
Python의 시맨틱 키워드 클러스터링
게시 됨: 2021-04-19디지털 마케팅 신화로 가득 찬 세상에서 일상적인 문제에 대한 실용적인 솔루션을 찾는 것이 우리에게 필요한 것이라고 믿습니다.
PEMAVOR에서는 디지털 마케팅 애호가의 요구를 충족시키기 위해 항상 전문 지식과 지식을 공유합니다. 따라서 ROI를 높이는 데 도움이 되는 무료 Python 스크립트를 자주 게시합니다.
Python을 사용한 SEO 키워드 클러스터링은 50줄 미만의 Python 코드로 대규모 SEO 프로젝트에 대한 새로운 통찰력을 얻을 수 있는 길을 열었습니다.
이 스크립트의 이면에 있는 아이디어는 '과장된 비용'을 지불하지 않고 키워드를 그룹화할 수 있도록 하는 것이었습니다. 글쎄, 우리는 누가…
그러나 우리는 이 스크립트만으로는 충분하지 않다는 것을 깨달았습니다. 다른 스크립트가 필요하므로 키워드에 대한 이해를 높일 수 있습니다 . 의미와 의미 관계에 따라 " 키워드를 그룹화할 수 있어야 합니다. "
이제 SEO용 Python을 한 단계 더 발전시킬 때입니다.
온크롤 데이터³
 더 알아보기
더 알아보기의미론적 클러스터링의 전통적인 방법
아시다시피, 의미론을 위한 전통적인 방법은 word2vec 모델 을 구축한 다음 Word Mover의 거리 를 사용하여 키워드를 클러스터링하는 것입니다.
그러나 이러한 모델을 구축하고 훈련하는 데 많은 시간과 노력이 필요합니다. 따라서 보다 직관적인 솔루션을 제공하고자 합니다. 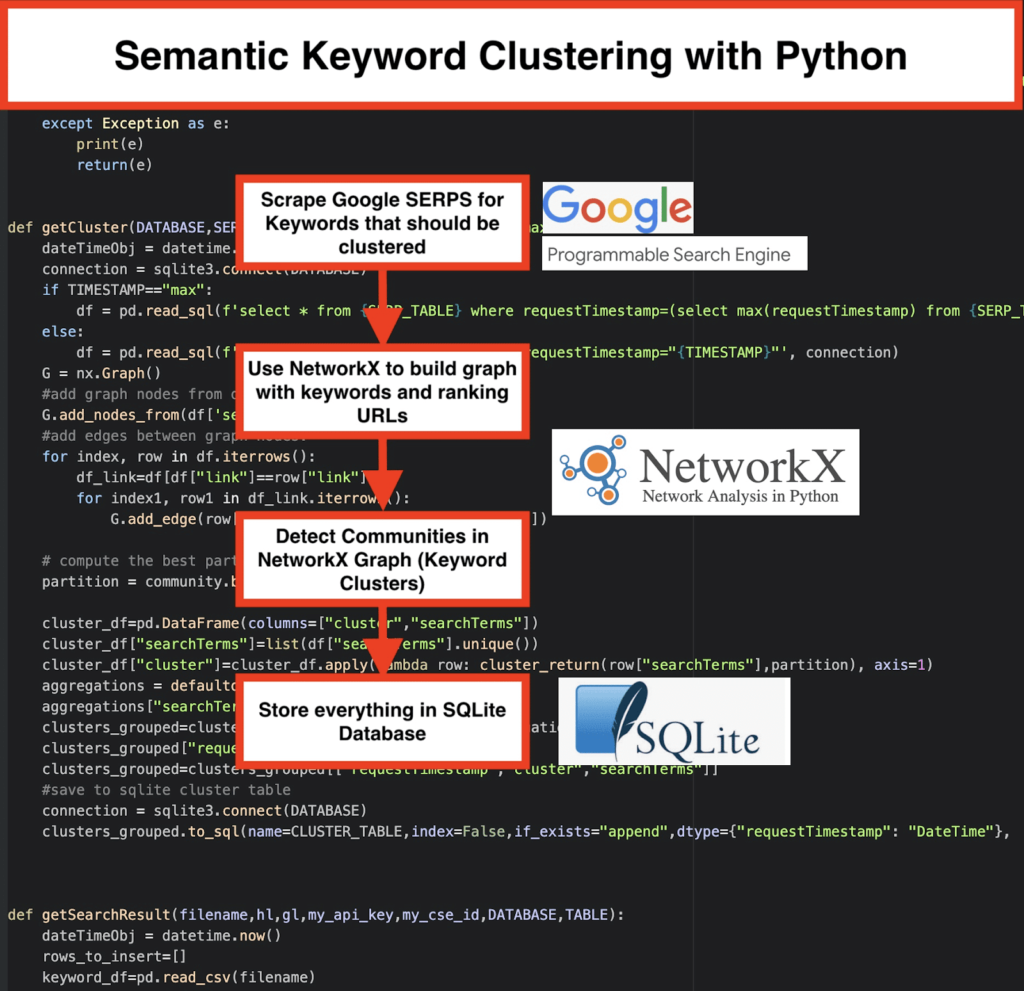
Google SERP 결과 및 의미 발견
Google은 NLP 모델을 사용하여 최상의 검색 결과를 제공합니다. 그것은 판도라의 상자가 열리는 것과 같으며 우리는 그것을 정확히 알지 못합니다.
그러나 모델을 구축하는 대신 이 상자를 사용하여 의미와 의미별로 키워드를 그룹화할 수 있습니다.
방법은 다음과 같습니다.
️ 먼저 주제에 대한 키워드 목록을 작성하십시오 .
️ 그런 다음 각 키워드에 대한 SERP 데이터를 스크랩하십시오 .
️ 다음으로 랭킹 페이지와 키워드의 관계를 그래프로 생성 합니다.
️ 같은 페이지가 다른 키워드에 대해 순위가 매겨지는 한, 그것은 함께 관련되어 있음을 의미합니다. 이것이 의미론적 키워드 클러스터 생성 의 핵심 원칙 입니다.
Python으로 모든 것을 통합할 시간
Python 스크립트는 다음 기능을 제공합니다.
- Google의 맞춤 검색 엔진을 사용하여 키워드 목록에 대한 SERP를 다운로드합니다. 데이터는 SQLite 데이터베이스 에 저장됩니다. 여기에서 사용자 정의 검색 API를 설정해야 합니다.
- 그런 다음 매일 100개 요청의 무료 할당량을 사용하십시오. 그러나 기다리기를 원하지 않거나 큰 데이터 세트가 있는 경우 1000개 퀘스트당 5달러의 유료 플랜도 제공합니다.
- 서두르지 않으면 SQLite 솔루션 을 사용하는 것이 좋습니다. SERP 결과는 실행할 때마다 테이블에 추가됩니다. (다음 날 다시 할당량이 있을 때 100개 키워드의 새로운 시리즈를 가져오기만 하면 됩니다.)
- 한편, Python Script 에서 이러한 변수를 설정해야 합니다.
- CSV_FILE=”keywords.csv” => 여기에 키워드 저장
- 언어 = "ko"
- 국가 = "ko"
- API_KEY="xxxxxx"
- CSE_ID=”xxxxxxx”
-
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)를 실행하면 SERP 결과가 데이터베이스에 기록됩니다. - 클러스터링은 networkx와 커뮤니티 감지 모듈에 의해 수행됩니다. 데이터는 SQLite 데이터베이스 에서 가져옵니다. 클러스터링은
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)로 호출됩니다. - 클러스터링 결과는 SQLite 테이블 에서 찾을 수 있습니다. 변경하지 않는 한 이름은 기본적으로 "keyword_clusters"입니다.
아래에 전체 코드가 표시됩니다.
# Pemavor.com의 시맨틱 키워드 클러스터링 # 저자: 스테판 니피셔 ([email protected]) googleapiclient.discovery 가져오기 빌드에서 pandas를 pd로 가져오기 수입 레벤슈타인 날짜/시간에서 가져오기 날짜/시간 fuzzywuzzy에서 가져오기 퍼즈 urllib.parse에서 urlparse 가져오기 tld에서 가져오기 get_tld 수입 json 가져오기 pandas를 pd로 가져오기 numpy를 np로 가져오기 networkx를 nx로 가져오기 수입 커뮤니티 가져오기 sqlite3 수입 수학 가져오기 컬렉션에서 defaultdict 가져오기 def cluster_return(searchTerm, 파티션): 파티션 반환[searchTerm] def 언어 감지(str_lan): lan=langid.classify(str_lan) 반환 LAN[0] def extract_domain(url, remove_http=True): uri = urlparse(url) remove_http인 경우: 도메인 이름 = f"{uri.netloc}" 또 다른: 도메인 이름 = f"{uri.netloc}://{uri.netloc}" 도메인 이름 반환 def extract_mainDomain(url): res = get_tld(url, as_object=True) res.fld를 반환 def fuzzy_ratio(str1,str2): fuzz.ratio(str1,str2)를 반환합니다. def fuzzy_token_set_ratio(str1,str2): fuzz.token_set_ratio(str1,str2) 반환 def google_search(search_term, api_key, cse_id, hl,gl, **kwargs): 노력하다: 서비스 = 빌드("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(제목,디스플레이링크,링크,스니펫)' ,num=10, cx=cse_id, **kwargs).execute() 반환 해상도 예외를 제외하고 e: 인쇄(e) 반환(e) def google_search_default_language(search_term, api_key, cse_id, gl, **kwargs): 노력하다: 서비스 = 빌드("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10 , cx=cse_id, **kwargs).execute() 반환 해상도 예외를 제외하고 e: 인쇄(e) 반환(e) def getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="최대"): dateTimeObj = datetime.now() 연결 = sqlite3.connect(데이터베이스) TIMESTAMP=="최대"인 경우: df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp=(select max(requestTimestamp) from {SERP_TABLE})', 연결) 또 다른: df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp="{TIMESTAMP}"', 연결) G = nx.Graph() # 데이터프레임 열에서 그래프 노드 추가 G.add_nodes_from(df['searchTerms']) #그래프 노드 사이에 간선 추가: 인덱스의 경우 df.iterrows()의 행: df_link=df[df["링크"]==행["링크"]] index1의 경우 df_link.iterrows()의 row1: G.add_edge(row["searchTerms"], row1['searchTerms']) # 커뮤니티(클러스터)에 가장 적합한 파티션을 계산합니다. 파티션 = 커뮤니티.베스트_파티션(G) cluster_df=pd.DataFrame(columns=["클러스터","searchTerms"]) cluster_df["searchTerms"]=list(df["searchTerms"].unique()) cluster_df["cluster"]=cluster_df.apply(람다 행: cluster_return(row["searchTerms"],partition), 축=1) 집계 = defaultdict() 집계["searchTerms"]=' | '.가입하다 clusters_grouped=cluster_df.groupby("클러스터").agg(집계).reset_index() clusters_grouped["requestTimestamp"]=dateTimeObj clusters_grouped=clusters_grouped[["requestTimestamp","cluster","searchTerms"]] #sqlite 클러스터 테이블에 저장 연결 = sqlite3.connect(데이터베이스) clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) def getSearchResult(파일명,hl,gl,my_api_key,my_cse_id,DATABASE,TABLE): dateTimeObj = datetime.now() rows_to_insert=[] keyword_df=pd.read_csv(파일명) 키워드=keyword_df.iloc[:,0].tolist() 키워드 쿼리: hl=="기본"인 경우: 결과 = google_search_default_language(쿼리, my_api_key, my_cse_id,gl) 또 다른: 결과 = google_search(쿼리, my_api_key, my_cse_id,hl,gl) 결과에 "항목"이 있고 결과에 "쿼리"가 있는 경우: 범위(0,len(result["items"]))의 위치: 결과["항목"][위치]["위치"]=위치+1 결과["항목"][위치]["주 도메인"]= extract_mainDomain(결과["항목"][위치]["링크"]) 결과["항목"][위치]["title_matchScore_token"]=fuzzy_token_set_ratio(결과["항목"][위치]["제목"], 쿼리) result["items"][position]["snippet_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["snippet"],query) 결과["항목"][위치]["title_matchScore_order"]=fuzzy_ratio(결과["항목"][위치]["제목"], 쿼리) result["items"][position]["snippet_matchScore_order"]=fuzzy_ratio(result["items"][position]["snippet"],query) result["items"][position]["snipped_language"]=language_detection(result["items"][position]["snippet"]) 범위(0,len(result["items"]))의 위치: rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl, "totalResults":result["queries"]["request"][0]["totalResults"],"link":result["items"][position]["link"], "displayLink":결과["항목"][위치]["디스플레이링크"],"주 도메인":결과["항목"][위치]["주 도메인"], "위치":결과["항목"][위치]["위치"],"조각":결과["항목"][위치]["조각"], "snipped_language":result["항목"][위치]["snipped_language"],"snippet_matchScore_order":result["항목"][위치]["snippet_matchScore_order"], "snippet_matchScore_token": 결과["items"][위치]["snippet_matchScore_token"],"title":result["items"][위치]["제목"], "title_matchScore_order":결과["항목"][위치]["title_matchScore_order"],"title_matchScore_token":결과["항목"][위치]["title_matchScore_token"], }) df=pd.DataFrame(rows_to_insert) # sqlite 데이터베이스에 serp 결과 저장 연결 = sqlite3.connect(데이터베이스) df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) #################################################### #################################################### ############################################ #읽어줘: # #################################################### #################################################### ############################################ #1- 구글 맞춤 검색 엔진을 설정해야 합니다. # # API Key와 SearchId를 입력해주세요. # # 또한 SERP 결과를 모니터링하려는 국가와 언어를 설정합니다. # # 아직 API Key와 Search ID가 없다면 # # 이 페이지의 전제 조건 섹션에 있는 단계를 따를 수 있습니다. https://developers.google.com/custom-search/v1/overview#prerequisites # # # #2- 결과를 저장하는 데 사용할 데이터베이스, serp 테이블 및 클러스터 테이블 이름도 입력해야 합니다. # # # #3- serp에 사용될 키워드가 포함된 csv 파일 이름 또는 전체 경로를 입력합니다. # # # #4- 키워드 클러스터링의 경우 클러스터링에 사용할 serp 결과의 타임스탬프를 입력합니다. # # 마지막 serp 결과를 클러스터링해야 하는 경우 타임스탬프에 "최대"를 입력합니다. # # 또는 "2021-02-18 17:18:05.195321"과 같은 특정 타임스탬프를 입력할 수 있습니다. # # #5- Sqlite 프로그램용 DB 브라우저를 통해 결과 찾아보기 # #################################################### #################################################### ############################################ serp에 대한 키워드가 있는 #csv 파일 이름 CSV_FILE="키워드.csv" # 언어 결정 언어 = "ko" #도시를결정하다 국가 = "엔" #google 맞춤 검색 json API 키 API_KEY="여기에 키 입력" #검색엔진아이디 CSE_ #sqlite 데이터베이스 이름 DATABASE="키워드.db" # serp 결과를 저장할 테이블 이름 SERP_TABLE="keywords_serps" # 키워드에 대해 serp 실행 getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE) # 클러스터 결과가 저장될 테이블 이름. CLUSTER_TABLE="키워드_클러스터" #특정 타임스탬프에 대한 클러스터를 만들려면 타임스탬프를 입력하세요. #마지막 serp 결과를 클러스터로 만들어야 한다면 "max" 값으로 보내주세요 #TIMESTAMP="2021-02-18 17:18:05.195321" TIMESTAMP="최대" #네트워크 및 커뮤니티 알고리즘에 따라 키워드 클러스터 실행 getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)

Google SERP 결과 및 의미 발견
시맨틱 모델에 의존하지 않고 키워드를 시맨틱 클러스터로 그룹화하는 단축키가 있는 이 스크립트를 즐겼기를 바랍니다. 이러한 모델은 종종 복잡하고 비용이 많이 들기 때문에 의미론적 속성을 공유하는 키워드를 식별하는 다른 방법을 찾는 것이 중요합니다.
의미적으로 관련된 키워드를 함께 취급함으로써 주제를 더 잘 다루고, 사이트의 기사를 서로 더 잘 연결하고, 주어진 주제에 대한 웹사이트의 순위를 높일 수 있습니다.