
Breadcrumb SEO, Python 3 및 Oncrawl: 자동화를 향한 길!
게시 됨: 2021-04-14OnCrawl 및 Python 3을 사용하여 이동 경로 기반 세분화를 자동으로 생성하는 방법을 알아보겠습니다.
Oncrawl에서 세분화란 무엇입니까?
Oncrawl은 세분화를 사용하여 페이지 집합을 그룹으로 분할합니다. 따라서 크롤링 보고서, 로그 분석 및 Google Analytics, Google Search Console, AT Internet, Adobe Analytics 또는 백링크용 Majestic과 크롤링 데이터를 혼합하는 기타 교차 분석 보고서의 데이터를 매우 쉽게 분석할 수 있습니다.
세분화를 만드는 것이 왜 중요한가요?
크롤링이 완료되면 사용자 지정 세분화를 만드는 것이 가장 중요합니다. 이를 통해 사이트와 해당 구조에 가장 적합한 관점에서 분석을 읽을 수 있습니다.
사이트의 페이지를 분할하는 방법에는 여러 가지가 있으며 옳고 그른 방법은 없습니다. 예를 들어 URL 구조를 기반으로 사이트 구조를 추적할 수 있습니다.
예를 들어, 이러한 종류의 URL " https://www.mydomain.com/news/canada/politics "는 다음과 같이 쉽게 분할될 수 있습니다.
- 홈페이지를 고립시키는 그룹
- 모든 뉴스를 위한 그룹
- 캐나다 디렉토리의 하위 그룹
- Politics 디렉토리의 하위 하위 그룹
보시다시피, 세분화에 대해 최대 3단계의 깊이를 생성할 수 있습니다. 이를 통해 세분화를 전환하지 않고도 SEO 분석의 특정 그룹 또는 하위 그룹에 집중할 수 있습니다.
기본 세분화는 어떻게 만듭니까?
Oncrawl은 자체적으로 첫 번째 분할 생성을 처리한다는 것을 알아야 합니다. 이것은 "첫 번째 경로" 또는 URL에서 발견된 첫 번째 디렉토리를 기반으로 합니다.
이를 통해 크롤링이 완료되는 즉시 분석을 사용할 수 있습니다.
이 세분화가 사이트의 구조를 반영하지 않거나 다른 각도에서 사물을 분석하기를 원할 수 있습니다.
따라서 Oncrawl Query Language를 의미하는 OQL이라고 하는 것을 사용하여 새 세분화를 만들 것입니다. SQL과 비슷하지만 훨씬 간단하고 직관적입니다. 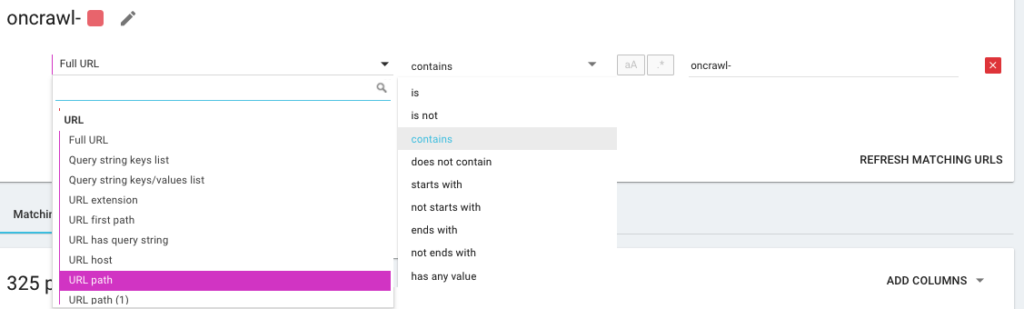
AND/OR 조건 연산자를 최대한 정확하게 사용할 수도 있습니다. 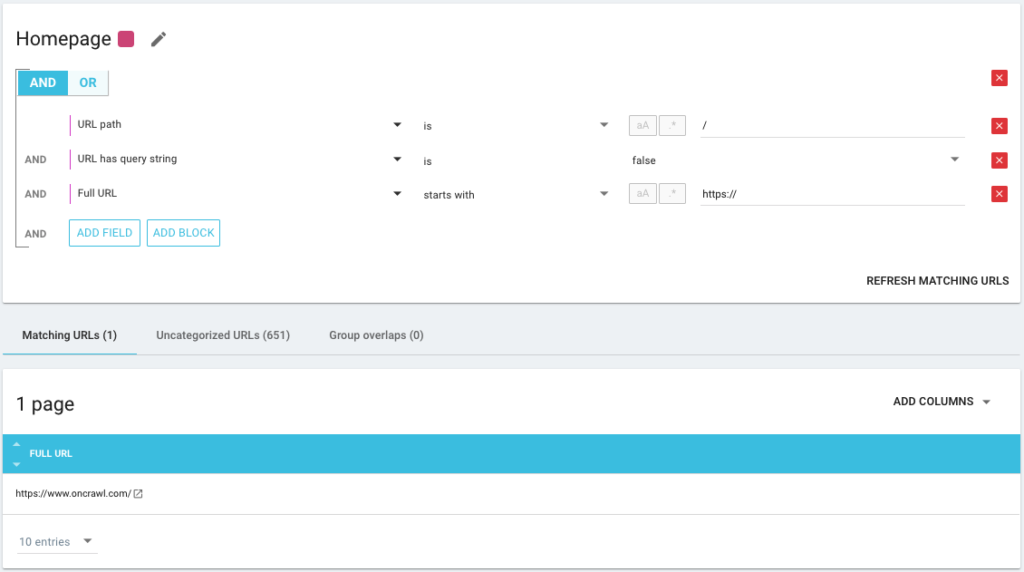
다른 방법을 사용하여 내 페이지 분할
다른 KPI 사용
URL을 기반으로 한 세분화도 좋지만 /car-rental/로 시작하고 H1에 " Car Rental Agency "라는 표현이 있는 그룹화 URL과 같은 다른 KPI도 결합할 수 있다면 완벽할 것입니다. " 유틸리티 렌탈 에이전시 ", 그게 가능합니까?
예, 가능합니다! 세분화를 생성하는 동안 크롤러의 KPI뿐만 아니라 커넥터의 KPI도 포함하여 우리가 사용하는 모든 KPI를 마음대로 사용할 수 있습니다. 이렇게 하면 세분화 생성이 매우 강력해지고 완전히 다른 분석 각도를 가질 수 있습니다!
예를 들어 Google Search Console 커넥터 덕분에 URL의 평균 위치를 사용하여 세분화를 만드는 것이 좋습니다.
이렇게 하면 내 구조에서 여전히 실행 중인 URL이나 Google의 2페이지에 있는 내 홈페이지에 가까운 URL을 쉽게 식별할 수 있습니다.
이 페이지에 중복된 콘텐츠가 있는지, 빈 제목 태그가 있는지, 충분한 링크를 받는지 등을 알 수 있습니다. Googlebot이 이러한 페이지에서 어떻게 작동하는지 볼 수도 있습니다. 크롤링 빈도가 좋은가 나쁜가? 요컨대, SEO와 ROI에 실질적인 영향을 미칠 우선 순위를 정하고 결정을 내리는 데 도움이 됩니다.
온크롤 데이터³
 더 알아보기
더 알아보기데이터 수집 사용
데이터 수집 기능에 익숙하지 않은 경우 먼저 해당 주제에 대한 이 기사를 읽어보시기 바랍니다. 이것은 Oncrawl에 외부 데이터 소스를 추가할 수 있는 또 다른 매우 강력한 도구입니다.
예를 들어, SEMrush, Ahrefs, Babbar.tech의 데이터를 추가할 수 있습니다... 이점은 이러한 도구에서 가져온 메트릭에 따라 페이지를 그룹화하고 관심 있는 데이터를 기반으로 분석을 수행할 수 있다는 것입니다. 기본적으로 Oncrawl에 있습니다.
최근에는 글로벌 호텔 그룹과 일했습니다. 그들은 내부 채점 방법을 사용하여 호텔 기록이 올바르게 작성되었는지, 이미지, 비디오, 콘텐츠 등이 있는지 여부를 확인합니다. 그들은 크롤링 및 로그 파일 데이터를 교차 분석하는 데 사용한 완료율을 결정합니다.
그 결과 Googlebot이 올바르게 채워진 페이지에서 더 많은 시간을 보내는지, 90% 이상의 점수를 받은 일부 페이지가 너무 깊은지, 충분한 링크를 수신하지 못하는지 등을 알 수 있습니다. 점수가 높을수록 페이지 방문이 많을수록 Google에서 페이지를 더 많이 탐색하고 Google SERP에서 더 나은 위치를 차지합니다. 호텔리어들이 호텔 목록을 작성하도록 독려하는 멈출 수 없는 논쟁!
SEO 이동 경로를 기반으로 세분화 만들기
이것이 이 기사의 주제이므로 문제의 핵심으로 들어가 보겠습니다. URL의 구조가 특정 디렉토리에 페이지를 첨부하지 않는 경우 사이트의 페이지를 분할하기 어려운 경우가 있습니다. 이것은 종종 제품 페이지가 모두 루트에 있는 전자 상거래 사이트의 경우입니다. 따라서 URL에서 페이지가 속한 그룹을 알 수 없습니다.
페이지를 그룹화하려면 페이지가 속한 그룹을 식별하는 방법을 찾아야 합니다. 따라서 우리는 Oncrawl에서 제공하는 Scraper 기능을 사용하여 각 URL의 이동 경로 SEO 추적을 검색하고 이동 경로 SEO의 값을 기반으로 분류하는 아이디어를 냈습니다.
Oncrawl을 사용한 SEO 이동 경로 스크래핑
위에서 보았듯이 이동 경로를 검색하기 위해 스크래핑 규칙을 설정할 것입니다. 대부분의 경우 div 에서 정보를 검색할 수 있기 때문에 매우 간단합니다. 그러면 각 레벨의 필드는
ul 및 li 목록: 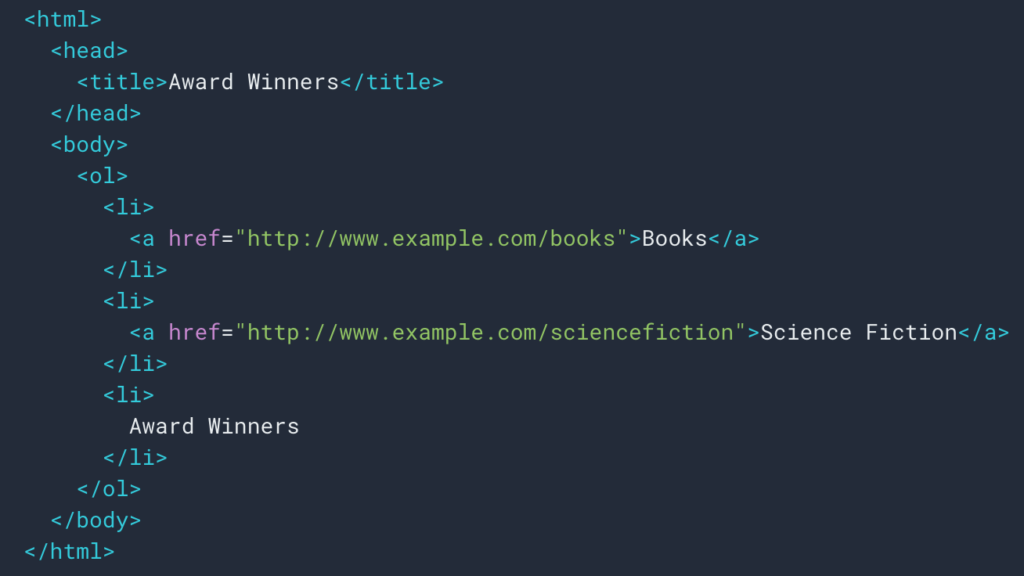
때로는 구조화된 데이터 유형 Breadcrumb 덕분에 정보를 쉽게 검색할 수도 있습니다. 따라서 각 위치에 대한 "이름" 필드의 값을 쉽게 검색할 수 있습니다. 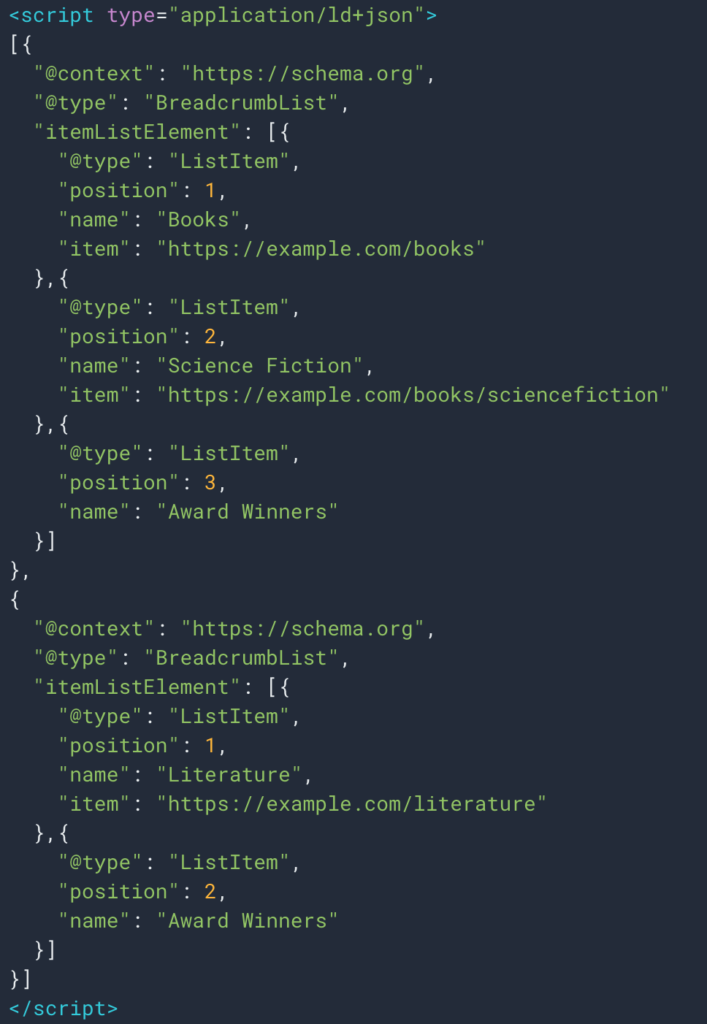
다음은 내가 사용하는 스크래핑 규칙의 예입니다. 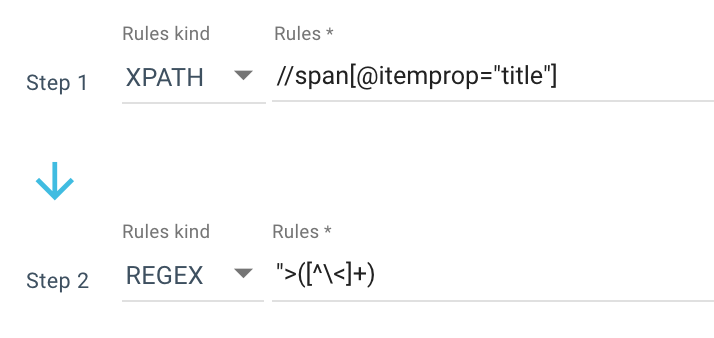
또는 다음 규칙: //li[contains(@class, "current-menu-ancestor") or contains(@class, "current-menu-parent") or contains(@class, "current-menu-item")]/a/text()
그래서 Xpath로 모든 span itemprop=”title” 을 얻은 다음 정규식을 사용하여 > 문자가 아닌 “> 이후의 모든 것을 추출합니다. Regex에 대해 더 알고 싶다면 주제에 대한 이 기사와 Regex에 대한 치트 시트를 읽는 것이 좋습니다.

출력으로 다음과 같은 여러 값을 얻습니다. 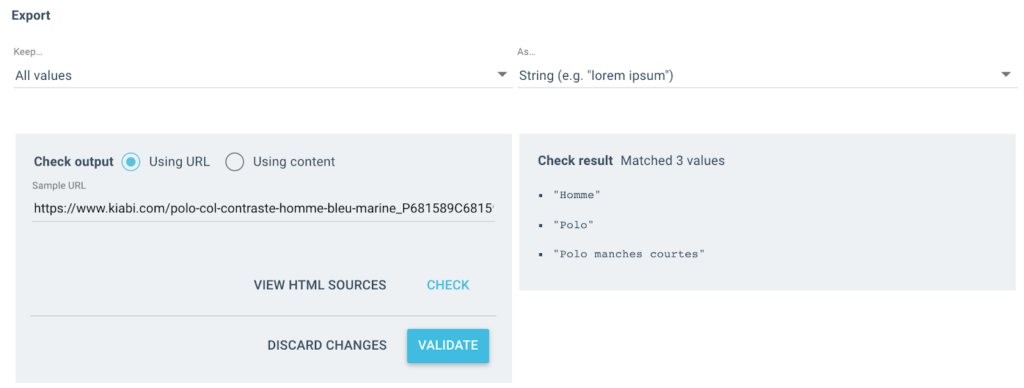
테스트된 URL의 경우 3개의 값이 있는 "Breadcrumb" 필드가 있습니다.
- 남성
- 폴로 셔츠
- 반팔 폴로
json 가져오기
무작위로 가져오기
가져오기 요청
# 정통
# 브라우저의 요청 헤더에서 얻을 수 있는 것보다 x-oncrawl-token을 사용하는 두 가지 방법
# 또는 여기에 api 토큰 사용: https://app.oncrawl.com/account/tokens
API_ACCESS_TOKEN = ' '
# 이동 경로 사용자 정의 필드가 있는 크롤링 ID를 설정합니다.
기다_
# 세분화에서 원하지 않는 금지된 이동 경로 항목을 업데이트합니다.
FORBIDDEN_BREADCRUMB_ITEMS = ('Accuei',)
FORBIDDEN_BREADCRUMB_ITEMS_LIST = [
대 스트립()
FORBIDDEN_BREADCRUMB_ITEMS.split(',')의 v용
]
def random_color():
random_number = random.randint(0, 16777215)
hex_number = str(hex(random_number))
hex_number = hex_number[2:].ljust(6, '0')
반환 f'#{hex_number}'
def value_to_group(값):
반품 {
'색상': random_color(),
'이름': 값,
'oql': {'or': [{'field': ['custom_Breadcrumb', '같음', 값]}]}
}
def walk_dict(사전, 수준=0):
렛 = {
"아이콘": "대시보드",
"transposable": 거짓,
"이름": "이동 경로"
}이제 규칙이 정의되었으므로 크롤링을 시작할 수 있으며 Oncrawl은 자동으로 이동 경로 값을 검색하여 크롤링된 각 URL과 연결합니다.
Python으로 다단계 세분화 생성 자동화
이제 각 URL에 대한 모든 SEO 이동 경로 값이 있으므로 Google Colab에서 SEO 자동화 파이썬 스크립트를 사용하여 Oncrawl과 호환되는 분할을 자동으로 생성합니다.
스크립트 자체의 경우 다음과 같은 3개의 라이브러리를 사용합니다.
- json(Json으로 작성된 분할 생성)
- CSV
- random(각 그룹에 대한 16진수 색상 코드 생성)
스크립트가 실행되면 자동으로 프로젝트에서 분할 생성을 처리합니다! 
분석의 데이터 미리보기
이제 세분화가 생성되었으므로 내 이동 경로를 기반으로 하는 세분화된 보기로 다양한 분석에 액세스할 수 있습니다. 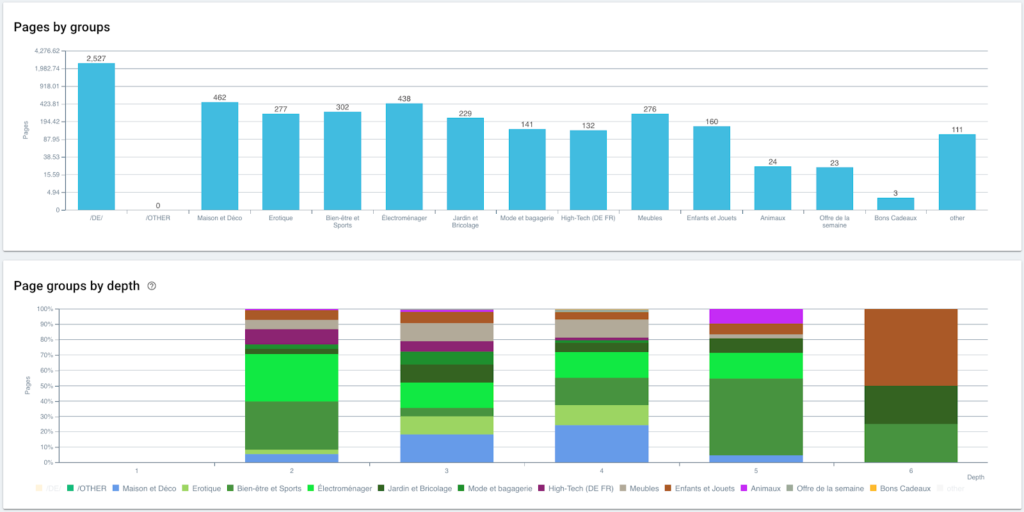
그룹 및 깊이별 페이지 분포
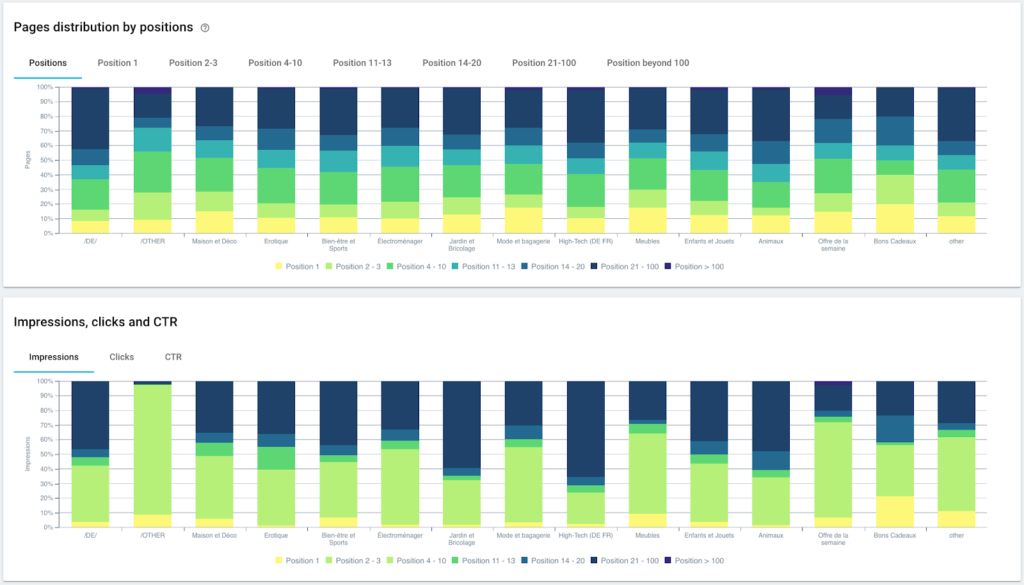
랭킹 실적(GSC)
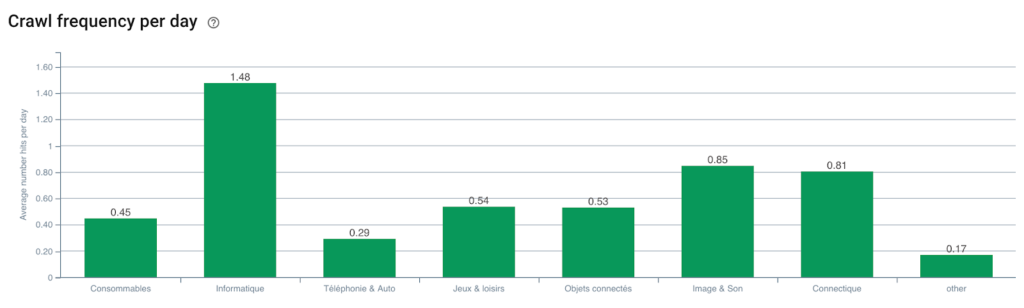
Googlebot 크롤링 빈도
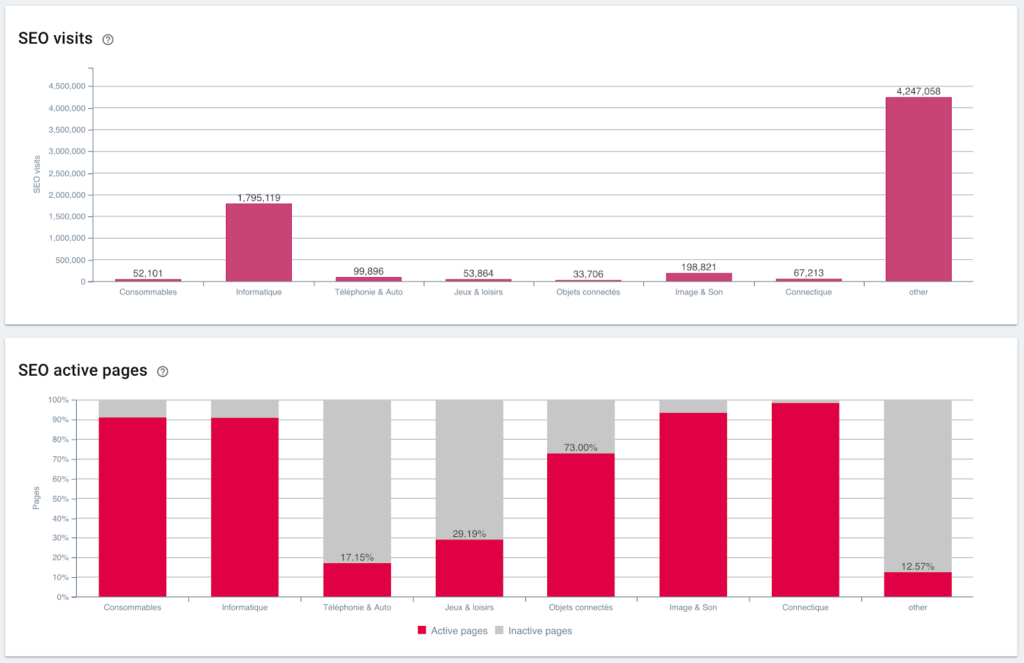
SEO 방문 및 활성 페이지 비율
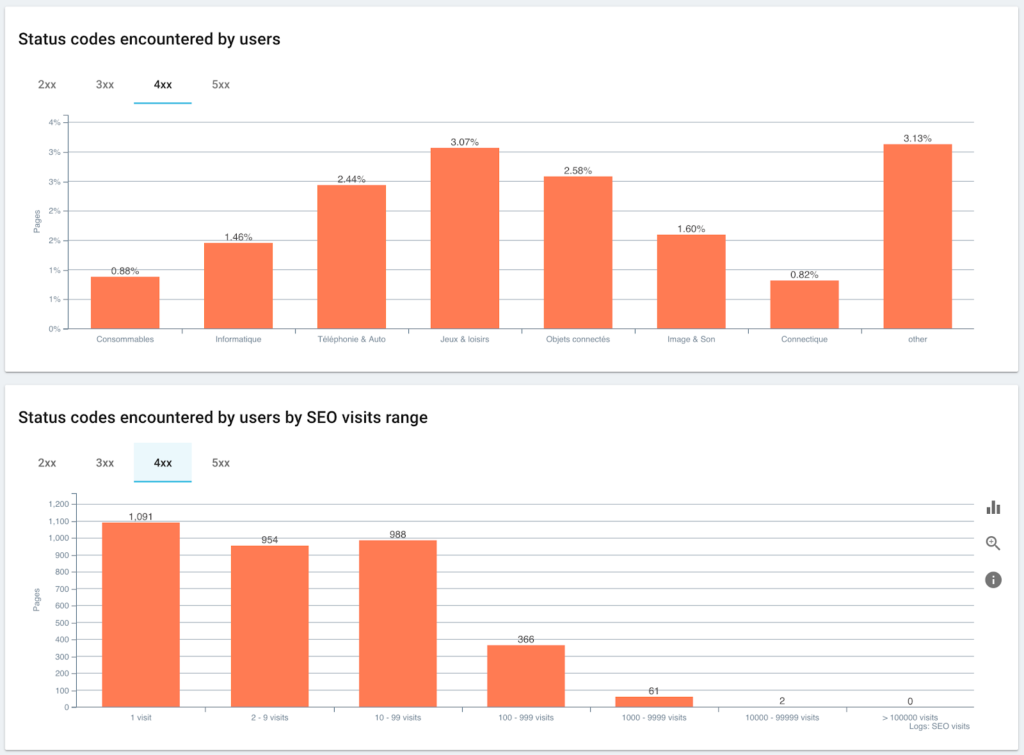
사용자와 SEO 세션이 마주하는 상태 코드
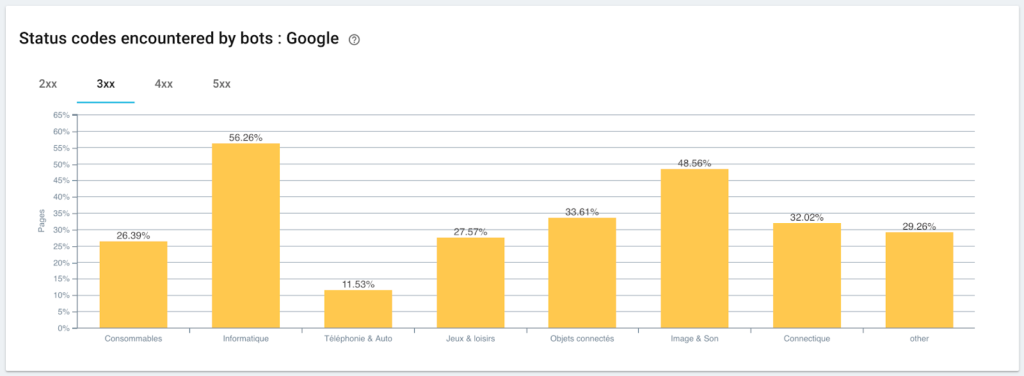
Googlebot이 발견한 상태 코드 모니터링
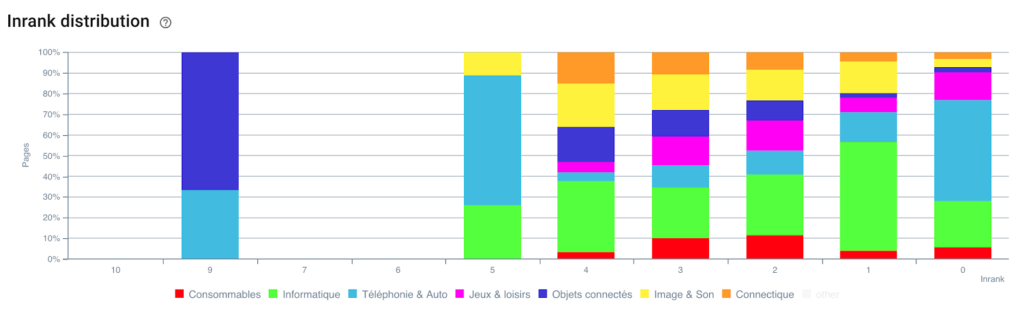
인랭크 분배
이제 Python과 OnCrawl을 사용하는 스크립트 덕분에 자동으로 분할을 만들었습니다. 모든 페이지는 이제 이동 경로 추적에 따라 그룹화되며 3가지 수준의 깊이로 그룹화됩니다. 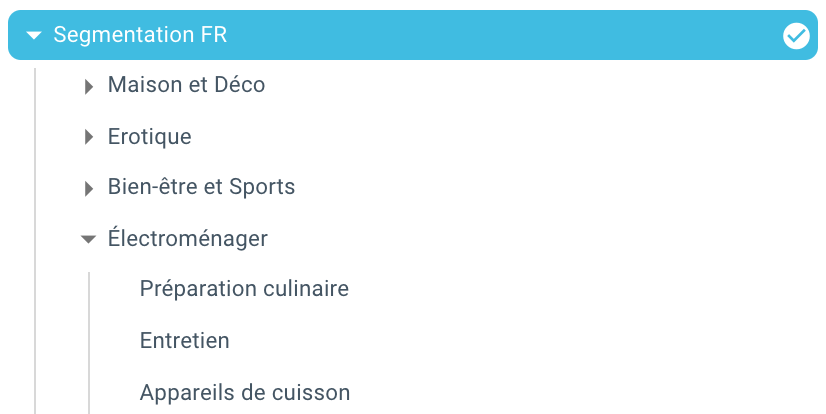
장점은 이제 각 그룹 및 페이지 하위 그룹에 대해 다양한 KPI(크롤링, 깊이, 내부 링크, 크롤링 예산, SEO 세션, SEO 방문, 순위 실적, 로드 시간)를 모니터링할 수 있다는 것입니다.
Oncrawl과 함께하는 SEO의 미래
이러한 "즉시 사용 가능한" 기능이 있으면 좋겠지만 모든 작업을 수행할 시간이 반드시 필요한 것은 아닙니다. 좋은 소식은 가까운 시일 내에 이 기능을 직접 통합하기 위해 노력하고 있다는 것입니다.
이는 곧 클릭 한 번으로 데이터 수집 에서 스크랩된 필드 또는 필드에 대한 분할을 자동으로 생성할 수 있음을 의미합니다. 그러면 엄청난 시간을 절약할 수 있을 뿐만 아니라 놀라운 횡단면 SEO 분석을 수행할 수 있습니다.
페이지의 소스 코드에서 데이터를 스크랩하거나 각 URL에 대한 KPI를 통합할 수 있다고 상상해 보십시오. 유일한 한계는 당신의 상상력입니다!
예를 들어, 제품의 판매 가격을 검색하고 가격에 따른 깊이, Inrank, 백링크, 크롤링 예산을 볼 수 있습니다.
그러나 우리는 또한 미디어 기사의 저자 이름을 검색하고 누가 가장 실적이 좋은지 확인하고 가장 효과적인 작성 방법을 적용할 수 있습니다.
우리는 귀하의 제품에 대한 리뷰와 평가를 검색하고 최고의 제품에 최소한의 클릭으로 액세스할 수 있는지, 충분한 링크를 수신하는지, 백링크가 있는지, Googlebot이 잘 크롤링하는지 등을 확인할 수 있습니다.
회전율, 마진, 전환율, Google Ads 비용과 같은 비즈니스 데이터를 통합할 수 있습니다.
이제 데이터를 상호 참조하여 분석을 확장하고 올바른 SEO 결정을 내리는 방법을 상상하는 것은 귀하에게 달려 있습니다.
이동 경로 추적에서 자동 분할을 테스트하시겠습니까? Oncrawl 내에서 직접 채팅 상자를 통해 저희에게 연락하십시오.
크롤링을 즐기십시오!