
SEO를 위한 시맨틱 네트워크의 중요성: 쿼리 및 문서 템플릿으로 시맨틱 콘텐츠 네트워크 생성 – 사례 연구
게시 됨: 2022-01-11시맨틱 네트워크는 관계 연결이 있는 사물에 대한 실제 정보를 나타낼 수 있는 지식 기반 개념과 연결됩니다. 지식 기반은 수십억 개의 엔터티 및 수조 개의 사실과 수천 개의 관계 유형을 가질 수 있습니다. 의미 네트워크는 무게, 크기, 유형, 냄새 또는 색상과 같은 상호 기능을 가진 모든 실세계 존재로부터 생성될 수 있습니다. Semantic Networks와 Semantic Web 간의 관계는 시맨틱 검색 엔진 및 최적화에 의해 생성됩니다.
시맨틱 네트워크는 시맨틱 파싱, 단어 의미 명확화, WordNet 생성, 그래프 이론, 자연어 처리, 이해 및 생성에 사용됩니다. 시맨틱 네트워크의 관점은 시맨틱 콘텐츠 네트워크를 제공함으로써 시맨틱 검색 엔진 최적화 내에서 사용될 수 있다.
이 SEO 사례 연구에서는 쿼리, 문서, 의도 템플릿 및 그 뒤에 있는 엔터티-속성 쌍을 기반으로 동일한 관점에서 두 가지 다른 방법을 사용하는 두 개의 다른 웹사이트를 설명합니다.
검색 엔진이 지식을 표현하는 방법과 지식 표현을 확장하는 방법에 대한 이해를 바탕으로 저는 이를 활용하여 놀라운 순위 결과를 산출할 수 있습니다. 기본 개념을 이해하면 두 웹 사이트에 적용한 방법을 설명한 다음 사용한 방법을 자세히 설명하겠습니다.
Semantic Networks가 웹사이트 순위에 어떻게 도움이 됩니까?
아래에서 프로젝트 I에 대한 전체 원시 결과를 찾을 수 있습니다.
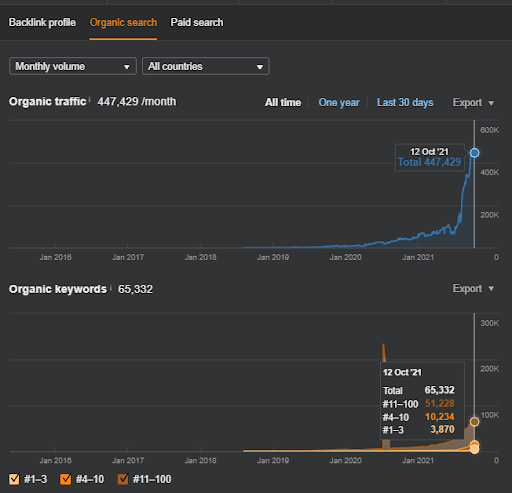
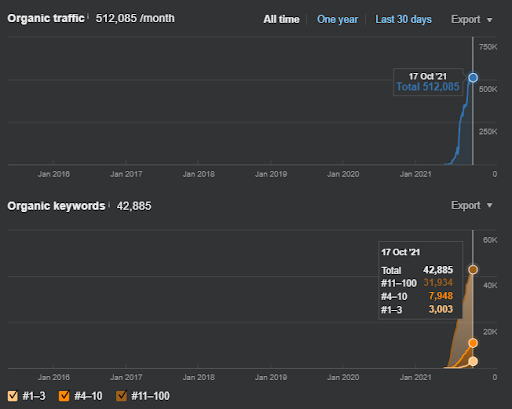
IstanbulBogaziciEnstitu.com인 Project One의 결과입니다. "Semantic Networks"가 쿼리 및 문서 템플릿과 함께 SEO에 사용될 수 있음을 증명하기 위해 Project One의 두 가지 다른 콘텐츠 네트워크를 시연하겠습니다. 프로젝트 1은 시맨틱 콘텐츠 네트워크 2 덕분에 가까운 장래에 훨씬 더 나은 결과를 얻을 것입니다. 클라이언트는 이 두 번째 네트워크의 롤아웃에 대한 책임이 있지만 그 논리도 설명하겠습니다.
17일 후 프로젝트 I의 진행 상황은 다음과 같습니다. 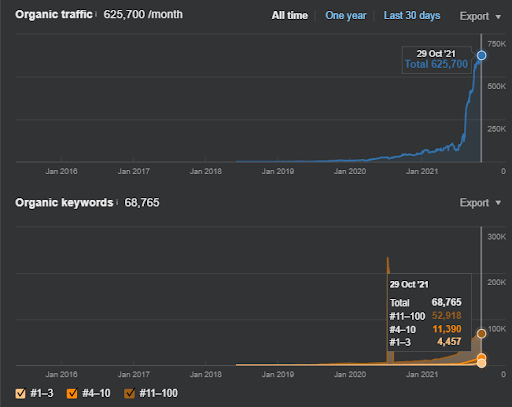
17일 후, Semantic Content Network의 re-ranking 과정은 더 명확해졌습니다.
시맨틱 콘텐츠 네트워크 개념은 동일한 유형의 엔터티에 대한 쿼리, 검색 의도, 동작 및 문서 템플릿의 가치를 이해하는 데 도움이 됩니다. 이 시맨틱 네트워크 중심의 SEO 사례 연구에서는 동일한 엔티티 유형에 대해 의미적으로 생성된 콘텐츠 네트워크를 사용하는 두 개의 새로운 웹사이트를 통해 이전의 Topical Authority 및 Semantic SEO 사례 연구를 심화할 것입니다.
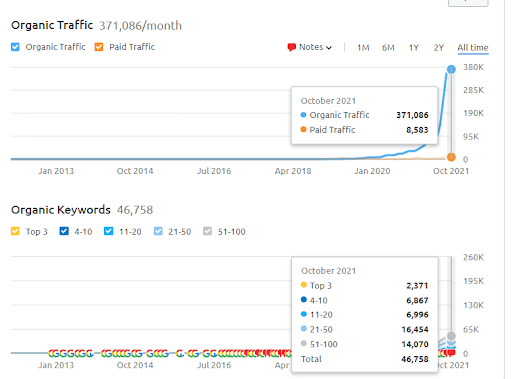
첫 번째 프로젝트의 SEMRush 그래픽입니다. 나는 또한 이 웹사이트가 6월 브로드 코어 알고리즘 업데이트를 잃어버렸다는 점을 언급해야 합니다. "순위"를 잃지 않는다면 결과가 더 좋을 것입니다. 더 나은 주제 권위, 적용 범위 및 과거 데이터로 다음 Broad Core Algorithm Update의 경우 "순위"를 쉽게 복구할 수 있습니다.
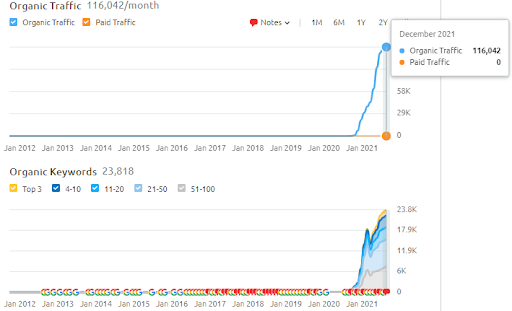
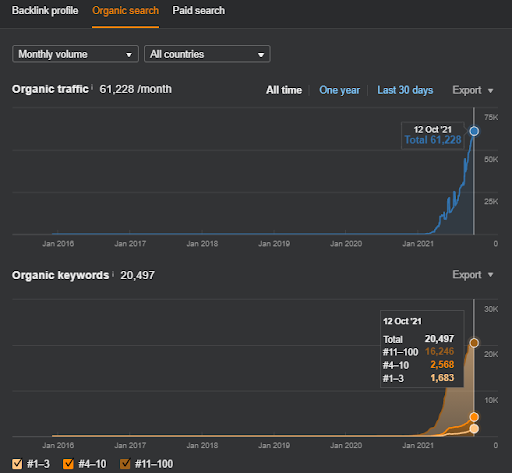
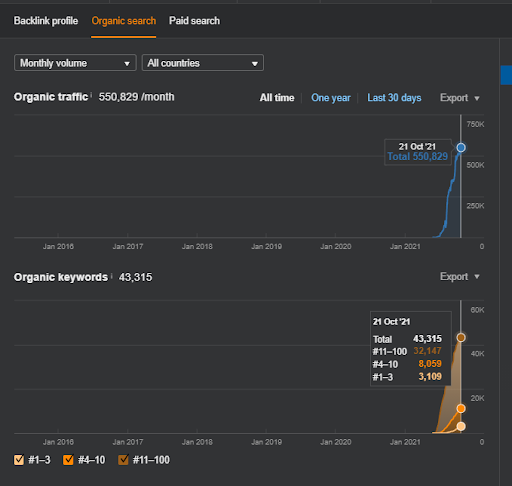
두 번째 프로젝트의 이름은 Vizem.net입니다. Project One과 달리 Vizem.net은 느리지만 꾸준히 증가하고 있음을 알 수 있습니다. 약간 다른 관점에서 Semantic Content Networks를 사용하기 때문입니다. 아래에서 두 번째 프로젝트의 Ahrefs 결과를 볼 수 있습니다.
두 번째 프로젝트의 결과는 주제 범위와 권위를 점진적으로 개선하여 "느린 순위 재지정 프로세스"를 나타냅니다. "Re-ranking" 및 "Initial Ranking"이라는 용어는 Semantic Content Networks와 관련된 개념 이후에 설명합니다. 그래픽 내에서 '안정성'을 느끼셨다면, 제가 소스에 새 콘텐츠 게시를 중단했기 때문입니다. 그리고 Top 3 Query Count의 개수에서 알 수 있듯이 Re-ranking Process에 영향을 줍니다. “모멘텀”과 “재순위” 관계는 기본 개념 설명 후에 찾을 수 있습니다.
아래에서 Vizem.net의 SEMRush 결과를 확인할 수 있습니다.
이 웹사이트의 실제 트래픽은 SEMRush에 명시된 수의 3배입니다. 이 그래프 내에서도 동일한 "안정성"과 "운동량" 개념을 실현할 수 있습니다.
Topical Authority SEO 사례 연구를 작성하는 동안 내 관점을 가르쳐준 Bill Slawski에게 감사했습니다. Semantic Content Network SEO 사례 연구에서도 이를 반복합니다. "재 순위 지정" 및 "초기 순위 지정" 개념을 이해하려면 "검색 엔진이 검색 결과의 순위를 재지정할 수 있는 방법"을 읽어야 합니다.
2021년 3월 18일 Oncrawl, RankSense 및 Holistic SEO & Digital은 Python SEO 및 데이터 과학 웨비나를 게시했습니다. 웨비나에서는 결과 차이를 애니메이션화하기 위해 SERP가 기록되었습니다. 검색 엔진이 특정 소스의 순위를 비슷한 빈도로 다른 소스와 변경하는 것을 볼 수 있습니다.
계속하기 전에 이것이 긴 기사라는 것을 압니다. 그러나 실제로 이것은 매우 복잡한 SEO 방법론에 대한 간략한 설명입니다. Semantic Content Networks는 설계하는 동안 너무 많은 생각을 하고 클라이언트, 작성자 및 온보딩을 위한 수개월의 교육을 필요로 합니다. 따라서 이 기사에서는 가장 실행 가능한 간략한 제안과 중요한 Google 및 기타 검색 엔진의 특허, 연구 논문과 함께 개념의 정의에 초점을 맞추고자 합니다. 긴 버전(기본적으로 책)에서는 시맨틱 콘텐츠 네트워크의 "초기 순위 지정"과 "재 순위 지정"에 중점을 두었습니다.
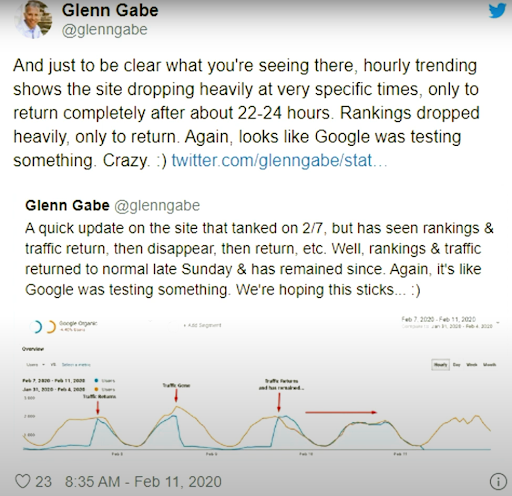
2020년 2월 11일부터 Glenn Gabe는 시각적으로 검색 엔진의 순위 재지정 및 테스트 방법론에 대한 좋은 예를 보여줍니다.
더 자세히 알고 싶다면 "SEO를 위한 초기 순위 및 재순위의 중요성"을 읽으십시오.
SEO 사례 연구를 위한 실제 데이터로 깊이 들어가려면 시맨틱 콘텐츠 네트워크를 이해하기 위한 개념을 검색 엔진 이해-커뮤니케이션 관점에서 처리해야 합니다.
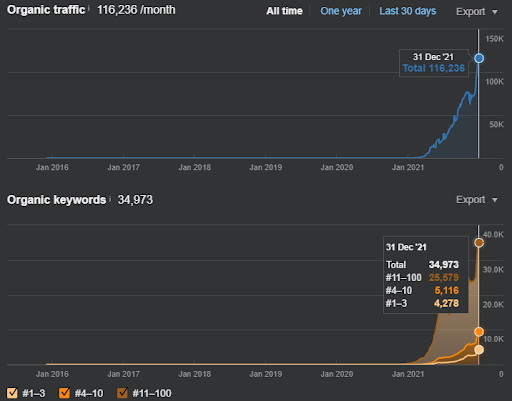
Vizem.net의 re-ranking 예시로 위와 같이 업데이트 된 상황을 볼 수 있습니다. SEO 사례 연구의 향후 섹션에서는 SEO를 위한 Google의 Re-ranking 알고리즘에 대한 더 많은 설명이 있을 것입니다.
시맨틱 네트워크란 무엇입니까?
시맨틱 네트워크는 사물 인터넷을 연결하고 분석하는 데 사용할 수 있습니다. 기술 시장에서 잠재적인 구매자를 인식하거나 키워드 네트워크 생성 및 클러스터링을 위한 단어 분석에 유용할 수 있습니다. 시맨틱 네트워크는 탐색을 지원하고 관계의 구조 또는 사물과 다른 사물의 상대적 중요성을 나타내는 데 사용할 수 있습니다. 시맨틱 네트워크에는 다음과 같은 구성 요소가 있습니다.
- 어휘 의미론(Lexical Semantics): 어떤 단어와 개념이 다른 것들과 연결되어 있고 어떤 차이점이 있는지 이해합니다.
- 구조적 구성요소: 어떤 노드가 어떤 모서리에 어떤 정보로 연결되어 있는지 이해합니다.
- 의미 구성 요소: 사실의 정의.
- 절차 부분: 구성 요소 간의 추가 연결을 만드는 데 도움이 됩니다.
시맨틱 네트워크는 다목적이므로 NLP 알고리즘은 복잡한 건강 문제를 식별하는 데 도움이 되는 것과 같이 매우 다양한 목적으로 사용될 수도 있습니다. 동일한 의미 네트워크 구조는 이러한 다른 영역이 서로 의미 관계가 있는 한 여러 다른 영역에서 구현될 수 있습니다.
첫 번째 프로젝트의 지난 6개월 비교.
지식 기반이란 무엇입니까?
지식 기반은 기계가 읽을 수 있는 형식으로 분류된 정보 라이브러리입니다. 지식 기반은 쿼리를 기반으로 좁혀지고 심화될 수 있는 백과사전으로 사용될 수 있습니다. 지식 기반은 명제, 사실 추출 및 정보 추출을 기반으로 구성될 수 있습니다. 의미 네트워크와 지식 기반 사이의 관계는 의미 네트워크에 있는 모든 것이 사실을 추출하는 동안 지식 기반에 배치된다는 것입니다.
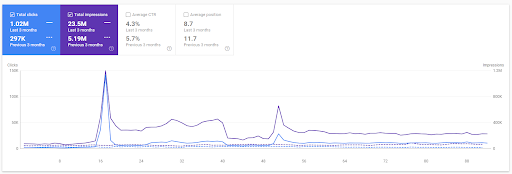
첫 번째 프로젝트의 지난 3개월 비교
시맨틱 콘텐츠 네트워크란 무엇입니까?
시맨틱 콘텐츠 네트워크는 시맨틱 네트워크 구성요소와 이해를 바탕으로 준비된 콘텐츠 네트워크를 의미합니다. 시맨틱 콘텐츠 네트워크는 더 자세한 지식 기반을 제공하기 위해 동일한 그룹의 엔터티 또는 엔터티의 여러 속성을 포함할 수 있습니다.
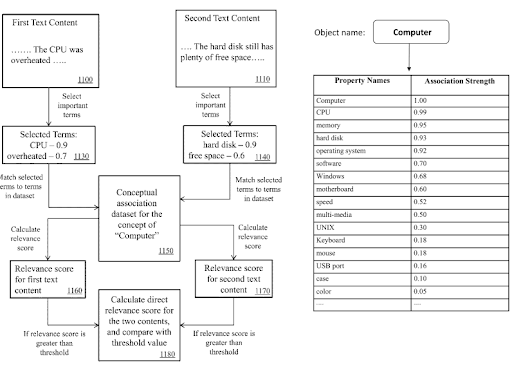
시맨틱 콘텐츠 네트워크 내에서 지식 도메인 용어 및 트리플을 사용하여 문서의 주요 목적과 가능한 이웃 콘텐츠 조각을 알릴 수 있습니다.
검색 엔진은 자신의 지식 기반을 웹사이트 콘텐츠에서 생성할 수 있는 지식 기반과 비교할 수 있습니다. 웹사이트가 다양한 컨텍스트 레이어에 대해 높은 수준의 정확성과 포괄적인 경우 검색 엔진은 웹사이트 콘텐츠에서 자체 지식 기반을 개선할 수 있습니다. 검색 엔진이 개방형 웹의 다른 소스에서 자체 지식 기반을 개선하고 확장하는 경우 높은 수준의 지식 기반 신뢰의 신호입니다.
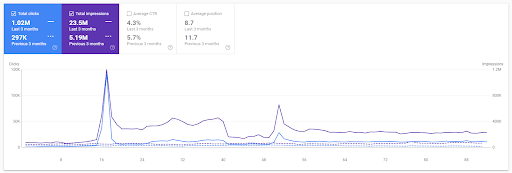
첫 번째 프로젝트를 기반으로 한 지난 3개월 동안의 연간 비교.
지식 기반 신뢰란 무엇입니까?
지식 기반 신뢰는 "PageRank"가 아닌 "정보의 정확성"을 기반으로 하는 개방형 웹에 중점을 둡니다. RankMerge와 유사한 알고리즘입니다. 지식 기반 신뢰는 텍스트 모호성을 제거하여 트리플렛, 사실 추출, 정확성 확인 및 텍스트 이해를 포함합니다. 지식 기반 신뢰는 다르지만 관련 컨텍스트 레이어를 기반으로 기사 내에서 강력하게 연결된 구성 요소를 포함하는 의미론적 콘텐츠 네트워크를 제공함으로써 얻을 수 있습니다.
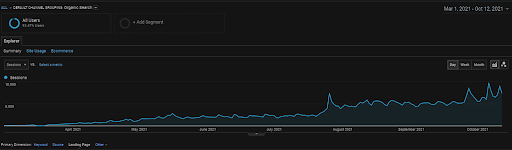
지난 6개월간 GA의 Vizem.net 유기적 세션.
아래에서 Luna Dong의 지식 기반 신뢰 프레젠테이션의 예를 볼 수 있습니다. 검색 엔진이 외부 순위 요소 대신 "내부 순위 요소"에 집중할 수 있는 방법을 보여줍니다. 높은 PageRank는 그 자체로 콘텐츠에 대한 높은 품질과 정확성을 나타낼 수 없다고 설명합니다. 따라서 KBT(Knowledge-Based Trust)를 갖는 것이 중요합니다.
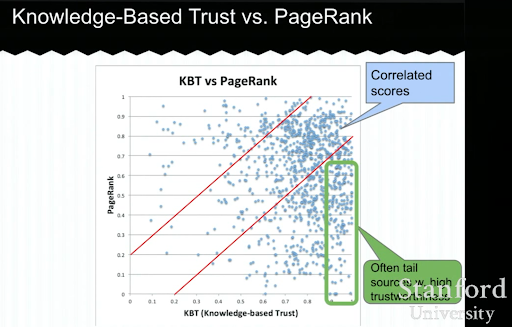
비공개 SEO 채팅 중에 이 교육 강의를 공유한 Arnout Hellemans에게 감사드립니다. 지식 기반 신뢰: Stanford Seminar – 지식 보관소 및 지식 기반 신뢰에 대해 자세히 알아보려면
컨텍스트 커버리지란 무엇입니까?
문맥 범위와 주제 범위는 지식 영역과 동일하지 않으며 문맥 영역은 동일하지 않습니다. 컨텍스트 범위는 개념의 처리 각도를 나타냅니다. 개념은 다른 것들에 대한 상호 포인트를 기반으로 처리될 수 있습니다. 예를 들어 기업이 국가인 경우 환경 위기에 대한 입장을 처리할 수 있습니다. 다른 나라들이 같은 각도에서 처리된다면 우리가 맥락적 영역을 다루고 있다는 뜻이다.

Google 검색 엔진은 시간이 지남에 따라 연구 논문과 특허를 구축합니다. 위 섹션의 오른쪽 인용은 "문맥 벡터"에 대한 속성이고 왼쪽 섹션은 "구 분류"에 대한 속성입니다. 재미있는 점은 예를 들어도 '디지털 카메라'가 동일하다는 점이다.
이러한 조합의 심화된 세부 사항과 하위 부분은 컨텍스트 도메인 내의 컨텍스트 레이어를 나타냅니다. 이름이 지정되었는지 여부에 관계없이 모든 엔터티에는 많은 컨텍스트 도메인이 있습니다. 따라서 Google은 더 많은 컨텍스트 도메인을 추출하고 사용자는 매년 더 긴 검색어를 검색합니다. 자연어 처리 및 자연어 이해가 개발되면 쿼리와 문서가 세부 사항 및 컨텍스트 측면에서 함께 확장됩니다.
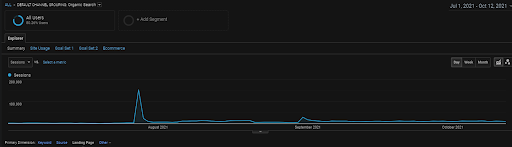
BogaziciEnstitu 프로젝트의 지난 4개월 동안의 GA 유기 세션 그래픽. 프로젝트의 "이력 데이터 획득 단계"로 인해 증가된 세부 정보가 선형으로 표시되기에 명확하지 않습니다.
컨텍스트 범위는 "컨텍스트 한정자"로 이해할 수 있습니다. 문맥 한정자는 형용사, 부사 또는 "for, in, at, during, while"로 시작하는 구와 같은 다른 전치사가 될 수 있습니다. 아래의 엔터티 관련 질문은 컨텍스트 도메인 측면에서 동일하지 않습니다.
- 불면증이 있는 어린이에게 가장 유용한 과일은 무엇입니까?
- 불안을 가진 아이들에게 가장 유용한 과일은 무엇입니까?
아래의 엔터티 관련 질문은 컨텍스트 레이어 측면에서 동일하지 않습니다.
- 6세 이상의 심한 불면증이 있는 어린이에게 가장 유용한 과일은 무엇입니까?
- 6세 미만의 낮은 수준의 불안을 가진 아이들에게 가장 유용한 과일은 무엇입니까?
아래의 엔터티 관련 질문은 지식 영역 측면에서 동일하지 않습니다.
- 6세 이상 심한 불면증이 있는 어린이에게 가장 유용한 책은 무엇입니까?
- 6세 미만의 낮은 수준의 불안을 가진 아이들에게 가장 유용한 게임은 무엇입니까?
그러나 이러한 모든 질문은 유사한 검색 활동 및 검색 관련 실제 활동을 가진 동일한 "개념" 및 "관심 영역"에 관한 것이기 때문에 동일한 시맨틱 콘텐츠 네트워크에 있을 수 있습니다.
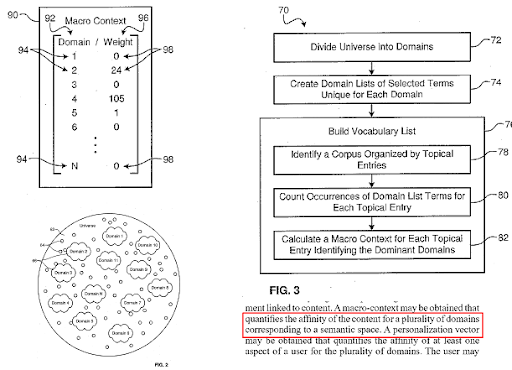
검색 엔진은 웹을 서로 다른 지식 영역으로 나누고 소스, 웹 페이지 및 웹 페이지 섹션에 대한 매크로 및 마이크로 컨텍스트 점수를 동시에 계산합니다.
새로운 개념이 많이 있다는 것을 알고 있으며 이것이 이 기사의 간략한 버전이므로 여기에서 모든 것을 이야기할 수는 없지만 향후 Semantic SEO 과정에서 다음과 같은 것들을 처리할 것입니다. "검색 활동"과 "검색 관련 실제 활동"의 차이.
좀 더 구체적인 것들로 조금 더 진행해 봅시다.
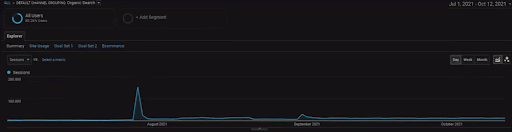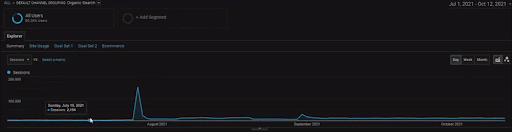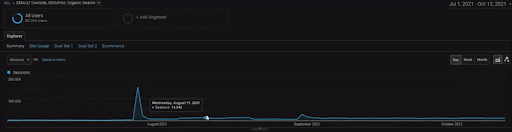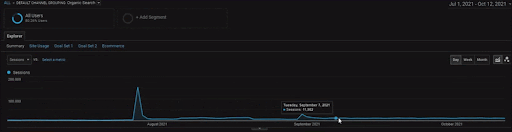
BogaziciEnstitu 프로젝트의 세부 사항을 보려면 대화형 이미지 버전을 확인할 수 있습니다. 이 프로젝트에서는 과거 데이터 소스 이벤트 이후에 검색 엔진의 테스트 및 순위 재지정 프로세스가 더 명확해졌습니다.
MuM은 시맨틱 콘텐츠 네트워크와 어떤 관련이 있습니까?
통합 변환기 또는 다중 작업 통합 모델을 사용한 다중 작업 학습은 언어 모델을 교육하여 텍스트뿐만 아니라 시각적 입력을 평가합니다. 이해와 함께 텍스트를 생성할 수 있습니다. 또한 MuM은 언어에 구애받지 않습니다. 즉, Semantic SEO는 언어 기술에 의존하지만 언어에 국한되지 않습니다. 엔터티에는 언어가 없고 의미가 보편적이므로 MuM은 여러 언어와 여러 컨텍스트의 정보를 단일 지식 기반으로 활용합니다.
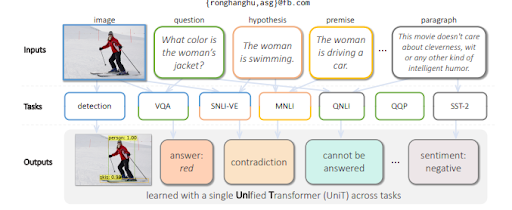
시각적 개체의 질문에 답하기 위해 MuM은 이미지 내에서 감지된 개체를 기반으로 질문을 생성합니다. 가까운 장래에 오디오 및 비디오 관련 질문도 생성될 수 있을 것입니다.
MuM은 변환기 인코더-디코더 구조로 객체 감지 및 자연어 이해를 위해 서로 다른 도메인을 사용합니다. 모든 입력은 단일 공유 디코더에서 평가되는 동안 개방형 웹의 다른 영역에서 제공됩니다. 아래에서 연구 논문의 추가 예를 볼 수 있습니다.
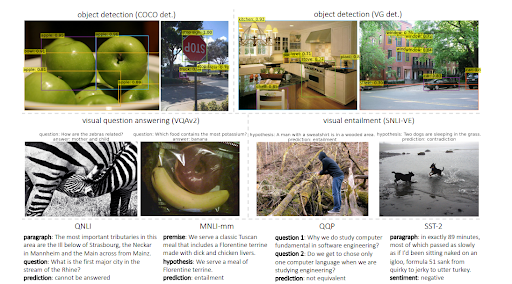
참고로 MuM은 BERT보다 1000배 더 강력할 수 있지만 BERT는 여전히 MuM의 텍스트 인코더 내에서 사용됩니다. MuM의 가장 큰 장점은 영상과 음성을 직접적으로 사용할 수 있다는 점입니다. 그래서 '멀티태스킹' 모델이라고 할 수 있습니다. 두 번째 장점은 모든 언어 장벽을 직접 제거한다는 것입니다. 세 번째 장점은 추가 중개자 없이 모든 것을 다른 것과 연결할 수 있다는 것입니다. 네 번째 장점은 MUM이 BERT와 달리 텍스트도 생성할 수 있다는 것입니다.
MuM, 지식 기반, 시맨틱 네트워크 및 컨텍스트 커버리지 간의 연결은 검색 엔진이 컨텍스트 한정자 및 가능한 지식 도메인과의 조합을 통해 훨씬 더 컨텍스트 도메인을 찾을 수 있다는 것입니다. 따라서 적절한 토픽 맵 및 소스 컨텍스트로 형성되는 잘 구조화된 시맨틱 콘텐츠 네트워크는 토픽 권위와 함께 지식 기반 신뢰를 향상시킬 수 있습니다.
소스의 컨텍스트는 무엇입니까?
소스의 컨텍스트는 두 가지를 나타냅니다. 소스의 중앙 검색 인터넷 및 관련 검색 활동으로 수행할 수 있는 중앙 검색 활동. 전자 상거래 웹 사이트의 경우 소스 컨텍스트는 특정 제품 또는 특정 유형의 제품을 구매하는 것입니다. 여행 웹사이트인 경우 소스의 컨텍스트는 다른 유형의 음식, 풍경 또는 비즈니스를 위해 다른 곳에서 이동합니다. 소스의 컨텍스트를 기반으로 시맨틱 콘텐츠 네트워크 디자인 및 주제 맵을 추가로 구성해야 합니다. 이를 위해서는 주제 맵 내의 중앙 섹션과 주제 맵 내의 보충 섹션을 선택해야 합니다.
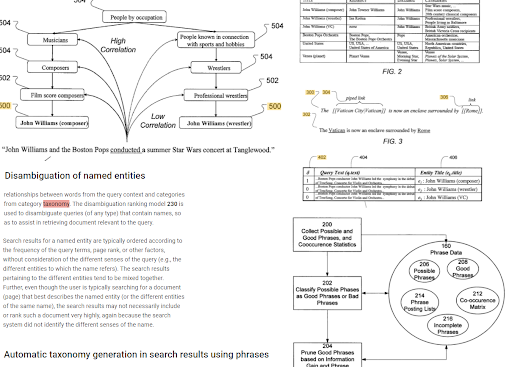
구문 기반 인덱싱과 엔터티 중심 검색 이해는 의미를 기반으로 서로 연결됩니다. 위에서 "명명된 엔터티 명확화"와 "구를 사용한 검색 결과의 자동 분류 생성"은 "컨텍스트"를 결정하기 위해 함께 볼 수 있습니다. 좋은 문구와 주제에 대한 독특하지만 상관관계가 있는 정보는 더 나은 초기 및 재순위 지정에 도움이 됩니다.
다시 말하지만, 이러한 개념 중 일부, "주제 맵 구성", "의미론적 콘텐츠 네트워크 디자인"은 아직 정의되지 않았으며 이는 적절한 위치가 아닙니다. 그러나 관련 검색 활동은 표준 검색 의도 및 이러한 표준 검색 의도에 대한 대표 문구와 함께 설명되었습니다.
시맨틱 네트워크 중심 SEO 사례 연구의 배경
위의 개념을 기반으로 Semantic Networks를 사용하여 SEO 사례 연구를 만들었습니다. 이 기사의 시작 부분에서 언급한 두 개의 웹사이트 프로젝트를 살펴보고 결과를 살펴보고 Semantic Networks를 구현하여 이를 생성한 방법을 살펴보겠습니다.
이러한 네트워크가 얼마나 강력할 수 있는지에 대한 아이디어를 제공하기 위해 시맨틱 네트워크 중심의 SEO 사례 연구에 대한 SEO 관련 결과가 아래에 나열되어 있습니다.
- 시맨틱 네트워크 이해는 적절한 토픽 맵을 생성하는 데 필요합니다.
- 두 프로젝트 모두 시맨틱 SEO의 효과를 분리하기 위해 Technical SEO가 사용되지 않습니다.
- 같은 이유로 Page Speed Optimization은 사용되지 않습니다.
- 디자인 및 WUX(웹사이트 사용자 경험) 최적화를 사용하지 않습니다.
- 백링크(외부 참조 및 PageRank 흐름)는 사용되지 않습니다.
- 두 브랜드 모두 과거 데이터가 없습니다. Vizem.net은 완전히 새로운 것이고 BogaziciEnstitusu는 오래된 역사를 가지고 있지만 실제 회사보다 낮습니다.
- OnPage SEO 또는 SEO의 다른 카테고리는 사용되지 않습니다.
- 두 브랜드 모두 이전의 Topical Authority 사례 연구 사례보다 더 나은 서버를 보유하고 있습니다.
이 Semantic Network 중심의 SEO 사례 연구는 두 개의 다른 웹사이트에 초점을 맞춘 두 가지 방법론과 개념으로 Semantic SEO 관점을 개선하려는 사람들을 도울 것입니다.
프로젝트 2: Vizem.net은 비자 신청 절차에 중점을 둡니다. 이 프로젝트를 작성, 게시 또는 시작하기 전에 저는 이 두 웹사이트를 다른 고객이나 파트너에게 여러 번 보여주었습니다. 그리고 Vizem.net은 최근 "Topical Authority" 여정을 시작했습니다.
Semantic Networks 사례 연구에 기반한 SEO 는 두 가지 다른 버전으로 작성되었습니다. 검색엔진의 의사결정트리를 더 깊이 이해하면서 관련 특허와 연구논문, 심도깊은 심사, 해석을 검색엔진의 관점에서 읽고 싶다면 초기 랭킹과 재 랭킹 SEO의 중요성을 읽어보세요. 30,000단어보다 긴 사례 연구 기사. SEO 및 역사적 배경에 대한 이론적 지식이 충분하지 않은 경우 계속해서 요약을 읽을 수 있습니다.
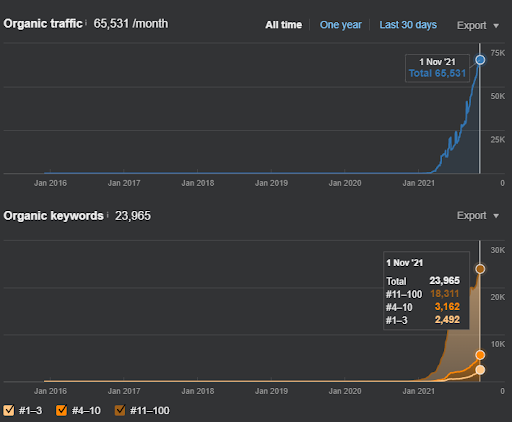
아래에서 SEMRush의 두 번째 프로젝트(Vizem.net) 그래픽을 볼 수 있습니다.
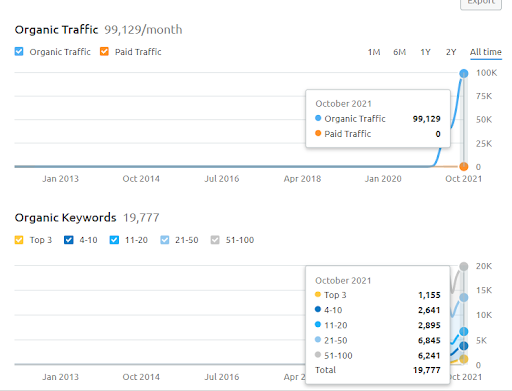
두 번째 웹사이트의 SEMRush 그래픽. Vizem.net은 “Visa Application”과 같이 뿌리 깊은 경쟁자가 있는 산업을 대상으로 하는 완전히 새로운 소스입니다. 특히 최근 터키에서 열리는 이벤트로 업계의 경쟁 수준이 높아지고 있다. 따라서 콘텐츠 네트워크를 생성하기 위해 시맨틱 네트워크 관점을 사용하는 것이 유용합니다.
첫 번째 프로젝트: Istanbul Bogazici Enstitusu: 3개월 만에 600% 유기적 클릭 증가 – 과거 데이터 및 초기 순위 활용
IstanbulBogazici Enstitusu는 검색 엔진 때문이 아니라 사람들과 내 건강 문제 때문에 내가 수행한 가장 어려운 SEO 사례 연구 중 하나입니다. 따라서 나는 프로젝트를 떠났고 소스의 컨텍스트를 기반으로 의미론적 관계를 완성하도록 설계된 세 번째 의미론적 콘텐츠 네트워크를 게시하지 않았습니다. 지식 영역 용어가 없고 문맥 구문이 적절하게 구현되어 있더라도 충분한 수준의 의미 연결 및 정확도로 구성되어 제3의 콘텐츠 네트워크가 다음과 같은 경우 월 3백만 세션 이상의 전체 유기적 검색 성능을 허용합니다. 두 번째 의미론적 콘텐츠 네트워크의 증가하는 효과를 설명하는 미래에 게시됩니다.
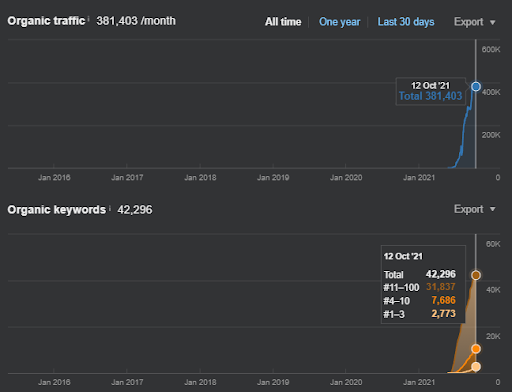
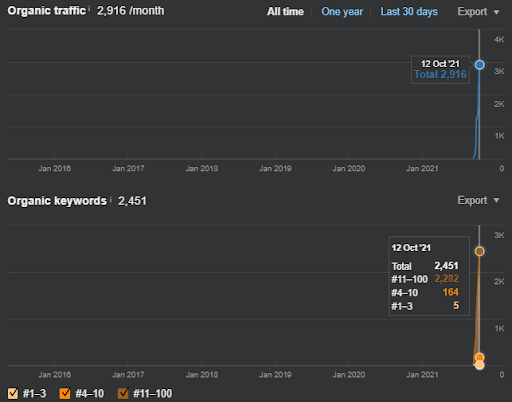
아래에서 지난 12개월 동안 GSC에서 IstanbulBogazici Enstitusu의 변화하는 그래픽을 볼 수 있습니다. 프로젝트는 2021년 5월에 적절한 방식으로 시작되었으며 2개의 Semantic Content Networks를 게시하여 2021년 9월 내에 종료되었습니다.
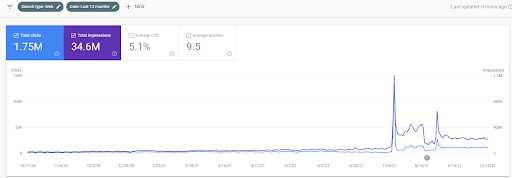
아래에서 더 자세한 버전을 볼 수 있습니다. 1400 일일 클릭에서 140000 클릭까지, 그리고 자연 검색 실적 내에서 하루에 10,000+ 이상의 일반 클릭을 볼 수 있습니다.
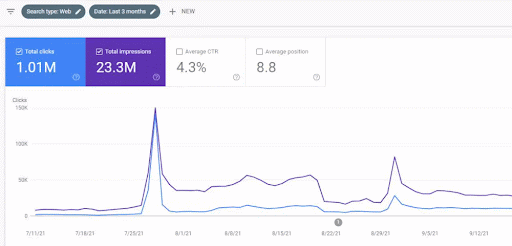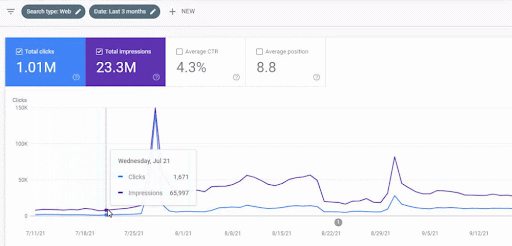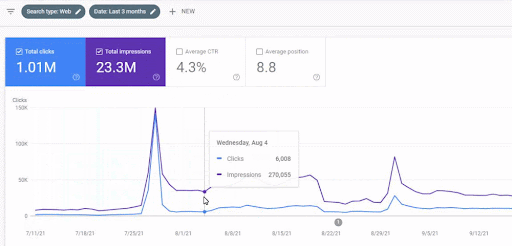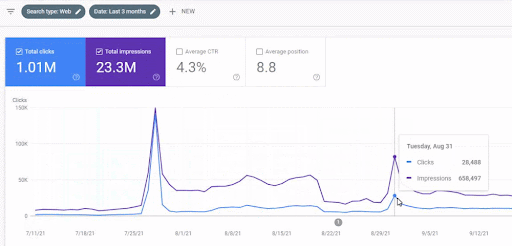
런칭 후 첫 번째 콘텐츠 네트워크의 트래픽 증가는 아래에서 볼 수 있습니다.
이 스크린샷은 First Semantic Content Network의 4번째 달을 보여줍니다.
그래픽에서 볼 수 있듯이 전체 웹 사이트의 전체 트래픽은 "교육 분기"에 중점을 둔 First Semantic Content Network에 의해 지배되고 영향을 받았습니다. 이 웹사이트로 시작한 두 번째 콘텐츠 네트워크는 Google Search Console에서 아래에서 볼 수 있습니다. 아래 스크린샷은 2차 시맨틱 콘텐츠 네트워크의 16일째입니다.
초기 순위 및 순위 재지정은 소스를 테스트하기 전에 유형 및 목적과 함께 순위 알고리즘의 단계를 정의하고 인기가 있는 더 중요한 쿼리에 대한 SERP 내 소스의 웹 페이지를 정의하기 때문에 기사 내에서 사용되었습니다. .
첫 번째 프로젝트의 첫 번째 시맨틱 콘텐츠 네트워크는 무엇에 중점을 두었습니까?
"의미론적 콘텐츠 네트워크"는 지식 기반의 의미론적 네트워크를 사용하여 지식 기반 내 사물 간의 주요, 2차 및 3차 관계를 설명합니다. 따라서 시맨틱 콘텐츠 네트워크를 생성하려면 웹사이트의 주요 기능인 소스 컨텍스트를 기반으로 다음 시맨틱 콘텐츠 네트워크를 설계해야 합니다. 이러한 맥락에서 최초의 의미론적 콘텐츠 네트워크는 “대학 학과, 교육 분과, 특정 조직 및 분과 내에서 대학 교육에 필요한 것”에 초점을 맞추어 왔다.
아래에서 First Semantic Content Network의 Ahrefs 그래픽을 찾을 수 있습니다.
이것은 이전 스크린샷에서 5일 후입니다.
"루트: istanbulbogazicienstitu.com/bolum", 첫 번째 초기 순위 단계 후 순위 재지정 프로세스가 더 효율적이고 생산적입니다.
'재순위'의 성격을 뒷받침하기 위해 아래와 같이 4일 후 버전을 볼 수 있습니다.
1차 프로젝트의 2차 시맨틱 콘텐츠 네트워크는 무엇에 중점을 두고 있습니까?
두 번째 의미론적 콘텐츠 네트워크는 직업, 직업, 기술 및 이러한 기술 또는 일상에 필요한 교육에 초점을 맞추었습니다. 첫 번째 의미론적 콘텐츠 네트워크를 기반으로 두 번째 의미론적 콘텐츠 네트워크가 지원되었습니다. 그리고 "질의 템플릿-의도 템플릿"에 따르면 두 개의 다른 의미론적 하위 콘텐츠 네트워크가 더 생성되어 "관계 연결"로 배치되고 유사한 상위 계층 수준에 연결됩니다.
아직 아래 항목에 대한 정의를 보지 않았기 때문에 이 섹션이 복잡하다는 것을 알고 있습니다.
- 시맨틱 콘텐츠 네트워크
- 소스 컨텍스트
- 시맨틱 하위 콘텐츠 네트워크
- 기술 자료
- 관계 연결
- 초기 순위
- 순위 재지정
- 문맥 범위
- 비교 순위
- 사실 추출
두 번째 웹사이트를 설명하고 나면 이러한 개념과 문장을 이해하기가 더 쉬울 것입니다.
Vizem.net: 6개월 동안 하루에 0에서 9,000개 이상의 일일 클릭 – 문맥 적용 범위를 활용한 비교 순위
지난 12개월간 Vizem.net의 그래프를 볼 수 있습니다. 이번 프로젝트는 코로나19로 인해 투자자가 헬스클럽 출신이라 경제적인 어려움을 많이 겪었습니다. 따라서 경제적인 문제로 인해 프로젝트 속도가 느려지고 "순위 재지정 프로세스"에 약간의 대기 시간이 발생했다고 말할 수 있습니다.
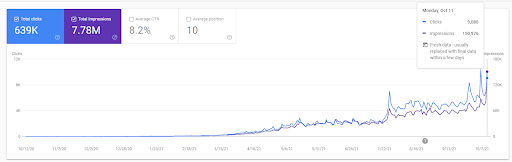
초기 순위를 이해하고 조금 더 순위를 다시 매기려면 아래 그래프를 사용할 수 있습니다.
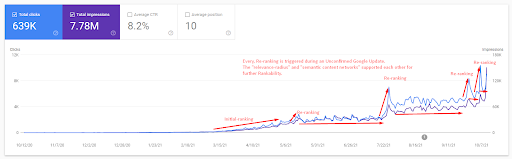
위의 그래픽에서 초기 랭킹 및 재 랭킹과 관련된 정의 중 일부는 아래에서 찾을 수 있습니다.
- Unconfirmed Google Updates 동안 큰 순위 상승이 발생했습니다. 일부 테스트에서는 일부 추천 스니펫을 제공했으며 사람들은 질문도 했습니다.
- Google의 일부 테스트에서 FS 및 PAA 수입이 삭제되었습니다.
- 매번 두 개의 순위 재지정 프로세스 사이의 타임라인은 더 짧아졌습니다.
- 순위 재지정 프로세스는 매번 소스의 순위 가능성을 개선했습니다.
- 소스는 쿼리 클러스터를 확장하는 동안 항상 관련성 반경을 개선했습니다.
참고로 아래에 한 문장 남길 수 있습니다.
검색 엔진이 웹 페이지의 색인을 생성한다고 해서 검색 엔진이 웹 페이지를 이해했다는 의미는 아닙니다. 인덱싱은 이해하는 것보다 빠르게 발생하며 대부분의 경우 검색 엔진은 "처음에" 예측이 포함된 웹 페이지의 순위를 지정합니다. 이해 후 "재 순위 지정"이 발생합니다. 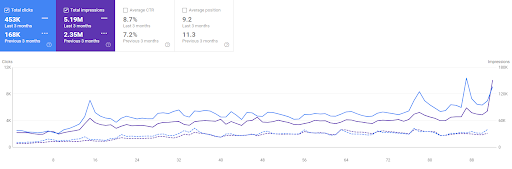
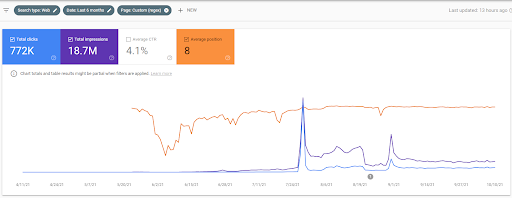
Vizem.net의 지난 3개월 비교
Vizem.net의 시맨틱 콘텐츠 네트워크는 어떻습니까?
내 고객, 친구 또는 비밀 SEO 그룹 중 많은 사람들이 회의 중에 "폭발할 것입니다"라고 말함으로써 이 두 웹사이트를 모두 시연한 것을 기억합니다. 그리고 이 글을 쓰면서 나는 이렇게 말한다.
"istanbulbogazicienstitu.com/meslek" Semantic Content Network가 폭발할 것이기 때문에 시청하십시오. 그리고, 이 글을 쓰기 전에 제가 공개한 영상에서 계절적 사건의 "과거 데이터"와 그것이 초기 및 순위 재지정 과정에 미치는 영향을 시연할 수 있습니다. 아래에서 볼 수 있습니다.
이를 기반으로 Vizem.net의 Semantic Content Network는 IstanbulBogazici Enstitusu와 유사하지 않으므로 "집약적인 수준의 Topical Coverage 및 Historical Data 증가"를 사용하지 않고 특정 관련 권한을 생성해야 했습니다. 엔터티 유형, 해당 속성 및 이러한 엔터티-속성 쌍에 대한 쿼리 이면의 가능한 작업. Vizem.net에는 "교육 대학 지점" 또는 "직업 및 온라인 과정"만 포함되어 있지 않습니다. "비자 신청 국가"가 있습니다. 따라서 충분한 수준의 주제 권한을 생성하려면 적어도 190개의 서로 다른 의미론적 콘텐츠 네트워크와 시간이 지남에 따라 일관성이 필요합니다.
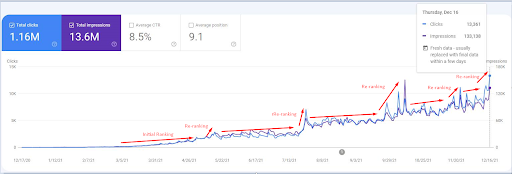
2021년 12월 18일의 스크린샷입니다. 계속해서 순위가 재조정되고 노출수와 클릭수가 증가하는 것을 볼 수 있습니다. 이전 스크린샷에서 4주 후입니다.
순위 재지정 이벤트를 보려면 Semantic SEO의 효과를 보여주는 기본 검색 성능 그래픽의 네이키드 버전을 비교할 수 있습니다. 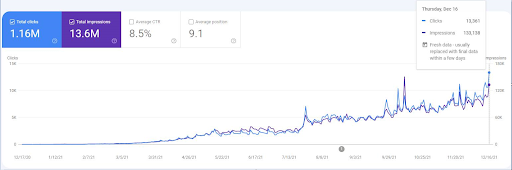
이 190개의 서로 다른 의미론적 콘텐츠 네트워크는 "국가" 자체를 기반으로 형성되며 국가는 검색 활동 범위를 개선하기 위해 가능한 모든 컨텍스트 레이어와 함께 주제 맵의 중앙에 배치됩니다.
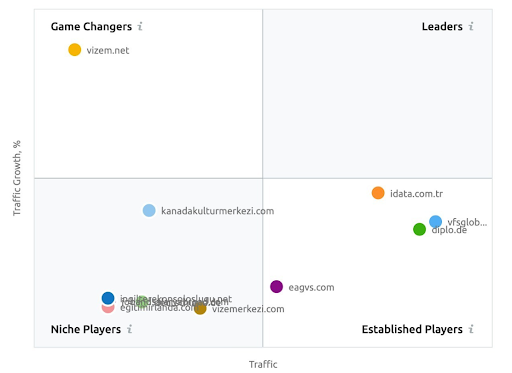
다른 업계 플레이어와 달리 Vizem.net에 대한 인식을 보여주는 SEMRush의 스크린샷.
Vizem.net만을 위한 다른 동영상도 게시했습니다. 이 영상에서는 웹사이트의 마지막 상황이 존재하지 않기 때문에 오늘과 그 날을 잘 비교할 수도 있다고 생각합니다.
마지막으로 관련 없는 기사, 웹사이트 세그먼트 또는 소스 내에 관련 없는 내용을 게시하면 특정 지식 도메인에 대한 웹 엔터티의 전반적인 관련성이 감소할 수 있습니다. Vizem.net은 그 진정한 가치를 보여줄 것이며, 향후 Rankability는 훨씬 더 좋아질 것입니다.
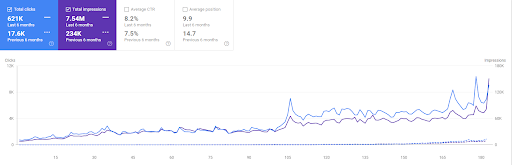
Vizem.net의 지난 6개월 비교.
계속하기 전에 이것이 긴 기사라는 것을 압니다. 그러나 실제로 이것은 매우 복잡한 SEO 방법론에 대한 간략한 설명입니다. Semantic Content Networks는 설계하는 동안 너무 많은 생각을 하고 클라이언트, 작성자 및 온보딩을 위한 수개월의 교육을 필요로 합니다. 따라서 이 기사에서는 가장 실행 가능한 간략한 제안과 중요한 Google 및 기타 검색 엔진의 특허, 연구 논문과 함께 개념의 정의에 초점을 맞추고자 합니다. 긴 버전(기본적으로 책)에서는 시맨틱 콘텐츠 네트워크의 "초기 순위 지정"과 "재 순위 지정"에 중점을 두었습니다.
더 자세히 알고 싶다면 "SEO를 위한 초기 순위 및 재순위의 중요성"을 읽으십시오.
지금까지 아래 사항을 처리했습니다.
- 시맨틱 네트워크
- 기술 자료
- 시맨틱 콘텐츠 네트워크
- 지식 기반 신뢰
- 문맥 범위
- 컨텍스트 도메인 및 레이어
- 의미론적 콘텐츠 네트워크에 대한 MuM의 관련성
- 소스의 컨텍스트
이러한 개념은 시맨틱 콘텐츠 네트워크가 작동하는 방식과 주제 맵과 함께 사용되는 방식을 이해하기 위한 것입니다. 다음 섹션은 검색 엔진이 시맨틱 콘텐츠 네트워크의 초기 및 이후 순위를 매기는 방법에 관한 것입니다. 이와 관련하여 아래 사항을 처리합니다.
- 초기 순위
- 순위 재지정
- 쿼리 템플릿
- 문서 템플릿
- 검색 의도 템플릿
- 시맨틱 콘텐츠 네트워크를 활용하기 위해 해야 할 일
SEO의 초기 순위는 무엇입니까?
이것은 SEO의 새로운 용어이자 개념이지만 검색 엔진의 경우 오래된 용어입니다. "시맨틱 네트워크 중심 SEO 사례 연구"의 긴 버전은 쿼리 종속, 문서 종속, 소스 종속 알고리즘 및 여러 특허를 기반으로 하는 순위 알고리즘에 중점을 둡니다. 예측 정보 검색 또는 예측 순위 알고리즘은 계산 비용을 줄이려고 합니다. 그리고 인덱싱이 하루 만에 이루어지더라도 문서를 이해하는 데 몇 달 또는 몇 년이 걸릴 수 있습니다. 따라서 초기 순위를 계산하는 것은 비용을 줄이면서 SERP 품질을 향상시키는 방법입니다. 일부 검색 엔진 관련 작업은 인덱스를 살아 있고 신선하며 충분히 높은 품질로 유지하기 위해 다른 작업보다 우선 순위가 높습니다.

초기 순위라는 용어는 검색 엔진 제작자 사이에서 고전적인 관점이기 때문에 수만 개의 서로 다른 Google 특허 및 연구 논문에 나타납니다. 따라서 위에서 동일한 단락이 계속되는 다른 특허 문서와 용어 초기 순위를 중심으로 약간의 변경이 있는 용어를 볼 수 있습니다.
초기 순위는 색인이 생성된 직후 SERP에서 문서의 순위를 나타냅니다. 문서의 초기 순위는 전체 권한과 특정 주제, 쿼리 템플릿 및 검색 의도에 대한 소스의 관련성을 나타냅니다. 동일한 콘텐츠가 다른 소스 간의 초기 순위 측면에서 다르게 순위가 매겨질 수 있습니다. 초기 순위는 Semantic Content Networks를 사용하여 소스의 전반적인 품질과 권한 증가를 확인하는 동안 중요합니다. 모든 새 문서는 시맨틱 콘텐츠 네트워크 디자인이 올바르게 구성되어 있으면 색인 생성 지연을 줄이면서 초기 순위를 높입니다.
초기 순위는 순위 재지정 프로세스와 소스에 대한 효율성을 지원합니다. 그리고 "출처의 순위 가능성"은 초기 및 재 순위라는 두 가지 용어로 처리되어야 합니다.
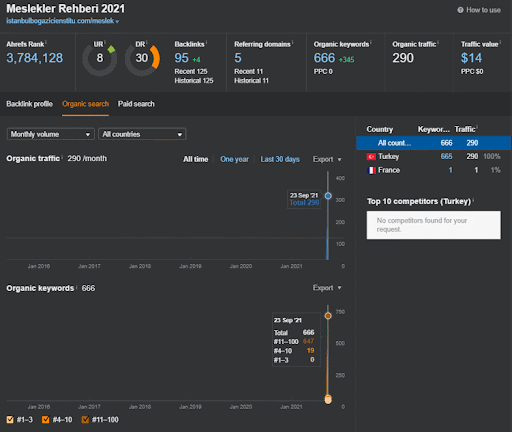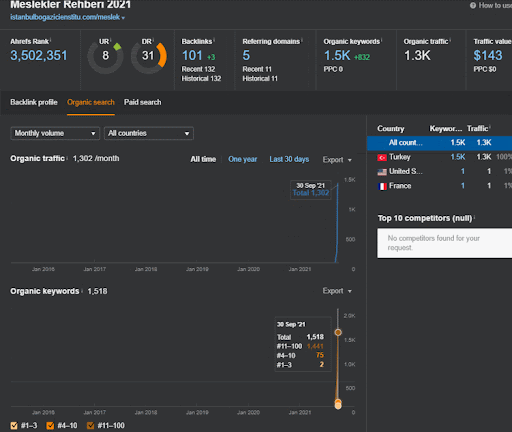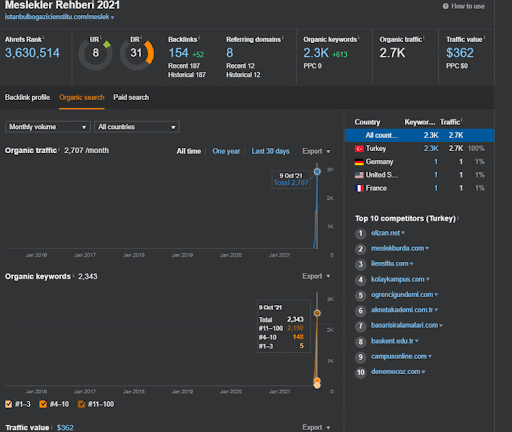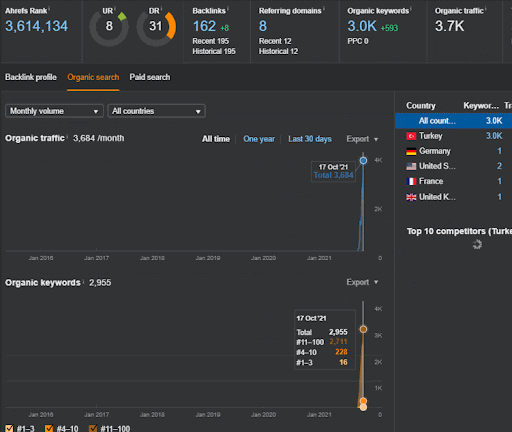
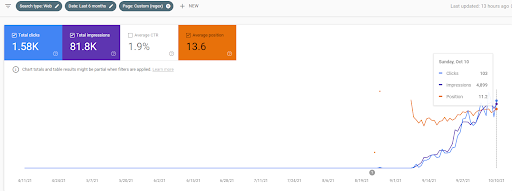
프로젝트 I에서 Second Content Network의 유기적 성과 변화의 첫 20일을 볼 수 있습니다.
이러한 맥락에서 Vizem.net이 새 문서를 게시할 때마다 또는 IstanbulBogazici Enstitu가 새로운 의미론적 콘텐츠 네트워크를 게시할 때마다 콘텐츠가 더 빨리 색인화되는 동안 초기 순위가 이전보다 좋습니다.
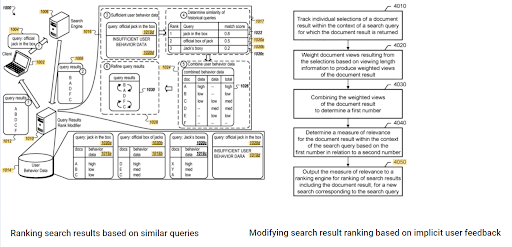
초기 순위와 과거 데이터의 중요성은 이 두 개의 보완적인 Google 특허 사이에서 볼 수 있습니다. 하나는 암시적 사용자 피드백을 기반으로 문서의 초기 및 순위를 재지정하는 것입니다. The other one is for doing the same if enough level of user data doesn't exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine's point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document's ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the IstanbulBogazici Enstitu in terms of the initial and re-ranking. 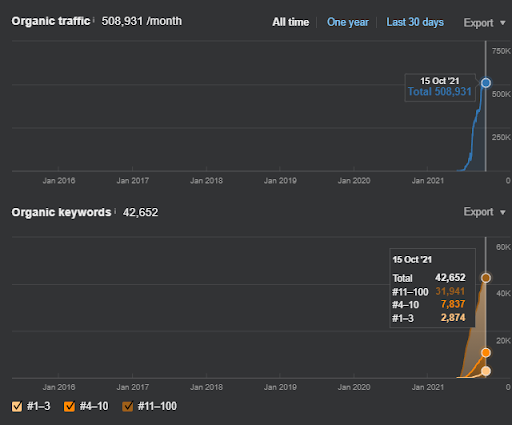
15 October 2021, performance of the first semantic content network of the IstanbulBogaziciEnstitusu which is the 124th day of the launch. 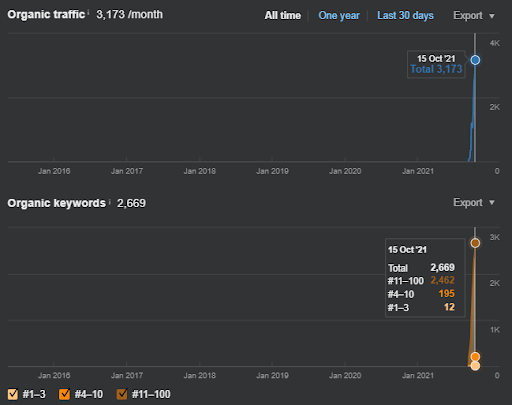
15 October 2021, performance of the Second Semantic Content Network of IstanbulBogazici Enstitu which is the 19th day of the launch. 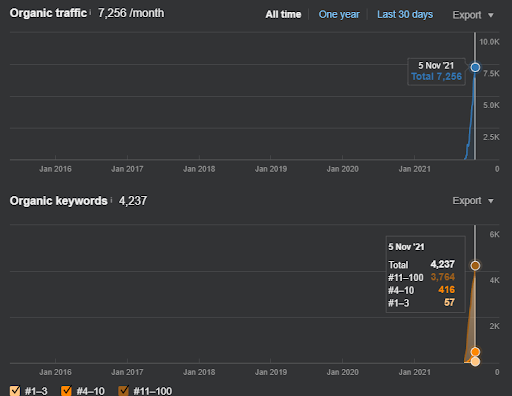
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”. 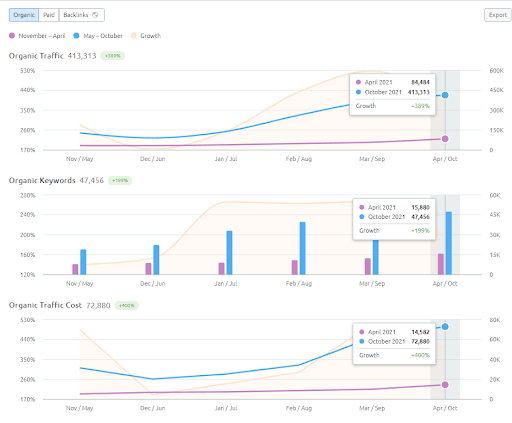
The 6 Months of Growth Comparison of the IstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source's context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction's validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.
In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months' for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.
Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.

The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
온크롤 데이터³
 더 알아보기
더 알아보기What is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them. 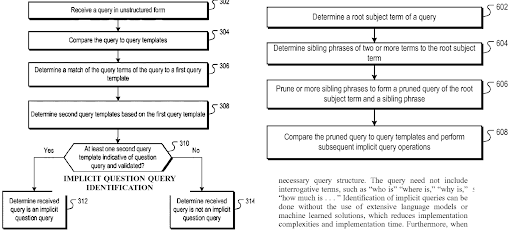
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.
In this context, a query template can be used for feeding the search engines' historical data for creating trust. Even if a search engine doesn't understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas. 
“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it. 
A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian , meaning that they are more influenced by the current page than their history of navigation. 
A section that explains how a search engine can use the document templates to see a user's interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”. 
A section from the “Are web users Markovian?” research paper.
예, 그렇습니다. Probabilistic Ranking, Degraded Relevance Ranking은 사용자를 이해하고 가능성의 상태에 대비한 최고의 품질의 SERP를 생성하기 위한 시맨틱 검색 엔진의 주요 컬럼입니다. 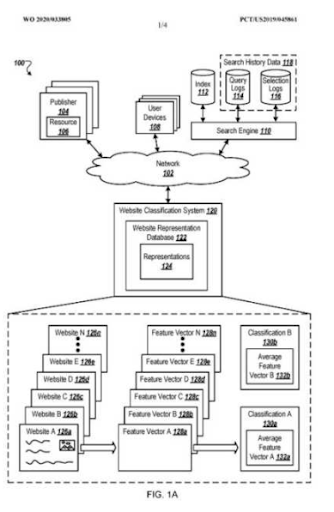
이전에 Bill Slawski는 웹사이트에 대한 표현 학습을 위해 "웹사이트 디자인, 모양 또는 색조"를 주장하기 위해 "웹사이트 표현 벡터"를 작성했습니다.
검색 의도 템플릿이란 무엇입니까?
검색 의도 템플릿은 쿼리 템플릿 이면의 필요성으로 나타낼 수 있습니다. 쿼리 문서 템플릿은 의도 템플릿을 기반으로 통합될 수 있습니다. 가능한 "Degraded Relevance Ranking" 및 "Probabilistic Ranking" 이해가 있는 검색 의도 템플릿이 있으면 올바른 순서로 최상의 검색 활동 및 검색 의도 범위를 만드는 데 도움이 됩니다. Semantic Content Network를 생성할 때 가장 중요한 것은 지식 기반 신뢰와 주제 권위를 향상시키기 위해 컨텍스트 커버리지를 개선하여 지식 도메인 기반 의미 네트워크를 완성하기 위해 소스 컨텍스트를 기반으로 문서 쿼리 의도 템플릿을 조정하는 것입니다. . 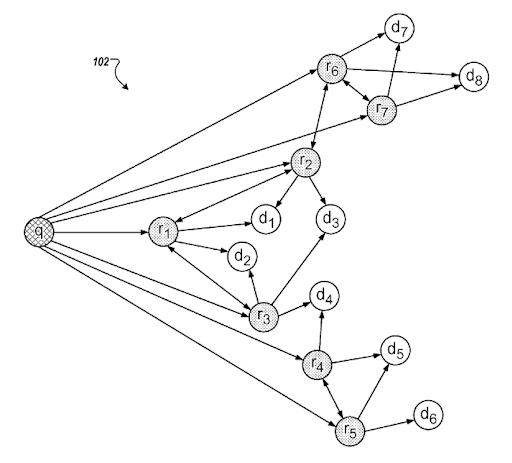
Google의 "추론된 의도를 기반으로 하는 쿼리 구체화" 섹션. 시맨틱 연결이 있는 쿼리 클러스터 및 인텐트 템플릿을 통해 작동합니다. 다양한 구문 분류 수준에서 이를 경험할 수 있습니다.
몇 가지 구체적인 예와 더 나은 시맨틱 콘텐츠 네트워크를 만드는 데 도움이 되는 제안으로 넘어가기 전에 이 SEO 사례 연구의 간단한 버전이라도 높은 수준의 검색 엔진 이해와 커뮤니케이션 기술이 필요하다는 점을 말씀드리고 싶습니다. 따라서 높은 수준의 정보를 제공한다고 느끼더라도 내가 만들 Semantic SEO 과정이 더 많고 더 나은 구체적인 예를 보여 줄 것이라는 것을 알고 있습니다. 
동일한 특허가 서로 다른 "쿼리 경로"와 "컨텍스트 이동" 간의 적절한 연결을 설명합니다.
시맨틱 콘텐츠 네트워크 활용에 대해 알아야 할 사항은 무엇입니까?
Semantic Content Network를 생성하기 위해 lexical semantics 또는 엔티티와 구문 간의 관계 유형을 기반으로 모든 관련 세부 정보를 입력하면 간단한 의미 컨텐츠 브리프 및 디자인조차도 1시간이 소요될 수 있습니다. 구문 기반 인덱싱과 같은 동시에 여러 각도를 사용하고 컨텍스트 도메인에 대한 전체 콘텐츠의 컨텍스트 관련성 또는 개별 하위 콘텐츠 유형을 기반으로 하는 관련성을 계산하기 위해 단어 벡터 또는 컨텍스트 벡터를 사용합니다. 높은 수준의 시맨틱 검색 엔진 이해가 필요합니다.
따라서 생성적 방법론을 사용하면 위에서 설명한 개념으로 모든 것이 더 쉬워집니다. 왜냐하면 모든 의미론적 콘텐츠 네트워크 부분을 완벽하게 준비하더라도 작성자와 작성자가 작성할 수 없거나 콘텐츠 관리자가 작성할 수 없기 때문입니다. 당신의 비전을 따를 수 없습니다. 따라서, 내가 충분히 활기차고 감사 가능한 방식으로 개념을 증명한 후 내가 이러한 SEO 사례 연구 프로젝트 중 일부에서 했던 것처럼 아무 이유 없이 피곤하게 만들고 프로젝트를 떠나게 만들 수 있습니다.
아래 제안 사항은 실행하기 쉽고 간단한 단계에 대해서만 도움이 될 것입니다.
1. 모든 시맨틱 콘텐츠 네트워크 네트워크에서 고정 사이드바 링크를 사용하지 마십시오.
모든 링크에는 웹 페이지 내의 모든 단어와 같이 두 개의 하이퍼텍스트 문서 간의 연결 설명이 있어야 합니다. 시맨틱 HTML 사용법은 웹 페이지에서 문서의 위치와 기능을 지정하는 데 도움이 될 수 있으며 검색 엔진이 컨텍스트 측면에서 섹션에 다른 가중치를 부여하는 데 도움이 됩니다.
Vizem.net 예제에서는 동일한 사이드바 디자인을 사용하지 않았습니다. 사이드바에 최신 게시물이나 가장 중요한 게시물이 표시되지 않았습니다. 사이드바는 중앙 엔티티의 속성만 표시하며 고정되지 않고 동적입니다. 즉, 주제 맵 내의 계층 구조를 기반으로 시맨틱 콘텐츠 네트워크 네트가 사이드바에 있더라도 변경됩니다. 
합리적인 서퍼와 신중한 서퍼 모델에 대해 생각하면 SEO가 서로 다른 하이퍼텍스트 문서 간의 관련성을 높이는 데 도움이 될 수 있습니다.
또한 링크는 중요도에 따라 흐르고 인기도는 가능한 최상의 연결에서 소스의 컨텍스트를 따라야 합니다. 아래에서 조정된 시맨틱 HTML 코드가 있는 사이드바 섹션을 볼 수 있습니다. 
사용자의 세션에서 활성화된 기사의 계층 구조에 따라 탭, 탭의 순서, 탭 내의 링크가 변경됩니다. 위의 예는 아래의 이동 경로 계층에서 가져온 것입니다. ![]()
2. PageRank로 시맨틱 콘텐츠 네트워크 지원
외부 PageRank가 외부 소스에서 필수가 아니더라도 사용할 수만 있다면 초기 순위와 재순위가 더 좋을 것이라는 것을 깨닫게 될 것입니다. 이 두 프로젝트 모두 사용하지 않았지만 이번에는 목적이 아니었습니다. Vizem.net의 경우 경제적인 문제가 있었고 디지털 PR과 홍보에 예산을 쓰고 싶지 않았습니다. Istanbul BogaziciEnstitusu의 경우 특정 주제에 대한 출처의 신뢰성을 지원하기 위해 몇 가지 "로컬로 상호 연결된 출처"를 마련했지만 다시 회사는 예산 및 조직 규율 문제로 인해 이를 구현할 수 없었습니다. 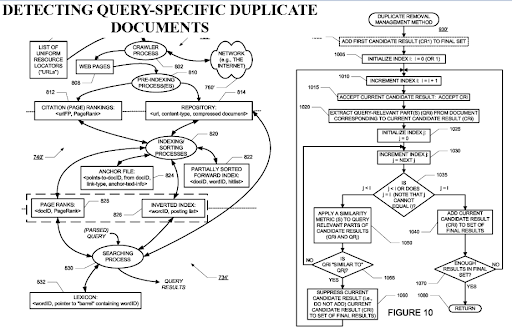
쿼리별 중복 문서 감지는 검색 엔진에서 중요한 관점입니다. PageRank는 문서가 중복되더라도 가치 있는 것으로 필터링하는 데 도움이 될 수 있기 때문입니다. 고도로 조직화된 의미론적 콘텐츠 네트워크는 서로 유사할 수 있으므로 PageRank 흐름 및 이력 데이터가 유용합니다.
이러한 유형의 시맨틱 콘텐츠 네트워크에 대한 외부 PageRank 흐름 지점을 선택할 때 기록 데이터가 있는 소스를 사용합니다. 제 경우에는 첫 번째 의미론적 콘텐츠 네트워크를 시작하고 게시하기 전에 이러한 PageRank 끝점을 더 일찍 정렬했습니다. 이런 식으로 직접 경쟁사로부터 외부 참조를 얻을 수 있었지만 시맨틱 콘텐츠 네트워크를 게시했을 때 경쟁업체는 경쟁자로서 소스의 대량 증가를 보았기 때문에 소스 연결을 포기했습니다.
이 상황은 우리를 세 번째 제안으로 이끕니다. 외부 참조에서 PageRank 흐름을 사용할 수 있다면 순위 재지정 프로세스가 더 빨라지고 초기 순위가 더 높을 것입니다.
3. 눈에 띄는 의미 체계 콘텐츠 네트워크 부분에 대해 바닥글, 머리글 및 주요 콘텐츠의 다른 앵커 텍스트 사용
검색 엔진의 관점에서 앵커 텍스트 또는 "링크 텍스트"는 하이퍼텍스트 문서가 다른 문서에 대한 관련성을 나타냅니다. PageRank의 원본 문서에 따르면 링크 수는 PageRank 흐름에 비례합니다. 그러나 나중에 Google은 "링크 스터핑"을 방지하고 실제로 PageRank를 통과할 수 있는 링크를 제한하기 위해 이를 변경했습니다. 이를 기반으로 TrustRank, Cautious Surfer, Hilltop Algorithm 또는 Reasonable Surfer Models가 개발됩니다. 
이것은 BogaziciEnstitusu에 대한 두 개의 다른 의미론적 콘텐츠 네트워크에 대한 두 개의 링크입니다. 그러나 기술적 SEO 또는 UX 개선을 구현하지 않았기 때문에 버튼 디자인의 "저렴함"을 깨달을 수 있습니다.
Google에 따르면 동일한 링크는 PageRank를 두 번째 다른 웹 페이지로 전달할 수 없지만 PageRank는 첫 번째 링크에서만 전달됩니다. 그리고 PageRank 알고리즘의 원래 형식에서 하이퍼텍스트 문서는 PageRank를 향상시키기 위해 자체적으로 링크되거나 301 리디렉션을 사용하여 링크 대상 문서의 PageRank를 취할 수 있습니다. 이 두 가지 상황 모두 PageRank를 가져오기 위해 웹 페이지를 일시적으로 다른 페이지로 리디렉션하는 것과 같은 오래된 Black Hat 기술을 만들었습니다. SEO가 구글 서치 콘솔이나 SERP에서 웹페이지의 PageRank를 볼 수 있었던 시절부터였습니다. 나중에 Google은 모든 리디렉션에 대해 PageRank를 약화시키기 시작했으며 Danny Sullivan은 301 리디렉션이 PageRank를 완전히 통과할 것이라고 설명했습니다. 이러한 모든 변경 사항 외에도 여기서 중요한 것은 두 번째 링크가 PageRank를 통과하지 못하더라도 여전히 링크 텍스트의 관련성을 통과한다는 것입니다. 
Semantic Content Network의 눈에 띄는 섹션은 "동사, 술어" 또는 "검색자의 활동"을 포함하는 "중간 쿼리 구체화"를 기반으로 홈페이지에서 연결되었습니다.
따라서 Semantic Content Network의 주요 섹션은 헤더 및 푸터 메뉴에서 상위 분류 섹션과 연결되어야 하며 링크 텍스트는 서로 달라야 합니다. 이 예제에서는 머리글 링크를 눈에 띄지만 짧은 링크 텍스트와 함께 사용하고 바닥글 예제는 더 길게 유지했습니다. 
"웹 크롤러 시스템의 앵커 태그 인덱싱" 섹션에서는 쿼리 클러스터 및 웹 페이지 클러스터 내에서 웹 페이지를 배치하기 위한 앵커 텍스트 및 주석 텍스트의 중요성을 요약합니다.
Semantic Content Network 섹션이 너무 눈에 띄는 경우 PageRank 및 크롤링 우선 순위를 적절하게 전달하기 위해 가장 중요한 섹션을 적절한 링크 텍스트와 연결하고 관련 N-Gram의 다양한 변형이 있는 두드러진 속성을 포함하는 설명 단락을 연결했습니다. 
Vizem.net 홈페이지에서 두 번째로 연결되는 영역으로 아코디언 뒤에 위치하며 쿼리 내 국가에 초점을 맞추고 시맨틱 콘텐츠 네트워크의 중간 부분을 연결합니다.
참고: 앵커 텍스트 주변에는 링크 목적의 정확성을 높이기 위해 항상 계획된 "주석 텍스트"가 사용되었습니다.
4. 링크 수 제한 및 데스크톱 및 모바일 링크 및 주요 콘텐츠 일치
두 프로젝트 모두 웹 페이지당 내부 링크가 150개 미만으로 제한됩니다. Semantic HTML의 도움으로 링크의 위치와 링크의 기능이 크롤러에게 명확해집니다. IstanbulBogazici Enstitusu에는 웹 페이지당 450개 이상의 링크가 있으며 이 중 일부는 자체 링크(같은 페이지에서 동일한 페이지로의 링크)였습니다. 최악의 부분은 이러한 링크의 절반이 콘텐츠의 모바일 버전 내에 존재하지 않는다는 것입니다. 
URL 유지 점수, 크롤링 점수 및 기타 유형의 점수를 사용하여 내부 URL 맵 내에서 링크의 중요도를 결정할 수 있으며 다양한 계층 내의 문서 식별 태그를 사용하여 쿼리 독립적 관련성 점수를 기반으로 색인을 정렬할 수 있습니다.
Google은 모바일 전용 인덱싱을 사용하기 때문에 콘텐츠가 모바일 버전에 존재하지 않으면 무시되며 관련성 평가 및 순위 지정 목적으로 사용되지 않습니다. 따라서 모바일 콘텐츠와 데스크톱 콘텐츠가 일치하도록 구성되었습니다. Google이 데스크톱 버전과 모바일 버전 간의 콘텐츠 불일치를 허용하더라도 검색 엔진이 웹 페이지를 이해하고 순위를 지정하는 것은 여전히 어렵습니다. 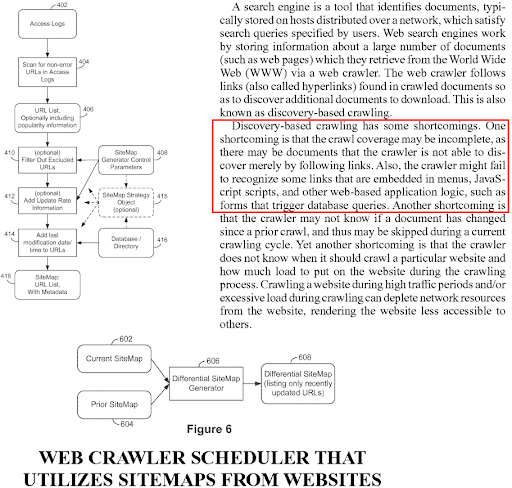
검색 엔진은 웹사이트에 대한 사이트맵을 생성할 수 있으며 링크와 URL 메타데이터가 사용자 에이전트 또는 타임라인 간에 일치하지 않는 경우 이 사이트맵은 루프에서 다시 생성될 수 있습니다. 따라서 크롤링 경로를 짧게 유지하고 크롤링 대기열을 간략하게 유지하며 내부 링크의 일관성을 유지하는 것이 중요합니다.
다른 웹 페이지 간의 링크와 함께 웹 페이지의 하위 섹션에 대한 링크도 "내용 목차" 및 "URL 조각"과 함께 사용됩니다. 이러한 URL 조각은 웹 페이지의 특정 하위 섹션을 대상으로 지정하면서 적절하게 이름을 지정하고 특정 섹션은 h2가 있는 섹션 태그에 삽입되었습니다. "페이지 내 탐색 링크"가 있는 URL 조각의 도움으로 SERP에서 웹 페이지의 특정 섹션으로 사용자를 방문하는 것이 더 쉬웠고 콘텐츠의 하단 섹션은 뒤에 있는 요구 사항을 충족하기 위해 더 눈에 띄게 되었습니다. 질문.
5. SEO 프로젝트에 대한 군사 수준의 훈련을 받으십시오.
이것은 완전히 다른 주제이며 군대 수준의 규율이 의미하는 바 또는 이것이 SEO 프로젝트에 유용한 이유를 정의하기 위해 또 다른 기사를 작성할 수 있습니다. 하지만 지난 2개월 동안 다른 에이전시의 많은 CEO와 SEO를 교육하여 내 코스 디자인이 잘 작동하는지 여부를 확인했습니다.
내가 수행하는 교육 세션에 대한 높은 수준의 이해와 성공을 볼 때마다 강한 의지와 끈기가 있습니다. 주요 문제는 Semantic SEO가 다른 SEO 카테고리보다 훨씬 어렵다는 것입니다. 기술 SEO는 보편적이며 모든 단계에 대한 가이드를 작성했습니다. OnPage SEO 또는 WUX 및 레이아웃 디자인은 숫자 측정으로 추적할 수 있습니다. Semantics에 관해서는 복잡한 적응 시스템을 기반으로 작동하는 기계의 관점을 기계가 작동하는 방식을 이해하지 못하는 호모 사피엔스와 통합하는 관행입니다.
이 구분은 프로젝트의 첫날부터 넣어야 하는 콘크리트 기초 지반이 필요합니다. 대부분의 경우 아래 규칙을 사용합니다.
- 콘텐츠 디자인과 의미론적 콘텐츠 네트워크는 저자나 작가에게 논리적일 필요가 없습니다.
- 콘텐츠 관리자의 임무는 콘텐츠 디자인과 콘텐츠의 호환성을 감사하는 것입니다.
- 저자의 임무는 높은 수준의 정확성과 세부 사항을 포함하는 관련 정보로 콘텐츠를 작성하는 것입니다.
- 링크, 정의, 증거, 비교, 명제, 참조는 보풀이 아닌 구체적인 예를 통해 이루어져야 합니다.
- 모든 불필요한 단어는 컨텍스트와 개념에 대한 희석입니다.
책을 읽으면 실천하기 쉬워 보일지 모르지만 그리 쉽지는 않습니다. 따라서 나는 심지어 내 직원 중 일부를 해고하려고 했다는 것을 알 수 있습니다. 적어도 지금은 그렇지 않아 다행입니다. 정상적인 상황에서는 질문 소유자가 SEO나 회사 소유자가 아니면 대답하지 않는 질문이 많이 있을 것입니다. 순위에 대한 중복되고 관련 없는 피드백이 아니라 긍정적인 피드백을 저장할 검색 엔진의 데이터 저장소에 에너지를 저장하십시오.
6. 상황에 맞는 소스 확장
이 섹션은 Google의 MuM 생성 필요성을 완전히 이해하는 것입니다. 토픽 맵을 디자인할 때 더 나은 사이트 수준 지식 기반을 제공할 많은 시맨틱 콘텐츠 네트워크가 포함됩니다. 따라서 이러한 하위 섹션을 게시하는 동안 소스의 컨텍스트에 연결할 수 있어야 합니다. 그렇지 않으면 검색 엔진이 소스를 보는 방식을 변경할 수 있고 웹사이트의 테마가 다른 지식 도메인으로 전환될 수 있습니다. 예를 들어, 개념과 관심 영역 주변의 사물을 가능한 행동으로 연결하려면 복잡한 의미가 서로 연결되어 있는지 이해해야 합니다. 이러한 연결을 사용자, 작가 및 기계에게 동시에 명확하게 하는 것이 시맨틱 콘텐츠 네트워크 생성 프로세스입니다. 
이를 수행하려면 웹사이트의 모든 새 섹션이 주제 맵의 중앙 섹션에 연결될 수 있어야 합니다. 이러한 컨텍스트 브리지는 Google 자체 LaMDA 설계 및 설명에서 확인할 수 있습니다.
"다른 주제에 대해 써야 하나", "두 개의 다른 틈새가 있으면 해가 될까요?"와 같은 질문을 많이 접합니다. 이러한 모든 하위 섹션, 웹 사이트 세그먼트를 강력하게 연결된 구성 요소로 연결하면 이러한 의미론적 콘텐츠 네트워크는 브랜드 아이덴티티를 나누는 대신 더 나은 순위를 위해 서로를 지원하고 서로 다른 두 가지 관련 없는 주제에 대한 주제 권한을 제공합니다.
7. Google Analytics Custom Segmentation으로 실제 트래픽 생성 및 감사
지식 기반 신뢰가 PageRank에 연결되는 것과 동일한 방식으로 실제 트래픽이 RankMerge에 연결됩니다. 곧, 검색 엔진이 부차적 신호로 PageRank에 영향을 미치려고 하는 이유를 설명하기 위해 "PageRank가 거짓말을 할 때..."라는 제목의 다른 기사를 작성할 생각입니다. 사실, PageRank는 출처의 권위, 전문성 및 신뢰성을 보여주는 결정적인 신호가 아닙니다. 순위의 신호일 수 있고 요인이 될 수 있지만 단독으로 신뢰할 수는 없습니다. RankMerge는 웹사이트가 검색 엔진에 이해될 수 있는 방식으로 웹사이트 트래픽과 PageRank를 통합하는 프로세스입니다. 높은 PageRank와 낮은 트래픽은 "인기 없는 트래픽" 또는 "PageRank 조작"을 나타낼 수 있습니다.
따라서 소스의 과거 데이터를 개선하기 위해 계절별 SEO 이벤트를 사용하고 "브랜드 + 일반 용어" 쿼리를 늘렸습니다. 직접 트래픽과 북마크된 웹 페이지는 실제 트래픽과 함께 증가합니다.
이러한 유형의 데이터는 검색 엔진이 SERP에서 더 높은 순위를 매길 수 있도록 신뢰하는 데 도움이 됩니다.
Semantic Content Network에서 오는 이러한 실제 트래픽을 감사할 수 있도록 SEO는 Google Analytics에서 맞춤 세그먼트를 만들어 직접 트래픽으로 오는 방법을 확인할 수 있습니다. 또한 첫 번째 시맨틱 콘텐츠 네트워크에서 두 번째 콘텐츠 네트워크로의 가능한 검색 여정을 만드는 것과 같은 사용자 지정 목표를 만들 수 있습니다. 이것은 시맨틱 네트워크가 관심, 개념 및 가능한 검색 관련 작업을 중심으로 구성된다는 개념 증명입니다.
아래에서 유기 트래픽을 통해 획득한 직접 트래픽을 보여주기 위해 첫 번째 시맨틱 콘텐츠 네트워크 내에 배치된 웹 페이지 중 하나에 대한 한 가지 예만 찾을 수 있습니다. 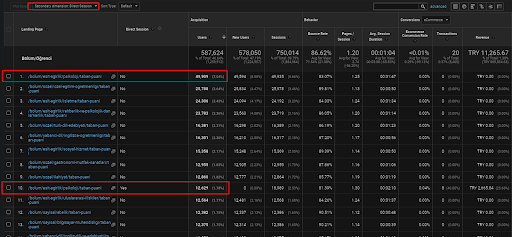
지난 3개월 동안 49,000명의 유기적 사용자가 첫 번째 의미론적 콘텐츠 네트워크에서 단 하나의 웹 페이지를 사용했습니다. 그리고 12,900명의 추가유저가 직접트래픽으로 유입되어 처음으로 오가닉 검색을 통해 확보하게 되었습니다. 그리고 세션/페이지 메트릭과 평균 세션 지속 시간은 이러한 사용자 세그먼트에서 더 높습니다.
이전에 말했듯이 검색 엔진은 쿼리, 문서, 의도, 개념, 관심사, 작업을 클러스터링할 수 있지만 사용자를 클러스터링할 수도 있습니다. 사용자 그룹이 이러한 웹페이지를 책갈피에 추가하고, 주소창을 직접 입력하고, 브랜드명과 함께 일반 용어를 검색하여 브랜드 가치를 창출하면서 긍정적인 피드백을 남기면 소스가 권위를 향상시키고 검색 엔진이 향상되었음을 보여줍니다. SERP, Chrome 및 자체 DNS 주소에서 모든 것을 인식할 수 있습니다. 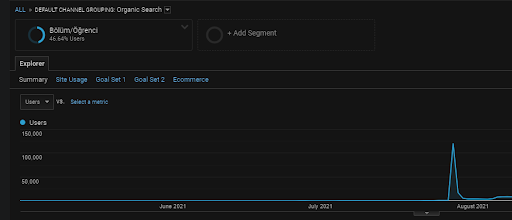
위에서 First Content Network의 사용자 세그먼트를 볼 수 있습니다. 사용자 정의 목표로 모든 시맨틱 콘텐츠 네트워크에 대한 사용자 세그먼트를 생성할 수 있으며 시맨틱 하위 콘텐츠 네트워크에 대한 하위 사용자 세그먼트도 추가할 수 있습니다.
8. 검색 활동에 기반한 하위 섹션으로 시맨틱 콘텐츠 네트워크 지원
이 섹션은 엔터티 속성 확인 및 또 다른 주제인 분석에 대해서도 설명합니다. 그러나 간단히 말해서 컨텍스트 도메인을 기반으로 하는 이러한 엔터티의 일부 속성은 상위 계층이 아닌 하위 계층에 배치되어야 합니다. 이 경우 "Vizem.net"이 더 좋은 예가 될 수 있고 Bogazici Enstitusu의 경우 "직업 급여" 및 "대학 시험 점수"로 시연할 수 있습니다. 이 두 가지 두드러진 속성은 시맨틱 하위 콘텐츠 네트워크에 대한 쿼리 및 문서 템플릿을 기반으로 배치되었습니다. 
검색 쿼리 내에서 의미 단위 식별은 구문을 다른 의미 범주로 나누고 쿼리의 모든 변형에 대한 근접성을 기반으로 문서의 관련성을 집계하는 또 다른 Google 특허입니다.
이전 SEO 사례 연구에서 저는 이러한 유형의 구조를 따르지 않고 엄격하게 제한된 내부 링크와 "연대기"를 기반으로 크롤링 경로를 만들었습니다. 이 기사에서 주요 콘텐츠 배치 내부 링크 양은 이전 것보다 높습니다.
9. URL 내 주제어 사용
Google이 정규화 신호 없이 동일한 콘텐츠를 포함하는 두 개의 다른 URL을 발견하면 짧은 URL을 정규화로 선택합니다. 짧은 URL은 구문 분석, 확인 및 요청이 더 쉽기 때문입니다. 매일 수십억 번 새로 고침하는 수조 개의 웹 페이지가 있는 경우 URL의 문자조차도 웹 사이트의 "비용/품질 균형"을 보여줄 수 있습니다. 앞서 말했듯이 "회수 비용"은 "회수하지 않는 비용"보다 낮아야 합니다. 검색 엔진이 이해하기를 원한다면 URL을 포함한 모든 수준에 "정렬되고 보완적인 컨텍스트 신호"를 넣어야 합니다. 
증거 집계를 통한 "증거 기반" 순위 섹션. 답변이 질문과 일치하는 방법을 설명합니다.
이러한 맥락에서 대부분의 경우 URL 내에서 한 단어를 사용합니다. 이는 의미론적 콘텐츠 네트워크의 계층 및 구조를 반영할 수 있습니다. 일부는 여전히 URL 내의 "레이어 수"가 크롤링 빈도에 영향을 미친다고 생각하지만 2019년 이전에는 사실이었습니다. 그러나 콘텐츠가 의미가 있고 인기 있거나 유명한 주제의 사용자를 만족시키는 한 그러한 상황의 영향을 받지 않습니다.
그것을 보여주기 위해 아래의 예를 따를 수 있습니다.
- Root-domain/semantic-content-network-1/type-1/sub-content-network-part-for-type-1
- Root-domain/semantic-content-network-2/type-2/sub-content-network-part-for-type-2
이 두 의미론적 콘텐츠 네트워크는 동일한 계층에서 서로를 연결할 수 있으며 관련성을 기반으로 자체적으로 연결할 수도 있습니다. "Entity Grouper Contents – Hub Type Content"와 같이 여기에서 더 많은 이야기를 할 수 있지만 다른 날의 주제입니다.
참고: 계획된 제3의 시맨틱 콘텐츠 네트워크는 "개념 그룹화 콘텐츠 네트워크"로도 처리될 수 있습니다. 그리고 그것이 퍼블리싱된다면 제2의 시맨틱 콘텐츠 네트워크의 효과로 전체 오가닉 트래픽은 월 3백만 세션이 넘을 수 있습니다.
10. 중첩과 연결의 차이점 이해
실제적인 방법론적 차이로서 연결은 맥락적 영역을 기반으로 유사한 것을 서로 연결하는 것이고, 중첩은 같은 목적을 가진 유사한 내용을 그룹화하는 것입니다. 이 클러스터링은 검색 엔진이 서로 유사한 콘텐츠를 더 빨리 찾고 이러한 그룹에 대한 소스 품질 점수를 생성하는 데 도움이 됩니다. 
아래와 같이 두 개의 다른 크롤링 경로가 있다고 상상해보십시오.
- 크롤링 경로 1: 템플릿, 유사성 및 문맥 관련성 없이 무작위로 URL을 만납니다.
- 크롤링 경로 2: 컨텍스트를 기반으로 하는 높은 수준의 유사성 및 관련성 템플릿을 사용하여 URL 자체에서도 의미가 있는 URL을 만납니다.
크롤링 경로에서라도 콘텐츠가 의미가 있다면 "검색 엔진의 커버리지 이해를 기반으로 한 재순위 트리거링" 덕분에 "초기 순위"와 "재순위"가 더 좋아질 것입니다.
참고: 적절한 방식으로 구문 분류와 함께 내부 링크를 사용하는 것은 중첩 및 연결에 중요합니다.
이것은 간단히 공유하는 마지막 두 가지 실용적인 방법론으로 우리를 인도합니다. 그리고, 이 섹션은 다시 높은 수준의 규율 및 조직적 충분성과 관련이 있습니다. 
HTML 목록 내에서 동시에 발생하는 용어를 인식한 Trystan Upstill과 Steven D. Baker의 특허. 이 특허의 두드러지는 주제 또는 구문 분류법의 일부에 대해 동시 발생 용어 목록을 결정하기 위해 단일 HTML 목록의 값을 보여줍니다.
11. 조정된 빈도로 시맨틱 콘텐츠 네트워크를 게시할 때 이해
이것은 이전에 설명되었지만 이러한 SEO 사례 연구 프로젝트 중 하나에서 저는 하루에 거의 400개의 콘텐츠를 게시했습니다. 다른 하나는 갑자기 10~15개의 콘텐츠만 올리기 시작했는데, 코로나 관련 경제적 문제가 시작될 때까지 꾸준하게 시간이 지남에 따라 속도를 높였습니다.
새로운 소스가 새로운 Semantic Content Network를 생성한다면, 첫날에 그것을 퍼블리싱하는 것이 생각보다 조금 어려울 수 있고, 웹 페이지의 모든 내부 링크, 문법 및 정보를 확인하는 것이 그렇게 쉬운 일이 아닙니다. 그러나 모든 콘텐츠가 단일 주제 및 쿼리 템플릿에서 비롯되고 소스에 해당 주제에 대한 기록이 없는 경우 의미론적 콘텐츠 네트워크의 대부분을 게시하면 더 빠른 인덱싱, 이해 및 재순위.
제 상황에는 계절성을 지닌 역사적 사건도 있었습니다. 그래서 내 목적은 검색 엔진에서 특정 엔터티에 대해 테스트하고 이전 소스에 대한 검색 활동을 테스트할 수 있을 때까지 충분한 수준의 평균 순위를 갖는 것이었습니다. 그래서 저는 시즌 이벤트로부터 45일 전에 높은 수준의 준비를 갖춘 첫 번째 Semantic Content Network를 발행했습니다.
그러면 아래와 같이 Search Engine이 소스를 반복적으로 테스트한 것을 볼 수 있습니다. 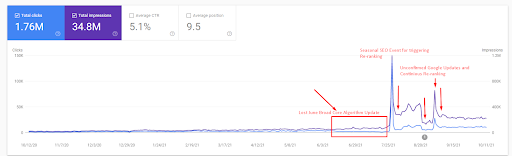
자세한 설명은 아래에서 확인할 수 있습니다. 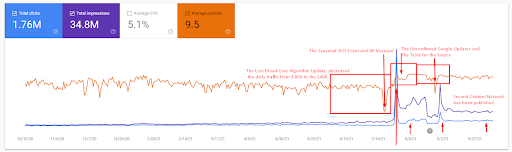
위의 스크린샷 설명에 대한 간단한 사실 확인은 아래에서 찾을 수 있습니다.
- Broad Core 알고리즘 업데이트로 웹사이트 트래픽이 200% 이상 감소했습니다.
- 웹사이트는 또한 15,000개 이상의 쿼리를 잃었습니다.
- 이것은 상세한 SEO 사례 연구 기사에서 더 잘 설명된 것처럼 새로운 의미론적 콘텐츠 네트워크에 대한 소스의 전체 인덱싱에 영향을 미쳤습니다.
- Seasonal SEO Event 덕분에 더 일찍 re-ranking이 이루어졌고, Seasonal SEO Event 이후에는 미확인 업데이트 동안 검색엔진이 실제 트래픽을 기반으로 소스의 순위를 정상화했습니다.
- First Semantic Content Network 및 Seasonal Event 덕분에 획득한 쿼리 및 순위는 보호되고 더욱 향상되었습니다.
- 첫 번째 Semantic Content Network는 새로운 Semantic Content Network와 두 번째 Semantic Content Network도 지원했습니다.
쿼리 손실과 평균 순위 손실도 Ahrefs에서 다음과 같이 볼 수 있습니다. 2021년 6월 Google Broad Core Algorithm Update(GBCAU) 효과와 미확인 업데이트의 효과를 확인하실 수 있습니다. 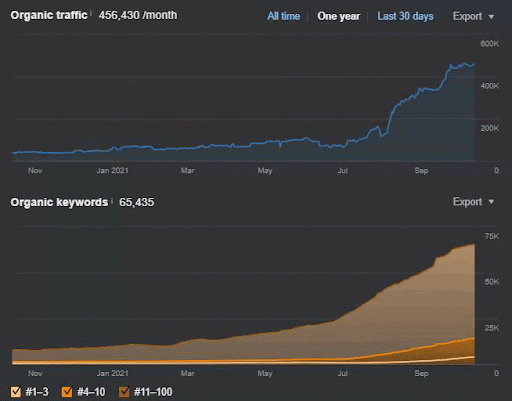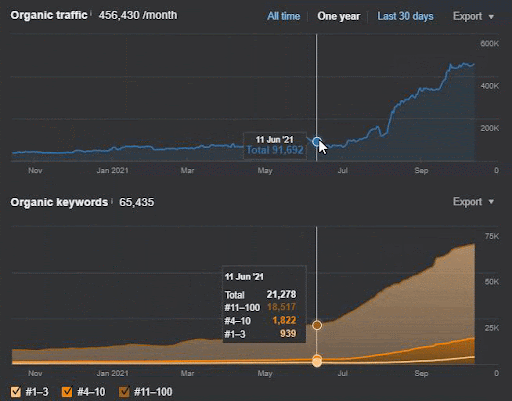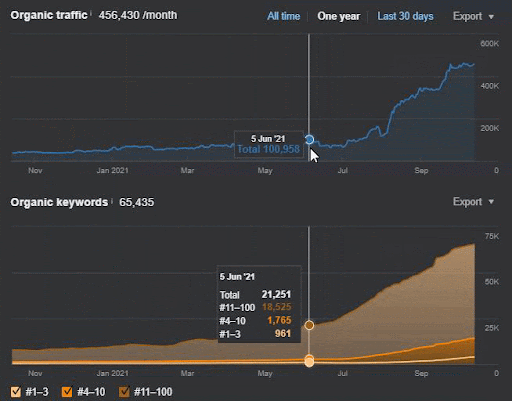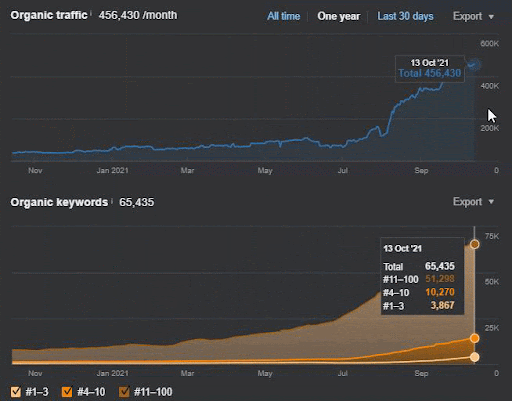
따라서 여러 가능한 전략을 가진 시맨틱 콘텐츠 네트워크를 사용하는 것이 필요합니다. GCBAU가 손실되더라도 여전히 검색 엔진 natura와 관련된 다른 요소 덕분에 SEO에 도움이 될 수 있습니다. 따라서 저자 또는 클라이언트에게 이러한 사항을 설명하는 것이 기술 SEO보다 어려운 이유를 상상할 수 있습니다. Semantic SEO는 숫자 값을 사용하지 않고 특허, 연구 논문, 경험 및 역사적 발표를 통해 검색 엔진 이해에서 나오는 이론적 지식을 사용합니다.
12. 더 나은 사실 구조를 위한 인페이지 문장 최적화 사용
솔직히 말하면, 10번째 목록조차도 완전히 새로운 주제이고 여기에 20,000단어를 작성해야 할 수도 있습니다. 그러나 간단한 예부터 시작하겠습니다.
- X는 Y입니다.
- Y는 X입니다.
위의 예시 문장의 경우 아래 내용을 이해할 수 있습니다.
- 위의 문장은 중복된 내용이 아닙니다.
- 위의 제안은 중복됩니다.
- 두 문장 사이의 관계 설명은 동일합니다.
- 시맨틱 역할 레이블은 100% 다릅니다.
- 명명된 엔터티 인식 출력은 100% 동일합니다.
페이지 내 문장 최적화는 질문 생성 알고리즘 및 질문-답변 페어링 기술과 관련이 있습니다. 질문 형식에는 특정 유형의 문장이 필요합니다. 그리고 특정 유형의 질문에는 특정 유형의 문장으로 답해야 합니다. 콘텐츠 형식, NER 및 Fact Extraction은 문장 구조 최적화의 영향을 받습니다. 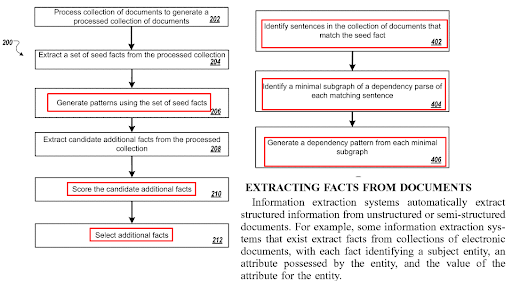
삼중항(객체 1개, 주제 2개)을 추출하여 정확도 면에서 더 빠르게 확인할 수 있습니다. 두 개의 유사한 문장이 중복되는 것이 아니라 문장 구조 측면에서 서로 가깝다는 것을 의미합니다. 명제가 다른 한, 서로 다른 쿼리 의도 쌍에 대해 유사한 문서 템플릿 간에 유사한 문장을 사용하는 것은 의미론적 콘텐츠 네트워크 생성에 필요합니다. 
적절한 패턴이 있는 명확한 문장 구조는 텍스트 조각을 서로 더 관련성 있게 만드는 동시에 검색 엔진이 이름이 지정된 엔티티, 주제, 속성을 서로의 값과 함께 인식하도록 돕는 데 유용합니다.
또한 기사의 어떤 섹션을 더 좋게 만들 수 있는지, 그리고 Topical Nets에서는 어떤 유형의 단어 쌍, 단어 벡터 및 의도에 대해 귀하의 콘텐츠 순위가 더 좋은지 확인하는 데 도움이 됩니다. 특정 유형의 질문에 대한 특정 유형의 문장 구조를 여러 웹 페이지에서 관찰할 수 있다면 끝없는 양의 데이터 샘플과 테스트 샘플이 있는 고급 SEO A/B 테스트에 도움이 되기 때문입니다. 여러 페이지 내 문장 디자인을 만들어 검색 엔진이 비교를 위해 사실을 추출하는 방법을 확인할 수 있습니다. 
사실을 말할 때 "지식 금고"와 루나 동을 기억해야합니다.
13. Fluff로 의견이 아닌 정확하고 일관성 있는 실제 정보 제공
여기서 정밀도는 숫자 값 또는 개념적 구체적인 관계와 비교할 수 있음을 의미합니다. 일관성이란 특정 제안에 대한 입장을 보호한다는 의미입니다. 예를 들어, Y와 관련된 모든 제품 리뷰에 대해 "X 제품이 Y에 가장 적합합니다"라고 말하지 마십시오. 사이트 전체에서 모순되는 제안을 제공하지 마십시오. 그리고 제품이 최고라면 그 증거는 무엇입니까? 재질, 크기 또는 색상과 냄새? 본문 내 보잘 것 없는 말은 불필요한 브릿지 단어를 사용하거나, 증명할 수 없는 것을 말하지 않거나, 진실과 모순되는 것을 의미합니다.
일부 예에서 지원하는 이러한 비정의적 지침의 맥락에서 Google의 언어 모델 중 하나인 KeALM을 확인할 수 있습니다.
data-to-text 모델로 데이터베이스에서 텍스트를 생성하기 위한 것으로 내용의 정확성을 확인하기 위한 것입니다. 
KELM은 텍스트-데이터 방식의 제안에 대한 정확성 감사의 예입니다.
이것은 또한 "Triple" 및 "Unknown Entities에 대한 공개 정보 추출"의 정의에 대한 약간의 설명입니다. 하지만 이것은 아시다시피 간략한 버전이고 제가 충분히 말씀드린 것 같습니다. 기본적으로 웹사이트에 잘못된 정보를 제공하는 경우 Google이 이를 이해할 수 있도록 하여 출처의 지식 기반 신뢰를 낮춥니다. 여기에서 지식 기반을 확장할 수 있기 때문에 PageRank 및 지식 기반 신뢰와 상관 소스가 있는 경우 검색 엔진이 사용자 정보를 기반으로 자체 지식 기반을 변경할 수 있음을 알아야 할 수도 있습니다. 높은 정확도와 독특한 삼중항.
14. 엔티티에 대한 의미론적 종속성 트리 이해
시맨틱 종속성 트리는 다른 엔터티와의 관계를 나타내는 속성이 그들 사이에 계층적 종속성을 갖는다는 것을 의미합니다. Semantic Dependency Tree는 여러 엔티티 프로파일을 확인하여 관찰할 수 있으며 국가가 조직의 구성원이 될 수 있고 다른 엔티티로서 이 조직이 추론된 관계로 연결된 국가에 귀속될 수 있는 몇 가지 다른 속성을 가질 수 있습니다.
아래에서 검색 엔진에서 직접 간단한 예를 볼 수 있습니다. 
REALM은 시맨틱 종속성 트리를 사용하여 모호한 텍스트에서 정보를 추출하는 방법입니다.
개방형 웹에서 개방형 정보 추출은 새로운 명명된 엔터티를 인식하고 이러한 동일한 엔터티를 다른 엔터티와 함께 발생하는 것으로 추출할 수 있습니다. 기사 내에서 이러한 동시 발생 및 상호 속성은 엔터티 간의 컨텍스트 및 후보 관계 유형을 할당할 수 있습니다. 연결 및 엔터티 유형을 기반으로 의미론적 종속성 트리를 생성할 수 있습니다. 어휘 의미론에서도 동일한 논리가 발생합니다. "소년"이라는 단어에는 몇 가지 가능한 의미와 정확한 다른 의미가 있습니다. 예를 들어, 소년은 남성이고 아마도 결혼하지 않은 십대일 것입니다. 학생 가까이에서도 사용할 수 있습니다. 반면에 "Queen"이라는 단어는 "여성", "총독"과 같은 다른 측면과 정확한 의미를 포함합니다. 따라서 통제할 것이 있다는 것은 "Queen of..." 또는 "For Quen"과 같은 일부 특정 유형의 쿼리 템플릿을 신호할 수 있는 자연스러운 의미론적 종속성 트리 계층입니다. These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together. 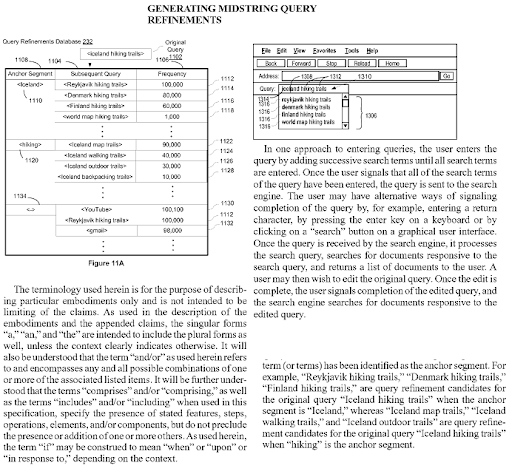
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network's connections to each other. Every midstring query refinement is a part of the topic's sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.