
HTML 페이지에서 관련 텍스트 콘텐츠를 추출하는 방법은 무엇입니까?
게시 됨: 2021-10-13문맥
Oncrawl의 R&D 부서에서는 웹 페이지의 의미론적 콘텐츠에 가치를 더하기 위해 점점 더 많은 노력을 기울이고 있습니다. 자연어 처리(NLP)용 머신 러닝 모델을 사용하면 SEO에 대한 실질적인 부가가치가 있는 작업을 수행할 수 있습니다.
이러한 작업에는 다음과 같은 활동이 포함됩니다.
- 페이지 콘텐츠 미세 조정
- 자동 요약 만들기
- 기사에 새 태그 추가 또는 기존 태그 수정
- Google Search Console 데이터에 따라 콘텐츠 최적화
- 등.
이 모험의 첫 번째 단계는 이러한 기계 학습 모델이 사용할 웹 페이지의 텍스트 콘텐츠를 추출하는 것입니다. 웹 페이지에 대해 이야기할 때 여기에는 HTML, JavaScript, 메뉴, 미디어, 머리글, 바닥글 등이 포함됩니다. 콘텐츠를 자동으로 올바르게 추출하는 것은 쉽지 않습니다. 이 기사를 통해 나는 문제를 탐구하고 이 작업을 달성하기 위한 몇 가지 도구와 권장 사항에 대해 논의할 것을 제안합니다.
문제
웹 페이지에서 텍스트 콘텐츠를 추출하는 것은 간단해 보일 수 있습니다. 예를 들어, 몇 줄의 Python, 예를 들어 몇 가지 정규식(regexp), BeautifulSoup4와 같은 구문 분석 라이브러리만 있으면 완료됩니다.
Vue.js나 React와 같은 JavaScript 렌더링 엔진을 사용하는 사이트가 점점 더 많아지고 있다는 사실을 몇 분 동안 무시한다면 HTML 구문 분석은 그리 복잡하지 않습니다. 크롤링에서 JS 크롤러를 활용하여 이 문제를 자세히 알아보려면 "JavaScript에서 사이트를 크롤링하는 방법"을 읽어보시기 바랍니다.
그러나 우리는 가능한 한 유익한 텍스트를 추출하고자 합니다. 예를 들어 John Coltrane의 마지막 사후 앨범에 대한 기사를 읽을 때 메뉴, 바닥글 등을 무시하고 ... 분명히 전체 HTML 콘텐츠를 보고 있지 않습니다. 거의 모든 페이지에 나타나는 이러한 HTML 요소를 상용구라고 합니다. 우리는 그것을 없애고 관련 정보를 전달하는 텍스트의 일부만 유지하기를 원합니다.
따라서 처리를 위해 기계 학습 모델에 전달하려는 것은 이 텍스트뿐입니다. 그렇기 때문에 추출이 가능한 한 정성적이어야 합니다.
솔루션
전반적으로 메뉴 및 기타 사이드바, 연락처 요소, 바닥글 링크 등 메인 텍스트에 "주워있는" 모든 것을 제거하고 싶습니다. 이를 수행하는 방법에는 여러 가지가 있습니다. 우리는 주로 Python 또는 JavaScript의 오픈 소스 프로젝트에 관심이 있습니다.
저스트텍스트
jusText는 "Web Corpora에서 상용구 및 중복 콘텐츠 제거"라는 박사 논문에서 제안된 Python 구현입니다. 이 방법을 사용하면 HTML의 텍스트 블록을 다양한 휴리스틱에 따라 "좋음", "나쁨", "너무 짧음"으로 분류할 수 있습니다. 이러한 경험적 방법은 대부분 단어 수, 텍스트/코드 비율, 링크의 유무 등에 기반합니다. 알고리즘에 대한 자세한 내용은 설명서를 참조하세요.
트라필라투라
Python에서도 생성된 trafilatura는 HTML 요소 유형과 콘텐츠(예: 텍스트 길이, HTML 요소의 위치/깊이 또는 단어 수)에 대한 경험적 방법을 제공합니다. trafilatura는 또한 jusText를 사용하여 일부 처리를 수행합니다.
가독성
Firefox의 URL 표시줄에 있는 버튼을 본 적이 있습니까? 독자 보기입니다. HTML 페이지에서 상용구를 제거하여 주요 텍스트 내용만 유지할 수 있습니다. 뉴스 사이트에 사용하기에 매우 실용적입니다. 이 기능 뒤에 있는 코드는 JavaScript로 작성되었으며 Mozilla에서는 가독성이라고 합니다. Arc90 연구소에서 시작한 작업을 기반으로 합니다.
다음은 France Musique 웹사이트의 기사에 대해 이 기능을 렌더링하는 방법의 예입니다. 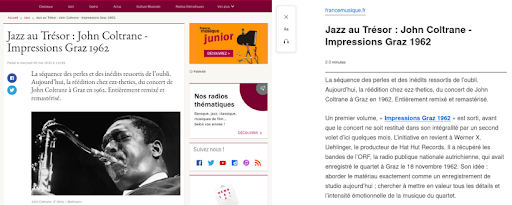
왼쪽은 원본 기사에서 발췌한 것입니다. 오른쪽은 Firefox의 리더 보기 기능을 렌더링한 것입니다.
기타
HTML 콘텐츠 추출 도구에 대한 연구를 통해 다음과 같은 다른 도구도 고려하게 되었습니다.
- 신문: 뉴스 사이트 전용 콘텐츠 추출 라이브러리(Python). 이 라이브러리는 OpenWebText2 말뭉치에서 콘텐츠를 추출하는 데 사용되었습니다.
- Boilerpy3은 Boilerpipe 라이브러리의 Python 포트입니다.
- dragnet Python 라이브러리도 Boilerpipe에서 영감을 받았습니다.
온크롤 데이터³
 더 알아보기
더 알아보기평가 및 권장 사항
다양한 도구를 평가하고 비교하기 전에 NLP 커뮤니티에서 이러한 도구 중 일부를 사용하여 말뭉치(큰 문서 세트)를 준비하는지 알고 싶었습니다. 예를 들어, GPT-Neo를 훈련하는 데 사용된 The Pile이라는 데이터 세트에는 Wikipedia, Openwebtext2, Github, CommonCrawl 등의 +800GB 영어 텍스트가 있습니다. BERT와 마찬가지로 GPT-Neo는 유형 변환기를 사용하는 언어 모델입니다. GPT-3 아키텍처와 유사한 오픈 소스 구현을 제공합니다.

"The Pile: An 800GB Dataset of Diverse Text for Language Modeling" 기사에서는 CommonCrawl에서 코퍼스의 많은 부분에 대해 jusText를 사용한다고 언급합니다. 이 연구원 그룹은 다양한 추출 도구에 대한 벤치마크도 수행할 계획이었습니다. 불행히도 그들은 자원 부족으로 계획된 작업을 수행하지 못했습니다. 그들의 결론에서 다음 사항에 유의해야 합니다.
- jusText는 때때로 너무 많은 콘텐츠를 제거했지만 여전히 좋은 품질을 제공했습니다. 그들이 가지고 있는 데이터의 양을 감안할 때 이것은 그들에게 문제가 되지 않았습니다.
- trafilatura는 HTML 페이지의 구조를 유지하는 데 더 좋았지만 너무 많은 상용구를 유지했습니다.
평가 방법으로 약 30개의 웹 페이지를 사용했습니다. 주요 내용을 "수동으로" 추출했습니다. 그런 다음 다른 도구의 텍스트 추출을 이 소위 "참조" 콘텐츠와 비교했습니다. 주로 자동 텍스트 요약을 평가하는 데 사용되는 ROUGE 점수를 메트릭으로 사용했습니다.
또한 이러한 도구를 HTML 구문 분석 규칙을 기반으로 하는 "집에서 만든" 도구와 비교했습니다. trafilatura, jusText 및 우리 집에서 만든 도구가 이 측정항목에 대한 대부분의 다른 도구보다 더 나은 것으로 나타났습니다.
다음은 ROUGE 점수의 평균 및 표준 편차 표입니다.
| 도구 | 평균 | 표준 |
|---|---|---|
| 트라필라투라 | 0.783 | 0.28 |
| 온크롤 | 0.779 | 0.28 |
| 저스트텍스트 | 0.735 | 0.33 |
| 보일러3 | 0.698 | 0.36 |
| 가독성 | 0.681 | 0.34 |
| 저인망 | 0.672 | 0.37 |
표준 편차 값의 관점에서 추출의 품질은 크게 다를 수 있습니다. HTML이 구현되는 방식, 태그의 일관성, 언어의 적절한 사용은 추출 결과에 많은 변화를 일으킬 수 있습니다.
최고의 성능을 발휘하는 세 가지 도구는 행사를 위해 "oncrawl"이라는 사내 도구인 trafilatura와 jusText입니다. jusText는 trafilatura의 대체 수단으로 사용되므로 trafilatura를 첫 번째 선택으로 사용하기로 결정했습니다. 그러나 후자가 실패하고 0개의 단어를 추출하는 경우 자체 규칙을 사용합니다.
trafilatura 코드는 수백 페이지에 대한 벤치마크도 제공합니다. 추출된 콘텐츠에서 특정 요소의 유무에 따라 정밀도 점수, f1 점수 및 정확도를 계산합니다. trafilatura와 goose3의 두 가지 도구가 눈에 띕니다. 다음을 읽을 수도 있습니다.
- 웹에서 콘텐츠를 추출하는 올바른 도구 선택(2020)
- Github 저장소: 기사 추출 벤치마크: 오픈 소스 라이브러리 및 상용 서비스
결론
HTML 코드의 품질과 페이지 유형의 이질성으로 인해 양질의 콘텐츠를 추출하기 어렵습니다. The Pile과 GPT-Neo 뒤에 있는 EleutherAI 연구원들이 발견했듯이 완벽한 도구는 없습니다. 모든 상용구가 제거되지 않은 경우 텍스트에서 가끔 잘리는 콘텐츠와 잔여 노이즈 사이에 절충점이 있습니다.
이러한 도구의 장점은 컨텍스트가 없다는 것입니다. 즉, 콘텐츠를 추출하기 위해 페이지의 HTML 이외의 데이터가 필요하지 않습니다. Oncrawl의 결과를 사용하여 사이트의 모든 페이지에서 특정 HTML 블록의 발생 빈도를 사용하여 상용구로 분류하는 하이브리드 방법을 상상할 수 있습니다.
웹에서 본 벤치마크에 사용된 데이터 세트는 뉴스 기사 또는 블로그 게시물과 같은 페이지 유형인 경우가 많습니다. 보험, 여행사, 전자 상거래 등 텍스트 콘텐츠가 추출하기 더 복잡한 경우가 있는 사이트는 여기에 포함되지 않습니다.
벤치마크와 관련하여 리소스 부족으로 인해 30페이지 정도는 점수를 더 자세히 보기에 충분하지 않다는 것을 알고 있습니다. 이상적으로는 벤치마크 값을 개선하기 위해 더 많은 수의 다른 웹 페이지를 사용하는 것이 좋습니다. 또한 goose3, html_text 또는 inscriptis와 같은 다른 도구도 포함하고 싶습니다.