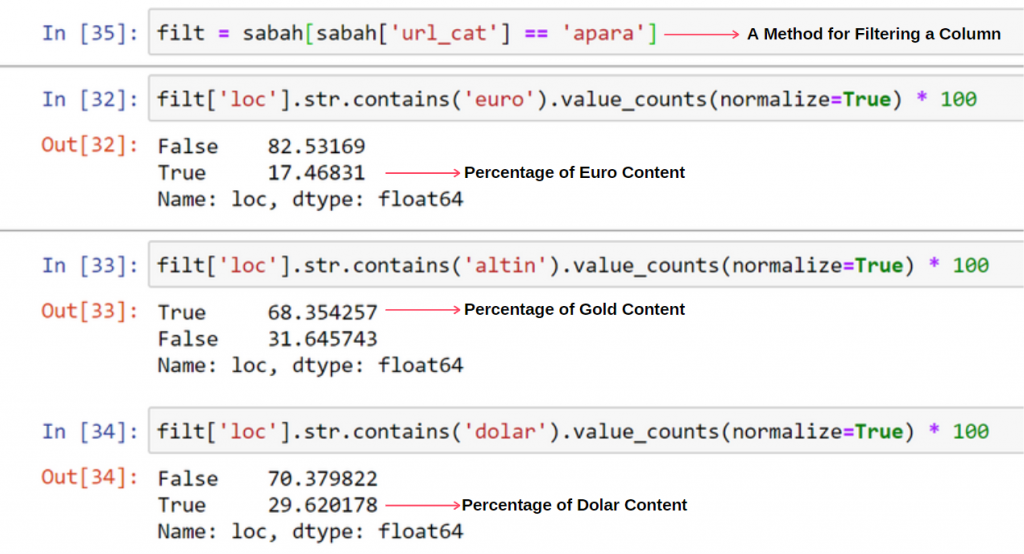
겹치는 값이 100% 이상 추가되는 것에 대해 이상한 점은 없습니다.
내가 뭔가를 놓치고 있지 않는 한?
보시다시피 모든 True Values를 더하면 115.16%의 결과가 나옵니다. 그 이유는 아래에 있습니다.
메인 그룹도 이렇게 서로 교차점이 있습니다. 이러한 교차점을 분석할 수도 있지만 다른 기사의 주제가 될 수 있습니다.
Apara URL 그룹의 콘텐츠 중 68%가 GOLD와 관련되어 있음을 알 수 있습니다.
이 상황을 더 잘 이해하기 위해 우리가 가장 먼저 해야 할 일은 골드 굴절의 URL을 스캔하는 것입니다.
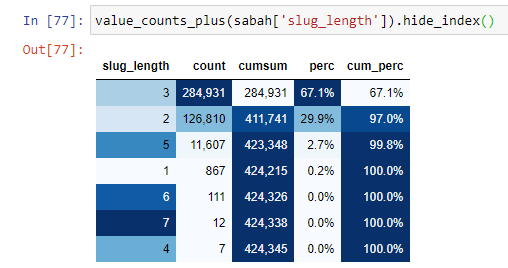
루트 섹션부터 '/'의 양에 따라 URL을 분류하면 최대 3개의 break가 있는 URL의 수가 많다는 것을 알 수 있습니다. 이러한 URL을 분석할 때 3개의 slug_length URL 중 270.000개가 Gold 카테고리에 있음을 알 수 있습니다.
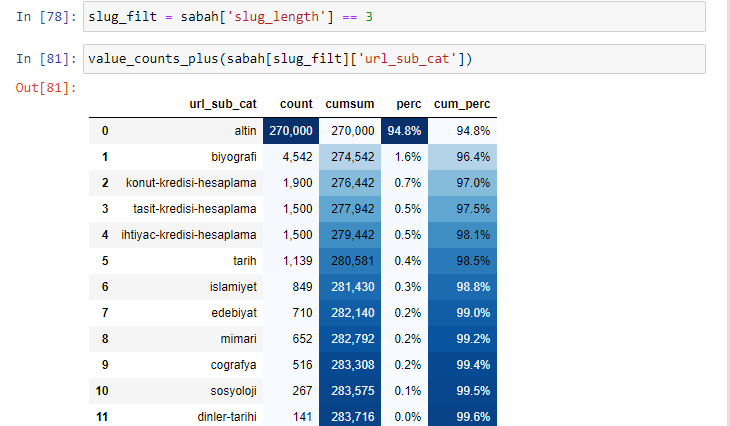
morning_filt = morning ['slug_length'] == 3 특정 데이터 프레임의 특정 열에 있는 int 데이터 유형의 데이터 그룹에서 3과 같은 것만 가져옴을 의미합니다. 그런 다음 이 정보를 기반으로 조건에 편리한 URL을 개수, 합계 및 집계 비율을 누적 합계로 프레이밍합니다.
골드 URL에서 가장 일반적으로 사용되는 단어를 추출할 때 "full", "republic", "quarter", "gram", "half", "ancestor"를 나타내는 단어를 접하게 됩니다. Ata 및 Republic 금 유형은 터키 고유의 유형입니다. 그들 중 한 명은 터키 주권을 대표하고 다른 한 명은 공화국의 설립자인 케말 아타투르크입니다. 그렇기 때문에 검색어 검색량이 많습니다.
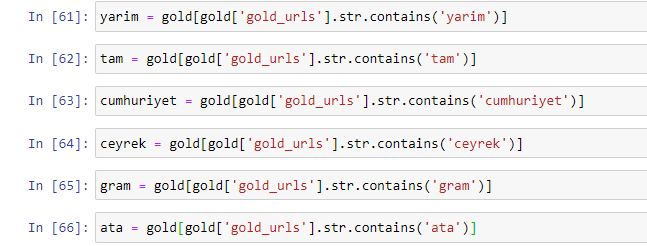
먼저 URL에서 흔히 볼 수 있는 단어를 제거하고 별도의 변수에 할당했습니다. 다음으로 Gold DataFrame에서 이러한 변수를 사용하여 해당 유형에 특정한 열을 생성합니다.
변수를 통해 새 열을 만든 후에는 부울 값으로 함께 필터링해야 합니다.
보시다시피 270,000행과 6열로 모든 골드 URL을 분류할 수 있었습니다. 금 관련 페이지 수가 많은 주된 이유는 달러나 유로에는 별도의 유형이 없는 반면 금에는 별도의 유형이 있기 때문입니다. 동시에 금과 다른 통화 사이의 교차 페이지의 다양성은 터키 사람들에 대한 전통적인 신뢰로 인해 다른 통화보다 높습니다.
제 생각에는 모든 종류의 골드 페이지가 균등하게 분배되어야 하지 않습니까?
Seaborn의 Heatmap 기능으로 이것을 쉽게 테스트할 수 있습니다.
씨본을 sns로 가져오기
matplotlib.pyplot을 plt로 가져오기
plt.Figure(figsize=(10,8))
sns.heatmap(a,yticklabels=False,cbar=False,cmap=”viridis”)
plt.show()
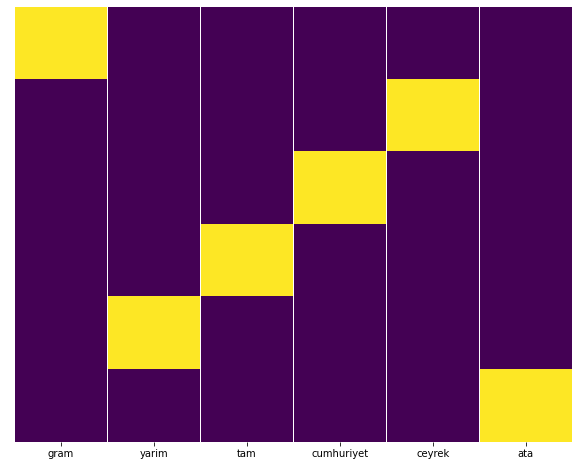
여기 히트 맵에서 각 열의 True가 간단히 표시됩니다. 보시다시피 각각의 크기는 서로 대칭을 이루며 지도에 깔끔하게 정리되어 있습니다.
따라서 우리는 통화 및 통화 계산에 관한 Sabah.com.tr 신문의 콘텐츠 정책에 대해 폭넓은 관점을 취했습니다.
앞으로 저는 Elias Dabbas가 시작한 Sitemaps Kaggle을 기반으로 터키 뉴스 웹사이트와 콘텐츠 전략을 작성할 예정이지만 이 기사에서는 사이트맵이 있는 크고 작은 웹사이트 모두에서 발견할 수 있는 것에 대해 충분히 이야기했습니다. .
결론 및 시사점
매끄럽고 의미 있는 URL 구조 덕분에 웹 사이트를 이해하는 것이 얼마나 쉬운지 본 것 같습니다. 또한 적절한 URL 구조가 Google에 얼마나 중요한지 기억해야 합니다.
앞으로 우리는 데이터 과학, 데이터 시각화, 프론트 엔드 프로그래밍 등에 점점 더 익숙해지는 많은 SEO를 보게 될 것입니다. 저는 이 프로세스를 피할 수 없는 변화의 시작으로 봅니다. SEO와 개발자 간의 격차가 완전히 좁혀질 것입니다. 수년 이내로.
Python을 사용하면 이러한 종류의 분석을 더욱 발전시킬 수 있습니다. 뉴스 사이트의 정치적 견해를 이해하는 것부터 누가 무엇을, 얼마나 자주, 어떤 감정으로 쓰는지에 대한 데이터를 얻을 수 있습니다. 이러한 프로세스는 SEO보다 순수한 데이터 과학에 더 가깝기 때문에 여기에서 다루지 않는 것을 선호합니다(이 기사는 이미 꽤 깁니다).
그러나 관심이 있는 경우 사이트맵에서 URL의 상태 코드를 확인하는 것과 같이 Sitemap 및 Python을 통해 수행할 수 있는 다른 많은 유형의 감사가 있습니다.
Python 및 Advertools로 수행할 수 있는 다른 SEO 작업을 실험하고 공유하기를 기대합니다.