
작동하는 Robots.txt를 빌드하기 위한 키
게시 됨: 2020-02-18크롤러 또는 스파이더라고도 하는 봇은 링크를 도로로 사용하여 웹 사이트에서 웹 사이트로 자동으로 "이동"하는 프로그램입니다. 그들은 항상 특정 호기심을 제시했지만, robots.txt 파일은 매우 효과적인 도구가 될 수 있습니다. Google 및 Bing과 같은 검색 엔진은 봇을 사용하여 웹 콘텐츠를 크롤링합니다. robots.txt 파일은 다양한 봇이 사이트에서 크롤링하지 말아야 할 페이지에 대한 지침을 제공합니다. 봇이 크롤링해야 하는 모든 페이지의 지도를 갖도록 robots.txt에서 XML 사이트맵에 연결할 수도 있습니다.
robots.txt가 유용한 이유는 무엇입니까?
robots.txt는 검색 엔진 봇의 경우 봇이 크롤링하고 색인을 생성해야 하는 페이지의 양을 제한합니다. Google이 관리자 페이지를 크롤링하지 않도록 하려면 robots.txt에서 해당 페이지를 차단하여 Google 서버에서 페이지를 차단할 수 있습니다.
페이지 색인 생성을 방지하는 것 외에도 robots.txt는 크롤링 예산을 최적화하는 데 유용합니다. 크롤링 예산은 Google에서 사이트에서 크롤링할 것으로 결정한 페이지 수입니다. 일반적으로 권한이 더 많고 페이지가 많은 웹 사이트는 페이지 수와 권한이 낮은 웹 사이트보다 크롤링 예산이 더 큽니다. 사이트에 할당된 크롤링 예산이 얼마인지 모르기 때문에 색인 생성을 원하지 않는 페이지를 크롤링하는 대신 Googlebot이 가장 중요한 페이지에 액세스할 수 있도록 하여 이 시간을 최대한 활용하고자 합니다.
robots.txt에 대해 알아야 할 매우 중요한 세부정보는 Google이 robots.txt에 의해 차단된 페이지를 크롤링하지 않지만 페이지가 다른 웹사이트에서 링크된 경우 색인이 생성될 수 있다는 것입니다. 페이지의 색인이 생성되어 Google 검색 결과에 표시되지 않도록 하려면 서버의 파일을 비밀번호로 보호하거나 noindex 메타 태그 또는 응답 헤더를 사용하거나 페이지를 완전히 제거해야 합니다(404 또는 410으로 응답). 크롤링 및 색인 생성 제어에 대한 자세한 내용은 OnCrawl의 robots.txt 가이드를 참조하세요.
[사례 연구] Google의 봇 크롤링 관리
 사례 연구 읽기
사례 연구 읽기올바른 Robots.txt 구문
robots.txt 구문은 크롤러마다 구문을 다르게 해석하기 때문에 때때로 약간 까다로울 수 있습니다. 또한 평판이 좋지 않은 일부 크롤러는 robots.txt 지시문을 따라야 하는 명확한 규칙이 아니라 제안으로 봅니다. 사이트에 기밀 정보가 있는 경우 robots.txt를 사용하여 크롤러를 차단하는 것 외에 비밀번호 보호를 사용하는 것이 중요합니다.
다음은 robots.txt에서 작업할 때 염두에 두어야 할 몇 가지 사항입니다.
- robots.txt 파일은 하위 디렉토리가 아니라 도메인 아래에 있어야 합니다. 크롤러는 하위 디렉토리에서 robots.txt 파일을 확인하지 않습니다.
- 각 하위 도메인에는 자체 robots.txt 파일이 필요합니다.
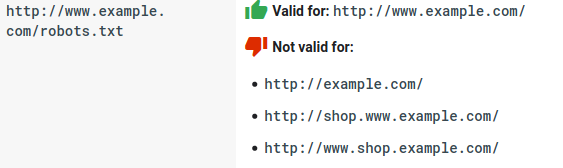
- Robots.txt는 대소문자를 구분합니다.
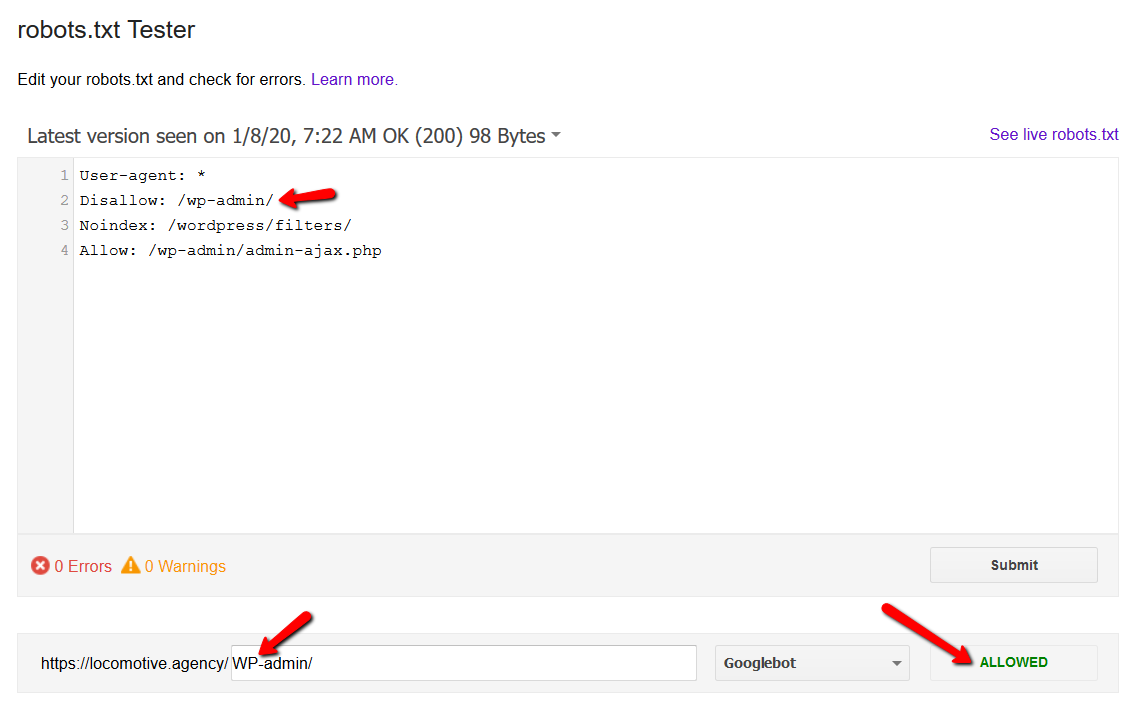
- noindex 지시문: robots.txt에서 noindex를 사용하면 disallow와 같은 방식으로 작동합니다. Google은 페이지 크롤링을 중지하지만 색인에는 유지합니다. @jroakes와 저는 /wordpress/filters/ 기사에서 Noindex 지시문을 사용하고 Google에 페이지를 제출하는 테스트를 만들었습니다. 아래 스크린샷에서 URL이 차단되었음을 확인할 수 있습니다.
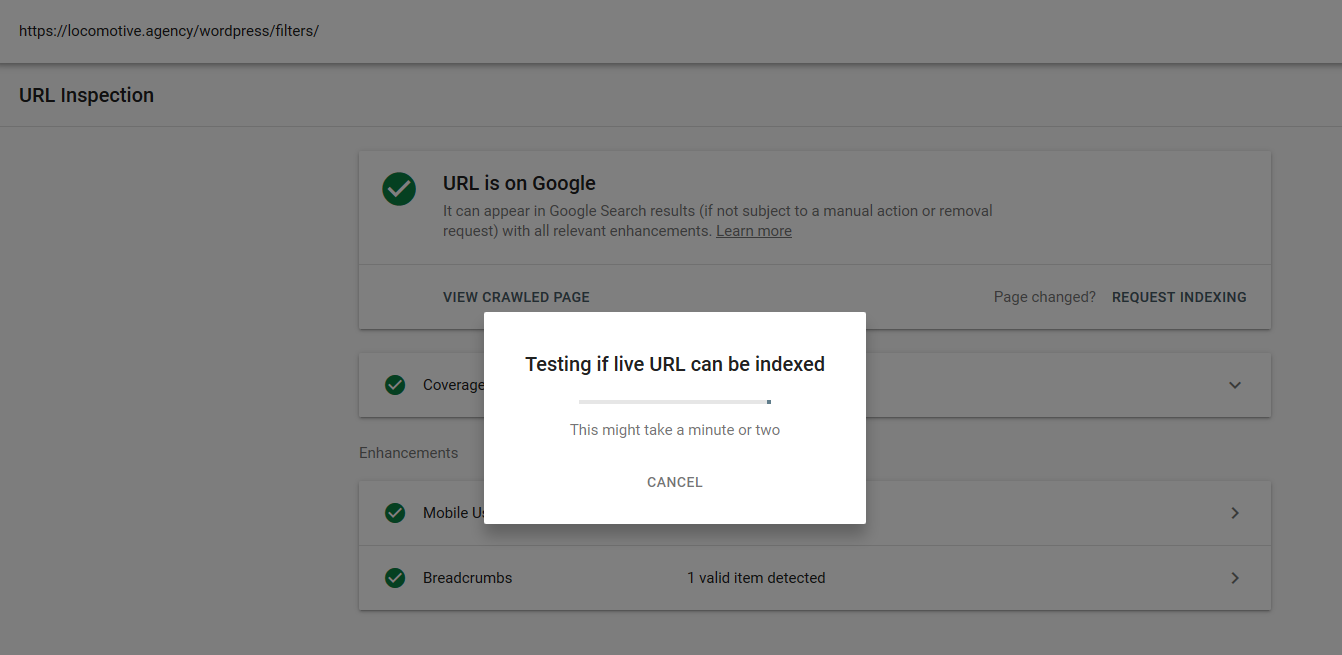
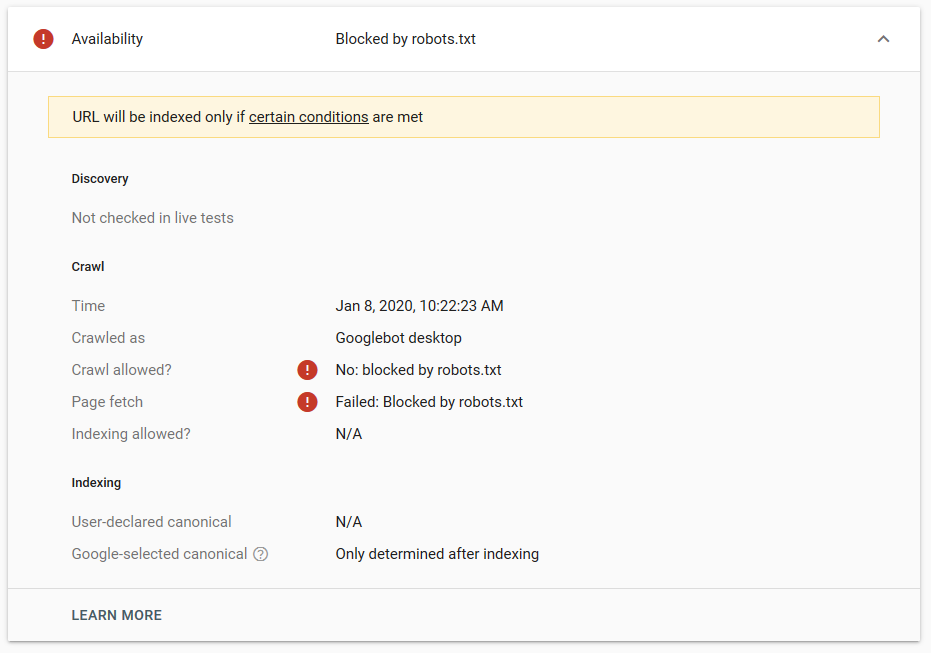
Google에서 여러 테스트를 수행했지만 해당 페이지는 색인에서 제거되지 않았습니다.
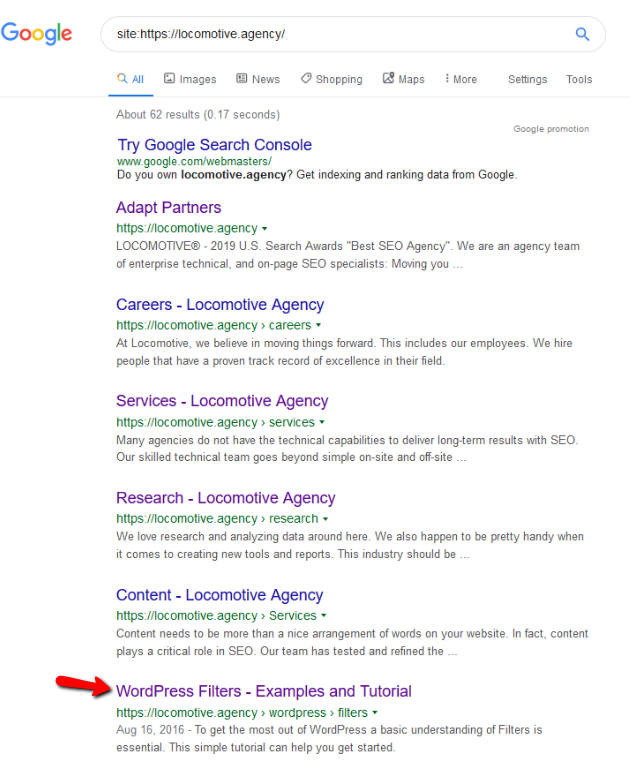
작년에 robots.txt에서 작동하는 noindex 지시문이 Google을 제외한 페이지를 제거하는 것에 대한 토론이 있었습니다. 다음은 Gary Illy가 사라진다고 말한 스레드입니다. 이 테스트에서 noindex 지시문이 검색 결과에서 페이지를 제거하지 않았기 때문에 Google의 솔루션이 제자리에 있음을 알 수 있습니다.

최근에 Christian Oliveira의 트위터에 또 다른 흥미로운 스레드가 있었는데, 여기에서 그는 robots.txt에서 작업할 때 고려해야 할 몇 가지 세부 정보를 공유했습니다.
- Googlebot에 대해서만 일반 규칙과 규칙을 갖고 싶다면 User-agent: Google 봇 규칙 세트 아래의 모든 일반 규칙을 복제해야 합니다. 포함되지 않은 경우 Googlebot은 모든 규칙을 무시합니다.

- 또 다른 혼란스러운 동작은 규칙의 우선 순위(동일한 User-agent 그룹 내)가 순서가 아니라 규칙의 길이에 의해 결정된다는 것입니다.
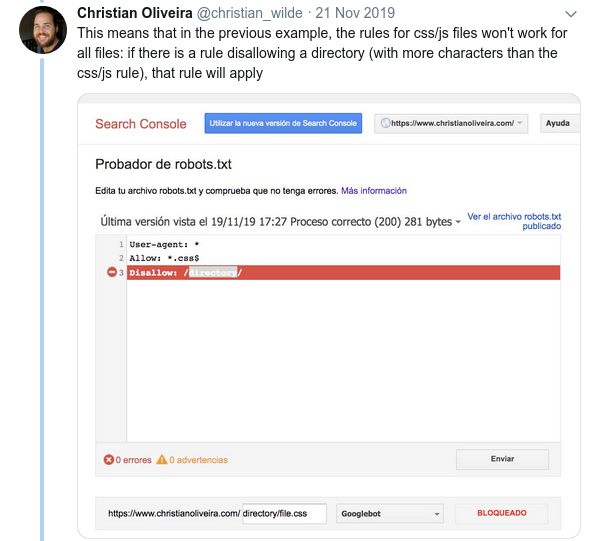
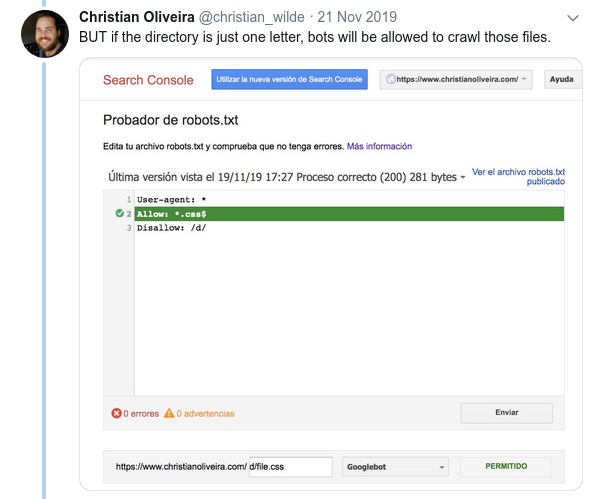
- 이제 길이가 같고 동작이 반대인 규칙이 두 개 있는 경우(하나는 크롤링을 허용하고 다른 하나는 크롤링을 허용하지 않음) 덜 제한적인 규칙이 적용됩니다.
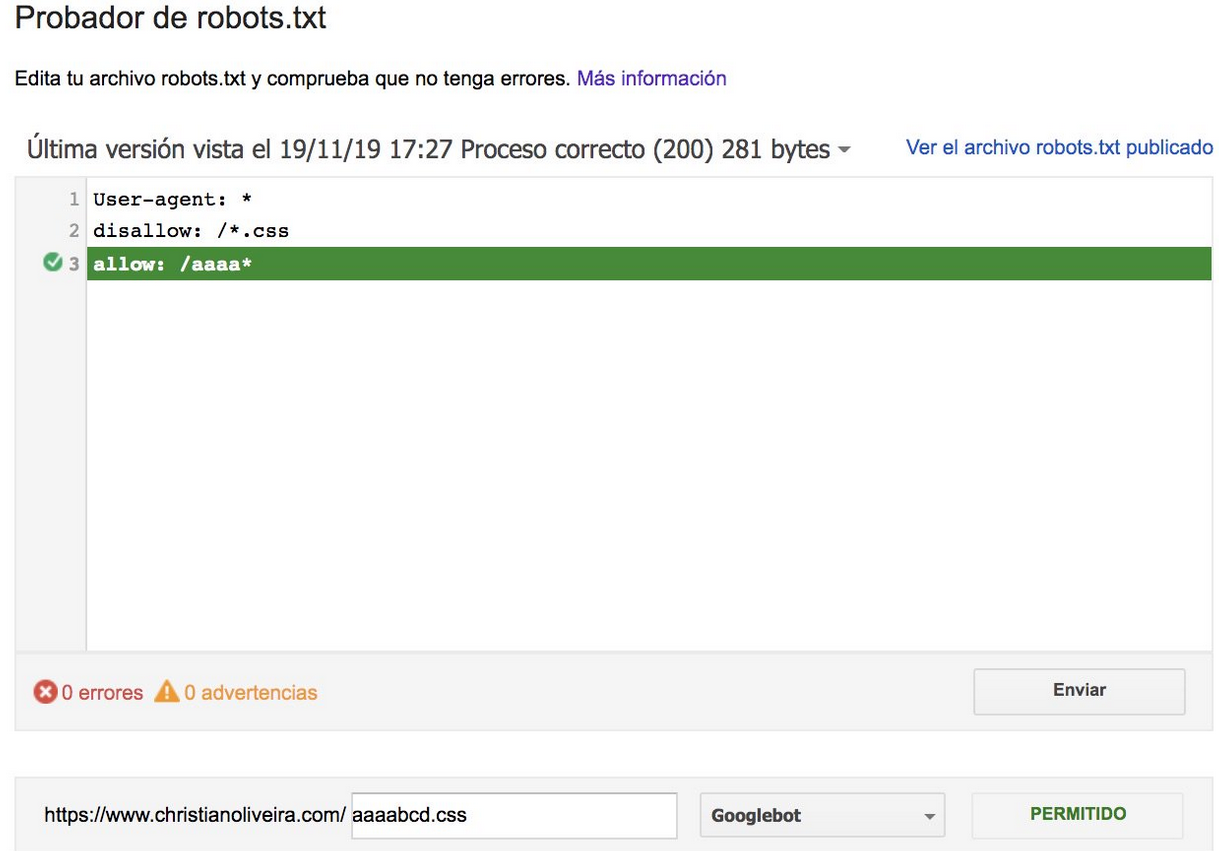
더 많은 예를 보려면 Google에서 제공하는 robots.txt 사양을 참조하세요.
Robots.txt를 테스트하기 위한 도구
robots.txt 파일을 테스트하려는 경우 도움이 될 수 있는 몇 가지 도구가 있으며 직접 만들려는 경우 몇 가지 github 리포지토리도 있습니다.
- 증류
- Google은 이전 Google Search Console의 robots.txt 테스터 도구를 여기에 남겼습니다.
- 파이썬에서
- C++에서
샘플 결과: 전자 상거래를 위한 Robots.txt의 효과적인 사용
아래에는 robots.txt 파일이 없는 Magento 사이트에서 작업한 사례가 포함되어 있습니다. Magento 및 기타 CMS에는 Google이 크롤링하지 않기를 바라는 파일이 포함된 관리 페이지와 디렉토리가 있습니다. 아래에는 robots.txt에 포함된 일부 디렉토리의 예가 포함되어 있습니다.
# # 일반 Magento 디렉토리 허용하지 않음: / 앱 / 허용하지 않음: / 다운로더 / 허용하지 않음: / 오류 / 금지: / 포함 / 허용하지 않음: / 라이브러리 / 허용하지 않음: / pkginfo / 허용하지 않음: / 쉘 / 허용하지 않음: / var / # # 검색 페이지 및 최적화되지 않은 링크 카테고리를 인덱싱하지 않습니다. 허용하지 않음: /catalog/product_compare/ 허용하지 않음: /catalog/category/view/ 허용하지 않음: /catalog/product/view/ 허용하지 않음: /catalog/product/gallery/ 허용하지 않음: /catalogsearch/
크롤링할 예정이 아니었던 엄청난 양의 페이지가 크롤링 예산에 영향을 미치고 있었고 Googlebot이 사이트의 모든 제품 페이지를 크롤링하지 못했습니다.
robots.txt가 구현된 10월 25일 이후에 색인이 생성된 페이지가 어떻게 증가했는지 아래 이미지에서 확인할 수 있습니다.
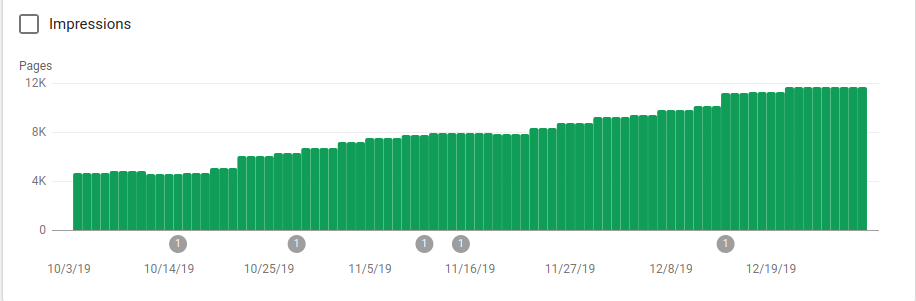
크롤링할 의도가 아닌 여러 디렉토리를 차단하는 것 외에도 로봇에는 사이트맵에 대한 링크가 포함되어 있습니다. 아래 스크린샷에서 제외된 페이지와 비교하여 인덱싱된 페이지 수가 어떻게 증가했는지 확인할 수 있습니다.
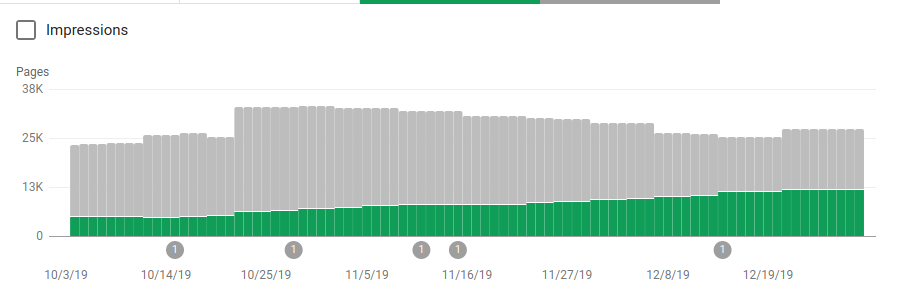
녹색 막대로 표시되는 색인이 생성된 유효한 페이지에는 긍정적인 경향이 있고 회색 막대로 표시되는 제외된 페이지에는 부정적인 경향이 있습니다.
마무리
robots.txt의 중요성은 때때로 과소평가될 수 있으며 이 게시물에서 볼 수 있듯이 생성할 때 고려해야 할 세부사항이 많이 있습니다. 그러나 작업 결과는 다음과 같습니다. robots.txt를 올바르게 설정하여 얻을 수 있는 긍정적인 결과 중 일부를 보여 주었습니다.