
다중 모드 및 다국어 검색의 부상
게시 됨: 2022-01-06텍스트 쿼리를 넘어 검색을 확장하고 언어 장벽을 제거하는 것은 검색 엔진의 미래를 형성하는 최근 추세입니다. 새로운 AI 기반 기능을 통해 검색 엔진은 더 나은 검색 경험을 촉진하는 동시에 사용자가 특정 정보를 검색하는 데 도움이 되는 새로운 도구를 제공하려고 합니다. 이 기사에서 우리는 다중 모드 및 다중 언어 검색 시스템 의 떠오르는 주제를 다룰 것입니다. 또한 Wordlift에서 구축한 데모 검색 도구의 결과도 보여줍니다.
차세대 검색 엔진
좋은 사용자 경험은 사용자와 검색 엔진 간의 다양한 상호 작용 측면을 포함합니다. 사용자 인터페이스의 디자인과 사용성에서 검색 의도의 이해와 모호한 쿼리 해결에 이르기까지 대규모 검색 엔진은 차세대 검색 도구를 준비하고 있습니다.
다중 모드 검색
다중 모드 검색 엔진을 설명하는 한 가지 방법 은 단일 쿼리에서 텍스트와 이미지 를 처리할 수 있는 시스템에 대해 생각하는 것입니다. 이러한 검색 엔진은 사용자가 다중 모드 검색 인터페이스 를 통해 입력 쿼리를 표현할 수 있게 하고 결과적으로 보다 자연스럽고 직관적인 검색 경험을 가능하게 합니다.
전자 상거래 웹사이트에서 다중 모드 검색 엔진을 사용하면 색인화된 데이터베이스에서 관련 문서를 검색할 수 있습니다. 관련성은 텍스트, 이미지, 오디오 또는 비디오와 같은 둘 이상의 형식으로 제공된 쿼리에 대해 사용 가능한 제품의 유사성을 측정하여 평가됩니다. 결과적으로 이 검색 엔진은 기본 메커니즘이 다른 입력 모달, 즉 형식을 동시에 처리할 수 있기 때문에 다중 모드 시스템입니다.
예를 들어, 검색어는 "꽃무늬 드레스"의 형태를 취할 수 있습니다. 이 경우 웹 스토어에서 많은 꽃무늬 드레스를 구입할 수 있습니다. 그러나 검색 엔진은 다음 그림과 같이 사용자에게 실제로 만족스럽지 않은 드레스를 반환합니다.
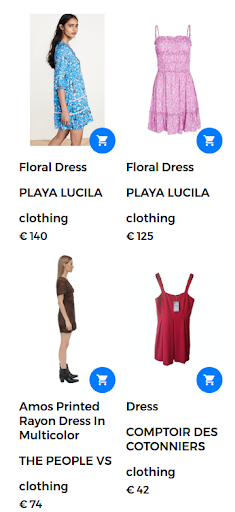
"꽃무늬 드레스"에 대한 검색 결과입니다.
좋은 검색 경험을 제공하고 관련성이 높은 결과를 반환하기 위해 다중 모드 검색 엔진은 단일 쿼리에서 텍스트와 이미지를 결합할 수 있습니다 . 이 경우 사용자는 원하는 상품의 샘플 이미지를 제공합니다. 이 검색을 다중 모드 검색으로 실행할 때 입력 이미지는 다음 이미지에 표시된 꽃무늬 드레스입니다.

다중 모드 쿼리에 대한 사용자 제공 이미지입니다.
이 시나리오에서 쿼리의 첫 번째 부분은 동일하게 유지되고(꽃무늬 드레스) 두 번째 부분은 다중 모드 쿼리에 시각적 측면을 추가합니다. 반환된 결과는 사용자가 제공한 꽃무늬 드레스와 유사한 드레스를 생성합니다. 이 사용 사례에서는 정확히 동일한 드레스를 사용할 수 있으므로 다른 유사한 드레스와 함께 반환되는 첫 번째 결과입니다.
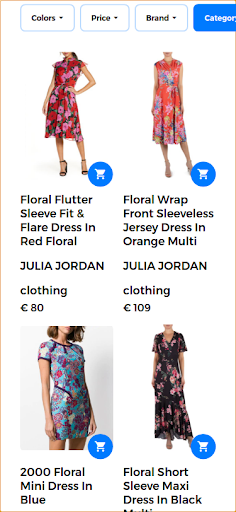
다중 모드 쿼리에 대한 응답으로 반환된 관련 검색 결과입니다.
침묵
Google은 복잡한 검색 작업을 지원하는 새로운 기술을 도입했습니다. MUM이라고 하는 이 새로운 기술은 Multitask Unified Model의 약자이며 언어 장벽을 허물고 웹 페이지 및 사진과 같은 다양한 콘텐츠 형식에서 정보를 해석 할 수 있습니다.
Google Lens 는 이미지와 텍스트를 단일 쿼리로 결합하는 이점을 활용한 최초의 제품 중 하나입니다. 검색 컨텍스트에서 MUM을 사용하면 사용자가 제공하는 이미지에서 특정 꽃 무늬와 같은 패턴을 쉽게 찾을 수 있습니다.
MUM은 다음과 같이 정보를 이해하기 위한 새로운 AI 이정표입니다.
"MUM을 탐색하는 초기 단계에 있지만 이는 Google이 사람들이 자연스럽게 정보를 전달하고 해석하는 다양한 방식을 모두 이해할 수 있는 미래를 향한 중요한 이정표입니다."
Google의 MUM 다중 모드 검색에 대해 자세히 알아보려면 다음 웹 스토리를 확인하세요. 
여러 언어로 검색 확장
이미지는 언어에 구애받지 않지만 검색어는 언어별로 다릅니다. 다국어 시스템을 설계하는 작업은 다양한 언어에 걸쳐 언어 모델을 구축하는 것으로 요약됩니다.
다국어 검색
현재 검색 시스템의 주요 제한 사항 중 하나는 사용자가 검색 쿼리를 작성한 언어로 작성되거나 주석이 달린 문서를 검색한다는 것입니다. 일반적으로 이러한 엔진은 영어 전용입니다. 이러한 단일 언어 검색 엔진은 다른 언어로 작성된 유용한 정보를 찾는 데 이러한 시스템의 유용성을 제한합니다.
반면에 다국어 시스템은 한 언어로 된 쿼리를 수락하고 다른 언어로 인덱싱된 문서를 검색합니다. 실제로 검색 시스템은 한 언어로 작성된 문서의 내용 또는 캡션을 다른 언어의 텍스트 쿼리와 일치시켜 데이터베이스에서 관련 문서를 검색할 수 있는 경우 다국어입니다. 일치 기술은 구문 메커니즘에서 의미 검색 접근 방식에 이르기까지 다양합니다.
다른 언어로 된 문장을 시각적 개념과 짝을 이루는 것은 교차 언어 비전 언어 모델의 사용을 촉진하기 위한 첫 번째 단계입니다. 좋은 소식은 시각적 개념이 모든 인간에 의해 거의 같은 방식으로 해석된다는 것입니다. 둘 이상의 소스와 하나 이상의 언어에 걸쳐 정보를 통합할 수 있는 이러한 시스템을 다중 모드 다국어 시스템 이라고 합니다. 그러나 다음 섹션에서 설명하는 것처럼 이미지-텍스트 쌍을 대규모로 모든 언어에 대해 항상 실현 가능한 것은 아닙니다.
[사례 연구] 온페이지 SEO로 새로운 시장에서 성장 주도
 사례 연구 읽기
사례 연구 읽기MUM에서 MURAL로
고급 딥 러닝 및 자연어 처리 기술을 검색 엔진에 적용하려는 노력이 증가하고 있습니다. 구글은 사용자가 이미지를 사용하여 단어를 표현할 수 있는 새로운 연구 작업을 선보였습니다. 예를 들어, "valiha"라는 단어는 튜브 치터로 만든 악기를 말하며 마다가스카르 사람들이 연주합니다. 이 단어는 대부분의 언어로 직접 번역되지 않지만 이미지를 사용하여 쉽게 설명할 수 있습니다.
MURA라고 하는 새로운 시스템은 Multimodal, Multi-task Retrieval Across Languages의 약자입니다. 목표 언어로 직접 번역되지 않을 수 있는 한 언어로 된 단어의 문제를 해결할 수 있습니다. 이러한 문제로 인해 사전 훈련된 많은 다국어 모델은 의미상 관련된 단어를 찾거나 리소스가 부족한 언어로 또는 그로부터 단어를 정확하게 번역하는 데 실패합니다. 실제로 MURAL은 많은 실제 문제를 해결할 수 있습니다.
- 다른 언어로 다른 정신적 의미를 전달하는 단어: 한 가지 예는 Google 블로그의 다음 이미지에서 볼 수 있듯이 영어와 힌디어로 된 "wedding"이라는 단어가 다른 정신적 이미지를 전달하는 것입니다.
- 웹에서 리소스가 부족한 언어에 대한 데이터 부족: 웹 에서 텍스트-이미지 쌍의 90%는 리소스가 많이 사용되는 상위 10개 언어에 속합니다.

이미지는 CC BY-SA 4.0 라이선스가 있는 Psoni2402(왼쪽)와 David McCandless(오른쪽)가 제공한 Wikipedia에서 가져왔습니다.

쿼리의 모호성을 줄이고 자원이 부족한 언어에 대한 이미지 텍스트 쌍의 희소성 문제에 대한 솔루션을 제공하는 것은 AI로 구동되는 차세대 검색 엔진에 대한 또 다른 개선 사항입니다.
다국어 및 다중 모드 검색 실행
이 작업에서 우리는 기존 도구와 사용 가능한 언어 및 비전 모델을 사용 하여 단일 언어를 넘어 한 번 에 하나 이상의 양식을 처리 할 수 있는 다중 모드 다국어 시스템을 설계합니다.
우선 다국어 시스템을 설계하기 위해서는 서로 다른 언어에서 온 단어를 의미적으로 연결하는 것이 중요합니다. 둘째, 시스템을 다중 모드로 만들기 위해서는 언어 표현을 이미지와 연관시키는 것이 필요합니다. 결과적으로 이것은 다중 모드 검색 다중 언어의 오랜 목표를 향한 큰 단계 입니다.
문맥
이 다중 모드 다국어 시스템의 주요 사용 사례는 이미지와 텍스트를 동시에 결합하는 쿼리가 주어지면 데이터 세트에서 관련 이미지를 반환하는 것입니다. 이러한 맥락에서 다양한 다중 모드 및 다중 언어 시나리오를 설명하는 몇 가지 예를 보여 드리겠습니다.
이 데모 앱의 백본은 오픈 소스 신경 검색 생태계인 Jina AI에 의해 구동됩니다. 심층 신경망 정보 검색(또는 신경 IR)으로 구동되는 신경 검색은 다중 모드 시스템을 구축하기 위한 매력적인 솔루션입니다. 이 데모에서는 Hugging Face의 MPNet Transformer 아키텍처, multilingual-mpnet-base-v2를 사용하여 텍스트 설명과 캡션을 처리합니다. 시각적인 부분은 MobileNetV2를 사용합니다.
다음에서는 다국어 및 다중 모드 검색 엔진의 성능을 보여주는 일련의 테스트를 제시합니다. 데모 도구의 결과를 발표하기 전에 다음은 이러한 테스트를 설명하는 주요 요소 목록입니다.
- 데이터베이스는 음악을 연주하는 사람들을 묘사하는 1k 이미지로 구성됩니다. 이 이미지는 공개 데이터 세트 Flickr30K에서 가져온 것입니다.
- 모든 이미지에는 영어로 작성된 캡션이 있습니다.
1단계: 영어로 된 텍스트 쿼리로 시작하기
먼저 대부분의 검색 엔진이 작동하는 현재 방식을 반영하는 텍스트 쿼리로 시작합니다. 검색어는 "음악가 그룹"입니다.
쿼리 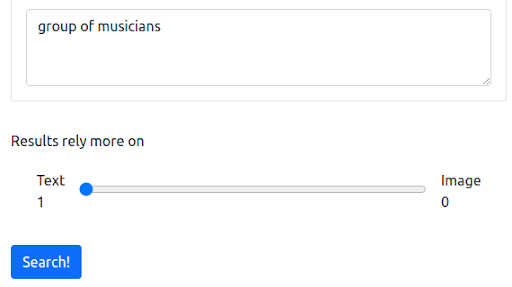
결과 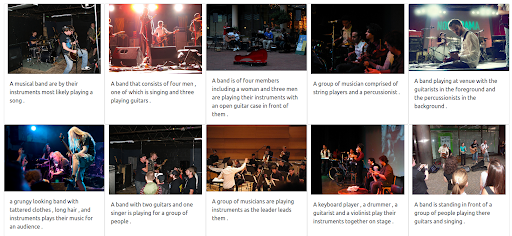
Jina 기반 데모 검색 엔진은 입력 쿼리와 의미적으로 관련된 음악가의 이미지를 반환합니다. 그러나 이것은 우리가 원하는 유형의 뮤지션이 아닐 수도 있습니다.
2단계: 다중 모드 추가
이제 이전 텍스트 쿼리와 이미지를 모두 결합하는 쿼리를 실행하여 다중 모드를 추가해 보겠습니다. 이 이미지는 우리가 찾고 있는 뮤지션을 보다 정확하게 표현한 것입니다.
우선 UI는 이러한 유형의 쿼리 실행을 지원해야 합니다. 그런 다음 결과를 검색할 때 각 양식의 중요성에 균형을 맞추기 위해 가중치를 할당해야 합니다. 이 경우 텍스트와 이미지의 가중치는 동일합니다(0.5). 아래에서 볼 수 있듯이 새 검색 결과에는 입력 이미지 쿼리와 시각적으로 유사한 여러 이미지가 포함됩니다.
쿼리 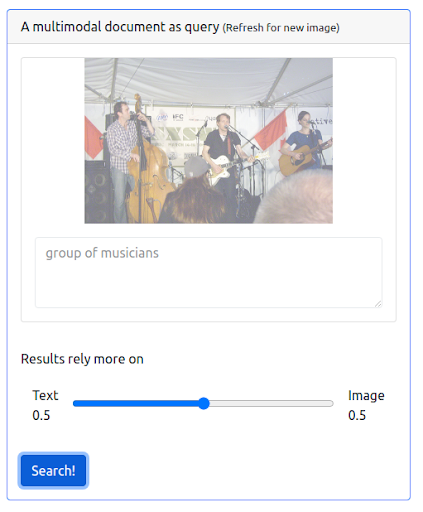
결과 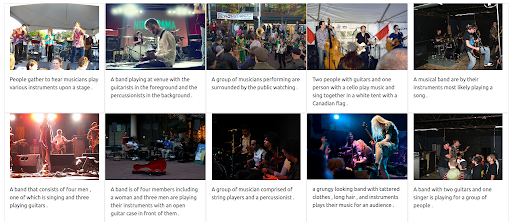
3단계: 이미지에 최대 가중치 할당
이미지에 최대 가중치를 부여하는 것도 가능합니다. 그렇게 하면 쿼리에서 입력 텍스트가 제외됩니다. 이 경우 입력 이미지와 시각적으로 유사한 이미지가 더 많이 반환되어 첫 번째 위치에 순위가 매겨집니다. 한 가지 명심해야 할 점은 결과가 데이터세트에서 사용 가능한 이미지로 제한된다는 것입니다.
쿼리 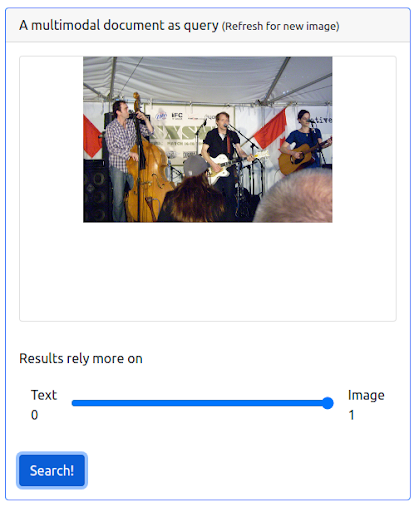
결과 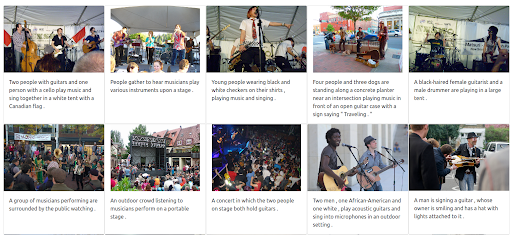
4단계: 다국어 검색 테스트
이제 동일한 쿼리를 실행하지만 다른 언어를 사용해 보겠습니다. 이 다국어 시스템의 모든 기능을 설명하기 위해 텍스트의 무게를 최대화했습니다. 이미지의 캡션은 영어로만 제공됩니다. 검색은 다음 언어를 포함하기 위해 반복됩니다.
- 프랑스어: Groupe de musiciens
- 이탈리아어: Gruppo di musicisti
- 독일어: Gruppe von Musikern
입력 쿼리의 언어에 관계없이 반환된 결과는 관련성이 있으며 세 가지 언어에서 일관됩니다. 결과는 아래와 같습니다.
프랑스어로 된 쿼리에 대한 결과 
이탈리아어로 된 쿼리에 대한 결과 
독일어로 된 쿼리에 대한 결과 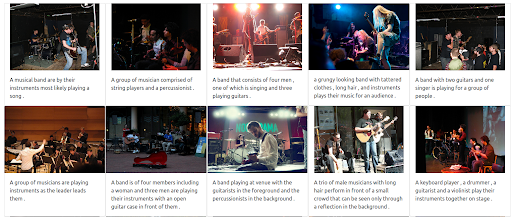
다중 모드 다국어 검색의 미래
앞으로 몇 년 동안 인공 지능은 검색을 점점 더 변화시키고 사람들이 쿼리를 표현하고 정보를 탐색하는 완전히 새로운 방법을 열어줄 것입니다. Google이 이미 발표한 것처럼 MUM으로 정보를 이해하는 것은 AI 이정표를 나타냅니다. 앞으로 더 많은 AI 기반 시스템에는 더 나은 검색 경험을 제공하는 것부터 정교한 질문에 대답하는 것, 언어 장벽을 허무는 것부터 다양한 검색 모드를 단일 쿼리로 결합하는 것까지 다양한 기능과 개선 사항이 포함될 것입니다.