
주제 권위의 중요성: 시맨틱 SEO 사례 연구
게시 됨: 2021-02-11Topical Authority와 Semantic SEO는 앞으로 구조화된 검색 엔진의 개념으로 더 자주 논의될 것입니다. 이 기사에서는 이러한 기술을 사용하여 단 5개월 만에 Interingilizce.com에서 월간 유기적 트래픽을 10,000에서 200,000 이상으로 늘리는 방법을 설명합니다.
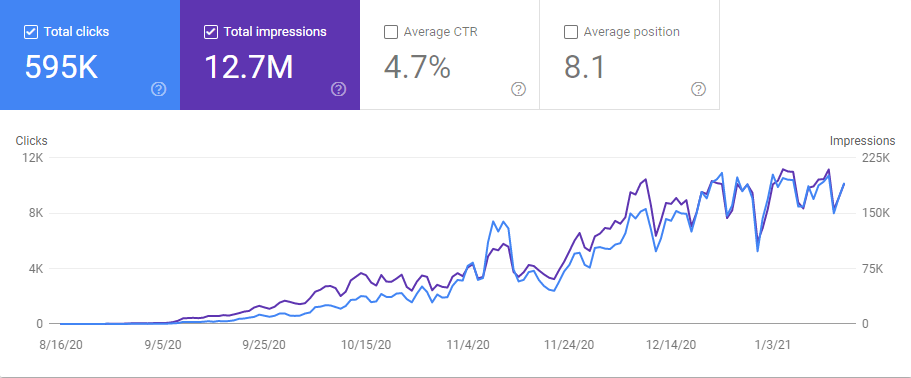
지난 5개월. GetWordly.com의 그래픽. 프로젝트는 6개월 전에 시작되었습니다.
이 SEO 사례 연구를 읽을 때 일부 항목은 약간 특별하기 때문에 이상하게 보일 수 있습니다. 따라서 우리는 시맨틱 SEO의 익숙하지 않은 개념을 강조할 필요가 있습니다.
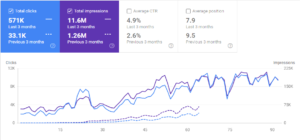
GetWordly.com의 GSC 유기적 트래픽 성능 보고서의 지난 3개월과 처음 3개월 비교.
Semantic SEO 사례 연구 및 프로젝트의 배경
이 SEO 사례 연구 동안 다음 방법 중 어느 것도 사용하지 않았으며 아래의 모든 중요한 눈에 보이는 SEO 요소는 프로젝트에서 의도적으로 제외되었습니다.
- 페이지 속도 최적화
- 브랜드 파워 및 브랜딩
- 테크니컬 SEO (맞아요: 안썼어요.)
- 고품질 웹 페이지 레이아웃 및 디자인
- 건강한 서버
- 온페이지 SEO
요약하면, 우리가 일반적으로 말하는 것은 일반적인 SEO 사례 연구에서 좋은 모범 사례입니다. 이 웹사이트에서는 수행되지 않았습니다. 그러므로 내가 이룬 성공이 우연이라고 생각할 수도 있습니다. 그러나 당신은 틀릴 것입니다. 동일한 방법론 으로 지난 5개월 동안 4개의 개별 SEO 사례 연구와 성공 사례를 만들었습니다.
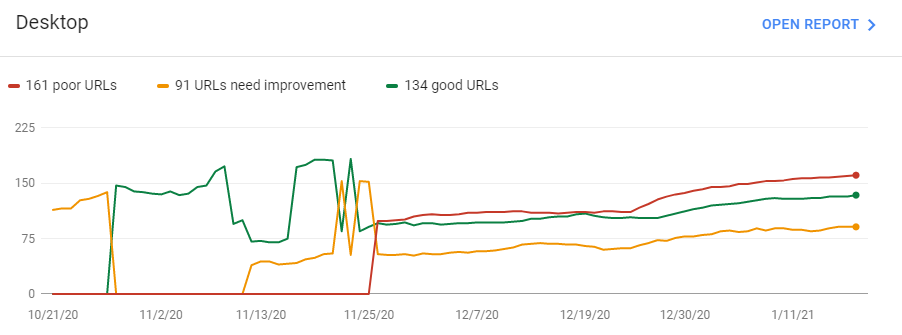
예를 들어 "데스크톱에 가난한 URL이 많이 있습니다."
이 기사는 내 방법론에 대한 요약이자 의미론적 SEO 및 자유로운 분석적 사고를 통한 SEO 이론의 진정한 가치에 대한 선언문입니다.
이것은 다음과 같은 관련 주제와 경험을 다루지 않기로 결정했음을 의미합니다.
- 사소한 Google 업데이트
- 하루 만에 모든 추천 스니펫을 잃어버린 이유
- 과도한 트래픽으로 인해 서버가 무너진 방법
- 검색 엔진 알고리즘에 대한 서버 오류의 영향.
이를 염두에 두고 방법론을 제시하겠습니다.
4가지 다른 SEO 프로젝트, 동일한 방법론 및 Semantic SEO를 통한 동일한 성공
이 기사에서는 간단한 의미론적 SEO 요약과 함께 Interingilizce.com에 초점을 맞출 것입니다. 그러나 가질 수 있는 질문을 줄이고 "SEO 이론 및 Google 특허" 가 구체적이고 실행 가능한 가치를 갖는다는 것을 보장하기 위해(Bill Slawski 덕분에) 4개의 서로 다른 SEO 프로젝트의 여정을 결과로만 요약하고 싶습니다.
이러한 SEO 사례 연구 및 프로젝트에 대한 모든 무거운 SEO 용어, 이론, 특허 및 실용적인 세부 정보를 읽고 싶다면 내 SEO에 대한 주제 권한, 적용 범위 및 컨텍스트 계층 구조를 읽는 것이 좋습니다. (길고 14,000단어 이상입니다.)
“우리는 새로운 프로젝트에서 빠른 효과로 단기간에 성공하는 것을 목표로 했습니다. 그리고 우리는 새로운 프로젝트에서 목표를 초과 달성했습니다.”
루스템 에르소일레옌
마케팅 책임자, KonusarakOgren
첫 번째 프로젝트: 5개월 만에 1100% 유기적 트래픽 증가, Interingilizce.com
Interingilizce.com은 실제로 2년이 되었지만 웹사이트에 콘텐츠도 없고 유기적인 트래픽도 없었습니다. 조직을 늘렸습니다. 145일 동안 트래픽이 1100% 증가했습니다. 10,000에서 200,000 클릭까지. 소개 섹션에서 "지난 6개월간의 유기적 트래픽" 결과를 이미 보았으므로 아래에서 "2020년 5월"과 "2020년 11월" 비교를 볼 수 있습니다.
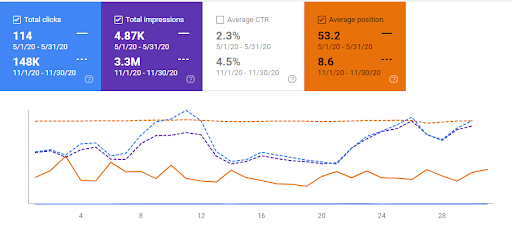
저는 실제로 이것이 1100% 유기적 트래픽 증가보다 훨씬 더 많다는 것을 압니다. 그러나 나는 당신이 충분히 구체적인 것을 상상하게 만들기 위해 이런 종류의 증가에 대해 "%" 기호를 사용할 수 없습니다.
아래에서 유기적 트래픽에 대한 Interingilizce.com의 지난 3개월 비교 그래픽을 볼 수 있습니다.
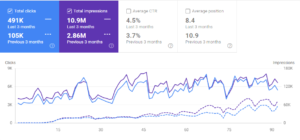
Interingilizce.com에 대한 지난 6개월간의 유기적 트래픽 그래픽.
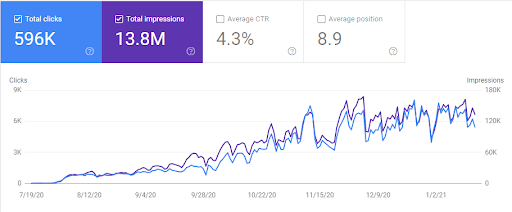
GetWordly.com의 GSC 보고서와 혼동할 수 있지만 서로 다릅니다. 동일한 방법론을 사용하기 때문에 Google 알고리즘 및 업데이트에 대해 동일한 반사신경을 가지고 있습니다.
두 번째 프로젝트: 0에서 330,000 월간 유기적 트래픽 및 10,000+ 일일 클릭: GetWordly.com
GetWordly.com은 두 번째 사이트이며, 웹사이트는 유기적 가시성과 역사 면에서 순수했습니다. GetWordly.com에서 저는 단 6개월 만에 하루에 11,000개의 자연 클릭과 월 330,000개의 자연 클릭 수준에 도달했습니다.
아래에서 Google Search Console에서 GetWordly.com의 지난 6개월간 유기적 트래픽 그래픽을 볼 수 있습니다.
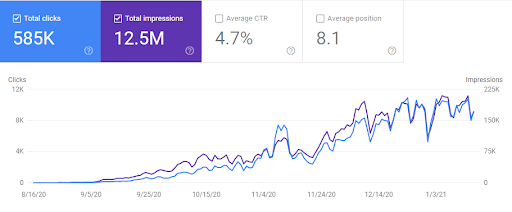
아래에서 GetWordly.com의 Ahrefs 그래픽을 볼 수 있습니다.
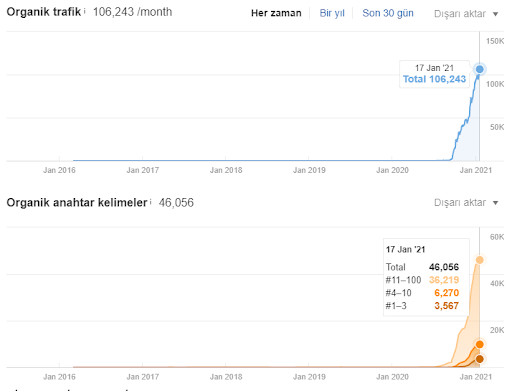
그리고 아래에 GetWordly.com용 SEMRush 그래픽이 표시됩니다.
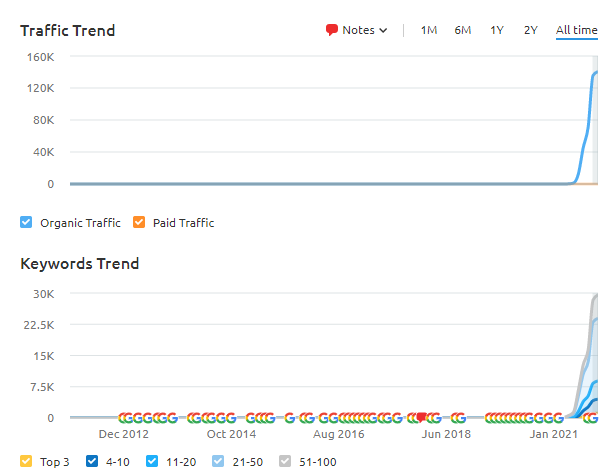
세 번째 프로젝트: 5개월 만에 600% 유기적 트래픽 증가: 아제르바이잔을 중심으로
세 번째 웹사이트(이름은 아직 공개되지 않음)는 600% 성장을 달성했습니다. 5개월 이내에 월간 유기적 트래픽이 10,000에서 70,000으로 증가했습니다. (세 번째 웹사이트가 아제르바이잔만을 대상으로 하기 때문에 트래픽 양이 이전 예보다 적습니다.)
아래에서 세 번째 사이트의 GSC 그래픽에 대한 지난 6개월간의 그래픽을 볼 수 있습니다.
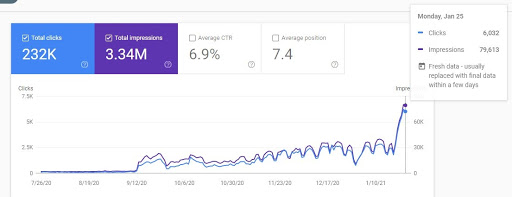
그리고 아래에는 "사전 섹션"의 지난 7개월이 표시됩니다.
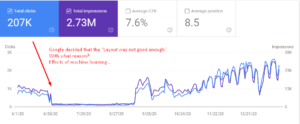
웹 사이트의 "사전 섹션"이 "하루 만에" 모든 트래픽을 잃은 것을 볼 수 있습니다. 우리는 아무것도 바꾸지 않았습니다. 모든 차이점은 Google의 자체 내부 시스템에서 비롯되었습니다. 구글이 딥 러닝과 머신 러닝에 전적으로 의존하기 시작했기 때문에 웹에서 수집한 '일반적인 피드백'에 따라 '페이지 레이아웃'도 평가한다는 것을 알고 있습니다.
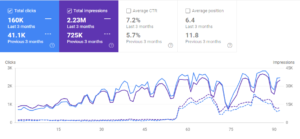
세 번째 프로젝트에 대한 지난 3개월 비교.
따라서 "배경 색상 변경"과 "페이지 요소 순서"만 포함하여 페이지 레이아웃을 변경했으며 모든 것이 이틀 만에 정상으로 돌아갔습니다.
이 SEO 사례 연구 및 실험의 이 부분은 의미론적 SEO에 관한 것이 아니지만 전체적 SEO로서 때때로 "다른 것들"에 집중해야 한다고 말하고 싶습니다. 아래에서 Google Patents의 "웹사이트 표현 벡터"를 볼 수 있습니다.
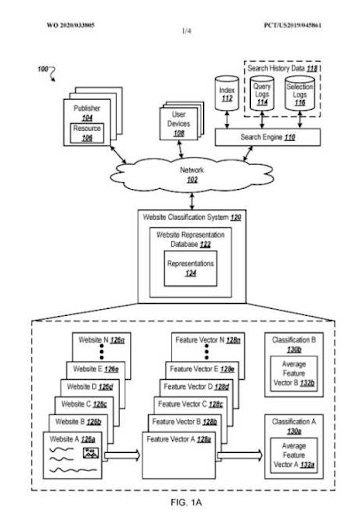
웹사이트 표현 벡터는 검색 엔진이 클릭한 후 "가능한 사용자 만족도"를 이해하는 데 사용할 수 있습니다.
네 번째 프로젝트: 400% 유기적 트래픽 증가 - 아랍 국가를 중심으로
네 번째 웹사이트(이름은 아직 공개되지 않음)는 아랍 세계 전체를 대상으로 합니다. 내 주요 초점은 웹사이트가 아니었기 때문에(아랍어를 할 수 없기 때문에) 400%의 성장만 달성했습니다.
아래에서 네 번째 사이트의 GSC 그래픽에 대한 지난 6개월의 그래픽을 볼 수 있습니다.
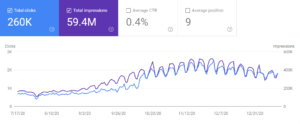
제 생각에는 이 웹사이트의 경우 시맨틱 SEO의 힘에 따른 트래픽 증가가 충분하지 않았습니다. 그것은 아랍어 능력이 부족하기 때문입니다. 기술적 SEO는 "언어에 구애받지 않는" 반면 의미론적 SEO는 단어, 용어, 개념 및 언어의 특성에 크게 구속됩니다.
시맨틱 SEO의 최종 증거로 네 번째 프로젝트에 대한 3개월 GSC 유기적 트래픽 성능 비교를 볼 수 있습니다.
시맨틱 웹, 시맨틱 검색, 토픽 권위에 대한 간략한 설명
시맨틱 웹은 웹상의 정보 조직의 상태입니다. 시맨틱 웹은 인간 두뇌와 우주의 본성에서 비롯된 두 가지 기본 요소인 분류학과 온톨로지를 사용합니다.
택소노미는 '택시' + '노미아'의 합성어로 '정렬'을 의미합니다. 온톨로지는 'on' + 'logy'의 합성어로 '사물의 본질'을 의미합니다. 둘 다 그룹과 범주로 분류하여 엔터티를 정의하는 수단입니다. 분류법과 온톨로지는 함께 시맨틱 웹을 구성합니다.
지난 10년 동안 Google은 시맨틱 웹으로 이동하는 여러 이니셔티브를 만들었습니다.
2011년 구글은 웹상의 정보를 구조화하기 위해 "구조화된 검색 엔진"을 발표했습니다.
그리고 2012년 5월에는 실제 개체에 대한 정보를 더 잘 이해하기 위해 지식 정보를 출시했습니다.
2019년에 그들은 인간의 언어와 인식에서 단어, 개념 및 개체 간의 관계를 더 잘 이해하기 위한 모델인 BERT를 출시했습니다.
이러한 모든 프로세스는 시맨틱 웹, 시맨틱 검색, 시맨틱 검색 엔진으로서의 Google, 그리고 결과적으로 시맨틱 SEO를 생성했습니다.
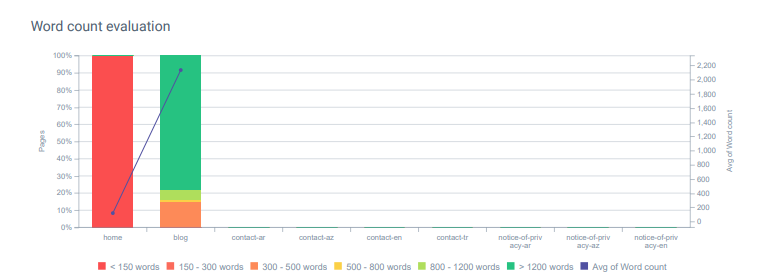
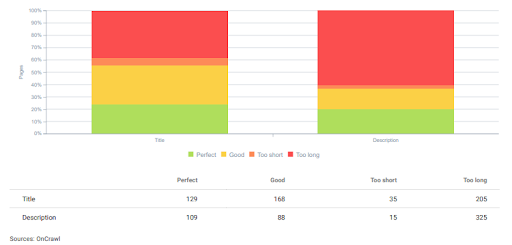
OnCrawl에서 GetWordly.com의 단어 수 평가. 이 프로젝트의 대부분의 콘텐츠에는 경쟁업체보다 더 자세한 내용과 정보가 포함되어 있습니다.
이 문맥에서 국소적 권위와 국소적 적용 범위는 무엇을 의미합니까?
시맨틱하고 조직화된 웹에서 모든 정보 소스는 다양한 주제에 대해 다른 수준의 적용 범위를 갖습니다. 사물이나 엔티티는 공유 속성을 통해 서로 연결됩니다. 이러한 속성은 "온톨로지"를 나타냅니다. 또한 분류 계층 내에서 사물이 서로 연결됩니다 . 이 계층은 "분류"를 나타냅니다. 시맨틱 검색 엔진의 관점에서 주제에 대한 권위자가 되려면 소스가 서로 다른 컨텍스트 내에서 사물의 서로 다른 속성을 다루어야 합니다. 또한 유사한 항목과 상위 및 하위 범주에 있는 항목을 참조해야 합니다.
논리적 내부 링크 및 앵커 텍스트를 사용하여 상황 관련성 및 계층 구조 내에서 가능한 모든 질문에 대해 모든 "하위 주제"에 대한 콘텐츠 네트워크를 만드는 것이 이러한 SEO 사례 연구의 핵심입니다.
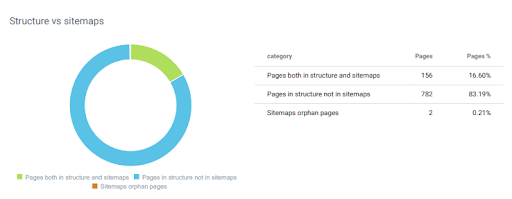
OnCrawl이 말했듯이 나는 이 SEO 사례 연구에서 정상적인 사이트맵을 사용하지 않았습니다. 여기 사이트가 다시 GetWordly.com입니다.
Topical Authority와 Topical Coverage는 가장 상세하고 엔티티 지향적이며 의미론적으로 조직된 포괄적인 콘텐츠 네트워크를 통해 획득할 수 있습니다. 모든 성공적인 콘텐츠는 연결된 엔터티 및 관련 쿼리에 대한 다른 콘텐츠의 성공 가능성을 높입니다.
간단히 설명하기 위해 "해야 할 일"과 "하지 말아야 할 일" 섹션으로 이동하겠습니다. 이러한 주제에 대한 자세한 내용이나 이해가 필요하면 이전에 언급한 기사를 읽는 것이 좋습니다.
시맨틱 SEO를 구현하려면 어떻게 해야 합니까?
시맨틱 SEO의 개념을 완전히 이해하려면 검색 엔진에 웹이 시맨틱해야 하는 이유를 이해해야 합니다. 특히, 규칙 기반의 검색 엔진 순위 시스템이 아닌 머신 러닝 기반의 검색 엔진 순위 시스템이 우세하고 자연어 처리 및 이해 기술의 사용으로 이러한 요구가 더욱 높아졌습니다. 따라서 아래 제안을 이해하려면 검색 엔진의 눈을 통해 이러한 개념에 접근하십시오.
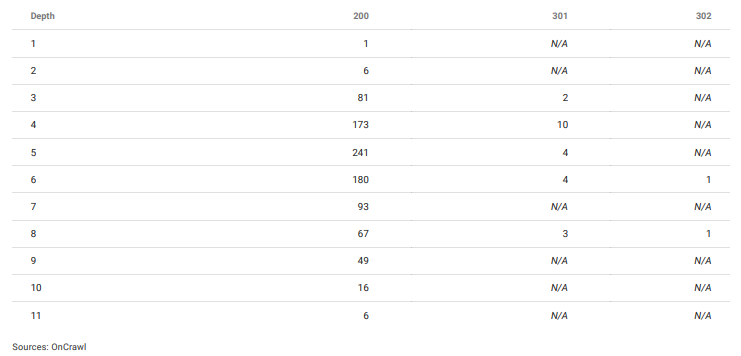
"머리글"이나 "바닥글" 메뉴를 사용하지 않았기 때문에 대부분의 페이지가 정말 깊숙이 있었습니다.
1- 첫 번째 기사 게시를 시작하기 전에 주제도 만들기
온톨로지와 분류법을 기억하십니까? Google의 경우 사전이나 백과사전과 다른 방식으로 사물이 연결될 수 있으므로 Google의 지식 정보를 확인해야 합니다. Google은 엔티티 인식 및 컨텍스트 벡터 계산을 위해 엔지니어가 제공한 웹 및 정보를 사용합니다.
따라서 SERP를 확인하여 어떤 엔터티가 어떤 쿼리에 대해 어떤 방식으로 연결되었는지 확인해야 합니다.
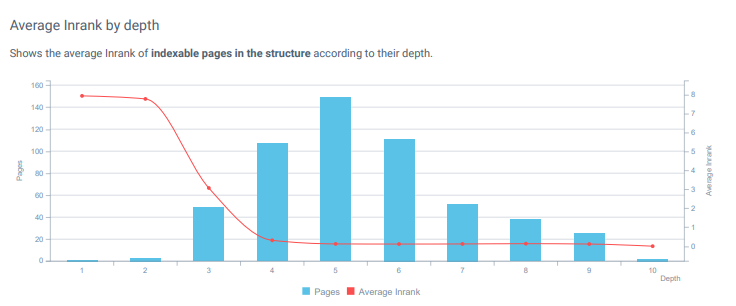
Inrank는 Google의 최초이자 독창적인 PageRank 공식에서 영감을 받은 OnCrawl의 "내부 PageRank" 분포 공식입니다. 그리고 Inrank는 홈페이지에서 멀리 떨어진 페이지에 대해 떨어졌습니다.
이것은 약간 피곤할 수 있지만 잠시 후 Google이 어떻게 생각하고, 행동하고, 사물을 서로 연결하는지 알게 될 것입니다. 토픽 맵을 생성하기 위해 틈새 및 쿼리 그룹을 확인하기 위해 수행할 수 있는 몇 가지 빠른 방법이 있습니다.
- 경쟁사의 사이트맵을 크롤링하여 주제 맵을 이해합니다.
- Google 트렌드 관련 검색어 및 관련 주제를 가져옵니다.
- 자동 완성 및 검색 제안에서 데이터를 수집합니다.
- 경쟁업체가 어떻게 콘텐츠 허브를 연결하는지 확인하십시오.
- Google 지식 정보를 사용하여 관련 항목을 가져옵니다.
- 웹이 아닌 리소스를 사용하여 엔터티와 해당 계층 및 연결의 속성을 봅니다.
마지막 항목은 검색 엔진의 지식 기반에 대한 독창적이고 권위 있는 정보를 제공하는 리소스가 되기 위해서도 중요합니다.
추신: 또한 다른 검색 엔진을 사용하십시오. 특히 의미론적 검색 엔진의 특성을 이해하려면 Swisscows를 확인하는 것이 좋습니다. 의미 검색을 이해하기 위해 Google에만 집중하지 마십시오.
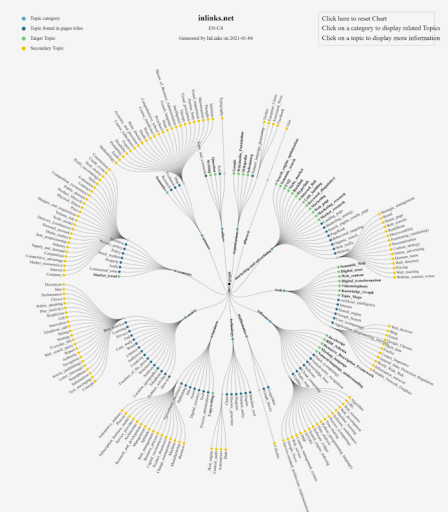
이것은 Inlinks.net의 Topical Map(Topical Graph) 예시입니다. 이것은 고유한 기술이고 InLinks는 Semantic SEO에 중점을 둔 유일한 SEO 회사이므로 해당 기술을 확인하는 것이 좋습니다.
2- 페이지당 링크 수 결정
이러한 모든 SEO 사례 연구 및 성과에서 각 웹 페이지의 총 링크 수는 최대 15개였습니다.
이러한 링크의 대부분은 관련성이 있고 자연스러운 앵커 텍스트와 함께 주요 콘텐츠에 있었습니다. 바닥글이나 머리글 메뉴를 사용하지 않았습니다. 이는 기술 SEO의 기존 권장 사항과 모순됩니다. 나는 그것을 받아들여야 했고 웹 페이지당 15개 이하의 링크를 사용해야 한다고 말하는 것이 아닙니다. 나는 당신이 주요 콘텐츠 내에서 관련성 있고 상황에 맞는 링크를 유지하고 검색 엔진이 해당 링크에 초점을 맞추도록 노력해야 한다고 말하고 있습니다.
다음 항목을 사용하여 웹 페이지에 표시되어야 하는 올바른 내부 링크 수를 결정할 수 있습니다.
- 최소값과 최대값을 이해하기 위한 내부 링크 수에 대한 업계 표준입니다.
- 콘텐츠의 명명된 엔터티 수
- 명명된 엔터티의 컨텍스트 수
- 콘텐츠의 "세분성" 수준
- 각 제목 섹션에 최대 1개의 링크
- "목록 형식"인 경우 동일한 유형에 속하는 엔터티를 해당 페이지에 연결합니다.
[사례 연구] 온페이지 SEO로 새로운 시장에서 성장 주도
 사례 연구 읽기
사례 연구 읽기3- 개수, 단어 및 위치 측면에서 자연스럽고 적절한 방식으로 앵커 텍스트를 결정합니다.
내부 링크가 자연스러워야 하는 필요성과 PageRank를 통과하는 방법에 대해서는 다루지 않겠습니다. 나는 이미 "모든 Google 핵심 알고리즘 업데이트에서 승자가 되는 방법"에서 이에 대해 자세히 다루었으므로 읽어 보시기 바랍니다.
다만, 메인 콘텐츠 내에서 웹페이지에 앵커 텍스트를 3번 이상 사용하지 않는다는 점을 간략하게 말씀드리겠습니다. 즉, 네 번째로 앵커 텍스트 내에서 단어를 더 추가하거나 일부 단어를 변경하는 것이 좋습니다.
앵커 텍스트에 대한 몇 가지 다른 유형의 규칙도 있습니다.
- 나는 페이지의 첫 번째 단락에 있는 텍스트를 해당 페이지에 대한 링크의 앵커 텍스트로 사용하지 않습니다.
- 나는 페이지에 있는 어떤 단락의 첫 단어도 해당 페이지의 앵커 텍스트로 사용하지 않습니다.
- 기사를 다른 맥락이나 부주제에 대한 다른 기사에 링크하는 경우 항상 마지막 제목의 단락 중 하나를 사용합니다(Google에서는 이러한 유형의 연결을 "보충 콘텐츠"라고 부릅니다).
- 나는 항상 특정 기사에 대한 경쟁사의 앵커 텍스트를 내외부적으로 확인합니다.
- 나는 앵커 텍스트를 만들 때 항상 주제에 대한 동의어를 사용하려고 노력합니다.
- 타겟 웹페이지의 콘텐츠와 링크 소스의 관련 제목 텍스트에 "앵커 텍스트"가 있는지 항상 확인합니다.
추신: 성공적인 시맨틱 SEO를 수행하기 위해 이렇게 해야 한다는 말은 아닙니다. 이것들은 내가 이러한 결과를 얻었을 때 따랐던 지침의 몇 가지 예일 뿐입니다. 이 지침을 준수하지 않는 몇 가지 예를 찾으면 아마도 내 사랑스러운 저자 때문일 것입니다.
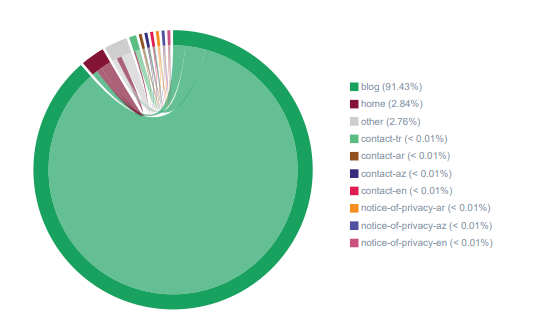
다양한 URL 카테고리에 대한 OnCrawl의 Inrank Flow 분포. 이 프로젝트에서 아무 것도 분류하지 않았기 때문에 대부분 "녹색"이며 가장 중요한 부분이 블로그임을 의미합니다.
4- 상황별 벡터 결정
이 용어는 귀에 약간 "긁적"일 수 있습니다. 이것은 나를 위한 Google Patents의 용어입니다. 컨텍스트 벡터, 컨텍스트 도메인, 컨텍스트 구문... Google Patents에는 파고들어야 할 것들이 많이 있습니다(교육자인 Bill Slawski에게 또 다른 감사를 전합니다).
간단히 말해서 컨텍스트 벡터는 콘텐츠의 각도를 결정하는 신호입니다. 주제는 "지진"이 될 수 있고 컨텍스트는 "지진 비교", "지진 추측" 또는 "지진 연대기"가 될 수 있습니다.
예를 들어 "사과"(과일)는 개체이자 주제이며 Healthline에는 "사과"에 대한 265개 이상의 기사가 있습니다. 사과의 효능, 사과의 영양, 사과의 종류, 사과나무 (기본적으로 다른 실체와 주제이지만 충분히 가깝습니다.)
따라서 이러한 맥락에서 이러한 사이트는 모두 제2외국어 교육 산업에서 온 것입니다. "영어 학습"이 주요 주제입니다. 게임, 비디오, 영화, 노래, 친구로부터 영어를 배우는 것은 다른 맥락입니다.
더 많은 맥락적 연결을 만들기 위해 저는 항상 서로 다른 유형의 기둥 클러스터 콘텐츠를 사용하여 서로 다른 주제와 그 안의 엔터티 사이의 간격을 채우려고 노력합니다. 또한 특허에서 Google의 컨텍스트 벡터 및 지식 도메인에 대해 읽어보는 것이 좋습니다.

OnCrawl의 내부 링크 상태 테이블입니다. 검색 엔진에 대한 명확한 "내부 링크" 상태 코드 및 크롤링 경로가 없었습니다.
5- 작성 및 게시할 콘텐츠 수 결정
콘텐츠 수는 순위 요소가 아닙니다. 사실, 더 포괄적이고 권위 있는 기사로 더 적은 콘텐츠로 더 많은 것을 전달하는 것이 크롤링 예산, PageRank 배포, 백링크 희석 또는 자기잠식 문제와 같은 여러 측면에서 더 좋습니다.
그러나 콘텐츠 수는 프로세스를 계획하는 데 중요합니다. 왜냐하면 얼마나 많은 저자가 필요한지 또는 하루 또는 일주일에 얼마나 많은 기사를 게시할지 알아야 하기 때문입니다. 콘텐츠 게시 및 콘텐츠 업데이트 빈도와 같은 SEO 용어를 이 요약에 많이 포함하지 않았습니다. 하지만 주제, 콘텐츠, 컨텍스트, 엔터티를 결정하더라도 얼마나 많은 콘텐츠가 필요한지 알 수 없습니다. Google은 동일한 페이지의 주제에 대해 서로 다른 컨텍스트를 표시하는 사이트를 선호하는 경우가 있지만 Google은 다른 페이지에서 다른 컨텍스트를 표시하는 것을 선호하는 경우도 있습니다.

웹 페이지의 표제 수준별 평균 표제 수는 위에 있습니다. 제목 유형별 제목 수는 SEO에 대한 콘텐츠 세부 정보, 길이 및 세분성 수준을 나타낼 수 있습니다.
콘텐츠/기사의 정확한 수를 알기 위해서는 Google SERP 유형을 조사하여 경쟁사의 콘텐츠 네트워크 형태가 중요합니다. 이것은 프로젝트의 예산에도 중요합니다 . 고객에게 120개의 콘텐츠만 있으면 된다고 말했지만 나중에 실제로는 180개의 콘텐츠가 필요하다는 것을 알게 되면 신뢰에 심각한 문제가 됩니다.
그리고 모든 SEO 성공 사례를 위해서는 명확한 커뮤니케이션이 필수입니다.
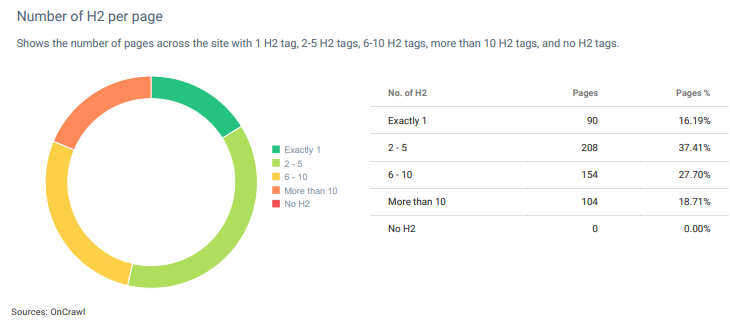
소스가 콘텐츠 구조에 "횡설수설한 문장"을 사용하지 않는 경우 H2의 숫자에서 웹 페이지의 세부 수준을 이해할 수 있습니다.

6- URL 범주 및 계층 구조 결정
URL 카테고리는 여기의 어떤 SEO 사례 연구에서도 사용되지 않았습니다. 그러나 이것이 URL 카테고리 및 해당 탐색경로가 시맨틱 SEO에 유용하지 않다는 것을 의미하지는 않습니다. URL 경로의 동일한 폴더에 유사한 콘텐츠를 유지하면 검색 엔진이 웹사이트를 더 쉽게 이해할 수 있습니다. 또한 사용자를 위한 팁을 제공하고 사이트 내 탐색을 용이하게 합니다.
그렇다면 나는 왜 그것을 사용하지 않았습니까? 동일한 두 가지 이유로 기술 SEO를 사용하지 않습니다. 시간 제약과 향후 SEO 실험을 실행하고 싶기 때문입니다.
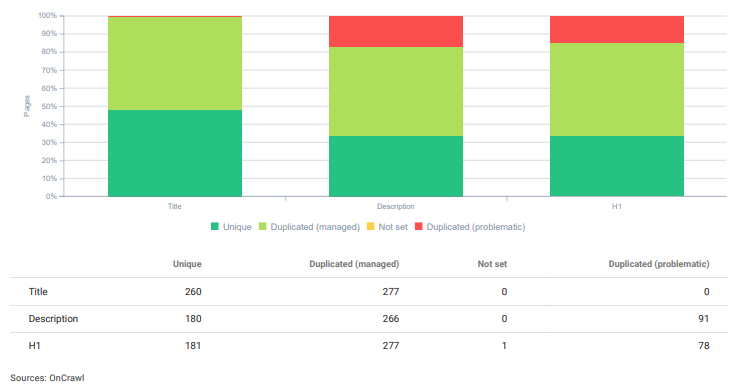
문제가 있고 관리되는 중복이 이러한 SEO 프로젝트에 대해 사이트 전체에 존재합니다.
7- URL 계층으로 조정하여 컨텍스트 벡터로 주제 계층 만들기
하위 주제는 2020년 1월 Google에서 사용하는 것으로 확인되었지만 실제로 Google은 이전에 이를 "신경망" 또는 "신경망"으로 언급했습니다. Google Developers의 YouTube 채널에서는 계층 구조 및 논리 내에서 주제가 서로 연결되는 방식에 대한 멋진 요약도 보여주었습니다. 이것이 다시 말하지만 분류와 온톨로지가 시맨틱 SEO의 핵심인 이유입니다.
그러나 "문맥 벡터를 사용하여 주제 계층 생성"은 무엇을 의미합니까? 이는 모든 주제가 논리적 URL 구조로 그룹화되어 가능한 모든 컨텍스트 및 관련 엔터티로 처리되어야 함을 의미합니다.
이것은 더 세분화되고 상세한 정보 아키텍처 덕분에 검색 엔진이 소스에 더 나은 주제 권위와 전문 지식을 제공하도록 할 것입니다.
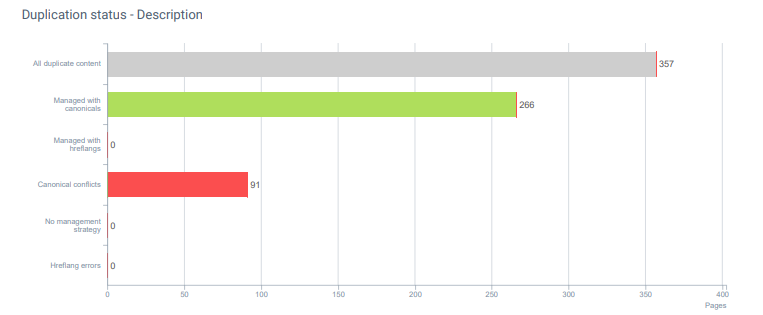
또한 "표준 충돌"이 있습니다.
8- 제목 벡터 조정
표제 벡터… 많은 귀에 생소한 또 다른 용어입니다. 표제 벡터는 실제로 내용의 주요 각도와 주제를 결정하기 위한 신호로서 표제 순서입니다. Google 품질 평가자 가이드라인에 따르면 콘텐츠는 '주 콘텐츠', '광고', '보충 콘텐츠'의 세 가지 섹션으로 구분됩니다.
Google은 스크롤 없이 볼 수 있는 부분이나 기사의 "상단 섹션"에 있는 콘텐츠에 더 많은 비중을 둡니다. 그렇기 때문에 콘텐츠의 상단 섹션에 대한 쿼리는 항상 하단 섹션의 쿼리보다 더 나은 순위를 갖습니다. Google에게 하단 섹션은 실제로 "보충 콘텐츠"를 나타냅니다.
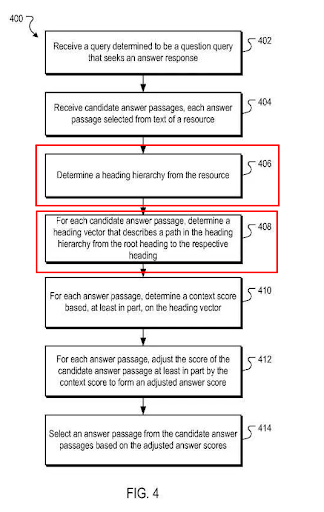
제목 벡터를 통한 문맥 답변 통과 점수 계산에 대한 Google의 방법론을 나타냅니다.
그렇기 때문에 제목 계층 구조 내에서 컨텍스트 관련성과 논리를 사용하는 것이 중요합니다. 간단히 말해서, 의미론적 SEO에 대한 제 관점에서 표제 벡터에 대한 몇 가지 기본 지침은 다음과 같습니다.
- 검색 엔진이 무엇을 말하든, 표제 태그를 포함하여 시맨틱 HTML 태그를 사용하십시오.
- 제목 벡터는 제목 태그에서 시작하므로 제목과 제목 태그는 서로 일치해야 합니다.
- 모든 제목은 서로 다른 정보에 초점을 맞추어야 하며 해당 제목 이후의 단락은 이전에 제공된 정보를 반복해서는 안 됩니다.
- 유사한 아이디어에 초점을 맞춘 제목은 함께 그룹화해야 합니다.
- 다른 엔터티를 포함해야 하는 모든 제목도 여기에 연결되어야 합니다.
- 모든 제목의 내용은 목록, 표, 설명적 정의 등을 포함하는 올바른 형식이어야 합니다.
보시다시피 이 섹션의 모든 내용에는 실제로 기본 논리가 있습니다. 새로운 것은 없다. 그러나 Google의 특허 중 하나인 "답변 구절에 대한 컨텍스트 채점 조정"을 아래에서 보여드리겠습니다.

출처: 답변 구절에 대한 컨텍스트 채점 조정
제목 벡터를 사용하여 Google은 주어진 쿼리에 가장 적합한 문맥 벡터가 있는 구절을 선택하려고 합니다. 그렇기 때문에 이러한 제목 사이에 명확한 논리적 구조를 만드는 것이 좋습니다.
원한다면 Bill Slawski의 분석적 관점에서 이 특허를 읽을 수도 있습니다. Adjusting Featured Snippet Answers by Context.
14일 무료 평가판 시작
 평가판 시작
평가판 시작9- 컨텍스트 내의 주제에 대한 관련 엔터티 연결
엔터티와 엔터티 연결을 연결하는 것은 서로 밀접한 용어입니다. 엔터티 연관은 엔터티의 속성을 기반으로 하고 가능한 검색 의도에 대해 쿼리가 표현되는 방식을 통해 검색 엔진에서 수행할 수 있습니다.
컨텍스트 내에서 엔티티를 연결하고 엔티티를 연관시키는 것은 온톨로지의 실제 적용입니다. 예를 들어, "영어 학습"이라는 SEO 프로젝트 산업의 맥락에서 "구동사" 주제에 대해 "불규칙 동사", "가장 많이 사용하는 동사", "변호사에게 유용한 동사"도 사용할 수 있습니다. ", "라틴어 동사의 어원", "잘 알려지지 않은 동사"는 서로 연결될 수 있습니다.
SEO 관련 HTML 태그는 그 안의 길이와 용어 측면에서 최적화되어야 합니다. 이 프로젝트에서는 보시다시피 구현하지 않았습니다.
이러한 모든 컨텍스트는 실제로 "영어 동사"에 중점을 둡니다. 그것들은 모두 "문법 규칙", "문장의 예", "발음" 및 "시제"와 관련이 있습니다. 이러한 모든 컨텍스트와 엔터티를 서로 자세히 설명하고, 구조화하고, 분류하고, 연결할 수 있습니다.
기본적으로 주제 및 모든 관련 엔터티에 대한 가능한 모든 컨텍스트를 다룬 후에는 시맨틱 검색 엔진이 이러한 항목에 대한 가능한 검색 의도에 대한 신뢰할 수 있는 소스로 사용자를 선택하는 것 외에 다른 기회가 없습니다.
10- 가능한 검색 의도에 대한 질문 및 답변 생성
"답에서 질문 생성"… 또 다른 Google 특허. 하지만 이 글은 이미 충분히 길기 때문에 자세히 설명하지는 않겠습니다. 기본적으로 검색 엔진은 웹의 콘텐츠에서 질문을 생성하고 이러한 질문을 쿼리 재작성으로 쿼리와 일치시킵니다. 그리고 이러한 질문을 사용하여 웹에서 가능한 검색 의도에 대한 가능한 콘텐츠 격차를 좁힙니다.
그렇기 때문에 모든 엔터티를 서로 연결하면서 모든 컨텍스트로 모든 엔터티를 처리하라고 말씀드리는 것입니다. 그러나 정보 추출이 무엇인지도 알아야 합니다. 정보 추출은 문서에서 개념에 대한 중요한 사실과 결정적인 연결을 끌어내는 것입니다. 정보 추출 덕분에 검색 엔진은 문서에서 답변할 수 있는 질문이나 이해할 수 있는 사실을 이해할 수 있습니다. 정보 추출을 사용하여 엔터티와 해당 속성 간의 지식 그래프를 만들고 관련 질문을 생성하는 데 사용할 수도 있습니다.

검색 쿼리에 대한 관련 질문 생성
검색량에만 집중해서는 안됩니다! 이전에 아무도 이 질문을 하지 않았을 수도 있습니다. 그리고 검색 엔진도 이 질문에 대한 답을 모를 수 있습니다. 그러나 이 고유한 정보가 주제 내 엔티티의 속성을 정의하는 데 유용하다면 이러한 질문을 생성하고 답하고 웹 및 틈새 시장의 검색 엔진에 대한 고유한 정보 소스가 됩니다.
11- 키워드 갭 대신 정보 갭 찾기
먼저 아래 인용문을 읽으십시오.
"주어진 문서에 대한 정보 획득 점수는 사용자가 이전에 본 문서에 포함된 정보 외에 문서에 포함된 추가 정보를 나타냅니다."

출처: 특허 "링크 정보 이득의 컨텍스트 추정"
우리 모두는 최근 2020년에도 "매일 쿼리의 15%가 새로운 것이며 Google은 RankBrain을 사용하여 이러한 쿼리를 가능한 검색 의도 및 새 문서와 일치시킵니다"라는 것을 알고 있습니다. 또한 Google은 항상 고유한 정보를 검색하고 사용자의 향후 쿼리에 대한 답변을 제공합니다. 고유한 정보를 제공하고 덜 알려진 "용어, 관련 정보, 질문, 연구, 사람, 장소, 이벤트 및 제안"을 포함하도록 노력하십시오.
따라서 "긴 콘텐츠" 또는 "키워드"는 이러한 SEO 사례 연구의 핵심이 아닙니다. "추가 정보" 및 "고유한 질문" 및 "고유한 연결"이 핵심입니다. 이러한 프로젝트의 모든 콘텐츠에는 검색량과 관련이 없는 고유한 제목이 있으며 사용자도 이를 인식하지 못할 수 있습니다.
아래에서 증강 쿼리 및 가능한 관련 검색 활동에 대한 문맥 관련성을 보여주는 또 다른 Google 특허를 볼 수 있습니다.
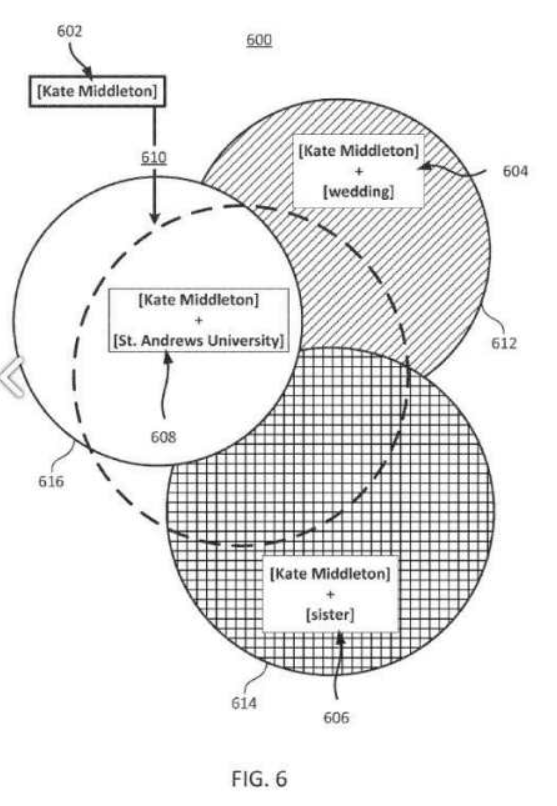
지식 정보를 이용한 증강 검색어
"핵심을 설명하면서 문맥적 연결이 있는 모든 관련 엔터티를 포함"은 여기서도 그 중요성을 볼 수 있습니다.
12- 키워드의 양이나 난이도에 신경쓰지 마세요
나는 이미 키워드 볼륨에 대한 나의 의견을 공유했습니다. 이 4개의 프로젝트를 진행하는 동안 저는 주로 품질이 높고 이해하기 쉬운 "교육용 책"을 만드는 것으로 제 자신을 보았습니다.
- 프로젝트 초기에 수많은 백링크를 가진 권위 있는 경쟁자들이 저를 위협하지 않았습니다.
- 나는 키워드 난이도와 같은 제3자 측정항목에 대해서는 신경 쓰지 않았습니다.
- 경쟁업체의 과거 데이터와 브랜드 강점은 저를 두렵게 하지 않았습니다.
- 그리고 마지막으로 "저는 Google Search Console을 사용하여 고객에게 프로젝트의 최신 상황을 보여주었습니다"라는 말을 피했습니다. Google의 반응을 검토하는 것 외에는 GSC에 들어가지 않았습니다.
기사를 작성할 때 주제의 의미 구조에서 부주제가 필요한 경우 작성해야 합니다. 검색량이 "0"이어도 작성해야 합니다. 키워드 난이도가 100이어도 작성해야 합니다.
여기에 또 다른 중요한 포인트가 있습니다.
SERP에서 "구"에 대한 순위를 매기려면 모든 관련 구문과 모든 관련 주제 그래프에 모든 세부 정보를 포함해야 합니다. 다시 말해, 시맨틱 SEO에서는 각 관련 주제를 완전히 처리하지 않고 해당 주제와 관련된 쿼리의 순위 상승을 볼 수 없습니다.
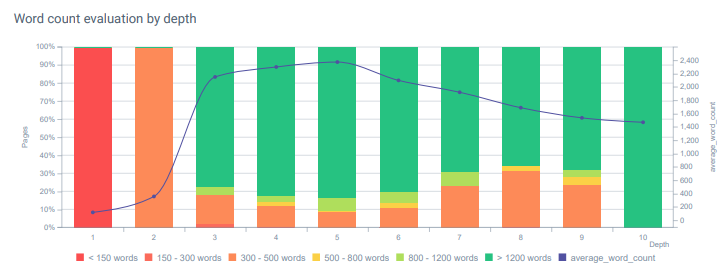
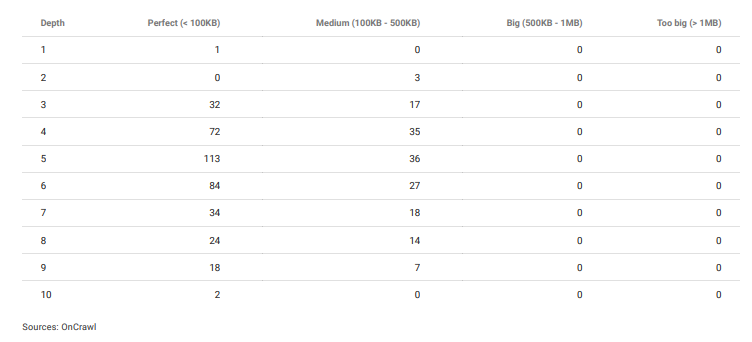
페이지 깊이에 따른 단어 수 평가. 콘텐츠가 오래될수록 이 예제에서는 표준 내부 탐색을 사용하지 않기 때문에 페이지 클릭 깊이가 증가합니다. 하지만 10번째 뎁스에서도 우리는 경쟁사보다 강력한 콘텐츠를 가지고 있습니다. 이를 통해 Google은 더 멀리, 더 깊이 들여다볼 수 있습니다.
13- 과거 데이터의 주제 범위 및 권위에 초점
주제 그래프는 어떤 주제가 어떤 연결 내에서 서로 연결되는지 보여주는 그래프입니다. 주제 범위는 이 그래프를 얼마나 잘 다루고 있는지를 의미합니다. 과거 데이터는 특정 수준에서 이 주제 그래프를 다룬 기간을 나타냅니다.
주제 권위 = 주제 범위 * 과거 데이터
그렇기 때문에 제가 보여드리는 모든 그래픽에서 일정 시간이 지나면 "급속한 성장"을 볼 수 있습니다. 그리고 저는 자연어 처리 및 이해를 사용하기 때문에 이러한 초기 급격한 유기적 트래픽 증가의 대부분은 추천 스니펫에서 비롯됩니다.
주제에 대한 추천 스니펫을 사용할 수 있다면 검색 엔진에 대한 이해하기 쉬운 콘텐츠 구조로 권위 있는 소스가 되기 시작했다는 의미입니다.
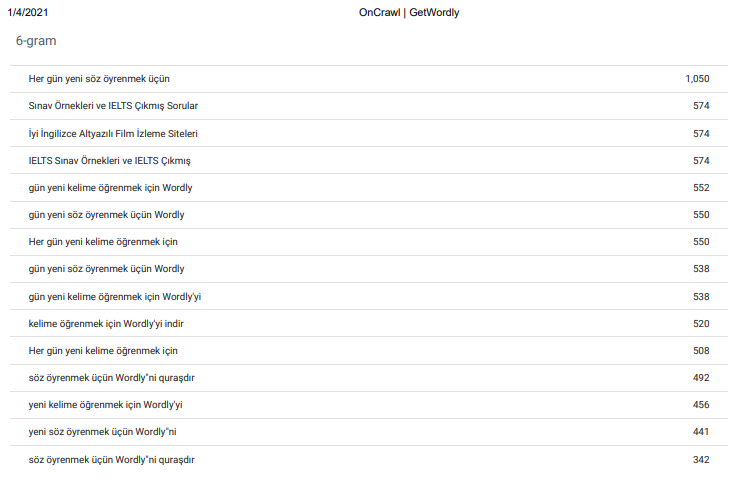
N-Gram Analysis는 저에게 OnCrawl의 최고의 기능 중 하나입니다. 그리고 이것은 SEO 크롤러의 고유한 기능입니다. 위에서 "사이트 전체로 6그램 분석"을 볼 수 있습니다. "영어 학습 및 교육"(Ingilizce Ogrenmek ve Ogretmek)은 보이는 바와 같이 이 단체의 주요 주제입니다.
14- 저자와 함께 자연어 처리 용어를 사용하여 가능한 최상의 문장 구조 및 콘텐츠 형식 결정
저자를 교육하십시오.
Google이 NLP와 NLU를 어떻게 사용하는지 보여주세요. "음성 태그의 일부"가 무엇인지 또는 "명명된 엔터티 인식" 및 "명명된 엔터티 연결"이 무엇인지 가르칩니다. N-Grams, Skip-Grams, Word2Vec을 구체적인 결과와 사례와 함께 사용하여 기계 실행 텍스트 분석을 이해할 수 있도록 합니다. Google 지식 정보가 어떻게 작동하는지 보여주세요.
Neural Matching 또는 Entity Type Matching이 무엇인지 가르쳐 주십시오. 콘텐츠를 수정하는 동안 Google 문서도구를 통해 실수를 보여주고 추천 스니펫으로 유기적 트래픽 증가를 보여줍니다.
저는 때때로 이것을 "추천 스니펫 지향 콘텐츠 마케팅" 이라고 부릅니다. 우리 모두는 Google이 NLP 모델을 사용하여 콘텐츠를 이해하고 솔직히 말해서 Google의 NLP 기반 알고리즘 덕분에 2011년보다 더 쉽게 가장 권위 있는 경쟁자를 제압한다는 것을 알고 있습니다.
그리고 이 Semantic SEO Manifesto의 시작 부분에서 말했듯이 나는 하루 만에 모든 추천 스니펫을 잃어버렸습니다. 이것은 Google이 하루에 추천 스니펫의 비율을 4% 줄이는 사소한 업데이트를 수행했을 때 발생했습니다. 동시에 과도한 트래픽으로 인해 서버가 다운되었습니다. 또한 "재순위 수요"를 만들기 위해 많은 콘텐츠를 업데이트하면서 새로운 콘텐츠를 계속 게시했습니다.
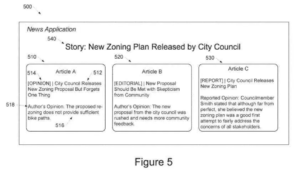
Google에서 콘텐츠가 의견 기반인지 사실 기반인지 이해하려고 시도하는 방법입니다. 특허명: 문서에서 의견을 식별하는 기계 학습.
아래에서 내 저자에 대한 몇 가지 규칙을 찾을 수 있습니다.
- 기사에서 절대 의견을 말하지 마십시오.
- 기사에서 "일상적인 언어"를 사용하지 마십시오.
- 비유를 사용하지 마십시오.
- 불필요한 단어를 사용하지 마십시오.
- 내용은 가능한 한 짧고 필요한 만큼 길어야 합니다.
- 항상 긴 문장 대신 짧은 문장을 사용하십시오.
- 항상 직접적이고 정확하게 답변하십시오.
- 진술을 하기 전에 항상 "출처"를 권위자로 사용하십시오.
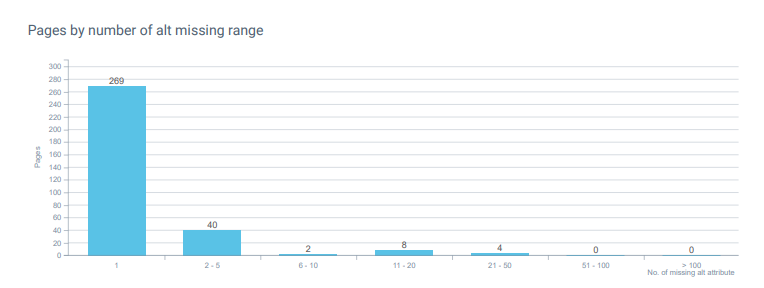
그리고 그리 놀라운 일은 아니지만 저는 이미지에 "alt 태그"를 사용하지 않았습니다. 하지만 이것도 접근성 문제이기 때문에 SEO 실험을 위한 것이라도 사이트를 접근할 수 없는 상황에 방치하는 것은 옳지 않습니다. 실험을 위해 상점으로 가는 휠체어 입구를 제거한다고 상상해 보십시오. 웹사이트에도 동일한 원칙이 적용됩니다.
Sometimes it is difficult to get your authors to follow these rules, and I am not saying that you must follow them.

I am saying that I (mostly) followed these rules during these SEO projects.
15- Educate Your Customer instead of Keeping them in the Dark
I see that most of the SEO agencies do not explain SEO's subtle sides to their customers. The main reason for this lies the basic side of their business model. SEO is a business model based on the subscription economy model. It means that customers should continue to buy the service.
But you can also use the “IKEA Effect” for your business. The IKEA Effect is when you make customers contribute to the work, and it makes them love you more. As an owner of a “one-man-one-desk” company, I use my customers' team for our SEO projects. In other words, I don't need an SEO team for myself because I already have multiple teams that I educate.
OnCrawl's response size report according to the click depth. Having a “bad design” can also be useful if you want to have “smaller response sizes”. It is not an intentional situation but it is a natural outcome.
And when the customer starts to understand, to learn from you and to work hands-on on their own project, they start to love SEO and they feel the IKEA Effect. They give more value to the SEO project through self-association and effort justification.
Thus, they will listen to you easier, and sharing the “real know-how” won't jeopardize your business. Instead, it will make things easier. I even educate interns or sometimes enter job interviews for my customers' job applicants, because their future team member is also my team member.
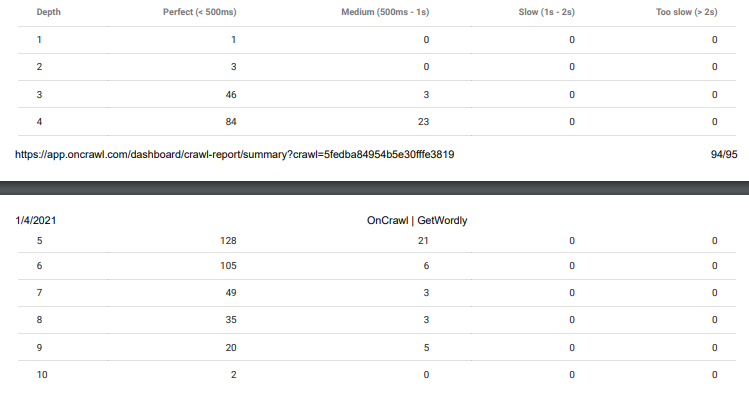
OnCrawl's response time report. After a server crash due to the organic traffic increase, we have bought a new server. That's why this crawl report shows better response timing. The other side of reality can be seen below.
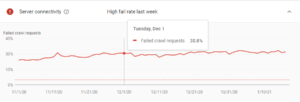
During the SEO case study and experiment, even the most important thing was not enough: the server. A screenshot from Interingilizce.com's Server Connectivity report from Google Search Console's Crawl Stats Report.
As an entrepreneur, this is my own model that is born from my own conditions. I hope this also fits for you as in other articles. Semantic SEO relies on patience, costly authors, highly theoric SEO terms, and content engineering with algorithmic knowledge. Without educating the customer, it might not be possible to convince the customer to follow you on this road.
And when you do convince them, they are happier to work with you, even when you propose theories that sound new or different to them:
“Koray likes to apply new things to our projects in a very short time. We got huge spikes in our web sites with his strategy. We like his enthusiasm. If you don't work with him, you haven't seen an advanced SEO theory glossary.”
Savas Ates
Owner of the KonusarakOgren
Last Thoughts on Semantic SEO
While writing this guide for this SEO case study with four different SEO projects, I have tried to keep things simple as much as possible. And I have told everything with complete honesty. If you can endure long theoric articles with a deep analytical analysis for SEO, I recommend you read the article that I recommended in the beginning that explains more than 40 different lesser-known SEO terms to understand everything behind this methodology.
As you have seen, in order to focus on an initial, rapid gain in traffic, I neglected a lot of SEO improvements for these sites. Working on these different technical SEO elements that you have seen in screenshots throughout the article will also improve traffic even more, but I wanted to be able to clearly show you the effects of semantic SEO alone.
Thanks to deep learning and machine learning, semantic SEO will soon become a more popular strategy. And I believe that technical SEO and branding will give more power to the SEOs who give value to the theoretical side of SEO and who try to protect their holistic approach.
See you in the future SEO case studies and experiments.