
Google 핵심 업데이트: YMYL 사이트의 효과, 문제 및 솔루션
게시 됨: 2019-12-04이 사례 연구에서는 터키의 가장 큰 금융 및 디지털 자산 중 하나인 Hangikredi.com을 살펴보겠습니다. 우리는 기술적 SEO 부제목과 일부 그래픽을 볼 것입니다.
이 사례 연구는 두 개의 기사로 제공됩니다. 이 기사는 웹사이트에 강력한 부정적인 영향을 미친 3월 12일 Google 핵심 업데이트와 이에 대응하기 위해 우리가 한 조치를 다룹니다. 우리는 13가지 기술적 문제와 솔루션, 그리고 전체적인 문제를 살펴볼 것입니다.
두 번째 기사를 읽고 이 업데이트의 학습을 적용하여 모든 Google 핵심 업데이트에서 승자가 된 방법을 알아보세요.
문제 및 솔루션: 3월 12일 Google Core 업데이트의 영향 수정
3월 12일 핵심 알고리즘 업데이트까지 웹사이트의 모든 것이 분석 데이터를 기반으로 순조롭게 진행되었습니다. Core Algorithm Update에 대한 뉴스가 나온 후 하루 만에 순위가 크게 하락하고 사무실에서 큰 좌절을 겪었습니다. 저는 개인적으로 그날을 보지 못했습니다. 그들이 저를 고용하여 14일 후에 새로운 SEO 프로젝트와 프로세스를 시작하도록 고용했을 때만 도착했기 때문입니다.
[사례 연구] 로그 파일 분석으로 순위, 유기적 방문 및 매출 향상
 사례 연구 읽기
사례 연구 읽기3월 12일 코어 알고리즘 업데이트 이후 회사 웹사이트에 대한 피해 보고서는 다음과 같습니다.
- 36% 유기적 세션 손실
- 65% 클릭 드롭
- 30% CTR 손실
- 33% 유기적 사용자 손실
- 하루에 100,000번의 노출이 손실됩니다.
- 9.72% 노출 손실
- 8,000개의 키워드 손실

이제 사례 연구 기사의 시작 부분에서 언급했듯이 한 가지 질문을 해야 합니다. “다음 코어 알고리즘 업데이트는 언제쯤 될까요?”라고 물어볼 수 없었습니다. 이미 일어난 일이기 때문입니다. 한 가지 질문만 남았습니다.
"Google은 나와 경쟁자 사이에 어떤 다른 기준을 고려했나요?"
위의 차트와 피해 보고서에서 볼 수 있듯이 우리는 주요 트래픽과 키워드를 잃었습니다.
1. 문제: 내부 연결
내부 링크 수, 앵커 텍스트 및 링크 흐름을 처음 확인했을 때 경쟁자가 나보다 앞서 있음을 알았습니다.
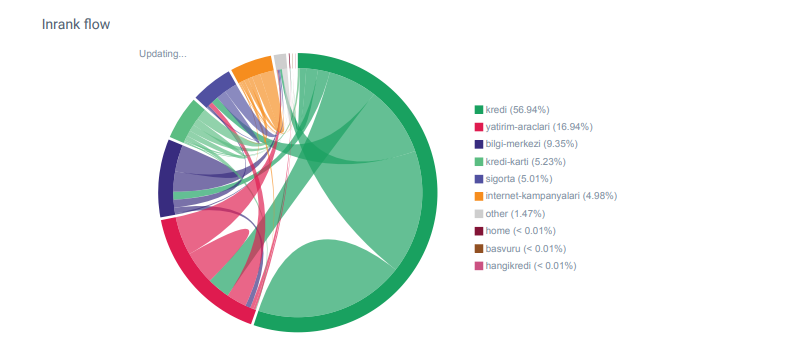
OnCrawl의 Hangikredi.com 카테고리에 대한 Linkflow 보고서
내 주요 경쟁업체에는 수천 개의 앵커 텍스트가 포함된 340,000개 이상의 내부 링크가 있습니다. 요즈음 우리 웹사이트에는 귀중한 앵커 텍스트가 없는 70,000개의 내부 링크만 있었습니다. 또한 내부 링크의 부족은 웹 사이트의 크롤링 예산과 생산성에 영향을 미쳤습니다. 트래픽의 80%가 20개의 제품 페이지에서 수집되었지만 사이트의 90%는 사용자에게 유용한 정보가 포함된 가이드 페이지로 구성되어 있습니다. 재정 쿼리에 대한 대부분의 키워드 및 관련성 점수는 이 페이지에서 가져옵니다. 또한 고아 페이지가 셀 수 없이 너무 많습니다.
내부 연결 구조가 없기 때문에 Kibana로 Log Analysis를 수행했을 때 가장 많이 크롤링된 페이지가 가장 적은 트래픽을 수신한 페이지라는 것을 알았습니다. 또한 이것을 내부 링크 네트워크와 연결했을 때 트래픽이 가장 낮은 회사 페이지(프라이버시, 쿠키, 보안, 회사 소개 페이지)의 내부 링크 수가 최대임을 발견했습니다.
다음 섹션에서 논의하겠지만 이로 인해 Googlebot은 사이트를 크롤링할 때 Pagerank에서 내부 링크 요소를 제거하여 내부 링크가 의도한 대로 구성되지 않았음을 깨달았습니다.
2. 문제: 사이트 아키텍처, 내부 Pagerank, 트래픽 및 크롤링 효율성
Google의 설명에 따르면 내부 링크와 앵커 텍스트는 Googlebot이 웹 페이지의 중요성과 맥락을 이해하는 데 도움이 됩니다. 내부 Pagerank 또는 Inrank는 둘 이상의 요소를 기반으로 계산됩니다. Bill Slawski에 따르면 내부 또는 외부 연결은 모두 동일하지 않습니다. Pagerank 흐름에 대한 링크 값은 위치, 종류, 스타일 및 글꼴 두께에 따라 변경됩니다.

Googlebot이 웹사이트에서 어떤 페이지가 중요한지 이해하면 더 많이 크롤링하고 더 빠르게 색인을 생성합니다. 내부 링크와 올바른 Site-Tree 디자인은 이를 위한 중요한 요소입니다. 다른 전문가들도 수년에 걸쳐 이 상관관계에 대해 논평했습니다.
“대부분의 링크는 앵커 텍스트를 통해 약간의 추가 컨텍스트를 제공합니다. 최소한 그래야 하지 않겠습니까?”
– 존 뮬러, Google 2017"사이트에서 중요하다고 생각하는 페이지가 있다면 15개 링크를 사이트 깊숙이 묻어두지 마세요. 디렉토리 길이에 대해 말하는 것이 아니라 실제에 대해 이야기하고 있는 것입니다. 해당 페이지를 찾으려면 15개 링크를 클릭해야 합니다. 중요하거나 이윤이 크거나 전환율이 매우 높은 페이지가 있는 경우 루트 페이지에서 해당 페이지로 연결되는 링크를 에스컬레이션하는 것이 의미가 있는 부분입니다.”
– Matt Cutts, Google 2011"한 페이지가 "연락처" 또는 "정보"라는 단어로 다른 페이지에 링크되고 링크되는 페이지에 주소가 포함되어 있는 경우 해당 주소 위치는 해당 링크를 수행하는 페이지와 관련된 것으로 간주될 수 있습니다.
변경되었을 수 있는 12가지 Google 링크 분석 방법 - Bill Slawski
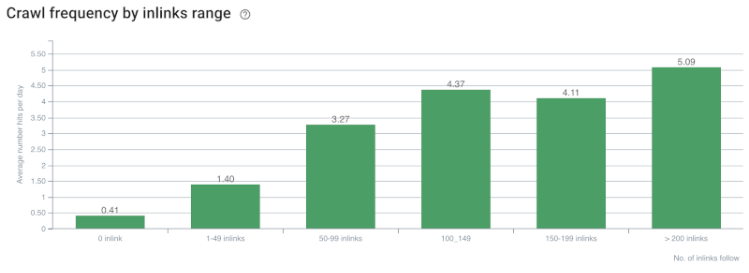
크롤링 속도/수요 및 내부 링크 수 상관 관계. 출처: OnCrawl.
지금까지 우리는 다음과 같은 추론을 할 수 있습니다.
- Google은 클릭 깊이를 중요하게 생각합니다. 웹 페이지가 홈 페이지에 더 가깝다면 더 중요해야 합니다. 이것은 또한 2018년 7월 1일 영어 Google 웹마스터 행아웃에서 John Mueller에 의해 확인되었습니다.
- 웹 페이지에 이를 가리키는 내부 링크가 많이 있는 경우 중요해야 합니다.
- 앵커 텍스트는 웹 페이지에 상황에 맞는 힘을 줄 수 있습니다.
- 내부 링크는 위치, 유형, 글꼴 두께 또는 스타일에 따라 다른 Pagerank 양을 전송할 수 있습니다.
- 검색 엔진 크롤러에 내부 페이지 권한에 대한 명확한 메시지를 제공하는 UX 친화적인 사이트 트리는 Inrank 배포 및 크롤링 효율성을 위한 더 나은 선택입니다.
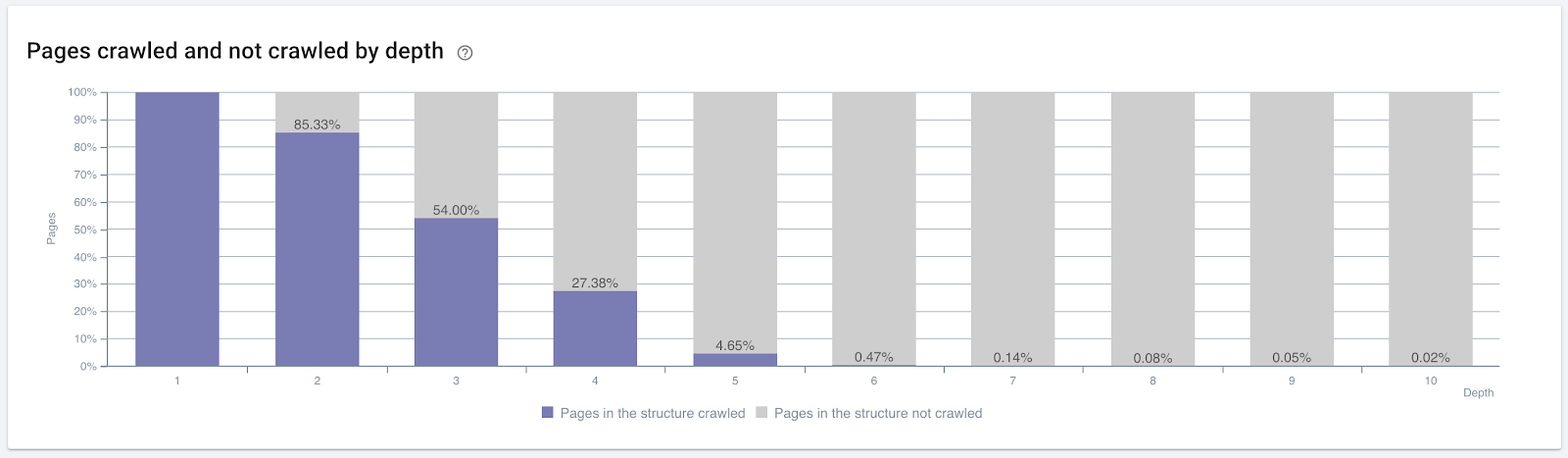
클릭 깊이별로 크롤링된 페이지의 비율입니다. 출처: OnCrawl.
그러나 이는 내부 링크의 특성과 크롤링 효율성에 대한 영향을 이해하는 데 충분하지 않습니다.
온크롤 SEO 크롤러
 더 알아보기
더 알아보기가장 내부적으로 연결된 페이지가 트래픽을 생성하지 않거나 클릭되지 않으면 Site-Tree 및 내부 링크 구조가 사용자 의도에 따라 구성되지 않았음을 나타내는 신호를 제공합니다. 그리고 Google은 항상 사용자 의도 또는 검색 항목이 있는 가장 관련성 높은 페이지를 찾으려고 합니다. 이 주제를 더 명확하게 하는 Bill Slawski의 또 다른 인용이 있습니다.
"리소스가 해당 링크를 사용하여 수신된 트래픽과 관련하여 불균형한 많은 리소스에 의해 링크된 경우 해당 리소스는 순위 프로세스에서 강등될 수 있습니다."
그라운드호그 업데이트가 Google에서 발생한 것입니까? — 빌 슬로스키"선택 품질 점수는 짧은 체류 시간을 초래하는 선택에 대한 선택 품질 점수보다 긴 체류 시간(예를 들어, 임계 시간 기간보다 큼)을 초래하는 선택에 대해 더 높을 수 있습니다."
그라운드호그 업데이트가 Google에서 이루어졌습니까? — 빌 슬로스키
따라서 두 가지 요인이 더 있습니다.
- 링크된 페이지의 체류 시간.
- 링크에 의해 생성된 사용자 트래픽입니다.
내부 링크 수와 스타일/위치가 유일한 요소는 아닙니다. 이러한 링크를 따르는 사용자의 수와 행동 지표도 중요합니다. 또한 클릭하거나 방문한 링크와 페이지는 클릭하거나 방문하지 않은 링크와 페이지보다 훨씬 더 Google에서 크롤링합니다.
"우리는 해당 섹션의 품질을 이해하기 위해 사이트 섹션을 이해하는 방향으로 점점 더 나아갔습니다."
John Mueller, 2017년 5월 2일, 영어 Google 웹마스터 행아웃.
이러한 모든 요소를 고려하여 두 가지 서로 다른 Pagerank 시뮬레이터 결과를 공유하겠습니다.
이러한 Pagerank 계산은 홈페이지를 포함하여 모든 페이지가 동일하다는 가정 하에 이루어집니다. 실제 차이는 링크 계층 구조에 의해 결정됩니다.
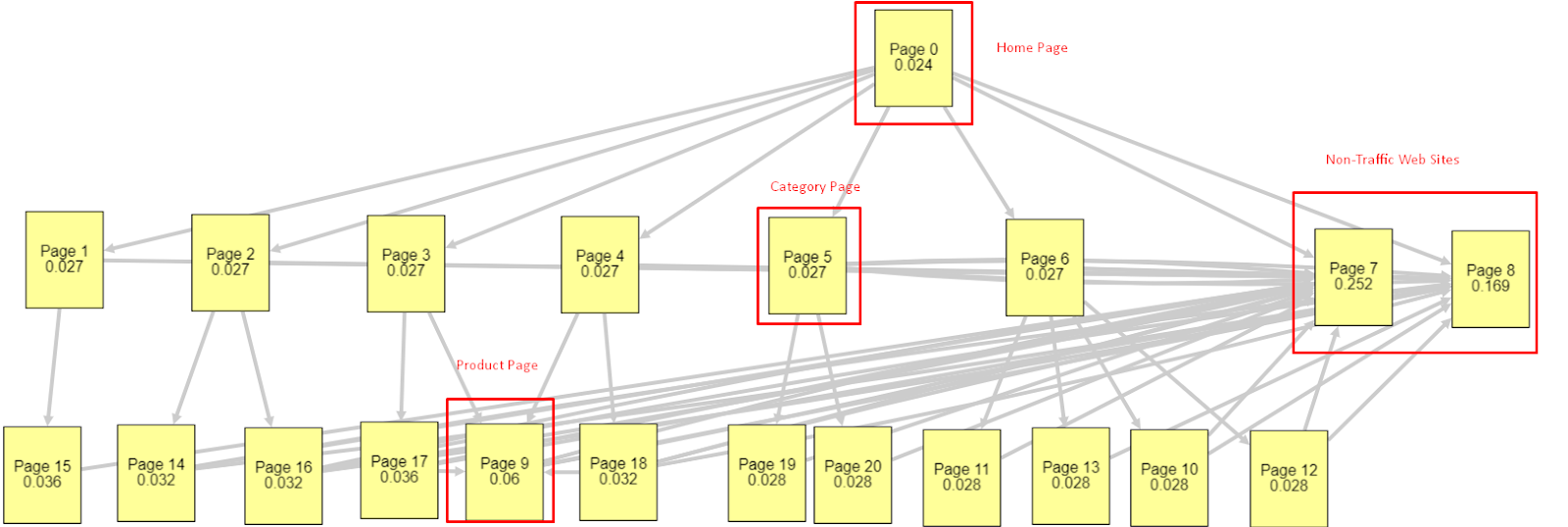
여기에 표시된 예는 3월 12일 이전의 내부 링크 구조에 더 가깝습니다. 홈페이지 PR: 0.024, 카테고리 페이지 PR: 0.027, 제품 페이지 PR: 0.06, 비트래픽 웹 페이지 PR: 0.252.
보시다시피 Googlebot은 내부 페이지 순위와 내부 페이지의 중요성을 계산하기 위해 이 내부 링크 구조를 신뢰할 수 없습니다. 트래픽이 없고 제품이 없는 페이지는 홈페이지보다 12배 더 많은 권한을 갖습니다. 그것은 제품 페이지 이상을 가지고 있습니다.

이 예는 6월 5일 Core Algorithm Update 이전의 상황에 더 가깝습니다. 홈페이지 PR: 0.033, 카테고리 페이지: 0,037, 제품 페이지: 0,148 및 Non-Traffic 페이지의 PR: 0,037입니다.
알다시피 내부 링크 구조는 여전히 옳지 않지만 최소한 Non-Traffic 웹 페이지는 카테고리 페이지 및 제품 페이지보다 PR이 많지 않습니다.
Google이 사용자 흐름 및 요청 및 의도에 따라 Pagerank 범위에서 내부 링크 및 사이트 구조를 제거했다는 추가 증거는 무엇입니까? 물론 Googlebot의 행동과 Inlink Pagerank 및 순위 상관 관계:
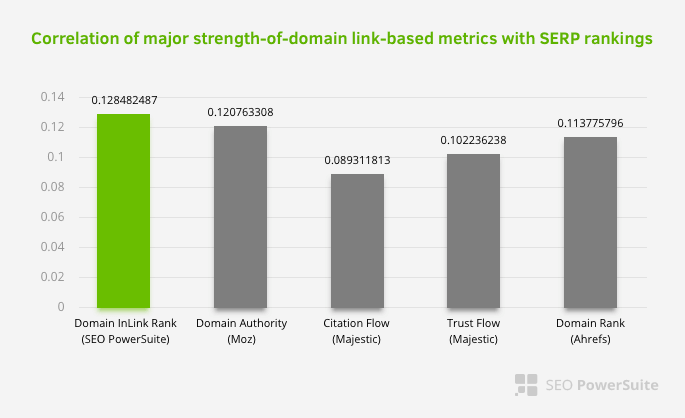
이는 내부 링크 네트워크, 특히 다른 요소보다 더 중요하다는 것을 의미하지는 않습니다. 단일 지점에 초점을 맞춘 SEO 관점은 결코 성공할 수 없습니다. 타사 도구 간의 비교에서 내부 Pagerank 값이 다른 기준과 관련하여 진행되고 있음을 보여줍니다.
Aleh Barysevich의 Inlink Rank 및 순위 상관 연구에 따르면 내부 링크가 가장 많은 페이지가 웹 사이트의 다른 페이지보다 순위가 높습니다. 2019년 3월 4-6일에 실시된 설문 조사에 따르면 33,500개의 키워드에 대한 내부 Pagerank 지표에 따라 1,000,000페이지가 분석되었습니다. SEO PowerSuite에서 수행한 이 연구의 결과는 Moz, Majestic 및 Ahrefs의 다양한 메트릭과 비교되었으며 더 정확한 결과를 제공했습니다.
다음은 3월 12일 핵심 알고리즘 업데이트 이전 사이트의 내부 링크 번호입니다.
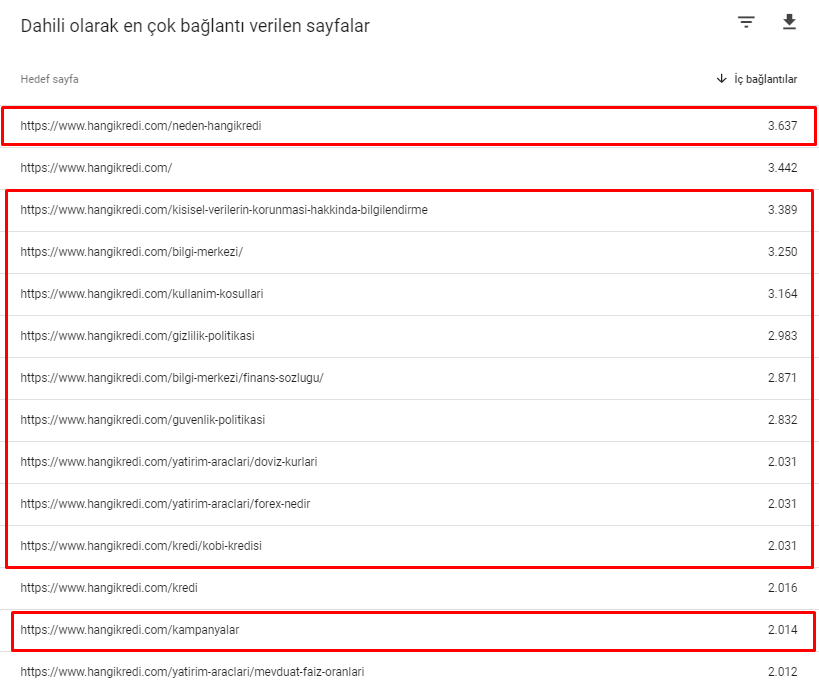
보시다시피 내부 연결 방식은 사용자의 의도와 흐름을 반영하지 않았습니다. 트래픽이 가장 적은 페이지(마이너 제품 페이지) 또는 트래픽이 전혀 발생하지 않는 페이지(빨간색)는 1st Click Depth에 직접 들어가고 홈페이지에서 PR을 받습니다. 그리고 일부는 홈페이지보다 내부 링크가 더 많았습니다.
이 모든 것에 비추어 볼 때 이 주제에 대해 우리가 보여줄 수 있는 것은 마지막 두 가지뿐입니다.
- 내부적으로 가장 많이 연결된 페이지에 대한 크롤링 속도/수요
- 링크 조각 및 Pagerank
2월 1일에서 3월 31일 사이에 Googlebot이 가장 자주 크롤링한 페이지는 다음과 같습니다.
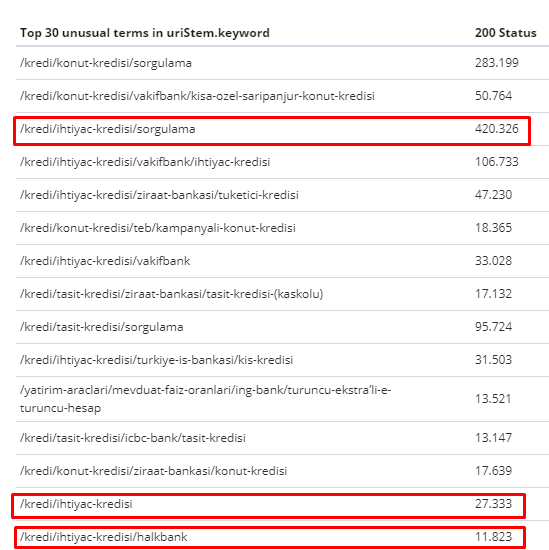
알다시피 크롤링된 페이지와 내부 링크가 가장 많은 페이지는 서로 완전히 다릅니다. 내부 링크가 가장 많은 페이지는 사용자 의도에 적합하지 않았습니다. 그들은 유기적 키워드나 직접적인 SEO 가치가 없습니다. (
빨간색 상자의 URL은 가장 많이 방문하고 중요한 제품 페이지 카테고리입니다. 이 목록의 다른 페이지는 두 번째 또는 세 번째로 많이 방문한 중요 카테고리입니다.)
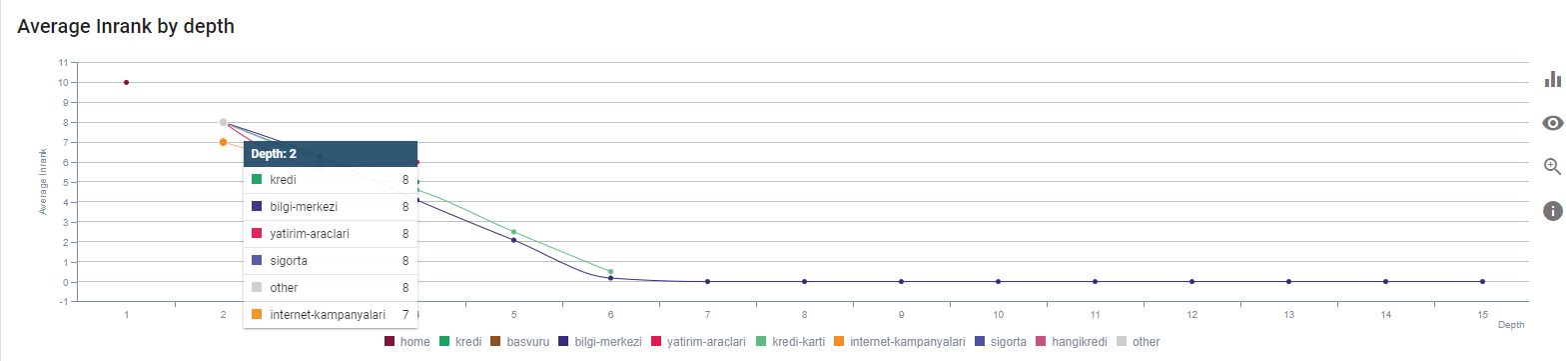
페이지 깊이별 현재 Inrank. 출처: 온크롤.
링크 스컬프팅이란 무엇이며 내부적으로 팔로우하지 않는 링크는 어떻게 해야 합니까?
대부분의 SEO가 생각하는 것과는 달리 "nofollow" 태그가 표시된 링크는 여전히 내부 Pagerank 값을 전달합니다. 저에게는 2009년 6월 15일의 Pagerank Sculpting 기사에서 Matt Cutts보다 이 SEO 요소를 더 잘 설명한 사람이 없습니다.
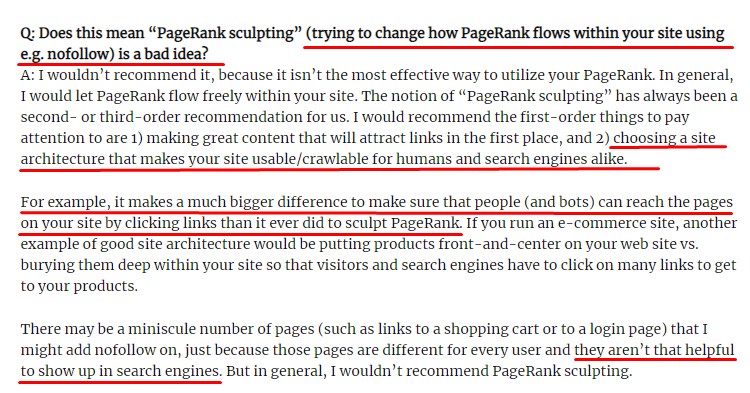
Pagerank Sculpting의 실제 목적을 보여주는 Link Sculpting에 유용한 부분입니다.
"나는 웹사이트 내에서 일종의 PageRank 조각을 위해 nofollow를 사용 하지 않는 것이 좋습니다. 왜냐하면 그것은 아마도 당신이 생각하는 일을 하지 않을 것이기 때문입니다."
– 존 뮬러, Google 2017
Google 및 사용자 측면에서 가치가 없는 웹 페이지가 있는 경우 "nofollow" 태그를 지정해서는 안 됩니다. Pagerank 흐름을 중지하지 않습니다. robots.txt 파일에서 허용하지 않아야 합니다. 이러한 방식으로 Googlebot은 크롤링하지 않을 뿐만 아니라 내부 Pagerank도 전달하지 않습니다. 하지만 10년 전 Matt Cutts가 말했듯이 정말 쓸모없는 페이지에만 이것을 사용해야 합니다. 제휴 마케팅을 위한 자동 리디렉션을 만드는 페이지 또는 콘텐츠가 거의 없는 페이지는 여기에서 몇 가지 편리한 예입니다.
솔루션: 더 우수하고 자연스러운 내부 연결 구조
우리 경쟁자는 불리한 점이 있었습니다. 그들의 웹사이트에는 더 많은 앵커 텍스트와 더 많은 내부 링크가 있었지만 구조가 자연스럽고 유용하지 않았습니다. 동일한 앵커 텍스트가 사이트의 각 페이지에서 동일한 문장과 함께 사용되었습니다. 각 페이지의 입력 단락은 이 반복적인 내용으로 덮여 있었습니다. 모든 사용자와 검색 엔진은 이것이 사용자의 이익을 고려하는 자연스러운 구조가 아님을 쉽게 인식할 수 있습니다.
그래서 내부 링크 구조를 수정하기 위해 세 가지 작업을 수행하기로 결정했습니다.
- 사이트 정보 아키텍처 또는 사이트 트리는 콘텐츠 내에 배치된 링크와 다른 경로를 따라야 합니다. 사용자의 마음과 키워드 신경망을 보다 밀접하게 따라야 합니다.
- 각 콘텐츠에서 사이드 키워드는 타겟 페이지의 메인 키워드와 함께 사용해야 합니다.
- 앵커 텍스트는 자연스럽고 내용에 맞게 조정되어야 하며 사용자의 인식에 주의하면서 각 페이지의 다른 지점에서 사용해야 합니다.
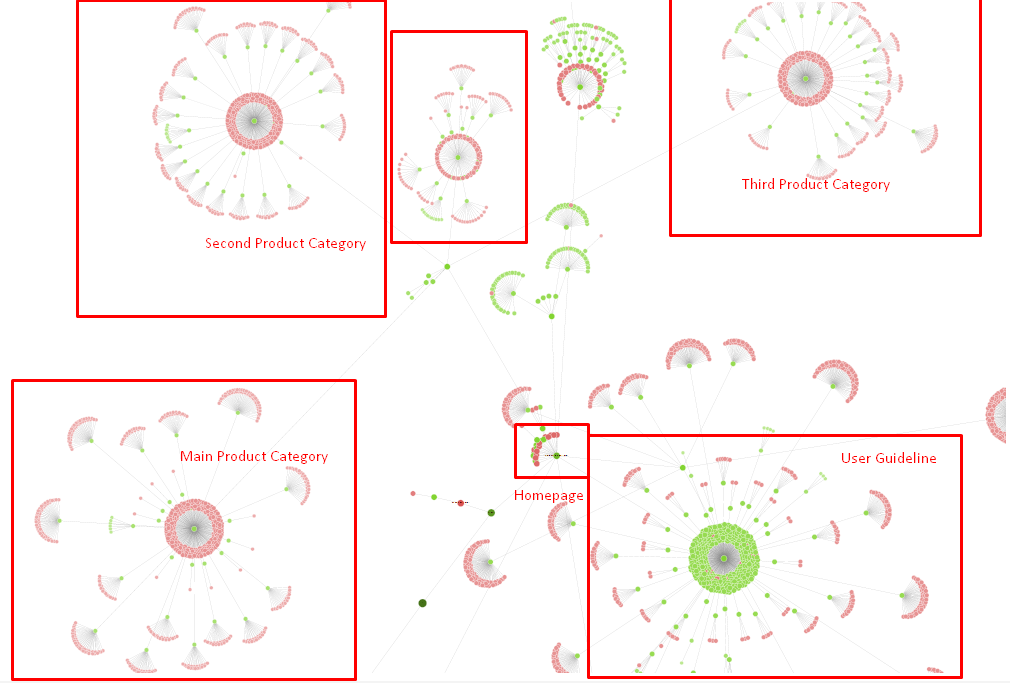
현재 사이트 트리 및 인링크 구조의 일부입니다.
위의 다이어그램에서 현재 내부 링크 링크와 사이트 트리를 볼 수 있습니다.
이 문제를 해결하기 위해 수행한 작업 중 일부는 다음과 같습니다.
- 유용한 앵커로 내부 링크를 30,000개 더 만들었습니다.
- 사용자를 위해 자연스러운 스팟과 키워드를 사용했습니다.
- 내부 연결을 위해 반복적인 문장과 패턴을 사용하지 않았습니다.
- 웹페이지의 Inrank에 대해 Googlebot에 올바른 신호를 보냈습니다.
- Log Analysis를 통해 올바른 내부 링크 구조가 크롤링 효율성에 미치는 영향을 조사한 결과 이전 통계에 비해 주요 제품 페이지가 더 많이 크롤링되었음을 확인했습니다.
- 고아 페이지에 대해 50,000개 이상의 내부 링크를 만들었습니다.
- 하위 페이지에 전원을 공급하기 위해 홈페이지 내부 링크를 사용하고 홈페이지에 더 많은 내부 링크 소스를 만들었습니다.
- Pagerank Power를 보호하기 위해 일부 불필요한 외부 링크에도 nofollow 태그를 사용했습니다. (이것은 내부 링크에 관한 것이 아니지만 동일한 목표를 달성합니다.)
3. 문제: 콘텐츠 구조
Google은 YMYL 웹사이트의 경우 다른 유형의 사이트보다 신뢰성과 권위가 훨씬 더 중요하다고 말합니다.

예전에는 키워드가 키워드였습니다. 그러나 이제 그것들은 또한 잘 정의되고, 독특하고, 의미 있고, 구별할 수 있는 실체 입니다. 우리 콘텐츠에는 4가지 주요 문제가 있었습니다.
- 우리의 내용은 짧았습니다. (보통 내용의 길이는 중요하지 않지만, 이 경우에는 주제에 대한 정보가 충분하지 않았습니다.)
- 우리 작가들의 이름은 하나의 실체가 아니었고, 의미가 없었고, 구별될 수 없었습니다.
- 우리의 콘텐츠는 눈에 띄지 않았습니다. 즉, '패스트푸드' 콘텐츠가 아니었다. 소제목이 없는 내용이었습니다.
- 마케팅 언어를 사용했습니다. 한 단락의 공간에서 브랜드 이름과 사용자를 위한 광고를 식별할 수 있습니다.
- 정보 페이지에서 제품 페이지로 사용자를 보내는 많은 버튼이 있었습니다.
- 우리 제품 페이지의 내용에는 충분한 정보나 포괄적인 지침이 없었습니다.
- 디자인은 사용자 친화적이지 않았습니다. 폰트와 배경색은 기본적으로 같은 색을 사용했습니다. (이는 대부분 인프라 문제로 인해 여전히 그렇습니다.)
- 이미지와 비디오는 콘텐츠의 일부로 간주되지 않았습니다.
- 특정 키워드에 대한 사용자 의도와 검색 의도는 이전에는 중요하게 여겨지지 않았습니다.
- 동일한 주제에 대해 중복되고 불필요하고 반복적인 내용이 많았습니다.
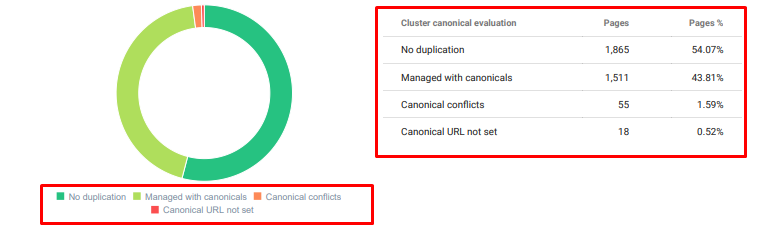
오늘부터 중복 콘텐츠 감사를 Oncrawl합니다.
솔루션: 사용자 신뢰를 위한 더 나은 콘텐츠 구조
사이트 전체의 문제를 확인할 때 사이트 전체의 감사 프로그램을 도우미로 사용하는 것이 SEO 프로젝트에 소요되는 시간을 정리하는 더 좋은 방법입니다. 내부 링크 섹션에서와 같이 다른 도구 및 Xpath 검사와 함께 Oncrawl Site Audit을 사용했습니다.
첫째, 콘텐츠 섹션의 모든 문제를 수정하는 데 너무 많은 시간이 걸렸을 것입니다. 무너지는 위기의 시대에 시간은 사치였습니다. 그래서 나는 다음과 같은 빠른 승리 문제를 해결하기로 결정했습니다.
- 중복, 불필요 및 반복 콘텐츠 삭제
- 포괄적인 정보가 부족한 짧고 얇은 콘텐츠 통합
- 부제목과 시선을 추적할 수 있는 구조가 없는 콘텐츠 재게시
- 콘텐츠의 집중 마케팅 톤 수정
- 콘텐츠에서 많은 클릭 유도문안 버튼 삭제
- 이미지 및 비디오를 통한 더 나은 시각적 커뮤니케이션
- 사용자 및 검색 의도에 맞는 콘텐츠 및 타겟 키워드 만들기
- 신뢰를 위한 콘텐츠에 금융 및 교육 기관 사용 및 표시
- 승인의 사회적 증거 생성을 위한 소셜 커뮤니티 사용
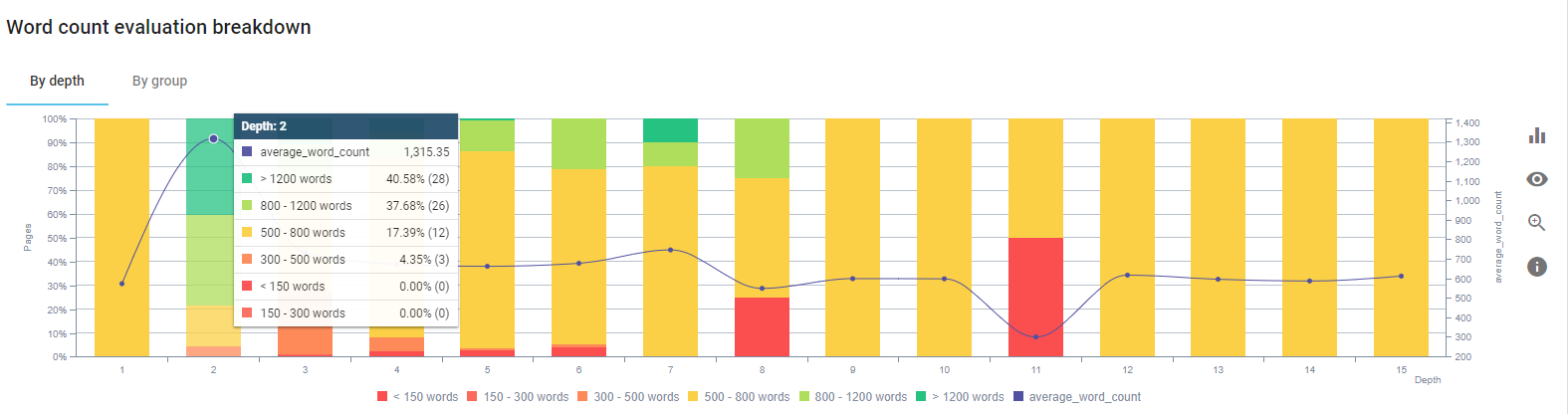

상품 페이지의 내용과 가장 가까운 가이드 페이지의 내용 수정에 집중했습니다.
이 프로세스가 시작될 때 대부분의 제품 및 거래 랜딩/가이드라인 페이지에는 포괄적인 정보 없이 500단어 미만이었습니다.
25일 동안 우리가 수행한 조치는 다음과 같습니다.
- 중복, 불필요, 반복적인 내용이 포함된 228페이지를 삭제했습니다. (삭제하기 전에 씨컨텐츠의 백링크 프로필을 확인했고 Googlebot과의 원활한 커뮤니케이션을 위해 301 또는 410 상태 코드를 사용했습니다.)
- 종합적인 정보가 부족한 123페이지 이상을 합쳤습니다.
- 내용의 중요도와 사용자 요구에 따라 소제목을 사용합니다.
- 마케팅 스타일의 언어로 브랜드 이름과 CTA 버튼을 삭제했습니다.
- 주요 주제를 강화하기 위해 이미지에 텍스트를 포함합니다.
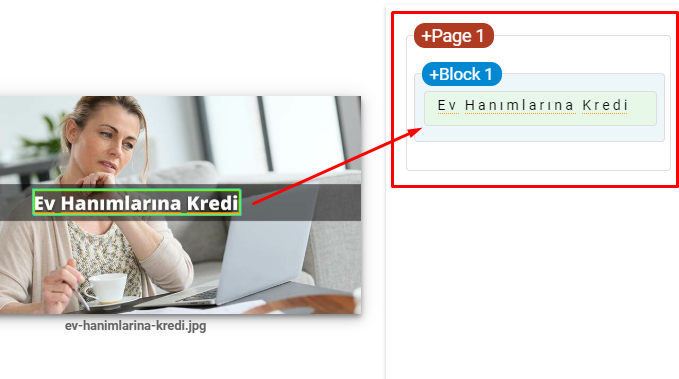
구글의 Vision AI의 스크린샷입니다. Google은 이미지의 텍스트를 읽고 엔티티 내의 감정과 정체성을 감지할 수 있습니다.
- 더 많은 사용자를 유치하기 위해 소셜 네트워크를 활성화했습니다.
- 경쟁사와 우리 사이의 콘텐츠 격차를 조사하고 80개 이상의 새로운 콘텐츠를 만들었습니다.
- Google Analytics, Search Console 및 Google Data Studio를 사용하여 이탈률이 높고 트래픽이 적은 실적이 저조한 페이지를 확인했습니다.
- 추천 스니펫과 키워드 및 콘텐츠 구조를 조사했습니다. 관련 콘텐츠에 동일한 제목과 콘텐츠 구조를 추가했습니다. 이로 인해 추천 스니펫이 증가했습니다.
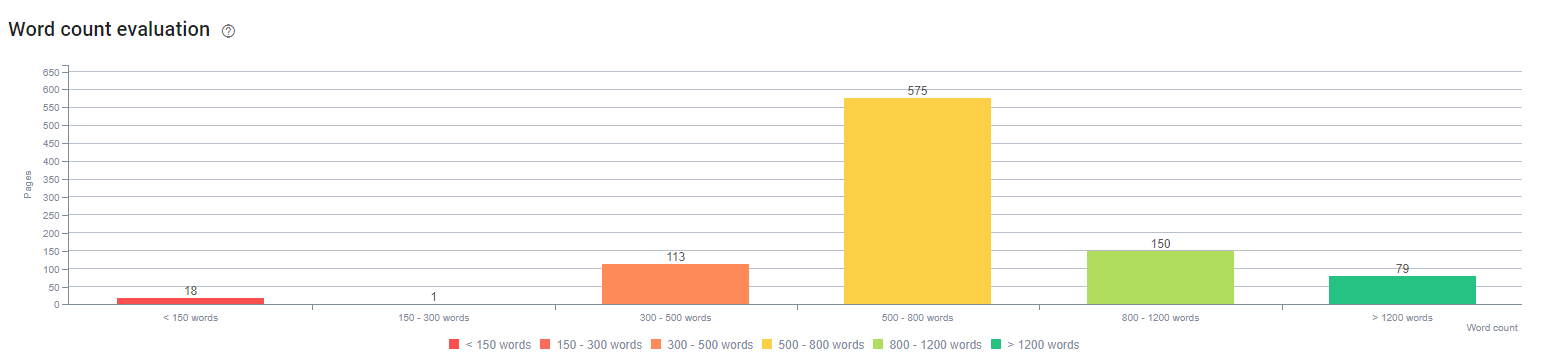
이 과정의 초기에 우리의 콘텐츠는 대부분 150~300단어 사이로 구성되었습니다. 사이트 전체에서 평균적으로 콘텐츠 길이가 350단어 증가했습니다.
4. 문제: 인덱스 오염, 팽창 및 표준 태그
Google은 Index Pollution에 대해 언급한 적이 없으며 사실 누군가가 이전에 이를 SEO 용어로 사용한 적이 있는지 확실하지 않습니다. 더 효율적인 색인 점수를 위해 Google에 의미가 없는 모든 페이지는 Google 색인 페이지에서 제거해야 합니다. 인덱스 오염을 일으키는 페이지는 몇 달 동안 트래픽을 생성하지 않은 페이지입니다. CTR과 자연 키워드가 없습니다. 몇 가지 유기적 키워드가 있는 경우 동일한 키워드에 대해 사이트의 다른 페이지와 경쟁자가 되어야 합니다.
또한 인덱스 bloat에 대한 연구를 수행하여 더 많은 불필요한 인덱스 페이지를 발견했습니다. 이 페이지는 잘못된 사이트 정보 구조 또는 잘못된 URL 구조로 인해 존재했습니다.
이 문제의 또 다른 이유는 표준 태그를 잘못 사용했기 때문입니다. 2년 이상 동안 표준 태그는 Googlebot에 대한 힌트로 취급되었습니다. 그것들이 잘못 사용되면 Googlebot은 사이트를 평가할 때 이를 계산하거나 주의를 기울이지 않습니다. 또한 이 계산의 경우 크롤링 예산을 비효율적으로 사용할 수 있습니다. 잘못된 표준 태그 사용으로 인해 중복 콘텐츠가 포함된 300개 이상의 댓글 페이지가 인덱싱되었습니다.
내 이론의 목표는 클릭을 얻고 사용자에게 가치를 창출할 수 있는 품질과 필수 페이지만 Google에 표시하는 것입니다.
솔루션: 지수 오염 및 팽창 수정
먼저 Google의 John Mueller에게 조언을 받았습니다. 나는 그에게 이 페이지에 대해 NOINDEX 태그를 사용했지만 여전히 Googlebot이 추적하도록 놔두는지 물었습니다. "링크 형평성과 크롤링 효율성을 잃게 될까요?"
짐작할 수 있듯이 그는 처음에는 예라고 말했지만 내부 링크를 사용하면 이 장애물을 극복할 수 있다고 제안했습니다.
또한 dofollow와 동시에 noindex 태그를 사용하면 이 페이지에서 Googlebot의 크롤링 속도가 감소한다는 사실도 발견했습니다. 이러한 전략을 통해 Googlebot이 내 제품과 중요한 가이드라인 페이지를 더 자주 크롤링할 수 있었습니다. 또한 John Mueller가 조언한 대로 내부 링크 구조를 수정했습니다.
짧은 시간 안에:
- 불필요한 색인 페이지가 발견되었습니다.
- 색인에서 300개 이상의 페이지가 제거되었습니다.
- Noindex 태그가 구현되었습니다.
- 색인에서 제거된 페이지에서 링크를 수신한 페이지에 대해 내부 링크 구조가 수정되었습니다.
- 크롤링 효율성과 품질은 시간이 지남에 따라 조사되었습니다.
5. 문제: 잘못된 상태 코드
처음에는 Googlebot이 과거의 삭제된 콘텐츠를 많이 방문한다는 것을 알았습니다. 8년 전의 페이지도 여전히 크롤링되고 있었습니다. 이는 특히 삭제된 콘텐츠에 잘못된 상태 코드를 사용했기 때문입니다.
404 함수와 410 함수 사이에는 큰 차이가 있습니다. 그 중 하나는 콘텐츠가 존재하지 않는 오류 페이지용이고 다른 하나는 삭제된 콘텐츠용입니다. 또한 유효한 페이지에서도 삭제된 소스 및 콘텐츠 URL이 많이 참조되었습니다. 일부 삭제된 이미지와 CSS 또는 JS 자산도 유효한 게시된 페이지에서 리소스로 사용되었습니다. 마지막으로 많은 소프트 404 페이지와 여러 리디렉션 체인, 영구적으로 리디렉션된 페이지에 대한 302-307 임시 리디렉션이 있었습니다.
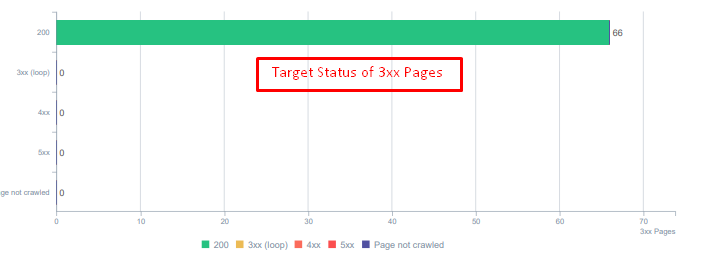
오늘 리디렉션된 자산의 상태 코드입니다.
솔루션: 잘못된 상태 코드 수정
- 모든 404 상태 코드는 410 상태 코드로 변환되었습니다. (30000 이상)
- 상태 코드가 404인 모든 리소스는 유효한 새 리소스로 교체되었습니다. (500개 이상)
- 모든 302-307 리디렉션은 301 영구 리디렉션으로 변환되었습니다. (1500개 이상)
- 사용 중인 자산에서 리디렉션 체인이 제거되었습니다.
- 매월 우리는 로그 분석에서 404 상태 코드를 포함하는 페이지 및 리소스에 대해 25,000회 이상의 조회수를 받았습니다. 이제 매월 404개의 상태 코드에 대해 50개 미만이고 410개 상태 코드에 대해 적중이 0입니다…
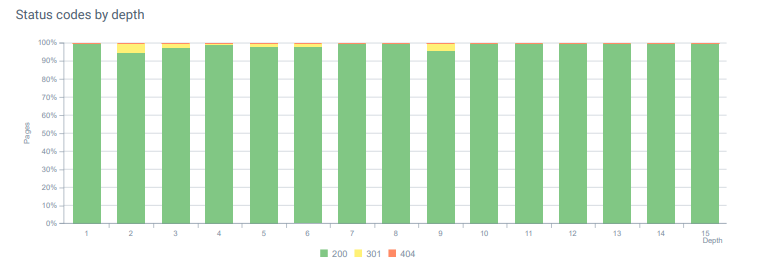
오늘 페이지 깊이 전체의 상태 코드.
6. 문제: 시맨틱 HTML
의미론은 무엇을 의미하는지 나타냅니다. 시맨틱 HTML에는 계층 구조 내에서 페이지 구성 요소에 의미를 부여하는 태그가 포함됩니다. 이 계층적 코드 구조를 사용하면 콘텐츠 일부의 목적이 무엇인지 Google에 알릴 수 있습니다. 또한 Googlebot이 페이지를 완전히 렌더링하는 데 필요한 모든 리소스를 크롤링할 수 없는 경우 최소한 웹페이지 레이아웃과 콘텐츠 부분의 기능을 Googlebot에 지정할 수 있습니다.
Hangikredi.com에서 3월 12일 Google Core Algorithm Update 이후 최적화되지 않은 웹사이트 구조로 인해 크롤링 예산이 충분하지 않다는 것을 알게 되었습니다. 그래서 구글봇이 웹페이지의 목적, 기능, 내용, 유용성을 보다 쉽게 이해할 수 있도록 Semantic HTML을 사용하기로 결정했습니다.
솔루션: 시맨틱 HTML 사용
Google의 품질 평가자 가이드라인에 따르면 모든 검색자는 의도가 있고 모든 웹 페이지에는 그 의도에 따른 기능이 있습니다. 이러한 기능을 Googlebot에 증명하기 위해 Googlebot이 덜 크롤링하는 일부 페이지의 HTML 구조를 일부 개선했습니다.
- 페이지의 주요 내용과 기능을 보여주는 <main> 태그를 사용합니다.
- 탐색 부분에 <nav>를 사용했습니다.
- 사이트 바닥글에 <footer>를 사용했습니다.
- 기사에 <article>을 사용했습니다.
- 모든 제목 태그에 사용된 <section> 태그.
- 콘텐츠의 이미지, 표, 인용문에 <그림>, <표>, <인용> 태그를 사용했습니다.
- 보조 콘텐츠에 사용되는 <aside> 태그입니다.
- H1-H6 계층 문제 수정(Google의 최신 "2개의 H1을 사용하는 것은 문제가 되지 않습니다"라는 문구에도 불구하고 올바른 구조를 사용하면 Googlebot이 도움이 됩니다.)
- 콘텐츠 구조 섹션에서처럼 우리는 또한 추천 스니펫에 시맨틱 HTML을 사용했고 더 많은 추천 스니펫 결과를 위해 테이블과 목록을 사용했습니다.

우리에게 이것은 전체 사이트에 대해 현실적으로 구현할 수 있는 개발이 아니었습니다. 그럼에도 불구하고 모든 디자인 업데이트와 함께 추가 웹 페이지에 대한 의미 체계 HTML 태그를 계속 구현하고 있습니다.
7. 문제: 구조화된 데이터 사용
시맨틱 HTML 사용과 마찬가지로 구조화된 데이터를 사용하여 웹페이지 부분의 기능 및 정의를 Googlebot에 표시할 수 있습니다. 또한 풍부한 결과를 얻으려면 구조화된 데이터가 필수입니다. 우리 웹사이트에서 구조화된 데이터는 3월 말까지 사용되지 않았거나 더 일반적으로 잘못 사용되었습니다. 웹 사이트 및 페이지 외부 계정의 엔터티와 더 나은 관계를 만들기 위해 구조화된 데이터를 구현하기 시작했습니다.
솔루션: 정확하고 테스트된 구조화된 데이터 사용
금융 기관 및 YMYL 웹사이트의 경우 구조화된 데이터는 많은 문제를 해결할 수 있습니다. 예를 들어 브랜드의 아이덴티티, 콘텐츠의 종류를 표시하고 더 나은 스니펫 보기를 만들 수 있습니다. 사이트 전체 및 개별 페이지에 대해 다음과 같은 구조화된 데이터 유형을 사용했습니다.
- 주요 제품 페이지에 대한 FAQ 구조화된 데이터
- 웹페이지 구조화된 데이터
- 조직화 데이터
- 탐색경로 구조화된 데이터
8. 사이트맵 및 Robots.txt 최적화
Hangikredi.com에는 Dynamic Sitemap이 없습니다. 당시 기존 사이트맵에는 필요한 모든 페이지가 포함되어 있지 않고 삭제된 콘텐츠도 포함되어 있었습니다. 또한 Robots.txt 파일에서 수천 개의 외부 링크가 있는 일부 제휴 리퍼러 페이지가 허용되지 않았습니다. 여기에는 콘텐츠와 관련이 없는 일부 타사 JS 파일 및 Googlebot에 불필요한 기타 추가 리소스도 포함되었습니다.
다음 단계가 적용되었습니다.
- 더 나은 크롤링 신호와 더 나은 적용 범위 검사를 위해 사이트 범주에 따라 생성되는 여러 사이트맵에 대해 sitemap_index.xml을 만들었습니다.
- 일부 타사 JS 파일 및 일부 불필요한 JS 파일이 robots.txt 파일에서 허용되지 않았습니다.
- Pagerank 또는 내부 링크 조각 섹션에서 언급했듯이 외부 링크가 있고 방문 페이지 값이 없는 제휴 페이지는 허용되지 않습니다.
- 500개 이상의 적용 범위 문제를 수정했습니다. (대부분 Robots.txt에서 허용하지 않음에도 불구하고 색인이 생성된 페이지였습니다.)
아래 차트에서 크롤링 속도, 로드 및 수요 증가를 확인할 수 있습니다.
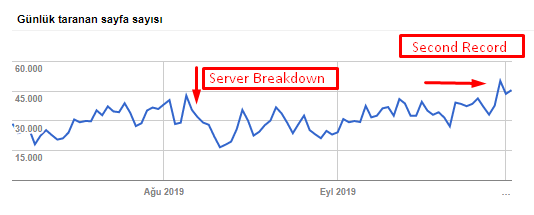
Googlebot이 하루에 크롤링한 페이지 수입니다. 8월 1일까지 매일 크롤링되는 페이지가 꾸준히 증가했습니다. 8월 초 공격으로 서버 장애가 발생한 후 한 달여 만에 안정을 되찾았습니다.

Googlebot의 일일 크롤링 로드는 하루 크롤링된 페이지 수와 함께 발전했습니다.
9. AMP 문제 수정
회사 웹 사이트의 모든 블로그 페이지에는 AMP 버전이 있습니다. 잘못된 코드 구현 및 누락된 AMP 표준으로 인해 모든 AMP 페이지가 색인에서 반복적으로 삭제되었습니다. 이로 인해 지수 점수가 불안정해지고 웹사이트에 대한 신뢰가 부족해졌습니다. 또한 AMP 페이지에는 터키어 콘텐츠에 기본적으로 영어 용어와 단어가 있습니다.
- 표준 태그는 400개 이상의 AMP 페이지에 대해 수정되었습니다.
- 잘못된 코드 구현이 발견되어 수정되었습니다. (주로 AMP-Analytics 및 AMP-Canonical 태그의 잘못된 구현 때문이었습니다.)
- 기본적으로 영어 용어는 터키어로 번역되었습니다.
- 지수 및 순위 안정성은 회사 웹사이트의 블로그 측면을 위해 만들어졌습니다.
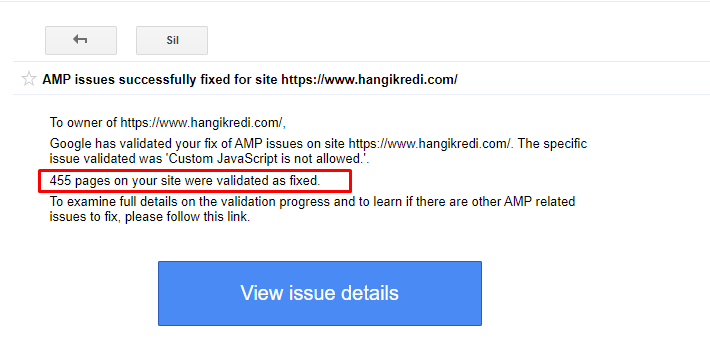
AMP 개선에 대한 GSC의 예시 메시지
10. 메타 태그 문제 및 솔루션
크롤링 예산 문제로 인해 때때로 중요한 주요 제품 페이지에 대한 중요한 검색어에서 Google은 메타 태그의 콘텐츠를 색인화하거나 표시하지 않았습니다. SERP 목록에는 메타 제목 대신 두 단어로 구성된 회사 이름만 표시되었습니다. 스니펫 설명이 표시되지 않았습니다. 이는 CTR을 낮추고 브랜드 아이덴티티를 손상시켰습니다. 아래와 같이 메타 태그를 소스 코드의 맨 위로 이동하여 이 문제를 해결했습니다.
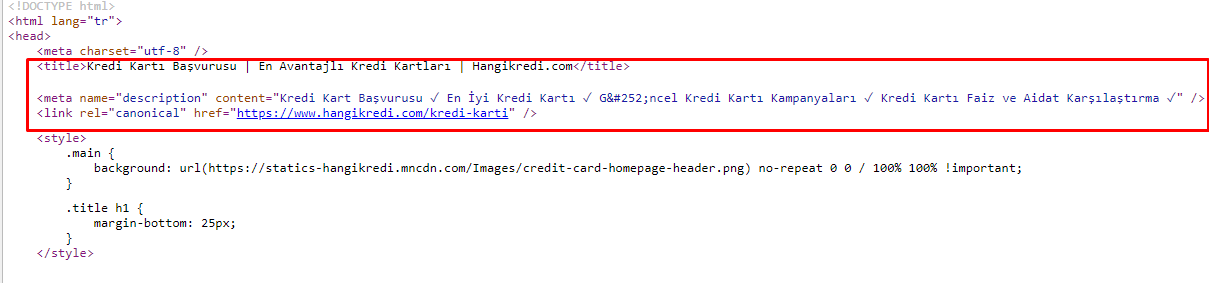
크롤링 예산 외에도 거래 및 정보 페이지에 대해 600개 이상의 메타 태그를 최적화했습니다.
- 모바일 장치에 최적화된 문자 길이.
- 제목에 더 많은 키워드를 사용함
- 다른 스타일의 메타 태그를 사용하고 CTR, 키워드 갭 및 순위 변화를 조사했습니다.
- 이러한 최적화 프로세스 덕분에 보조 키워드를 더 잘 타겟팅하기 위해 올바른 사이트 트리 구조로 더 많은 페이지를 만들었습니다.
- 우리 사이트에는 여전히 Google 알고리즘 및 검색 사용자 CTR을 테스트하기 위한 다양한 메타 제목, 설명 및 제목이 있습니다.
11. 이미지 성능 문제 및 해결 방법
이미지 문제는 두 가지 유형으로 나눌 수 있습니다. 콘텐츠 편의성과 페이지 속도를 위해. 둘 다 회사의 웹 사이트에는 할 일이 많습니다.
부정적인 3월 12일 핵심 알고리즘 업데이트 이후의 3월과 4월:
- 이미지에 대체 태그가 없거나 잘못된 대체 태그가 있습니다.
- 그들은 타이틀이 없었습니다.
- URL 구조가 올바르지 않습니다.
- 그들은 차세대 확장이 없었습니다.
- 그들은 압축되지 않았습니다.
- 그들은 모든 장치 화면 크기에 적합한 해상도를 가지고 있지 않았습니다.
- 자막이 없었습니다.
다음 Google 핵심 알고리즘 업데이트를 준비하려면 다음 단계를 따르세요.
- 이미지가 압축되었습니다.
- 그들의 확장은 부분적으로 변경되었습니다.
- 대부분의 경우 Alt 태그가 작성되었습니다.
- 사용자에 대한 제목과 캡션이 수정되었습니다.
- URL 구조는 사용자에 대해 부분적으로 수정되었습니다.
- 아직 브라우저에서 로드되고 있는 사용하지 않는 이미지를 발견하여 시스템에서 삭제했습니다.
사이트 인프라로 인해 이미지 SEO 수정을 부분적으로 구현했습니다.
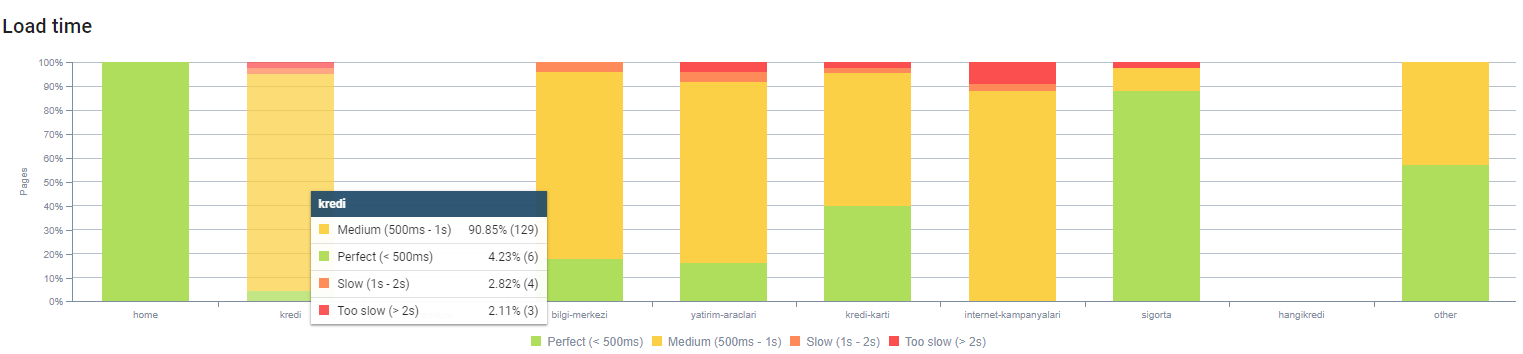
위의 페이지 깊이별로 페이지 로드 시간을 관찰할 수 있습니다. 보시다시피 대부분의 제품 페이지는 여전히 무겁습니다.
12. 캐시, 프리페치 및 프리로드 문제 및 솔루션
3월 12일 핵심 알고리즘 업데이트 이전에는 회사 웹 사이트에 느슨한 캐시 시스템이 있었습니다. 콘텐츠 부분 중 일부는 캐시에 있었지만 일부는 그렇지 않았습니다. 이것은 경쟁사의 제품 페이지보다 2배 느리기 때문에 제품 페이지에서 특히 문제였습니다. 우리 웹 페이지의 대부분의 구성 요소는 실제로 정적 소스이지만 여전히 캐시 범위를 나타내는 Etag가 없습니다.
다음 Google 핵심 알고리즘 업데이트를 준비하려면 다음 단계를 따르세요.
- 모든 웹 페이지에 대해 일부 구성 요소를 캐시하고 정적으로 만들었습니다.
- 이 페이지는 중요한 제품 페이지였습니다.
- 사이트 인프라 때문에 여전히 E-Tags를 사용하지 않습니다.
- 특히 이미지, 정적 리소스 및 일부 중요한 콘텐츠 부분은 이제 사이트 전체에 완전히 캐시됩니다.
- 잊혀진 아웃소싱 리소스에 대해 dns-prefetch 코드를 사용하기 시작했습니다.
- 우리는 여전히 프리로드 코드를 사용하지 않지만 미래에 구현하기 위해 사이트에서 사용자 여정을 작업하고 있습니다.
13. HTML, CSS 및 JS 최적화 및 축소
사이트 인프라 문제로 인해 사이트 속도를 위해 할 일이 많지 않았습니다. 일부 페이지 구성 요소를 삭제하는 것을 포함하여 가능한 모든 방법으로 격차를 좁히려고 노력했습니다. 중요한 제품 페이지의 경우 HTML 코드 구조를 정리하고 축소 및 압축했습니다.
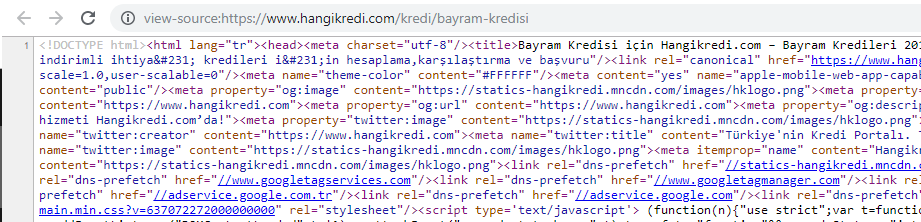
계절적이지만 중요한 제품 페이지의 소스 코드 중 하나의 스크린샷. FAQ 구조화된 데이터, HTML 축소, 이미지 최적화, 콘텐츠 새로고침 및 내부 연결을 사용하여 적시에 1위를 차지했습니다. (키워드는 터키어로 "휴일 크레딧"을 의미하는 "Bayram Kredisi"입니다)
또한 CSS Factoring, Refactoring 및 JS Compression을 부분적으로 작은 단계로 구현했습니다. 순위가 떨어졌을 때 우리는 경쟁자의 페이지와 우리 페이지 사이의 사이트 속도 차이를 조사했습니다. 우리는 속도를 높일 수 있는 긴급한 페이지를 선택했습니다. 또한 이 페이지에서 중요한 CSS 파일을 부분적으로 정제하고 압축했습니다. 우리는 회사의 다른 부서에서 사용하는 일부 타사 JS 파일을 제거하는 프로세스를 시작했지만 아직 제거되지 않았습니다. 일부 제품 페이지의 경우 리소스 로드 순서도 변경할 수 있었습니다.
경쟁사 조사
모든 기술적인 SEO 개선 외에도 경쟁업체를 조사하는 것은 핵심 알고리즘 업데이트의 성격과 목표를 이해하는 데 가장 좋은 가이드였습니다. 나는 경쟁자의 디자인, 내용, 순위 및 기술 변화를 따르기 위해 유용하고 유용한 프로그램을 사용했습니다.
- 키워드 순위 변경에는 Wincher, Semrush 및 Ahrefs를 사용했습니다.
- 브랜드 언급에는 Google 알리미, BuzzSumo, Talkwalker를 사용했습니다.
- 새로운 링크와 새로운 키워드 획득 보고서를 위해 나는 Ahrefs Alert를 사용했습니다.
- 콘텐츠 및 디자인 변경에는 Visualping을 사용했습니다.
- 기술 변화를 위해 나는 SimilarTech를 사용했습니다.
- Google 업데이트 뉴스 및 검사를 위해 Semrush Sensor, Algoroo 및 CognitiveSEO 신호를 주로 사용했습니다.
- 경쟁업체의 URL 이력을 확인하기 위해 Wayback Machine을 사용했습니다.
- 경쟁사의 서버 속도는 Chrome DevTools와 ByteCheck를 사용했습니다.
- 크롤링 및 렌더링 비용에 대해 "내 사이트 비용은 얼마입니까"를 사용했습니다. (Since last month, I have started using Onely's new JS Tools like WWJD or TL:DR..)

A screenshot from SimilarTech for my main competitor.
A screenshot from Visualping which shows the layout changes for my secondary competitor.
Testing the value of the changes
With all of these problems identified and solutions in place, I was ready to see whether the website would hold up to the next Google core algorithm updates.
In the next article, I'll look at the major core algorithm updates over the next several months, and how the site performed.