
Prophet 및 Python으로 SEO 트래픽 예측
게시 됨: 2021-03-16목표를 설정하고 시간이 지남에 따라 성취를 평가하는 것은 우리가 달성할 수 있는 것과 우리가 사용하는 전략이 효과적인지 여부를 이해하기 위해 매우 흥미로운 연습입니다. 그러나 먼저 예측을 해야 하기 때문에 일반적으로 이러한 목표를 설정하는 것이 쉽지 않습니다.
예측을 생성하는 것은 쉬운 일이 아니지만 사용 가능한 몇 가지 예측 절차, CPU 및 일부 프로그래밍 기술 덕분에 복잡성을 상당히 줄일 수 있습니다. 이 게시물에서는 점쟁이의 초능력 없이도 Python과 Prophet 라이브러리를 사용하여 정확한 예측을 수행하는 방법과 이를 SEO에 적용하는 방법을 보여 드리겠습니다.
Prophet에 대해 들어본 적이 없다면 그것이 무엇인지 궁금할 것입니다. 요컨대, Prophet은 Python 및 R에서 사용할 수 있는 Facebook의 Core Data Science 팀에서 발표한 예측을 위한 절차로, 이상치 및 계절적 영향을 매우 잘 처리합니다.
정확하고 빠른 예측을 제공합니다.
예측에 대해 이야기할 때 다음 두 가지를 고려해야 합니다.
- 과거 데이터가 많을수록 모델이 더 정확하므로 예측이 더 정확해집니다.
- 예측 모델은 내부 요인이 동일하게 유지되고 이에 영향을 미치는 외부 요인이 없는 경우에만 유효합니다. 즉, 예를 들어 매주 한 개의 게시물을 게시하고 매주 두 개의 게시물을 게시하기 시작하는 경우 이 모델은 이 전략 변경의 결과를 예측하는 데 유효하지 않을 수 있습니다. 반면에 알고리즘 업데이트가 있는 경우 모델도 유효하지 않을 수 있습니다. 모델은 과거 데이터를 기반으로 구축된다는 점에 유의하십시오.
이것을 SEO에 적용하기 위해 우리가 할 일은 다음 단계에 따라 다음 달의 SEO 세션을 예측하는 것입니다.
- 특정 기간 동안의 유기적 세션에 대한 데이터를 Google 애널리틱스에서 가져옵니다.
- 우리 모델 훈련.
- 다음 달의 SEO 트래픽 예측.
- 평균 절대 오차로 모델이 얼마나 좋은지 평가합니다.
이 예측 절차의 작동 방식에 대해 더 알고 싶습니까? 그럼 시작해봅시다!
Google 애널리틱스에서 데이터 가져오기
일반 인터페이스에서 Excel 파일을 내보내거나 API를 사용하여 이 데이터를 검색하는 두 가지 방법으로 Google Analytics에서 데이터 추출에 접근할 수 있습니다.
Excel 파일에서 데이터 가져오기
Google Analytics에서 이 데이터를 얻는 가장 쉬운 방법은 사이드 바의 채널 섹션으로 이동하여 자연을 클릭하고 페이지 상단에 있는 버튼으로 데이터를 내보내는 것입니다. 그래프 상단의 드롭다운 메뉴에서 분석하려는 변수(이 경우 세션)를 선택했는지 확인합니다.
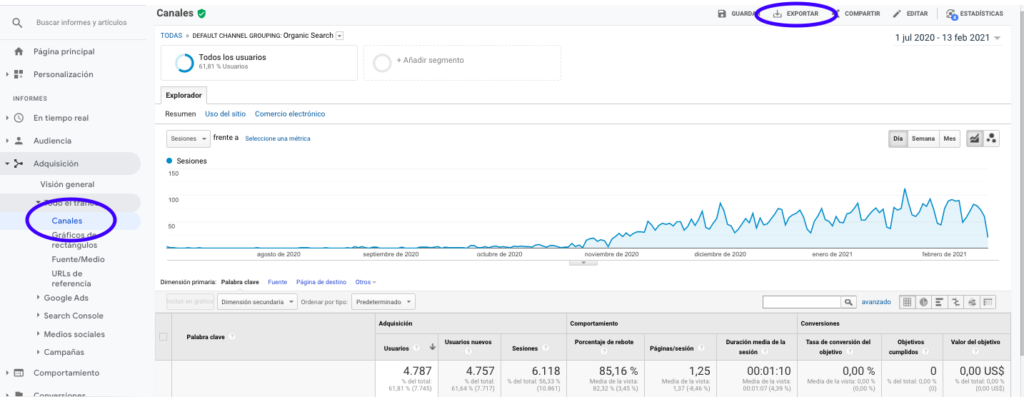
데이터를 Excel 파일로 내보낸 후 Pandas를 사용하여 노트북으로 가져올 수 있습니다. 이러한 데이터가 포함된 Excel 파일에는 다른 탭이 포함되므로 월간 트래픽이 있는 탭은 아래 코드에서 인수로 지정해야 합니다. 또한 마지막 행에 총 세션 수가 포함되어 있으므로 모델을 왜곡할 수 있으므로 마지막 행을 지웁니다.
pandas를 pd로 가져오기
df = pd.read_excel('.xlsx', sheet_name= "")
df = df.drop(len(df) - 1)
Matplotlib으로 데이터가 어떻게 보이는지 그릴 수 있습니다.
matplotlib에서 pyplot 가져오기
df["세션"].plot(제목 = "세션")
pyplot.show() 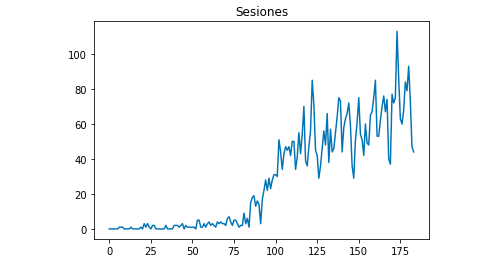
Google 애널리틱스 API 사용
먼저 Google Analytics API를 사용하려면 Google 개발자 콘솔에서 프로젝트를 생성하고 Google Analytics 보고 서비스를 활성화하고 자격 증명을 받아야 합니다. Jean-Christophe Chouinard는 이 기사에서 이것을 설정하는 방법을 아주 잘 설명합니다.
자격 증명을 받으면 요청하기 전에 인증해야 합니다. 인증은 처음에 Google 개발자 콘솔에서 얻은 자격 증명 파일로 수행해야 합니다. 또한 사용하려는 속성의 GA 보기 ID를 코드에 기록해야 합니다.
apiclient.discovery 가져오기 빌드에서
oauth2client.service_account에서 ServiceAccountCredentials 가져오기
범위 = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = ''
보다_
자격 증명 = ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE_LOCATION, SCOPES)
분석 = build('analyticsreporting', 'v4', 자격 증명=자격 증명)인증 후에는 요청만 하면 됩니다. 매일의 유기적 세션에 대한 데이터를 얻는 데 사용해야 하는 것은 다음과 같습니다.
응답 = analytics.reports().batchGet(본문={
'보고 요청': [{
'viewId': VIEW_ID,
'dateRanges': [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}],
'측정항목': [
{"표현": "가:세션"}
], "차원": [
{"이름": "가:날짜"}
],
"filtersExpression":"ga:channelGrouping=~유기적",
"includeEmptyRows": "참"
}]}).실행하다()dateRanges에서 시간 범위를 선택합니다. 제 경우에는 9월 1일부터 1월 31일까지 데이터를 검색할 예정입니다. [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}]
그 후에 우리는 유기 세션이 있는 날 목록에 추가할 응답 파일만 가져와야 합니다.
목록 값 = [] x에 대한 응답["reports"][0]["data"]["rows"]: list_values.append([x["차원"][0],x["메트릭"][0]["값"][0]])
보시다시피 Google Analytics API를 사용하는 것은 매우 간단하며 많은 목적에 사용할 수 있습니다. 이 기사에서는 Google Analytics API를 사용하여 실적이 저조한 페이지를 감지하는 알림을 생성하는 방법을 설명했습니다.

목록을 데이터 프레임에 적용하기
Prophet을 사용하려면 "ds"와 "y"라는 이름을 지정해야 하는 두 개의 열이 있는 데이터 프레임을 입력해야 합니다. Excel 파일에서 데이터를 가져온 경우 이미 데이터 프레임으로 가지고 있으므로 열 이름을 "ds" 및 "y"로 지정하기만 하면 됩니다.
df.columns = ['ds', 'y']
API를 사용하여 데이터를 검색한 경우 목록을 데이터 프레임으로 변환하고 필요에 따라 열 이름을 지정해야 합니다.
팬더에서 DataFrame 가져오기 df_sessions = DataFrame(목록 값, 열=['ds','y'])
모델 훈련
필요한 형식의 데이터 프레임이 있으면 다음을 사용하여 모델을 매우 쉽게 결정하고 훈련할 수 있습니다.
가져오기 fbprophet fbprophet에서 가져오기 예언자 모델 = 예언자() model.fit(df_sessions)
예측하기
마지막으로 모델을 훈련시킨 후 예측을 시작할 수 있습니다! 예측을 진행하려면 먼저 예측하고 날짜/시간 형식을 조정하려는 시간 범위가 포함된 목록을 만들어야 합니다.
팬더에서 to_datetime으로 가져오기 Forecast_days = [] 범위(1, 28)의 x에 대해: 날짜 = "2021-02-" + str(x) Forecast_days.append([날짜]) Forecast_days = DataFrame(forecast_days) Forecast_days.columns = ['ds'] Forecast_days['ds']= to_datetime(forecast_days['ds'])
이 예제에서는 2월의 모든 날짜를 포함할 데이터 프레임을 생성하는 루프를 사용합니다. 이제 이전에 훈련된 모델을 사용하기만 하면 됩니다.
예측 = model.predict(forecast_days)
예측 기간을 강조 표시하는 플롯을 그릴 수 있습니다.
matplotlib에서 pyplot 가져오기 model.plot(예측) pyplot.show()
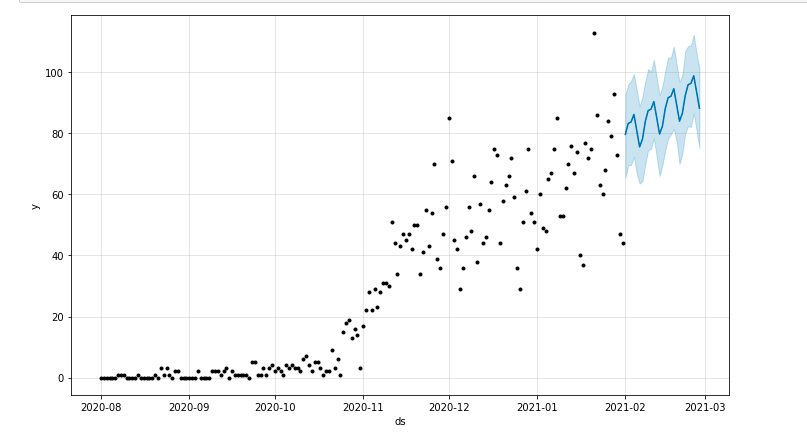
모델 평가
마지막으로 모델을 훈련하는 데 사용되는 데이터에서 며칠을 제거하고 해당 날짜의 세션을 예측하고 평균 절대 오차를 계산하여 모델이 얼마나 정확한지 평가할 수 있습니다.
예를 들어, 원래 데이터 프레임에서 1월부터 지난 12일을 제거하여 매일 세션을 예측하고 실제 트래픽과 예측된 트래픽을 비교하려고 합니다.
먼저 원래 데이터 프레임에서 pop을 사용하여 마지막 12일을 제거하고 예측에 사용될 12일만 포함하는 새 데이터 프레임을 만듭니다.
기차 = df_sessions.drop(df_sessions.index[-12:]) 미래 = df_sessions.loc[df_sessions["ds"]> train.iloc[len(train)-1]["ds"]]["ds"]
이제 우리는 모델을 훈련하고 예측을 하고 평균 절대 오차를 계산합니다. 결국 실제 예측 값과 실제 값의 차이를 보여주는 플롯을 그릴 수 있습니다. 이것은 Jason Brownlee가 작성한 이 기사에서 배운 것입니다.
sklearn.metrics에서 mean_absolute_error 가져오기
numpy를 np로 가져오기
numpy 가져오기 배열에서
#우리는모델을훈련시킨다
모델 = 예언자()
model.fit(기차)
#예측일에 사용되는 데이터 프레임을 Prophet의 필수 형식으로 조정합니다.
미래 = 목록(미래)
미래 = DataFrame(미래)
미래 = future.rename(열={0: 'ds'})
# 우리는 예측을 한다
예측 = model.predict(미래)
# 실제 값과 예측 값 사이의 MAE를 계산합니다.
y_true = df_sessions['y'][-12:].값
y_pred = 예측['yhat'].값
mae = mean_absolute_error(y_true, y_pred)
# 시각적 이해를 위해 최종 출력을 플로팅합니다.
y_true = np.stack(y_true).astype(float)
pyplot.plot(y_true, 레이블='실제')
pyplot.plot(y_pred, 레이블='예측')
pyplot.legend()
pyplot.show()
인쇄(매) 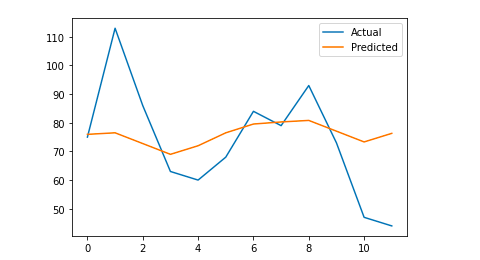
내 평균 절대 오차는 13이며, 이는 내 예측 모델이 실제 세션보다 매일 13개 더 많은 세션을 할당한다는 것을 의미하며, 이는 허용 가능한 오류인 것 같습니다.
그게 다야! 이 기사가 흥미롭고 목표를 설정하기 위해 SEO 예측을 시작할 수 있기를 바랍니다.
더 나아가기: OnCrawl Labs
이 방법으로 트래픽 예측을 즐겼다면 SEO 워크플로를 위해 사전 코딩된 프로젝트를 제공하는 OnCrawl의 데이터 과학 및 기계 학습 연구소인 OnCrawl Labs에도 관심이 있을 것입니다.
SEO 예측에서 OnCrawl Labs는 SEO 예측을 구체화하는 데 도움이 됩니다.
- Facebook Prophet 알고리즘 이면의 이론과 프로세스를 더 잘 이해합니다.
- 롱테일 키워드의 트래픽 또는 브랜드 키워드의 트래픽과 같은 트래픽 세그먼트를 분석합니다.
- 단계별 프로세스에 따라 역사적 사건을 설정하고 영향력과 재발 가능성을 조정하십시오.