
텍스트에서 자동으로 개념 및 키워드 추출(파트 I: 기존 방법)
게시 됨: 2022-02-22Oncrawl의 R&D 부서에서는 웹 페이지의 의미론적 콘텐츠를 향상시키기 위해 점점 더 많은 노력을 기울이고 있습니다. 자연어 처리(NLP)용 기계 학습 모델을 사용하여 페이지 콘텐츠를 자세히 비교하고, 자동 요약을 생성하고, 기사 태그를 완성 또는 수정하고, Google Search Console 데이터에 따라 콘텐츠를 최적화하는 등의 작업을 수행할 수 있습니다.
이전 기사에서 HTML 페이지에서 텍스트 콘텐츠를 추출하는 방법에 대해 이야기했습니다. 이번에는 텍스트에서 키워드를 자동으로 추출하는 방법에 대해 이야기해보려고 합니다. 이 주제는 두 개의 게시물로 나뉩니다.
- 첫 번째는 몇 가지 구체적인 예와 함께 컨텍스트와 소위 "전통적인" 방법을 다룰 것입니다.
- 곧 나올 두 번째 방법은 이러한 다양한 방법을 벤치마킹하기 위해 변환기 및 평가 방법을 기반으로 하는 보다 의미론적인 접근 방식을 다룰 것입니다.
문맥
제목이나 초록 외에 몇 가지 키워드를 사용하는 것보다 텍스트, 과학 논문 또는 웹 페이지의 내용을 식별하는 더 좋은 방법이 어디 있겠습니까? 훨씬 긴 텍스트의 주제와 개념을 식별하는 간단하고 효과적인 방법입니다. 또한 일련의 텍스트를 분류하는 좋은 방법이 될 수 있습니다. 텍스트를 식별하고 키워드별로 그룹화하는 것입니다. PubMed 또는 arxiv.org와 같은 과학 기사를 제공하는 사이트는 이러한 키워드를 기반으로 카테고리 및 권장 사항을 제공할 수 있습니다.
키워드는 또한 매우 큰 문서의 색인을 생성하고 검색 엔진에서 잘 알려진 전문 분야인 정보 검색에 매우 유용합니다.
키워드의 부족은 과학 논문의 자동 분류에서 반복되는 문제입니다[1]: 많은 논문에 키워드가 할당되어 있지 않습니다. 따라서 텍스트에서 개념과 키워드를 자동으로 추출하는 방법을 찾아야 합니다. 자동으로 추출된 키워드 세트의 관련성을 평가하기 위해 데이터세트는 알고리즘으로 추출한 키워드를 여러 사람이 추출한 키워드와 비교하는 경우가 많습니다.
상상할 수 있듯이 이것은 웹 페이지를 분류할 때 검색 엔진이 공유하는 문제입니다. 키워드 추출의 자동화된 프로세스를 더 잘 이해하면 웹 페이지가 그러한 키워드에 대해 배치되는 이유를 더 잘 이해할 수 있습니다. 그것은 또한 당신이 목표로 한 키워드에 대해 좋은 순위를 정하지 못하게 하는 의미적 격차를 드러낼 수 있습니다.
텍스트나 단락에서 키워드를 추출하는 방법에는 분명히 여러 가지가 있습니다. 이 첫 번째 게시물에서는 소위 "고전적인" 접근 방식에 대해 설명합니다.
[전자책] 데이터 SEO: 다음 큰 모험
 전자책 읽기
전자책 읽기구속
그럼에도 불구하고 알고리즘 선택에는 몇 가지 제한 사항과 전제 조건이 있습니다.
- 메서드는 단일 문서에서 키워드를 추출할 수 있어야 합니다. 일부 방법에는 완전한 말뭉치(예: 수백 또는 수천 개의 문서)가 필요합니다. 이러한 방법은 검색 엔진에서 사용할 수 있지만 단일 문서에는 유용하지 않습니다.
- 우리는 감독되지 않은 기계 학습의 경우입니다. 프랑스어, 영어 또는 기타 언어로 된 주석이 달린 데이터 세트가 없습니다. 즉, 이미 추출된 키워드가 있는 수천 개의 문서가 없습니다.
- 메소드는 문서의 도메인/어휘 필드와 독립적이어야 합니다. 뉴스 기사, 웹 페이지 등 모든 유형의 문서에서 키워드를 추출할 수 있기를 원합니다. 각 문서에 대해 이미 추출된 키워드가 있는 일부 데이터 세트는 종종 도메인 특정 의학, 컴퓨터 과학 등입니다.
- 일부 방법은 POS 태깅 모델, 즉 동사, 명사, 한정사와 같은 문법적 유형으로 문장의 단어를 식별하는 NLP 모델의 기능을 기반으로 합니다. 한정사보다 명사인 키워드의 중요성을 결정하는 것은 분명히 관련이 있습니다. 그러나 언어에 따라 POS 태깅 모델의 품질이 매우 균일하지 않은 경우가 있습니다.
전통적인 방법에 대해
우리는 소위 "전통적인" 방법과 NLP(자연어 처리)를 사용하는 최신 방법(예: 단어 임베딩 및 컨텍스트 임베딩)을 구분합니다. 이 주제는 향후 게시물에서 다룰 것입니다. 그러나 먼저 고전적인 접근 방식으로 돌아가서 두 가지를 구별합니다.
- 통계적 접근
- 그래프 접근
통계적 접근은 주로 단어 빈도와 그 동시 발생에 의존합니다. 우리는 발견적 방법을 구축하고 중요한 단어를 추출하기 위한 간단한 가설로 시작합니다: 매우 빈번한 단어, 여러 번 나타나는 일련의 연속 단어 등. 그래프 기반 방법은 각 노드가 단어, 그룹에 해당할 수 있는 그래프를 작성합니다. 단어나 문장. 그런 다음 각 호는 이러한 단어를 함께 관찰할 확률(또는 빈도)을 나타낼 수 있습니다.
다음은 몇 가지 방법입니다.
- 통계 기반
- TF-IDF
- 갈퀴
- 야케
- 그래프 기반
- 텍스트 순위
- 주제 순위
- 싱글랭크
제공된 모든 예제는 이 웹 페이지에서 가져온 텍스트를 사용합니다. Jazz au Tresor: John Coltrane – Impressions Graz 1962.
통계적 접근
Rake와 Yake의 두 가지 방법을 소개합니다. SEO 맥락에서 TF-IDF 방식에 대해 들어본 적이 있을 것입니다. 그러나 문서 모음이 필요하므로 여기서는 다루지 않습니다.
갈퀴
RAKE는 Rapid Automatic Keyword Extraction의 약자입니다. rake-nltk를 포함하여 Python에는 이 방법의 여러 구현이 있습니다. 여러 단어를 포함하기 때문에 키프레이즈라고도 하는 각 키워드의 점수는 단어의 빈도와 동시 발생의 합계라는 두 가지 요소를 기반으로 합니다. 각 키 프레이즈의 구성은 매우 간단하며 다음으로 구성됩니다.
- 텍스트를 문장으로 자르다
- 각 문장을 키 프레이즈로 자르다
다음 문장에서는 구두점 요소나 불용어로 구분된 모든 단어 그룹을 사용합니다.
직전에 Coltrane은 Eric Dolphy가 그의 편에, Reggie Workman이 더블 베이스에 있는 5중주를 이끌고 있었습니다.
그 결과 다음과 같은 핵심 문구가 나타날 수 있습니다.
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" .
불용어 the " ", " in ", "and" or " it "과 같이 매우 자주 사용되는 일련의 단어입니다. 고전적인 방법은 종종 단어의 발생 빈도 계산을 기반으로 하므로 불용어를 신중하게 선택하는 것이 중요합니다. 대부분의 경우 우리는 키프레이즈 제안에서 >"to" , "of" "the" or "of"와 같은 단어를 원하지 않습니다. 실제로 이러한 불용어는 특정 어휘 분야와 관련이 없으므로 예를 들어 " jazz " 또는 " saxophone "이라는 단어보다 관련성이 훨씬 낮습니다.
여러 후보 키프레이즈를 분리하고 나면 단어의 빈도와 동시 발생에 따라 점수를 부여합니다. 점수가 높을수록 키프레이즈가 더 관련성이 있어야 합니다.
John Coltrane에 대한 기사의 텍스트로 빠르게 시도해 보겠습니다.

# 레이크용 파이썬 스니펫 rake_nltk에서 가져오기 레이크 # 'text' 변수에 이미 기사가 있다고 가정합니다. 레이크 = 레이크(중단어=FRENCH_STOPWORDS, 최대 길이=4) rake.extract_keywords_from_text(텍스트) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
다음은 처음 5개의 핵심 문구입니다.
"오스트리아 국립 공영 라디오", "더 천상의 서정적", "그라츠에는 두 가지 특성이 있습니다", "존 콜트레인 테너 색소폰", "오직 녹음된 버전"
이 방법에는 몇 가지 단점이 있습니다. 첫 번째는 불용어가 문장을 후보 키워드로 분할하는 데 사용되기 때문에 불용어 선택의 중요성입니다. 두 번째는 키프레이즈가 너무 길면 존재하는 단어의 동시 발생으로 인해 종종 더 높은 점수를 받게 된다는 것입니다. 키프레이즈의 길이를 제한하기 위해 max_length=4 로 메소드를 설정했습니다.
야케
YAKE는 또 다른 키워드 추출기의 약자입니다. 이 방법은 다음 기사 YAKE를 기반으로 합니다! 2020년부터 시작된 여러 로컬 기능을 사용하여 단일 문서에서 키워드 추출. 저자가 Github에서 사용 가능한 Python 구현을 제안한 RAKE보다 최신 방법입니다.
RAKE는 단어 빈도와 동시 발생에 의존합니다. 저자는 또한 흥미로운 발견적 방법을 추가할 것입니다.
- 소문자 단어와 대문자 단어(첫 글자 또는 전체 단어)를 구별합니다. 여기서 우리는 대문자로 시작하는 단어(문장의 시작 부분 제외)가 사람, 도시, 국가, 브랜드의 이름과 같은 다른 단어보다 더 관련성이 있다고 가정합니다. 이것은 모든 대문자 단어에 대해 동일한 원칙입니다.
- 각 후보 키프레이즈의 점수는 텍스트에서의 위치에 따라 달라집니다. 후보 키프레이즈가 텍스트의 시작 부분에 나타나면 끝 부분에 나타나는 경우보다 점수가 더 높습니다. 예를 들어, 뉴스 기사는 기사 시작 부분에 중요한 개념을 언급하는 경우가 많습니다.
# yake용 파이썬 스니펫 yake에서 KeywordExtractor를 Yake로 가져오기 yake = Yake(lan="fr", stopwords=FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords(텍스트)
RAKE와 마찬가지로 다음은 상위 5개 결과입니다.
"보물 재즈", "존 콜트레인", "임프레션 그라츠", "그라츠", "콜트레인"
일부 핵심 문구에서 특정 단어의 일부 중복에도 불구하고 이 방법은 매우 흥미로워 보입니다.
그래프 접근
이러한 유형의 접근 방식은 단어 동시 발생도 계산한다는 점에서 통계적 접근 방식과 크게 다르지 않습니다. TextRank 와 같은 일부 메서드 이름과 관련된 Rank 접미사는 들어오는 링크와 나가는 링크를 기반으로 각 페이지의 인기도를 계산하는 PageRank 알고리즘의 원리를 기반으로 합니다.
[전자책] Oncrawl로 SEO 자동화
 전자책 읽기
전자책 읽기텍스트 순위
이 알고리즘은 2004년의 TextRank: Bringing Order into Texts에서 가져온 것으로 PageRank 알고리즘과 동일한 원칙을 기반으로 합니다. 그러나 페이지와 링크로 그래프를 작성하는 대신 단어로 그래프를 작성합니다. 각 단어는 동시 발생에 따라 다른 단어와 연결됩니다.
Python에는 여러 가지 구현이 있습니다. 이 기사에서는 pytextrank를 소개합니다. 우리는 POS 태깅에 대한 우리의 제약 중 하나를 깨뜨릴 것입니다. 실제로 그래프를 작성할 때 모든 단어를 노드로 포함하지는 않습니다. 동사와 명사만 고려됩니다. 관련 없는 후보를 필터링하기 위해 불용어를 사용하는 이전 방법과 마찬가지로 TextRank 알고리즘은 문법 유형의 단어를 사용합니다.
다음은 알고리즘에 의해 구축될 그래프 일부의 예입니다. 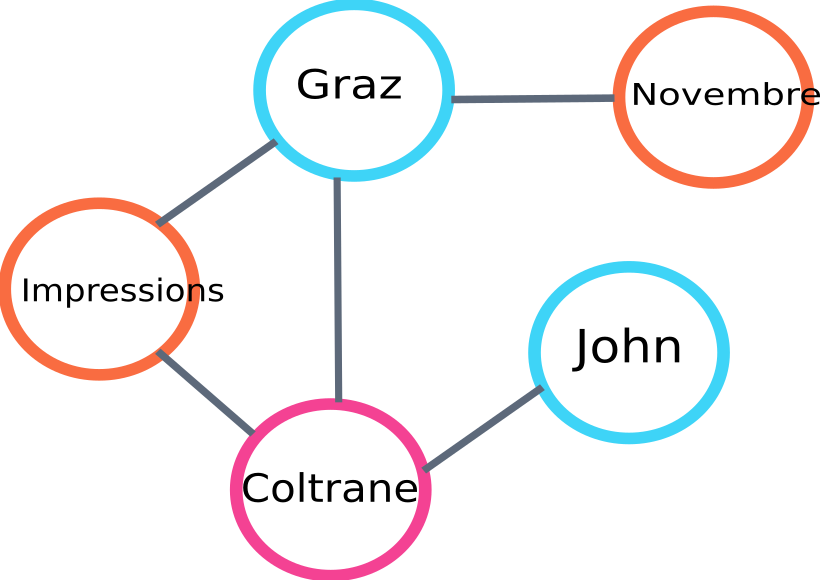
텍스트 순위 그래프 예
다음은 Python에서 사용하는 예입니다. 이 구현은 spaCy 라이브러리의 파이프라인 메커니즘을 사용합니다. POS 태깅이 가능한 라이브러리입니다.
# pytextrank용 파이썬 스니펫
수입 공간
가져오기 pytextrank
# 프랑스 모델 불러오기
nlp = spacy.load("fr_core_news_sm")
# 파이프에 pytextrank 추가
nlp.add_pipe("텍스트 순위")
문서 = nlp(텍스트)
textrank_keyphrases = doc._.phrases
다음은 상위 5개 결과입니다.
"Copenhague", "novembre", "Impressions Graz", "Graz", "John Coltrane"
TextRank는 키프레이즈를 추출하는 것 외에도 문장도 추출합니다. 이것은 소위 "추출 요약"을 만드는 데 매우 유용할 수 있습니다. 이 부분은 이 기사에서 다루지 않을 것입니다.
결론
여기에서 테스트한 세 가지 방법 중 마지막 두 가지는 본문의 주제와 매우 관련이 있는 것 같습니다. 이러한 접근 방식을 더 잘 비교하려면 더 많은 예제에서 이러한 서로 다른 모델을 평가해야 합니다. 실제로 이러한 키워드 추출 모델의 관련성을 측정하는 메트릭이 있습니다.
이러한 기존 모델에 의해 생성된 키워드 목록은 귀하의 페이지가 제대로 타겟팅되었는지 확인하기 위한 훌륭한 기초를 제공합니다. 또한 검색 엔진이 콘텐츠를 이해하고 분류하는 방법에 대한 첫 번째 근사치를 제공합니다.
반면에 BERT와 같은 사전 훈련된 NLP 모델을 사용하는 다른 방법을 사용하여 문서에서 개념을 추출할 수도 있습니다. 소위 고전적 접근 방식과 달리 이러한 방법을 사용하면 일반적으로 의미 체계를 더 잘 포착할 수 있습니다.
다양한 평가 방법, 컨텍스트 임베딩 및 변환기는 해당 주제에 대한 두 번째 기사에서 제공됩니다!
다음은 언급된 세 가지 방법 중 하나로 이 기사에서 추출한 키워드 목록입니다.
"메서드", "키워드", "키프레이즈", "텍스트", "추출된 키워드", "자연어 처리"
참고 문헌
- [1] 더 많은 언어 지식을 제공하는 향상된 자동 키워드 추출, Anette Hulth, 2003
- [2] 개별 문서에서 자동 키워드 추출, Stuart Rose et. 알, 2010
- [3] 야크! 여러 로컬 기능을 사용하여 단일 문서에서 키워드 추출, Ricardo Campos et. 알, 2020
- [4] TextRank: 텍스트에 질서 가져오기, Rada Mihalcea et. 알, 2004
14일 무료 평가판 시작
 평가판 시작
평가판 시작