
숨길 곳 없음: 검색 엔진 스파이더의 콘텐츠 차단
게시 됨: 2022-06-12TL;DR
- 검색 엔진에서 콘텐츠를 제외하는 것을 고려하고 있다면 먼저 올바른 이유로 제외하고 있는지 확인하십시오.
- 봇이 이해할 수 없는 언어나 형식으로 콘텐츠를 숨길 수 있다고 가정하는 실수를 하지 마십시오. 근시안적인 전략입니다. robots.txt 파일이나 Meta Robots 태그를 사용하여 그들에게 먼저 다가가십시오.
- 권장되는 방법을 사용하여 콘텐츠를 차단하고 있다는 사실만으로도 안전하다는 사실을 잊지 마십시오. 콘텐츠를 차단하면 귀하의 사이트가 봇에 어떻게 표시되는지 이해하십시오.
검색 엔진 색인에서 콘텐츠를 제외하는 시기와 방법
SEO의 주요 측면은 귀하의 웹사이트가 평판이 좋고 검색자에게 실질적인 가치를 제공한다는 것을 검색 엔진에 확신시키는 것입니다. 그리고 검색 엔진이 콘텐츠의 가치와 관련성을 판단하기 위해서는 사용자 입장이 되어야 합니다.
이제 귀하의 사이트를 보는 소프트웨어에는 검색 엔진에서 특정 리소스를 숨기기 위해 SEO가 전통적으로 악용해 온 특정 제한 사항이 있습니다. 그러나 봇은 계속해서 발전하고 있으며 인간 사용자가 브라우저에서 보는 것처럼 웹 페이지를 보기 위해 계속해서 정교해지고 있습니다. 이제 검색 엔진 봇이 사용할 수 없는 사이트의 콘텐츠와 사용할 수 없는 이유를 다시 검토해야 합니다. 봇에는 여전히 한계가 있으며 웹마스터는 특정 콘텐츠를 차단하거나 외부화할 정당한 이유가 있습니다. 검색 엔진은 사용자에게 양질의 콘텐츠를 제공하는 사이트를 찾고 있으므로 사용자 경험이 프로젝트를 안내하도록 하면 나머지는 제자리에 놓입니다.
콘텐츠를 전혀 차단하는 이유는 무엇입니까?

- 비공개 콘텐츠. 페이지의 색인을 생성한다는 것은 검색 결과에 페이지를 표시할 수 있고 따라서 공개적으로 볼 수 있음을 의미합니다. 개인 페이지(고객 계정 정보, 개인 연락처 정보 등)가 있는 경우 색인에서 제외하고 싶습니다. (일부 후이즈 유형 사이트는 등록자 정보를 자바스크립트로 표시하여 스크레이퍼 봇이 개인 정보를 훔치는 것을 방지합니다.)
- 중복된 콘텐츠입니다. 텍스트 스니펫(상표 정보, 슬로건 또는 설명) 또는 전체 페이지(예: 사이트 내 맞춤 검색 결과)에 관계없이 사이트의 여러 URL에 콘텐츠가 표시되는 경우 검색 엔진 스파이더는 이를 낮은 품질로 볼 수 있습니다. . 사용 가능한 옵션 중 하나를 사용하여 해당 페이지(또는 페이지의 개별 리소스)가 인덱싱되지 않도록 차단할 수 있습니다. 사용자에게는 계속 표시되지만 검색 결과에서는 차단되므로 검색에 표시하려는 콘텐츠의 순위에 영향을 미치지 않습니다.
- 다른 출처의 콘텐츠. 광고와 같은 콘텐츠는 제3자 소스에서 생성되고 웹 전체에 복제되어 페이지의 기본 콘텐츠에 속하지 않습니다. 해당 광고 콘텐츠가 웹 전체에 여러 번 복제되는 경우 웹마스터는 광고가 페이지의 일부로 표시되지 않도록 할 수 있습니다.
그것은 왜, 어떻게에 대해 돌봐?
물어봐주셔서 정말 기쁩니다. 콘텐츠를 인덱스에서 제외하는 데 사용된 한 가지 방법은 봇이 구문 분석하거나 실행할 수 없는 언어를 사용하여 차단된 외부 소스에서 콘텐츠를 로드하는 것입니다. 그것은 방에 있는 유아가 당신이 무슨 말을 하는지 알기를 원하지 않기 때문에 다른 어른에게 철자법을 쓰는 것과 같습니다. 문제는 이런 상황의 아이가 점점 똑똑해지고 있다는 점이다. 오랫동안 검색 엔진에서 무언가를 숨기고 싶다면 JavaScript를 사용하여 해당 콘텐츠를 로드할 수 있습니다. 즉, 사용자는 얻지만 봇은 그렇지 않습니다.

그러나 Google은 봇으로 JavaScript를 구문 분석하려는 욕구에 대해 전혀 수줍어하지 않습니다. 그리고 그들은 그것을 하기 시작했습니다. 웹마스터 도구의 Fetch as Google 도구를 사용하면 Google 봇이 보는 것처럼 개별 페이지를 볼 수 있습니다.
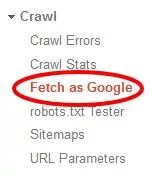
JavaScript를 사용하여 사이트의 콘텐츠를 차단하는 경우 이 도구에서 일부 페이지를 확인해야 합니다. 가능성은 Google이 보고 있습니다.
그러나 Google이 JavaScript로 콘텐츠를 렌더링할 수 있다고 해서 콘텐츠가 캐시되는 것은 아닙니다. "Fetch and Render" 도구는 봇이 볼 수 있는 것을 보여줍니다. 인덱싱되는 항목을 찾으려면 페이지의 캐시된 버전을 확인해야 합니다.
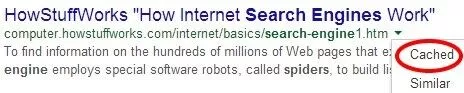
iframe, AJAX, jQuery와 같이 사람들이 논의하는 콘텐츠를 외부화하는 다른 방법이 많이 있습니다. 그러나 2012년까지 Google이 iframe에 배치된 링크를 크롤링할 수 있다는 실험이 있었습니다. 그래서 그 기술이 간다. 사실, 봇이 이해할 수 없는 언어로 말하는 시대는 거의 끝나가고 있습니다.
하지만 봇에게 특정 사물을 보지 않도록 정중하게 요청하면 어떻게 될까요? robots.txt 또는 Meta Robots 태그의 요소를 차단하거나 허용하지 않는 것은 요소 또는 페이지가 인덱싱되지 않도록 하는 유일한 확실한 방법(암호로 보호되는 서버 디렉토리의 줄임말)입니다.
John Mueller는 최근 AJAX/JSON 피드로 생성된 콘텐츠가 "JavaScript 크롤링을 허용하지 않으면 [Google]에 보이지 않을 것"이라고 말했습니다. 그는 계속해서 단순히 CSS나 자바스크립트를 차단한다고 해서 순위가 나빠지는 것은 아니라는 점을 분명히 했습니다. 따라서 콘텐츠를 색인에서 제외하는 가장 좋은 방법은 검색 엔진에 콘텐츠를 색인하지 않도록 요청하는 것입니다. 개별 URL, 디렉토리 또는 외부 파일이 될 수 있습니다.
이것은 우리를 처음으로 돌아가게 합니다: 왜. 콘텐츠를 차단하기로 결정하기 전에 차단하는 이유와 위험 요소를 파악하세요. 우선 CSS 또는 JavaScript 파일(특히 사이트 레이아웃에 크게 기여하는 파일)을 차단하는 것은 위험합니다. 무엇보다도 검색 엔진이 귀하의 페이지가 모바일에 최적화되어 있는지 확인하지 못하게 할 수 있습니다. 뿐만 아니라 Panda 4.0이 출시된 후 큰 타격을 받은 일부 사이트는 CSS 및 JavaScript의 차단을 해제하여 반등할 수 있었습니다.
콘텐츠를 차단할 때 발생할 수 있는 또 하나의 위험: 검색 엔진 스파이더는 차단된 항목을 볼 수 없지만 차단되는 항목이 있다는 것을 알고 있으므로 해당 콘텐츠가 무엇인지 가정해야 할 수 있습니다. 예를 들어 광고가 종종 iframe이나 CSS에 숨겨져 있다는 것을 알고 있습니다. 따라서 페이지 상단 근처에 차단된 콘텐츠가 너무 많으면 "Top Heavy" 페이지 레이아웃 알고리즘에 영향을 받을 위험이 있습니다. iframe 사용을 고려하고 있는 이 글을 읽는 모든 웹마스터는 먼저 평판이 좋은 SEO와 상의하는 것을 강력히 고려해야 합니다. (여기에 뻔뻔한 BCI 프로모션을 삽입하십시오.)