
웹 크롤러 소개
게시 됨: 2016-03-08내가 하는 일과 SEO가 무엇인지에 대해 사람들과 이야기할 때, 그들은 보통 상당히 빨리 이해하거나 하는 대로 행동합니다. 좋은 웹사이트 구조, 좋은 콘텐츠, 좋은 백링크를 보증합니다. 그러나 때로는 좀 더 기술적으로 발전하여 결국 귀하의 웹사이트를 크롤링하는 검색 엔진에 대해 이야기하게 되며 일반적으로 잃어버리게 됩니다...
웹사이트를 크롤링하는 이유는 무엇입니까?
웹 크롤링은 인터넷을 매핑하고 각 웹 사이트가 서로 연결되는 방식으로 시작되었습니다. 또한 새로운 온라인 페이지를 발견하고 색인을 생성하기 위해 검색 엔진에서 사용되었습니다. 웹 크롤러는 웹사이트를 테스트하고 문제가 발견되었는지 분석하여 웹사이트의 취약성을 테스트하는 데에도 사용되었습니다.
이제 통찰력을 제공하기 위해 웹사이트를 크롤링하는 도구를 찾을 수 있습니다. 예를 들어 OnCrawl은 콘텐츠 및 페이지를 가리키는 모든 링크에 대한 통찰력을 제공하는 사이트 SEO 또는 Majestic에 관한 데이터를 제공합니다.
크롤러는 문서를 분류하고 수집된 데이터에 대한 통찰력을 제공하는 데 사용 및 처리될 수 있는 정보를 수집하는 데 사용됩니다.
크롤러 빌드는 약간의 코드를 아는 사람이라면 누구나 액세스할 수 있습니다. 그러나 효율적인 크롤러를 만드는 것은 더 어렵고 시간이 걸립니다.
어떻게 작동합니까?
웹사이트나 웹을 크롤링하려면 먼저 진입점이 필요합니다. 로봇은 웹사이트가 존재한다는 것을 알아야 방문하여 볼 수 있습니다. 예전에는 웹사이트가 온라인 상태임을 알리기 위해 검색 엔진에 웹사이트를 제출했을 것입니다. 이제 귀하의 웹사이트에 대한 몇 가지 링크를 쉽게 구축할 수 있습니다.
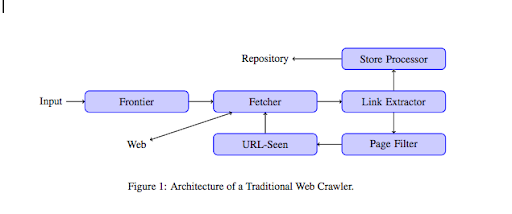
크롤러가 웹사이트에 도착하면 모든 콘텐츠를 한 줄씩 분석하고 내부 또는 외부 링크를 따라갑니다. 그리고 더 이상 링크가 없는 페이지에 도달하거나 404, 403, 500, 503과 같은 오류가 발생할 때까지 계속됩니다.
보다 기술적인 관점에서 크롤러는 URL의 시드(또는 목록)와 함께 작동합니다. 이것은 페이지의 콘텐츠를 검색할 Fetcher로 전달됩니다. 그런 다음 이 콘텐츠는 HTML을 구문 분석하고 모든 링크를 추출하는 링크 추출기로 이동됩니다. 이러한 링크는 이름에서 알 수 있듯 저장 프로세서 둘 다에 전송됩니다. 이러한 URL은 페이지 필터를 통과하여 모든 흥미로운 링크를 URL에서 본 모듈로 보냅니다. 이 모듈은 URL이 이미 표시되었는지 여부를 감지합니다. 그렇지 않은 경우 페이지 등의 콘텐츠를 검색하는 Fetcher로 전송됩니다.
Flash와 같은 일부 콘텐츠는 스파이더가 크롤링할 수 없습니다. Javascript는 이제 GoogleBot에 의해 제대로 크롤링되지만 때때로 크롤링되지 않습니다. 이미지는 Google이 기술적으로 크롤링할 수 있는 콘텐츠가 아니지만 이미지를 이해하기 시작할 만큼 똑똑해졌습니다!
로봇이 반대로 말하지 않으면 모든 것을 기어갈 것입니다. 이때 robots.txt 파일이 매우 유용합니다. 크롤러에게 크롤링할 수 없는 페이지를 알려줍니다(GoogleBot 또는 MSN Bot과 같이 크롤러별로 다를 수 있습니다. 여기에서 봇에 대해 자세히 알아보세요). 예를 들어 패싯을 사용하는 탐색이 있고 부가가치가 거의 없고 크롤링 예산을 사용하기 때문에 로봇이 모든 패싯을 크롤링하는 것을 원하지 않을 수 있습니다. 이 간단한 줄을 사용하면 로봇이 크롤링하는 것을 방지할 수 있습니다.
사용자 에이전트: *
허용하지 않음: /folder-a/
이것은 모든 로봇이 폴더 A를 크롤링하지 않도록 지시합니다.
사용자 에이전트: GoogleBot
허용하지 않음: /레퍼토리-b/
반면에 이것은 Google Bot만 폴더 B를 크롤링할 수 없도록 지정합니다.
rel=”nofollow” 태그를 사용하여 로봇이 특정 링크를 따르지 않도록 지시하는 HTML의 표시를 사용할 수도 있습니다. 일부 테스트에서는 링크에 rel=”nofollow” 태그를 사용해도 Googlebot이 링크를 팔로우하는 것을 차단하지 않는 것으로 나타났습니다. 이것은 목적과 모순되지만 다른 경우에 유용합니다.
[사례 연구] Googlebot의 웹사이트 크롤링 기능을 개선하여 가시성 향상
 사례 연구 읽기
사례 연구 읽기
크롤링 예산을 언급했지만 무엇입니까?
검색 엔진에 의해 발견된 웹사이트가 있다고 가정해 보겠습니다. 그들은 정기적으로 웹 사이트를 업데이트하고 새 페이지를 만들었는지 확인합니다.
각 웹사이트에는 웹사이트의 페이지 수 및 정상 상태(예: 오류가 많은 경우)와 같은 여러 요인에 따라 자체 크롤링 예산이 있습니다. Search Console에 로그인하면 크롤링 예산을 빠르게 파악할 수 있습니다.
크롤링 예산은 로봇이 방문할 때마다 웹사이트에서 크롤링하는 페이지 수를 고정합니다. 웹사이트에 있는 페이지 수에 비례하여 연결되며 이미 크롤링되었습니다. 일부 페이지는 특히 정기적으로 업데이트되거나 중요한 페이지에서 링크된 경우 다른 페이지보다 더 자주 크롤링됩니다.
예를 들어 집은 매우 자주 크롤링되는 주요 진입점입니다. 블로그 또는 카테고리 페이지가 있는 경우 기본 탐색에 연결되어 있으면 자주 크롤링됩니다. 블로그는 정기적으로 업데이트되므로 자주 크롤링됩니다. 블로그 게시물은 처음 게시될 때 자주 크롤링될 수 있지만 몇 달 후에는 업데이트되지 않을 수 있습니다.
페이지가 크롤링되는 빈도가 높을수록 로봇은 다른 페이지에 비해 중요하다고 생각합니다. 크롤링 예산 최적화 작업을 시작해야 할 때입니다.
크롤링 예산 최적화
예산을 최적화하고 가장 중요한 페이지가 주목을 받을 수 있도록 하려면 서버 로그를 분석하고 웹사이트가 어떻게 크롤링되는지 확인할 수 있습니다.
- 귀하의 상위 페이지가 크롤링되는 빈도
- 덜 중요한 페이지가 더 중요한 다른 페이지보다 더 많이 크롤링되는 것을 볼 수 있습니까?
- 로봇이 웹사이트를 크롤링할 때 종종 4xx 또는 5xx 오류가 발생합니까?
- 로봇이 거미 함정을 만나나요? (Matthew Henry는 그들에 대한 훌륭한 기사를 썼습니다)
로그를 분석하면 덜 중요하다고 생각하는 페이지가 많이 크롤링되고 있음을 알 수 있습니다. 그런 다음 내부 링크 구조를 더 깊이 파고들 필요가 있습니다. 크롤링 중인 경우 이를 가리키는 많은 링크가 있어야 합니다.
OnCrawl을 사용하여 이러한 모든 오류(4xx 및 5xx)를 수정하는 작업도 할 수 있습니다. 크롤링 가능성과 사용자 경험을 개선할 수 있으며 이는 윈-윈 사례입니다.
크롤링 대 스크래핑 ?
크롤링과 긁는 것은 다른 목적으로 사용되는 두 가지 다른 것입니다. 웹사이트 크롤링은 페이지에 방문하여 콘텐츠를 스캔할 때 찾은 링크를 따라가는 것입니다. 그런 다음 크롤러는 다른 페이지 등으로 이동합니다.
반면에 스크래핑은 페이지를 스캔하고 페이지에서 제목 태그, 메타 설명, h1 태그 또는 가격 목록과 같은 웹사이트의 특정 영역과 같은 특정 데이터를 수집하는 것입니다. 스크레이퍼는 일반적으로 "인간"으로 행동하며, robots.txt 파일의 모든 규칙을 무시하고, 양식에 파일을 작성하고, 감지되지 않도록 브라우저 사용자 에이전트를 사용합니다.
검색 엔진 크롤러는 일반적으로 스크레이퍼 역할을 하며 순위 알고리즘을 위해 데이터를 처리하기 위해 데이터를 수집해야 합니다. 그들은 스크래퍼와 비교하여 특정 데이터를 찾지 않고 페이지에서 사용 가능한 모든 데이터를 사용하며 그 이상을 사용합니다(로딩 시간은 페이지에서 얻을 수 없는 것입니다). 검색 엔진 크롤러는 항상 자신을 크롤러로 식별하여 웹사이트 소유자가 웹사이트를 마지막으로 방문한 시간을 알 수 있습니다. 이는 실제 사용자 활동을 추적할 때 매우 유용할 수 있습니다.
이제 크롤링, 작동 방식 및 중요한 이유에 대해 조금 더 알게 되었으며 다음 단계는 서버 로그 분석을 시작하는 것입니다. 이를 통해 로봇이 웹사이트와 상호 작용하는 방식, 로봇이 자주 방문하는 페이지, 웹사이트를 방문하는 동안 발생하는 오류 수에 대한 깊은 통찰력을 얻을 수 있습니다.
웹 크롤러에 대한 자세한 기술 및 역사적 정보는 "웹 크롤러의 간략한 역사"를 참조하십시오.