
CTR 곡선이란 무엇이며 Python으로 계산하는 방법은 무엇입니까?
게시 됨: 2022-03-22CTR 곡선, 즉 위치에 따른 유기적 클릭률은 검색 엔진 결과 페이지(SERP)에서 해당 위치에 따라 CTR을 얻는 파란색 링크의 수를 보여주는 데이터입니다. 예를 들어, 대부분의 경우 SERP의 첫 번째 파란색 링크가 가장 많은 CTR을 얻습니다.
이 튜토리얼이 끝나면 디렉토리를 기반으로 사이트의 CTR 곡선을 계산하거나 CTR 쿼리를 기반으로 유기적 CTR을 계산할 수 있습니다. 내 Python 코드의 출력은 사이트 CTR 곡선을 설명하는 통찰력 있는 상자 및 막대 플롯입니다.
초보자이고 CTR 정의를 모르는 경우 다음 섹션에서 자세히 설명하겠습니다.
유기적 CTR 또는 유기적 클릭률이란 무엇입니까?
CTR은 자연 클릭을 노출로 나눈 값입니다. 예를 들어 100명이 "사과"를 검색하고 30명이 첫 번째 결과를 클릭하면 첫 번째 결과의 CTR은 30 / 100 * 100 = 30%입니다.
이것은 100번의 검색에서 30%를 얻는다는 것을 의미합니다. Google Search Console(GSC)의 노출은 검색자 표시 영역에서 웹사이트 링크의 모양을 기반으로 하지 않는다는 점을 기억하는 것이 중요합니다. 검색자 SERP에 결과가 표시되면 각 검색에 대해 1회의 노출이 발생합니다.
CTR 곡선의 용도는 무엇입니까?
SEO의 중요한 주제 중 하나는 유기적 트래픽 예측입니다. 일부 키워드 세트의 순위를 높이려면 더 많은 공유를 얻기 위해 수천 달러를 할당해야 합니다. 그러나 회사의 마케팅 수준에서 질문은 종종 "이 예산을 할당하는 것이 비용 효율적입니까?"입니다.
또한 SEO 프로젝트에 대한 예산 할당 주제 외에도 향후 유기적 트래픽 증가 또는 감소를 추정해야 합니다. 예를 들어, 경쟁업체 중 하나가 SERP 순위에서 우리를 대체하려고 애쓰는 것을 본다면 비용이 얼마나 듭니까?
이 상황이나 다른 많은 시나리오에서는 사이트의 CTR 곡선이 필요합니다.
CTR 곡선 연구를 사용하고 데이터를 사용하지 않는 이유는 무엇입니까?
간단히 말해서 SERP에 귀하의 사이트 특성이 있는 다른 웹사이트는 없습니다.
다양한 산업 및 다양한 SERP 기능의 CTR 곡선에 대한 많은 연구가 있지만 데이터가 있는 경우 사이트에서 타사 소스에 의존하는 대신 CTR을 계산하지 않는 이유는 무엇입니까?
이 작업을 시작하겠습니다.
Python으로 CTR 곡선 계산: 시작하기
Google의 위치 기반 클릭률 계산 프로세스에 대해 알아보기 전에 기본 Python 구문을 알고 Pandas와 같은 일반적인 Python 라이브러리에 대한 기본 이해가 필요합니다. 이렇게 하면 코드를 더 잘 이해하고 원하는 방식으로 사용자 지정하는 데 도움이 됩니다.
또한 이 프로세스에서는 Jupyter 노트북을 사용하는 것을 선호합니다.
위치를 기반으로 유기적 CTR을 계산하려면 다음 Python 라이브러리를 사용해야 합니다.
- 판다
- 음모
- 칼레이도
또한 다음 Python 표준 라이브러리를 사용합니다.
- 운영 체제
- json
앞서 말했듯이 CTR 곡선을 계산하는 두 가지 다른 방법을 살펴보겠습니다. Python 패키지 가져오기, 플롯 이미지 출력 폴더 생성, 출력 플롯 크기 설정 등 일부 단계는 두 방법 모두에서 동일합니다.
# 프로세스에 필요한 라이브러리 가져오기 수입 OS json 가져오기 pandas를 pd로 가져오기 plotly.express를 px로 가져오기 plotly.io를 pio로 가져오기 수입 칼레이도
여기에서 플롯 이미지를 저장하기 위한 출력 폴더를 만듭니다.
# 플롯 이미지 출력 폴더 생성
os.path.exists('./출력 플롯 이미지')가 아닌 경우:
os.mkdir('./출력 플롯 이미지')
아래에서 출력 플롯 이미지의 높이와 너비를 변경할 수 있습니다.
# 출력 플롯 이미지의 너비와 높이 설정 pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
쿼리 CTR을 기반으로 하는 첫 번째 방법부터 시작하겠습니다.
첫 번째 방법: 쿼리 CTR을 기반으로 전체 웹사이트 또는 특정 URL 속성에 대한 CTR 곡선 계산
우선 CTR, 평균 게재순위 및 노출수와 함께 모든 쿼리를 가져와야 합니다. 나는 지난 달의 완전한 한 달 데이터를 사용하는 것을 선호합니다.
이를 위해 Google 데이터 스튜디오의 GSC 사이트 노출 데이터 소스에서 쿼리 데이터를 가져옵니다. 또는 GSC API 또는 "시트용 검색 애널리틱스" Google 스프레드시트 추가 기능과 같이 원하는 방식으로 이 데이터를 얻을 수 있습니다. 이렇게 하면 블로그 또는 제품 페이지에 전용 URL 속성이 있는 경우 이를 GDS에서 데이터 소스로 사용할 수 있습니다.
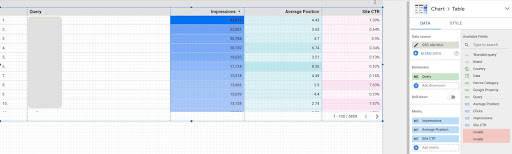
1. Google 데이터 스튜디오(GDS)에서 쿼리 데이터 가져오기
이것을하기 위해:
- 보고서를 만들고 여기에 테이블 차트 추가
- 보고서에 사이트 '사이트 노출' 데이터 소스 추가
- 측정기준에 대해 '쿼리'를 선택하고 측정항목에 대해 'ctr', '평균 게재순위' 및 '노출수'를 선택합니다.
- 필터를 만들어 브랜드 이름이 포함된 쿼리를 필터링합니다(브랜드가 포함된 쿼리의 클릭률이 높아져 데이터 정확도가 떨어짐).
- 테이블을 마우스 오른쪽 버튼으로 클릭하고 내보내기를 클릭합니다.
- 출력을 CSV로 저장
2. 위치에 따라 데이터 로드 및 쿼리 레이블 지정
다운로드한 CSV를 조작하기 위해 Pandas를 사용합니다.
프로젝트의 폴더 구조에 대한 모범 사례는 모든 데이터를 저장하는 '데이터' 폴더를 갖는 것입니다.
여기서는 튜토리얼의 유동성을 위해 이 작업을 수행하지 않았습니다.
query_df = pd.read_csv('./downloaded_data.csv')
그런 다음 위치에 따라 쿼리에 레이블을 지정합니다. 위치 1에서 10까지의 레이블을 지정하기 위해 'for' 루프를 만들었습니다.
예를 들어 쿼리의 평균 위치가 2.2 또는 2.9인 경우 "2"라는 레이블이 지정됩니다. 평균 위치 범위를 조작하여 원하는 정확도를 얻을 수 있습니다.
범위(1, 11)의 i에 대해:
query_df.loc[(query_df['평균 위치'] >= i) & (
query_df['평균 위치'] < i + 1), '위치 레이블'] = i
이제 위치에 따라 쿼리를 그룹화합니다. 이것은 다음 단계에서 더 나은 방식으로 각 위치 쿼리 데이터를 조작하는 데 도움이 됩니다.
query_grouped_df = query_df.groupby(['위치 레이블'])
3. CTR 곡선 계산을 위해 데이터를 기반으로 쿼리 필터링
CTR 곡선을 계산하는 가장 쉬운 방법은 모든 쿼리 데이터를 사용하여 계산하는 것입니다. 하지만; 데이터의 두 번째 위치에 한 번의 노출이 있는 쿼리를 생각하는 것을 잊지 마십시오.
내 경험에 따르면 이러한 쿼리는 최종 결과에 많은 차이를 만듭니다. 하지만 가장 좋은 방법은 직접 해보는 것입니다. 데이터세트에 따라 변경될 수 있습니다.
이 단계를 시작하기 전에 막대 플롯 출력을 위한 목록과 조작된 쿼리를 저장하기 위한 DataFrame을 만들어야 합니다.
# 'query_df' 조작 데이터를 저장할 DataFrame 생성 수정된_df = pd.DataFrame() # 막대 차트의 각 위치 평균을 저장하기 위한 목록 mean_ctr_list = []
그런 다음 query_grouped_df 그룹을 반복하고 노출을 기반으로 상위 20% 쿼리를 modified_df DataFrame에 추가합니다.
가장 많이 노출된 검색어의 상위 20%만을 기준으로 CTR을 계산하는 것이 가장 적합하지 않은 경우 변경할 수 있습니다.
그렇게 하려면 .quantile(q=your_optimal_number, interpolation='lower')] 을 조작하여 값을 늘리거나 줄일 수 있으며 your_optimal_number 는 0에서 1 사이여야 합니다.
예를 들어 쿼리의 상위 30%를 얻으려면 your_optimal_num 이 1과 0.3(0.7)의 차이입니다.
범위(1, 11)의 i에 대해:
# 디렉토리에 일부 위치에 대한 데이터가 없는 상황을 처리하기 위한 try-except
노력하다:
tmp_df = query_grouped_df.get_group(i)[query_grouped_df.get_group(i)['노출수'] >= query_grouped_df.get_group(i)['노출수']
.quantile(q=0.8, 보간='낮은')]
mean_ctr_list.append(tmp_df['ctr'].mean())
수정된_df = 수정된_df.append(tmp_df, ignore_index=True)
키 오류 제외:
mean_ctr_list.append(0)
# 메모리 사용량 줄이기 위해 'tmp_df' DataFrame 삭제
델 [tmp_df]
4. 상자 그림 그리기
이 단계는 우리가 기다려온 것입니다. 플롯을 그리기 위해 Matplotlib, Matplotlib의 래퍼로 seaborn 또는 Plotly를 사용할 수 있습니다.
개인적으로 Plotly를 사용하는 것이 데이터 탐색을 좋아하는 마케터에게 가장 적합하다고 생각합니다.
Mathplotlib에 비해 Plotly는 사용하기 매우 쉽고 몇 줄의 코드로 아름다운 플롯을 그릴 수 있습니다.
# 1. 박스 플롯
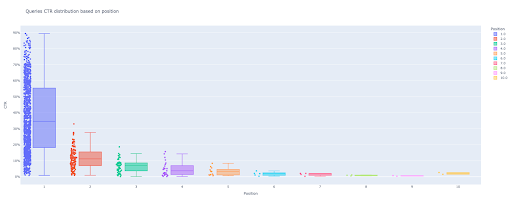
box_fig = px.box(modified_df, x='위치 레이블', y='사이트 CTR', title='위치 기반 쿼리 CTR 분포',
포인트='전체', 색상='위치 레이블', 레이블={'위치 레이블': '위치', '사이트 CTR': 'CTR'})
# 10개의 x축 눈금 모두 표시
box_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# y축 눈금 형식을 백분율로 변경
box_fig.update_yaxes(tickformat=".0%")
# 플롯을 '출력 플롯 이미지' 디렉토리에 저장
box_fig.write_image('./출력 플롯 이미지/쿼리 상자 플롯 CTR 곡선.png')
이 네 줄만 있으면 아름다운 상자 그림을 얻고 데이터 탐색을 시작할 수 있습니다.
이 열과 상호 작용하려면 새 셀 실행에서 다음을 수행하십시오.
box_fig.show()
이제 대화형 출력에 매력적인 상자 그림이 있습니다.
출력 셀의 대화형 플롯 위로 마우스를 가져갈 때 관심 있는 중요한 숫자는 각 위치의 "사람"입니다.
각 위치에 대한 평균 CTR을 보여줍니다. 평균 중요성 때문에 기억하시겠지만 우리는 각 위치의 평균을 포함하는 목록을 만듭니다. 다음으로 각 위치의 평균을 기반으로 막대 그래프를 그리는 다음 단계로 넘어갑니다.
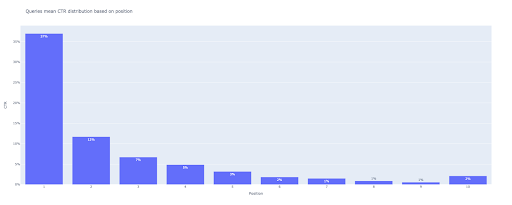
5. 막대 그래프 그리기
상자 그림과 마찬가지로 막대 그림을 그리는 것은 매우 쉽습니다. px.bar() 의 title 인수를 수정하여 차트 title 을 변경할 수 있습니다.
# 2. 막대 플롯
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title='쿼리는 위치에 따른 CTR 분포를 의미합니다',
레이블={'x': '위치', 'y': 'CTR'}, text_auto=True)
# 10개의 x축 눈금 모두 표시
bar_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# y축 눈금 형식을 백분율로 변경
bar_fig.update_yaxes(tickformat='.0%')
# 플롯을 '출력 플롯 이미지' 디렉토리에 저장
bar_fig.write_image('./출력 플롯 이미지/쿼리 막대 플롯 CTR 곡선.png')
출력에서 다음 플롯을 얻습니다.
상자 플롯과 마찬가지로 bar_fig.show() 를 실행하여 이 플롯과 상호 작용할 수 있습니다.
그게 다야! 몇 줄의 코드로 쿼리 데이터의 위치에 따라 유기적 클릭률을 얻을 수 있습니다.
각 하위 도메인 또는 디렉터리에 대한 URL 속성이 있는 경우 이러한 URL 속성 쿼리를 가져와 CTR 곡선을 계산할 수 있습니다.
[사례 연구] 로그 파일 분석으로 순위, 유기적 방문 및 매출 향상
 사례 연구 읽기
사례 연구 읽기두 번째 방법: 각 디렉토리의 방문 페이지 URL을 기반으로 CTR 곡선 계산
첫 번째 방법에서는 쿼리 CTR을 기반으로 유기적 CTR을 계산했지만 이 접근 방식을 사용하면 모든 방문 페이지 데이터를 얻은 다음 선택한 디렉토리에 대한 CTR 곡선을 계산합니다.
나는 이 방법을 좋아한다. 아시다시피 제품 페이지의 CTR은 블로그 게시물이나 다른 페이지의 클릭률과 매우 다릅니다. 각 디렉토리에는 위치에 따라 고유한 CTR이 있습니다.

보다 발전된 방법으로 각 디렉토리 페이지를 분류하고 페이지 세트의 위치를 기반으로 Google 유기적 클릭률을 얻을 수 있습니다.
1. 방문 페이지 데이터 가져오기
첫 번째 방법과 마찬가지로 Google Search Console(GSC) 데이터를 가져오는 방법에는 여러 가지가 있습니다. 이 방법에서는 https://developers.google.com/webmaster-tools/v1/searchanalytics/query의 GSC API 탐색기에서 방문 페이지 데이터를 가져오는 것을 선호했습니다.
이 접근 방식에 필요한 경우 GDS는 확실한 방문 페이지 데이터를 제공하지 않습니다. 또한 "시트용 애널리틱스 검색" Google 스프레드시트 추가 기능을 사용할 수 있습니다.
Google API 탐색기는 데이터 페이지 수가 25,000개 미만인 사이트에 적합합니다. 더 큰 사이트의 경우 방문 페이지 데이터를 부분적으로 가져와 함께 연결하거나 'for' 루프가 있는 Python 스크립트를 작성하여 GSC에서 모든 데이터를 가져오거나 타사 도구를 사용할 수 있습니다.
Google API 탐색기에서 데이터를 가져오려면:
- "검색 애널리틱스: 쿼리" GSC API 문서 페이지로 이동합니다. https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- 페이지 오른쪽에 있는 API 탐색기 사용
- "siteUrl" 필드에
https://www.example.com과 같은 URL 속성 주소를 입력합니다. 또한sc-domain:example.com과 같이 도메인 속성을 삽입할 수 있습니다. - "요청 본문" 필드에
startDate및endDate를 추가합니다. 나는 지난 달의 데이터를 얻는 것을 선호합니다. 이 값의 형식은YYYY-MM-DD입니다. -
dimension을 추가하고 해당 값을page로 설정 - "dimensionFilterGroups"를 만들고 브랜드 변형 이름이 있는 쿼리를 필터링합니다(
brand_variation_names를 브랜드 이름 RegExp로 대체). -
rawLimit을 추가하고 25000으로 설정하십시오. - 마지막에 'EXECUTE' 버튼을 누릅니다.
아래에서 요청 본문을 복사하여 붙여넣을 수도 있습니다.
{
"시작일": "2022-01-01",
"종료일": "2022-02-01",
"차원": [
"페이지"
],
"dimensionFilterGroups": [
{
"필터": [
{
"차원": "QUERY",
"표현": "brand_variation_names",
"연산자": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
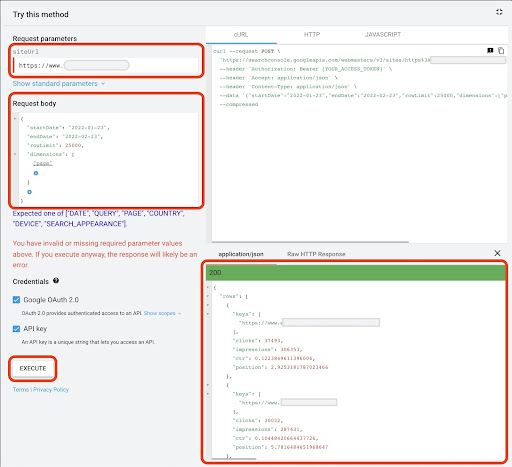
요청이 실행된 후 저장해야 합니다. 응답 형식 때문에 JSON 파일을 생성하고 모든 JSON 응답을 복사한 다음 downloaded_data.json 파일 이름으로 저장해야 합니다.
SASS 회사 사이트와 같이 사이트가 작고 방문 페이지 데이터가 1000페이지 미만인 경우 GSC에서 날짜를 쉽게 설정하고 "PAGES" 탭의 방문 페이지 데이터를 CSV 파일로 내보낼 수 있습니다.
2. 랜딩 페이지 데이터 로드
이 자습서에서는 Google API 탐색기에서 데이터를 가져와 JSON 파일에 저장한다고 가정합니다. 이 데이터를 로드하려면 아래 코드를 실행해야 합니다.
# 다운로드한 데이터에 대한 DataFrame 생성
open('./downloaded_data.json')을 json_file로 사용:
랜딩 데이터 = json.loads(json_file.read())['행']
Landings_df = pd.DataFrame(landings_data)
또한 열 이름을 변경하여 의미를 부여하고 "랜딩 페이지" 열에서 직접 랜딩 페이지 URL을 가져오는 기능을 적용해야 합니다.
# 'keys' 컬럼의 이름을 'landing page' 컬럼으로 변경하고 'landing page' 목록을 URL로 변환
Landings_df.rename(columns={'keys': '방문 페이지'}, inplace=True)
Landings_df['방문 페이지'] = Landings_df['방문 페이지'].apply(람다 x: x[0])
3. 모든 방문 페이지 루트 디렉토리 가져오기
먼저 사이트 이름을 정의해야 합니다.
# 따옴표 사이에 사이트 이름을 정의합니다. 예: 'https://www.example.com/' 또는 'http://mydomain.com/' 사이트 이름 = ''
그런 다음 방문 페이지 URL에서 함수를 실행하여 루트 디렉터리를 가져오고 출력에서 확인하여 선택합니다.
# 각 방문 페이지(URL) 디렉토리 가져오기
Landings_df['디렉토리'] = Landings_df['방문 페이지'].str.extract(pat=f'((?<={site_name})[^/]+)')
# 출력의 모든 디렉토리를 얻으려면 Pandas 옵션을 조작해야 합니다.
pd.set_option("display.max_rows", 없음)
# 웹사이트 디렉토리
Landings_df['디렉토리'].value_counts()
그런 다음 CTR 곡선을 얻기 위해 필요한 디렉토리를 선택합니다.
important_directories 변수에 디렉터리를 삽입합니다.
예: product,tag,product-category,mag . 쉼표로 디렉토리 값을 구분하십시오.
중요 디렉토리 = ''
중요 디렉토리 = 중요 디렉토리.split(',')
4. 방문 페이지 레이블 지정 및 그룹화
검색어와 마찬가지로 평균 게재순위에 따라 방문 페이지에 레이블을 지정합니다.
# 방문 페이지 위치에 레이블 지정
범위(1, 11)의 i에 대해:
Landings_df.loc[(landings_df['위치'] >= i) & (
Landings_df['위치'] < i + 1), '위치 레이블'] = i
그런 다음 "디렉토리"를 기반으로 방문 페이지를 그룹화합니다.
# '디렉토리' 값을 기준으로 랜딩 페이지 그룹화 Landings_grouped_df = Landings_df.groupby(['디렉토리'])
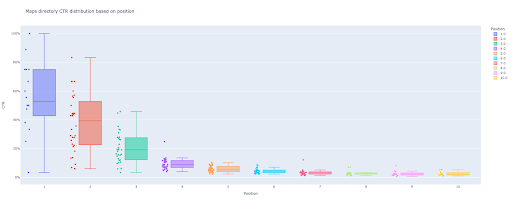
5. 디렉토리에 대한 상자 및 막대 플롯 생성
이전 방법에서는 플롯을 생성하는 함수를 사용하지 않았습니다. 하지만; 다양한 방문 페이지에 대한 CTR 곡선을 자동으로 계산하려면 함수를 정의해야 합니다.
# 디렉토리별 차트 생성 및 저장 기능
def each_dir_plot(dir_df, 키):
# '위치 레이블' 값에 따라 디렉토리 방문 페이지 그룹화
dir_grouped_df = dir_df.groupby(['위치 레이블'])
# 'dir_grouped_df' 조작 데이터를 저장할 DataFrame 생성
수정된_df = pd.DataFrame()
# 막대 차트의 각 위치 평균을 저장하기 위한 목록
mean_ctr_list = []
'''
'query_grouped_df' 그룹을 반복하고 노출을 기반으로 상위 20% 쿼리를 'modified_df' DataFrame에 추가합니다.
가장 많이 노출된 검색어의 상위 20%만을 기준으로 CTR을 계산하는 것이 가장 적합하지 않은 경우 변경할 수 있습니다.
변경하려면 '.quantile(q=your_optimal_number, interpolation='lower')]'를 조작하여 늘리거나 줄일 수 있습니다.
'you_optimal_number'는 0에서 1 사이여야 합니다.
예를 들어 쿼리의 상위 30%를 얻으려면 'your_optimal_num'이 1과 0.3(0.7)의 차이입니다.
'''
범위(1, 11)의 i에 대해:
# 디렉토리에 일부 위치에 대한 데이터가 없는 상황을 처리하기 위한 try-except
노력하다:
tmp_df = dir_grouped_df.get_group(i)[dir_grouped_df.get_group(i)['노출'] >= dir_grouped_df.get_group(i)['노출']
.quantile(q=0.8, 보간='낮은')]
mean_ctr_list.append(tmp_df['ctr'].mean())
수정된_df = 수정된_df.append(tmp_df, ignore_index=True)
키 오류 제외:
mean_ctr_list.append(0)
# 1. 박스 플롯
box_fig = px.box(modified_df, x='position label', y='ctr', title=f'{key} 위치에 따른 디렉토리 CTR 분포',
Points='all', color='position label', labels={'position label': 'Position', 'ctr': 'CTR'})
# 10개의 x축 눈금 모두 표시
box_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# y축 눈금 형식을 백분율로 변경
box_fig.update_yaxes(tickformat=".0%")
# 플롯을 '출력 플롯 이미지' 디렉토리에 저장
box_fig.write_image(f'./출력 플롯 이미지/{key} 디렉토리-박스 플롯 CTR 곡선.png')
# 2. 막대 플롯
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title=f'{key} 디렉토리 평균 CTR 분포는 위치',
레이블={'x': '위치', 'y': 'CTR'}, text_auto=True)
# 10개의 x축 눈금 모두 표시
bar_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# y축 눈금 형식을 백분율로 변경
bar_fig.update_yaxes(tickformat='.0%')
# 플롯을 '출력 플롯 이미지' 디렉토리에 저장
bar_fig.write_image(f'./출력 플롯 이미지/{key} 디렉토리-바 플롯 CTR 곡선.png')
위의 함수를 정의한 후 CTR 곡선을 얻으려는 디렉토리 데이터를 반복하기 위해 'for' 루프가 필요합니다.
# 디렉토리 반복 및 'each_dir_plot' 함수 실행
키의 경우, Landings_grouped_df의 항목:
Important_directories의 키인 경우:
each_dir_plot(항목, 키)
출력에서 output plot images 폴더에서 플롯을 얻습니다.
고급 팁!
쿼리 방문 페이지를 사용하여 다른 디렉토리의 CTR 곡선을 계산할 수도 있습니다. 기능을 약간 변경하여 방문 페이지 디렉토리를 기반으로 쿼리를 그룹화할 수 있습니다.
아래 요청 본문을 사용하여 API 탐색기에서 API 요청을 할 수 있습니다(25000개 행 제한을 잊지 마십시오).
{
"시작일": "2022-01-01",
"종료일": "2022-02-01",
"차원": [
"질문",
"페이지"
],
"dimensionFilterGroups": [
{
"필터": [
{
"차원": "QUERY",
"표현": "brand_variation_names",
"연산자": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
Python으로 CTR 곡선 계산을 사용자 정의하기 위한 팁
CTR 곡선을 계산하기 위한 보다 정확한 데이터를 얻으려면 타사 도구를 사용해야 합니다.
예를 들어, 어떤 쿼리에 추천 스니펫이 있는지 아는 것 외에도 더 많은 SERP 기능을 탐색할 수 있습니다. 또한 타사 도구를 사용하는 경우 SERP 기능을 기반으로 해당 쿼리에 대한 랜딩 페이지 순위가 포함된 쿼리 쌍을 얻을 수 있습니다.
그런 다음, 루트(상위) 디렉토리로 랜딩 페이지에 레이블을 지정하고, 디렉토리 값을 기반으로 쿼리를 그룹화하고, SERP 기능을 고려하고, 마지막으로 위치를 기반으로 쿼리를 그룹화합니다. CTR 데이터의 경우 GSC의 CTR 값을 피어 쿼리에 병합할 수 있습니다.