
OnCrawl의 고급 세분화를 활용하는 방법
게시 됨: 2018-11-29우리 분야에서 당신이 할 수 있는 가장 중요한 일 중 하나는 SEO 데이터의 효율적이고 적절한 교차 분석을 성공적으로 실행하는 것입니다. 경험을 통해 데이터의 일부 교차점이 다른 교차점보다 더 강력하며 사용자 지정 세분화를 만들 때 특정 패턴이 나타난다는 것을 알게 될 것입니다.
"많은 데이터도 좋지만 데이터로 무엇을 해야 하는지 아는 것이 더 좋습니다!" SEOHacker 설립자 Paul Sanches
이 기사에서는 OnCrawl에서 사용할 수 있는 최고의 데이터 표현 모델과 교차 데이터 분석을 사용하여 가장 가치 있는 최적화를 찾는 방법을 공유하려고 합니다. 그러나 이 기사는 무엇보다도 OnCrawl의 각 차트가 서로 다른 관점에서 검토될 수 있고 또 검토되어야 함을 깨닫는 데 도움이 되는 수단입니다.
차트에 접근하면서 각 렌즈가 최적화를 나타내거나 가설을 확인/반증할 수 있는 방법과 다음과 같은 OnCrawl의 고급 기능을 사용하는 데 익숙하다면 도움이 된다는 것을 이해하게 될 것입니다.
- 측정항목 기반” 세분화
- 스크랩한 데이터를 사용하여 페이지 그룹을 만드는 사용자 정의 필드
- 사용자 정의 대시보드의 교차 세분화
이 기사의 모든 분할 예제는 JSON 파일로 다운로드할 수 있습니다. OnCrawl의 자체 데이터에 적용하려면 이 문서의 지침에 따라 새 세분화를 만드십시오. "기존 세트에서 가져오기 또는 가져오기"를 선택한 다음 "JSON 붙여넣기"를 선택해야 합니다.
참고: 향후 업데이트를 활용하려면 분할을 생성할 때 분할에 사용된 정확한 이름을 유지하는 것이 중요합니다.
14일 무료 평가판 시작
 평가판 시작
평가판 시작다양한 측정항목을 기반으로 한 세분화
좋은 세분화는 데이터 세트의 다른 값을 기반으로 페이지를 분류하기 위해 OnCrawl 필드의 관점을 사용할 수 있는 세분화입니다.
다섯 가지 간단한 예를 들어보겠습니다.
- 추천 스니펫 위치에서 주요 표현에 대한 페이지 순위는 무엇입니까?
세분화: oncrawl-segmentation-seo-voice-search.json
이름: SEO 음성 검색 - 가장 유기적인 방문을 생성하는 페이지는 무엇입니까?
세분화: oncrawl-segmentation-seo-top-visits-by-day.json
이름: 일별 SEO 방문수 - Google에 따르면 어떤 페이지가 가장 중요합니까?
세분화: oncrawl-segmentation-log-bot-hit-by-day.json
이름: 일별 LOG 봇 조회수 - 내 사이트에서 가장 많이 복제되는 페이지는 무엇입니까?
세분화: oncrawl-segmentation-seo-duplicate-rate.json
이름: SEO 중복 비율 - Google에서 가장 좋은 위치에 있는 페이지는 무엇입니까?
세분화: oncrawl-segmentation-gsc-positions.json
이름: GSC 포지션
OnCrawl 분석에서 사용할 수 있는 이러한 5가지 중요한 SEO 측면에 대한 표현의 시각적 모델이 있는 경우 가장 중요한 최적화 또는 가장 가치 있는 최적화를 신속하게 감지하고 다음을 기반으로 기술 프로젝트의 우선 순위를 지정할 수 있습니다. 견고하고 정량화된 데이터.
음, 이것이 바로 OnCrawl 세분화를 통해 수행할 수 있는 것입니다... 그리고 우리는 이 기능을 제공하는 유일한 것입니다!
위에서 언급한 5가지 사항에서 가져온 몇 가지 예:
1. 잠재적인 "추천 스니펫"에 순위가 매겨진 모든 페이지가 자연 방문을 받습니까?
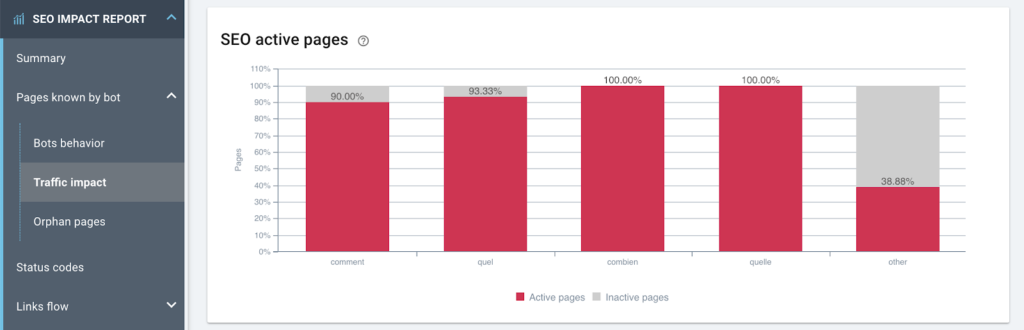
2. 가장 많이 방문한 페이지의 크롤링 빈도가 평균 이상입니까?
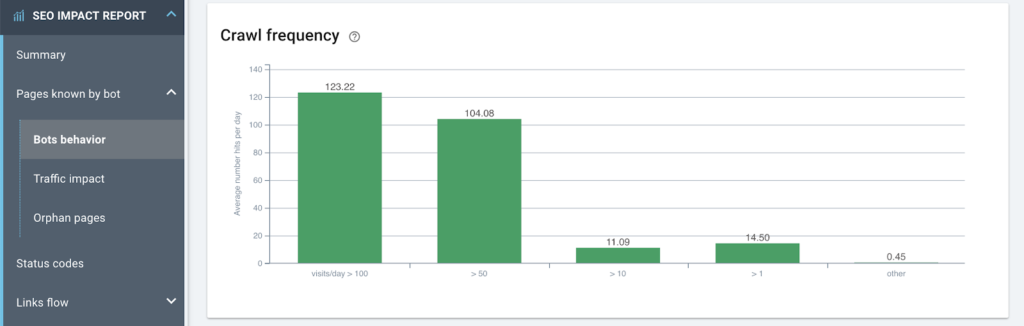
강한 상관관계가 있는 것 같다.
더 나은! 더 이상 내부 링크를 받지 않는 "많이 방문한" 페이지가 있습니까?
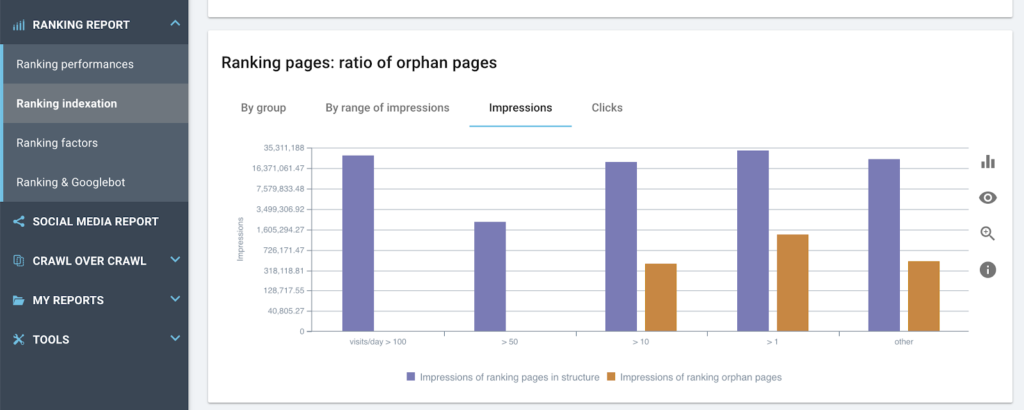
3. 클릭수에 있어서 홈페이지로부터의 거리와 구글의 크롤링 행위 사이에 상관관계가 있습니까?
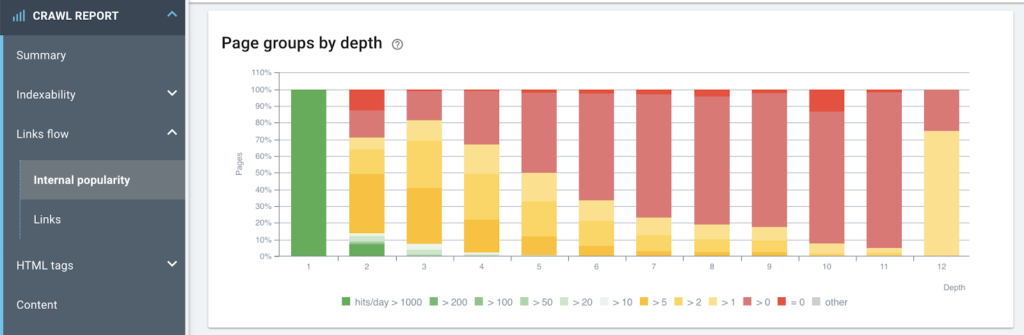
4. 중복 콘텐츠가 순위에 영향을 미칩니까?
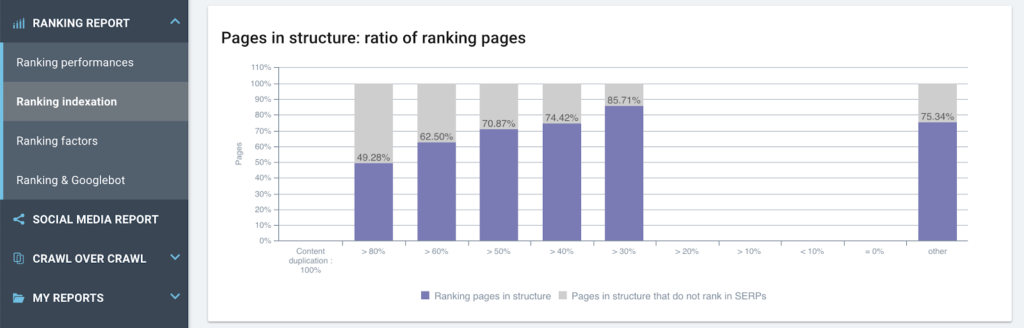
5. Google은 순위에 따라 페이지를 더 자주 크롤링합니까(순위에 크롤링 빈도가 순위와 연결되어 있음을 나타냄)?
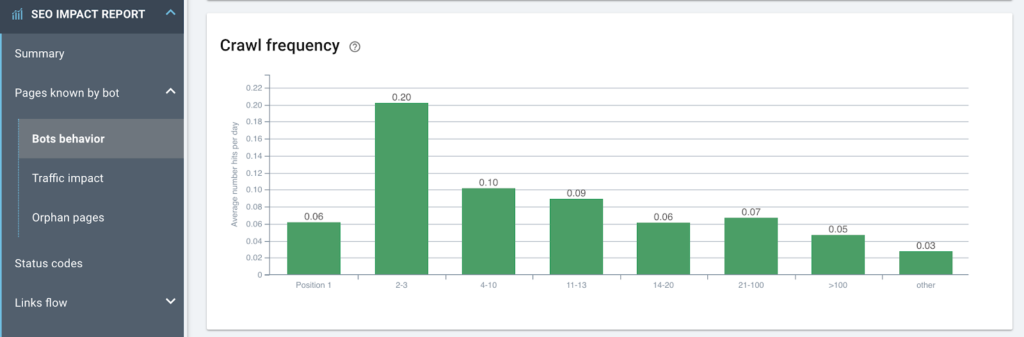
참고: 고객 성공 관리자로서 우리는 거의 모든 웹사이트에서 이 현상을 보고 있으며 이를 해석하는 방법은 다음과 같습니다.
– 오른쪽에서 왼쪽으로 위치가 향상되고 크롤링 빈도가 향상됩니다.
– SERP 1페이지의 다음 위치보다 3배 더 많은 봇 히트를 수신하는 위치 2-3까지.
– 그러나 위치 1(기간의 평균)에서 크롤링 빈도는 다른 모든 그룹보다 훨씬 적습니다.
페이지가 위치 1에 있을 때 Google이 확인하는 것은 이 페이지가 아닙니다. Google은 경쟁업체를 크롤링합니다(경쟁업체 사이트의 이 차트를 상상해 보세요. 시간의 90%가 동일합니다). 이는 2-3위의 경쟁 페이지를 의미합니다.
맞습니다. 특정 데이터에 대한 새로운 관점을 가지면 SEO 전략에 필수적인 교훈을 찾을 수 있습니다.
이제 여기에 몇 가지 깔끔한 세분화가 있습니다.
로드 시간
현재 로드 시간은 사용자의 관점과 Google 크롤러의 관점 모두에서 중요한 요소입니다. "로드 시간" 측정항목을 기반으로 한 세분화를 사용하면 페이지를 가장 빠른 것부터 가장 느린 것까지 분류하고 로드 시간이 사용자 행동에 미치는 영향을 모니터링할 수 있습니다(Google Analytics가 활성화된 경우 이 데이터를 CTR과 교차). 로그에서 봇을 인덱싱하는 동작과 GSC를 사용한 순위 지정 성능에 대해 설명합니다.
이 옵션 중 하나를 테스트하는 데 관심이 있다면 [email protected]으로 문의하십시오.
세분화: oncrawl-segmentation-seo-load-time.json
이름: SEO 로드 시간
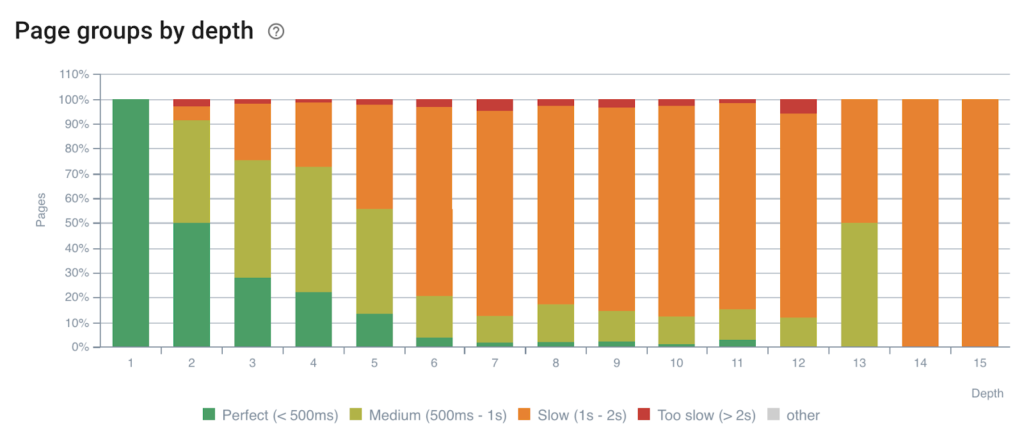
하중 시간에 대한 깊이의 영향
구조에서 페이지가 깊을수록 응답하는 데 더 오래 걸립니다.
참고: 경험에 따르면 페이지가 깊을수록 시스템 아키텍처의 요소가 데이터를 캐시하지 않는다는 것을 알고 있습니다. 데이터베이스에는 메모리에 대한 요청이 없으며 캐시 시스템은 해당 콘텐츠에 액세스할 수 없습니다. 이 페이지는 덜 자주 요청됩니다. 이것은 정상입니다!
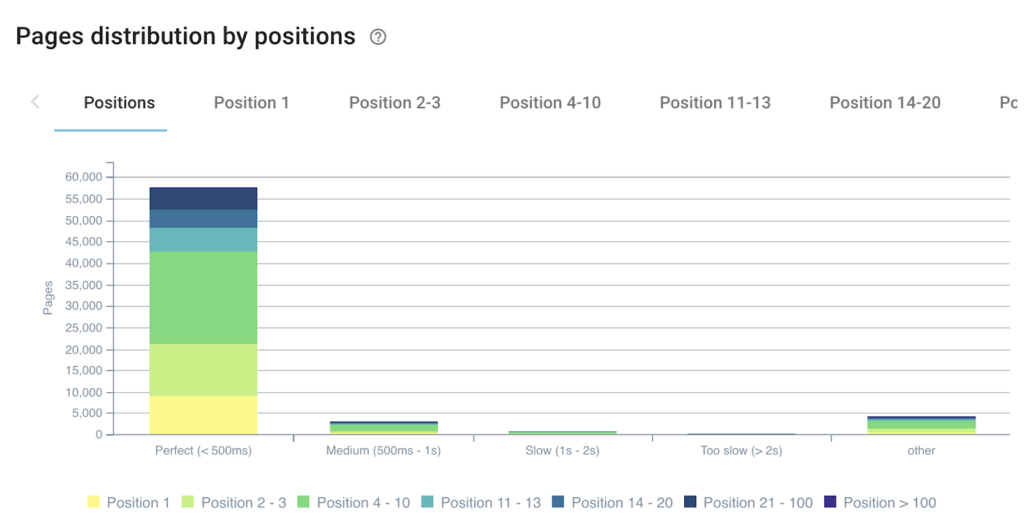
로드 시간이 순위 성능에 미치는 영향
빠르게 응답하는 페이지가 많을수록 해당 순위의 페이지가 더 많이 있습니다.
인덱싱 가능성
이 세분화를 통해 잘못된 버전의 페이지를 가리키는 내부 링크를 식별하거나 잘못된 그룹으로 전송된 Inrank(내부 인기도)를 확인하여 사이트 구조의 결함을 빠르게 식별할 수 있습니다.
세분화: oncrawlmentation-seo-indexability.json
이름: SEO indexability-seg
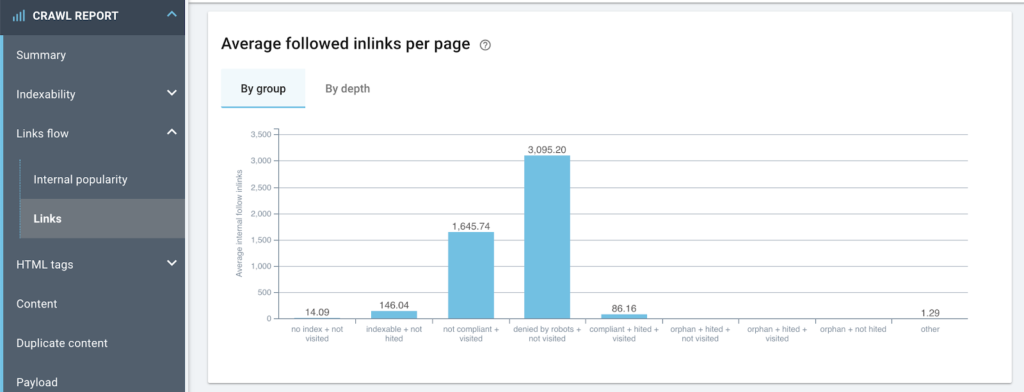
인덱싱 유형별 평균 인링크 수
robots.txt 및 비준수 페이지에서 거부하도록 설정된 그룹에 대한 많은 낭비 링크
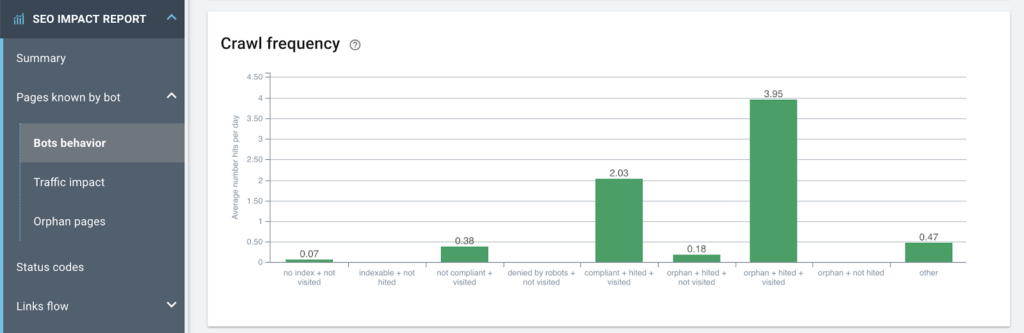

색인 생성 유형별 크롤링 빈도
많은 고아 페이지가 활성 상태이며 크롤링 예산의 가장 큰 소비자 중 하나입니다.
구글 서치 콘솔 세분화
OnCrawl에서 크롤링 데이터를 GSC의 데이터와 교차하면 페이지를 그룹화하는 데 사용할 수 있는 새 필드가 생성됩니다. 위치, CTR, 노출 및 클릭은 모두 세그먼트가 될 수 있습니다.
세분화: oncrawl-segmentation-seo-load-time.json
이름: GSC 노출수
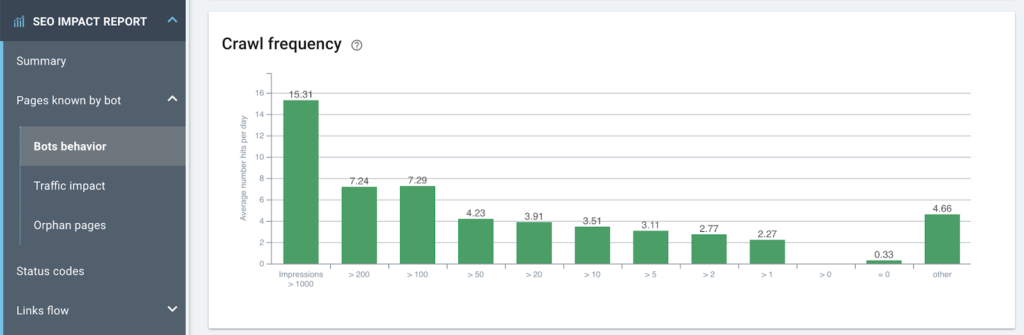
Google의 노출수당 크롤링 빈도 표시
데이터가 일관성이 있음을 확인했습니다(크롤링 예산 대 노출수).
세분화: oncrawl-segmentation-gsc-positions.json
이름: GSC 포지션
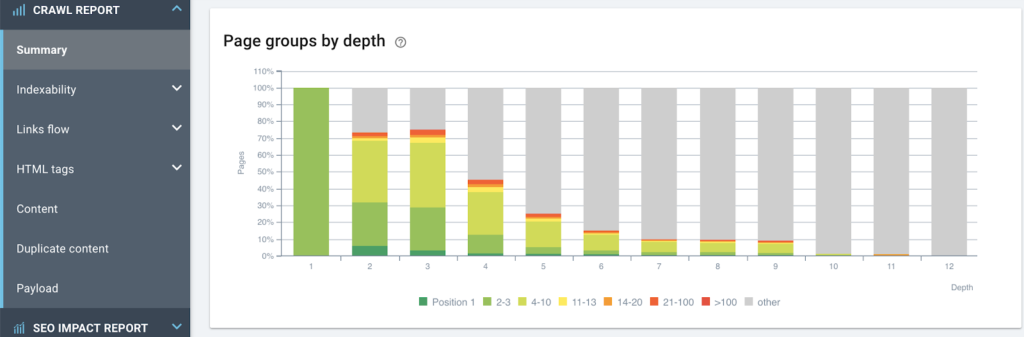
사이트 구조에 따른 랭킹 실적 조회
페이지가 깊을수록 순위가 낮아집니다.
세분화: oncrawl-segmentation-gsc-clicks.json
이름: GSC 클릭수
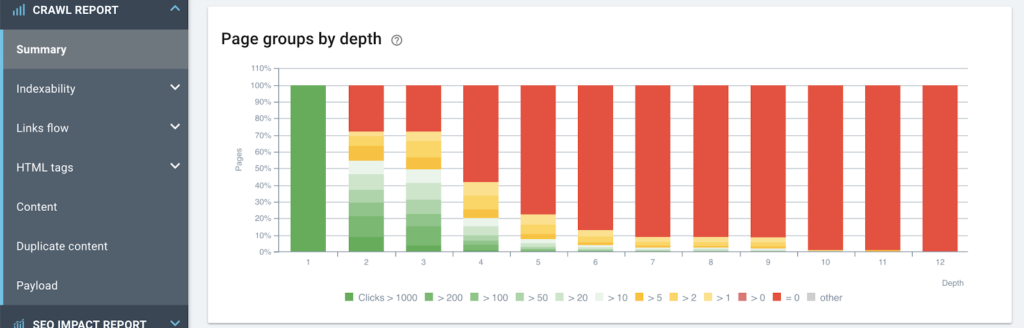
클릭 수(따라서 자연 방문)에 대한 깊이의 영향
구조에서 페이지가 높을수록 SEO 성능이 향상됩니다.
세분화: oncrawl-segmentation-gsc-ranking-pages.json
이름: GSC 순위 페이지
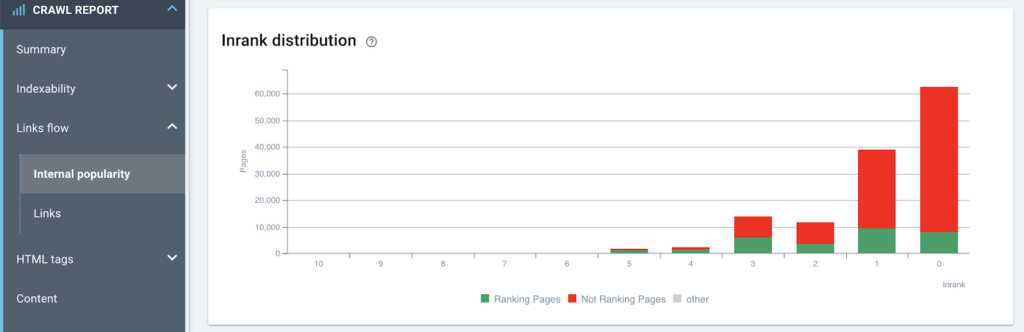
내부 인기가 인상(순위) 생성 능력에 미치는 영향
이 사이트의 내부 링크와 관련하여 취해야 할 몇 가지 조치가 분명히 있습니다.
세분화: oncrawl-segmentation-gsc-ctr.json
이름: GSC CTR
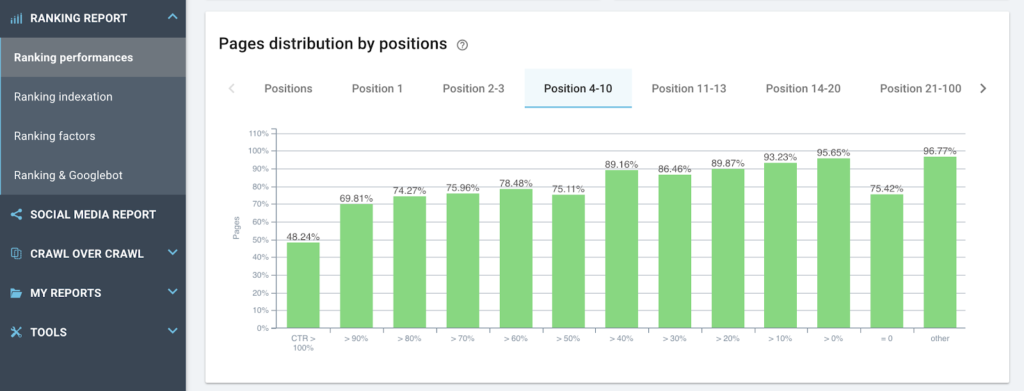
게재순위 4-10에 대한 페이지당 평균 CTR 그룹
이를 통해 페이지를 신속하게 타겟팅하여 먼저 최적화(최고의 CTR)하고 최상의 결과를 얻기 위한 작업의 우선 순위를 지정할 수 있습니다.
로그 기반 세분화
로그 데이터를 기반으로 하는 세분화를 통해 OnCrawl 차트 분석을 위한 명확한 표현을 생성할 수 있습니다. 유기적 방문 수(봇 유형별 – 모바일/데스크톱) 또는 일일 봇 적중 수(크롤링 예산)를 기준으로 페이지를 그룹화할 때 검색한 각 SEO 요소의 영향을 볼 수 있습니다. 무한 궤도.
세분화: oncrawl-segmentation-log-bot-hit-by-day.json
이름: 일별 LOG 봇 조회수
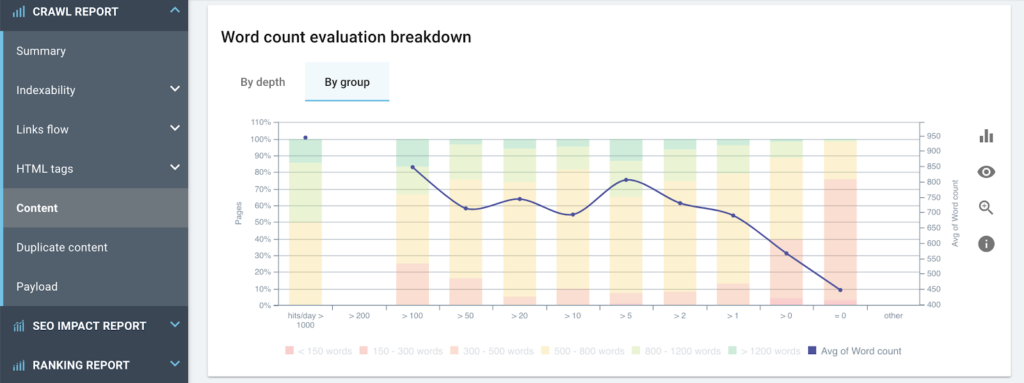
페이지당 평균 단어 수를 기준으로 Googlebot의 방문 빈도를 나타냅니다.
세분화: oncrawl-segmentation-log-seo-visits-by-day.json
이름: LOG SEO 일별 방문
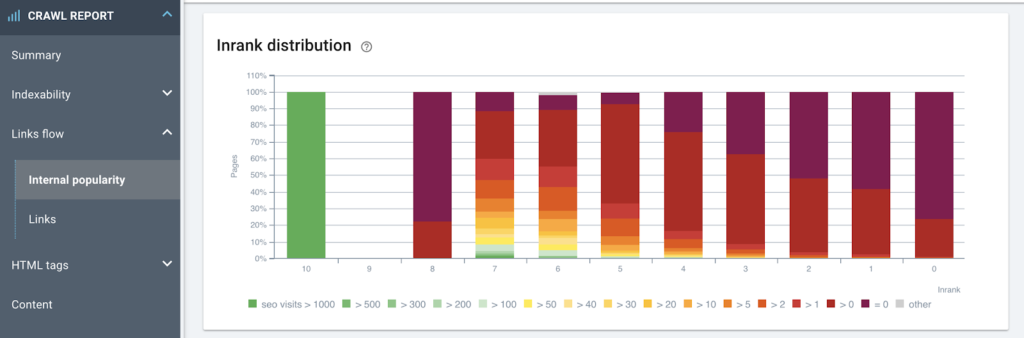
내부 인기도와 검색엔진 방문수와의 관계 분석
이것은 몇 가지 최적화를 제안합니다. 방문이 없는 가장 인기 있는 페이지는 더 느슨하게 연결되어야 합니다. / 특정 페이지에는 많은 방문이 있지만 인기가 낮을 수 있습니다. 그것들을 강화하면 좋은 최적화가 될 수 있습니다.
트래픽 획득 세분화
더 나아가 현재 관찰된 성능에 따라 페이지를 그룹화하도록 선택할 수 있습니다. 이를 통해 이미 가치가 있는 페이지 집합을 대상으로 하고 이러한 페이지에 도움이 될 수 있는 최적화(깊이, 순위, 콘텐츠, 복제, 로드 시간 등)가 있는지 빠르게 식별할 수 있습니다. 이미 잘 수행되고 있는 페이지 세트를 최적화하여 획득한 트래픽에 미치는 영향을 배가할 수 있습니다. 당신의 노력은 큰 결실을 맺습니다!
세분화: oncrawl-segmentation-seo-top-visits-by-day.json
이름: 일별 SEO 최고 방문수
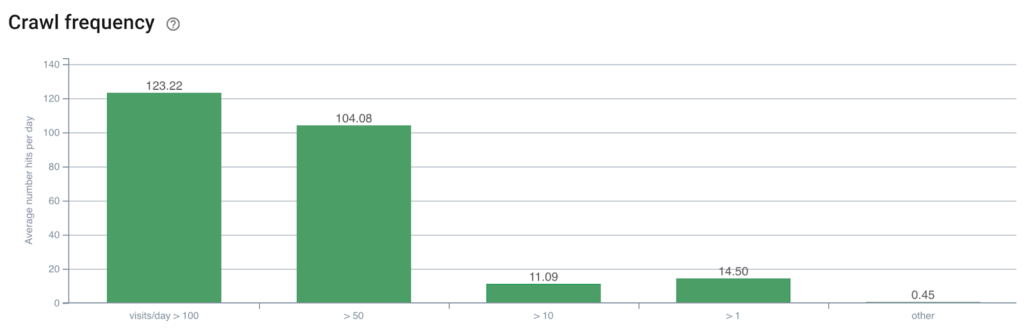
참고: 이 샘플 세분화는 로그 데이터를 사용하지만 Google Analytics 세션 또는 GSC 클릭과 함께 사용하도록 쉽게 조정할 수 있습니다.
스크랩 데이터를 기반으로 한 세분화
OnCrawl을 사용하면 소스 코드(XPATH 또는 REGEX)에서 규칙 기반 추출로 개인화된 필드를 만들 수 있습니다. 이러한 새 필드를 사용하여 대표적인 페이지 집합을 만들 수 있습니다. 페이지 유형, 데이터 영역 또는 발행 날짜를 새 세분화에 사용할 수 있습니다.
세분화: oncrawl-segmentation-date-published.json
이름: 발행일
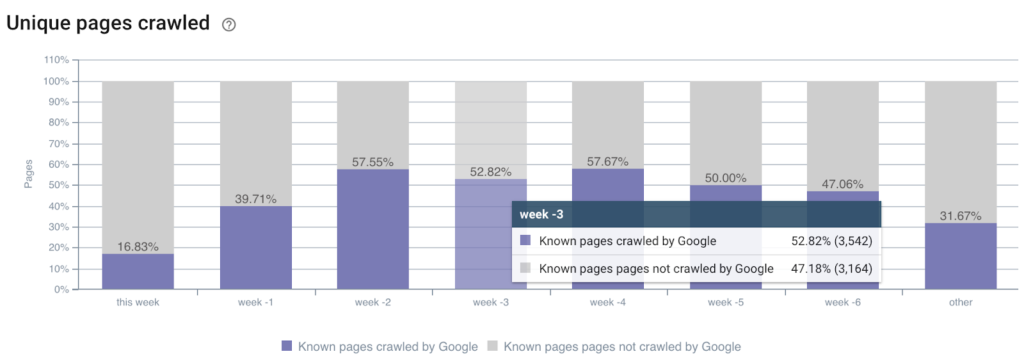
발행일 기준 페이지 크롤링 속도
참고: 추출된 필드의 이름은 publicationDate로 지정해야 하고 각 크롤링과 함께 자동으로 업데이트되는 이 슬라이딩 세분화를 허용하는 "날짜" 유형 필드여야 합니다.
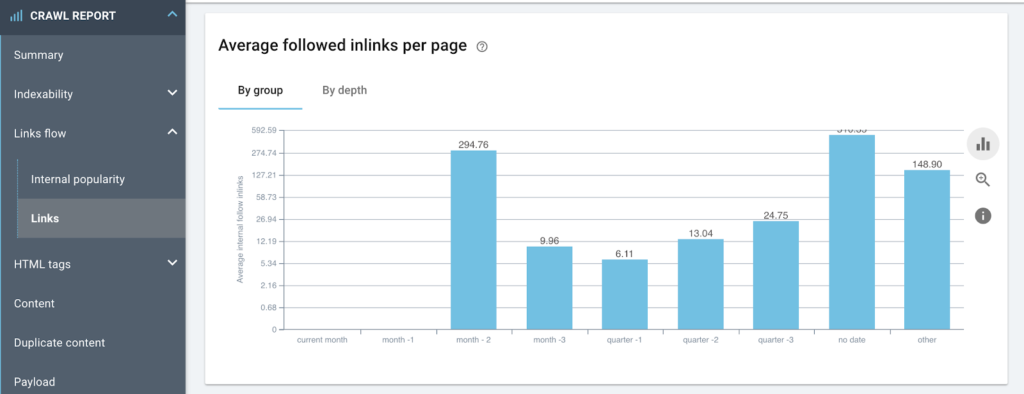
발행일을 기준으로 페이지에 대한 평균 인링크 수를 나타냅니다.
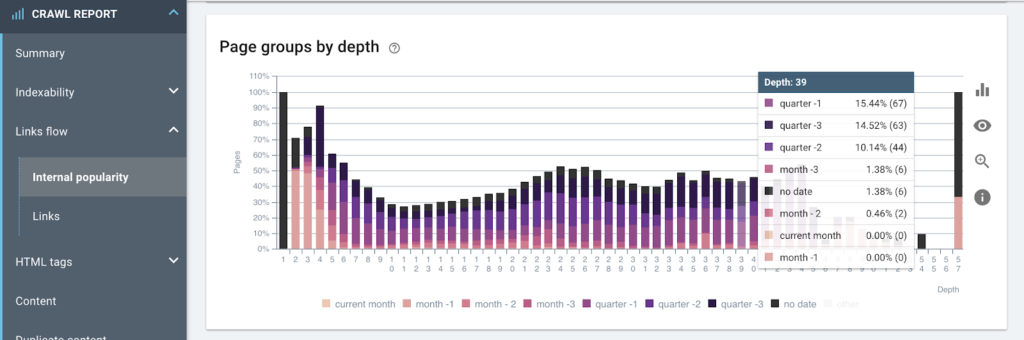
게시 날짜를 기반으로 한 사이트 구조의 형식 지정
페이지 유형(데이터 영역에서 가져온 데이터) 기반 세분화
크롤링 설정(이 주제에 대한 기사)에서 스크래핑 규칙이 설정되면 팀에서 처리하는 데 익숙한 데이터 유형과 정확히 일치하는 새 필드를 얻게 됩니다. DataLayer가 설정되면 귀하와 함께 일하는 다른 모든 전문가가 이를 사용하며 공통 표준을 기반으로 보고서를 제공하면 공유 목표를 향해 함께 작업하는 데 도움이 됩니다.
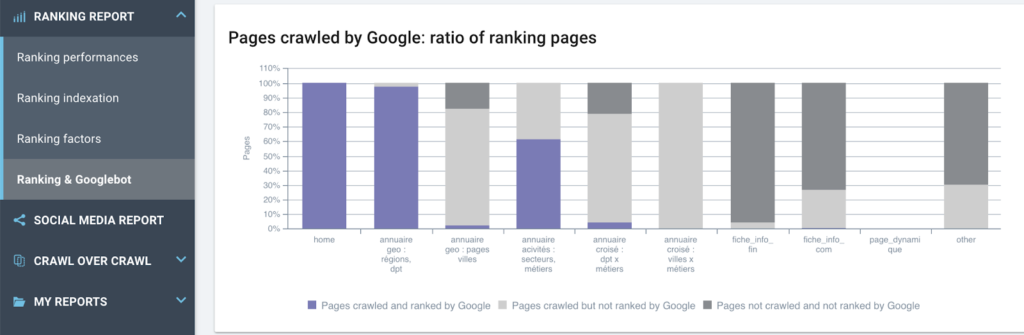
데이터 영역에 정의된 각 페이지 유형에 대해 Google에서 크롤링하거나 크롤링하지 않은 순위 페이지의 비율 연구
교차 세분화
단독으로 이러한 세분화는 거시적 관점에서 최적화 또는 장애물을 발견하도록 안내할 수 있지만 OnCrawl을 사용하면 고유한 방식으로 이러한 세분화를 사용할 수도 있습니다. 다양한 표현 모드를 다시 세분화 하여 분석 범위를 좁힐 수 있습니다. 사용자 정의 대시보드에서 고정 세분화로 설정된 차트와 필터를 결합하여
사용자 정의 대시보드 기능(youtube 비디오/기사)에 이미 익숙하다면 차트에서 특정 세분화를 강제로 사용할 수 있다는 사실을 알고 계실 것입니다. 사용자 정의 대시보드 생성. 이를 통해 글로벌 세분화(페이지 상단의 메뉴에서 설정한 세분화)를 유지하고 다른 세분화에서 가져온 표현으로 차트의 데이터를 볼 수 있습니다.
예를 들어:
"상위 대상" 분류의 페이지 그룹 내 Inrank의 정확한 분포를 알고 싶고 차트의 "GSC 노출수" 보기를 사용하여 특정 국가에 대한 해당 데이터를 표시하고 싶습니다.
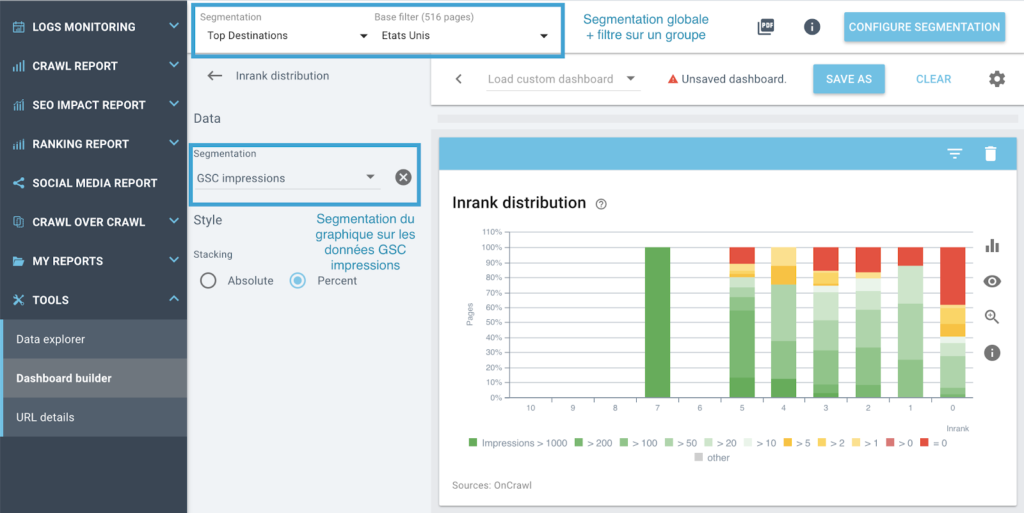
교차 분할의 그림: 동일한 차트에서 두 개의 분할 사용
결론
URL 경로를 기반으로 하는 지나치게 제한적인 세분화에서 한 발 물러나면 매우 다양하고 훨씬 더 정확한 각도에서 사이트 데이터를 탐색할 수 있습니다. OnCrawl은 현재 이러한 방식으로 사용 가능한 모든 데이터의 형식을 지정할 수 있는 유일한 도구입니다.
약간의 경험과 호기심으로 데이터를 보다 효율적으로 전달할 수 있으며 우선 순위를 지정하기 쉬운 관련 SEO 개선을 위한 새로운 경로를 찾는 것을 피할 수 없습니다.
OnCrawl의 세분화 생성 및 탐색의 유일한 한계는 자신의 창의성의 한계입니다. 공은 지금 당신의 코트에 있습니다!
그리고 잊지 마세요. 모든 OnCrawl 팀이 귀하의 프로젝트를 돕기 위해 여기 있습니다.