
딥 러닝이 의료 서비스를 바꾸는 방법 2부: 예방
게시 됨: 2022-05-07지난 주에 우리는 AI가 의사가 질병과 장애를 진단하는 방식을 어떻게 변화시키고 있는지에 대해 이야기했습니다.
그러나 빠르고 저렴하며 정확한 진단만큼 중요한 것은 예방입니다.

이번 주에는 의사가 질병과 입원을 예측하고 예방하는 방식을 AI가 어떻게 변화시키고 있는지 살펴보겠습니다.
시기 적절한 예측은 질병 예방에 도움이 됩니다
미국 의료 연구 품질청(US Agency for Healthcare Research and Quality)의 추정에 따르면 매년 미국 병원은 440만 명의 환자를 불필요하게 입원시키고 308억 달러의 비용을 지출합니다.
심장병과 당뇨병 합병증이라는 두 가지 질병이 모든 불필요한 입원의 절반을 차지합니다.

심장병 인포그래픽(출처: Huffington Post)
다음은 딥 러닝이 이미 심장 질환 및 당뇨병과 관련된 부정적인 건강 사건을 예측하고 예방하는 데 어떻게 도움이 되는지에 대한 몇 가지 예입니다.
- 보스턴 대학 정보 및 시스템 공학 센터의 연구원들은 지역 병원과 협력하여 심장 질환 및 당뇨병 환자를 모니터링하고 입원이 필요한 환자를 예측했습니다. 의료 제공자가 도움이 필요하기 전에 누가 도움이 필요한지 예측할 수 있다면 이러한 입원을 예방할 수 있습니다. 연구원들이 사용하는 딥러닝 모델은 약 1년 전에 입원이 필요한 사람을 82%의 정확도로 예측할 수 있습니다.
- Sutter Health와 Georgia Institute of Technology의 연구원들은 이제 의사가 전통적인 방법을 사용하기 9개월 전에 전자 건강 기록을 분석하기 위해 딥 러닝을 사용하여 심부전을 예측할 수 있습니다.
- Royal Philips의 회장이자 CEO인 Frans Von Houten은 5월에 CNBC에 자신의 회사가 AI를 사용하여 환자가 심장마비가 발생하기 몇 시간 전에 발병할지 여부를 정확하게 예측한다고 말했습니다.
그러나 AI는 갑작스러운 의료 사건을 예방하는 데 도움이 되지 않습니다. 또한 진행 중인 퇴화를 방지하는 데 도움이 됩니다.
예를 들어, 당뇨병성 망막병증은 생산 가능한 성인의 실명의 주요 원인입니다.
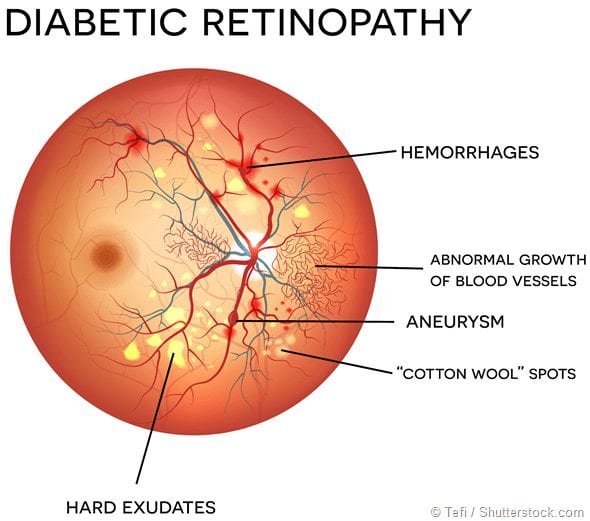
당뇨망막병증 도표 (출처: news-medical.net)
이러한 당뇨병 관련 합병증은 혈당 수치의 급등과 저하로 인해 발생하므로 혈당 수치를 정확하게 예측하는 것이 초기에 적절한 간식과 인슐린 주사로 저하 및 급상승을 예방하는 열쇠입니다.
2017년 7월 논문에 따르면 딥 러닝을 수행하는 심층 신경망은 한 세트의 당뇨병 어린이로부터 더 많은 어린이 그룹에서 혈당 수치를 정확하게 예측하는 방법(이러한 강하 및 급증을 방지하기 위해)을 배울 수 있습니다.
유전자가 어떻게 질병을 유발하는지에 대한 이해가 깊어질 것입니다.
AI로 질병을 예방하는 또 다른 방법은 유전자 구성을 기반으로 누가 특정 장애를 앓을 것인지 예측하는 것입니다.
Gartner 의료 분석가인 Richard Gibson에 따르면 유전자는 "1950년 항생제가 등장한 이래로 의료 분야에 가장 큰 영향을 미친 것"입니다.
특히, 연구자들이 전례 없는 수준으로 유전체학 데이터를 수집하고 딥 러닝 모델이 그 데이터를 분석하고 연결을 그리는 것을 그 어느 때보다 쉽게 만들면서 우리는 돌연변이와 같은 유전적 요인이 어떻게 질병을 유발하는지에 대해 엄청난 양을 배우고 있습니다.
이러한 발전은 각 환자의 게놈 구성에 맞는 치료법을 목표로 하는 개인화 또는 "정밀" 의학으로 이어집니다.
당신의 게놈은 "당신"을 구축하기 위한 완전한 화학적 지침 세트입니다. 유전체학은 아직 초기 단계에 있지만 진전을 이루는 프로젝트가 있습니다. 예를 들어, 토론토 대학의 연구원 팀은 개별 환자에서 암을 유발하는 돌연변이를 신속하게 식별하기 위한 유전자 해석 엔진을 구축하기 위해 노력하고 있습니다.

또한 토론토에서 Deep Genomics라는 신생 기업은 유전 정보 및 의료 기록의 방대한 데이터 세트에 딥 러닝 모델을 적용하여 해당 질병과 유전적 변이를 일치시킵니다.
두 조직 모두 AI 컴퓨팅 플랫폼인 Nvidia GPU를 모델에 사용합니다.
적합한 소프트웨어로 딥 러닝 준비
Nvidia에서 만든 GPU와 같은 GPU는 딥 러닝 알고리즘을 실행하는 데 필수적이지만 의료 AI를 현실로 만들기 위해서는 전문 소프트웨어도 필요합니다.
Boston University 그룹은 심층 신경망(DNN)을 사용했기 때문에 의사 혼자보다 훨씬 더 정확하게 입원이 필요한 사람을 예측할 수 있었습니다.
DNN은 건강 기록 및 인구 통계 정보와 같은 최대 200개의 요소를 분석하여 미래의 질병과 관련된 요소를 식별할 수 있습니다. 그러나 DNN 모델이 작동하려면 EHR 레코드의 데이터가 필요합니다.
한 가지 잠재적인 문제는 EHR이 일반적으로 이러한 유형의 데이터를 큰 텍스트 블록에 저장한다는 것입니다. 예를 들어, EHR은 "메모" 섹션에 환자의 우울증 이력에 대한 기록이 있을 수 있습니다. 이 섹션에는 의사가 현재의 불만, 문제 등과 함께 "환자의 어머니가 우울한 기분으로 고통받았습니다"라고 씁니다.
그러나 AI 모델이 작동하려면 잘 구조화된 데이터가 필요합니다. "가족력"이라는 열과 "우울증" 옆에 확인란이 있으면 기계가 환자에게 우울증의 가족력이 있는지 구문 분석하기가 더 쉽습니다.
Andreessen Horowitz 파트너인 Frank Chen은 Fortune에 곧 딥 러닝이 "정교한 소프트웨어 애플리케이션을 구축하는 사람들에게 필수"가 될 것이라고 말했습니다.
SaaS 스타트업에 투자하는 사람들을 포함한 대부분의 벤처 캐피털리스트들은 5년 전 딥 러닝이 무엇인지조차 몰랐습니다. 오늘날 투자자들은 "그것이 없는 신생 기업을 경계합니다"라고 Chen은 말합니다.
마찬가지로, 딥 러닝 모델과 함께 작동하는 잘 구조화된 데이터 종류를 생성 및 저장하지 않는 EHR에 주의해야 합니다. Nuance와 파트너십을 맺은 Epic과 같이 임상 문서 기능에 AI를 내장한 EHR을 찾을 수도 있습니다.
그러나 IBM Watson Health의 부사장 겸 최고 건강 정보학 책임자인 Anil Jain, MD, FACP에 따르면 대부분의 EHR 시스템에는 한동안 AI가 내장되지 않을 것이라고 합니다. 이러한 경우 옵션은 AI 기능을 기존 EHR에 통합하는 것입니다. 이제부터 대부분의 의료 시스템은 추가 기능으로 AI를 개발하고 배포해야 합니다.
Intermountain Healthcare는 EHR을 사용하여 Cerner에 150개 이상의 프로토콜을 구축했습니다. 각 프로토콜에서 Cerner는 특정 의학적 상태를 나타내는 환자 정보를 수신할 때 경고를 표시한 다음 제안된 추가 검사 및 잠재적 치료를 통해 임상의를 안내합니다.
12명의 의사, 간호사, 분석 전문가가 필요했던 이러한 프로토콜을 구축하려면 1년 이상이 소요됩니다. 그러나 Intermountain과 협력하면 사람의 노동 없이 10일 만에 지을 수 있습니다.
EHR 소프트웨어를 찾고 있든 의료 관리 소프트웨어를 찾고 있든 소프트웨어 영업 사원과 이야기할 때 어떤 질문을 해야 하는지 아는 것이 중요합니다.
VC 파트너 Chen의 조언을 듣고 다음과 같은 질문을 하십시오.
- "당신의 자연어 처리 버전은 어디에 있습니까?"
- "메뉴를 클릭할 필요가 없도록 앱과 대화하려면 어떻게 해야 하나요?"
다음 단계
현재 대규모 연구 센터와 의료 시스템은 질병 및 입원을 예측 및 예방하고 어떤 유전자가 미래의 질병 및 장애와 관련이 있는지 발견할 수 있는 딥 러닝 모델을 개발하고 있습니다.
EHR 소프트웨어를 비교할 때 후보 목록에 있는 공급업체에 제공하는 AI 기능 또는 통합에 대해 문의하십시오. 예를 들어, 데이터가 텍스트 블록에 저장되어 있습니까? 아니면 더 구조화되어 있습니까?
이상적으로는 AI 기능이 내장된 EHR 또는 딥 러닝 모델과 통합할 수 있는 EHR을 선택해야 합니다.