
A/B 테스트 통계적 의미: 테스트를 종료하는 방법 및 시기
게시 됨: 2020-05-22
Convert 고객이 실행한 28,304개의 실험에 대한 최근 분석에서 20%의 실험만 이 95%의 통계적 유의 수준에 도달하는 것으로 나타났습니다. Econsultancy는 2018 최적화 보고서에서 유사한 추세를 발견했습니다. 응답자의 2/3는 실험의 30% 이하에서만 "명확하고 통계적으로 유의미한 승자"를 보았습니다.
따라서 대부분의 실험(70-80%)은 결정적이지 않거나 조기에 중단됩니다.
이들 중 일찍 중단된 것은 최적화 프로그램이 적합하다고 판단될 때 실험을 종료하기 위해 전화를 걸기 때문에 흥미로운 경우를 만듭니다. 그들은 명백한 승자(또는 패자) 또는 명백히 하찮은 테스트를 "볼" 수 있을 때 그렇게 합니다. 일반적으로 이를 정당화할 수 있는 데이터도 있습니다.
옵티마이저의 50%가 실험을 위한 표준 "정지 지점"이 없다는 점을 감안하면 이는 그리 놀라운 일이 아닐 수 있습니다. 대부분의 경우 특정 테스트 속도(XXX 테스트/월)를 유지해야 하는 압력과 경쟁에서 우위를 점하기 위한 경쟁 때문에 그렇게 하는 것이 필요합니다.
또한 부정적인 실험이 수익을 저해할 가능성도 있습니다. 자체 연구에 따르면 낙찰되지 않은 실험은 평균적으로 전환율을 26% 감소시킬 수 있습니다 !
실험을 일찍 끝내는 것은 여전히 위험합니다…
... 올바른 표본 크기에 의해 실험이 의도한 길이만큼 실행될 확률을 남겨두기 때문에 결과가 다를 수 있습니다.
그렇다면 실험을 일찍 종료하는 팀은 실험을 종료해야 할 때를 어떻게 알 수 있을까요? 대부분의 경우 답변은 품질을 손상시키지 않으면서 의사 결정 속도를 높이는 중지 규칙을 고안하는 데 있습니다.
전통적인 정지 규칙에서 벗어나기
웹 실험의 경우 p-값 0.05가 표준으로 사용됩니다. 이 5%의 오류 허용 오차 또는 95%의 통계적 유의 수준은 최적화 프로그램이 테스트의 무결성을 유지하는 데 도움이 됩니다. 그들은 결과가 우연이 아닌 실제 결과임을 보장할 수 있습니다.
고정된 수평 테스트를 위한 기존 통계 모델(테스트 데이터가 고정된 시간 또는 특정 수의 참여 사용자에서 한 번만 평가됨)에서는 p-값이 0.05보다 낮을 때 결과를 유의미한 것으로 받아들입니다. 이 시점에서 통제와 치료가 동일하고 관찰된 결과가 우연이 아니라는 귀무가설을 기각할 수 있습니다.
수집되는 데이터를 평가할 수 있는 기능을 제공하는 통계 모델과 달리 이러한 테스트 모델은 실험이 실행되는 동안 실험 데이터를 보는 것을 금지합니다. 엿보기라고도 하는 이 방법은 p-값이 거의 매일 변동하기 때문에 이러한 모델에서는 권장되지 않습니다. 실험이 어느 날 의미가 있고 그 다음날 p-값이 더 이상 의미가 없는 지점까지 상승한다는 것을 알 수 있습니다.
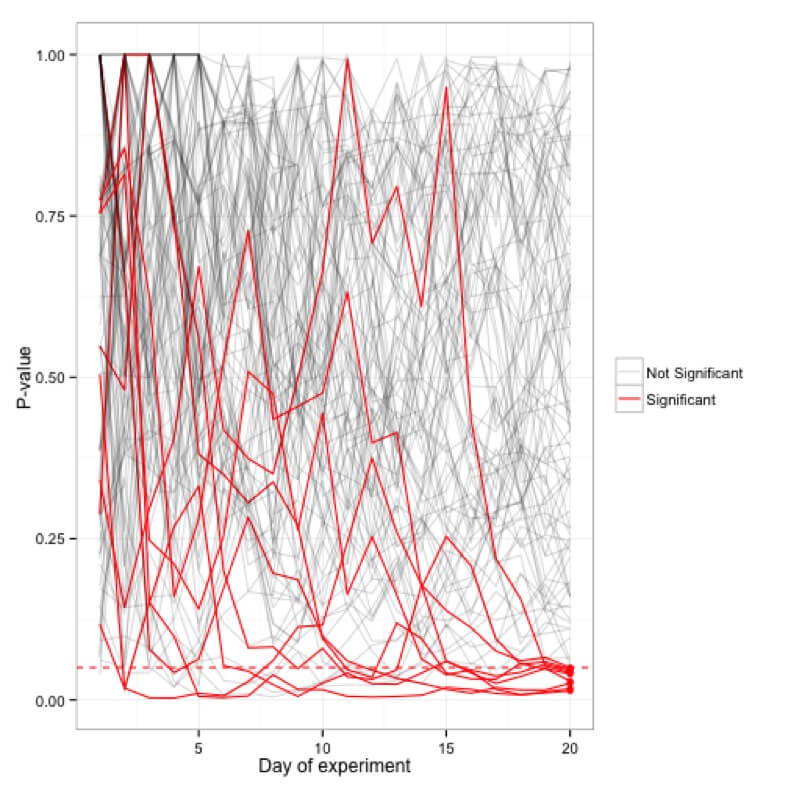
백(20일) 실험에 대해 플롯된 p-값 시뮬레이션 5개의 실험만이 실제로 20일 표시에서 중요하지만 많은 실험이 중간에 <0.05 컷오프에 도달하는 경우가 있습니다.
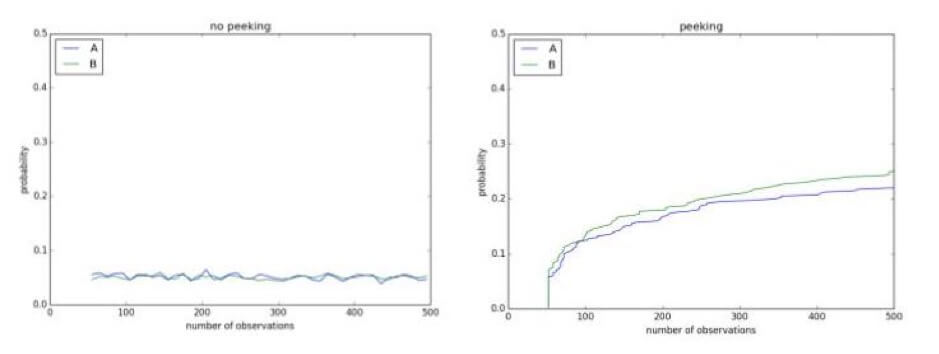
중간에 실험을 엿보면 존재하지 않는 결과가 나타날 수 있습니다. 예를 들어, 아래에는 0.1의 유의 수준을 사용하는 A/A 테스트가 있습니다. A/A 테스트이기 때문에 컨트롤과 처리의 차이는 없습니다. 그러나 진행 중인 실험 동안 500번의 관찰 후에는 서로 다르고 귀무 가설이 기각될 수 있다는 결론을 내릴 확률이 50% 이상입니다.
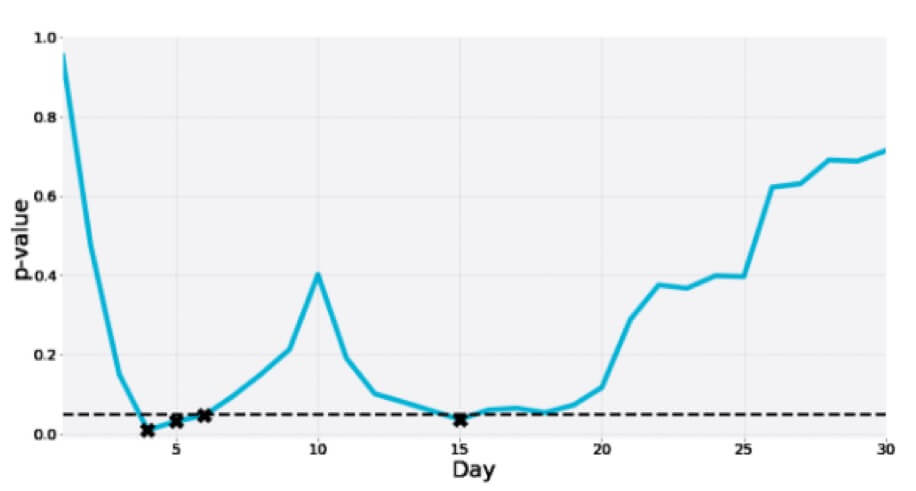
다음은 30일 동안의 A/A 테스트 중 하나입니다. 여기서 p-값이 그 사이에 여러 번 유의 영역으로 내려가 결국 컷오프보다 훨씬 더 커집니다.
고정된 수평 실험에서 p-값을 올바르게 보고한다는 것은 고정된 샘플 크기 또는 테스트 기간에 미리 커밋해야 함을 의미합니다. 일부 팀은 이 실험 중단 기준과 의도된 길이에 특정 수의 전환을 추가하기도 합니다.
그러나 여기서 문제는 대부분의 웹사이트에서 이 표준 방식을 사용하여 최적의 중지를 위해 모든 단일 실험에 연료를 공급할 수 있는 충분한 테스트 트래픽을 확보하는 것이 어렵다는 것입니다.
여기에 선택적 중지 규칙을 지원하는 순차 테스트 방법을 사용하는 것이 도움이 됩니다.
더 빠른 결정을 가능하게 하는 유연한 중지 규칙으로 이동
순차 테스트 방법을 사용하면 실험 데이터가 표시되는 대로 활용하고 고유한 통계적 유의성 모델을 사용하여 유연한 중지 규칙으로 승자를 더 빨리 발견할 수 있습니다.
CRO 성숙도의 최고 수준에 있는 최적화 팀은 종종 이러한 테스트를 지원하기 위해 자체 통계 방법론을 고안합니다. 일부 A/B 테스트 도구에는 이 기능이 포함되어 있으며 버전이 이기는 것 같으면 제안할 수 있습니다. 그리고 일부는 사용자 정의 값 등을 사용하여 통계적 유의성을 계산하는 방법을 완전히 제어할 수 있습니다. 따라서 진행 중인 실험에서도 승자를 엿볼 수 있습니다.

A/B 테스트 통계에 대한 인기 있는 CXL 과정의 통계학자이자 저자이자 강사인 Georgi Georgiev는 중간 분석의 수와 시기에 유연성을 허용하는 다음과 같은 순차적 테스트 방법을 위한 것입니다.
" 순차 테스트를 사용하면 승리한 변종을 조기에 배포하여 수익을 극대화할 수 있을 뿐만 아니라 가능한 한 빨리 승자가 나올 가능성이 거의 없는 테스트를 중지할 수 있습니다. 후자는 열등한 변형으로 인한 손실을 최소화하고 변형이 단순히 제어를 능가할 가능성이 없을 때 테스트 속도를 높입니다. 통계적으로 엄격함이 모든 경우에 유지됩니다. "
Georgiev는 팀이 실험이 계속 실행되는 동안 승자를 감지할 수 있는 고정 샘플 테스트 모델을 버리는 데 도움이 되는 계산기를 만들기까지 했습니다. 그의 모델은 많은 통계를 고려하고 품질을 희생하지 않으면서 표준 통계적 유의성 계산보다 약 20-80% 더 빠르게 테스트를 호출할 수 있도록 도와줍니다.
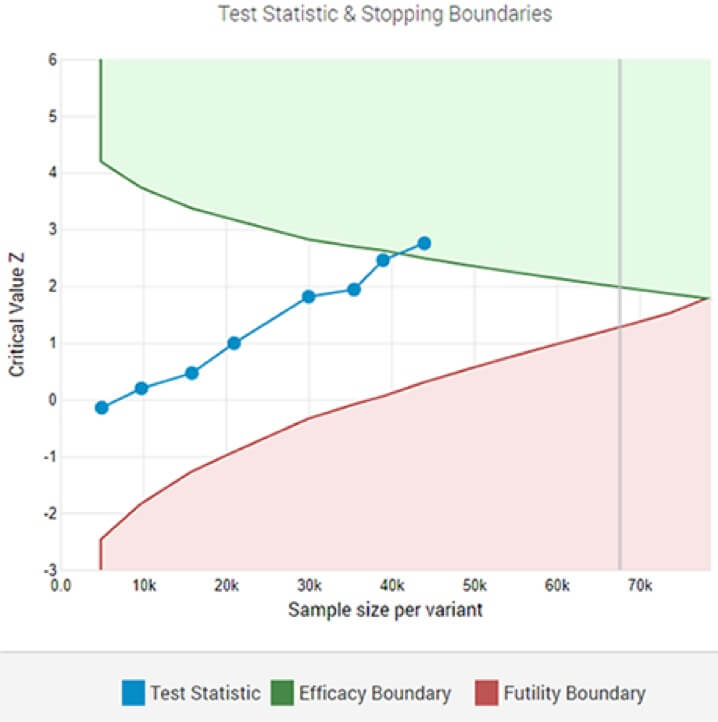
8차 중간 분석 후 지정된 유의 임계값에서 통계적으로 유의한 승자를 나타내는 적응형 A/B 검정입니다.
이러한 테스트를 통해 의사 결정 과정을 가속화할 수 있지만 해결해야 할 중요한 측면이 하나 있습니다. 바로 실험의 실제 영향입니다 . 실험을 중간에 종료하면 실험을 과대평가할 수 있습니다.
효과 크기에 대해 조정되지 않은 추정치를 보는 것은 위험할 수 있다고 Georgiev는 경고합니다. 이를 피하기 위해 그의 모델은 중간 모니터링으로 인해 발생하는 편향을 고려한 조정을 적용하는 방법을 사용합니다. 그는 애자일 분석이 "정지 단계와 통계의 관찰된 값(오버슈트가 있는 경우)에 따라" 추정치를 조정하는 방법을 설명합니다. 아래에서 위의 테스트에 대한 분석을 볼 수 있습니다. (추정 상승도가 관찰된 것보다 낮고 간격이 중심에 있지 않은 점에 유의하세요.)
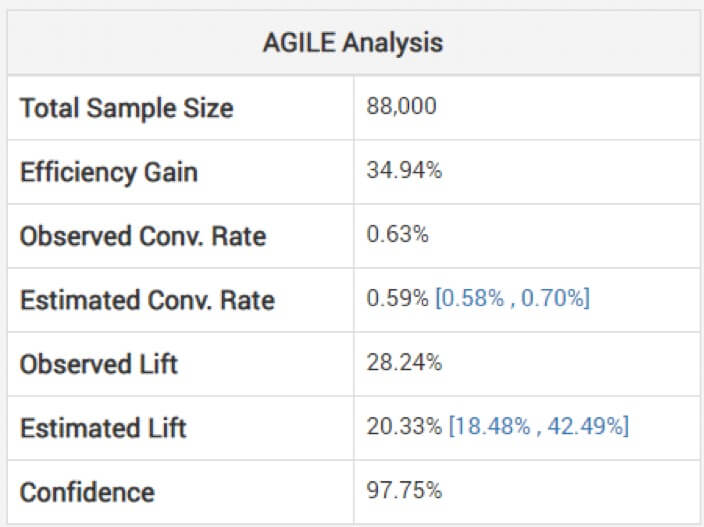
따라서 승리는 의도한 것보다 짧은 실험을 기반으로 하는 것처럼 크지 않을 수 있습니다.
손실도 고려해야 합니다. 너무 일찍 승자를 잘못 호출했을 수 있기 때문입니다. 그러나 이러한 위험은 고정 수평 테스트에서도 존재합니다. 그러나 외부 유효성은 더 오래 실행되는 고정 수평 테스트와 비교할 때 조기에 실험을 호출할 때 더 큰 문제가 될 수 있습니다. 그러나 이것은 Georgiev가 설명하는 것처럼 " 더 작은 샘플 크기와 이에 따른 테스트 기간의 단순한 결과입니다. "
결국… 승자도 패자도 아니다…
... 그러나 Chris Stucchio가 말했듯이 더 나은 비즈니스 결정에 대해.
또는 Tom Redman(Data Driven: Profiting from Your Most Important Business Asset의 저자)은 비즈니스에서 다음과 같이 주장합니다. “ 통계적 중요성보다 더 중요한 기준이 있는 경우가 많습니다. 중요한 질문은 “ 그 결과가 시장에서 단기간만 지속된다면? "'
Georgiev는 " 통계적으로 유의미하고 외부 타당성 고려 사항이 설계 단계에서 만족스러운 방식으로 해결된 경우" 짧은 기간 동안이 아니라 대부분 그럴 것이라고 말합니다.
실험의 핵심은 팀이 정보에 입각한 결정을 내릴 수 있도록 하는 것입니다. 따라서 실험 데이터가 가리키는 결과를 더 빨리 전달할 수 있다면 그 이유는 무엇입니까?
실제로 "충분한" 샘플 크기를 얻을 수 없는 작은 UI 실험일 수 있습니다. 그것은 또한 당신의 도전자가 원본을 부수고 당신이 그 내기를 할 수 있는 실험일 수도 있습니다!
Jeff Bezos가 Amazon 주주들에게 보낸 편지에서 말했듯이 큰 실험은 큰 시간을 요합니다.
" 100배의 결과가 나올 확률이 10%라면 매번 그 베팅을 해야 합니다. 하지만 열에 아홉은 여전히 틀릴 것입니다. 펜스를 향해 스윙을 하면 삼진을 많이 잡게 되지만 홈런도 칠 수 있다는 것을 우리 모두 알고 있습니다. 그러나 야구와 비즈니스의 차이점은 야구는 잘린 결과 분포가 있다는 것입니다. 스윙할 때 볼과 얼마나 잘 연결되더라도 얻을 수 있는 최대 런은 4개입니다. 비즈니스에서 때때로, 당신이 본선에 올라서면 1,000점을 득점할 수 있습니다. 이처럼 긴 꼬리를 가진 수익 분포가 과감한 태도를 취하는 것이 중요한 이유입니다. 큰 승자는 많은 실험에 비용을 지불합니다. "
실험을 일찍 시작하는 것은 큰 의미에서 매일 결과를 엿보고 좋은 내기를 보장하는 지점에서 멈추는 것과 같습니다.

