
제1종 오류와 제2종 오류: 최적화의 불가피한 오류
게시 됨: 2020-05-29
유형 I 및 유형 II 오류는 실험에서 승자를 잘못 발견하거나 발견하지 못할 때 발생합니다. 두 오류 모두 작동하거나 작동하지 않는 것처럼 보이는 결과를 초래합니다. 그리고 실제 결과가 아닙니다.
테스트 결과를 잘못 해석하면 최적화 노력이 잘못될 뿐만 아니라 장기적으로 최적화 프로그램이 탈선할 수도 있습니다.
이러한 오류를 포착할 수 있는 가장 좋은 시간은 오류를 범하기도 전입니다! 따라서 최적화 실험에서 유형 I 및 유형 II 오류가 발생하지 않도록 하는 방법을 살펴보겠습니다.
그러나 그 전에 귀무가설을 살펴보겠습니다. 귀무가설 의 잘못된 기각 또는 비기각이 제1종 오류와 제2종 오류를 유발 하기 때문입니다.
귀무 가설: H0
실험에 대한 가설을 세울 때 제안된 변경 사항이 특정 측정항목을 이동할 것이라고 직접 제안하지 않습니다.
제안된 변경 사항이 관련 측정항목에 전혀 영향을 미치지 않을 것이라고 말하면서 시작합니다. 즉, 관련이 없습니다.
이것이 귀무가설(H0)입니다. H0는 항상 변화가 없다는 것입니다. 이것은 기본적으로 ... 귀하의 실험이 그것을 반증할 때까지(그리고 만약에) 당신이 믿는 것입니다.
그리고 대안 가설(Ha 또는 H1)은 긍정적인 변화가 있다는 것입니다. H0와 Ha는 항상 수학적으로 반대입니다. Ha는 제안된 변경 사항이 차이를 만들 것으로 예상하는 부분이며, 대안 가설입니다. 이것이 바로 여러분이 실험으로 테스트하는 것입니다.
따라서 예를 들어 가격 페이지에서 실험을 실행하고 여기에 다른 지불 방법을 추가하려면 먼저 다음과 같은 귀무 가설을 세워야 합니다. 추가 지불 방법은 판매에 영향을 주지 않습니다. 대체 가설은 다음과 같습니다 . 추가 지불 방법은 매출을 증가시킵니다.
실제로 실험을 실행하는 것은 귀무 가설이나 현상 유지에 도전하는 것입니다.

유형 I 및 유형 II 오류는 귀무 가설을 잘못 기각하거나 기각하지 못할 때 발생합니다.
제1종 오류 이해하기
유형 I 오류는 거짓 긍정 또는 알파 오류로 알려져 있습니다.
가설 테스트의 제1종 오류 인스턴스에서 최적화 테스트 또는 실험 * APPEARS TO BE SUCCESSFUL* 이고 테스트 중인 대안이 원본과 다르게(더 좋거나 나쁘게) 수행되고 있다고 (잘못) 결론을 내립니다.
제1종 오류에서는 일시적일 뿐이고 장기적으로 유지될 가능성이 없는 상승 또는 하락을 보고 결국 귀무 가설을 기각하고 대립 가설을 수락하게 됩니다.
귀무 가설을 잘못 기각하는 것은 여러 가지 이유로 발생할 수 있지만 주요 원인은 엿보기 (즉, 중간에 결과를 보거나 실험이 아직 실행 중일 때 확인)하는 것입니다. 그리고 설정된 중지 기준에 도달하기 전에 테스트를 호출합니다.
많은 테스트 방법론은 중간 결과를 보는 것이 유형 I 오류를 초래하는 잘못된 결론으로 이어질 수 있으므로 엿보기 연습을 권장하지 않습니다.
유형 I 오류를 만드는 방법은 다음과 같습니다.
B2B 웹사이트의 방문 페이지를 최적화하고 여기에 배지 또는 상을 추가하면 잠재 고객의 불안이 줄어들고 따라서 양식 작성 비율이 증가한다고 가정하고 결과적으로 더 많은 리드를 얻게 됩니다.
따라서 이 실험에 대한 귀무 가설은 다음과 같습니다. 배지를 추가해도 양식 채우기에는 영향이 없습니다.
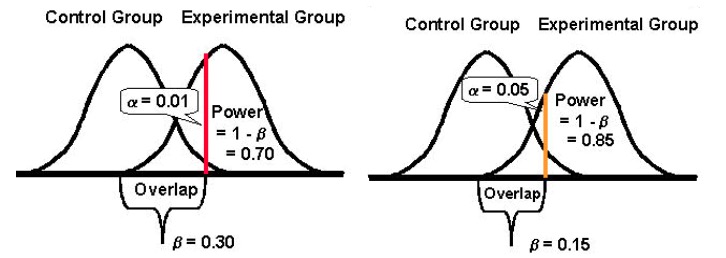
이러한 실험의 중지 기준은 일반적으로 특정 기간 및/또는 설정된 통계적 유의 수준에서 X개의 전환이 발생한 후입니다. 일반적으로 최적화 프로그램은 대부분의 최적화 실험에서 충분히 낮은 것으로 간주되는 제1종 오류를 만들 확률이 5%이기 때문에 95%의 통계적 신뢰 수준에 도달하려고 합니다. 일반적으로 이 지표가 높을수록 제1종 오류를 범할 가능성이 낮아집니다.
목표로 하는 신뢰 수준에 따라 제1종 오류(α)가 발생할 확률이 결정됩니다.
따라서 95% 신뢰 수준을 목표로 한다면 α 값은 5%가 됩니다. 여기서 당신은 당신의 결론이 틀릴 가능성이 5%라는 것을 인정합니다.
대조적으로, 99% 신뢰 수준으로 실험을 진행하면 제1종 오류가 발생할 확률이 1%로 떨어집니다.
이 실험의 경우 너무 조급해 실험이 끝날 때까지 기다리는 대신 테스트 도구의 대시보드(피크!)를 하루 만에 살펴봅니다. 그리고 양식 작성 비율이 95%의 신뢰 수준과 함께 무려 29.2%나 증가한 "명백한" 상승도를 확인했습니다.
그리고 BAM…
... 실험을 중지합니다.
... 귀무 가설(배지가 판매에 영향을 미치지 않는다는)을 기각합니다.
... 대립 가설(배지가 판매를 촉진한다는)을 받아들입니다.
... 그리고 수상 배지가 있는 버전으로 실행하십시오.
그러나 한 달 동안 리드를 측정하면 원래 버전에서 보고한 것과 거의 비슷한 수치를 알 수 있습니다. 배지는 결국 그렇게 중요하지 않았습니다. 그리고 귀무가설은 아마도 헛되이 기각되었을 것입니다.
여기서 일어난 일은 실험을 너무 빨리 끝내고 귀무 가설을 기각하고 결국 거짓 승자가 되어 제1종 오류를 범했다는 것입니다.
실험에서 제1종 오류 피하기
제1종 오류가 발생할 확률을 낮추는 확실한 방법 중 하나는 더 높은 신뢰 수준을 사용하는 것입니다. 5% 통계적 유의 수준(95% 통계적 신뢰 수준으로 변환)이 허용됩니다. 대부분의 옵티마이저가 안전하게 할 수 있는 내기입니다. 여기에서는 예상 밖의 5% 범위에서 실패할 것이기 때문입니다.
높은 신뢰 수준을 설정하는 것 외에도 테스트를 충분히 오래 실행하는 것이 중요합니다. 테스트 기간 계산기는 테스트를 실행해야 하는 기간을 알려줄 수 있습니다(특히 지정된 효과 크기 등을 고려한 후). 실험이 의도한 대로 실행되도록 하면 1종 오류가 발생할 가능성이 크게 줄어듭니다(높은 신뢰 수준을 사용하는 경우). 통계적으로 유의미한 결과에 도달할 때까지 기다리면 귀무 가설을 잘못 기각하고 제1종 오류를 범할 가능성이 매우 낮습니다(보통 5%). 즉, 통계적으로 유의미한 결과를 얻는 데 중요하기 때문에 좋은 표본 크기를 사용합니다.
이제 실험의 신뢰도(또는 유의성) 수준과 관련된 제1종 오류에 관한 것이었습니다. 그러나 테스트에 침투할 수 있는 또 다른 유형의 오류가 있습니다. 바로 유형 II 오류입니다.
제2종 오류 이해하기
유형 II 오류는 거짓 부정 또는 베타 오류로 알려져 있습니다.
제1종 오류와 대조적으로 제2종 오류의 경우 실험 *APPEARS TO BE UNSUCCESSFUL(OR INCONCLUSIVE)* 및 귀하는 (잘못) 테스트 중인 대안이 다른 결과를 낳지 않는다는 결론을 내립니다. 원래의.

유형 II 오류에서는 실제 상승 또는 하락을 보지 못하고 결국 귀무 가설을 기각하지 못하고 대립 가설을 기각합니다.
유형 II 오류를 만드는 방법은 다음과 같습니다.
위에서 동일한 B2B 웹 사이트로 돌아가기…
따라서 이번에는 양식 상단에 GDPR 준수 면책조항을 눈에 띄게 추가하면 더 많은 잠재 고객이 양식을 작성하도록 장려할 것이라고 가정합니다(결과적으로 더 많은 리드가 발생함).
따라서 이 실험에 대한 귀무 가설은 다음과 같습니다 . GDPR 준수 면책 조항은 양식 작성에 영향을 미치지 않습니다.
동일한 내용에 대한 대체 가설은 다음과 같습니다 . GDPR 준수 면책 조항으로 인해 더 많은 양식이 채워집니다.
테스트의 통계적 검정력은 편차가 있는 경우 원래 버전과 도전자 버전의 성능 차이를 얼마나 잘 감지할 수 있는지를 결정합니다. 전통적으로 옵티마이저는 80% 통계적 검정력을 달성하려고 시도합니다. 이 지표가 높을수록 제2종 오류를 범할 가능성이 더 낮기 때문입니다.
통계적 검정력은 0과 1 사이의 값(종종 %로 표시됨)을 취하고 제2종 오류(β)의 확률을 제어합니다. 다음과 같이 계산됩니다. 1 – β
검정의 통계적 검정력이 높을수록 제2종 오류가 발생할 확률은 낮아집니다.
따라서 실험의 통계적 검정력이 10%이면 제2종 오류에 매우 취약할 수 있습니다. 반면, 실험의 통계적 검정력이 80%이면 제2종 오류를 범할 가능성이 훨씬 낮아집니다.
다시 테스트를 실행했지만 이번에는 양식 채우기가 크게 향상되지 않았습니다. 두 버전 모두 거의 유사한 전환을 보고합니다. 따라서 실험을 중지하고 GDPR 준수 면책 조항 없이 원래 버전을 계속 사용합니다.
그러나 실험 기간의 리드 데이터를 더 깊이 파고들면 두 버전(원본 및 도전자)의 리드 수가 동일해 보였지만 GDPR 버전은 숫자가 상당히 증가했음을 알 수 있습니다. 유럽에서 리드의. (물론 잠재고객 타겟팅을 사용하여 유럽의 리드에게만 실험을 보여줄 수도 있었지만 그건 다른 이야기입니다.)
여기서 일어난 일은 충분한 검정력을 얻었는지 확인하지 않고 테스트를 너무 일찍 종료했다는 것입니다. 제2종 오류입니다.
실험에서 제2종 오류 피하기
제2종 오류를 방지하려면 통계적 검정력이 높은 검정을 실행하십시오. 최소한 80%의 통계적 파워 마크에 도달할 수 있도록 실험을 구성하십시오. 이것은 대부분의 최적화 실험에서 허용되는 통계적 검정력 수준입니다. 이를 통해 최소한 80%의 경우에서 거짓 귀무 가설을 올바르게 기각할 수 있습니다.
이렇게 하려면 여기에 추가되는 요소를 살펴봐야 합니다.
이들 중 가장 큰 것은 표본 크기입니다(관찰된 효과 크기가 주어졌을 때). 표본 크기는 검정력과 직접적인 관련이 있습니다. 거대한 표본 크기는 높은 검정력 테스트를 의미합니다. 저전력 테스트는 특히 낮은 MEI의 경우 도전자와 원본 버전의 결과 차이를 감지할 가능성이 크게 줄어들기 때문에 유형 II 오류에 매우 취약합니다(자세한 내용은 아래 참조). 따라서 제2종 오류를 방지하려면 제2종 오류를 최소화하기 위해 검정이 충분한 검정력을 축적할 때까지 기다리십시오. 이상적으로는 대부분의 경우 최소 80%의 거듭제곱에 도달하는 것이 좋습니다.
또 다른 요인은 실험에서 목표로 삼는 최소 관심 효과(MEI) 입니다. MEI(MDE라고도 함)는 해당 KPI에서 감지하려는 차이의 최소 크기입니다. 낮은 MEI를 설정하는 경우(예: 1.5% 증가를 목표로) 작은 차이를 감지하려면 (충분한 검정력을 얻기 위해) 훨씬 더 큰 표본 크기가 필요하기 때문에 제2종 오류가 발생할 가능성이 높아집니다.
그리고 마지막으로, 제1종 오류를 범할 확률(α)과 제2종 오류를 범할 확률(β) 사이에는 역의 관계가 있는 경향이 있다는 점에 주목하는 것이 중요합니다. 예를 들어, 제1종 오류를 범할 확률을 낮추기 위해 α 값을 줄이면(α를 1%로 설정하여 99%의 신뢰 수준을 의미함) 실험의 통계적 검정력(또는 실험 능력, β , 차이가 존재할 때 감지하는 것)도 감소하여 제2종 오류가 발생할 확률이 높아집니다.
오류 중 하나를 더 많이 수용하기: 유형 I 및 II(및 균형 맞추기)
한 유형의 오류 확률을 낮추면 다른 유형의 오류 확률이 높아집니다(다른 모든 오류는 동일하게 유지됨).
따라서 더 관대할 수 있는 오류 유형에 대해 문의해야 합니다.
한편으로는 제1종 오류를 범하고 모든 사용자를 대상으로 변경 사항을 적용하면 전환수와 수익이 손실될 수 있으며, 더 나아가 전환율이 저하될 수도 있습니다.
반면에 유형 II 오류를 범하고 모든 사용자를 위해 성공적인 버전을 출시하지 못하면 다시 얻을 수 있었던 전환 비용이 발생할 수 있습니다.
항상 두 가지 오류 모두 비용이 듭니다.
그러나 실험에 따라 하나가 다른 것보다 더 적합할 수 있습니다. 일반적으로 테스터는 제1종 오류가 제2종 오류보다 약 4배 더 심각하다고 생각합니다 .
보다 균형 잡힌 접근 방식을 취하고 싶다면 통계학자 Jacob Cohen은 " 알파와 베타 위험 사이의 합리적인 균형"과 함께 제공되는 80%의 통계적 검정력을 선택해야 한다고 제안합니다. ” (80% 전력은 대부분의 테스트 도구의 표준이기도 합니다.)
그리고 통계적 유의성에 관한 한 기준은 95%로 설정되어 있습니다.
기본적으로, 그것은 모두 타협과 당신이 기꺼이 감수할 수 있는 위험 수준에 관한 것입니다. 두 오류의 가능성을 진정으로 최소화하려면 99%의 신뢰 수준과 99%의 검정력을 사용할 수 있습니다. 그러나 그것은 당신이 영원히 긴 것처럼 보이는 기간 동안 불가능할 정도로 거대한 표본 크기로 작업한다는 것을 의미합니다. 게다가, 그때에도 오류의 여지를 남겨둘 것입니다.
때때로, 당신은 실험을 잘못 결론짓게 될 것입니다. 그러나 그것은 테스트 프로세스의 일부입니다. A/B 테스트 통계를 마스터하는 데 시간이 걸립니다. 성공하거나 실패한 실험을 조사하고 다시 테스트하거나 후속 조치를 취하는 것은 발견을 재확인하거나 실수를 했음을 발견하는 한 가지 방법입니다.
