
OnCrawl을 사용한 5가지 시간 절약 팁
게시 됨: 2017-06-21고급 OnCrawl 기능을 활용하여 일일 SEO 모니터링 중에 효율성을 개선하는 방법.
OnCrawl은 전자 상거래 웹사이트, 온라인 게시자 또는 애플리케이션에 대한 검색 엔진의 가시성을 모니터링하고 최적화하는 데 도움이 되는 강력한 SEO 도구입니다. 이 도구는 트래픽 관리자가 분석 프로세스와 일일 SEO 프로젝트 관리에서 시간을 절약할 수 있도록 돕는 간단한 원칙을 중심으로 구축되었습니다.
모든 웹사이트 데이터를 통합하는 API가 지원하는 SaaS 플랫폼을 기반으로 하는 현장 감사 도구일 뿐만 아니라 로그 서버 파일에서 데이터 추출 및 분석을 간소화하는 로그 분석기이기도 합니다.
OnCrawl의 가능성은 매우 넓지만 마스터해야 합니다. 이 기사에서는 SEO 크롤러 및 로그 분석기를 매일 사용하기 위한 5가지 시간 절약 팁을 공유합니다.
1# HTTP 및 HTTPS URL을 분류하는 방법
HTTPS 마이그레이션은 SEO 영역에서 뜨거운 주제입니다. 이 핵심 단계를 완벽하게 처리하려면 두 프로토콜에서 봇 동작을 정확하게 따르는 것이 중요합니다.
경험에 따르면 봇이 HTTP에서 HTTPS로 완전히 전환하는 데 다소 시간이 걸립니다. 평균적으로 이러한 전환은 사이트 품질 및 마이그레이션과 관련된 외부 및 내부 요인에 따라 몇 주 또는 몇 달이 걸립니다.
크롤링 예산이 크게 영향을 받는 전환 단계를 정확하게 이해하려면 봇 히트를 모니터링하는 것이 좋습니다. 따라서 서버 로그 분석이 필요합니다. 봇은 일반 사용자로서 그가 만드는 모든 페이지, 리소스 및 요청에 흔적을 남깁니다. 로그는 이러한 호출을 전달한 포트를 소유합니다. 따라서 HTTPS 웹사이트의 마이그레이션 품질을 확인할 수 있습니다.
페이지 그룹의 전용 http 대 https 세트를 설정하는 방법
고급 프로젝트 홈에서 오른쪽 상단 모서리에 "설정" 버튼이 있습니다. 그런 다음 "페이지 그룹 구성" 메뉴를 선택합니다. 여기에서 새 "그룹 집합 만들기"를 만들고 이름을 "HTTP 대 HTTPS"로 지정합니다.
로그에 액세스하려면 "로그 모니터링 및 교차 분석 대시보드에서 이 세트를 사용하고 싶습니다" 옵션을 선택하는 것이 중요합니다.
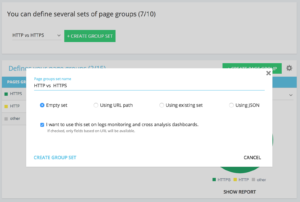
- HTTPS : "전체 URL" / "다음으로 시작" / https
- HTTP : "전체 URL" / "다음으로 시작하지 않음" / https
저장되면 HTTPS 마이그레이션 보기에 액세스할 수 있습니다(로그 라인에 요청 포트를 추가한 경우. 가이드를 볼 수 있습니다.)
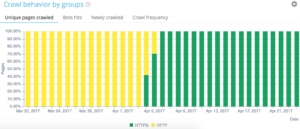
당사의 QuickFilter는 데이터 탐색기에서 찾을 수 있습니다. 404, 500 또는 301/302를 가리키는 링크, 너무 느리거나 너무 열악한 페이지 등과 같은 일부 중요한 SEO 메트릭에 쉽게 액세스할 수 있도록 제작되었습니다.
전체 목록은 다음과 같습니다.
- 404 오류
- 5xx 오류
- 활성 페이지
- Google에서 크롤링하지 않은 활성 페이지
- Google에서 발견한 상태 코드가 200과 다른 활성 페이지
- 표준이 일치하지 않음
- 표준이 설정되지 않음
- 인덱싱 가능한 페이지
- 인덱싱 가능한 페이지 없음
- 고아 활성 페이지
- 고아 페이지
- Google에서 크롤링한 페이지
- Google 및 OnCrawl에서 크롤링한 페이지
- Google에서 크롤링하지 않는 구조의 페이지
- 3xx 오류를 가리키는 페이지
- 4xx 오류를 가리키는 페이지
- 5xx 오류를 가리키는 페이지
- 잘못된 h1이 있는 페이지
- 잘못된 h2가 있는 페이지
- 잘못된 메타 설명이 있는 페이지
- 제목이 잘못된 페이지
- HTML 복제 문제가 있는 페이지
- 인링크가 10개 미만인 페이지
- 리디렉션 3xx
- 너무 무거운 페이지
- 너무 느린 페이지
그러나 때때로 이러한 QuickFilter가 모든 비즈니스 문제에 답을 주지는 않습니다. 이 경우 그 중 하나에서 시작하여 필터에 조각을 추가하고 도구에 연결할 때마다 필터를 빠르게 찾을 수 있도록 저장하여 "자체 필터"를 만들 수 있습니다.
예를 들어, 4xx를 가리키는 링크에서 빈 앵커가 있는 링크를 필터링하도록 선택할 수 있습니다("Anchor" / "is" / ""). 그리고 해당 필터를 저장할 수 있습니다. 한 번 저장하면 필요한 만큼 수정할 수 있습니다.
이제 아래 스크린샷과 같이 "소유" 부분 하단의 "퀵필터 선택" 목록에서 특정 "퀵필터"에 직접 액세스할 수 있습니다.
3# DataLayer 관련 사용자 정의 필드를 설정하는 방법은 무엇입니까?
예를 들어 분석 도구 태그를 정의할 때 관련 페이지 유형의 세분화를 사용할 수 있습니다. 이 특정 코드는 OnCrawl의 데이터를 외부 데이터와 분할하거나 교차하는 데 매우 흥미가 있습니다.
분석을 위한 "중추 열"을 생성할 수 있도록 크롤링 중에 이러한 코드 조각을 추출하고 프로젝트의 데이터 유형으로 다시 가져올 수 있습니다.
"사용자 정의 필드" 옵션을 사용하면 정규식 또는 XPath 덕분에 소스 코드 페이지의 모든 요소를 긁을 수 있습니다. 이러한 언어에는 고유한 정의와 규칙이 있습니다. 여기에서 XPath에 대한 정보를, 여기에서 정규식에 대한 정보를 찾을 수 있습니다.
사용 사례 1: 페이지 소스 코드에서 데이터 레이어 데이터 추출
분석할 코드:


솔루션 : "regex" 사용 : s.prop2=”([^”]+)” / Extract : Mono-value / Field Format : Value

- s.prop2=" 문자열 찾기
- "(추출할 데이터 다음의 첫 번째 문자)가 아닌 모든 문자를 긁습니다.
- "를 닫기 전에 추출할 문자열을 찾을 수 있습니다.
크롤링 후 데이터 탐색기에서 sProp2, sProp3 열 또는 이름 필드에서 추출된 데이터를 찾을 수 있습니다.

XPATH 사용
분석할 코드:
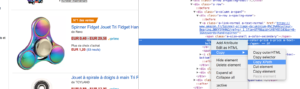
Chrome 코드 분석기에서 직접 스크랩하려는 Xpath 요소를 복사/붙여넣기만 하면 됩니다. 코드가 JavaScript로 렌더링되는 경우 사용자 지정 스크래핑 프로젝트를 설정해야 합니다. Xpath 언어는 매우 강력하고 조작하기 어려울 수 있으므로 도움이 필요하면 전문가에게 문의하십시오.
사용 사례 3: 수신 단계에서 분석 태그 존재 테스트
정규식 사용
분석할 코드:

Solution : "regex" 사용 : '_setAccount', 'UA-364863-11' / Extract : 존재하는지 확인
문자열이 발견되면 데이터 탐색기에 "true"가 표시되고, 반대로 "false"가 표시됩니다.
4# 웹사이트의 각 부분에서 Google 크롤링 빈도를 시각화하는 방법
크롤링 예산은 SEO 문제의 핵심입니다. 이는 "페이지 중요성" 개념 및 Google의 크롤링 일정과 깊이 관련되어 있습니다. 2012년부터 Google 특허에 도입된 이러한 원칙을 통해 Mountain View 사회는 웹 크롤링 전용 리소스를 최적화할 수 있습니다.
Google은 웹사이트의 모든 부분에 동일한 에너지를 사용하지 않습니다. 웹사이트의 각 부분에 대한 크롤링 빈도는 Google이 보기에 페이지의 중요성에 대한 정확한 통찰력을 제공합니다.
크롤링 예산은 페이지 순위 기술과 밀접하게 연결되어 있기 때문에 중요한 페이지는 Google 봇이 더 많이 크롤링합니다.
OnCrawl Advanced 프로젝트를 사용하면 기본적으로 "로그 모니터링" / "크롤링 동작" / "그룹별 크롤링 동작" 부분에서 크롤링 예산을 볼 수 있습니다.
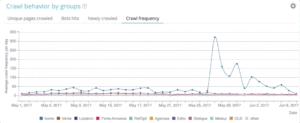
"홈 페이지" 그룹의 크롤링 빈도가 가장 높은 것을 볼 수 있습니다. Google이 지속적으로 새로운 기사를 찾고 있으며 일반적으로 홈페이지에 나열되기 때문에 정상적인 현상입니다. 페이지 중요성 아이디어는 Google Freshness 개념과 깊은 관련이 있습니다. 홈페이지는 Google 크롤링 예산의 우선순위를 정하는 데 가장 중요한 페이지입니다. 그런 다음 최적화는 깊이와 인기도에 관한 다른 페이지로 퍼집니다.
그러나 주파수 차이를 확인하는 것은 어렵습니다. 따라서 제거하려는 그룹을 클릭하고(범례를 클릭하여) 데이터가 표시되는지 확인해야 합니다.
5# 마이그레이션 후 URL 목록에서 상태 코드를 테스트하는 방법
URL 집합에서 상태 코드를 빠르게 테스트하려는 경우 새 크롤링 설정을 수정할 수 있습니다.
- 모든 시작 URL 추가("시작 URL 추가" 버튼)
- 최대 깊이를 1로 정의
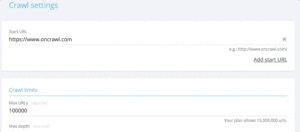
이 사용자 지정 크롤링은 이 URL 집합과 관련된 정성적 데이터를 반환합니다.
리디렉션이 제대로 설정되었는지 확인하거나 시간이 지남에 따라 상태 코드의 발전을 따를 수 있습니다. 정기적으로 크롤링하는 것의 이점에 대해 생각하면 자동으로 이전 URL을 추적할 수 있습니다.
API를 통해 자동화된 대시보드를 만들고 이러한 측면에 대한 자동화된 테스트 모니터링을 생성하지 않으시겠습니까?
이러한 해킹이 OnCrawl을 사용하여 효율성을 개선하는 데 도움이 되기를 바랍니다. 아직 보여드릴 고급 트릭이 많이 있습니다. 예를 들어 Twitter에서 #oncrawlhacks를 공유해 주세요. 사용자가 우리 도구를 사용하는 것만큼 많은 즐거움을 누릴 수 있어 기쁩니다.