
Python의 단일 뉴런 신경망 – 수학적 직관 사용
게시 됨: 2021-06-21단일 계층을 사용하여 매우 간단하지만 완전한 네트워크인 간단한 네트워크를 구축해 보겠습니다. 하나의 입력과 하나의 뉴런(출력이기도 함), 하나의 가중치, 하나의 편향.
먼저 코드를 실행한 다음 부분별로 분석해 보겠습니다.
Github 프로젝트를 복제하거나 즐겨 사용하는 IDE에서 다음 코드를 실행하기만 하면 됩니다.
IDE 설정에 도움이 필요한 경우 여기에서 프로세스를 설명했습니다.
모든 것이 정상이면 다음과 같은 출력이 표시됩니다.
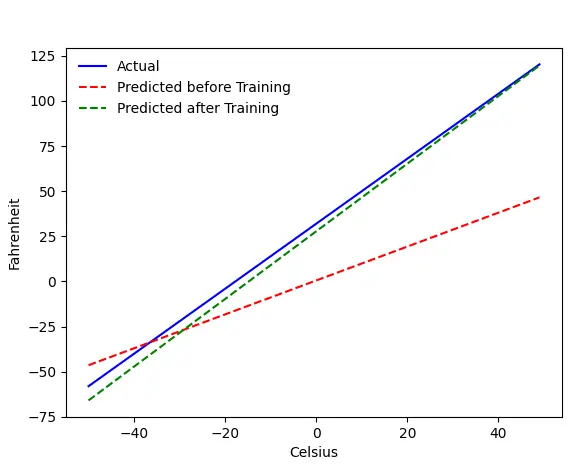
문제 — 섭씨에서 화씨
우리는 섭씨에서 화씨를 예측하도록 기계를 훈련할 것입니다. 코드(또는 그래프)에서 알 수 있듯이 파란색 선은 실제 섭씨-화씨 관계입니다. 빨간 선은 아무런 훈련 없이 베이비 머신이 예측한 관계입니다. 마지막으로 우리는 기계를 훈련하고 녹색 선은 훈련 후 예측입니다.
Line#65–67을 보세요. 훈련 전후에 동일한 함수( get_predicted_fahrenheit_values() )를 사용하여 예측하고 있습니다. 그래서 마술 기차()는 무엇을 하고 있습니까? 알아 보자.
네트워크 구조
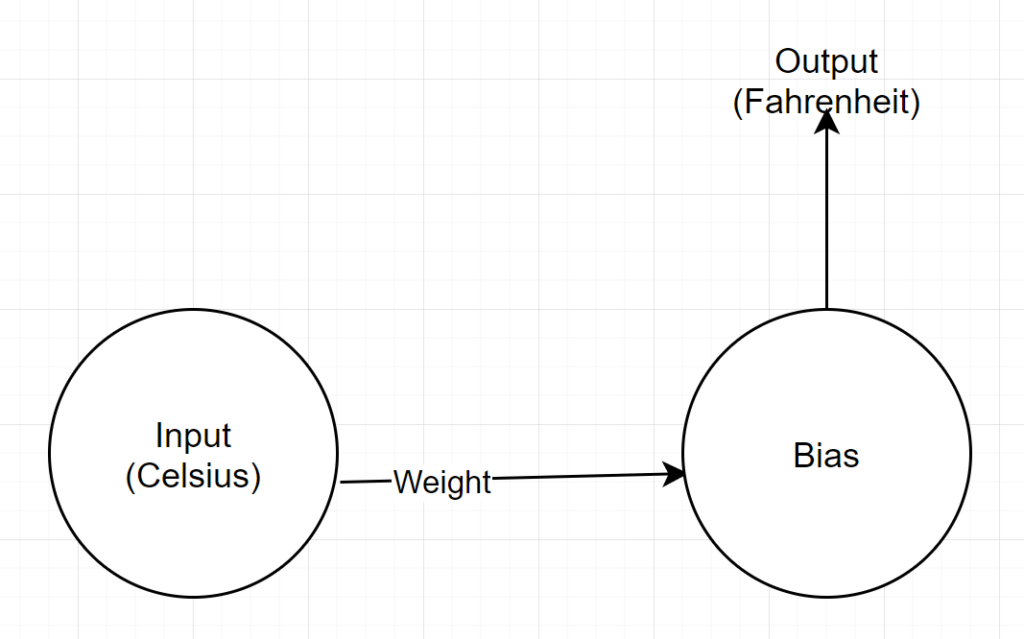
입력: 섭씨를 나타내는 숫자
무게: 무게 를 나타내는 float
바이어스: 바이어스를 나타내는 부동 소수점
출력: 예측된 화씨를 나타내는 부동 소수점
따라서 총 2개의 매개변수가 있습니다. 1개의 가중치와 1개의 편향
코드 분석
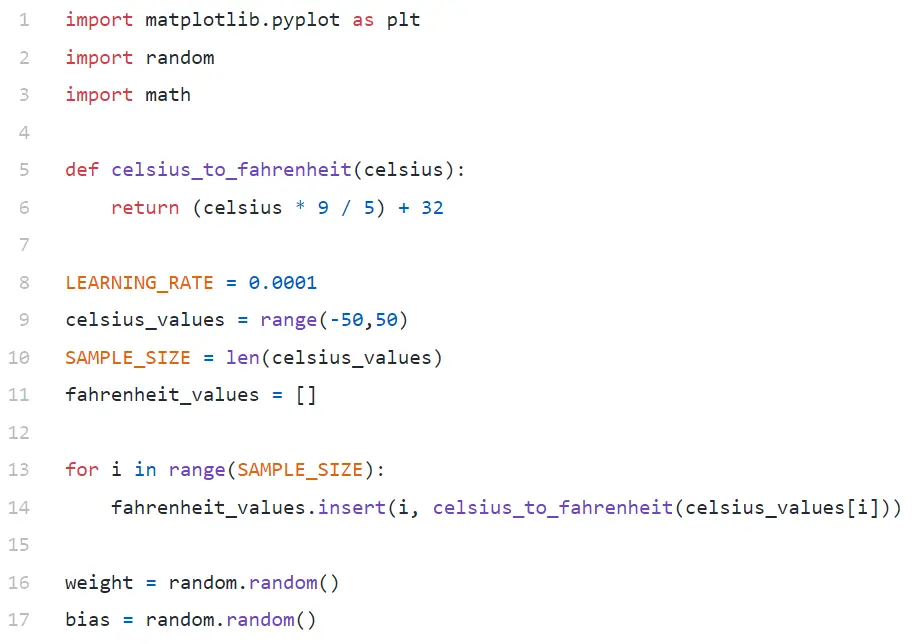
Line#9에서는 -50에서 +50 사이의 100개 숫자 배열을 생성합니다(50 제외 - 범위 함수는 상한값 제외).
Line#11–14에서는 각 섭씨 값에 대해 화씨를 생성합니다.
16번과 17번 줄에서 weight와 bias를 초기화하고 있습니다.
기차()

여기에서 10000번의 반복 훈련을 실행하고 있습니다. 각 반복은 다음으로 구성됩니다.
- 앞으로(57행) 패스
- 뒤로(58행) 패스
- update_parameters(라인 #59)
파이썬을 처음 접한다면 조금 이상하게 보일 수 있습니다. 파이썬 함수는 여러 값을 tuple 로 반환할 수 있습니다.
update_parameters 가 우리가 관심을 갖는 유일한 것임을 주목하십시오. 여기서 우리가 하는 다른 모든 것은 이 함수의 매개변수를 평가하는 것입니다. 이 매개변수는 가중치와 편향의 기울기 (아래에서 기울기가 무엇인지 설명할 것입니다)입니다.
- grad_weight: 가중치의 기울기를 나타내는 float
- grad_bias: 바이어스 기울기를 나타내는 float
역방향 호출을 통해 이 값을 얻지만 출력이 필요합니다. 이 출력은 57번 줄에서 forward를 호출하여 얻습니다.
앞으로()

여기서 celsius_values 및 fahrenheit_values 는 100개 행의 배열입니다.
Line#20–23을 실행한 후 섭씨 값의 경우 42
출력 = 42 * 가중치 + 편향
따라서 celsius_values 의 100개 요소에 대해 출력은 각 해당 섭씨 값에 대해 100개 요소의 배열이 됩니다.
Line#25–30은 MSE(Mean Squared Error) 손실 함수를 사용하여 손실을 계산하고 있습니다. 이는 모든 차이의 제곱을 샘플 수(이 경우 100)로 나눈 멋진 이름입니다.
작은 손실은 더 나은 예측을 의미합니다. 모든 반복에서 인쇄 손실을 계속 유지하면 훈련이 진행됨에 따라 감소하는 것을 볼 수 있습니다.
마지막으로 Line#31에서는 예측된 출력과 손실을 반환합니다.
뒤로

우리는 가중치와 편향을 업데이트하는 데만 관심이 있습니다. 이러한 값을 업데이트하려면 기울기를 알아야 하며 이것이 여기에서 계산하는 것입니다.
주의 기울기는 역순으로 계산됩니다. 출력 기울기가 먼저 계산된 다음 가중치 및 편향에 대해 계산되므로 "역전파"라는 이름이 지정됩니다. 그 이유는 가중치와 편향의 기울기를 계산하려면 출력 기울기를 알아야 체인 규칙 공식에서 사용할 수 있기 때문입니다.
이제 그래디언트와 체인 규칙이 무엇인지 살펴보겠습니다.
구배
간단하게 하기 위해 celsius_values 및 fahrenheit_values , 42 및 107.6 의 값이 각각 하나만 있다고 가정합니다.
이제 Line#30의 계산 분석은 다음과 같습니다.
손실 = (107.6 — (42 * 가중치 + 편향))² / 1
보시다시피 손실은 가중치와 편향의 2가지 매개변수에 따라 달라집니다. 무게를 고려하십시오. 예를 들어 0.8과 같은 임의의 값으로 초기화하고 위의 방정식을 평가한 후 손실 값으로 123.45를 얻는다고 상상해 보세요. 이 손실 값을 기반으로 체중 업데이트 방법을 결정해야 합니다. 0.9로 해야 할까요 0.7로 해야 할까요?
다음 반복에서 더 낮은 손실 값을 얻을 수 있도록 가중치를 업데이트해야 합니다(손실 최소화가 궁극적인 목표임을 기억하십시오). 따라서 체중을 늘리면 감량이 증가하면 감량합니다. 체중을 늘리면 감량이 감소하면 체중을 늘릴 것입니다.
이제 문제는 무게를 늘리면 손실이 증가하거나 감소하는지 어떻게 알 수 있습니까? 여기에서 그라디언트가 나타 납니다. 일반적으로 기울기는 미분으로 정의됩니다. 고등학교 미적분학에서 ∂y/∂x(x에 대한 y의 편미분/기울기)는 x의 작은 변화로 y가 어떻게 변할 것인지를 나타냅니다.
∂y/∂x가 양수이면 x가 약간 증가하면 y가 증가한다는 의미입니다.
∂y/∂x가 음수이면 x의 작은 증가가 y를 감소시킨다는 것을 의미합니다.
∂y/∂x가 크면 x의 작은 변화가 y의 큰 변화를 일으킵니다.
∂y/∂x가 작다면 x의 작은 변화는 y의 작은 변화를 일으킬 것입니다.
따라서 그라디언트에서 2개의 정보를 얻습니다. 매개변수가 업데이트되어야 하는 방향(증가 또는 감소) 및 얼마나(크거나 작은).

연쇄 법칙
비공식적으로 말하면 연쇄 법칙은 다음과 같이 말합니다.
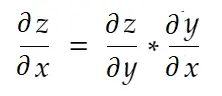
위의 무게 예를 고려하십시오. 이 가중치를 업데이트하려면 grad_weight 를 계산해야 합니다. 이 가중치는 다음과 같이 계산됩니다.
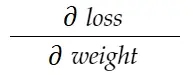
연쇄 규칙 공식을 사용하여 다음을 도출할 수 있습니다.
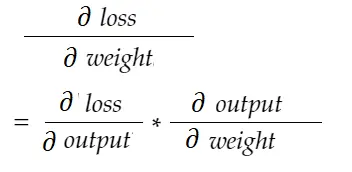
마찬가지로 편향에 대한 기울기:
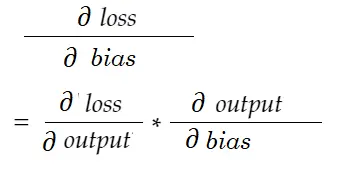
의존성 다이어그램을 그려봅시다.
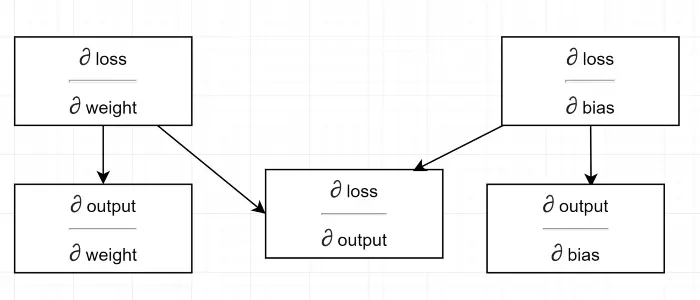
모든 계산은 출력 기울기에 따라 다릅니다 (∂ 손실/∂ 출력) . 이것이 우리가 백패스(Line#34–36)에서 먼저 계산하는 이유입니다.
실제로 PyTorch와 같은 고급 ML 프레임워크에서는 백패스용 코드를 작성할 필요가 없습니다! 정방향 패스 시에는 연산 그래프를 생성하고, 역방향 패스 시에는 그래프의 반대 방향으로 이동하여 연쇄 법칙을 사용하여 기울기를 계산합니다.
∂ 손실 / ∂ 출력
코드의 grad_output 에 의해 이 변수를 정의합니다. 이는 Line#34–36에서 계산했습니다. 코드에서 사용한 수식 뒤에 숨겨진 이유를 알아봅시다.
우리는 기계에 있는 모든 100 celsius_values 를 함께 공급하고 있음을 기억하십시오. 따라서 grad_output은 100개 요소의 배열이 될 것이며, 각 요소는 celsius_values 의 해당 요소에 대한 출력 기울기를 포함합니다. 단순화를 위해 celsius_values 에는 2개의 항목만 있다고 가정해 보겠습니다.
따라서 #30 라인을 분해하면,
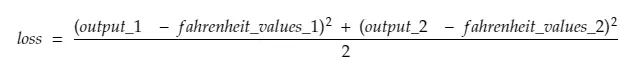
어디,
output_1 = 첫 번째 섭씨 값에 대한 출력 값
output_2 = 두 번째 섭씨 값에 대한 출력 값
fahreinheit_values_1 = 첫 번째 섭씨 값에 대한 실제 화씨 값
fahreinheit_values_1 = 두 번째 섭씨 값에 대한 실제 화씨 값
이제 결과 변수 grad_output에는 output_1 및 output_2의 그라디언트인 2개의 값이 포함됩니다. 다음을 의미합니다.
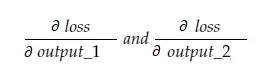
output_1의 그래디언트만 계산하면 다른 것들에 대해서도 같은 규칙을 적용할 수 있습니다.
미적분 시간!

이는 #34–36 행과 동일합니다.
무게 구배
celsius_values에 하나의 요소만 있다고 상상해 보세요. 지금:

Line #38–40과 동일합니다. 100 celsius_values의 경우 각 값의 기울기 값이 합산됩니다. 분명한 질문은 결과를 축소하지 않는 이유입니다(즉, SAMPLE_SIZE로 나누기). 매개변수를 업데이트하기 전에 모든 그래디언트에 작은 인수를 곱하기 때문에 필요하지 않습니다(마지막 매개변수 업데이트 섹션 참조).
바이어스 기울기

Line # 42와 동일합니다. 가중치 기울기와 마찬가지로 100개 입력 각각에 대한 이러한 값이 합산됩니다. 다시 말하지만, 매개변수를 업데이트하기 전에 그라디언트에 작은 요소를 곱하기 때문에 괜찮습니다.
매개변수 업데이트

마지막으로 매개변수를 업데이트합니다. 훈련을 안정적으로 만들기 위해 빼기 전에 작은 인자(LEARNING_RATE)를 곱한 그라디언트에 주목하세요. LEARNING_RATE 값이 크면 오버슈팅 문제가 발생하고 값이 매우 작으면 학습 속도가 느려져 더 많은 반복이 필요할 수 있습니다. 약간의 시행착오를 거쳐 최적의 값을 찾아야 합니다. 학습 속도에 대해 더 많이 알기 위해 이것을 포함하여 많은 온라인 리소스가 있습니다.
우리가 조정하는 정확한 양은 그다지 중요하지 않습니다. 예를 들어 LEARNING_RATE를 약간 조정하면 descent_grad_weight 및 descent_grad_bias 변수(라인 #49–50)가 변경되지만 기계는 여전히 작동할 수 있습니다. 중요한 것은 동일한 인수(이 경우 LEARNING_RATE)로 그라디언트를 축소하여 이러한 양이 파생되었는지 확인하는 것입니다. 즉, "그라디언트의 하강 을 비례적으로 유지"하는 것이 " 하강 하는 정도"보다 더 중요합니다.
또한 이러한 기울기 값은 실제로 100개의 입력 각각에 대해 평가된 기울기의 합입니다. 하지만 이것들은 같은 값으로 스케일링되기 때문에 위에서 언급한 것처럼 괜찮습니다.
매개변수를 업데이트하려면 전역 키워드로 매개변수를 선언해야 합니다(Line#47).
여기서 어디로 갈까
for 루프를 파이썬 방식으로 목록 이해로 교체하면 코드가 훨씬 작아집니다. 지금 한 번 보세요. 이해하는 데 몇 분도 걸리지 않을 것입니다.
지금까지 모든 것을 이해했다면 여러 개의 뉴런/계층이 있는 간단한 네트워크의 내부를 살펴보는 것이 좋습니다. 여기 기사가 있습니다.