
Wikipedia 및 Google Language API로 주제 그래프 해킹
게시 됨: 2019-08-27지난 10년 동안 내가 가장 좋아하는 슬라이드 데크 중 하나는 Mark Johnstone이 여전히 Distilled에 있는 동안 2014년에 만든 것입니다. 이 데크는 어떻게 더 나은 콘텐츠 아이디어를 생산하는가라는 제목이었고 콘텐츠 홍보의 힘든 작업을 수행하기 위해 팀을 구성하는 동안 몇 년 동안 내 성경으로 사용했습니다.
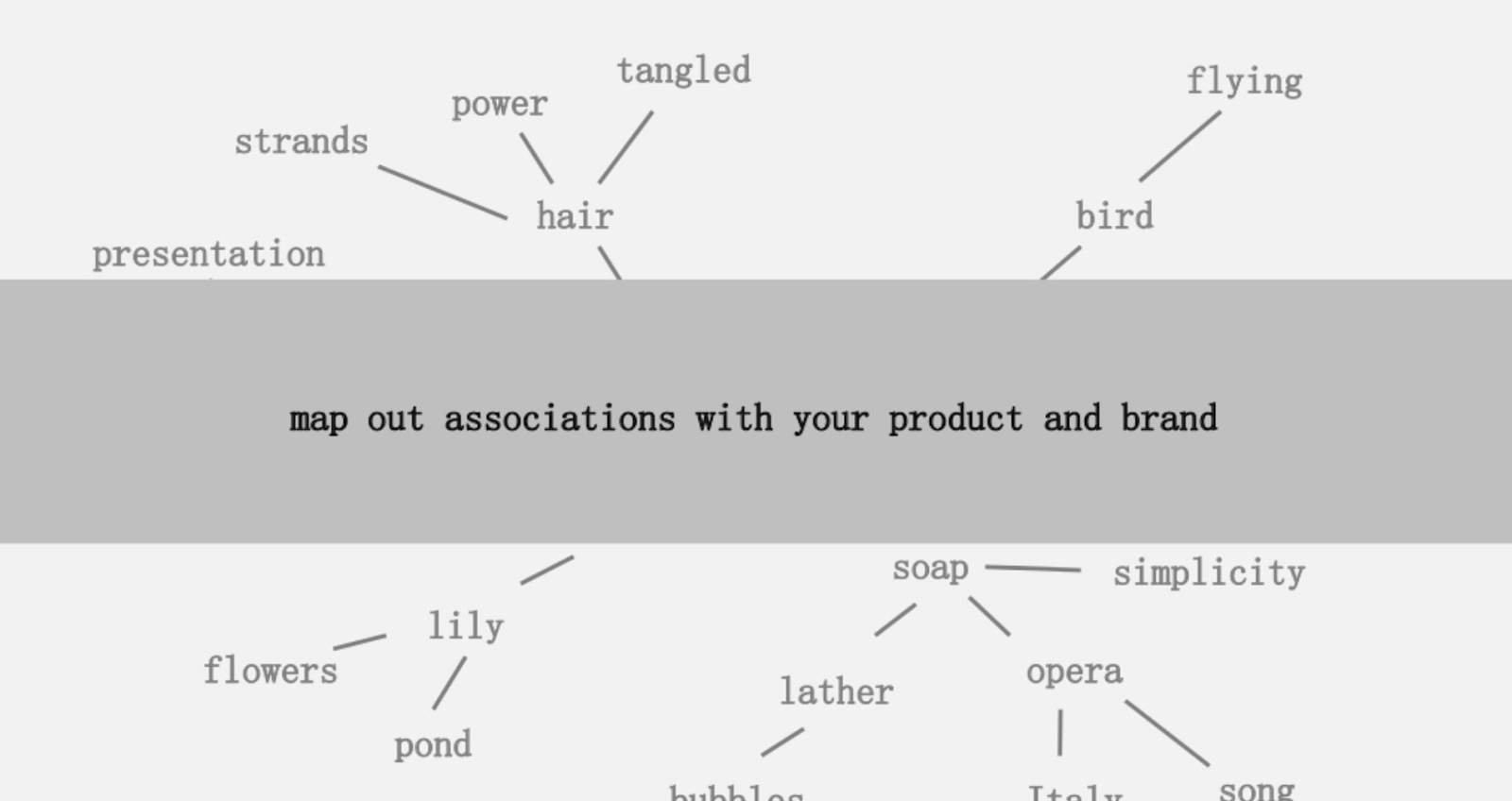
제안된 아이디어 중 하나는 제품 또는 브랜드와 관련된 단어의 연결성을 시각적으로 매핑하여 뒤로 물러나 흥미로운 무언가로 연관성을 결합하는 방법을 찾는 것이었습니다. 목표는 아이디어의 생산이며, 그는 이를 " 가치를 추가하는 방식으로 이전에 연결되지 않은 요소의 새로운 조합"으로 정의합니다.
이 기사에서는 Google의 언어 API인 Python과 Wikipedia를 사용하여 시드 주제에서 존재하는 엔티티 연관을 탐색하는 훨씬 더 좌뇌 접근 방식을 취합니다. 목표는 주제 그래프를 따라 엔터티 관계의 상위 수준 보기입니다. 이 기사는 일반 독자를 위한 것이 아닙니다. Python에 익숙하고 최소한 기본 수준의 코딩 능력이 있는 독자는 Python이 훨씬 더 유익하다는 것을 알게 될 것입니다.
아이디어
Mark Johnstone의 매핑 아이디어를 따라 Google과 Wikipedia가 시드 주제 또는 웹페이지에서 시작하는 주제 구조를 정의하도록 하면 재미있을 것이라고 생각했습니다. 목표는 연결을 찾고 콘텐츠 아이디어를 생성하기 위해 검토할 수 있는 나무와 같은 그래프에서 시각적으로 주요 주제에 대한 관계 매핑을 구축하는 것입니다. 다음 이미지는 초기 디자인 아이디어를 나타냅니다.
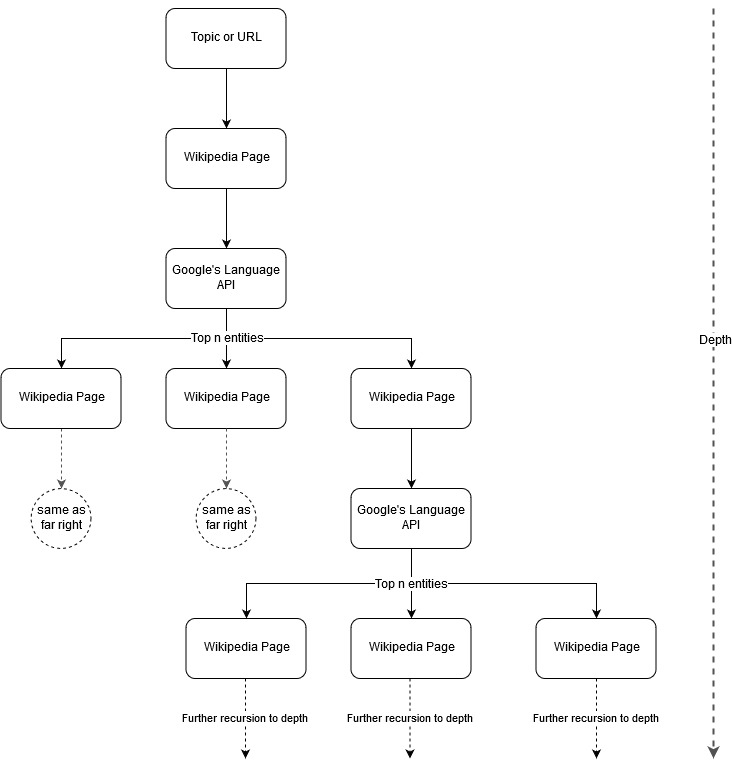
기본적으로 우리는 도구에 주제 또는 URL을 제공하고 Google의 Language API가 각 항목 페이지에 대해 상위 n개(이 예에서는 3개) 항목(Wikipedia URL 포함)을 선택하도록 하고 발견된 각 항목에 대해 네트워크 그래프를 계속해서 재귀적으로 작성합니다. 최대 깊이까지.
사용 도구의 배경
구글 언어 API
Google의 언어 API를 사용하면 일반 텍스트나 HTML을 전달할 수 있으며 콘텐츠와 관련된 모든 다양한 엔터티를 마술처럼 반환합니다. API는 이 이상을 수행하지만 이 분석에서는 이 부분에만 초점을 맞춥니다. 다음은 반환하는 엔터티 유형의 목록입니다.
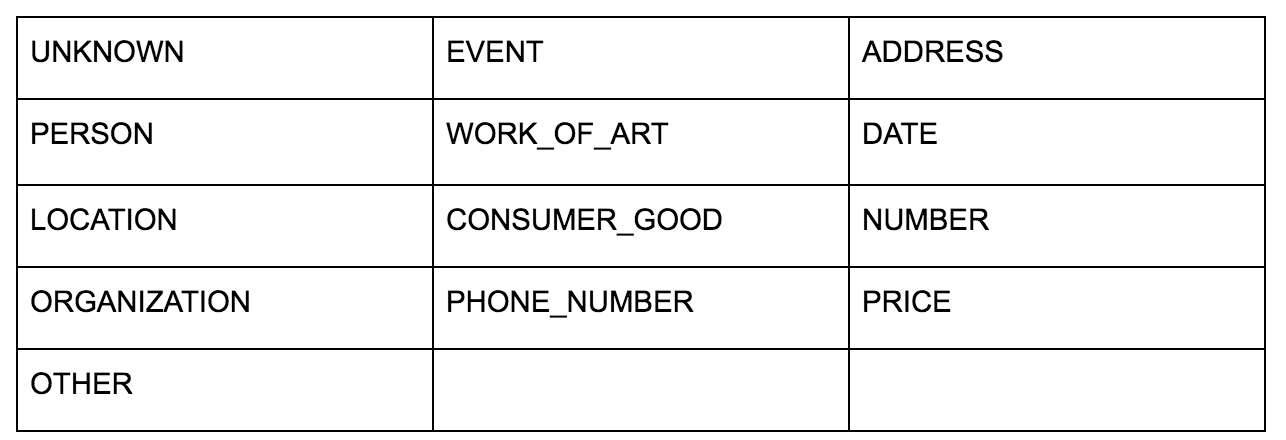
개체 식별은 오랫동안 자연어 처리(NLP)의 기본 부분이었고 작업에 대한 올바른 용어는 명명된 개체 인식(NER)입니다. 많은 단어가 사용되는 컨텍스트에 따라 다른 의미를 갖기 때문에 NER은 어려운 작업이므로 NLP 도구 또는 API는 특정 엔터티로 적절하게 식별할 수 있도록 용어를 둘러싼 전체 컨텍스트를 이해해야 합니다.
이 기사를 끝내기 전에 일부 컨텍스트를 따라잡고 싶다면 opensource.com의 기사에서 이 API, 특히 엔티티에 대한 매우 자세한 개요를 제공했습니다.
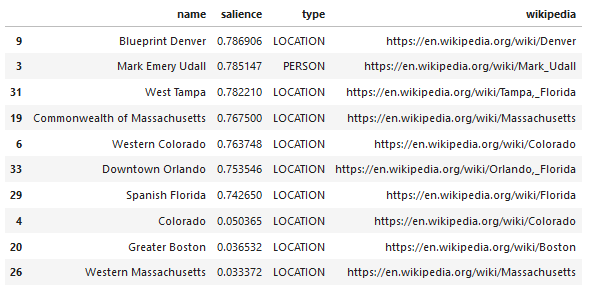
Google Language API의 흥미로운 기능 중 하나는 관련 엔터티를 찾는 것 외에도 전체 문서(중요도)와 얼마나 관련되어 있는지 표시하고 일부의 경우 엔터티를 나타내는 관련 Wikipedia(지식 그래프) 문서를 제공한다는 것입니다.
다음은 API가 반환하는 내용의 샘플 출력입니다(중요성 기준으로 정렬).
온크롤 개발자
 더 알아보기
더 알아보기파이썬
Python은 대규모 데이터 세트를 쉽게 수집, 정리, 조작 및 분석할 수 있는 대규모 라이브러리 세트로 인해 데이터 과학 분야에서 널리 보급된 소프트웨어 언어입니다. 또한 사용자가 손쉽게 코드를 테스트하고 주석을 추가할 수 있는 Jupyter 노트북이라는 협업 환경의 이점도 있습니다.
이 검토를 위해 Google의 NLP 데이터로 몇 가지 흥미로운 작업을 수행할 수 있는 몇 가지 주요 라이브러리를 사용할 것입니다.
- Pandas: 스프레드시트를 읽고, 저장하고, 구문 분석하거나 재정렬하기 위해 Microsoft Excel을 스크립팅할 수 있다고 생각하면 Pandas가 하는 일에 대한 아이디어를 얻을 수 있습니다. 팬더는 놀랍습니다. (링크)
- Networkx: Networkx는 노드 간의 관계를 정의하는 노드 및 에지의 그래프를 구성하기 위한 도구입니다. 또한 그래프를 그리는 기능이 내장되어 있어 쉽게 시각화할 수 있습니다. (링크)
- Pywikibot: Pywikibot은 Wikipedia와 상호 작용하여 각 Wikipedia 사이트의 모든 콘텐츠를 검색, 편집, 관계 찾기 등을 수행할 수 있는 라이브러리입니다. (링크)
과정
따라 하는 데 사용할 수 있는 Google Colab 노트북을 공유합니다. (기사와 이 노트북에 대한 온전한 확인을 해준 Tyler Reardon에게 특별한 감사를 전합니다.)
설정
노트북의 처음 몇 개의 셀은 일부 라이브러리를 설치하고, 해당 라이브러리를 Python에서 사용할 수 있도록 하며, 각각 Google의 언어 API 및 Pywikibot에 대한 자격 증명 및 구성 파일을 제공하는 작업을 처리합니다. 다음은 도구가 실행될 수 있도록 설치해야 하는 모든 라이브러리입니다.
- 팬더
- 요청
- httplib2
- 구글 클라우드 언어
- 파이위키봇
- 네트워크
- 검증인
- Bs4
참고: 이 노트북을 실행하는 데 있어 가장 어려운 부분은 API에 액세스하기 위해 Google에서 자격 증명을 얻는 것입니다. 경험이없는 사람들은 이것을 알아내는 데 1 시간 정도 걸릴 것입니다. 귀하를 돕기 위해 노트북 상단에 서비스 계정 자격 증명을 얻기 위한 지침을 연결했습니다. 아래는 우리가 어떻게 포함했는지에 대한 예입니다.
승리를 위한 기능
"Google NLP에 대한 일부 기능 정의"로 표시된 셀에서 Language API 쿼리, Wikipedia와의 상호 작용, 웹 페이지 텍스트 추출, 그래프 작성 및 플로팅과 같은 작업을 처리하는 8가지 기능을 개발합니다. 함수는 기본적으로 일부 설정 데이터를 받아 일부 작업을 수행하고 무언가를 생성하는 작은 코드 단위입니다. 모든 함수는 그들이 받아들이는 변수와 생성하는 변수를 알려주기 위해 주석을 달았습니다.

API 테스트
다음 두 셀은 URL을 가져와 URL에서 텍스트를 추출하고 Google의 Language API에서 항목을 가져옵니다. 하나는 Wikipedia URL이 있는 엔터티만 가져오고 다른 하나는 해당 페이지에서 모든 엔터티를 가져옵니다.
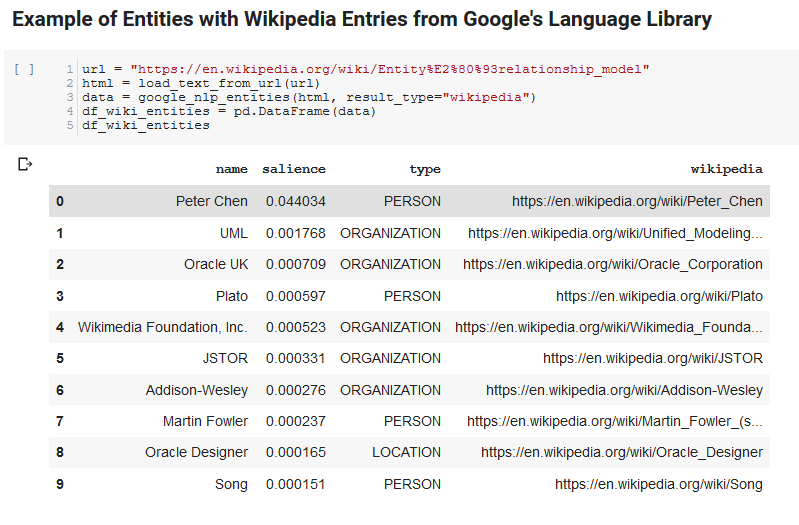
이것은 콘텐츠 추출 부분을 정확하고 Language API가 어떻게 작동하고 데이터를 반환하는지 이해하기 위한 중요한 첫 번째 단계였습니다.
네트웍스
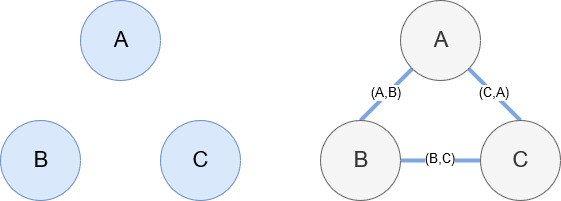
앞에서 언급했듯이 Networkx는 사용하기에 상당히 직관적인 훌륭한 라이브러리입니다. 기본적으로 노드가 무엇인지, 노드가 어떻게 연결되어 있는지 알려야 합니다. 예를 들어 아래 이미지에서 우리는 Networkx에 3개의 노드(A,B,C)를 제공합니다. 그런 다음 Networkx에 노드 간의 관계를 정의하는 가장자리 (A,B), (B,C), (C,A)로 연결되어 있음을 알립니다. 우리의 사용을 위해 Wikipedia URL이 있는 엔터티는 노드가 되고 가장자리는 현재 엔터티 페이지에서 발견되는 새 엔터티로 정의됩니다. 따라서 엔티티 A에 대한 Wikipedia 페이지를 검토하고 해당 페이지에서 엔티티 B가 발견되면 엔티티 A와 엔티티 B 사이의 가장자리입니다.
함께 모아서
노트북의 다음 섹션은 Wikipedia Topic Branching by URL이라고 합니다. 마법이 일어나는 곳입니다. 우리는 이전에 Google 언어 API에 의해 정의된 새로운 엔티티를 따라 Wikipedia의 페이지를 통해 재귀하는 특수 함수(recurse_entities)를 정의했습니다. 또한 많은 노드가 있는 나무 모양의 그래프를 잘 표시하는 스택 오버플로에서 제거한 정말 이해하기 어려운 함수(hierarchy_pos)를 추가했습니다. 아래 셀에서 입력 을 "검색 엔진 최적화"로 정의하고 깊이 3(재귀적으로 따라오는 페이지 수)과 제한 3(페이지당 가져오는 엔터티 수)을 지정합니다.
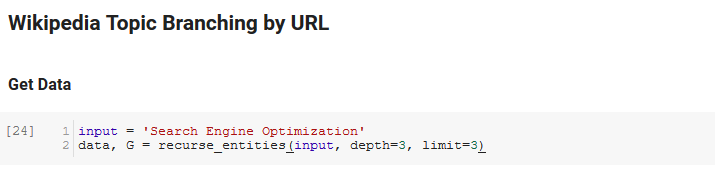
"검색 엔진 최적화"라는 용어에 대해 실행하면 Wikipedia의 검색 엔진 최적화 페이지(레벨 0)에서 시작하여 지정된 최대 깊이(3)까지 페이지를 재귀적으로 따라가며 도구가 취한 다음 경로를 볼 수 있습니다.

그런 다음 발견된 모든 엔터티를 Pandas DataFrame에 추가하여 CSV로 저장하기가 정말 쉽습니다. 우리는 이 데이터를 중요도(해당 항목이 발견된 페이지에서 항목이 얼마나 중요한지)별로 정렬하지만 항목이 원래 용어(" 검색 엔진 최적화"). 그 추가 작업은 독자에게 맡기겠습니다.

마지막으로 모든 엔티티의 연결성을 표시하기 위해 도구로 작성된 그래프를 플로팅합니다. 아래 셀에서 함수에 전달할 수 있는 매개변수는 다음과 같습니다. ( G : recurse_entities 함수에 의해 이전에 작성된 그래프, w: 플롯의 너비, h: 플롯의 높이, c: 퍼센트 원형 플롯 및 파일 이름: 이미지 폴더에 저장되는 PNG 파일입니다.)

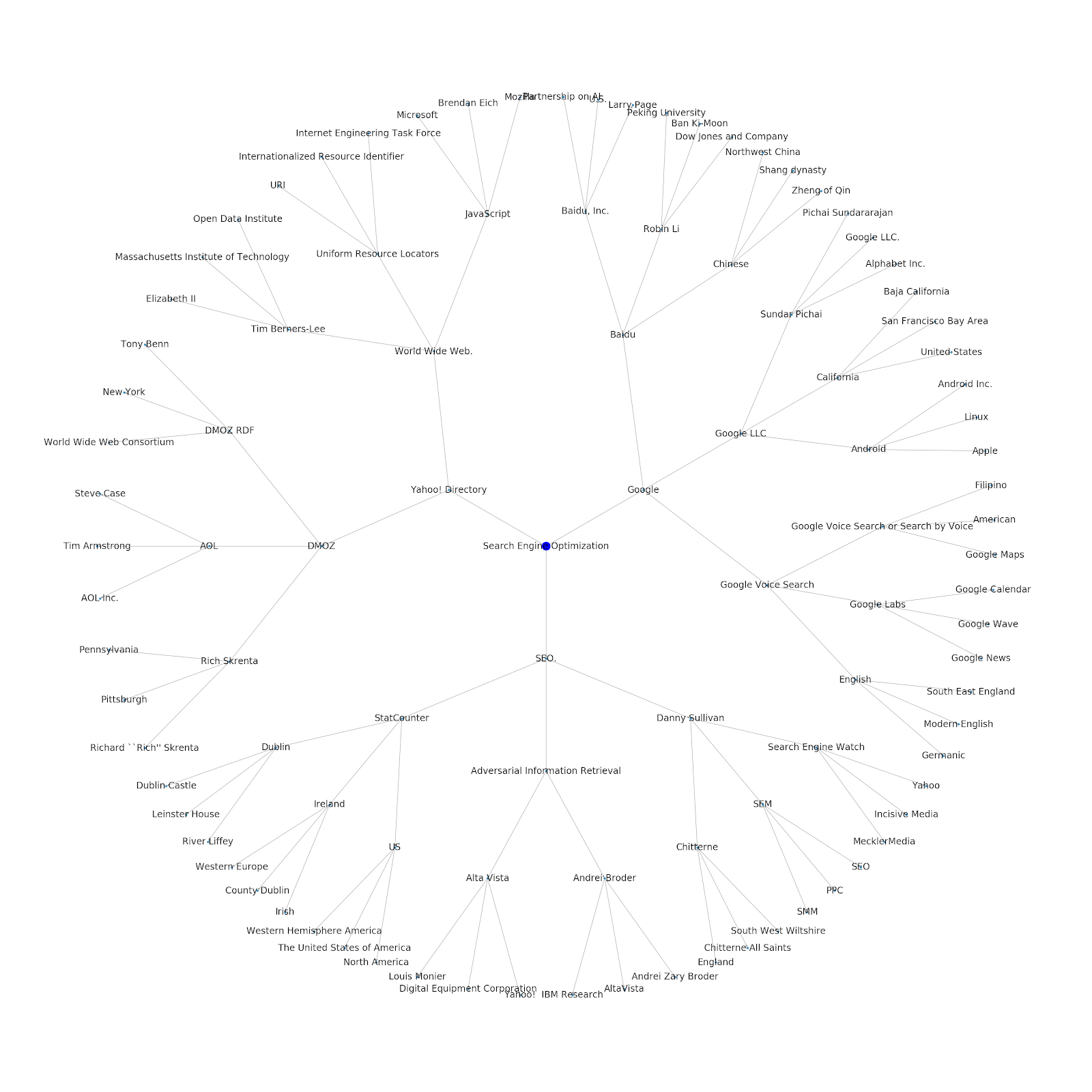
시드 주제 또는 시드 URL을 제공하는 기능을 추가했습니다. 이 경우 Google의 인덱싱 문제는 계속되지만 이 문제는 다릅니다 기사와 연결된 엔터티를 살펴봅니다.
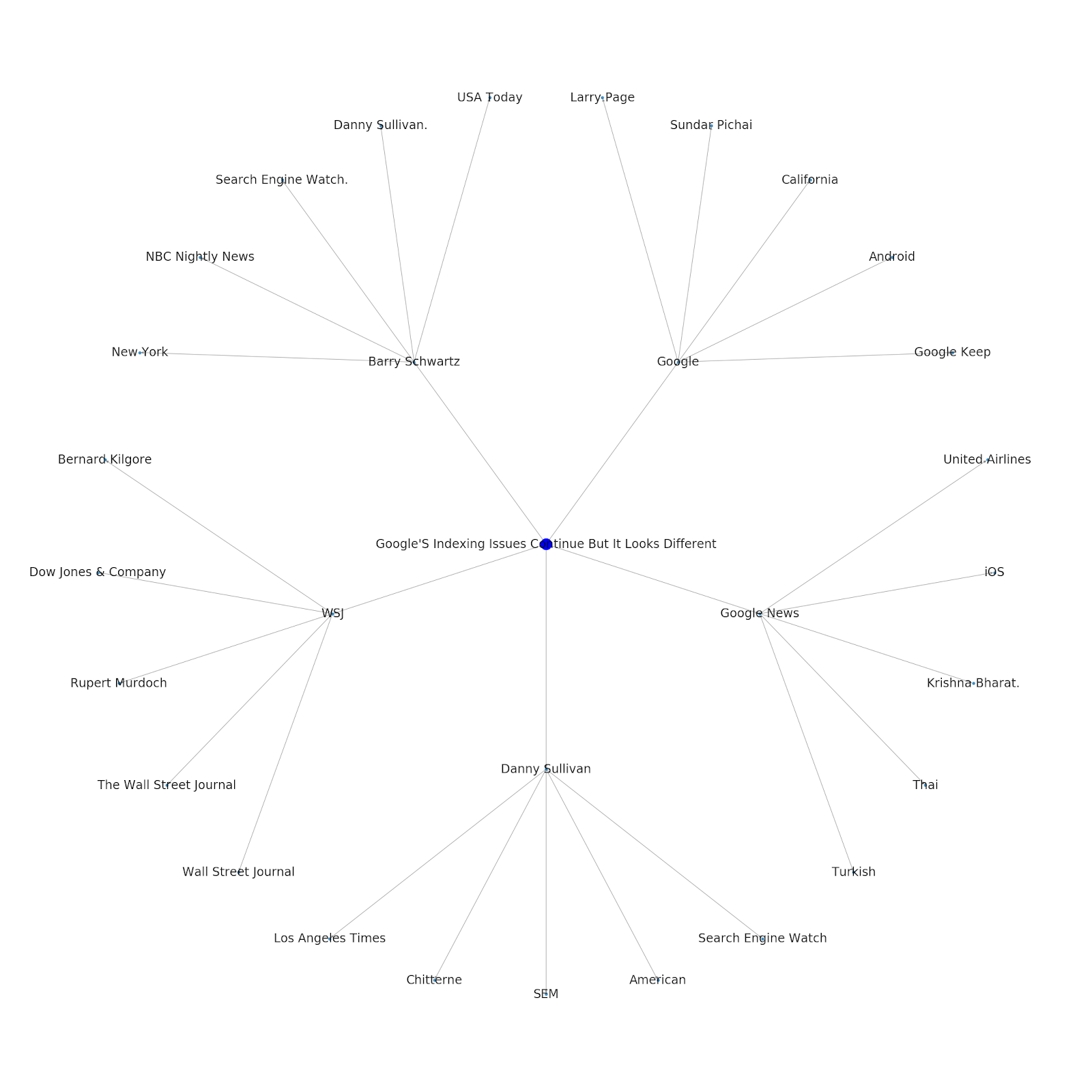
다음은 Python용 Google/Wikipedia 엔터티 그래프입니다.
이게 무슨 뜻이야
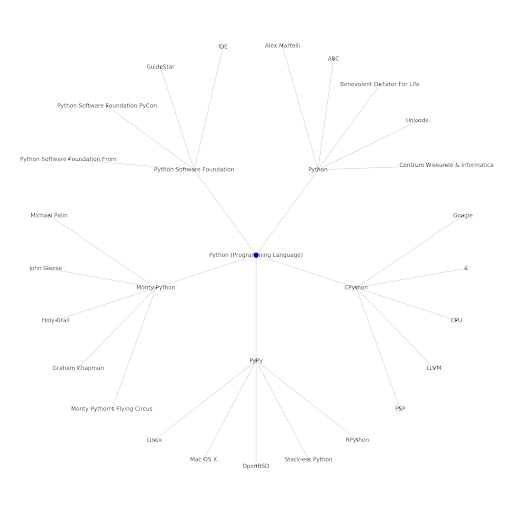
인터넷의 토픽 레이어를 이해하는 것은 SEO 관점에서 흥미롭습니다. 개별 쿼리가 아니라 사물이 어떻게 연결되어 있는지 생각해야 하기 때문입니다. Google은 이 레이어를 사용하여 개별 사용자의 선호도를 주제와 일치시키기 때문에 Google Discover 재도입에서 언급했듯이 데이터 중심 SEO에 더 중요한 워크플로가 될 수 있습니다. 위의 "Python" 그래프에서 시드 주제와 관련된 주제에 대한 사용자의 친숙도는 시드 주제에 대한 전문 지식 수준의 합리적인 척도일 수 있다고 추론할 수 있습니다.
아래 예는 관련 주제에 대한 역사적 관심 또는 친화성을 보여주는 녹색 강조 표시가 있는 두 명의 사용자를 보여줍니다. IDE가 무엇인지 이해하고 PyPy와 CPython이 무엇을 의미하는지 이해하고 있는 왼쪽의 사용자는 Python이 언어라는 것을 아는 사람보다 훨씬 더 경험이 풍부한 Python 사용자일 것입니다. 이것은 각 사용자에 대한 각 주제에 대한 숫자 점수로 쉽게 전환할 수 있습니다.

결론
오늘 저의 목표는 Jupyter Notebook을 사용하여 다양한 도구 또는 API의 효율성을 테스트하고 검토하기 위해 거치는 꽤 표준적인 프로세스를 공유하는 것이었습니다. 주제 그래프를 탐색하는 것은 매우 흥미롭고 공유된 도구를 통해 스스로 탐색을 시작하는 데 필요한 출발점을 찾을 수 있기를 바랍니다. 이러한 도구를 사용하면 Google의 Language API 할당량(하루 800,000개)의 범위로만 제한되는 다양한 관계 수준을 탐색하는 주제 그래프를 작성할 수 있습니다. (업데이트: 가격은 API로 전송된 1,000개의 유니코드 문자 단위를 기반으로 하며 최대 5,000개 단위까지 무료입니다. Wikipedia 기사가 길어질 수 있으므로 지출을 지켜보고 싶습니다. 이 점을 지적한 John Murch에게 모자 팁.) 노트북을 강화하거나 흥미로운 사례를 찾으면 알려주셨으면 합니다. Twitter의 @jroakes에서 저를 찾을 수 있습니다.